

在完成本教程之后,你将了解:
- 为什么 PyTorch 是构建多模态机器学习工作流的绝佳选择。
- 为什么需要来自可信数据提供方、包含数百万条记录的数据集(例如 Bright Data 提供的数据集)。
- 如何在 PyTorch 中利用 Bright Data 数据集,通过多模态流程微调一个用于商品图片分类的机器学习模型。
让我们开始吧!
为何在多模态机器学习中选择 PyTorch
数据的价值取决于它能带来什么洞察。对企业而言,以正确的方式利用数据可以帮助做出更明智的决策、优化策略,并提升客户留存、营销效果等业务结果。
现代机器学习不仅可以处理评分或销售数据等结构化数据,还能处理图片、文本甚至视频等非结构化数据,从而实现多模态洞察。例如,将评论图片与文本结合起来,可以更深入理解驱动客户参与的因素。
本文基于 PyTorch,这是一个广泛用于构建与训练深度神经网络的 Python 机器学习框架。该库支持包括图像分类、自然语言处理以及多种数据类型联合分析在内的一长串任务。
一些常见的 PyTorch 应用场景包括:
- 评估商品图片质量:自动判断图片是否具有视觉吸引力以及是否可能提升用户参与度。
- 分析客户情绪:从文本评论中提取洞察,以理解用户观点与满意度。
- 构建推荐系统:融合文本和图像特征,生成更精准且个性化的商品推荐。
- 基于多模态数据的预测建模:同时利用视觉与文本信息来预测趋势、销量或客户行为。
如何为企业获取高质量多模态数据
无论你在开发哪种类型的机器学习或 AI 应用,都必须牢记一点:这些系统的效果,取决于用于训练的数据质量。
在多模态应用中,数据获取尤为具有挑战性,因为这需要同时收集文本和图像等多种格式的信息。这正是像 Bright Data 这样的可信数据提供方发挥作用的地方。
Bright Data 为各类企业(从初创公司到大型企业)提供一整套面向 AI 与机器学习的即用型解决方案:
- Web Scraper API:以编程方式从数百个热门网站获取结构化数据,实现大规模自动化采集最新网页数据。
- 数据集市场(Dataset Marketplace):提供包含数十亿条记录的即用型多模态数据集,包括图片、文本以及结构化字段。
- 托管数据采集服务:企业级全托管方案,让团队无需自建或维护抓取流水线即可持续获取与维护数据。
- 数据标注服务:面向 NLP、计算机视觉、语音识别任务的可扩展、可定制标注解决方案。
借助这些解决方案,研究人员、中小企业和大型企业都可以高效采集并整合公共网络数据,用于支撑多模态机器学习工作流、训练复杂 AI 模型、构建智能 Agent,以及打造分析与商业智能系统。
如何使用 PyTorch 与 Bright Data 数据集构建多模态机器学习分析流水线
在本引导部分,你将学习如何在 Bright Data 的“Amazon products”数据集上训练机器学习模型。该数据集同时包含文本与图像数据。
我们假设你在线上销售商品,也清楚展示优质图片的重要性。目标是使用 PyTorch 在电商商品图片及其评分信息上训练机器学习模型,使其能够自动评估商品图片是“好(GOOD)”还是“坏(BAD)”。
得益于这个多模态 ML 工作流,你的业务可以以编程方式评估商品图片吸引客户和促进互动的可能性。
注意:这只是一个示例。通过将 PyTorch 与 Bright Data 数据集及数据流结合,你还可以覆盖许多其他用例与场景。
按下面的步骤操作!
前提条件
要跟随本节操作,请确保你已经:
- 在本地安装了Python 3.9 或更高版本。
- 拥有一个Bright Data 账号。
另外,如果你熟悉 ResNet-18 模型以及微调的工作原理,将更容易完全理解本教程中的多模态 PyTorch 图像分类逻辑。
步骤一:创建 JupyterLab 项目
在处理多模态数据时,可视化数据集非常有帮助。因此,JupyterLab 是极佳的开发环境选择。等工作流开发完成后,再将代码转换为生产环境可用的机器学习流水线会非常容易。
首先创建一个独立的项目文件夹并进入其中:
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysis接下来在该目录中初始化虚拟环境:
python -m venv .venv在 macOS/Linux 上,激活虚拟环境:
source .venv/bin/activate在 Windows 上则运行:
.venv\Scripts\activate激活虚拟环境后,通过 jupyterlab 包安装 JupyterLab:
pip install jupyterlab启动 JupyterLab:
jupyter lab浏览器中会在 http://localhost:8888/lab/ 打开 JupyterLab。点击 “Notebook” 区域下的 “Python 3 (ipykernel)” 按钮创建新 Notebook:
你会看到一个名为 Untitled.ipynb 的文件:
将该 Notebook 重命名为类似 “Bright Data + PyTorch” 并保存。
至此完成!你已经拥有一个完全就绪的 Python 环境,可以使用 PyTorch 开发多模态机器学习工作流。
步骤二:安装并导入所需依赖
在 Notebook 中新增一个代码单元,并执行以下 pip 命令:
!pip install pillow tqdm requests scikit-learn torch torchvision pandas运行此单元会安装所有所需库:
pillow:用于加载和处理图片。tqdm:为循环显示进度条,便于跟踪数据加载和训练过程。requests:通过 HTTP 请求从 URL 下载图片。scikit-learn:提供诸如train_test_split等数据集划分工具。torch:PyTorch 核心库,用于构建与训练机器学习模型。torchvision:提供数据集、预训练模型和图像变换。pandas:便于处理 CSV 等结构化数据并执行数据操作。
再创建一个代码单元,导入所有所需模块:
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import Image很好!通过这两个单元,你的 Notebook 已经完全就绪,可以处理 Bright Data 多模态数据集,并在 PyTorch 中执行图像与文本处理。
步骤三:下载 Bright Data 数据集
现在 Notebook 中的 PyTorch 开发环境已经就绪,是时候获取此工作流中最重要的组件:输入数据!
