

在本指南中,您将看到
- 什么是微调?
- 如何通过 n8n 使用网络抓取 API 微调 GPT-4o。
- 微调方法比较
- 为什么高质量数据是任何微调过程的核心?
让我们深入了解一下!
什么是微调?
微调–又称监督微调(SFT)–是一种提高预训练 LLM 中特定知识或能力的程序。就 LLM 而言,预训练是指从头开始训练人工智能模型。
微调非常重要,因为模型会模仿训练数据。这意味着,在训练后测试 LLM 时,它的输出会在某种程度上遵循训练数据。由于 LLM 是通用模型,如果想让它们获得特定知识,就必须根据特定数据对其进行微调。
如果您想了解有关 SFT 的更多信息,请阅读我们的 “LLM 中的监督微调 “指南。
如何利用 Bright Data n8n 集成微调 GPT-4o
正如我们在最近的教程中所介绍的,您现在已经知道如何利用云计算和使用Web Scraper API 抓取的数据对 Llama 4 进行微调。在本指导章节中,您将通过使用 n8n–一个流行的工作流程自动化平台–微调 GPT-4o 来实现同样的效果。
具体来说,我们将参考同一个目标网页,即亚马逊畅销办公产品页面:
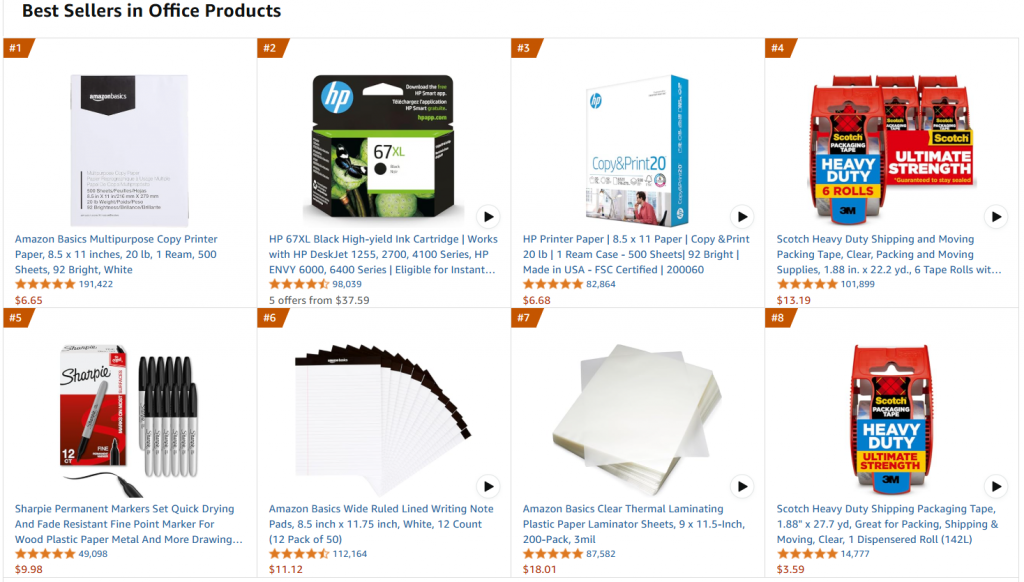
本项目的目标是对GPT-4o-mini进行微调,使其能够根据提示输入的某些特征,创建类似于办公室的产品描述。
请按照以下步骤学习如何使用 n8n 和通过 Bright Data 解决方案获取的训练数据集对 GPT-4o-mini 进行微调!
要求
要重现这一微调过程,您需要具备以下条件:
- 有效的Bright Data API 令牌。
- 一个激活的n8n 帐户。
- OpenAI API 令牌。
太好了!您可以开始微调 GPT-4o 了。
