

在本文中,您将了解到:
- 什么是 Agno 以及它作为 AI 代理框架的独特之处。
- 为什么将其与数据检索工具集成能显著提升 AI 代理的能力。
- 如何将 Agno 与 Bright Data 工具结合,构建具备实时数据检索能力的代理。
让我们开始吧!
什么是 Agno?
Agno 是一个开源的 Python 框架,用于构建轻量级 AI 代理和多代理系统。它内置了记忆、知识整合、高级推理等支持。
Agno 的独特之处在于以下几点:
- 模型无关:提供统一接口,支持超过 23 家大模型提供商。
- 高性能:代理实例化仅需约 3 微秒,平均只占用约 6.5 KiB 内存。
- 推理优先:强调推理以提升代理的可靠性并处理复杂任务。它支持三种推理方式:推理模型、推理工具以及自定义思维链管道。
- 原生多模态:代理开箱即可处理和生成文本、图像、音频和视频。
- 支持多代理场景:可构建具备共享记忆、上下文和协调推理的协作代理团队。
- 内置代理搜索:代理可在运行时在 20 多个向量数据库中搜索,实现先进的代理 RAG 工作流。
- 集成记忆和会话存储:代理内置存储和记忆驱动,提供长期记忆和持久会话跟踪。
- 结构化输出:返回完全类型化的响应。
此外,Agno 内置支持 50 多家第三方 AI 工具提供商。这意味着使用 Agno 构建的 AI 代理可以轻松集成市场上一些顶级 AI 解决方案。
AI 代理需要访问网络数据以保持准确和高效
每个 AI 代理框架都继承了其所依赖的 LLM 的关键局限性。由于大多数LLM 预训练于静态数据集,它们缺乏实时感知,无法可靠地访问实时网络内容。
这常常导致答案过时甚至产生幻觉。为克服这些限制,代理(以及在扩展中使用的 LLM)需要访问可信的网络数据。为什么是网络数据?因为网络是最全面的信息来源。
因此,实现这一目标的有效方法是赋予 Agno 代理执行实时搜索查询并抓取任意网页内容的能力。通过Agno 的 Bright Data 工具即可做到这一点!
这些工具原生集成于 Agno,为代理提供了对丰富的 AI 就绪网络数据工具的访问。功能包括网页爬取、SERP 数据检索、截图功能,以及来自 40 多个知名站点的 JSON 格式数据源访问。
如何将 Bright Data 爬取工具集成到 Agno 代理中
在本节中,您将学习如何使用 Agno 构建一个能够连接到 Bright Data 工具的 Python AI 代理。这些工具将为您的代理提供从任意页面抓取数据和获取最新搜索引擎结果的能力。
请按照以下步骤在 Agno 中构建您的 Bright Data 驱动 AI 代理!
前提条件
要遵循本教程,请确保您具备以下条件:
- 本地安装 Python 3.7 或更高版本(建议使用最新版本)。
- 一个 Bright Data API 密钥。
- 一个受支持的大模型提供商的 API 密钥(本教程将使用 OpenAI,但其他支持的提供商也可)。
如果您还没有 Bright Data API 密钥,不用担心,我们将在接下来的步骤中引导您创建。