本教程将使用 “Amazon products” 数据集,这是 Bright Data 提供的众多电商数据集之一。截至撰文时,该数据集包含超过 3.11 亿条记录,每条记录拥有 87 个字段。对于每个商品,这些字段涵盖图片 URL、评论评分、商品 ASIN 以及更多信息。
注意:你也可以使用 Bright Data 的 eCommerce Scraper 从 Amazon、eBay、Walmart 等平台采集最新的结构化数据。
首先,如果你还没有 Bright Data 账号,请注册一个。如果已有账号,则登录并进入账户中的 “Dataset marketplace” 页面:
在 “Most popular” 中选择 “Amazon products” 数据集:
随后你会进入该数据集详情页: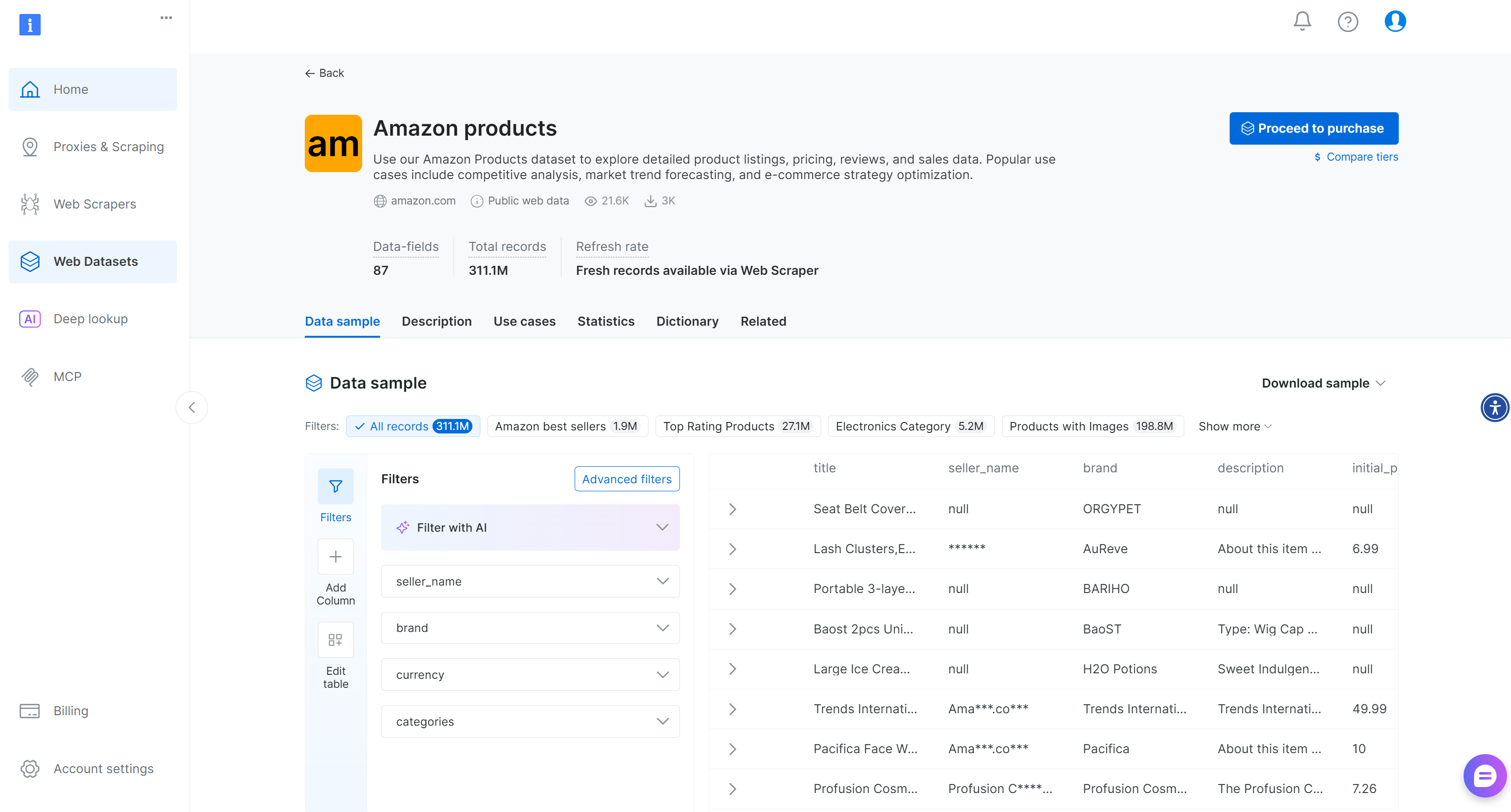
在这里,你可以手动使用过滤条件,或通过 AI 驱动的过滤器创建适配自身需求的子集。注意,这些过滤器也可以通过 Filter API 以编程方式调用,用于基于特定条件创建数据集快照。
本教程只需要一个较小的样本数据集来演示多模态 ML 工作流,因此免费样本就足够了。如果是生产级或企业级工作流,你需要基于具体业务需求下载完整数据集。
要下载样本数据集,打开 “Dataset sample” 下拉菜单并选择 “Download as CSV”: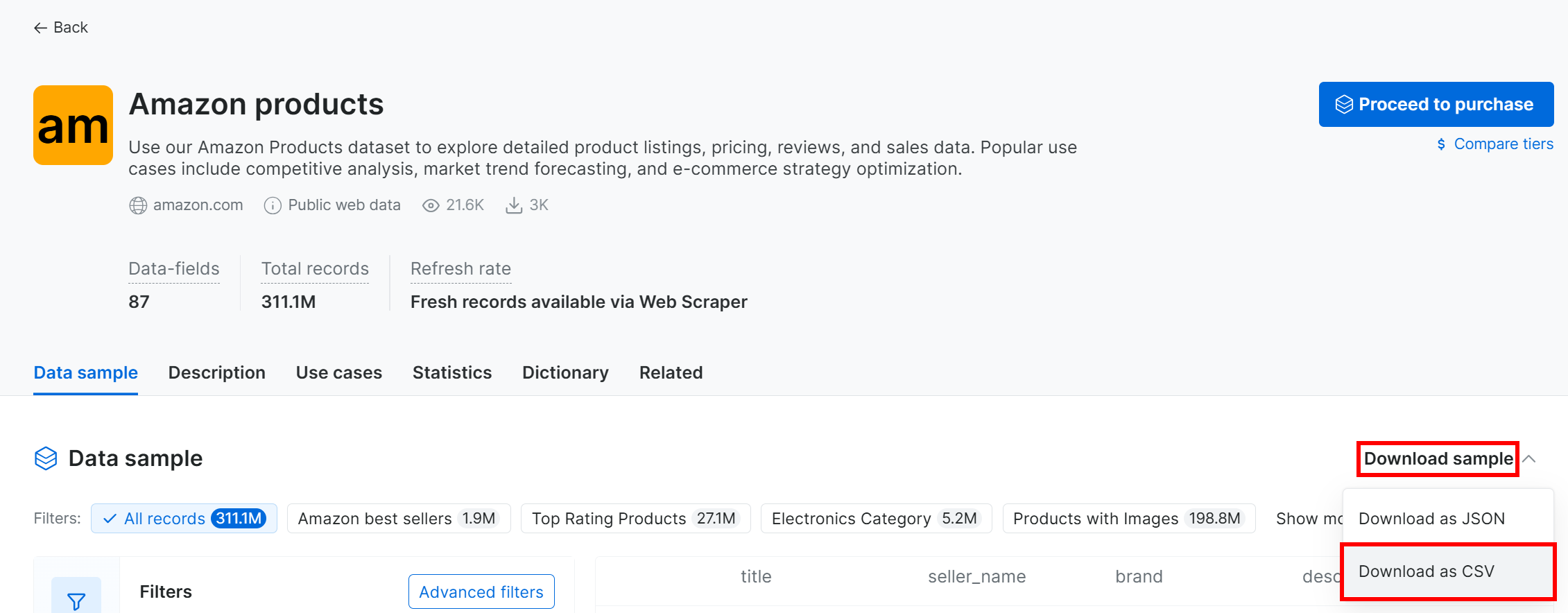
你将获得一个名为 Amazon products.csv 的文件,包含约 1,000 条商品记录(约 7.3 MB)。将其重命名为 amazon_products.csv 并放入项目文件夹中: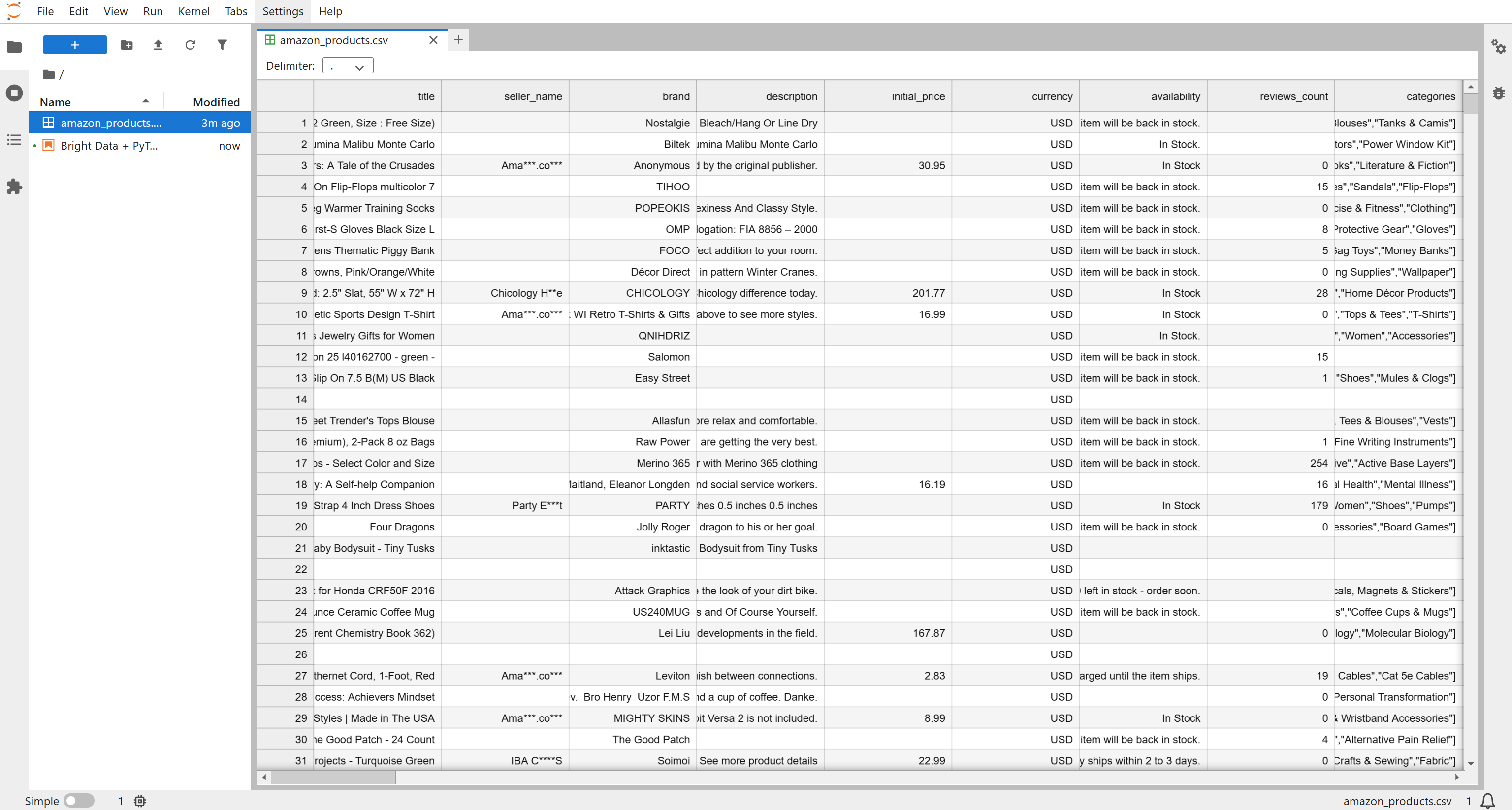
在 87 个可用字段中,与本多模态工作流最相关的是:
asin:Amazon 上的唯一商品标识符。image_url:商品主图的 URL。images:一个 JSON 格式的数组,包含该商品的更多图片 URL。rating:平均用户评分,范围 1–5。
这些字段让你可以在多模态 PyTorch 工作流中,将视觉数据(图片)与结构化数值数据(评分)结合使用。很棒,你已经拿到了输入数据集。
步骤四:定义下载与标注商品图片的逻辑
回到 Notebook,首先编写用于下载与标注图片的核心函数。这两个函数是实现 ML 图像分类流程的基础,其整体流程包括:
- 从 Bright Data 的 “Amazon products” 数据集中采集包含
image_url、images数组、rating和asin的商品数据。 - 为每个商品条目提取并去重所有图片 URL。
- 从所有 URL 下载图片并存储到本地。
- 结合视觉启发(白底、分辨率)与评分信息为图片打标签。
- 基于已标注图片构建 PyTorch 数据集,用于训练 CNN(卷积神经网络)模型。
- 微调 CNN,使其能够根据标签预测图片质量(“GOOD” vs “BAD”)。
- 在测试集上评估模型表现。
- 使用模型自动评估新的商品图片。
在 Notebook 中新建代码单元,写入以下用于下载和标注图片的函数:
def download_image(url):
# Send a GET request to the URL of the image
response = requests.get(url)
# Read the content of the response into a BytesIO object
image_bytes = io.BytesIO(response.content)
