

在本教程中,您将学到
- Dify 是什么,为什么它是构建人工智能代理的有趣工具?
- 为什么人工智能代理需要访问新鲜、准确的网络数据才能提供可靠的结果?
- 如何使用无代码 Dify 工作流创建具有数据检索功能的人工智能代理。
让我们深入了解一下!
什么是 Dify?
Dify是一个日益流行的开源平台,用于利用 LLM 构建生成式人工智能应用程序。它提供无代码/低代码可视化界面,用于创建人工智能工作流和RAG 管道,从而简化了开发流程。
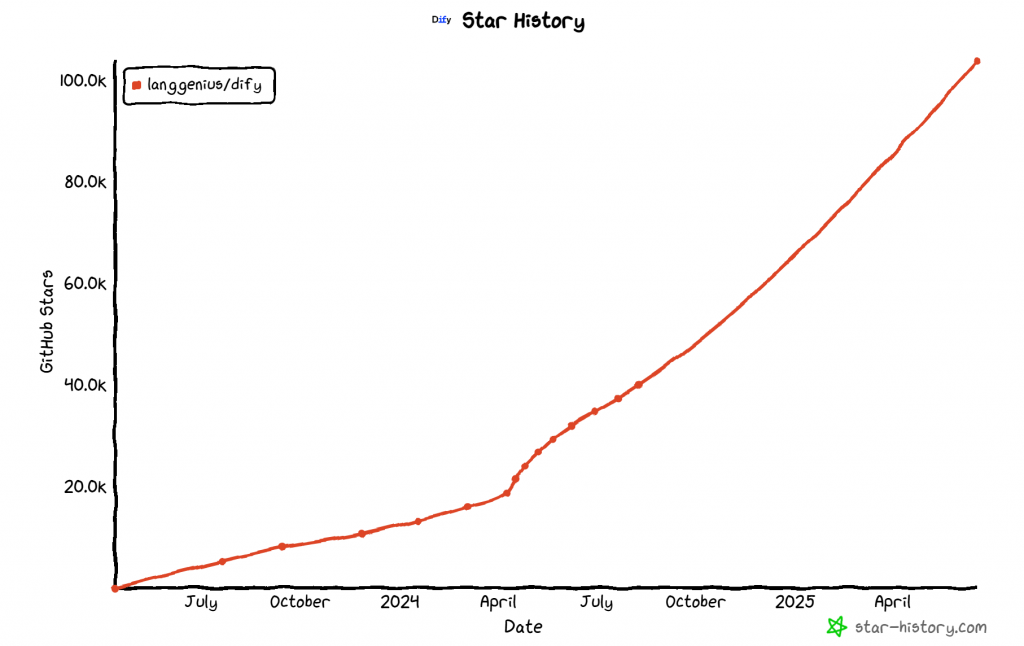
您可以通过自托管的开源版本利用 Dify,也可以直接在云中使用它,无需任何设置(就像我们在这里要做的)。从本质上讲,它就像一个用于 LLM 操作的 BaaS(后端即服务)。
Dify 支持多种 LLM,并通过多个插件提供广泛的集成功能。这些插件可以连接各种第三方服务和解决方案。截至本报告撰写时,其市场拥有约 100 个插件和扩展功能。
人工智能代理必须准确有效
无论您选择哪种人工智能代理构建平台、库或工具,都有一个主要限制:人工智能代理要想准确,就需要高质量的数据。在这方面,请记住网络是最丰富、最可靠的数据来源之一。
因此,要想真正有效,人工智能代理应该能够直接从网页中访问和提取数据。但仅仅提取原始内容是不够的。数据必须针对人工智能的使用进行优化,最好是 Markdown 格式。
专业提示:Markdown 结构紧凑,更易于人工智能模型处理,通常能带来更准确的结果,我们的基准测试也证实了这一点。
因此,您的 Dify 人工智能代理需要一个能从任何网页中提取 Markdown 等结构化内容的插件。这正是Bright Data Dify 插件所能提供的。除此之外,它还能让您的无代码人工智能代理以结构化 JSON 格式从搜索引擎和 50 多个流行平台中提取新鲜数据。
Bright Data 插件可为您处理网络抓取的所有难题,包括验证码、IP 屏蔽、速率限制等。然后,借助 Dify 的无代码流程生成器,您只需连接节点即可将所有内容集成到您的人工智能代理中。这样,一个可访问可靠、实时网络数据的生产就绪型人工智能代理就诞生了。
如何将 Bright Data 插件集成到 Dify 中以构建人工智能代理
在本指导章节中,您将学习如何在 Dify 中构建人工智能代理。特别是,您将使用 Bright Data 插件作为人工智能就绪数据引擎,利用可信信息为代理提供动力。
我们将逐步建立一个简单的摘要代理,它可以摘要任何网页的内容。请注意,这只是演示 Dify + Bright Data 集成的一个示例。您可以同样轻松地涵盖许多其他用例。
注:在某种程度上,所选示例可视为RAG 代理工作流程。原因在于,Bright Data 插件可视为 RAG 代理流程中的检索组件。
请按照以下步骤在 Dify 中创建一个无代码人工智能代理,访问最新的网络数据!