步骤一:项目设置
打开终端,为您的 Agno AI 代理创建一个新的文件夹,以启用 Bright Data 驱动的数据检索:
mkdir agno-bright-data-agentagno-bright-data-agent 文件夹将包含您 AI 代理的所有 Python 代码。
接下来,进入项目文件夹,并在其中创建一个虚拟环境:
cd agno-bright-data-agent
python -m venv venv现在,在您喜欢的 Python IDE 中打开该项目文件夹。我们推荐使用带 Python 扩展的 Visual Studio Code 或 PyCharm 社区版。
在项目文件夹内创建一个名为 agent.py 的新文件。您的项目结构现在应如下所示:
agno-bright-data-agent/
├── venv/
└── agent.py在终端中激活虚拟环境。在 Linux 或 macOS 上,执行以下命令:
source venv/bin/activate在 Windows 上,则运行:
venv/Scripts/activate接下来,您将学习如何安装所需依赖。如果您想现在就安装所有内容,请在已激活的虚拟环境中运行以下命令:
pip install agno python-dotenv openai requests注意:我们安装 openai 因为本教程使用 OpenAI 作为大模型提供商。如果您打算使用其他模型,请安装该提供商对应的库。
一切就绪!您现在拥有了使用 Agno 和 Bright Data 工具构建 AI 代理的 Python 开发环境。
步骤二:设置环境变量读取
您的 Agno 代理将通过 API 与 OpenAI、Bright Data 等第三方服务交互。为了安全起见,不应将 API 密钥硬编码到 Python 代码中,而应将其存储为环境变量。
为简化环境变量加载,请使用 python-dotenv 库。在激活的虚拟环境中安装它:
pip install python-dotenv然后,在您的 agent.py 文件中,导入该库并使用 load_dotenv() 加载环境变量:
from dotenv import load_dotenv
load_dotenv()该函数使脚本能够从本地 .env 文件读取变量。请在项目根目录下创建一个 .env 文件:
agno-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.py太好了!您现在已设置好使用环境变量安全地管理第三方集成密钥。
步骤三:开始使用 Bright Data
截至目前,Agno 集成的 Bright Data 工具可访问以下解决方案:
- SERP API:提供所有主要搜索引擎的实时搜索结果的 API。
- Web Unlocker API:一种高级爬取 API,可绕过复杂的反机器人保护,让您访问任意网页(以 Markdown 格式提供,该格式针对 AI 使用优化)。