步骤 #1:创建新的 n8n 工作流程并安装 Bright Data 节点
登录 n8n 后,仪表板如下图所示:
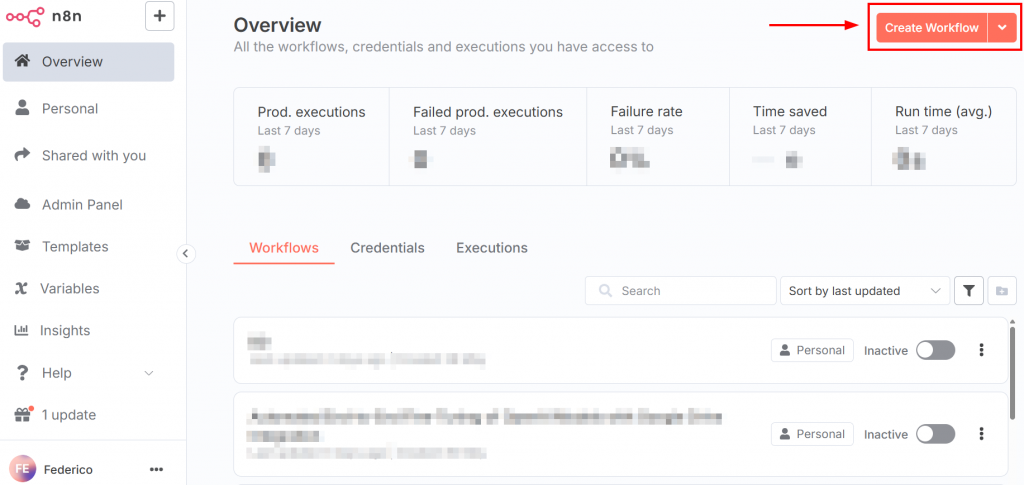
要创建新的工作流程,请单击 “创建工作流程 “按钮。然后点击 “打开节点面板”:
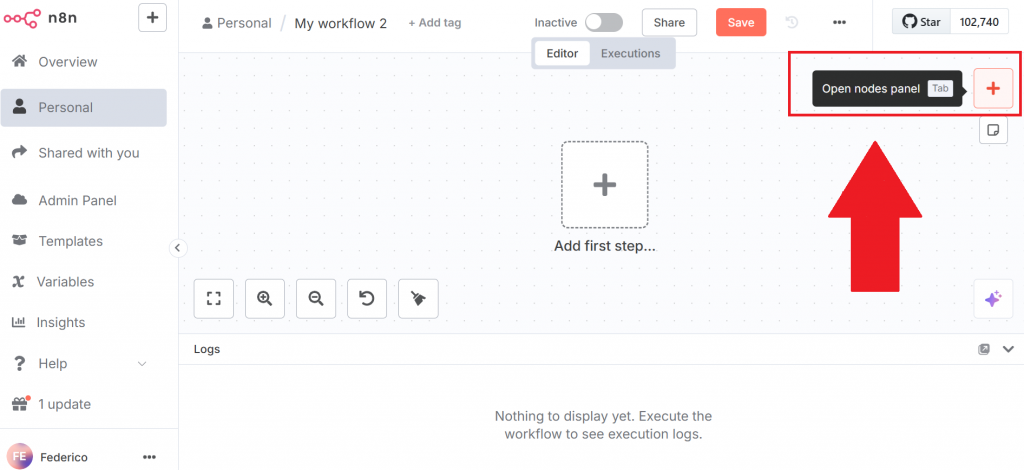
在节点面板中,搜索 Bright Data 的节点。在 n8n 中,”节点 “是自动化工作流程的一个构件,代表数据处理管道中的一个独特步骤或操作。
点击 Bright Data n8n 节点进行安装:
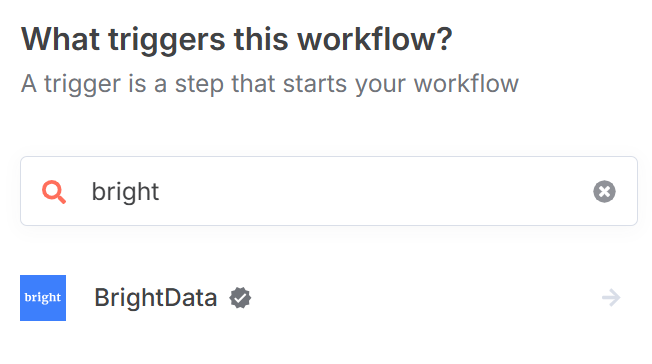
如需了解更多信息,请参阅有关如何在 n8n 中设置 Bright Data 的官方文档页面。
很好!你初始化了第一个 n8n 工作流程。
步骤 #2:设置亮数据节点并抓取数据
点击用户界面中的 “添加第一步”,然后选择 “手动触发”:
该节点允许您手动触发整个工作流程。
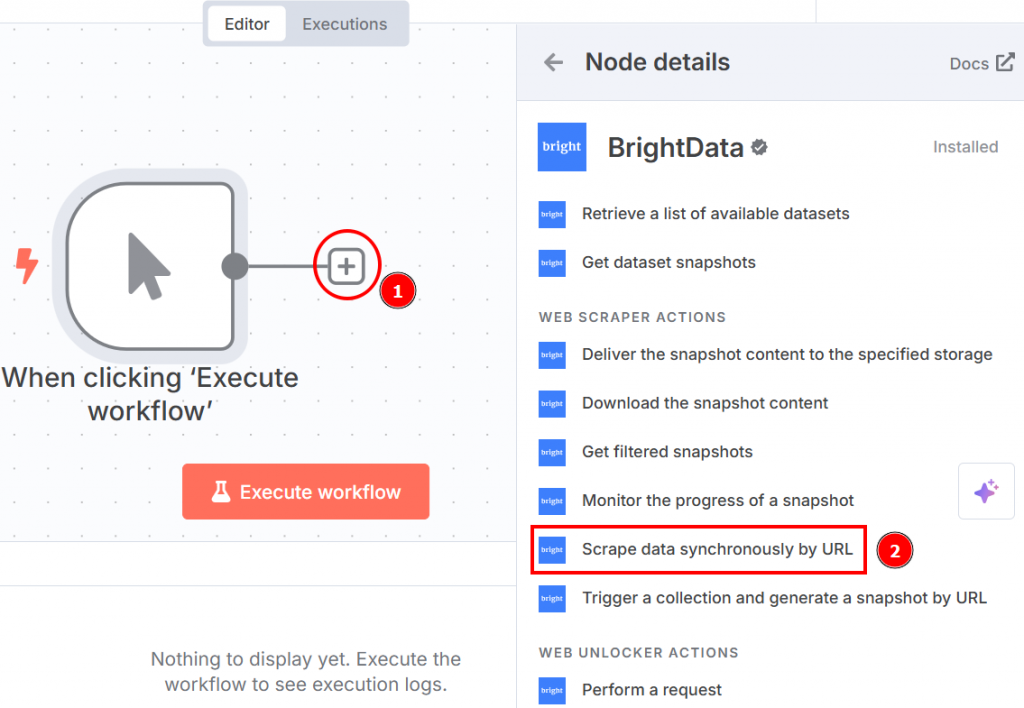
点击手动触发器节点右侧的 “+”,搜索 Bright Data。在 “网络抓取器操作 “部分,点击 “通过 URL 同步抓取数据”:
下面是点击节点时节点设置的显示方式:
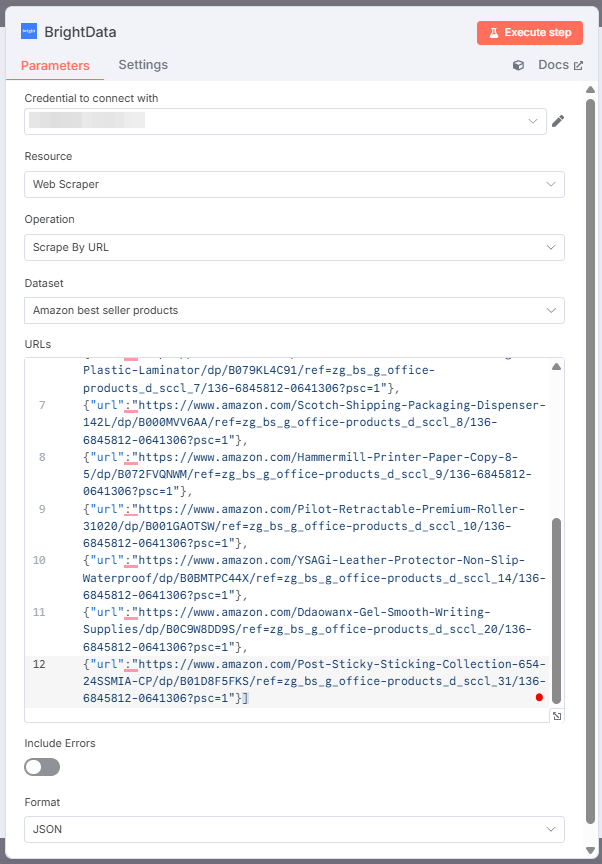
设置如下
- “连接凭证”:点击它并添加您的 Bright Data API 令牌。凭据将被保存。
- “操作”:选择 “按 URL 抓取 “选项。这样就可以传递 URL 列表,Web Scraper API 将把这些 URL 作为提取数据的目标页面。
- “数据集”:选择 “亚马逊畅销产品 “选项。这是从亚马逊畅销产品中提取数据的优化方法。