先决条件
要复制本教程并在由 Bright Data 提供支持的 Dify 中构建一个人工智能代理,您需要具备以下条件:
- 一个Dify 账户(免费计划即可)。
- 一个Bright Data API 密钥。
- LLM 提供商提供的 API 密钥(本例中我们将使用Gemini API 密钥)
如果您还没有这些设备,请单击上面的链接并按照设置说明进行操作。
步骤 1:LLM 整合
注:如果您的 Dify 账户中已经设置了 LLM 集成,则可以跳过此步骤。
要在 Dify 中建立人工智能代理,您首先需要配置一个 LLM 提供商。为此,请登录 Dify并进入您的仪表板。点击右上角的个人资料图片,选择 “设置 “选项:
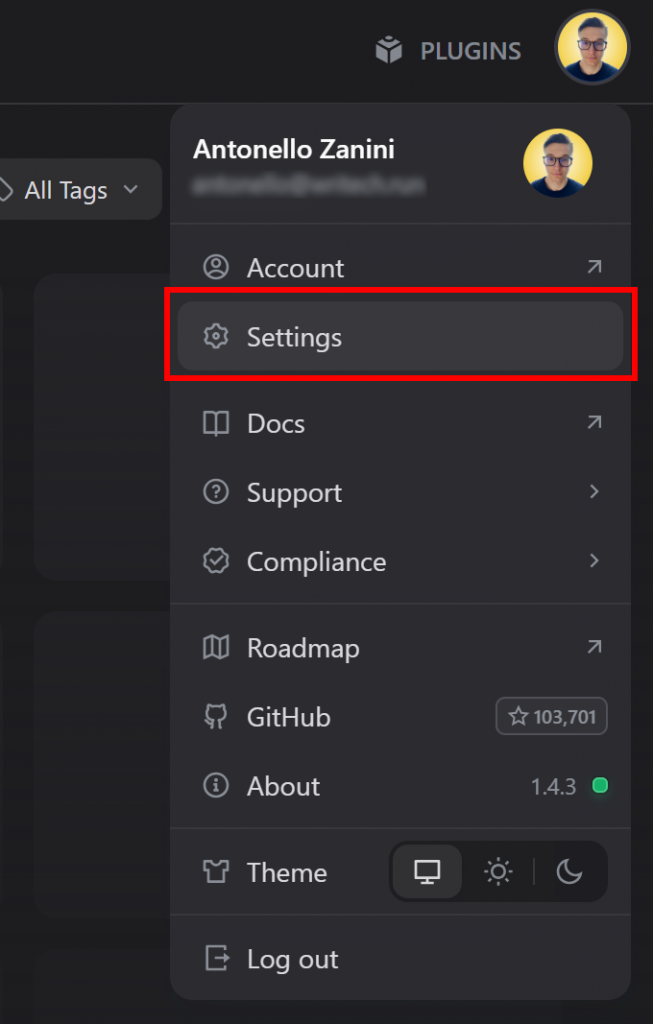
然后,在模态侧边栏中点击 “模型提供程序 “选项。在这里,您可以安装要使用的 LLM 提供程序。在本教程中,我们将使用 Gemini(可通过 API 免费使用):