# Open the image with PIL and convert to RGB mode
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# Get the width and height of the image
w, h = image.size
# Crop the top 10 pixels to analyze the border for brightness
border = image.crop((0, 0, w, 10))
# Compute statistics (mean) for the border
stat = ImageStat.Stat(border)
# Average brightness across RGB channels
brightness = sum(stat.mean) / 3
# Determine if the image has a white background
is_white_bg = brightness > 240
# Determine if the image is low resolution (smallest side < 400px)
is_low_res = min(image.size) < 400
# Heuristic label: 1=good if white background and not low-res, else 0=bad
heuristic_label = 1 if (is_white_bg and not is_low_res) else 0
# If rating is missing or zero, rely only on heuristic
if rating is None or rating == 0:
return heuristic_label
# Normalize rating to range 0-1
r = rating / 5
# Apply weak supervision to adjust the label based on extreme ratings
if heuristic_label == 1 and r < 0.5: # very low rating → mark as bad
return 0
if heuristic_label == 0 and r > 0.9: # excellent rating → mark as good
return 1
# Otherwise, keep the heuristic label
return heuristic_labeldownload_image() 函数只是从给定 URL 下载图片,并以 PIL 的 Image 实例返回。而 label_image() 函数则实现了多模态的图片评价逻辑,综合视觉线索与文本/数值数据(如用户评分)对商品图片打分。
label_image() 会先应用启发式规则——检查图片是否为白底以及是否具有足够分辨率——以给出初始 “好/坏” 标签。然后,如果评分可用,该函数会进一步按如下方式调整标签:
- 非常低的评分会覆盖一张在视觉上看起来不错的图片。
- 极高的评分则可能“拯救”一张外观较差的图片。
这一逻辑是合理的:即便图片看起来不错,如果评分很差,说明它并未真正带来收益;相反,如果评分极高,即便图片不佳,也说明其在实际业务中较为成功。通过这种方式,在最终打标签时,不仅考虑视觉信息,也考虑数值信息。
很好!接下来将导入数据集,并为商品条目做预处理,以便对所有图片应用这两个函数。
步骤五:加载数据集并准备下载所有图片
如果你打开 amazon_products.csv 文件,会发现商品图片存储在两个字段中:
