

在本指南中,你将学习:
- 为什么网页抓取是用真实世界数据丰富 LLM 的绝佳方式
- 在 LangChain 工作流中使用抓取数据的优势与挑战
- 一个能简化抓取集成的库
- 如何通过逐步教程创建完整的 LangChain 网页抓取集成
让我们开始吧!
使用网页抓取为你的 LLM 应用提供动力
网页抓取 涉及从网页检索数据。然后可以将这些数据与 LLM(大型语言模型)结合,为 RAG(检索增强生成)应用提供支持。
RAG 系统需要获取丰富、新鲜、实时、领域特定或大规模的数据,而这些数据在静态的 可购买或在线下载的数据集中并不易获取。网页抓取通过从新闻文章、产品列表、社交媒体等多种来源提取结构化信息来弥补这一空白。
在我们的文章中了解有关收集 LLM 训练数据 的更多内容。
在 LangChain 中使用抓取数据的优势与挑战
LangChain 是一个强大的 AI 工作流构建框架,能够简化 LLM 与多样数据源的集成。它通过将 LLM 与实时、领域特定知识结合,擅长数据分析、摘要和问答。然而,高质量数据的获取始终是一个难题。
网页抓取可以解决这一问题,但同时也带来多项挑战,包括反爬措施、CAPTCHA 以及动态网站。维护合规且高效的爬虫既耗时又技术复杂。详情请查看我们的 反爬措施指南。
这些障碍会减缓依赖实时数据的 AI 应用开发。解决方案是什么?Bright Data Web Scraper API —— 一个现成可用的工具,为数百个网站提供抓取端点。
Bright Data 拥有 IP 轮换、CAPTCHA 解决、JavaScript 渲染等高级功能,为你自动化数据提取,确保可靠、高效且无忧的数据收集,全都通过简单的 API 调用即可访问。
LangChain Bright Data 工具
虽然你 可以 在 LangChain 工作流中直接集成 Bright Data Web Scraper API 或其他抓取工具,但那需要自定义逻辑和样板代码。为了节省时间和精力,建议使用官方 LangChain Bright Data 集成包 langchain-brightdata。
该包允许你在 LangChain 工作流中连接 Bright Data 服务。具体来说,它暴露以下类:
BrightDataSERP:集成 Bright Data 的 SERP API,执行具有地理定位的搜索引擎查询。BrightDataUnblocker:与 Bright Data 的 Web Unlocker 协同工作,访问可能受地域限制或防爬系统保护的网站。BrightDataWebScraperAPI:与 Bright Data 的 Web Scraper API 对接,从各种域名提取结构化数据。
在本教程中,我们将专注于 BrightDataWebScraperAPI 类。现在开始吧!
由 Bright Data 驱动的 LangChain 网页抓取:逐步指南
在本节中,你将学习如何构建 LangChain 网页抓取工作流。目标是利用 LangChain 调用 Bright Data Web Scraper API 获取 LinkedIn 简历内容,并使用 OpenAI 评估候选人是否适合某个岗位。
我们将使用 我的公共 LinkedIn 主页 作为示例,任何其他 LinkedIn 主页也可:
注意:此处构建的仅为示例。你即将编写的代码易于适配不同场景,也可扩展更多 LangChain 功能。例如,你甚至可以创建一个 基于 SERP 数据的 RAG 聊天机器人。
按下列步骤开始!