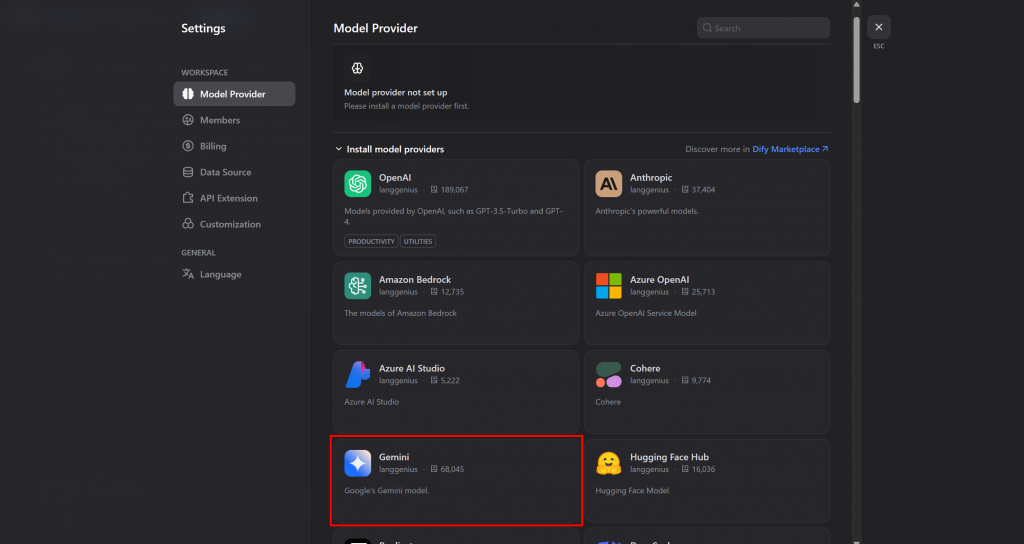
将鼠标悬停在 Gemini 选项上,然后点击 “安装 “按钮。安装完成后,点击 “设置 “按钮并粘贴 Gemini API 密钥以完成配置:
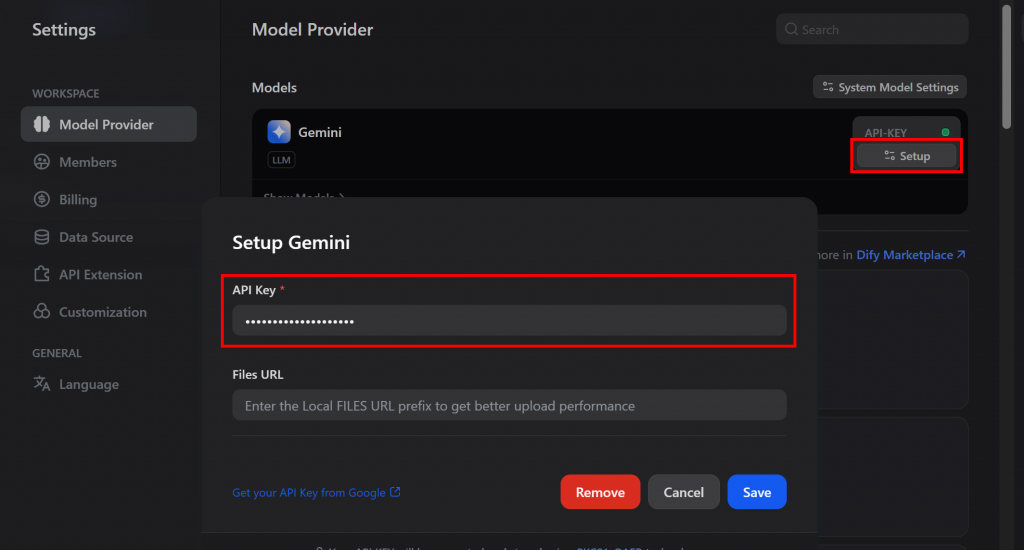
然后,按 “System Model Settings(系统模型设置)”将 Gemini 设置为 Dify 账户中的全球 LLM 提供商:
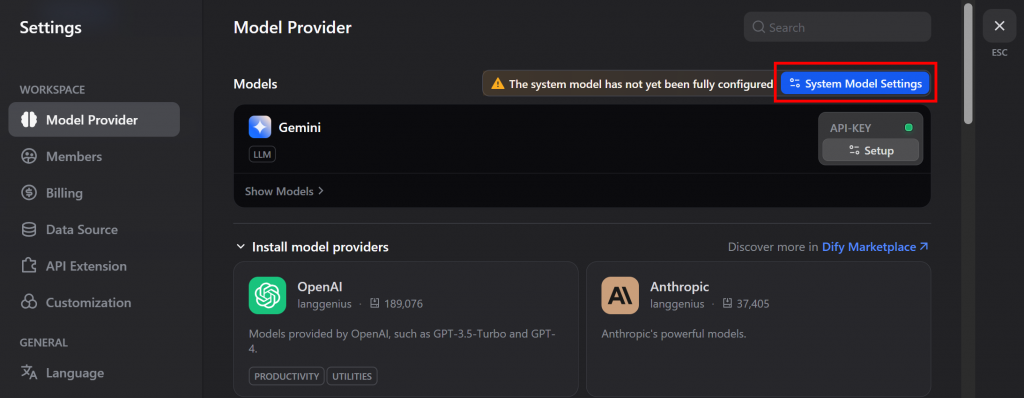
选择要使用的模型。在本例中,我们将选择 “Gemini 2.0 Flash“(通过 API 免费提供)。然后点击 “保存”:
完美!Dify 中的 LLM 集成现已完成。
步骤 #2:安装 Bright Data 插件
现在是安装 Bright Data Dify 插件的时候了。为此,请单击个人资料图片左侧边栏中的 “PLUGINS(插件)”选项:
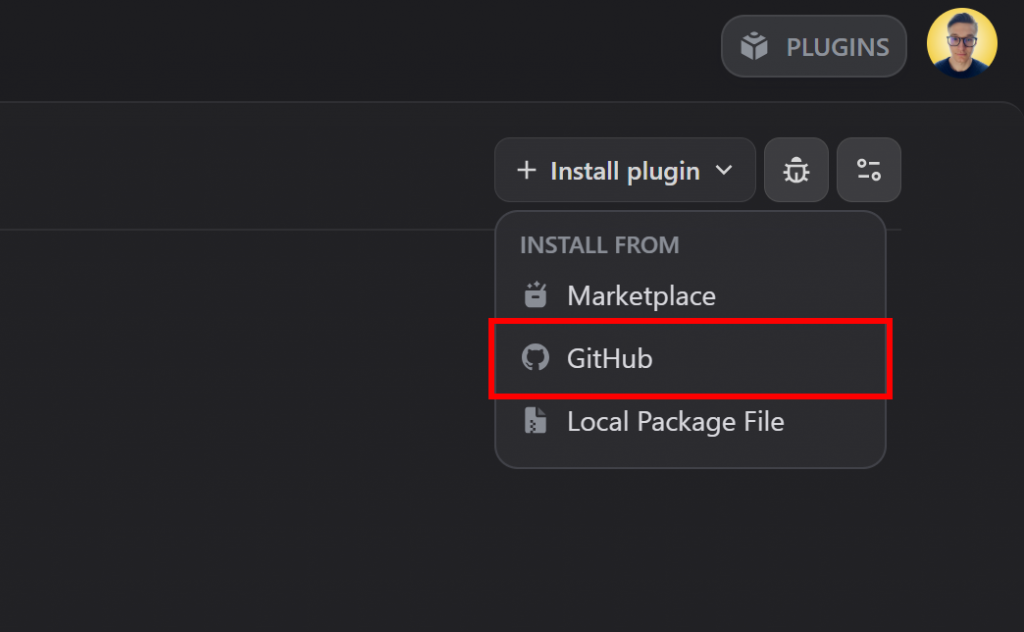
在 Dify 插件市场部分,点击 “安装插件 “按钮,然后选择 “GitHub “选项:
在出现的模式窗口中,粘贴 Bright Data Dify 插件的 GitHub URL:
https://github.com/Idanvilenski/BrightData_Dify_Plugin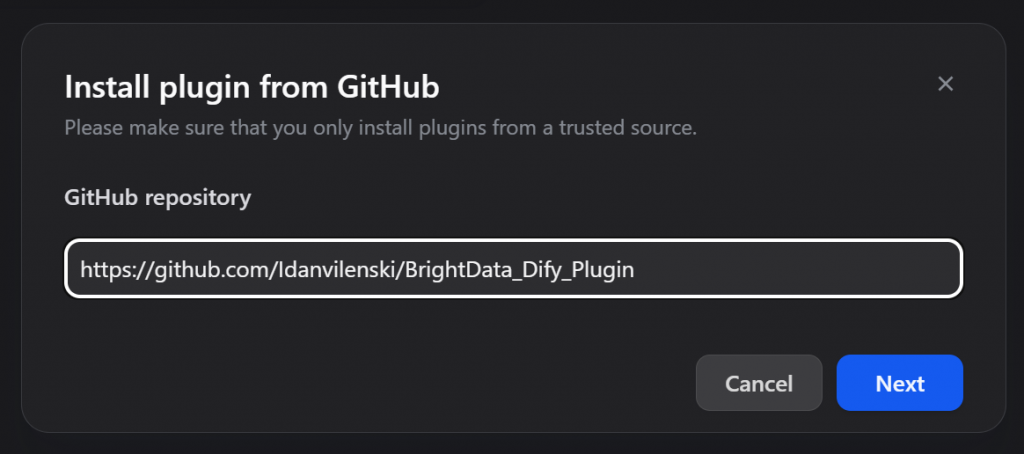
选择插件版本(建议使用最新版本),选择插件包,然后点击 “下一步”:
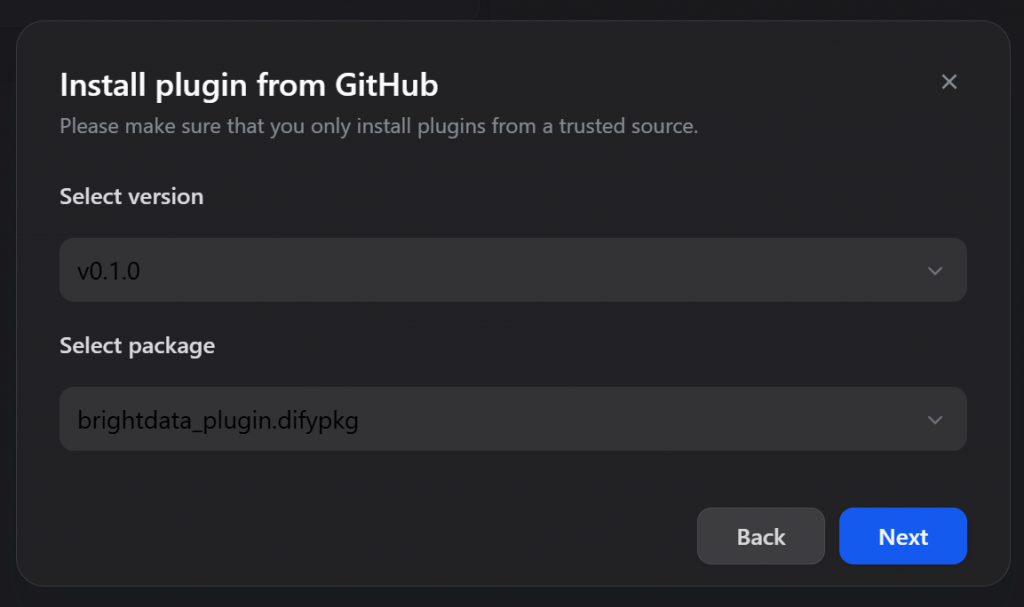
点击 “安装 “完成插件安装。安装完成后,点击插件卡。在右侧打开的面板中,点击 “授权 “按钮:
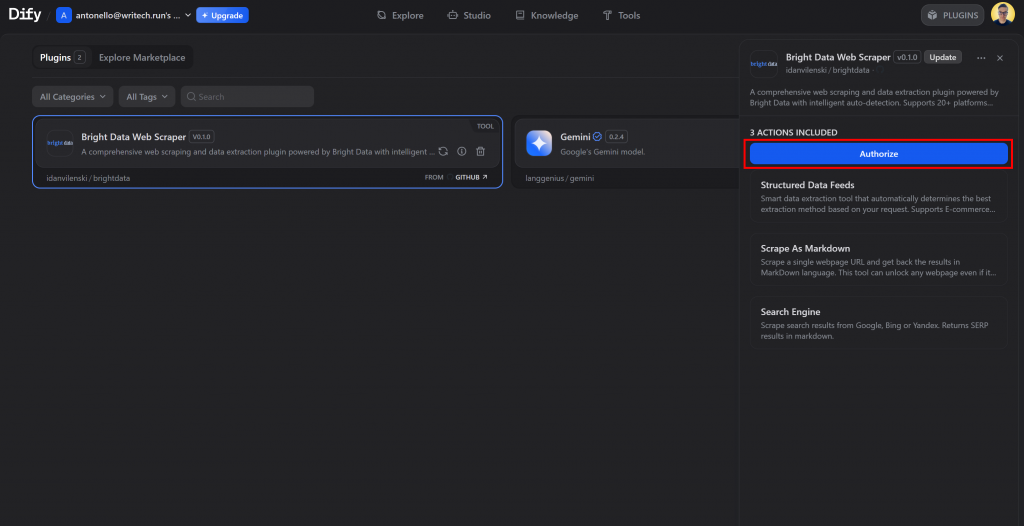
粘贴您的 Bright Data API 令牌,然后点击 “保存”:
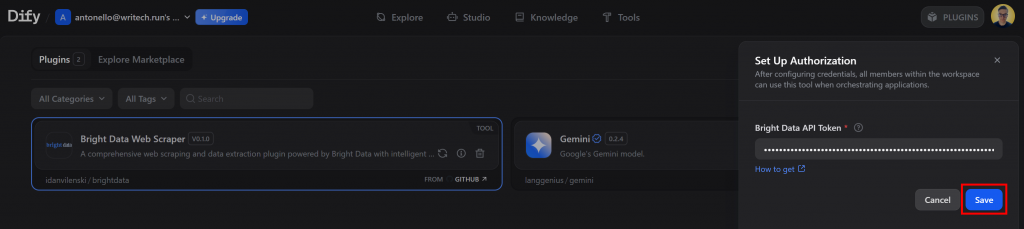
太棒了Bright Data Dify 插件已安装,其工具也已准备就绪。
步骤 #3:创建新的 Dify 应用程序
现在,您已具备创建无代码人工智能摘要代理的一切条件。回到 Dify 面板,点击 “创建应用程序 > 从空白创建”,开始一个新的人工智能代理项目:
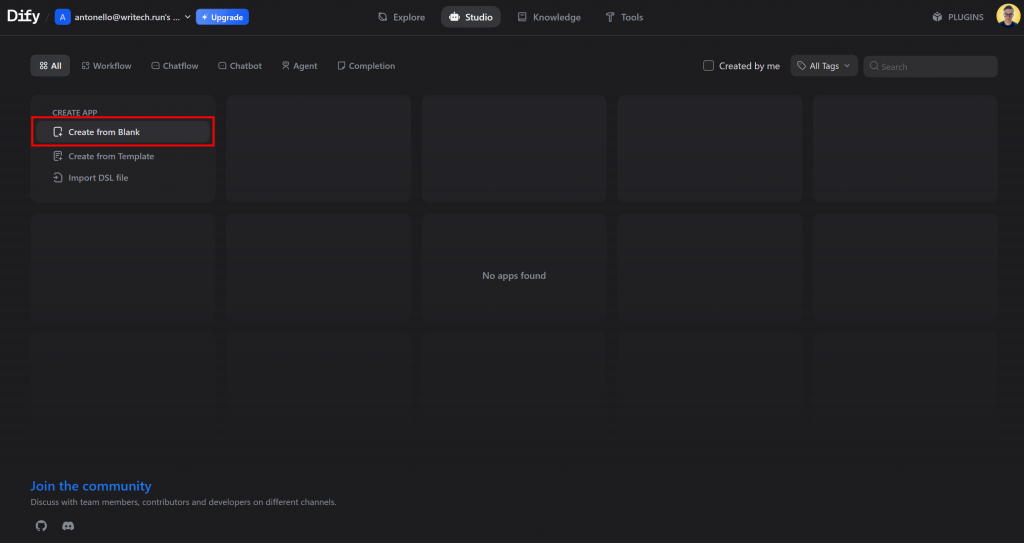
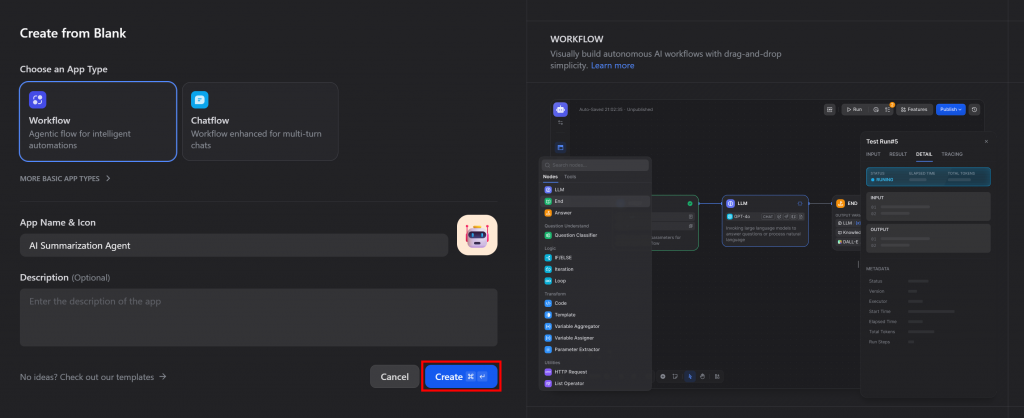
选择 “工作流 “模板,将人工智能代理命名为 “人工智能摘要代理”,然后点击 “创建 “初始化应用程序:
您将看到可视化画布,在这里您可以通过连接节点来创建代理:
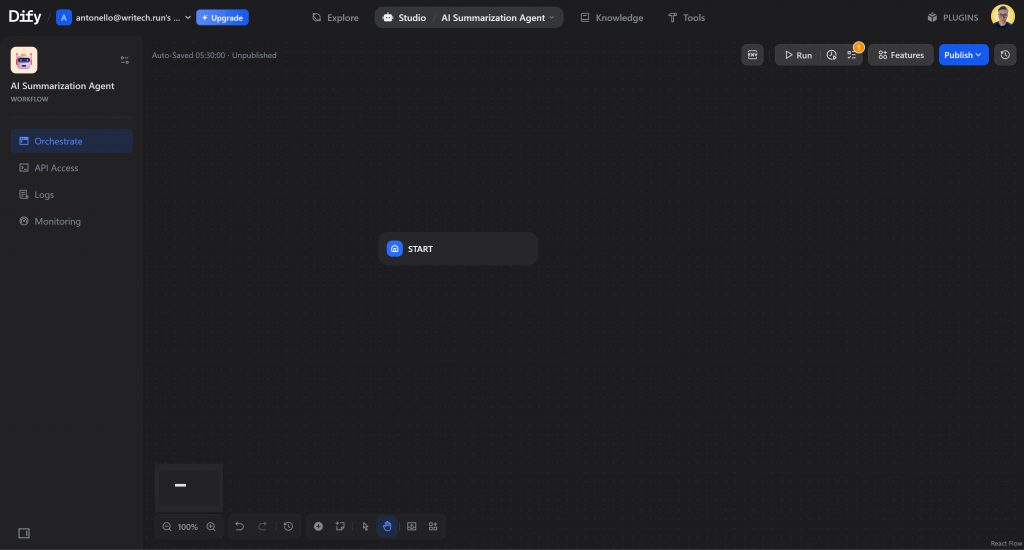
在这里,您将通过把不同的组件连接在一起来定义人工智能代理的逻辑和数据流。太棒了
步骤 #4:设计人工智能代理逻辑