- Web Scraper APIs:专用的爬取端点,用于从多个热门域名中道德地提取新鲜、结构化的网络数据。
要集成上述工具,您需要:
- 在您的 Bright Data 帐户中配置 SERP API 和 Web Unlocker 服务。
- 获取您的 Bright Data API 令牌以访问这些服务。
请按照下文说明完成这两步!
首先,如果您还没有 Bright Data 帐户,请先创建一个。如果已有帐号,请登录并打开仪表板:
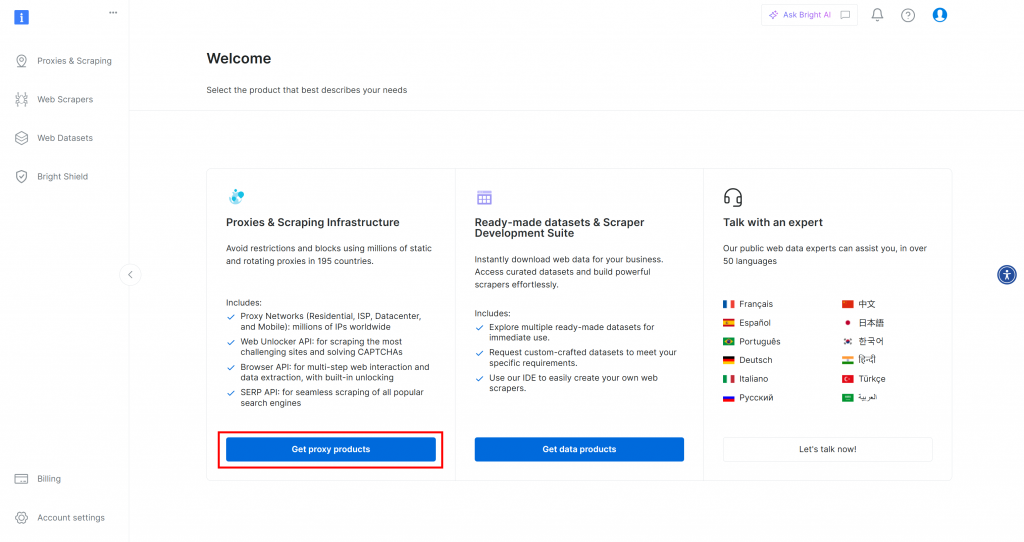
点击“获取代理产品”按钮,会跳转到“代理与爬取基础设施”页面:
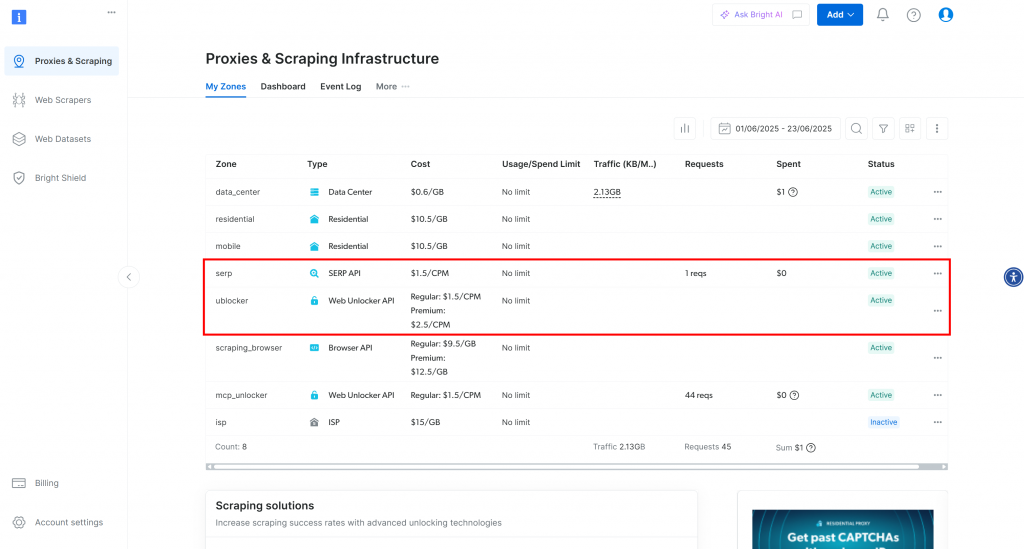
在此示例中,您可以看到 SERP API 和 Web Unlocker API 均已激活并可使用。它们的区域名称分别为 serp 和 unblocker。
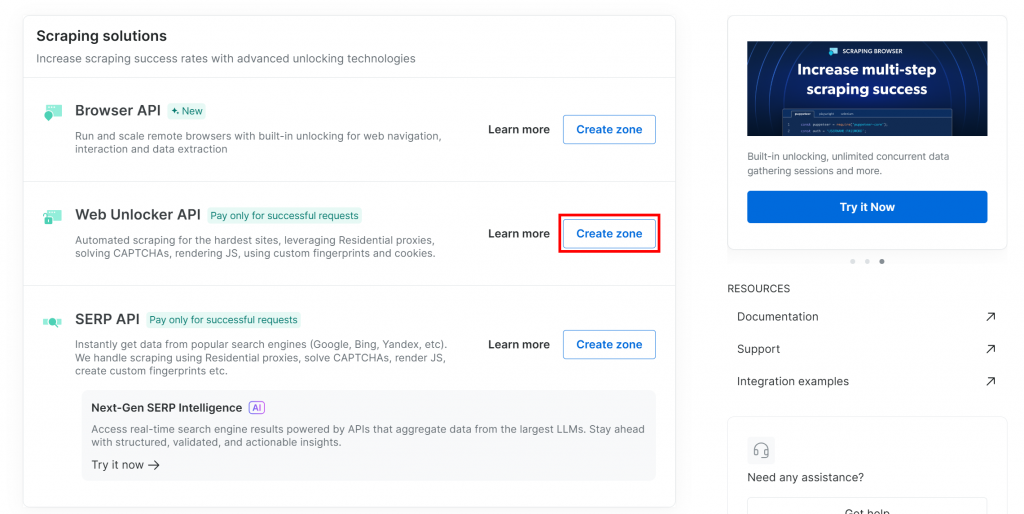
如果您的情况不同,则需要进行设置。我们将演示如何创建 Web Unlocker API 区域,但创建 SERP API 区域的流程类似。
向下滚动,在“Web Unlocker API”卡片上点击“创建区域”:
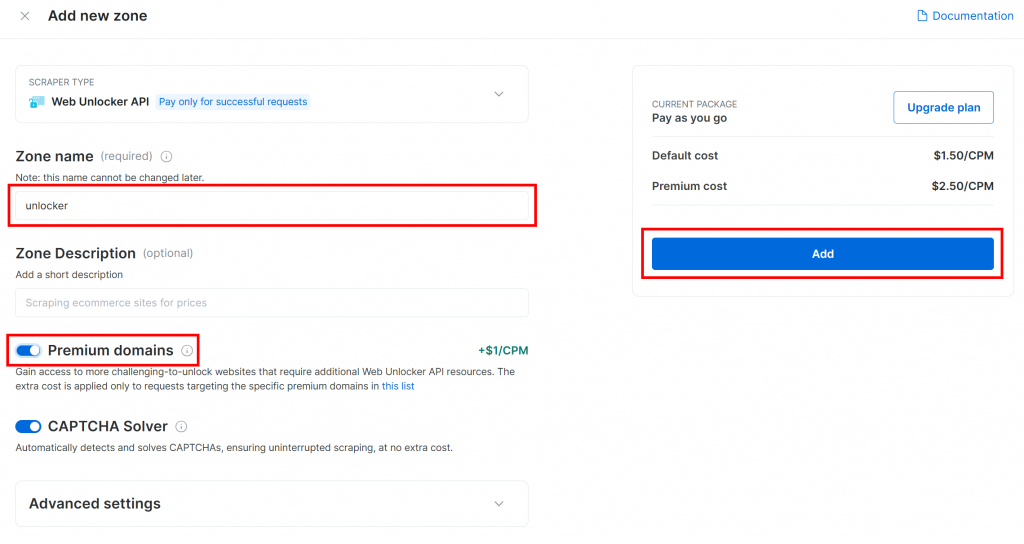
为您的区域命名(例如 unlocker),启用高级功能以达到最佳效果,然后点击“添加”:
之后,您将被重定向到区域页面,如下所示:
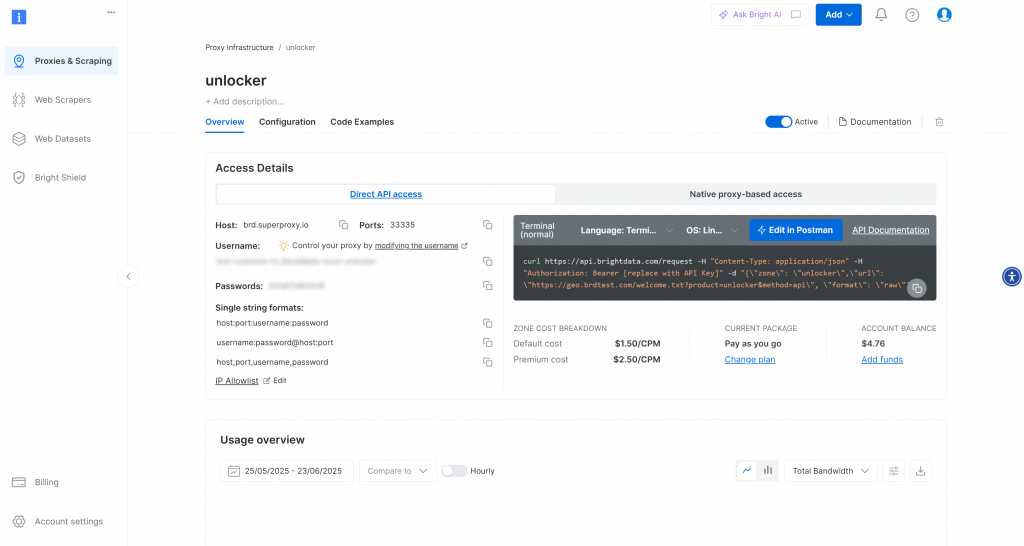
确保激活开关置于“已激活”状态,这意味着您的区域已正确设置并可使用。
接下来,按照Bright Data 官方指南生成 API 密钥。生成后,将其添加到您的 .env 文件,如下所示:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 占位符替换为您的实际 API 密钥。
太好了!现在将 Bright Data 工具集成到您的 Agno 代理脚本中。
步骤四:安装并配置 Agno Bright Data 工具
在项目文件夹中,并激活虚拟环境后,运行以下命令安装 Agno:
pip install agno注意:agno 包已内置 Bright Data 工具支持,因此无需安装其他特定集成的包。
由于 Bright Data 工具依赖于Python requests 库,请确保也安装它:
pip install requests在您的 agent.py 文件中,从 Agno 导入 Bright Data 工具:
from agno.tools.brightdata import BrightDataTools然后,按如下方式初始化工具:
bright_data_tools = BrightDataTools(
serp_zone="YOUR_SERP_ZONE_NAME",