前置条件
完成本教程,你需要:
- 已在本机安装 Python 3+
- 一个 OpenAI API 密钥
- 一个 Bright Data 账号
如果缺少任何一项,别担心。我们将从安装 Python 到获取 OpenAI 与 Bright Data 凭据的全流程引导。
步骤 #1:项目搭建
首先检查你的机器是否已安装 Python 3,若无,下载并安装。
在终端运行以下命令,为项目创建文件夹:
mkdir langchain-scrapinglangchain-scraping 将存放你的 Python LangChain 抓取项目。
然后进入项目文件夹并在其中初始化 Python 虚拟环境:
cd langchain-scraping
python3 -m venv venv注意:Windows 上使用 python 替代 python3。
现在,在你喜欢的 Python IDE 中打开该目录。PyCharm Community 或 VS Code(Python 扩展)皆可。
在 langchain-scraping 内添加 script.py 文件。它是空脚本,稍后将写入抓取逻辑。
在 IDE 终端中,Linux/macOS 激活虚拟环境:
source venv/bin/activate或在 Windows:
venv/Scripts/activate很好!环境已搭建完成。
步骤 #2:安装所需库
本 Python 抓取项目依赖以下库:
python-dotenv:从.env文件加载环境变量,用于管理 Bright Data 和 OpenAI API 密钥。langchain-openai:通过openaiSDK 集成 OpenAI。langchain-brightdata:集成 Bright Data 抓取服务。
在激活的虚拟环境中,运行:
pip install python-dotenv langchain-openai langchain-brightdata太棒了!准备编写抓取逻辑。
步骤 #3:准备项目