image_url:主商品图片 URL。images:一个 JSON 格式字符串,内部为包含所有附加商品图片 URL 的数组。
在一个新的代码单元中加载该 CSV,并通过辅助函数提取每个商品的所有图片:
def extract_image_list(row):
image_urls = []
# Check for a single main image_url and add it if it exists and is non-empty
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# Check the "images" field, which can be a JSON string or a Python list
images_field = row.get("images")
if isinstance(images_field, str):
# Decode JSON string into a Python list
decoded = json.loads(images_field)
if isinstance(decoded, list):
# Add all images from the list to the image_urls
image_urls.extend(decoded)
# Deduplicate the URLs by converting to a set, then back to a list
return list(set(image_urls))
# Load the Amazon products CSV into a DataFrame
df = pd.read_csv("amazon_products.csv")
# Drop rows that are missing required fields
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# Apply the extract_image_list function to each row to generate a list of all unique image URLs
df["all_image_urls"] = df.apply(extract_image_list, axis=1)导入后的数据集中现在多了一列 all_image_urls,该列保存了去重后的图片 URL 列表,将主图和所有附加图片统一整合。接下来,你将通过该字段下载并处理每个商品的所有图片。
步骤六:下载并标注所有图片
在单元格中实现下载所有商品图片到本地 images/ 文件夹并为其打标签的逻辑:
# Create the "images" folder if it does not already exist
os.makedirs("images", exist_ok=True)
# Initialize a list to store metadata for each downloaded and labeled image
records = []
# Iterate over each product row in the DataFrame with a progress bar
for idx, row in tqdm(df.iterrows(), total=len(df)):
# Access the required product data fields
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# Iterate over each image URL for this product to download and label it
