
在本教程中,你将学到:
- 什么是 LangChain MCP Adapters 库,以及它能提供什么功能。
- 为何通过 Bright Data Web MCP 为代理提供网页搜索、网页数据获取与网页交互能力。
- 如何在 ReAct 代理中将 LangChain MCP Adapters 连接到 Web MCP。
我们开始吧!
什么是 LangChain MCP Adapters 库?
LangChain MCP Adapters 是一个让你在 LangChain 和 LangGraph 中使用 MCP 工具的包。它通过开源的 langchain-mcp-adapters 提供,负责将 MCP 工具转换为与 LangChain 和 LangGraph 兼容的工具。
得益于这种转换,你可以在 LangChain 工作流或 LangGraph 代理中,直接使用来自本地或远程服务器的 MCP 工具。这些 MCP 工具的使用方式与已经发布给 LangGraph 代理的数百个工具相同。
此外,该包还包含一个 MCP 客户端实现,让你可以连接多个 MCP 服务器并从中加载工具。更多使用方法请参见官方文档。
为什么要将 LangGraph 代理与 Bright Data 的 Web MCP 集成
用 LangGraph AI 构建的 AI 代理会继承其底层 LLM 的限制,其中包括无法访问实时信息,有时会导致回答不准确或过时。
幸运的是,这一限制可以通过为代理配备最新的网页数据与实时网页探索能力来克服。这正是 Bright Data 的 Web MCP 派上用场的地方!
Web MCP 作为一个开源 Node.js 包提供,可与 Bright Data 的一系列面向 AI 的数据获取工具集成,使你的代理能够随时访问网页内容、查询结构化数据集、执行网页搜索,并与网页进行交互。
其中,Web MCP 暴露的两个常用工具包括:
| 工具 | 描述 |
|---|---|
scrape_as_markdown |
以高级提取选项抓取单个网页 URL 的内容,并以 Markdown 形式返回结果。可绕过机器人检测与 CAPTCHA。 |
search_engine |
从 Google、Bing 或 Yandex 提取搜索结果,并以 JSON 或 Markdown 格式返回 SERP 数据。 |
此外,Bright Data 的 Web MCP 还提供约 60 个专用工具,用于与网页交互(例如 scraping_browser_click)以及从各种网站收集结构化数据,包括 Amazon、TikTok、Instagram、Yahoo Finance、LinkedIn、ZoomInfo 等。
例如,web_data_zoominfo_company_profile 工具通过接收有效的公司 URL 作为输入,从 ZoomInfo 获取详细的结构化公司信息。在官方 Web MCP 文档了解更多!
如果你想直接通过 LangChain 工具进行Bright Data 集成,请参考以下指南:
如何使用 LangChain MCP Adapters 在 AI 代理中连接 Web MCP
在此分步教程中,你将学习如何使用 MCP Adapters 库将 Bright Data Web MCP 集成到 LangGraph 代理中。最终,你的 AI 代理将获得 60+ 个用于网页搜索、数据访问与网页交互的工具。
设置完成后,我们将让该 AI 代理获取 ZoomInfo 的公司数据并生成一份详细报告。该输出可帮助你评估一家企业是否值得投资、投递简历或进一步调研。
按以下步骤开始!
说明:本教程以 Python 版 LangChain 为主,但也可轻松改编为 LangChain JavaScript SDK。同理,虽然示例使用 OpenAI,你也可以替换为 LangChain 支持的任何其他 LLM。
前置条件
要跟随本教程,请确保你已经具备:
- 本地安装 Python 3.8+。
- 本地安装 Node.js(推荐最新 LTS 版本)。
- 一个 Bright Data API key。
- 一个 OpenAI API key(或来自任何LangChain 支持的其他 LLM的 API key)。
暂时不必担心 Bright Data 的具体设置,下一步会逐步引导。
下面这些背景知识也会有帮助(可选):
- 对MCP 工作原理的基本了解。
- 对 Bright Data 的 Web MCP 及其提供的工具稍有熟悉。
步骤一:创建你的 LangChain 项目
打开终端,为你的 LangGraph MCP 驱动的 AI 代理创建一个新目录:
mkdir langchain-mcp-agentlangchain-mcp-agent/ 文件夹将存放你的 AI 代理的 Python 代码。
然后,进入该目录并创建一个虚拟环境:
cd langchain-mcp-agent
python -m venv .venv现在,用你喜欢的 Python IDE 打开该项目。我们推荐 安装了 Python 扩展的 Visual Studio Code 或 PyCharm 社区版。
在项目文件夹内,新建一个名为 agent.py 的文件。你的项目结构应如下:
langchain-mcp-agent/
├── .venv/
└── agent.pyagent.py 将作为主 Python 文件。先初始化为异步执行:
import asyncio
async def main():
