

要让模型真正理解你的业务领域,往往需要的不仅是提示工程或检索增强生成(RAG)。公开可用的模型很强大,但可能缺乏最新知识或不符合你的场景“口味”。有了从网络获取的文章、文档、商品列表与视频转录等数据,这个差距可以通过微调来弥合。
在这篇文章中你将学到:
- 如何使用 Bright Data 的爬取工具与数据集来收集和准备领域数据。
- 如何用收集到的数据微调一个开源的 GPT 模型。
- 如何评估并将微调后的模型部署到真实任务中。
让我们开始吧!
什么是微调
通俗地说,微调是将一个已在大型通用数据集上预训练过的模型,进一步适配到一个新的(通常更具体的)数据集或任务上的过程。做微调时,本质上是修改模型的权重,而不是从零开始训练。改变权重使模型的行为发生变化,从而朝着你期望的方式工作。
网络数据适合用于微调,因为它具备:
- 新鲜度:持续更新,能捕捉最新趋势、事件与技术。
- 多样性:可访问不同写作风格、来源与观点,减少来源狭窄数据集带来的偏差。
微调流程如下图所示:
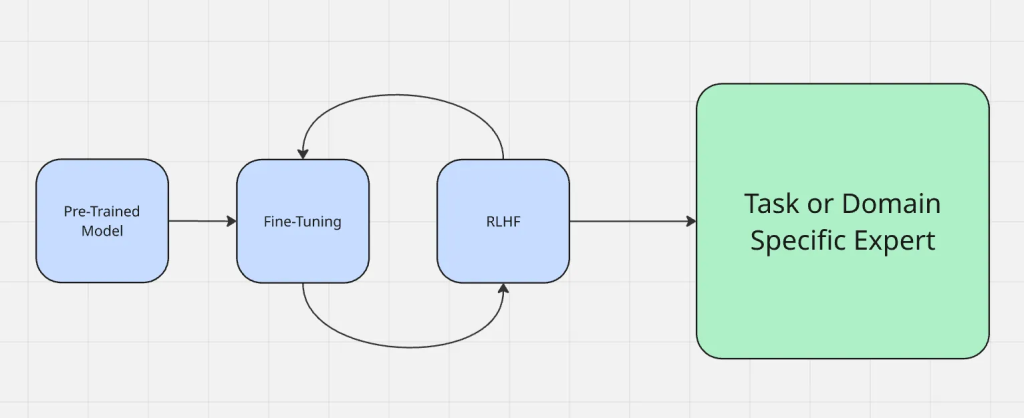
微调不同于其他常见的适配方法,如提示工程与检索增强生成。提示工程只是改变你向模型提问的方式,并不改变模型本身。RAG 则是在运行时添加外部知识,就像给出新的上下文。相反,微调直接更新模型参数,使其无需每次额外提供上下文也能更可靠地给出领域精确的输出。
与检索增强生成(RAG)在运行时以外部上下文增强模型不同,微调会适配模型本体。若想更深入了解权衡,请查看RAG vs 微调。
为何用网络数据进行微调
网络数据形态丰富且与时俱进(文章、商品列表、论坛帖子、视频转录,甚至由视频生成的文本),具备静态或合成数据集难以匹敌的优势。这种多样性帮助模型更有效地处理不同输入类型。
以下是网络数据表现突出的几类场景:
- 社交媒体数据:来自社交平台的标记有助于模型理解非正式语言、俚语与实时趋势,对情感分析或聊天机器人等应用至关重要。
- 结构化数据集:来自商品目录、财报等结构化来源的标记可带来精确的领域理解,对推荐系统或金融预测尤为关键。
- 垂直领域:初创公司与专业应用可受益于与其用例相关的数据集标记,例如法律科技的法律文书或医疗 AI 的医学期刊。
网络数据带来自然多样性与上下文,提高微调模型的真实性与鲁棒性。
数据采集策略
大规模爬虫与数据集提供方(如 Bright Data)可以让你快速稳定地收集海量网页内容,从而在无需耗费数月人工的情况下构建领域数据集。
Bright Data 构建了业内最为多元与可靠的网络数据采集基础设施,由多种网络出口与来源组成。网络数据并不限于纯文本。Bright Data 还能采集多模态输入,如元数据、商品属性与视频转录,帮助模型学习更丰富的上下文。
不建议直接使用原始抓取数据,因为其中几乎总是包含噪声、无关内容或格式伪影。过滤、去重与结构化清洗是关键步骤,确保训练数据集提升性能而非引入混淆。
为微调准备网络数据
- 将原始抓取数据转为结构化的输入/输出对。未处理的数据很少能直接用于训练。首先要将数据转换为结构化的输入/输出对。例如,一篇关于微调的文档可整理为提示“什么是微调?”并以原始答案作为目标输出。此类结构能确保模型从清晰的示例中学习,而非散乱文本。
- 处理多种格式:JSON、CSV、转录、网页。网络数据通常来自多种格式:API 的 JSON、CSV 导出、原始 HTML,或视频的转录文本。将其标准化为统一格式(如 JSONL)便于管理并接入训练流水线。