for i, url in enumerate(url_list):
# Download the image
image = download_image(url)
if image is None:
continue
# Construct a filename using ASIN and the image index
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# Save the downloaded image to disk
image.save(path)
# Label the image using the multi-modal information
label = label_image(image, rating)
# Store relevant metadata for this image
records.append({
"asin": asin,
"image_path": path,
"image_url": url,
"label": label
})
# Convert the records list into a DataFrame and export it to a CSV file
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)在 Notebook 中运行这一代码块后,图片下载过程就会启动。需要下载 2,500 张以上图片,因此请耐心等待几分钟。
完成后,输出单元中会显示进度条达到 100%:
此时,项目目录中的 images/ 文件夹将包含从数据集中下载的所有商品图片: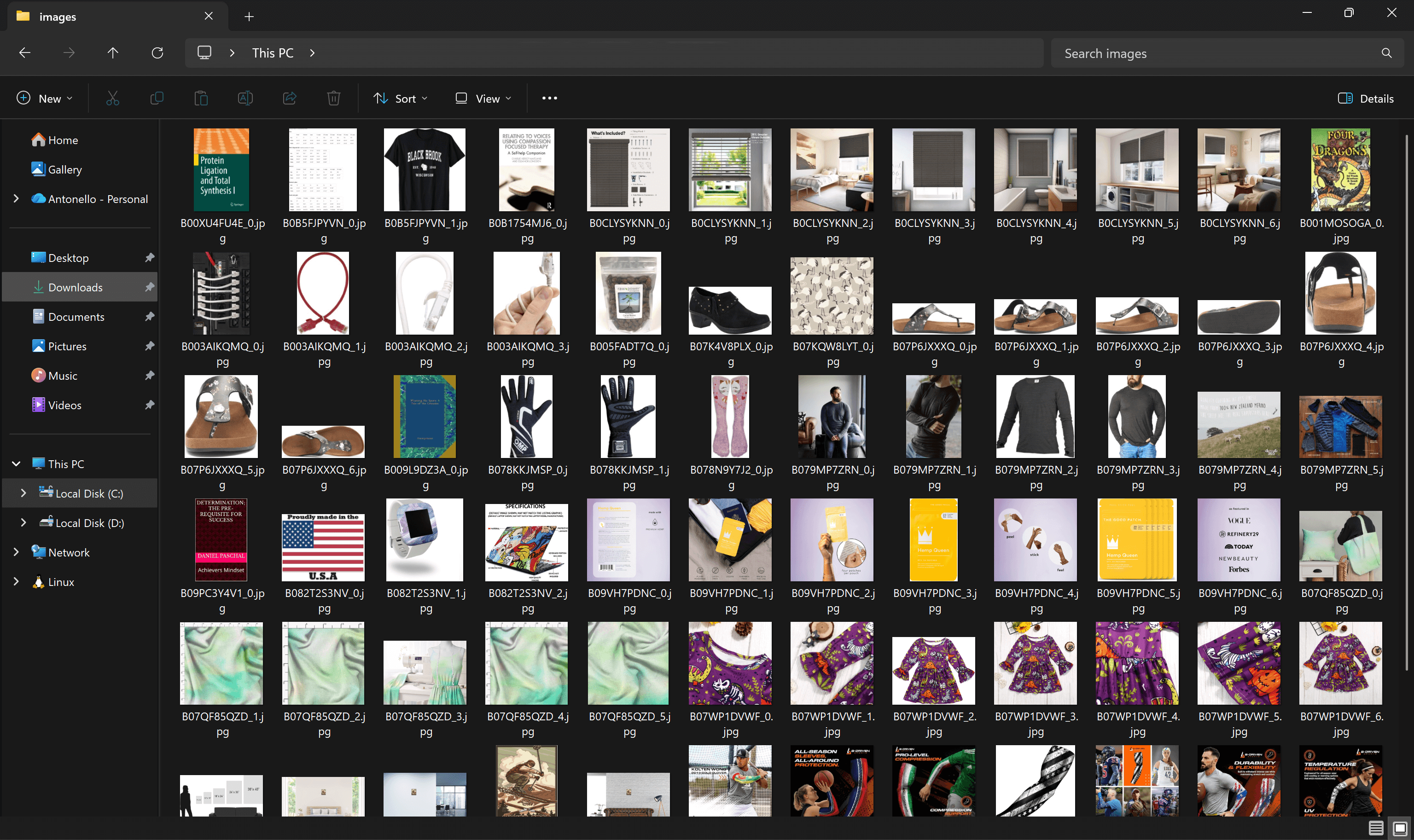
同时,labeled_images.csv 文件会被创建并填充每张图片对应的打标信息: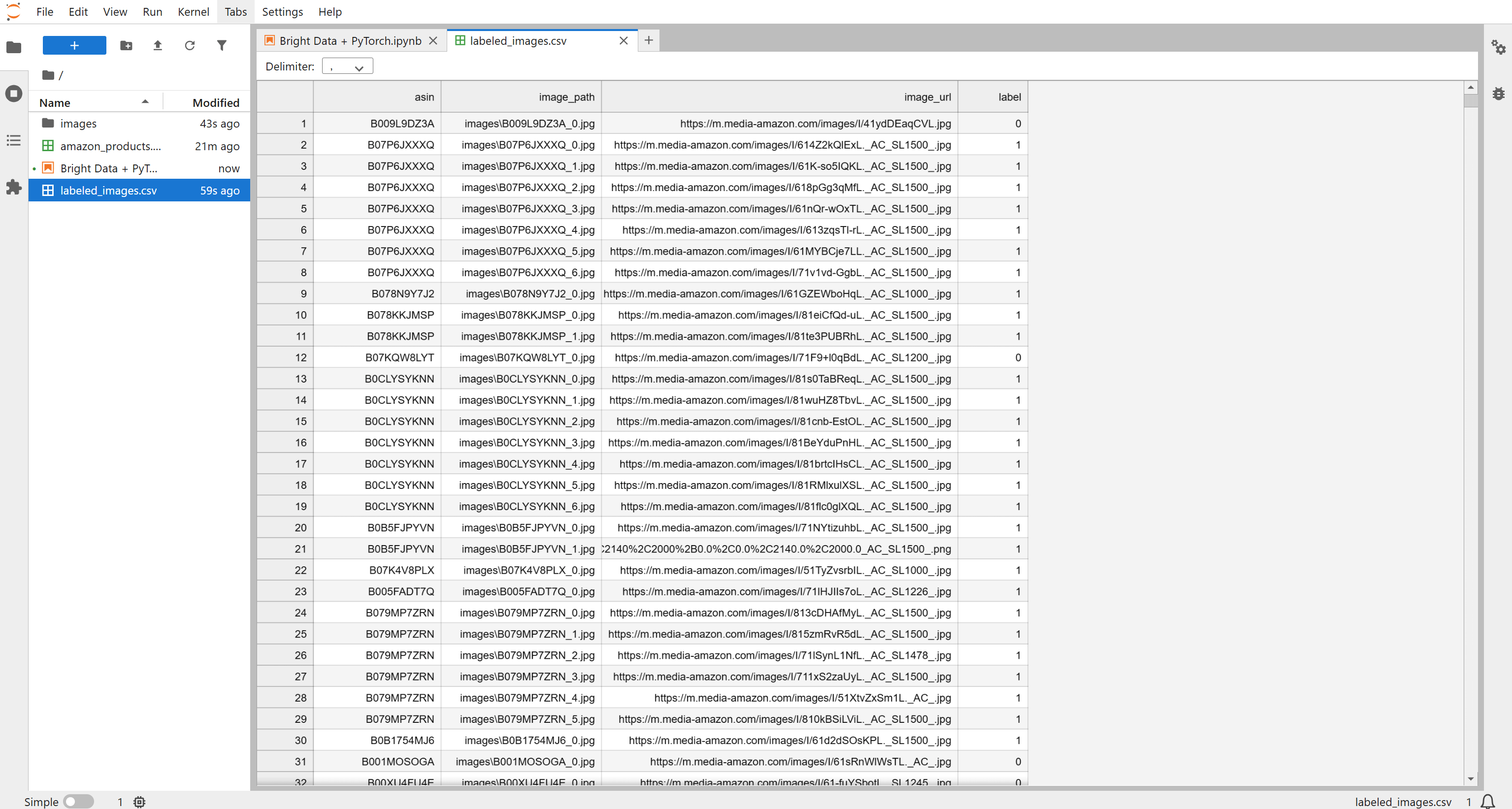
非常棒!到这里,你已经拥有足够的本地图片和标注信息,可以在多模态流程中训练机器学习模型。
步骤七:准备训练集与测试集
在新代码块中,从 labeled_images.csv 中读取图片标注信息,并基于此生成后续用于模型微调的训练与测试数据集:
# Define a custom PyTorch Dataset class for product images
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# Return the total number of samples in the dataset
return len(self.df)
def __getitem__(self, idx):
# Get the image path and label for a given index
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# Load the image and convert to RGB
image = Image.open(path).convert("RGB")
# Apply transformations if provided (e.g., resizing, tensor conversion)
if self.transform:
image = self.transform(image)