# Agent definition logic...
if __name__ == "__main__":
asyncio.run(main())该激活虚拟环境。在 Linux 或 macOS 上运行:
source .venv/bin/activate在 Windows 上等效命令为:
.venv/Scripts/activate激活环境后,安装所需依赖:
pip install langchain["openai"] langchain-mcp-adapters langgraph各包的作用如下:
langchain["openai"]:LangChain 核心库与 OpenAI 集成。langchain-mcp-adapters:将 MCP 工具适配为 LangChain 与 LangGraph 可用的轻量封装。langgraph:一个用于构建、管理和部署长生命周期、有状态代理的底层编排框架,通常与 LangChain 配合使用。
注意:如果不计划使用 OpenAI 进行 LLM 集成,请将 langchain["openai"] 替换为你的 AI 提供商的等效集成包。
完成!你的 Python 开发环境已准备好连接 Bright Data Web MCP 的 AI 代理。
步骤二:集成你的 LLM
免责声明:如果你使用的不是 OpenAI,而是其他 LLM 提供商,请相应调整本节内容。
首先,在环境中设置你的 OpenAI API key:
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"在生产环境中,请使用更安全可靠的方式(例如 python-dotenv)来管理环境变量,避免将密钥直接硬编码在脚本中。
接着,从 langchain_openai 包中导入 ChatOpenAI:
from langchain_openai import ChatOpenAIChatOpenAI 会自动读取 OPENAI_API_KEY 环境变量。
现在,在 main() 函数中,用所需模型初始化一个 ChatOpenAI 实例:
llm = ChatOpenAI(
model="gpt-5-mini",
)此处使用 gpt-5-mini,你也可以替换为任何其他可用模型。该 LLM 实例将作为 AI 代理的引擎。
步骤三:测试 Bright Data Web MCP
在将代理连接到 Bright Data 的 Web MCP 前,先验证你的机器是否能运行 MCP 服务器。
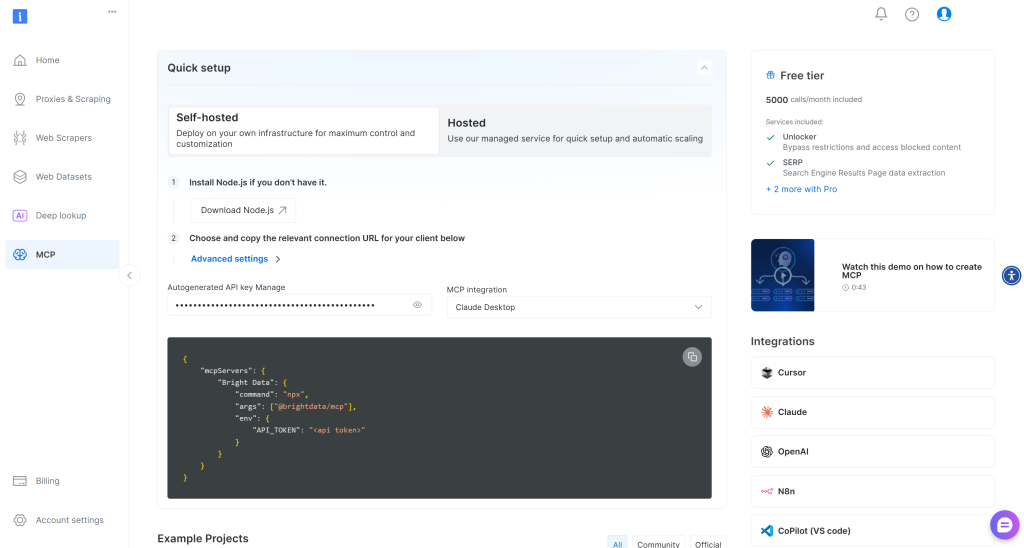
如果还没有账号,请先创建一个 Bright Data 账号;如果已有,直接登录。为了快速设置,打开你账号中的 “MCP” 页面并按指引操作:
否则,请按如下更详细的步骤操作。
首先,生成一个 Bright Data API key 并妥善保存(稍后会用到)。本教程将假设该 API key 具有 Admin 权限,这会让集成过程更为简单。
打开终端,通过 @brightdata/mcp 包全局安装 Web MCP:
npm install -g @brightdata/mcp通过以下 Bash 命令验证本地 MCP 服务器是否可运行:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp在 Windows PowerShell 中等效命令为:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你的 Bright Data API token。以上两条命令会设置必需的 API_TOKEN 环境变量,并在本地启动 MCP 服务器。
如果成功,你应能看到类似如下的日志:

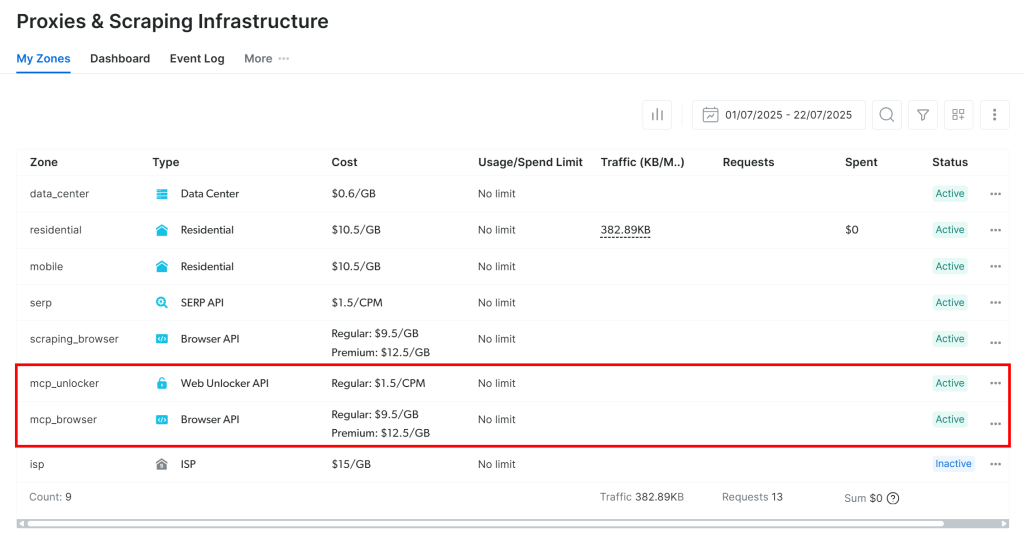
首次启动时,@brightdata/mcp 包会在你的 Bright Data 账户中自动创建两个默认区域(zone):
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