web_unlocker_zone="YOUR_UNLOCKER_ZONE_NAME"
)将 "YOUR_SERP_ZONE_NAME" 和 "YOUR_UNLOCKER_ZONE_NAME" 替换为您之前配置的 Bright Data 区域名称。例如,如果您的区域分别命名为 serp 和 unlocker,代码如下:
bright_data_tools = BrightDataTools(
serp_zone="serp",
web_unlocker_zone="unlocker"
)注意,您也可以不在代码中直接传递区域名称,而是在您的 .env 文件中使用以下环境变量:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"
BRIGHT_DATA_SERP_ZONE="<YOUR_BRIGHT_DATA_SERP_ZONE>"用您 Bright Data 区域的实际名称替换占位符。然后,在 BrightDataTools 中移除 serp_zone 和 web_unlocker_zone 参数,
注意:要连接到 Bright Data 服务,BrightDataTools 依赖于 BRIGHT_DATA_API_KEY 环境变量。具体而言,它期望 BRIGHT_DATA_API_KEY 环境变量中包含您的 Bright Data API 密钥。这就是我们在上一步将其添加到 .env 文件的原因。
太棒了!接下来进行的是与大模型的集成。
步骤五:设置大模型 (LLM)
要连接本教程使用的 LLM 提供商 OpenAI,首先安装所需的 openai 依赖:
pip install openai然后,从 Agno 导入 OpenAI 集成类:
from agno.models.openai import OpenAIChat现在,按如下方式初始化您的大模型:
llm_model = OpenAIChat(id="gpt-4o-mini")上述 "gpt-4o-mini" 是本指南中使用的 OpenAI 模型名称。如有需要,您可以更换为其他受支持的 OpenAI 模型。
在后台,OpenAIChat 期望您的 OpenAI API 密钥定义在名为 OPENAI_API_KEY 的环境变量中。为此,请将以下行添加到您的 .env 文件:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"将 <YOUR_OPENAI_API_KEY> 占位符替换为您实际的 OpenAI API 密钥。
注意:如果您希望连接其他 Agno 支持的 LLM,请参阅官方文档获取说明。
做得好!您现在拥有了构建具备网络数据检索能力的 Agno 代理的所有基础组件。
步骤六:创建代理
在您的 agent.py 文件中,定义您的代理:
agent = Agent(
tools=[bright_data_tools],
show_tool_calls=True,
model=llm_model,