- 为高效训练进行数据打包。为提升训练效果与过程效率,常将多个较短示例“拼接”到单个序列,以减少 token 浪费并在微调期间优化 GPU 内存利用。
- 平衡领域数据与通用网络数据。找到平衡很重要。单一领域数据过多会让模型变得狭窄且浅显,而通用数据过多则可能稀释目标领域知识。最佳结果通常来自“强基座通用数据 + 精心挑选的领域示例”的混合。
选择基座模型
选择合适的基座模型会直接影响微调系统的效果。不存在通用万能解,尤其是在同一模型家族内部也有多种选择。根据你的数据类型、期望结果与预算,不同模型适配度各异。
选择入门模型时可按以下清单思考:
- 你的模型需要支持哪些模态?
- 输入与输出数据有多大?
- 你要解决的任务有多复杂?
- 性能与预算哪个更重要?
- AI 助手的安全性对你的用例有多关键?
- 公司是否已与 Azure 或 GCP 有合作安排?
例如,如果要处理超长视频或文本(数小时或数十万字),Gemini 1.5 Pro 可能是最优选择,提供最高 100 万 token 的上下文窗口。
多款开源模型是进行网络数据微调的有力候选,包括 Gemma 3、Llama 3.1、Mistral 7B 或 Falcon 系列。小参数版本适合大多数微调项目;当你的领域需要高覆盖与高精度时,大模型会更出色。你也可以查看这份指南了解如何适配 Gemma 3 进行微调。
使用 Bright Data 进行微调
为展示网络数据如何驱动微调,我们以 Bright Data 为数据来源做一个示例。在该示例中,我们将使用 Bright Data 的Scraper API从亚马逊收集商品信息,然后在 Hugging Face 上微调 Llama 4 模型。
步骤一:收集数据集
使用 Bright Data 的 Web Scraper API,你只需几行 Python 代码就能获取结构化商品数据(标题、商品、描述、评论等)。
本步骤的目标是创建一个小项目:
- 激活 Python 虚拟环境
- 调用 Bright Data 的 Web Scraper API
- 将结果保存到 amazon-data.json
先决条件
- Python 3.10+
- 一个 Bright Data API token
- 一个 Bright Data 采集器 ID(在 Bright Data 控制台)/cp/scrapers
- 一个 OPENAI_API_KEY(因为我们将微调 GPT-4 模型)。
创建项目文件夹
mkdir web-scraper && cd web-scrapper创建并激活虚拟环境
激活虚拟环境,终端提示前应出现(venv)。
//macOS/Linux (bash or zsh):
python3 -m venv venv
source venv/bin/activate
Windows
python -m venv venv
.venvScriptsActivate.ps1安装依赖
用于发起 HTTP 请求的库
pip install requests完成后,你就可以使用 Bright Data 的 Scraper APIs 抓取所需数据了。
定义爬取逻辑
以下代码会触发你的 Bright Data 采集器(如亚马逊商品),轮询直至抓取完成,并将结果保存为本地 JSON 文件。
请将 API key 替换到相应位置。
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "your_api_key"
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")运行代码