在 script.py 中添加:
from dotenv import load_dotenv然后在项目根目录创建 .env 文件存储凭据。当前项目结构应如下:

在 script.py 中通过以下代码加载环境变量:
load_dotenv()酷!接下来配置 Bright Data Web Scraper API。
步骤 #4:配置 Web Scraper API
如前文所述,网页抓取挑战多。但 Bright Data 的一站式 Web Scraper API 让一切轻松。它能从 120 多个网站检索解析内容。
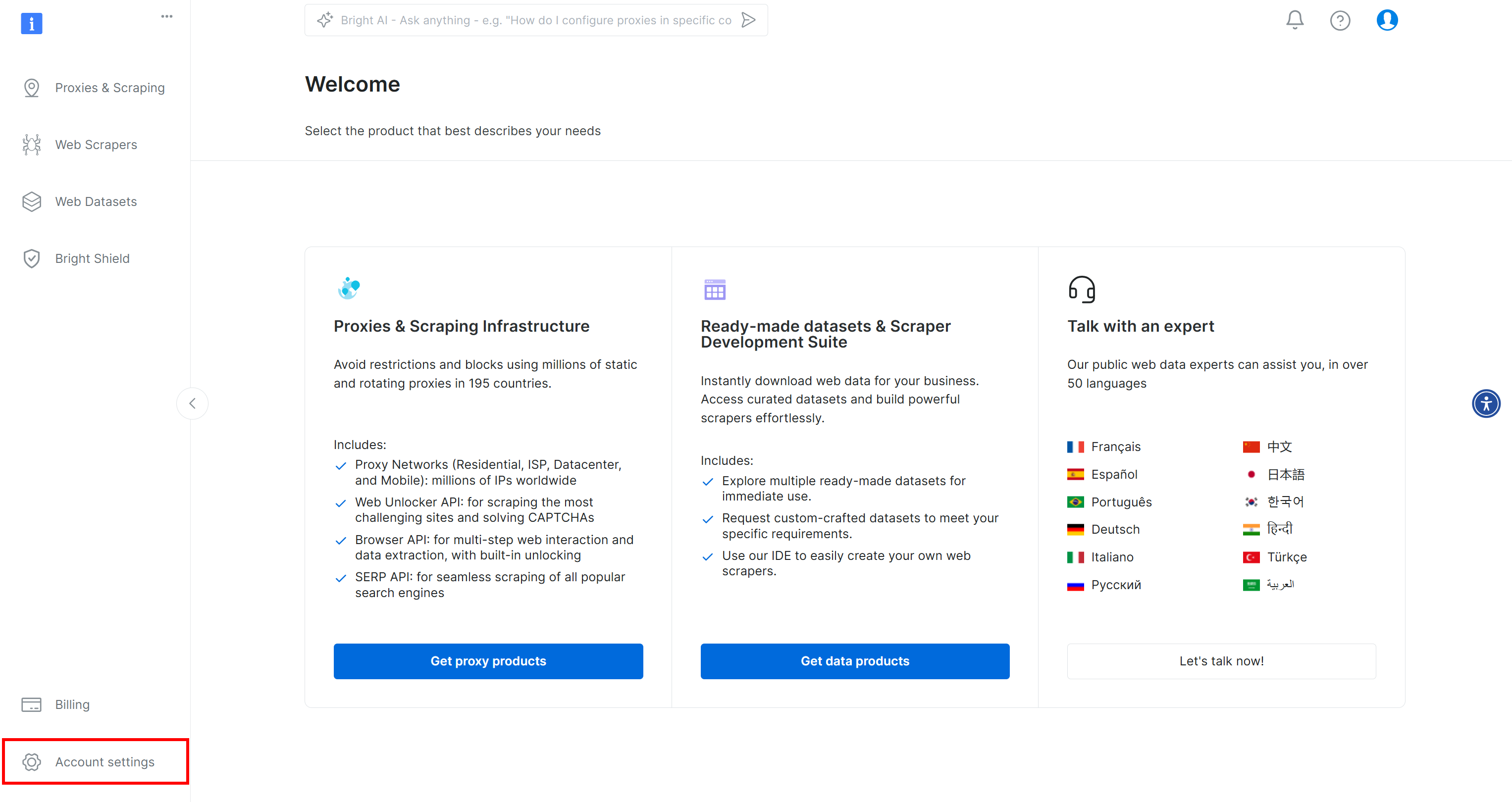
若尚未操作,创建 Bright Data 账号。登录后进入仪表板,点击左下角 “Account settings”:
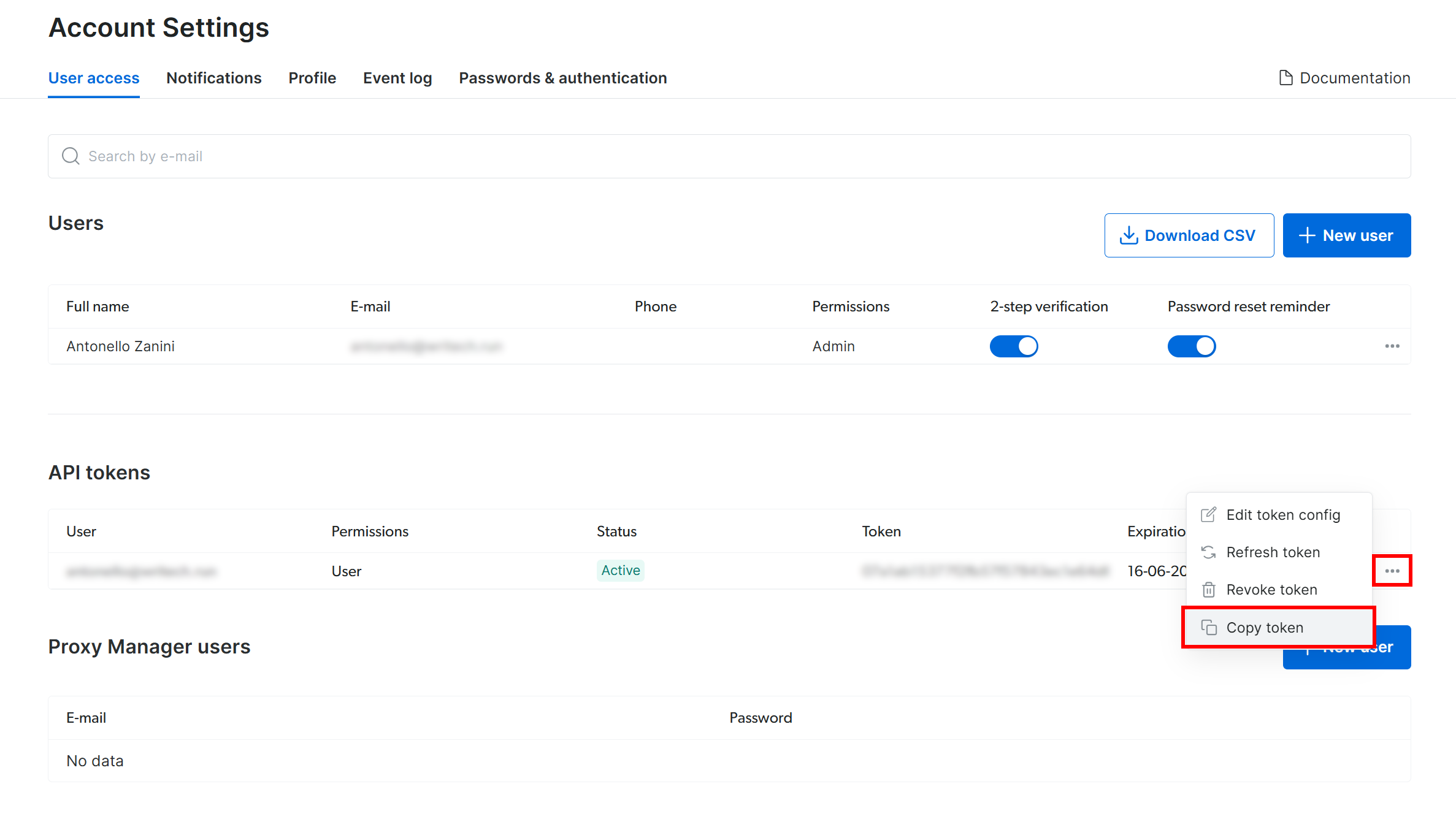
在 “Account Settings” 页面,若已有 API token,点击 “…” 然后选择 “Copy token”:
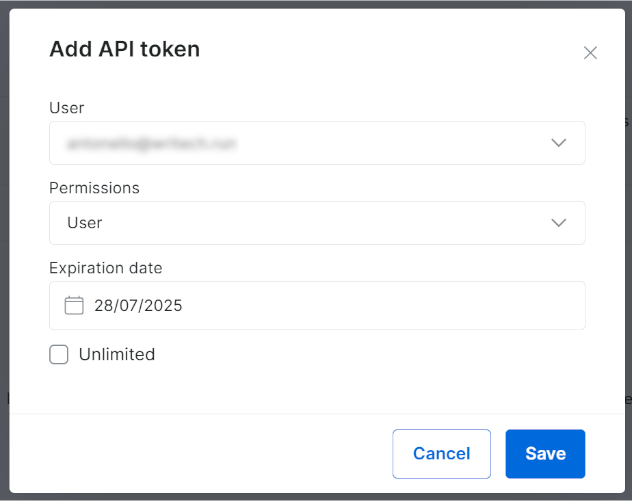
否则点击 “Add token”:
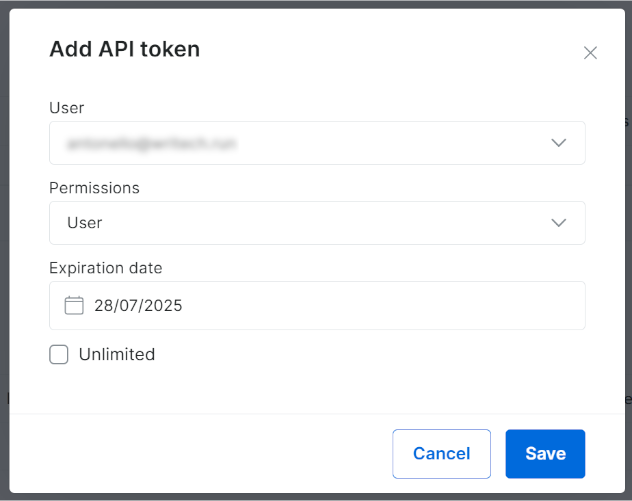
在弹窗中配置并点击 “Save”:
你将获得新的 API token:
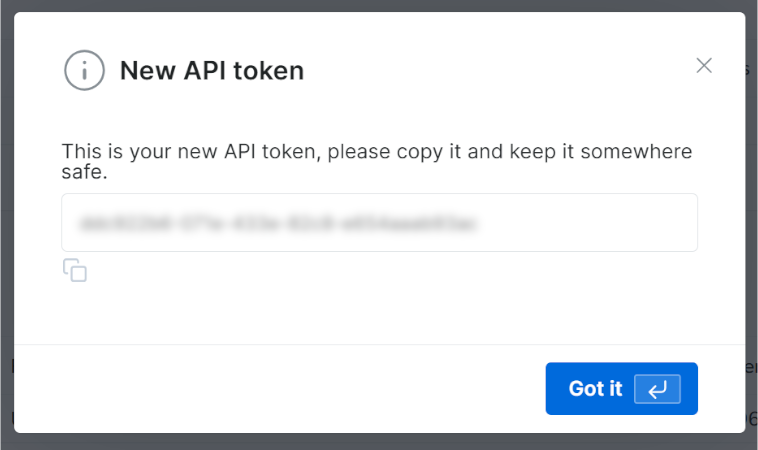
复制该值。
在 .env 中添加:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你复制的值。
接着在 script.py 中导入:
from langchain_brightdata import BrightDataWebScraperAPI无需进一步操作,因为 langchain_brightdata 会自动尝试从 BRIGHT_DATA_API_KEY 环境变量中读取 Bright Data API 密钥。
好了!你现在可以在 LangChain 中使用 Web Scraper API 了。
步骤 #5:使用 Bright Data 进行网页抓取
langchain_brightdata 通过 BrightDataWebScraperAPI 类集成 Web Scraper API。
其工作流程概述如下:
- 向配置的 Web Scraper API 同步请求,并传入需抓取页面的 URL。
- 云端启动抓取任务,检索并解析指定 URL 的数据。
- 库等待任务结束,随后以 JSON 返回抓取数据。
在 LangChain 工作流中,定义可复用函数:
def get_scraped_data(url, dataset_type):
# Initialize the LangChain Bright Data Scraper API integration class
web_scraper_api = BrightDataWebScraperAPI()
# Retrieve the data of interest by connecting to Web Scraper API
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results函数参数:
url:待抓取页面的 URL。dataset_type:指定使用哪种 Web Scraper API 解析页面。例如"linkedin_person_profile"表示抓取公开的 LinkedIn 个人页。
示例调用:
url = "https://linkedin.com/in/antonello-zanini"
scraped_data = get_scraped_data(url, "linkedin_person_profile")scraped_data 将包含如下数据:
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# Omitted for brevity...