- “网址”:访问亚马逊畅销办公产品页面,复制并粘贴至少 10 个 URL 的列表。您需要至少 10 个 URL,因为 OpenAI 聊天节点需要至少 10 个 URL。如果少于 10 个,OpenAI 节点将在微调目标 LLM 时返回错误信息。
- “格式”:选择 “JSON “数据格式,因为 Web Scraper API 支持多种输出格式。
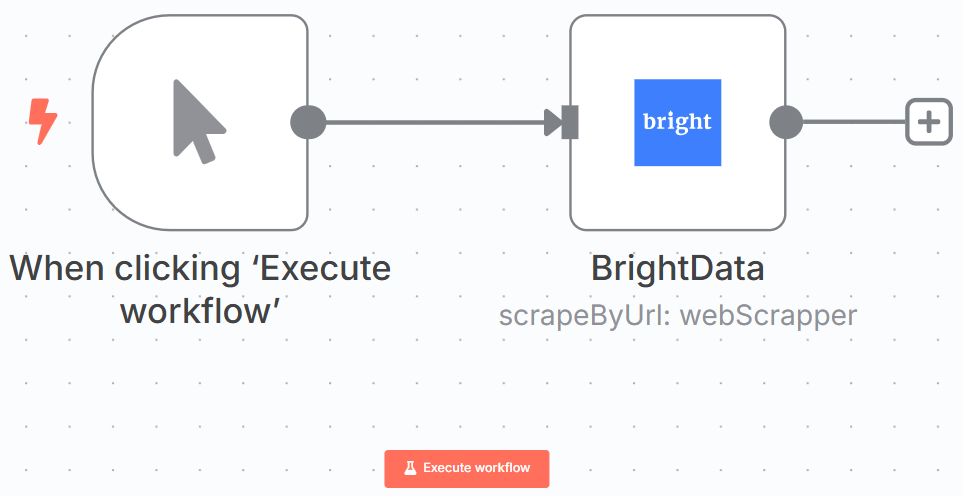
以下是您目前的工作流程:
如果按下 “执行工作流程 “按钮,抓取的数据将出现在输出部分的 Bright Data 节点中:
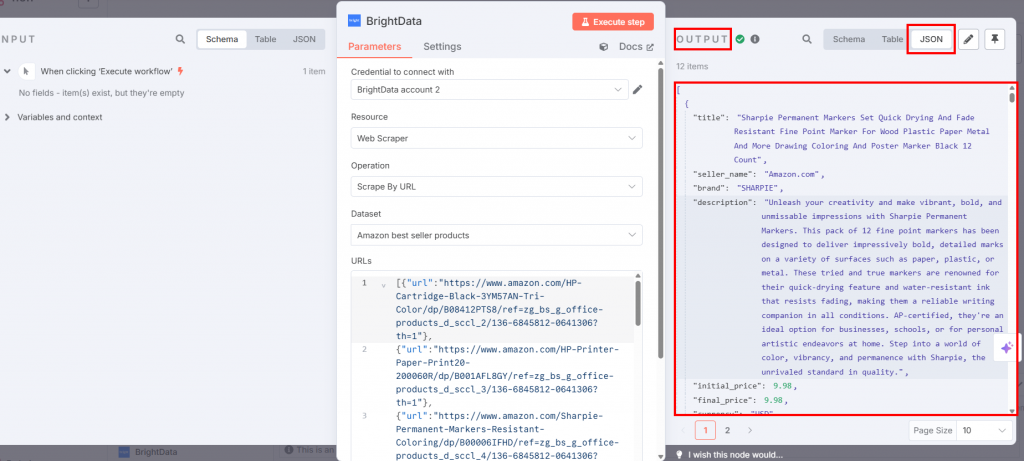
太棒了!您使用 Bright Data 的 Web Scraper API 无需编写任何代码就能获取所需的目标数据。
步骤 #3:设置代码节点
连接 “亮数据 “节点的 “代码“节点,在 “语言 “框中选择 JavaScript:
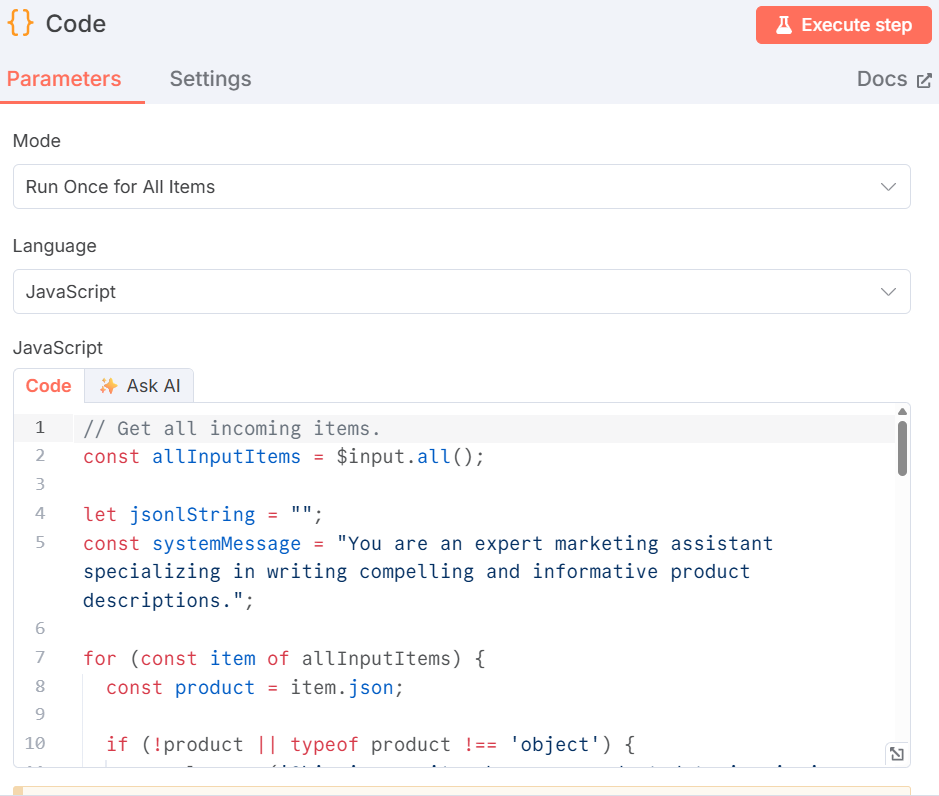
在 “JavaScript “字段中,粘贴以下代码:
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];该节点的输入是 JSON 文件,其中包含从 Bright Data 抓取的数据。不过,OpenAI 节点需要一个 JSONL 文件。JavaScript 代码将 JSON 转换为 JSONL,具体如下:
- 它使用
$input.all()方法检索来自前一个节点的所有数据。 - 它对产品进行迭代和处理。特别是,对于每个产品项目,它都会
- 提取产品详细信息,如
标题、品牌、功能、描述、评级和可用性。如果缺少某些数据,它还会包含后备值。 - 将这些详细信息格式化为请求 LLM 生成产品描述的格式,从而构建一个