Web MCP 需要这两个区域来暴露全部 60+ 工具。
要确认上述区域已创建,请登录 Bright Data 控制台。导航到“Proxies & Scraping Infrastructure”页面,你应能在表格中看到这两个区域:
如果你的 API token 没有 Admin 权限,将不会自动创建这些区域。在这种情况下,你可以在控制台中手动创建,并通过环境变量指定它们的名称,详见该包的 GitHub 说明。
注意:默认情况下,Web MCP 服务器只暴露 search_engine 与 scrape_as_markdown 两个工具(即使在免费套餐也可使用!)。若要解锁用于浏览器自动化与结构化数据抽取的高级工具,需要启用 Pro 模式。
启用 Pro 模式时,在启动 MCP 服务器前设置 PRO_MODE=true 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp在 PowerShell 中:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp重要:选择 Pro 模式将获得全部 60+ 工具的访问权限,但 Pro 模式不包含在免费套餐中,会产生额外费用。
很好!你已验证本机可以运行 Web MCP 服务器。请结束该服务器进程,接下来将配置由 LangChain 自动启动并连接它。
步骤四:通过 LangChain MCP Adapters 初始化 Web MCP 连接
首先,从 LangChain MCP Adapters 包中导入所需库:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools既然你的机器可以运行本地 Web MCP 服务器,最简单的连接方式就是通过 stdio(标准输入/输出),而不是 SSE 或 Streamable HTTP。简而言之,你将把 MCP 服务器作为子进程启动,并通过标准输入/输出直接通信。
为此,定义 StdioServerParameters 配置对象:
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
)该配置与之前手动测试 Web MCP 时运行的命令一致。你的应用会使用该配置以所需的环境变量运行 npx,并将 Web MCP 作为子进程启动(PRO_MODE 可选)。
接下来,初始化 MCP 会话并加载暴露的工具:
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)load_mcp_tools() 会完成繁重的适配工作:它会自动将 MCP 工具转换为可在 LangChain 与 LangGraph 中使用的工具。
太棒了!你现在已经有了一组工具,可以传入到你的 LangGraph 代理定义中。
步骤五:创建并与 ReAct 代理交互
在内层 with 代码块中,使用 LLM 引擎与 MCP 工具列表,通过 create_react_agent() 创建 LangGraph 代理:
agent = create_react_agent(llm, tools) 注意:在使用工具时,最好依赖遵循 ReAct 架构的 AI 代理。原因在于,这种方法能使它们对流程进行更深入的推理,并选择合适的工具来完成任务。
从 LangGraph 导入 create_react_agent():
from langgraph.prebuilt import create_react_agent接下来与 AI 代理交互。与其等待完整响应再一次性打印,不如将输出直接流式打印到控制台。由于调用工具可能需要时间,流式输出能在代理处理任务时提供有用的反馈:
input_prompt = """
Scrape data from the ZoomInfo company page: 'https://www.zoominfo.com/c/nike-inc/27722128'. Then, using the retrieved data, produce a concise report in Markdown format summarizing the main information about the company.
