
在本指南中,你将学习:
- 什么是 Agentic 检索增强生成(RAG),以及为何引入 Agentic 能力至关重要
- Bright Data 如何为 RAG 系统提供自治且实时的网页数据检索
- 如何处理与清洗网页抓取数据以生成嵌入
- 如何实现代理控制器,在向量检索与大模型文本生成之间进行编排
- 如何设计反馈回路,收集用户输入并动态优化检索与生成
让我们开始吧!
人工智能(AI)的兴起带来了新的概念,其中包括 Agentic RAG。简单来说,Agentic RAG 是集成了AI 代理的检索增强生成(RAG)。顾名思义,RAG 是一种信息检索系统,遵循线性流程:接收查询、检索相关信息并生成响应。
为什么将 AI 代理与 RAG 结合?
最新调查显示,近三分之二使用 AI 代理的工作流报告了生产力提升,且接近 60% 报告了成本节省。这使得将 AI 代理与 RAG 结合,成为现代检索工作流的潜在变革者。
Agentic RAG 具备更高级的能力。与传统 RAG 系统不同,它不仅能检索数据,还能自主决定从外部来源获取信息,例如将实时网页数据嵌入到数据库中。
本文将演示如何构建一个Agentic RAG 系统:使用 Bright Data 进行网页数据采集,Pinecone 作为向量数据库,OpenAI 进行文本生成,并以 Agno 作为代理控制器。
Bright Data 概览
无论你是从实时数据流获取数据,还是使用数据库中的预备数据,Agentic RAG 系统的输出质量都取决于输入数据的质量。这正是 Bright Data 发挥作用的地方。
Bright Data 为各类用例提供可靠、结构化且最新的网页数据。凭借 Bright Data 的Web Scraper API(覆盖 120 多个域名),网页抓取比以往更高效。它能够处理常见抓取挑战,如 IP 封禁、验证码(CAPTCHA)、Cookie 以及其他各类反爬机制。
开始之前,请注册免费试用,然后获取你的 API key 和目标域名的 dataset_id。准备就绪后即可开始。
以下是在热门域名(如 BBC News)获取最新数据的步骤:
- 如果尚未创建 Bright Data 账户,请先创建(提供免费试用)。
- 前往 Web Scrapers 页面。在 Web Scrapers Library 下浏览可用的爬虫模板。
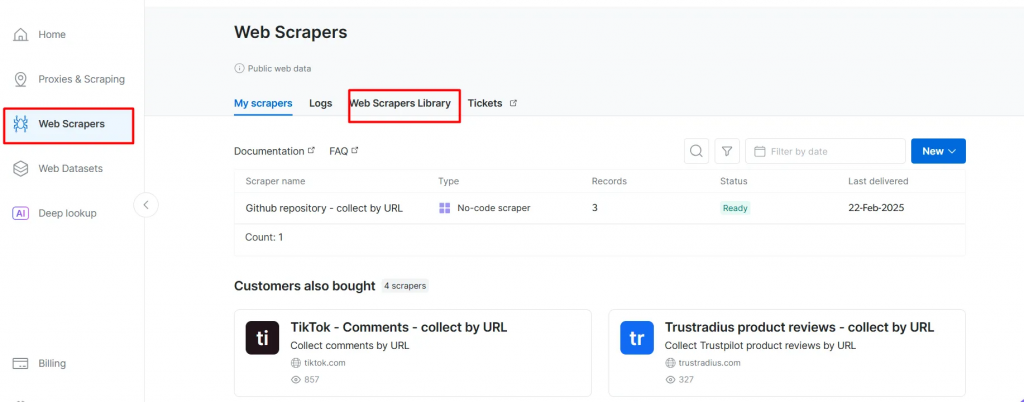
- 搜索你的目标域名,如 BBC News,并选择它。
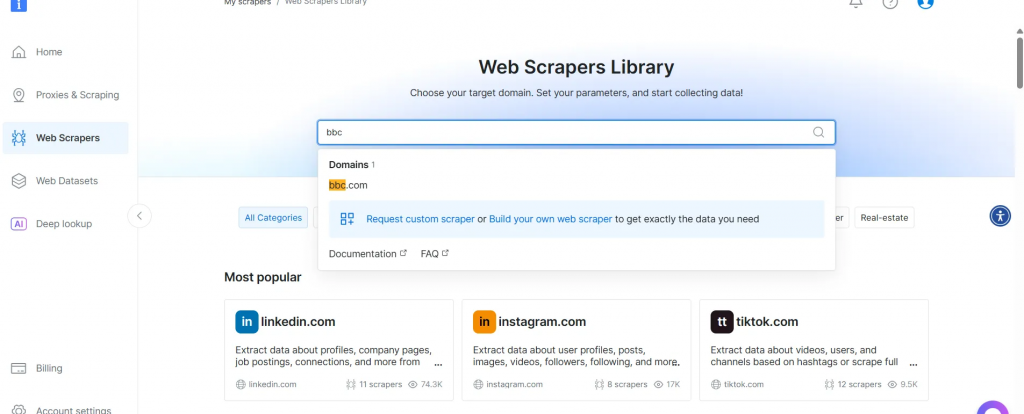
- 在 BBC News 爬虫列表中,选择 BBC News — collect by URL。该爬虫允许你在无需登录的情况下获取数据。
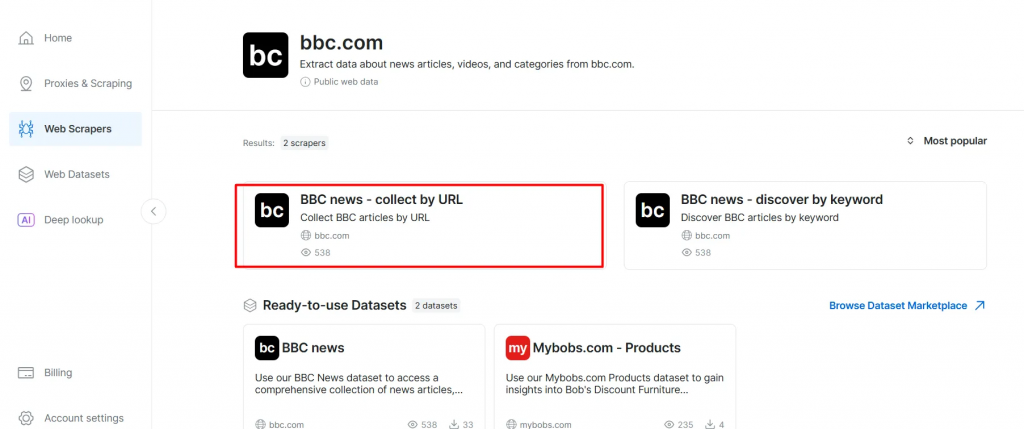
- 选择 Scraper API 选项。No-Code Scraper 则可用于无代码获取数据集。
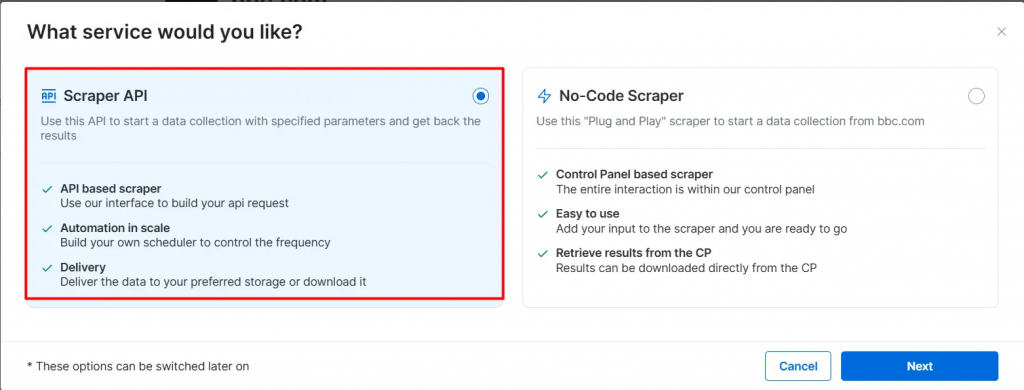
- 点击 API Request Builder,然后复制你的