"about": "I'm a freelance software engineer, technical editor, and technical writer with hundreds...",
"current_company": {
"name": "Freelance"
},
"current_company_name": "Freelance",
# Omitted for brevity...
"languages": [
{
"title": "Italian",
"subtitle": "Native or bilingual proficiency"
},
{
"title": "English",
"subtitle": "Full professional proficiency"
},
{
"title": "Spanish",
"subtitle": "Full professional proficiency"
}
],
"recommendations_count": 32,
"recommendations": [
# Omitted for brevity...
],
"posts": [
# Omitted for brevity...
],
"activity": [
# Omitted for brevity...
],
# Omitted for brevity...
}该 JSON 包含目标 LinkedIn 公开页面上的所有信息。Web Scraper API 已为你绕过反爬机制。
太棒了!你已学会在 LangChain 中使用 Bright Data Web Scraper API 进行抓取。
步骤 #6:准备使用 OpenAI 模型
此示例依赖 OpenAI 模型在 LangChain 中进行 LLM 集成。要使用这些模型,你必须在环境变量中配置 OpenAI API 密钥。
因此,请在你的 .env 文件中添加以下行:
OPENAI_API_KEY="<YOUR_OPEN_API_KEY>"将 <YOUR_OPENAI_API_KEY> 替换为你的 OpenAI API key。如需指南,请查看 官方教程。
然后在 script.py 中导入:
from langchain_openai import ChatOpenAI你无需再做任何操作。langchain_openai 会自动在 OPENAI_API_KEY 环境变量中查找你的 OpenAI API 密钥。
太棒了!现在可以在你的 LangChain 抓取脚本中使用 OpenAI 模型了。
步骤 #7:生成 LLM 提示词
定义一个 f-string 变量,它接收抓取的数据并为 LLM 生成提示。在本例中,提示词包含你的 HR 请求,并嵌入抓取到的候选人数据:
prompt = f"""
"Do you think this candidate is a good fit for a remote Software Engineer position? Why?
Answer in no more than 150 words.
CANDIDATE:
'{scraped_data}'
"""此示例构建了一个 HR 顾问 AI 工作流。凭借 Web Scraper API(支持 120+ 域)与 LLM 的灵活性,你可轻松拓展到更多 LangChain 工作流。
💡 提示:为更大灵活性,可从 .env 读取 prompt。
完整 prompt 如下:
Do you think this candidate is a good fit for a remote Software Engineer position? Why?
Answer in no more than 150 words.
CANDIDATE:
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// omitted for brevity...