python3 web_scraper.py你将会看到:
- 打印出的快照 ID
- 抓取完成
- 保存为 amazon-data.json(…items)
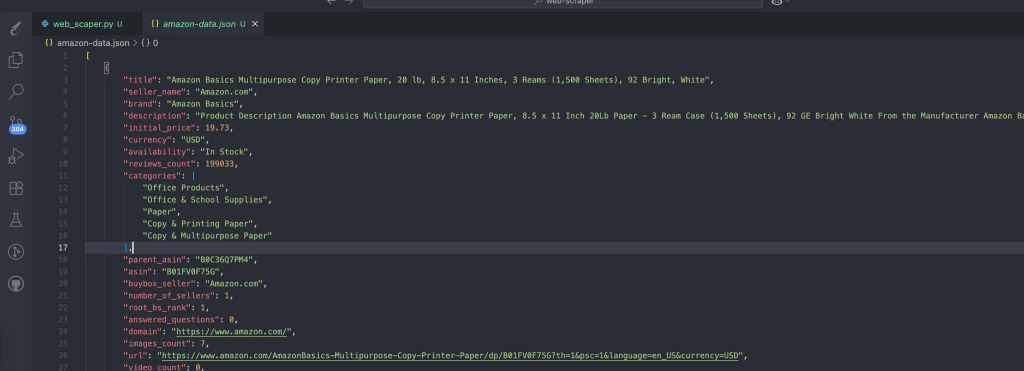
该流程会自动生成包含我们抓取数据的数据文件。预期数据结构如下:
步骤二:将 JSON 转为训练对
在项目根目录创建 prepare_pair.py,用以下代码将数据整理为 JSONL 格式,方便微调步骤使用。
import json, random, os
INPUT = "amazon-data.json"
OUTPUT = "pairs.jsonl"
SYSTEM = "You are an expert copywriter. Generate concise, accurate product descriptions."
def make_example(item):
title = item.get("title") or item.get("name") or "Unknown product"
brand = item.get("brand") or "Unknown brand"
features = item.get("features") or item.get("bullets") or []
features_str = ", ".join(features) if isinstance(features, list) else str(features)
target = item.get("description") or item.get("about") or ""
user = f"Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:"
assistant = target.strip()[:1200] # keep it tight
return {"system": SYSTEM, "user": user, "assistant": assistant}
def main():
if not os.path.exists(INPUT):
raise SystemExit(f"Missing {INPUT}")
data = json.load(open(INPUT, "r", encoding="utf-8"))
pairs = [make_example(x) for x in data if isinstance(x, dict)]
random.shuffle(pairs)
with open(OUTPUT, "w", encoding="utf-8") as out:
for ex in pairs:
out.write(json.dumps(ex, ensure_ascii=False) + "n")
print(f"Wrote {len(pairs)} examples to {OUTPUT}")
if __name__ == "__main__":
main()运行以下命令:
python3 prepare_pairs.py文件中应得到如下输出:
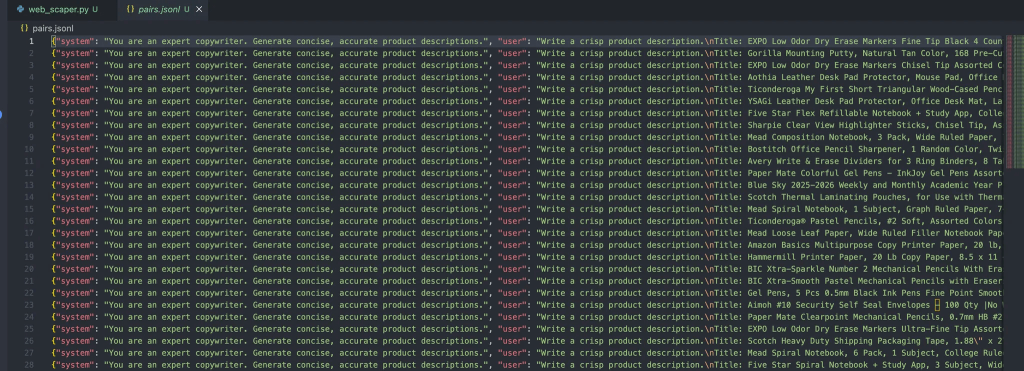
每个对象包含三种角色:
- System:为助手提供初始上下文。
- User:用户输入。
- Assistant:助手回复。
步骤三:上传文件用于微调
文件准备好后,按以下步骤对接到 OpenAI 的微调流程:
安装 OpenAI 依赖