userPrompt。 - 使用包含产品属性的模板生成
理想描述(idealDescription)。这将成为训练数据中理想的 “助手 “回复。 - 将系统消息、
用户提示和理想描述合并为一个trainingExample对象,格式为对话式 LLM 培训。 - 将此
trainingExample序列化为 JSON 字符串,并将其追加到一个不断增长的字符串中,每个 JSON 对象位于新的一行(JSONL 格式)。
- 提取产品详细信息,如
- 处理完所有项目后,它会将累积的 JSONL 字符串转换为二进制数据
缓冲区。 - 它会返回名为
data.jsonl的文件。
如果点击代码节点中的 “执行步骤”,JSONL 将出现在输出部分:
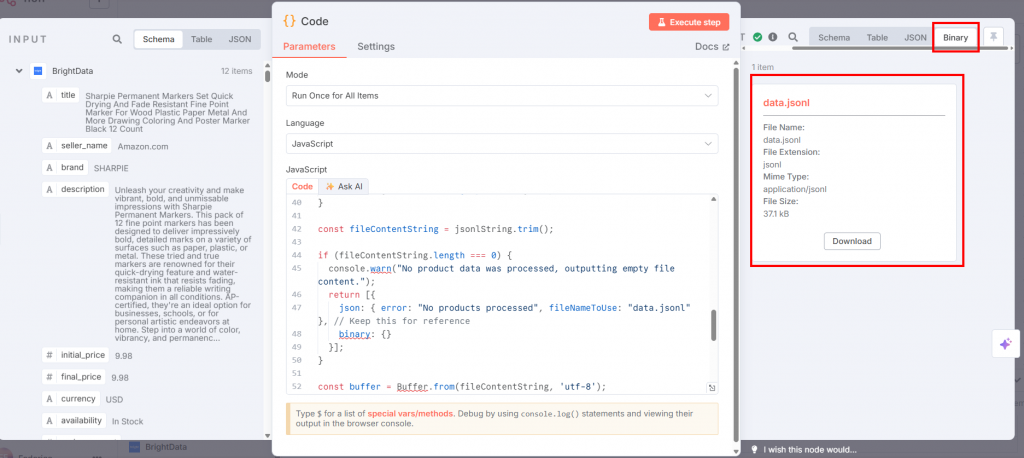
以下是您目前的工作流程:
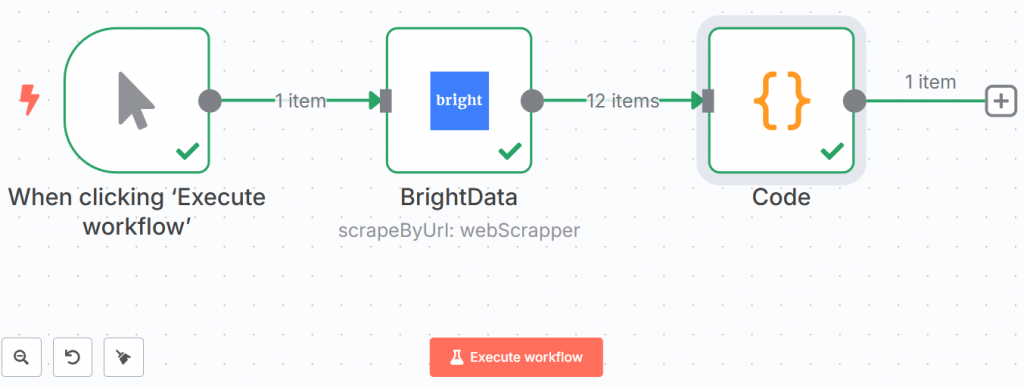
绿线和”√”表示每个步骤都已成功完成。
太好了!您使用 Bright Data 获取了数据,并将其保存为 JSONL 格式。现在,您可以将其推送到 LLM 中了。
步骤 #4:将微调数据推送至 OpenAI 聊天节点
微调 JSONL 文件已准备就绪,可以上传到 OpenAI 平台进行微调。为此,请添加一个 OpenAI 节点。在 “文件操作 “部分选择 “上传文件”:
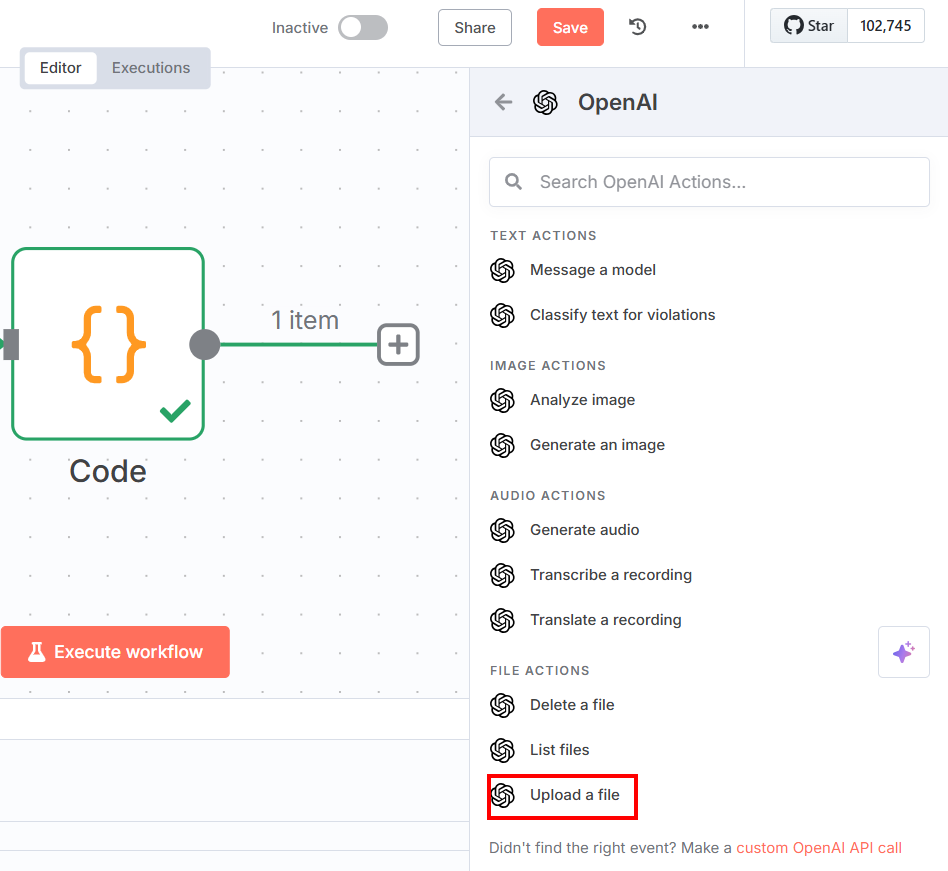
以下是您需要配置的设置:
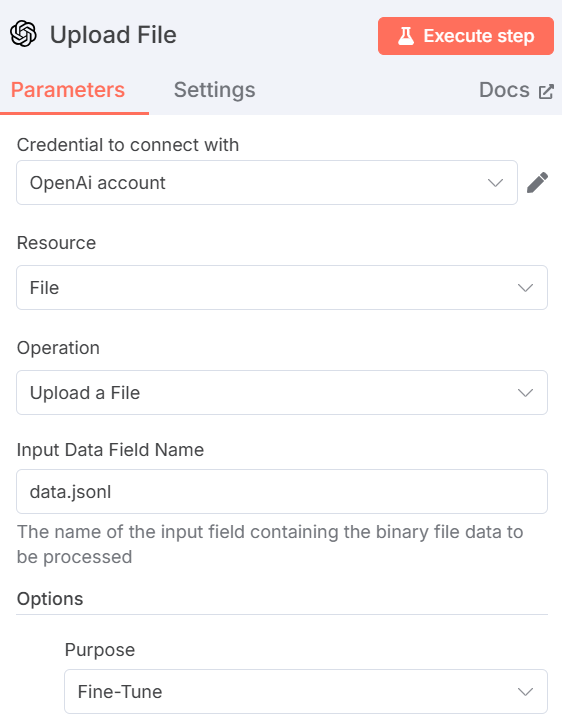
上述节点为微调过程提供了输入。设置参数如下
- “连接凭证”:添加您的 OpenAI API 令牌。设置完成后,凭据将被保存。