# Return the image tensor and label as a torch tensor
return image, torch.tensor(label, dtype=torch.long)
# Load the labeled images CSV
labeled_df = pd.read_csv("labeled_images.csv")
# Split the dataset into training and testing sets, keeping label distribution balanced
train_df, test_df = train_test_split(
labeled_df,
test_size=0.2,
stratify=labeled_df["label"]
)
# Define transformations to resize images to 224x224 and convert to tensors
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# Initialize the dataset objects
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# Wrap the datasets in DataLoaders for batching and shuffling
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)该代码片段通过自定义 Dataset 类为训练 CNN 做好准备,并应用了以下图像变换:
transforms.Resize((224, 224)):将所有图片统一缩放至224×224。这很重要,因为原始图片分辨率与长宽比各不相同,而 CNN 需要固定大小的输入。transforms.ToTensor():PyTorch 模型操作的是张量而非原始 PIL 图片,该变换会将图片转换为形状为(C, H, W)(通道数、高度、宽度)的归一化张量,使其适配 CNN。
以上变换可统一每张图片的尺寸和格式,让模型专注于学习视觉模式,而非处理不一致的输入。随后,数据被分为训练集与测试集(保持标签分布),并通过 DataLoader 封装成批量产生图片与标签的数据迭代器。
整体而言,这一步确保 CNN 得到的是格式正确的数据,为后续有效的多模态机器学习训练打下基础。
步骤八:训练多模态机器学习模型
训练与测试数据集就绪后,可以通过以下代码在 PyTorch 中微调一个 CNN 模型用于图片分类:
# Select the device for training (GPU if available, otherwise CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load a pre-trained ResNet-18 model from torchvision
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# Replace the final fully connected layer to output 2 classes (GOOD/BAD)
model.fc = nn.Linear(model.fc.in_features, 2)
# Move the model to the selected device
model = model.to(device)
# Define the loss function for classification
criterion = nn.CrossEntropyLoss()