"""
# Stream the agent’s response
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()在这个示例中,代理被要求:
“从 ZoomInfo 的公司页面 ‘https://www.zoominfo.com/c/nike-inc/27722128‘ 抓取数据。随后基于获取的数据,用 Markdown 生成一份简明的公司信息总结报告。”
注意:该 ZoomInfo 公司页面 URL 对应 Nike,你可以换成任何其他公司,或修改提示以适应不同的数据获取场景。
这与本章开头的说明完全一致。重要的是,此类任务会迫使代理使用 Web MCP 工具来获取并组织真实数据,因此非常适合作为集成的演示!
好!你的 Web MCP + LangChain LangGraph AI 代理已经就绪。接下来看看它的实际效果。
步骤六:整合所有代码
agent.py 的最终代码如下:
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Initialize the LLM engine
llm = ChatOpenAI(
model="gpt-5-mini",
)
# Configuration to connect to a local Bright Data Web MCP server instance
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Replace with your Bright Data API key
"PRO_MODE": "true"
}
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the MCP client session
await session.initialize()
# Get the MCP tools
tools = await load_mcp_tools(session)
# Create the ReAct agent
agent = create_react_agent(llm, tools)
# Agent task description
input_prompt = """
Scrape data from the ZoomInfo company page: 'https://www.zoominfo.com/c/nike-inc/27722128'. Then, using the retrieved data, produce a concise report in Markdown format summarizing the main information about the company.
"""
# Stream the agent’s response
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())哇!仅约 50 行代码,就借助 LangChain MCP Adapters 构建了一个带 MCP 集成的 ReAct 代理。
用以下命令启动你的代理:
python agent.py在终端中,你应能立即看到:

这表明 LangGraph 代理如预期接收到了你的提示。随后,LLM 引擎进行处理并立即判断,为完成任务应调用来自 Web MCP 的 web_data_zoominfo_company_profile 工具。它会用从提示中推断出的正确 ZoomInfo URL 参数(https://www.zoominfo.com/c/nike-inc/27722128)进行调用。
工具调用的输出如下:

web_data_zoominfo_company_profile 工具会以 JSON 格式返回 ZoomInfo 的公司档案数据。请注意,这些并非 gpt-5 mini 模型的臆造内容!