- “资源”:选择 “文件”。这是因为您将上传一个 JSONL 文件到平台。
- “操作”:选择 “上传文件”。
- “输入数据字段名”:微调文件的名称是
data.jsonl。 - 在 “选项 “部分,添加 “目的 “并选择 “微调”。
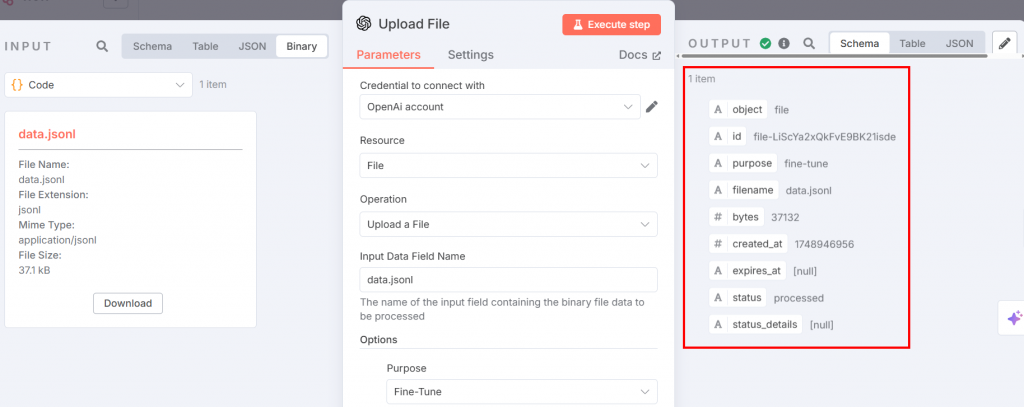
执行该步骤后,输出结果如下:
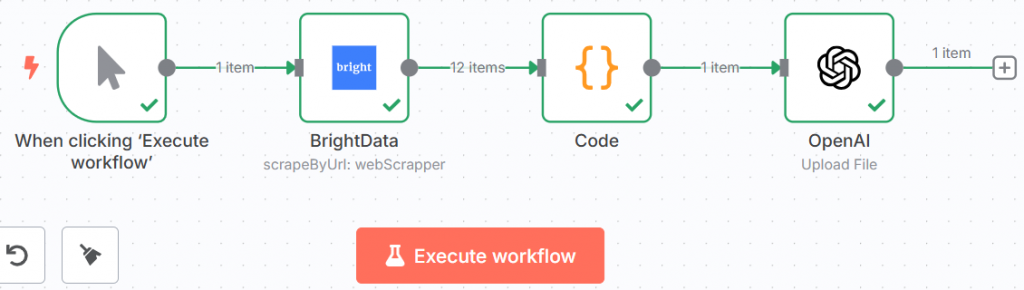
现在,您的工作流程将是这样的:
太神奇了你为微调过程准备好了一切。是时候进行实际操作了。
步骤 #5:微调 LLM
为了进行实际微调,请将HTTP 请求节点连接到 OpenAI节点:
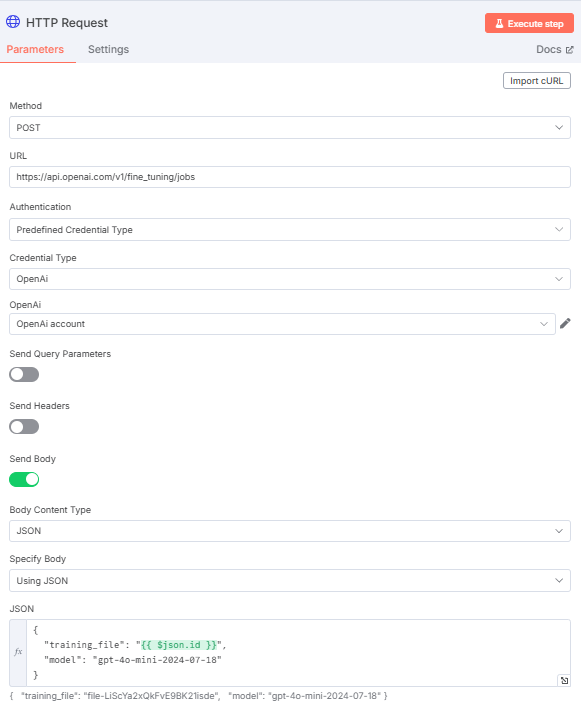
设置必须如下:
- 方法 “必须是 “POST”,因为您上传的是训练数据文件。
- URL “字段必须为
https://api.openai.com/v1/fine_tuning/jobsendpoint。这是 OpenAI 平台上微调作业的标准 URL。 - 在 “身份验证 “字段中,选择 “预定义凭证类型”,以便使用 OpenAI API 令牌。
- 在 “凭证类型 “中,选择 “OpenAi”,这样节点就能连接到 OpenAI。
- 在 “OpenAI “框中,选择您的 OpenAI 账户名。
- 必须启用 “发送正文 “切换。在 “正文内容类型 “和 “指定正文 “字段中分别选择 “JSON “和 “使用 JSON”。
JSON 字段必须包含以下内容:
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} 这个 JSON:
- 用