)这将创建一个 Agno 代理,使用配置的大模型来处理用户输入,并可访问 Bright Data 工具进行数据检索。show_tool_calls=True 选项有助于了解代理的操作过程,因为它会显示代理为处理请求而使用了哪些工具。
别忘了从 Agno 导入 Agent 类:
from agno.agent import Agent太棒了!Agno 与 Bright Data 的集成已完成。接下来,只需向代理发送查询,看看它的实际表现。
步骤七:查询由 Bright Data 工具驱动的代理
现在,您可以使用下面两行代码与您的 Agno AI 代理交互:
prompt = "Search for AAPL news"
agent.print_response(prompt, markdown=True)第一行定义了提示,描述了您希望代理处理的任务或问题。第二行则执行该提示并打印输出。
markdown=True 选项确保响应以 Markdown 格式呈现,适合可读且 AI 友好的输出。
注意:您可以尝试任何提示,但“Search for AAPL news”是测试 SERP 数据检索功能的不错起点。
步骤八:整合所有内容
您的 agent.py 文件最终代码应如下所示:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.openai import OpenAIChat
from agno.agent import Agent
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
serp_zone="serp", # Replace with your SERP API zone name
web_unlocker_zone="unlocker" # Replace with your Web Unlocker API zone name
)
# The LLM that will be used by the AI agent
llm_model = OpenAIChat(id="gpt-4o-mini")
# The definition of your Agno agent, with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
show_tool_calls=True, # Useful for understanding what happens behind the scenes
model=llm_model,
)
# Run a task in the AI agent
prompt = "Search for AAPL news"
agent.print_response(prompt, markdown=True)不到 30 行代码,您就构建了一个能够从任意网页抓取数据并在主要搜索引擎中执行实时搜索的 AI 代理。这就是 Agno 作为构建 AI 代理的全栈框架的强大之处!