"about": "I'm a freelance software engineer, technical editor, and technical writer with hundreds...",
},
[ommitted for brevity...]'若将其传入 ChatGPT,你将得到预期结果:
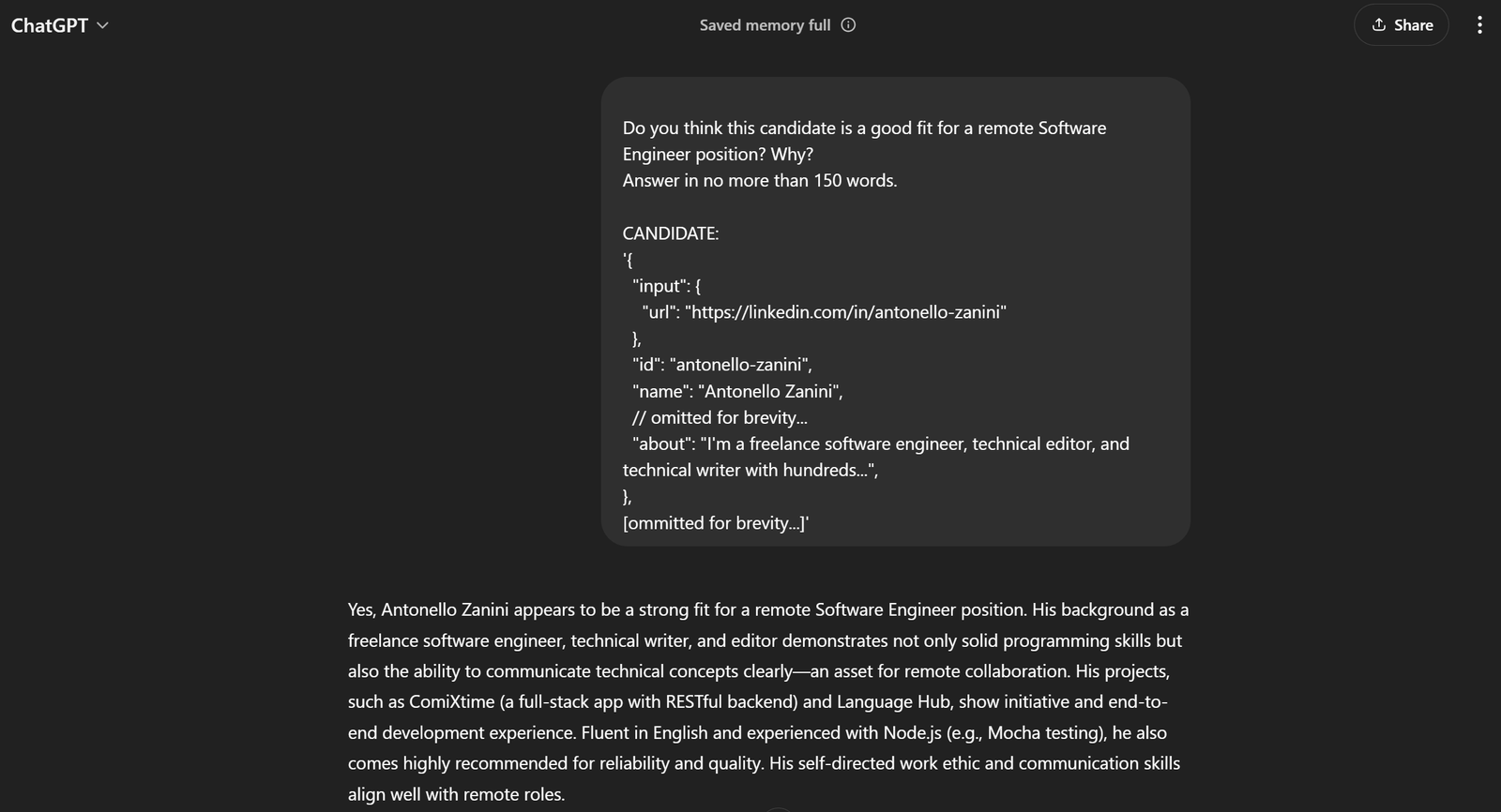
这足以证明 prompt 效果良好!
步骤 #8:集成 OpenAI
将 prompt 传入配置为 GPT-4o mini 模型的 ChatOpenAI 对象:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)处理结束后,response.content 将包含类似 ChatGPT 生成的评估。获取文本:
evaluation = response.content精彩!LangChain 抓取逻辑已完成。
步骤 #9:导出 AI 处理结果
现在需要将 AI 生成的数据导出为易读格式,例如 JSON。
首先初始化一个字典,然后写入 JSON 文件:
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)从标准库导入 json:
import json恭喜!脚本已就绪。
步骤 #10:添加日志
使用 Web Scraper API 的抓取和 ChatGPT 的分析可能需要一些时间。这是由于调用第三方服务进行抓取和数据处理所带来的额外开销。因此最好添加日志以跟踪脚本进度。
在脚本的关键步骤添加 print 语句,如下:
url = "https://linkedin.com/in/antonello-zanini"
print(f"Scraping data with Web Scraper API from {url}...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Data successfully scrapedn")
print("Creating the AI prompt...")
prompt = f"""
"Do you think this candidate is a good fit for a remote Software Engineer position? Why?