相反,这些数据直接源自 Bright Data 基础设施中的 ZoomInfo Scraper,该工具会在后台由所选的 web_data_zoominfo_company_profile Web MCP 工具调用。
ZoomInfo Scraper 能绕过各种反爬保护,实时从公司公共资料页面收集数据,并以结构化 JSON 格式返回。你可以直接对照实际 ZoomInfo 页面验证,所获取数据准确且直接来自目标页面:
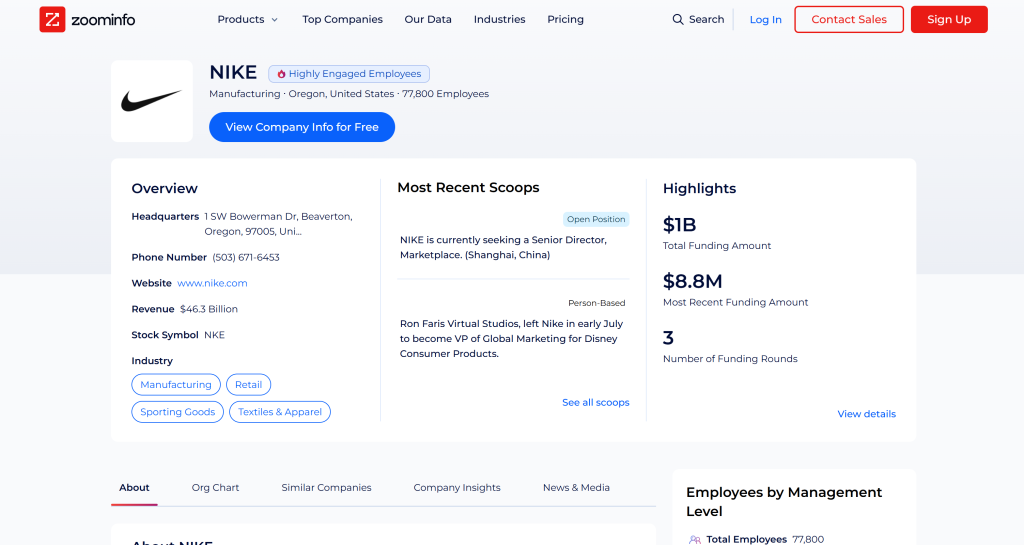
请记住,由于 ZoomInfo 的反爬策略(包括较难的 CAPTCHA),抓取 ZoomInfo 并非易事。这不是任何 LLM 自身就能完成的工作,而是需要能访问专用网络数据获取工具的代理才能做到。
该简单示例展示了 LangChain + Bright Data Web MCP 集成的强大之处!
基于 ZoomInfo 的公司档案数据,代理生成的有根据的 Markdown 报告大致如下:
# NIKE, Inc. — Company Snapshot
## Overview
NIKE, Inc. designs, develops, markets and sells athletic footwear, apparel, equipment and accessories worldwide.
## Quick Facts
- **Name:** NIKE, Inc.
- **Website:** [https://www.nike.com/](https://www.nike.com/)
- **Headquarters:** 1 SW Bowerman Dr, Beaverton, OR 97005, United States
- **Phone:** (503) 671-6453
- **Stock ticker:** NYSE: NKE
- **Revenue:** $46.3 Billion (reported)
- **Employees:** 77,800
- **Industries:** Manufacturing; Retail; Sporting Goods; Textiles & Apparel; Apparel & Accessories Retail
- **ZoomInfo timestamp:** 2026-09-02T08:47:19.789Z
## Financial / Funding
- **Reported revenue:** $46.3B
- **Funding (ZoomInfo):** Total funding $1.0B across 3 rounds *(figures may reflect historical or non-public datapoints; Nike is a public company)*
## Workforce & Culture
- **Total employees:** 77,800
- **Employee breakdown (ZoomInfo):**
- C-level: 23
- VPs: ~529
- Directors: ~6,115
- Managers: ~13,289
- Non-managers: ~29,578
- **eNPS score:** 20 *(Promoters 50% / Passives 20% / Detractors 30%)*
## Leadership (Selected / from org chart)
- Amy Montagne — President, Nike
- Nicole Graham — Executive VP & Chief Marketing Officer
- Cheryan Jacob — Chief Information Officer
- Muge Dogan — Executive VP & Chief Technology Officer
- Chris George — Vice President & Chief Financial Officer (Geo...)
- Sarah Mensah — President, Jordan Brand
> *Note: ZoomInfo profile did not list a single CEO entry in the captured data.*
## Technology & Tools (Examples)
- SolidWorks (Dassault Systèmes)
- EventPro (Profit Systems)
- Microsoft IIS (Microsoft)
- SAP Sybase RAP (SAP)
## Recent Scoops / Media Highlights (Summarized)
- **Hiring:** Senior Director, Marketplace (Shanghai).