$json.id指定训练数据的名称。 - 定义用于微调的模型。在本例中,您将使用 2024-07-18 发布的 GPT-4o-mini 版本。
以下是您将收到的输出结果:

当 HTTP 请求节点被触发时,微调过程就开始了。您可以在OpenAI 平台的微调部分看到其进展。当微调过程成功完成后,OpenAI 将为您提供将在步骤 #7 中使用的微调模型:
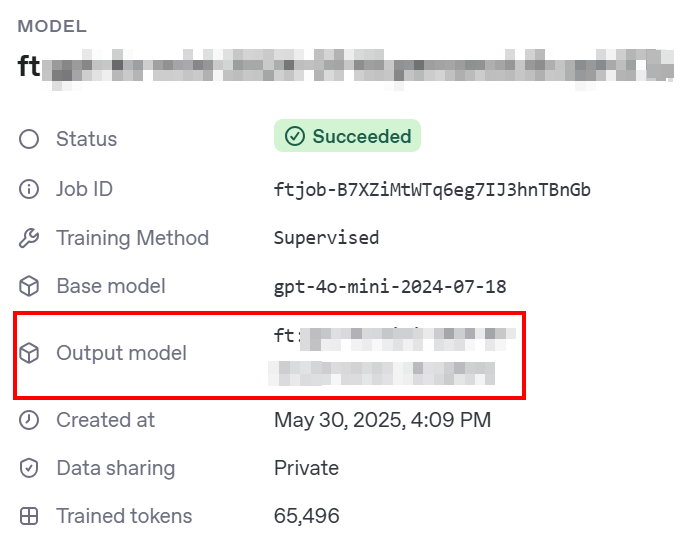
n8n 工作流程现在应如下所示:

祝贺您!您使用 Bright Data 的 Scraper API 通过 n8n 获取的数据训练了第一个 GPT 模型。
这是整个工作流程前半部分的最后一个节点。
步骤 #6:添加聊天节点
整个工作流程的后半部分必须从聊天触发器节点开始。在这里,您将插入测试微调 LLM 的提示:
下面是您可以在聊天中插入的提示:
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.正如您所看到的,这个提示
- 报告在培训阶段使用的 “成为营销专家助理 “这句话。
- 要求根据所需的办公用品信息生成产品描述:
- 标题是
- 品牌
- 办公产品的主要功能。
提示的结构必须如此。因为在这个阶段,模型会模仿训练数据。所以你必须给它一个提示和数据,这些提示和数据要与你在训练阶段使用的相似。然后,经过微调的 LLM 将根据这些因素编写产品描述。
您可以在用户界面底部的聊天部分插入提示:
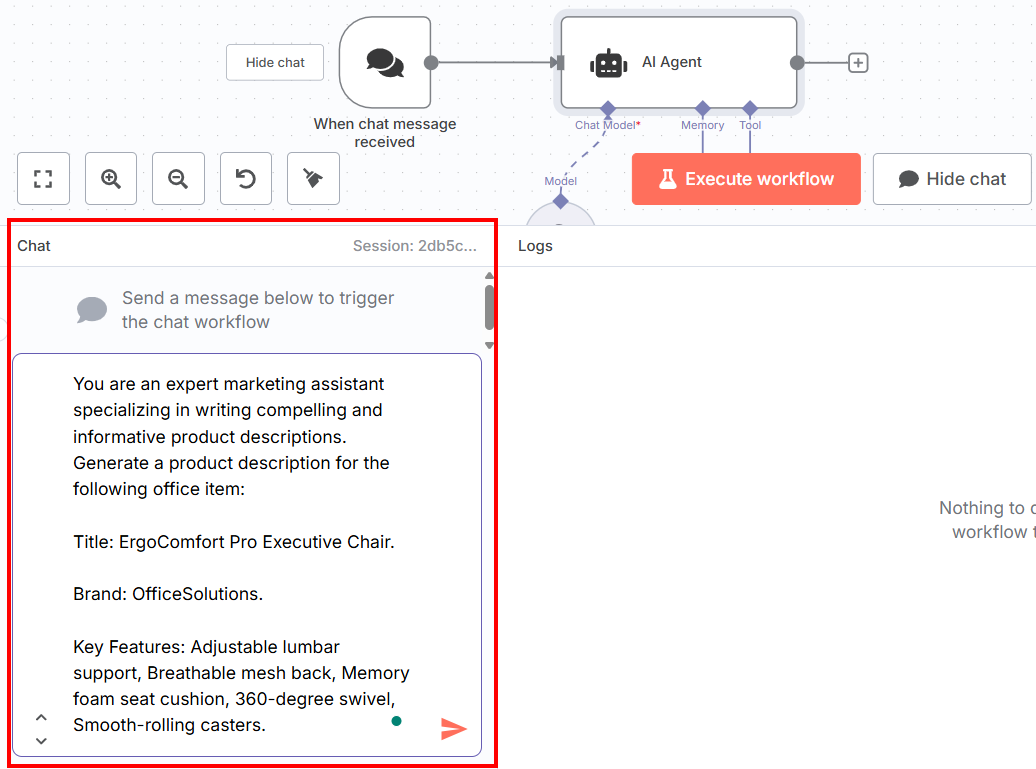
这就是您当前的 n8n 工作流程:
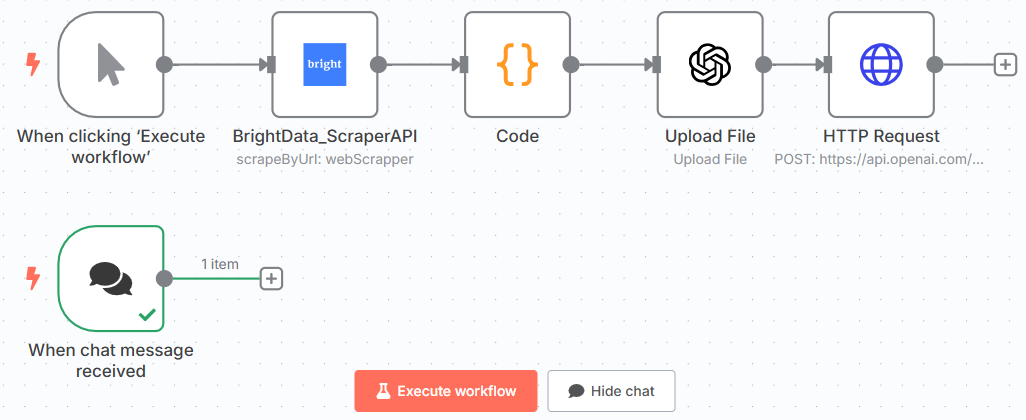
太好了你定义了测试微调模型的提示。
步骤 #7:添加人工智能代理和 OpenAI 聊天节点
现在,您必须将人工智能代理节点连接到聊天触发器:
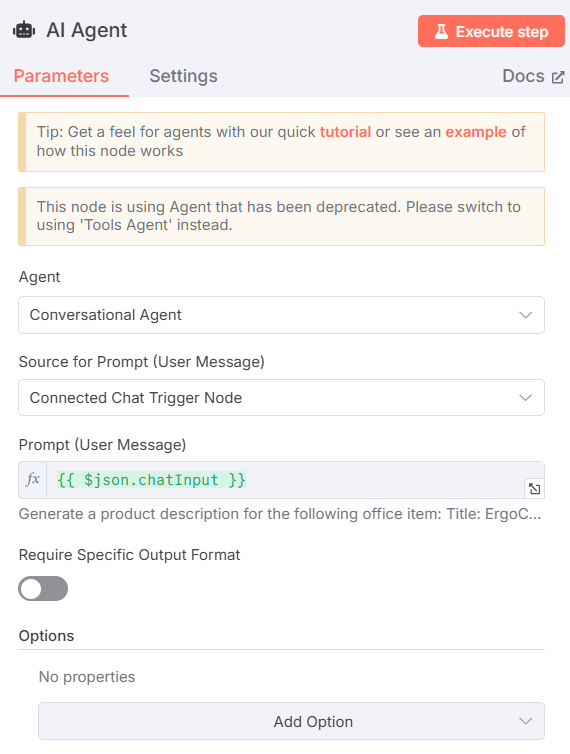
设置必须是
- “特工”选择 “对话代理”。这样就可以使用聊天触发器节点修改任何内容,就像使用其他对话代理一样。
- 将 “提示(用户消息)来源 “设置为 “连接的聊天触发节点”,这样它就能直接从聊天中获取提示。
通过 “聊天模型 “连接选项,将OpenAI 聊天模型节点连接到 AI Agent 节点:
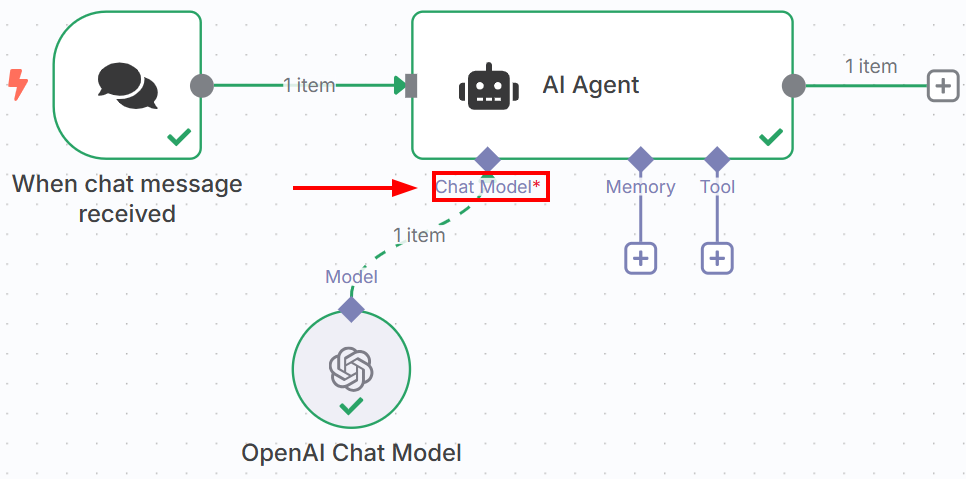
下图显示了 OpenAI 聊天模型节点的设置:
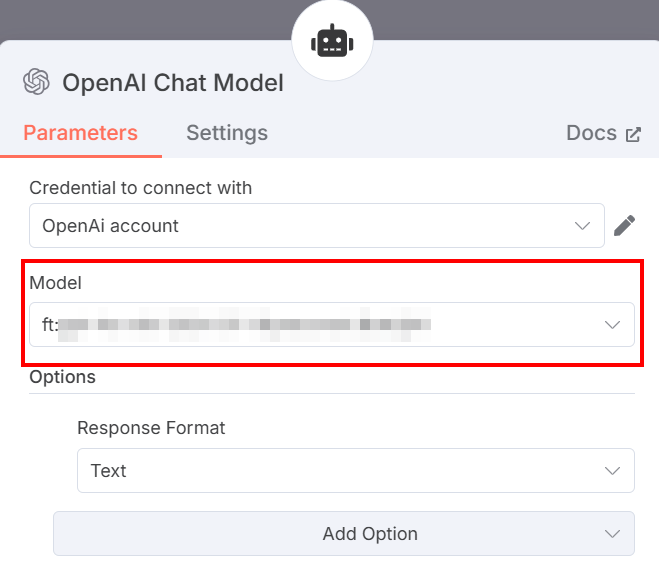
节点配置如下
- “连接凭证”:选择您保存的 OpenAI 凭据。
- “模型”:粘贴OpenAI 平台微调部分的微调输出模型。
返回人工智能代理节点,点击 “执行步骤 “按钮。您将看到最终的产品描述:
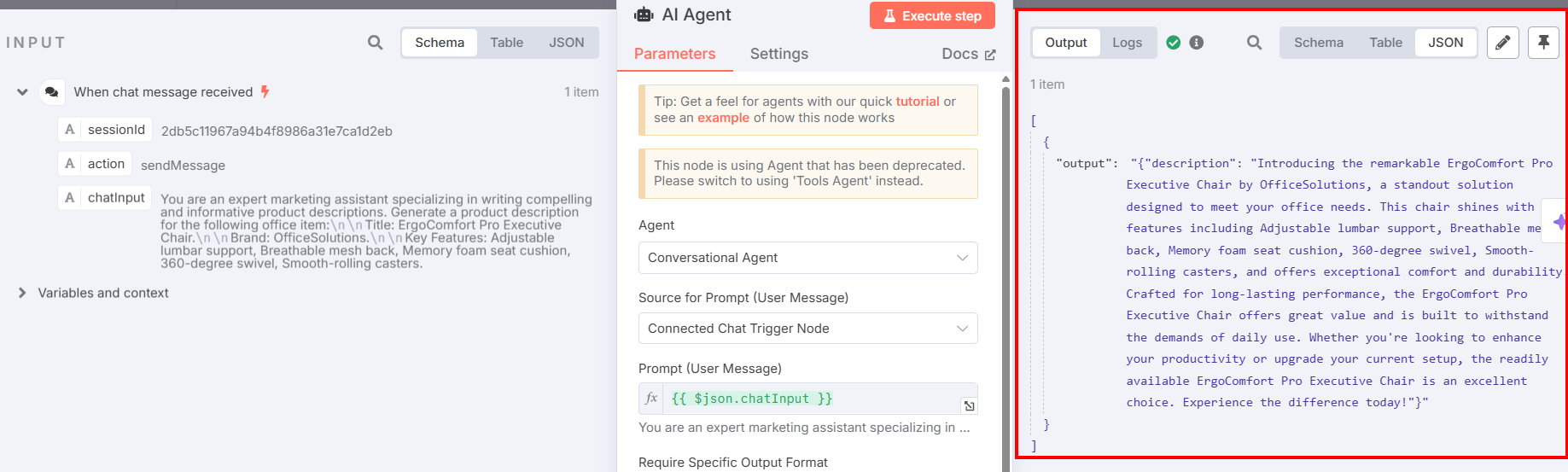
以下是结果的纯文本描述:
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!如您所见,该描述利用了对象的标题名称(”ErgoComfort Pro Executive Chair”)、品牌(”OfficeSolutions”)及其所有功能来生成产品描述。特别要指出的是,描述并不只是罗列输入数据,而是利用这些数据创建一个引人入胜的描述。最后几个短语是关键:
- “ErgoComfort Pro 大班椅具有持久的性能,价值不菲,可满足日常使用需求”。
- “无论您是想提高工作效率,还是想升级现有配置,随时可用的 ErgoComfort Pro 大班椅都是您的最佳选择。今天就来体验它的与众不同吧!”