在实施无代码人工智能代理之前,先花一些时间设计人工智能代理需要做什么。在这种情况下,人工智能代理应该
- 接收要汇总的网页 URL。
- 将 URL 传递给 Bright Data 插件,以获取 Markdown 格式的页面内容。
- 将 Markdown 内容发送到配置的 LLM,并提示生成摘要。
- 将摘要内容返回给用户。
在接下来的四个步骤中,您将通过连接节点和使用 Dify 中的插件来实现这些操作。
步骤 #5:配置页面 URL 输入参数
首先,点击 “START(开始)”节点,然后点击 “+”图标添加新的输入变量:
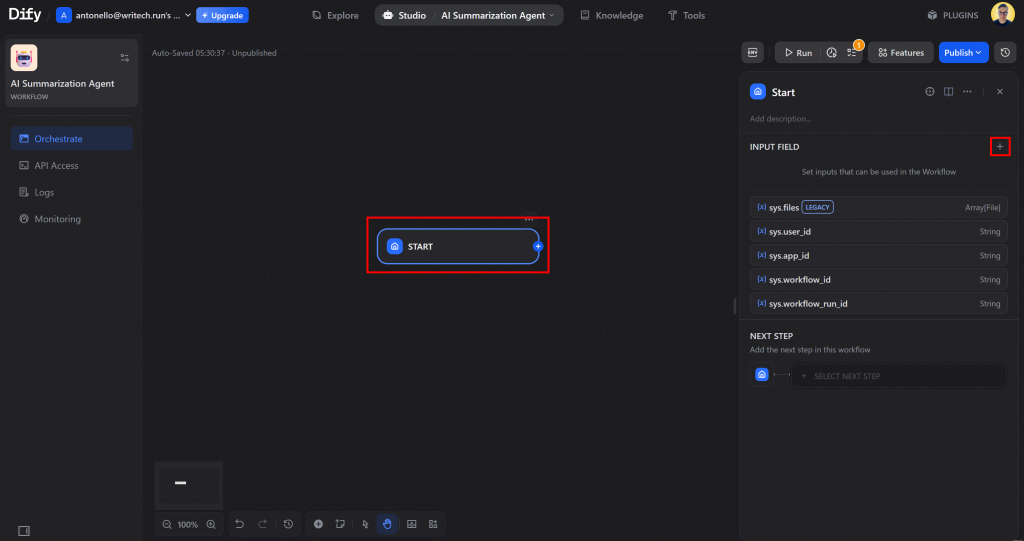
从输入类型选项中,选择 “段落 “数据类型。这是输入 URL 等文本的理想选择。将输入内容命名为page_url:
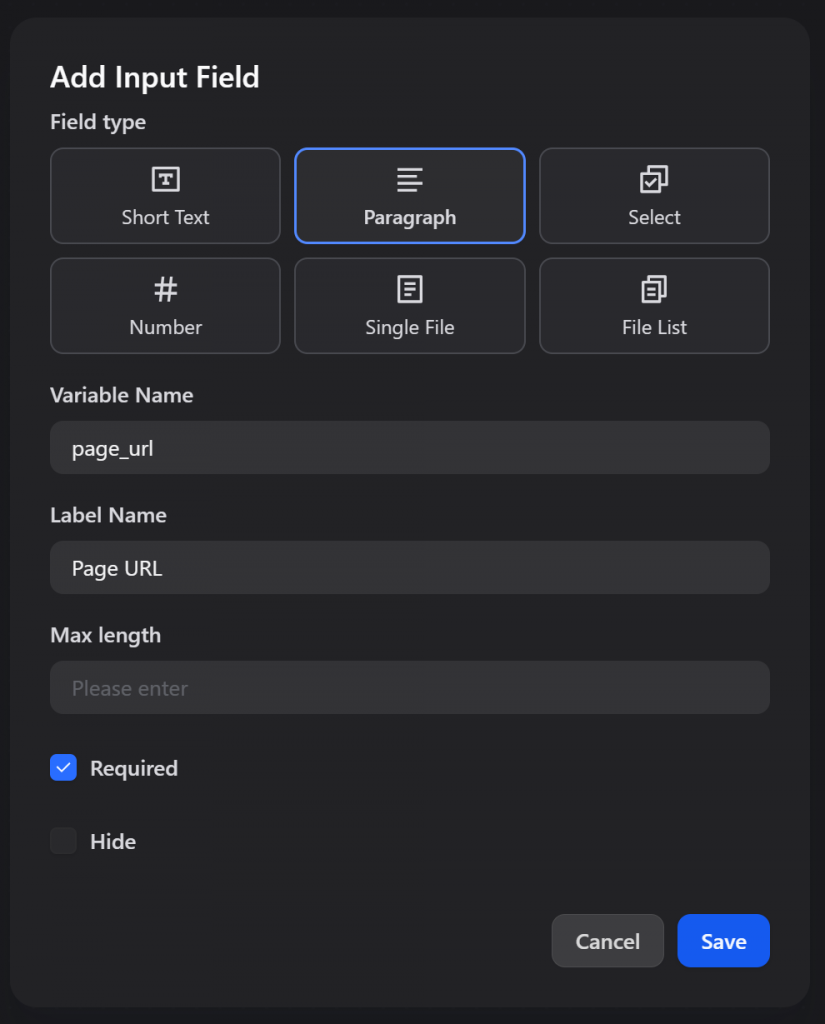
确保 “Required(必填)”切换打开,因为该输入对人工智能代理的运行至关重要。保存后,您将看到如下内容:
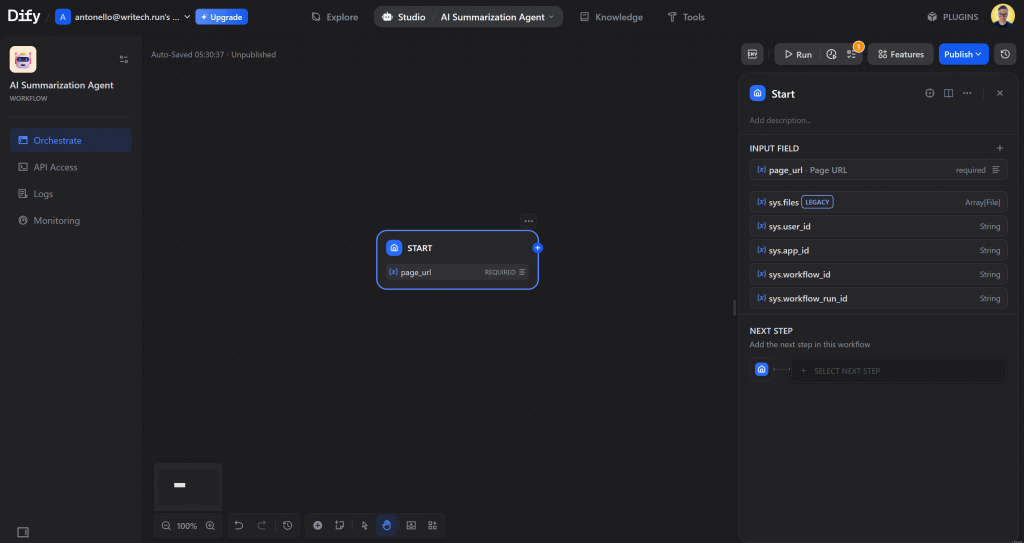
看看 “开始 “节点现在如何显示你的自定义输入变量。干得好
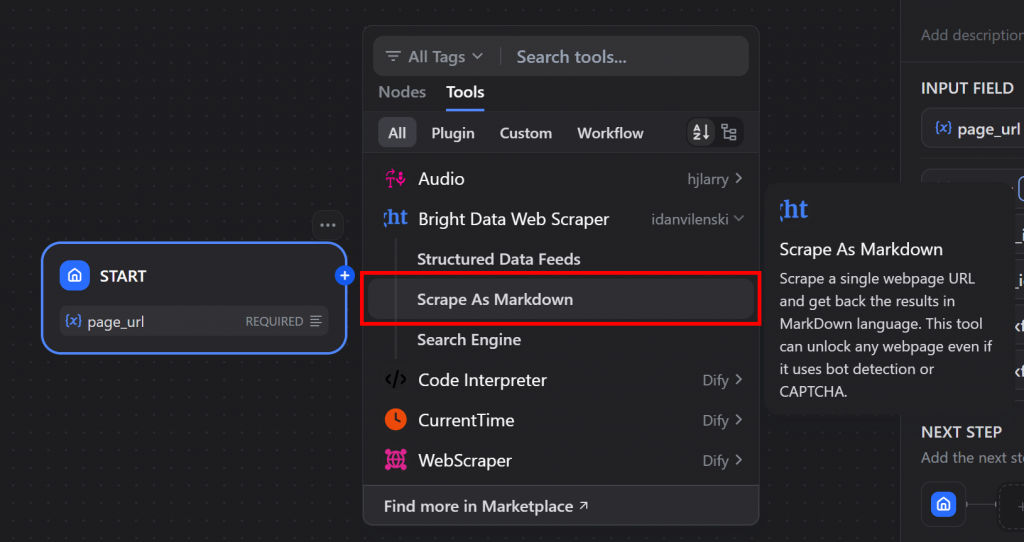
第 6 步:使用 Bright Data 插件检索 Markdown 内容
点击 “START(开始)”节点上的 “+”按钮,选择 Bright Data 插件。然后选择 “Scrape As Markdown “工具:
通过将page_url设置为输入参数来配置工具。此外,启用 “RETRY ON FAILURE(失败重试)”选项。这将允许 Bright Data 插件在抓取过程中发生错误时自动重试:
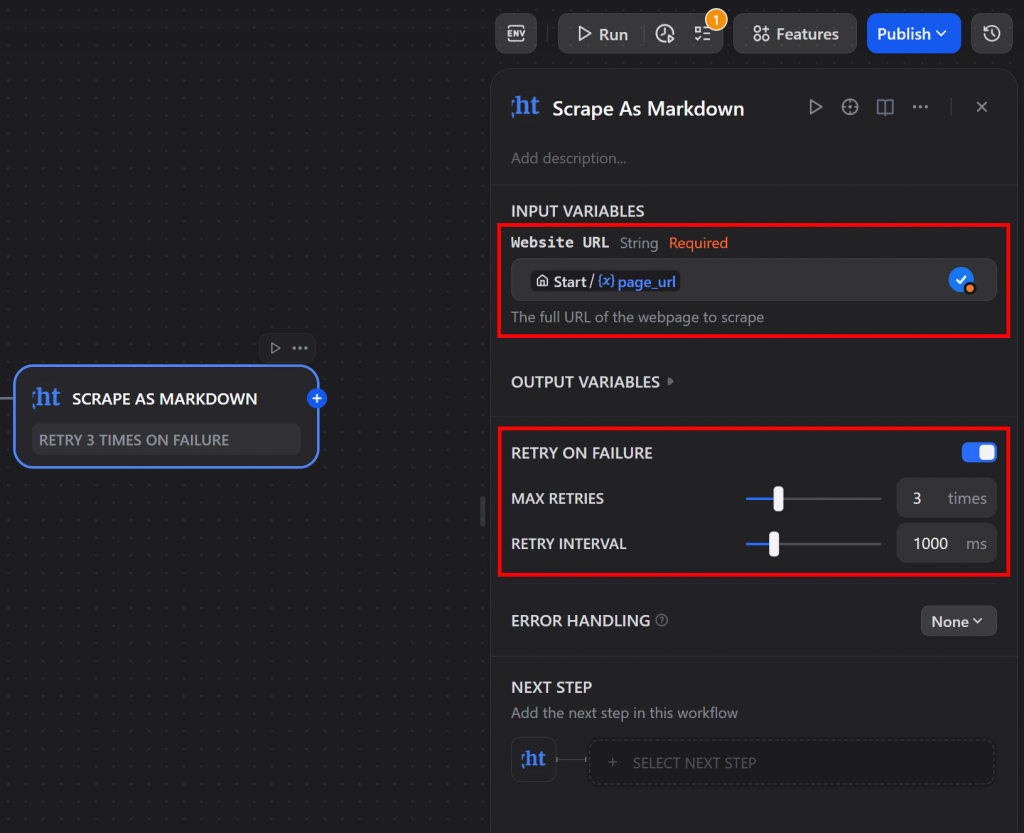
太棒了!现在,Bright Data 插件将使用所提供的 URL,抓取页面并以 Markdown 格式返回其内容。
步骤 #7:整合 LLM 总结逻辑