API-key、BBC Dataset URL和dataset_id。在下一节构建 Agentic RAG 工作流时会用到它们。
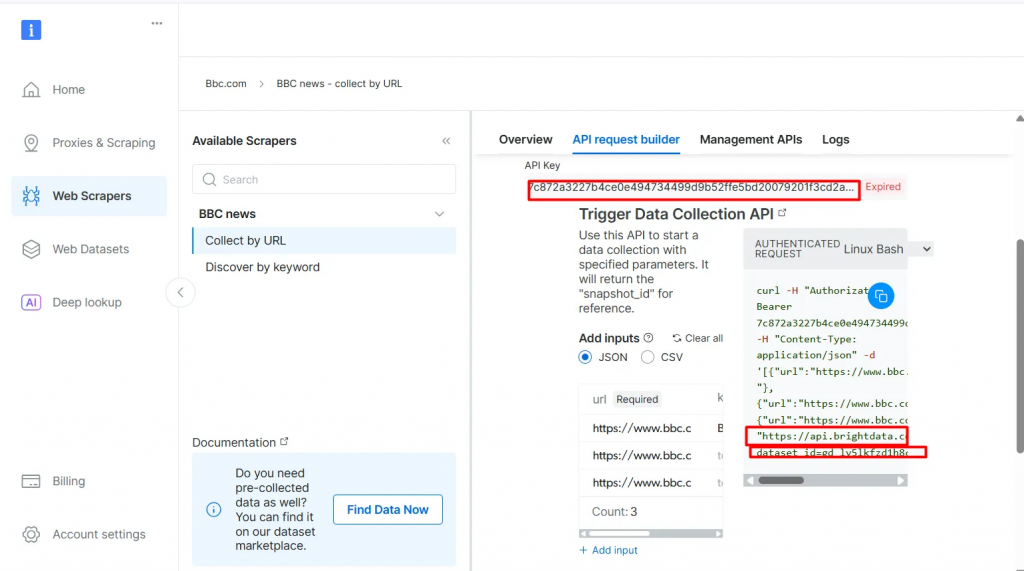
API-key 与 dataset_id 是在工作流中启用 Agentic 能力的必要条件。它们允许你将实时数据嵌入向量数据库,并支持实时查询,即使查询与预先索引的内容不直接匹配。
先决条件
在开始之前,请确保你具备以下条件:
- 一个 Bright Data 账户
- 一个 OpenAI API key。请在 OpenAI 注册并获取 API key
- 一个 Pinecone API key。请参考 Pinecone 文档,按照 Get an API key 部分的步骤操作
- 具备 Python 基础。可从官方网站下载并安装 Python
- 对 RAG 与代理(Agent)概念有基本了解
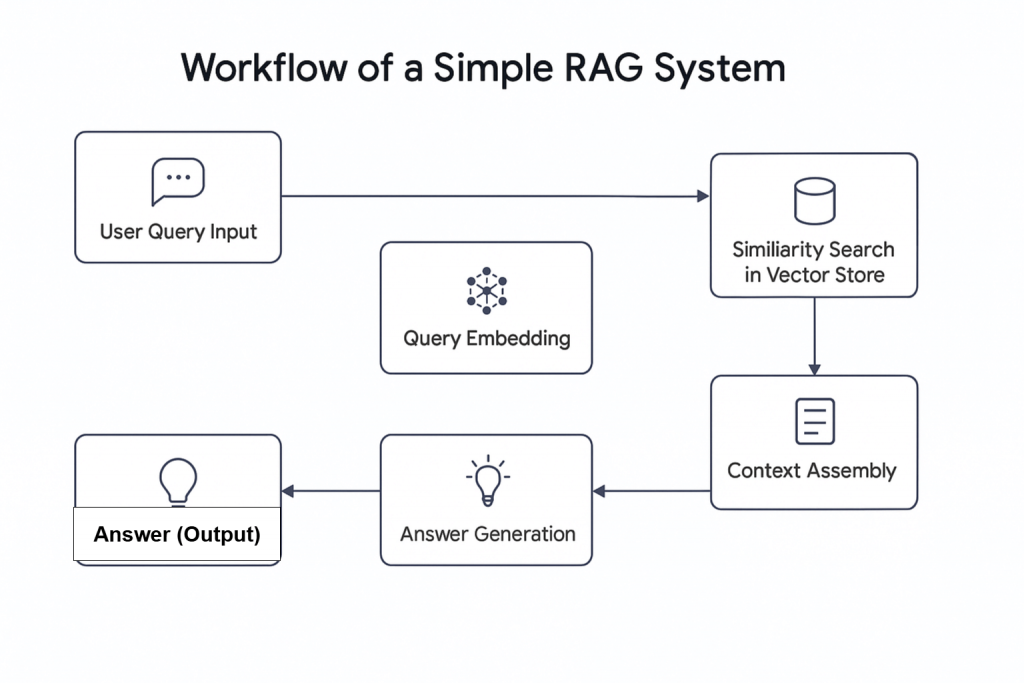
Agentic RAG 的结构
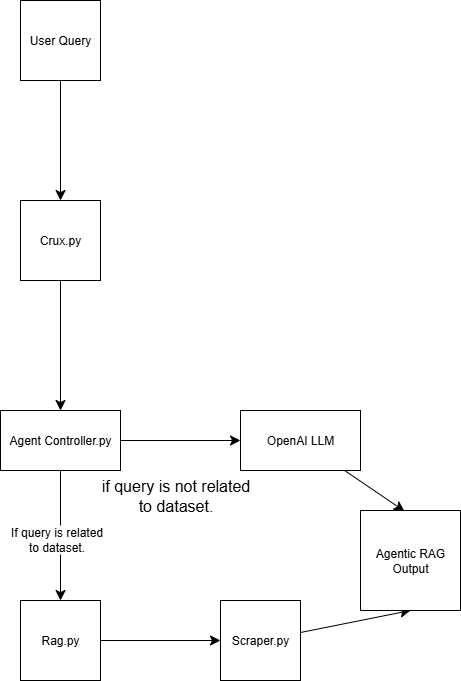
该 Agentic RAG 系统由四个脚本构建:
scraper.py 通过 Bright Data 获取网页数据
rag.py 将数据嵌入到向量数据库(Pinecone)中。说明:向量(数值嵌入)数据库用于存储通常由机器学习模型生成的非结构化数据,这种格式非常适合在检索任务中进行相似度搜索。
agent_controller.py 包含控制逻辑。它会根据查询的性质决定使用来自向量数据库的预处理数据,还是依赖 GPT 的通用知识
crux.py 是 Agentic RAG 系统的核心。它存储 API keys 并初始化工作流。
完成演示后,你的 Agentic RAG 目录结构将如下所示:
使用 Bright Data 构建 Agentic RAG
步骤 1:设置项目
1.1 创建新的项目目录
为你的项目创建一个文件夹并进入该目录:
mkdir agentic-rag
cd agentic-rag1.2 在 Visual Studio Code 中打开项目
启动 Visual Studio Code,并打开新创建的目录:
.../Desktop/agentic-rag> code .1.3 设置并激活虚拟环境
设置虚拟环境,运行:
python -m venv venv或者在 Visual Studio Code 中,按照Python 环境指南中的提示创建虚拟环境。
激活环境:
- Windows:
.venv\Scripts\activate - macOS 或 Linux:
source venv/bin/activate
步骤 2:实现 Bright Data 检索器
2.1 在 scraper.py 中安装 requests 库
pip install requests2.2 导入以下模块
import requests
import json
import time2.3 配置凭证
使用前面复制的 Bright Data API key、dataset URL 和 dataset_id。