pip install openai创建 upload.py 上传数据集
该脚本会读取我们已有的 pairs.jsonl 文件
from openai import OpenAI
client = OpenAI(api_key="your_api_key_here")
with open("pairs.jsonl", "rb") as f:
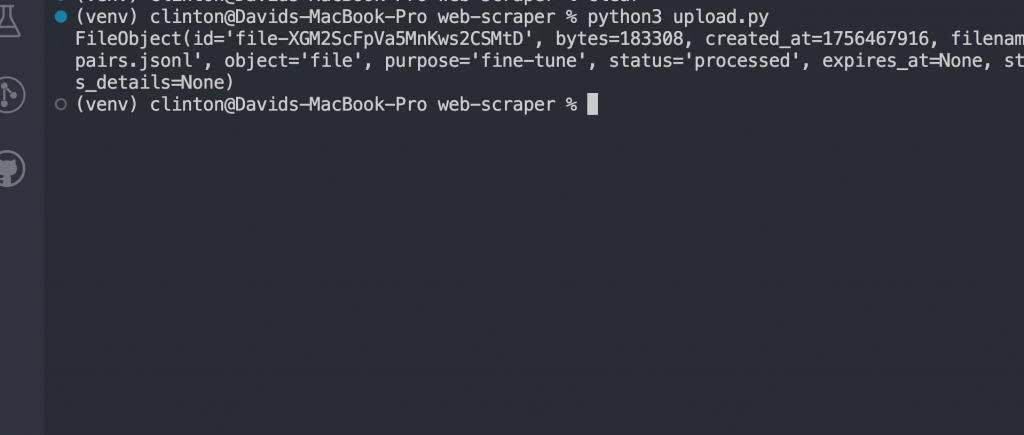
uploaded = client.files.create(file=f, purpose="fine-tune")运行:
python3 upload.py你应能看到类似如下的响应:
微调模型
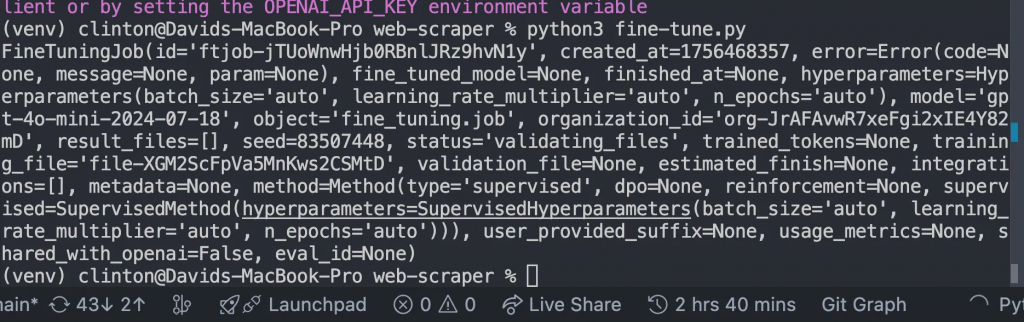
创建 fine-tune.py,用上一步返回的文件 ID 替换 FILE_ID,然后运行:
from openai import OpenAI
client = OpenAI()
# replace with your uploaded file id
FILE_ID = "file-xxxxxx"
job = client.fine_tuning.jobs.create(
training_file=FILE_ID,
model="gpt-4o-mini-2024-07-18"
)
print(job)这将返回类似如下的响应:
监控直到训练完成
启动微调任务后,模型需要时间在你的数据集上训练。具体时长取决于数据规模,可能从几分钟到数小时不等。
不要盲等;创建并运行 monitor.py:
from openai import OpenAI
client = OpenAI()
jobs = client.fine_tuning.jobs.list(limit=1)
print(jobs)然后在终端运行 python3 manage.py,你将看到如下信息:
- 训练是否成功或失败。
- 训练了多少 tokens。
- 新微调模型的 ID。
仅当 status 字段为
"succeeded"时再继续下一步。
与微调后的模型对话
任务完成后,你就拥有了自己的定制 GPT 模型。要使用它,打开 chat.py,将 MODEL_ID 替换为微调任务返回的模型 ID,然后运行:
from openai import OpenAI
client = OpenAI()
# replace with your fine-tuned model id
MODEL_ID = "ft:gpt-4o-mini-2024-07-18:your-org::custom123"
while True:
user_input = input("User: ")
if user_input.lower() in ["quit", "q"]:
break
response = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "You are a helpful assistant fine-tuned on domain data."},
{"role": "user", "content": user_input}
]
)
print("Assistant:", response.choices[0].message.content)这一步可以验证微调是否奏效。你将不再使用通用基座模型,而是在与一个专门基于你的数据训练过的模型对话。
此时你就能看到微调带来的实际效果。