步骤九:运行您的 Agno 代理
现在是运行您的 Agno AI 代理的时候了。在终端中,执行:
python agent.py您将在终端看到一个动态输出,显示代理正在处理“Search for AAPL news”提示。完成后,代理将生成如下结果:
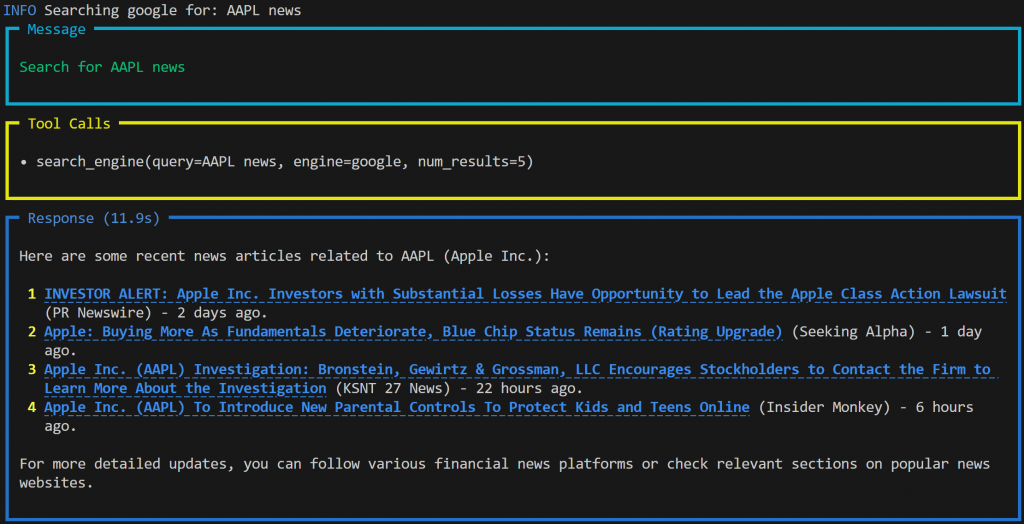
输出内容包括:
- 您提交的提示。
- 代理用于完成任务的工具。在此示例中,它使用了 Bright Data 工具的
search_engine()函数,通过 SERP API 访问 Google 并检索有关 AAPL 股票的实时新闻。 - 基于检索到的数据,由 OpenAI 模型生成的 Markdown 格式响应。
注意:结果包含带可点击链接的实时新闻内容,得益于 Markdown 格式。此外,部分新闻非常新,仅在运行提示前几小时内发布。
现在,让我们更进一步。假设您想要对检索到的某篇新闻文章做个摘要。您只需更新提示:
prompt = """
Give me a summary of the following news in around 150 words.
NEWS URL:
https://www.msn.com/en-us/money/other/apple-inc-aapl-to-introduce-new-parental-controls-to-protect-kids-and-teens-online/ar-AA1HdVd6
"""
agent.print_response(prompt, markdown=True)这次,输出将类似于:
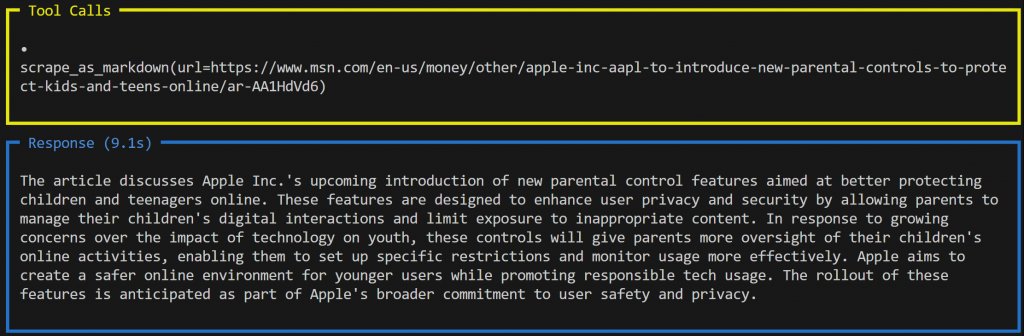
在此示例中,代理使用了另一种工具:scrape_as_markdown(),该工具连接到 Web Unlocker API。它以 Markdown 格式获取网页内容,并将其传递给大模型进行摘要。
就这样!您刚刚体验了由 Bright Data 工具和 Agno 驱动的 AI 代理中的无缝数据检索与处理。
下一步
您在本教程中使用 Agno 构建的 AI 代理只是一个起点。实际上,我们只触及了可能性的冰山一角。要进一步推进您的项目,您可以考虑以下操作:
- 添加知识存储:使用 Bright Data 工具检索网络数据并将其存储在 Agno 内置的向量数据库中,以提升代理能力。这将实现长期记忆并支持代理 RAG。
- 启用代理记忆和推理:为您的代理配备记忆和多步推理能力,让其能够学习、反思并做出明智决策。这使您能够实现高级模式,如流行的ReAct(推理 + 行为)代理架构。
- 构建简化交互的 UI:添加用户界面,以提供类似 ChatGPT 的体验,为与您的 AI 代理进行更自然的对话打开大门。
有关更多想法和高级集成,请查看官方 Agno 文档。
结论
在本文中,您学习了如何使用 Agno 和 Bright Data 工具构建具备实时数据检索能力的 AI 代理。此集成可让您的代理访问来自网站和搜索引擎的公共网络内容。
别忘了,这里展示的只是一个简单示例。如果您希望构建更高级的代理,您需要可以检索、验证和转换实时网络数据的解决方案。这正是您在Bright Data 的 AI 基础设施中可以找到的。
创建一个免费的 Bright Data 帐户,开始尝试我们的 AI 就绪数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