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}2.4 设置响应逻辑
将你要抓取的页面 URL 填入请求中。本例聚焦于体育相关的文章。
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")2.5 运行代码
运行脚本后,项目文件夹中会出现名为 news-data.json 的文件。它以结构化 JSON 格式包含已抓取的文章数据。
以下为该 JSON 文件内容的示例:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \"great concern\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\"We have to create a basis with a car so that he can fight for the world championship.\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\"Verstappen has said this year that he is \"relaxed\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},现在你已经拿到数据,下一步是进行嵌入。
步骤 3:设置嵌入与向量存储
3.1 在 rag.py 中安装所需库
pip install openai pinecone pandas3.2 导入所需库
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec3.3 配置 OpenAI key
使用 OpenAI 从 text_for_embedding 字段生成嵌入。
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key3.4 配置 Pinecone API key 与索引设置
设置 Pinecone 环境并定义索引配置。
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"3.5 初始化 Pinecone 客户端与索引
确保客户端与索引已正确初始化,用于数据存储与检索。
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)3.6 清洗、加载与预处理数据
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df注意:你可以重新运行
scraper.py以确保数据是最新的。
3.7 使用 OpenAI 生成嵌入
使用 OpenAI 的嵌入模型从预处理文本创建嵌入。
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings3.8 将嵌入写入 Pinecone