你可以期待类似如下的结果:
--- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data ---
PROMPT for item: ErgoPro-EL100
GENERATED (Fine-tuned):
**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**
Experience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.
The breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.
Built to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simply
--------------------------------------------------
PROMPT for item: HeightRise-FD20
GENERATED (Fine-tuned):
**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**
Take your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.
**Experience the Benefits of Standing**
The HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.
**Durable and Reliable**
With a sturdy construction and non-slip rubber feet
--------------------------------------------------结论
在网页规模上进行微调时,需要对约束与流程保持现实预期:
- 资源需求:在大而多样的数据集上训练需要算力与存储。若处于试验阶段,先用小样本数据再逐步扩大。
- 逐步迭代:不要一开始就投入数百万条记录;先用小数据集优化流程,再据结果查漏补缺、修正预处理管线。
- 部署流程:像管理软件制品一样管理微调模型。进行版本管理,尽量接入 CI/CD,并保留回滚选项以防新模型表现不佳。
好在,Bright Data 提供了丰富的AI 就绪服务,助你获取或生成数据集:
- 抓取浏览器:兼容 Playwright、Selenium、Puppeteer,内置解锁能力的浏览器。
- 网络抓取 APIs:预配置 API,可从 100+ 主流站点提取结构化数据。
- 网络解锁器:一体化 API,处理具备反爬机制网站的解锁。
- 搜索引擎 API:专用于解锁搜索引擎结果并提取完整 SERP 数据的 API。
- 基础模型数据:获取合规的网络级数据集,助力预训练、评测与微调。
- 数据提供方:与可信供应商对接,在规模上获取高质量、AI 就绪的数据集。
- 数据包:获取策划好的即用型数据集——结构化、强化并带标注。
利用网络数据微调大语言模型,能够解锁强大的领域专精能力。网络提供了新鲜、多样且多模态的内容——从文章与评论到转录与结构化元数据——这些是单纯依赖策划数据集难以匹敌的。
立即免费创建 Bright Data 账户,试用我们的 AI 就绪数据基础设施!



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