- **Personnel move:** Ron Faris Virtual Studios left Nike to join Disney Consumer Products (VP, Global Marketing).
- **Business notes:** Tariff/geopolitical headwinds impacted near-term results; company implementing mitigation actions and “win now” measures.
- **Layoffs:** Reports of a small corporate layoff (~1% of corporate employees).
## Comparable Companies (Examples)
- ANTA Sports Products
- adidas AG
- Foot Locker
- Guess
- Timberland
- Genesco
## Contacts & Outreach
- **Corporate website:** [https://www.nike.com/](https://www.nike.com/)
- **Typical email formats (observed):** `[email protected]` (also `@converse.com` for related brands)
## Data Source
- ZoomInfo company profile for NIKE, Inc.
[https://www.zoominfo.com/c/nike-inc/27722128](https://www.zoominfo.com/c/nike-inc/27722128)
**Snapshot timestamp:** 2026-09-02T08:47:19.789Z在 Markdown 查看器中可视化后你会看到:
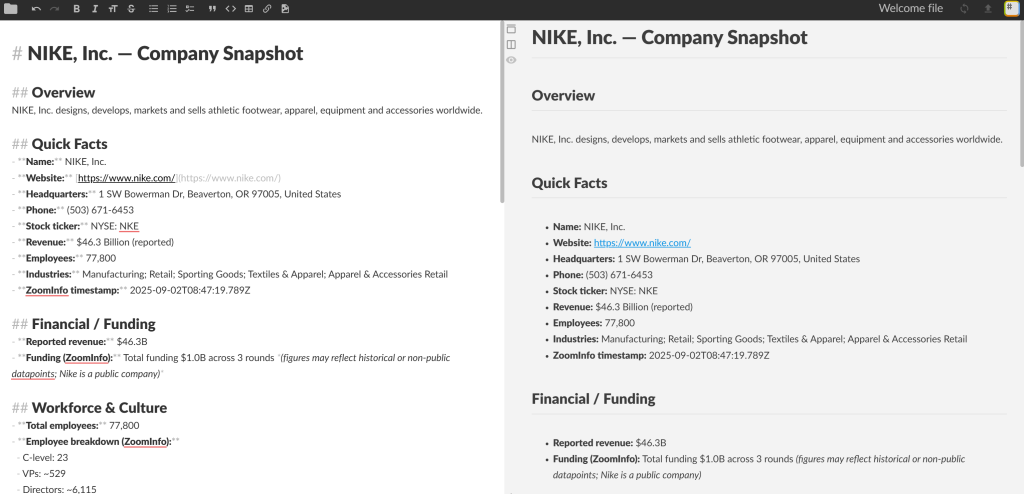
大功告成!你的 ReAct 代理为任务选择了正确的工具,并据此生成了包含真实公司数据的信息丰富的 Markdown 报告。
这一切离不开 Web MCP 集成,而现在借助 MCP Adapters 库,LangChain 也已支持该能力。
下一步
本教程中的 LangChain MCP 驱动代理只是一个简单但可用的示例。若要达到生产级准备,可考虑:
- 实现 REPL:添加一个 REPL(Read-Eval-Print Loop),以便实时与代理交互。为维持上下文与历史对话,引入记忆层——理想情况下存储于临时数据库或持久化存储中。
- 将输出导出到文件:修改输出逻辑,支持将生成的结果(如报告)保存到本地文件,方便与团队成员共享。
- 部署你的代理:将 AI 代理部署到云端、混合云或自托管环境,参考 LangChain 文档中的部署选项。
尝试用不同的提示测试你的 LangChain + Web MCP 代理,并探索其他更高级的代理式工作流!
结论
本文演示了如何利用 Bright Data 的 Web MCP(现已提供免费层!)在 LangGraph 中构建一个 AI 代理。这要得益于 LangChain MCP Adapters 库,它为 LangChain 与 LangGraph 生态增加了 MCP 支持。
文中的任务仅是一个示例,但你可以用相同的集成来设计更复杂的工作流,包括多代理方案。借助 Web MCP 提供的 60+ 个工具以及 Bright Data 的 AI 基础设施的全面解决方案,你可以让 AI 代理高效地获取、验证并转换实时网页数据。
立即免费创建 Bright Data 账号,开始体验我们面向 AI 的网页数据解决方案吧



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