将生成的嵌入推送至 Pinecone,以保持向量数据库的最新状态。
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")注意:你只需运行此步骤一次来填充数据库。之后可以将这部分代码注释掉。
3.9 初始化 Pinecone 检索函数
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered说明:
分数阈值(score_threshold)定义了结果被视为相关的最低相似度分数。你可以根据需求调整该值。分数越高,结果越准确。
3.10 使用 OpenAI 生成答案
使用 OpenAI 从 Pinecone 检索到的上下文生成答案。
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\n\nContext:\n" + "\n\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer3.11(可选)运行简单测试以查询并打印结果
包含便于 CLI 使用的代码,以便你运行基础测试。该测试可帮助验证实现是否正常,并预览数据库中存储的数据。
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\nGenerated answer:\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)提示:你可以通过切片控制显示文本的长度,例如:
[:250]。
现在数据已经存储在向量数据库中。这意味着你有两种查询选项:
- 从数据库检索
- 使用 OpenAI 生成通用回答
步骤 4:构建代理控制器
4.1 在 agent_controller.py 中
从 rag.py 导入所需功能。
from rag import openai_generate_answer, pinecone_search4.2 实现 Pinecone 检索
添加逻辑,从 Pinecone 向量存储中检索相关数据。
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")4.3 实现 OpenAI 回退生成
当未检索到相关上下文时,创建逻辑使用 OpenAI 生成答案。
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."步骤 5:将所有部分串联
5.1 在 crux.py 中
从 agent_controller.py 导入所有必要函数。
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function5.2 提供你的 API keys
确保正确设置 OpenAI 与 Pinecone 的 API keys。
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"5.3 在 main() 函数中输入你的提示
在 main() 函数中定义输入提示。