# Define the optimizer with a small learning rate
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# Training loop for 3 epochs
for epoch in range(3):
model.train()
total_loss = 0
# Iterate over batches of images and labels
for images, labels in tqdm(train_dl, desc=f"Epoch {epoch+1}"):
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# Print average loss for the epoch
print(f"Epoch {epoch+1}: Average Loss={total_loss/len(train_dl):.4f}")上述代码对一个预训练的 ResNet-18 CNN 模型进行微调。ResNet-18 是一个 18 层深的卷积神经网络,通常用于将图片划分到不同类别中。
在这里,该模型会将商品图片分为“好”或“坏”两类。使用基于 ImageNet 的预训练权重可以加速收敛,并复用从数百万自然图片中学到的特征,然后将最后一层全连接层替换为输出两个类别(“GOOD” 与 “BAD”)。
在训练循环中,CrossEntropyLoss 用于衡量分类误差,而 Adam 优化器负责更新模型权重。每个 epoch 遍历所有批次,执行前向传播、计算损失、反向传播及权重更新。
运行该代码块后,你将看到类似如下输出: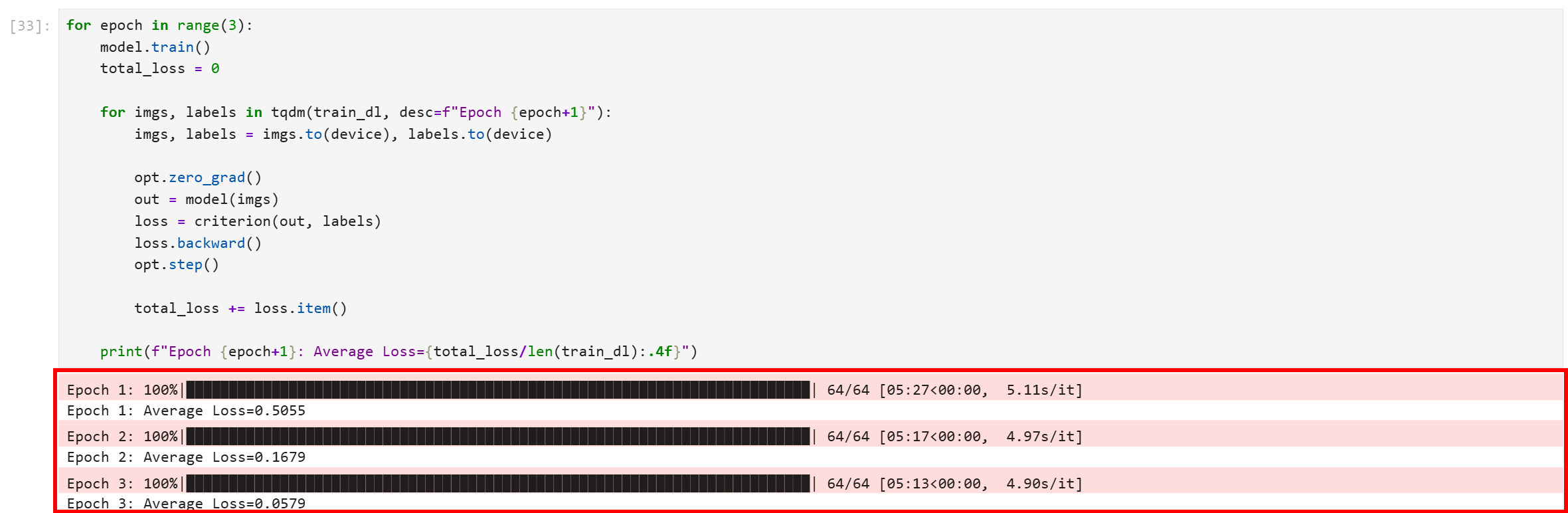
可见所有三个 epoch 都已成功完成。最终的平均损失约为 0.0579,这个数值非常低,表明模型已良好收敛,并且能够高置信度地区分训练数据中的图片。
至此你已经完成了一个用于电商图片质量区分的 CNN 微调过程。
步骤九:评估模型表现
为了验证模型性能,请运行如下评估步骤:
# Load the evaluation version of the model
model.eval()
# To keep track of the processed images
correct = 0
total = 0
# Evaluating the model against the train dataset
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# Output the results
print("Test Accuracy:", correct / total)这一步用于衡量微调后的模型在未见过的数据(测试集)上的泛化能力,本质上是在进行推理阶段的模型评估。
上述代码首先将模型切换到评估模式,并禁用梯度计算以加速推理并保证行为一致。随后在循环中遍历测试集,将模型输出与真实标签进行比较,并最终计算整体准确率,给出模型在训练集之外的数据上的表现指标。
结果可能类似这样:

约为 0.924XXX 的测试准确率意味着,微调后的 ResNet-18 模型在未见测试集上,有超过 92.4% 的商品图片被正确分类为 “GOOD” 或 “BAD”。
对于真实世界的电商商品图片二分类任务而言,这是一个非常优秀的结果,也充分说明模型确实学会了区分好图与差图的关键特征,而不仅仅是在记忆训练数据。
很好!接下来我们将把这个微调后的模型应用到两张完全新图片上检验其效果。
步骤十:使用 ML 模型预测图片质量