Answer in no more than 150 words.
CANDIDATE:
'{scraped_data}'
"""
print("Prompt createdn")
print("Sending prompt to ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("Received response from ChatGPTn")
print("Exporting data to JSON"...)
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Data exported to '{file_name}'")注意,LangChain 网页抓取工作流的每一步都已清晰记录。终端输出将更易于跟踪。
步骤 #11:整合全部代码
你的最终 script.py 文件应包含:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# Load the environment variables from the .env file
load_dotenv()
def get_scraped_data(url, dataset_type):
# Initialize the LangChain Bright Data Scraper API integration class
web_scraper_api = BrightDataWebScraperAPI()
# Retrieve the data of interest by connecting to Web Scraper API
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# Retrieve the content from the given web page
url = "https://linkedin.com/in/antonello-zanini"
print(f"Scraping data with Web Scraper API from {url}...")
# Use Web Scraper API to get the scraped data
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Data successfully scrapedn")
print("Creating the AI prompt...")
# Define the prompt using the scraped data as context
prompt = f"""
"Do you think this candidate is a good fit for a remote Software Engineer position? Why?
Answer in no more than 150 words.
CANDIDATE:
'{scraped_data}'
"""
print("Prompt createdn")
# Ask ChatGPT to perform the task specified in the prompt
print("Sending prompt to ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# Get the AI result
evaluation = response.content
print("Received response from ChatGPTn")
print("Exporting data to JSON...")
# Export the produced data to JSON
export_data = {
"url": url,
"evaluation": evaluation
}
# Write the output dictionary to JSON file
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Data exported to '{file_name}'")难以置信!仅用约 50 行代码,你就构建了一个基于 AI 的 LangChain 网页抓取脚本。
使用以下命令验证脚本:
python3 script.pyWindows 环境:
python script.py终端输出应类似:
Scraping data with Web Scraper API from https://linkedin.com/in/antonello-zanini...
Data successfully scraped
Creating the AI prompt...
Prompt created
Sending prompt to ChatGPT...
Received response from ChatGPT
Exporting data to JSON...
Data exported to 'analysis.json'打开项目目录中出现的 analysis.json 文件,你应看到类似以下内容:
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zanini appears to be a strong candidate for a remote Software Engineer position. His experience as a freelance software engineer indicates adaptability and self-motivation, crucial for remote work. His technical writing and editorial background suggest strong communication skills, essential for collaborating with remote teams. Additionally, his diverse programming knowledge, evidenced by posts on unit testing and JavaScript bundlers, reinforces his technical expertise.nnHe has garnered significant positive feedback from clients, emphasizing his reliability and clarity in deliverables, which are critical traits for effective remote collaboration. Moreover, his multilingual abilities in Italian, English, and Spanish can enhance communication in diverse international teams. Overall, Antonello's combination of technical proficiency, communication skills, and positive recommendations makes him an excellent fit for a remote position."
}大功告成!这个通过实时数据丰富的 HR LangChain 工作流现已完成。
结论
在本教程中,你了解了为何网页抓取是为 AI 工作流收集数据的有效方法,以及如何使用 LangChain 分析这些数据。
具体而言,你创建了一个基于 Python 的 LangChain 网页抓取脚本,从 LinkedIn 个人页提取数据,并通过 OpenAI API 进行处理。虽然该工作流适用于 HR 任务,但所示代码可轻松扩展至其他工作流和场景。
在 LangChain 中进行网页抓取面临的主要挑战:
- 网站经常更改页面结构。
- 许多网站实施先进的反爬措施。
- 同时检索大量数据可能既复杂又昂贵。
Bright Data 的 Web Scraper API 是从主要网站提取数据的有效解决方案,能够轻松克服这些挑战。凭借与 LangChain 的顺畅集成,它是支持 RAG 应用和其他 LangChain 方案的宝贵工具。
别忘了探索我们的其他AI 与 LLM 解决方案。
立即注册,发现 Bright Data 的代理服务或抓取产品中最适合你的方案。开始免费试用吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