就是这样!您测试了经过微调的 GPT-4o-mini 模型,该模型生成了产品描述以回答给定的提示(在步骤 #6 中定义)。
步骤 #8:将所有内容整合在一起
最终的 GTP-4o n8n 微调工作流程如下:
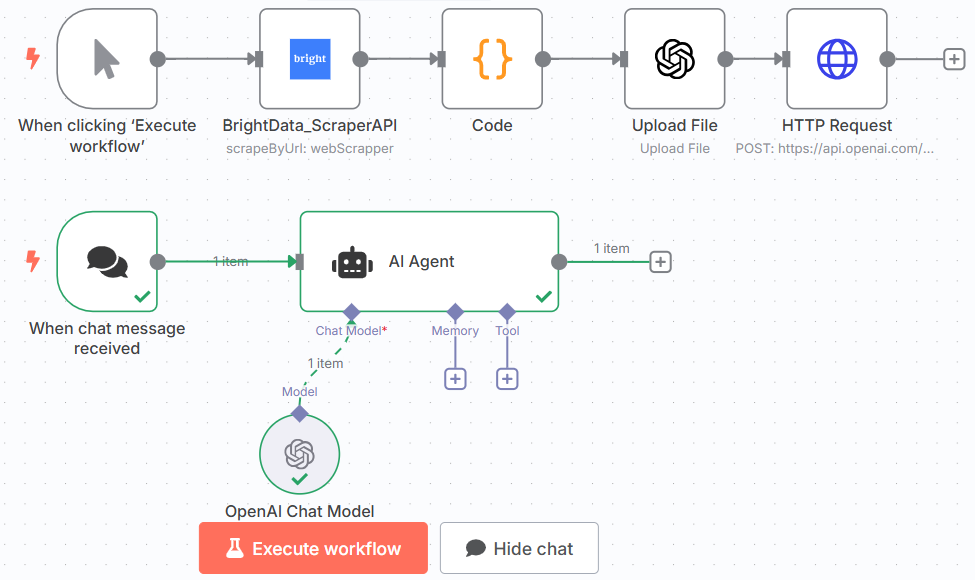
现在工作流程已完全设置完毕,如果点击 “执行工作流程”,它将从头开始重新执行。不过请注意,每一步都会保存结果。这意味着,如果您想尝试不同的提示来测试微调模型,只需将它们写入聊天触发器节点,然后执行该节点和人工智能代理节点即可。
比较微调方法:云基础设施与工作流程自动化
编写本指南有两个原因:
- 教你如何使用 n8n 等工作流程自动化工具微调 LLM
- 将这种微调 LLM 的方法与我们在文章 “利用新鲜网络数据微调 Llama 4 以获得更好的结果“中使用的方法进行比较
是时候比较这两种方法了!
微调方法的比较
我们在上一篇文章中采用的微调 Llama 4 的方法要求:
- 使用云基础设施,这需要时间来建立并产生成本。
- 编写代码,使用 Bright Data 的 Scraper API 获取数据。
- 设置拥抱脸。
- 需要开发一个带有 Python 代码的笔记本来进行微调,这需要时间和技术技能。
您无法估计所需的技术能力。但是,您可以估算出建立整个基础设施所需的全部时间和花费的资金:
- 时间:大约一个工作日。
- 钱:25 美元。花费 25 美元购买云服务后,消费将按小时计算。同时,您需要在开始使用前支付 25 美元。因此,这就是使用云服务的最低价格。
您在本指南中学到的方法要求
- n8n,可免费使用,不需要太多专业技术知识。
- 用于访问 GPT-4o 或其他模型的 OpenAI API 令牌。
- 基本编码技能,特别是为代码节点编写 JavaScript 代码段。
在这种情况下,对技术能力的要求要低得多。如果你无法自己编写 JavaScript 代码段,任何法律硕士都可以轻松创建。除此之外,在整个工作流程中,您不需要编写任何其他代码片段。
在这种情况下,您可以估算出建立基础设施所需的时间和所需的资金如下:
- 时间:约半个工作日。
- 费用:10 美元购买一个 OpenAI API 令牌。即使在这种情况下,您也需要为每次 API 请求付费。不过,您只需支付 10 美元即可开始使用。目前,基本计划的n8n 许可证每月费用为25 美元,如果您选择使用自托管版本,则完全免费。因此,您只需花费大约 10 美元即可开始使用。
您应该选择哪种方法?
| 方面 | 云基础设施方法 | 工作流程自动化方法 |
|---|---|---|
| 技术技能 | 高(需要 Python、云计算和数据检索编码技能) | 低(基本 JavaScript) |
| 设置时间 | 大约一个完整的工作日 | 约半个工作日 |
| 初始成本 | ~云服务最低 25 美元 + 小时费 | ~10 美元购买 OpenAI 应用程序接口令牌 + 24 美元/月的 n8n 许可证或免费托管服务 |
| 灵活性 | 高(适合高级定制和各种用例) | 适中(适合自动化工作流程和低代码定制) |
| 最适合 | 需要强大、灵活基础设施的高技能团队 | 寻求快速设置或编码专业知识有限的团队 |
| 额外福利 | 全面控制微调环境和流程 | 预建模板、低门槛、与其他工作流程集成 |
这两种方法需要的初始投资相似,都是时间和金钱方面的投资。那么,如何在两者之间做出选择呢?以下是一些指导原则:
- n8n:如果您需要自动化其他工作流程,如果您的团队技术水平不高,请选择 n8n 或任何类似的工作流程自动化工具来微调 LLM。这种低代码方法将帮助你实现任何其他工作流程的自动化。只有在需要定制时,才需要编写代码。它还提供可免费使用的预建模板,降低了使用该工具的门槛。
- 云服务:如果您需要对 LLM 进行多种微调,并且拥有一支技术精湛的团队,那么请选择云服务。建立云环境和开发微调笔记本需要高级专业技术。
微调过程的核心:高质量数据
无论您选择哪种方法,Bright Data 始终是这两种方法的关键中间人。原因很简单:高质量的数据是微调过程的基础!
Bright Data为您提供人工智能数据基础设施,提供一系列服务和解决方案,支持您的人工智能应用:
- MCP 服务器:开源 Node.js MCP 服务器,提供 20 多种用于人工智能代理数据检索的工具。
- Web Scraper API:预配置 API,用于从 100 多个主要域中提取结构化数据。
- 网络解锁程序:一体化应用程序接口,可在具有反僵尸保护功能的网站上处理网站解锁。
- SERP API:专门的 API,可解锁搜索引擎结果并提取完整的 SERP 数据。
- 基础模型:访问符合要求的网络规模数据集,为 LLM 预训练、评估和微调提供支持。
- 数据提供商:与值得信赖的提供商建立联系,大规模地获取高质量的人工智能就绪数据集。
- 数据包:获取经过整理、随时可用的数据集–结构化、丰富和注释。
本指南教您如何使用 Web Scraper API 微调 GPT-4o-mini 的数据,您也可以使用我们的服务选择不同的方法。
结论
在本文中,您将学习如何使用 n8n 自动化整个工作流程,利用从亚马逊获取的数据对 GPT-4o-mini 进行微调。整个过程包括两个分支:
- 抓取数据后执行微调。
- 通过聊天触发器插入提示,测试微调模型。
您还对这种使用工作流程自动化工具的方法和另一种使用云服务的方法进行了比较。
无论哪种方法最适合您的需求和团队,请记住,高质量的数据仍然是整个过程的核心。在这方面,Bright Data为您提供多项人工智能数据服务。
免费创建 Bright Data 账户,测试我们的人工智能就绪数据基础设施!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。