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\nAgent's answer:\n", answer)
if __name__ == "__main__":
main()5.4 调用 Agentic RAG
运行 Agentic RAG 的逻辑。你将看到它如何先检查查询的相关性,然后再查询向量数据库。

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.尝试使用与数据库不匹配的查询,例如:
def main():
query = "Why Sleep?"代理会判断在 Pinecone 中没有找到合适的匹配,并回退为使用 OpenAI 生成通用回答。

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.提示:你可以打印每次提示的相关性分数(score_threshold),以了解代理的信心程度。
就是这样!你已经成功构建了一个 Agentic RAG。
步骤 6(可选):反馈回路与优化
你可以通过实现反馈回路来增强系统,以便随着时间的推移改进训练与索引。
6.1 添加反馈函数
在 agent_controller.py 中创建一个函数,在展示回答后询问用户反馈。你可以在 crux.py 的主运行器末尾调用该函数。
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments6.2 实现反馈处理逻辑
在 agent_controller.py 中创建一个新函数,当反馈为负时,重新调用检索流程。然后在 crux.py 中调用它:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\nNew answer based on feedback:\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\nAnswer generated without retrieval:\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None总结与后续步骤
在本文中,你构建了一个自治的 Agentic RAG 系统:使用 Bright Data 进行网页抓取、Pinecone 作为向量数据库、OpenAI 进行文本生成。该系统为扩展更多功能提供了基础,例如:
- 将向量数据库与关系型或非关系型数据库集成
- 使用 Streamlit 创建用户界面
- 自动化网页数据检索,以保持训练数据的时效性
- 增强检索逻辑与代理推理能力
如文中所示,Agentic RAG 系统输出的质量高度依赖于输入数据的质量。Bright Data 在其中发挥了关键作用,提供了可靠且新鲜的网页数据,这是高效检索与生成的基础。
建议进一步探索该工作流的增强方案,并在未来项目中使用 Bright Data,以维持一致且高质量的输入数据。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。