要真正验证微调模型的有效性,必须在完全未见过的图片上进行测试。由于模型是针对任意电商商品图片进行训练的,你可以用 eBay、Walmart、Alibaba 或你自己的内部商品库中的图片进行测试。
在本示例中,我们将使用以下两张来自 eBay 的商品图片进行测试:
为此,在单独的代码块中加入如下代码:
def predict_image_quality(img: Image.Image) -> str:
# Set model to evaluation mode
model.eval()
# Apply transformations and add a batch dimension
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# Forward pass, get the predicted class index, and extract it as a scalar
prediction = model(x).argmax().item()
# Return the result string
return "GOOD" if prediction == 1 else "BAD"
# Test images
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# Loop through image URLs, download, predict, and display
for image_url in image_urls:
# Download the image content using HTTP request
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# Call the prediction function
quality = predict_image_quality(image)
# Display the image in the notebook together with the model results
display(image)
print(image_url, "→", quality)执行该代码块后,你将看到如下分类结果:
可以看到模型将第一张图片分类为 “BAD”。这一结果是合理的,因为图片整体质量偏低、较为模糊,背景对比度不够,无法很好地突出商品。
对于第二张图片,模型输出如下:
这一次,分类结果为 “GOOD”。从图片效果来看,这也是可信的判断:图像清晰、光线充足、构图良好,并清楚展示了商品。
如此一来,借助 Bright Data 丰富的数据集,你先获取了电商商品数据(此处来自 Amazon),再使用 PyTorch 在 Python Notebook 中采用多模态数据分析方法,对 CNN 模型进行了图片识别微调。
结语
在本文中,你学习了如何构建一个多模态机器学习系统。我们使用了包含数亿条 Amazon 商品及其对应图片的数据集。
将这些数据输入到 PyTorch 工作流中并在 Python Notebook 里操作后,你成功地微调了一个 CNN(卷积神经网络),用于将电商商品图片划分为“好”或“坏”。
这一项目能够直接满足中小企业乃至大型企业的需求,帮助它们快速评估商品展示图片的质量,尤其适用于电商场景。
而这一切离不开 Bright Data 的企业级数据服务,它可以帮助你从 100 多个域名采集数据,包括 Amazon、Walmart、LinkedIn、Zillow、Airbnb、Yahoo Finance 等等。
立即注册 Bright Data 账号,免费试用我们的数据解决方案吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