下一步是连接一个 LLM 节点,该节点将汇总 Bright Data 插件返回的 Markdown 内容。点击 “Scrape As Markdown “节点上的 “+”图标,然后选择 “LLM”:
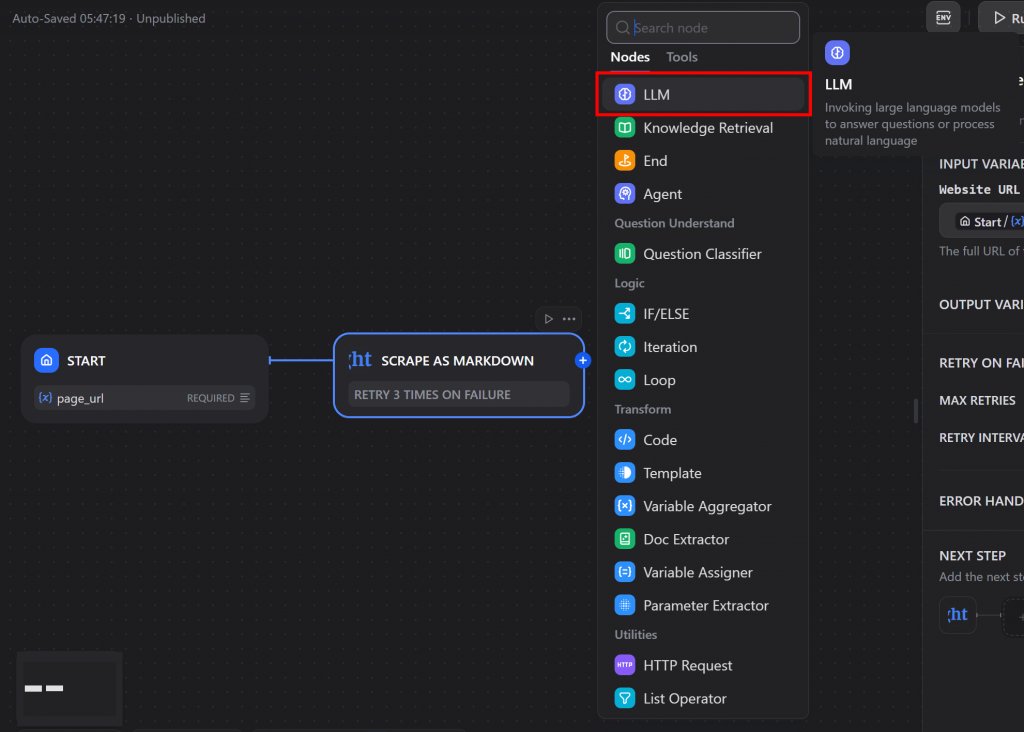
在 “LLM “节点设置中,将 “CONTEXT “输入设置为文本变量,即 “Scrape As Markdown “工具的输出。
接下来,请写出如下提示:
You are a summarization agent. Based on the Markdown content provided below, write a concise and helpful summary in no more than 150 words. Focus on capturing the key elements of the content.
Content:
{CONTEXT}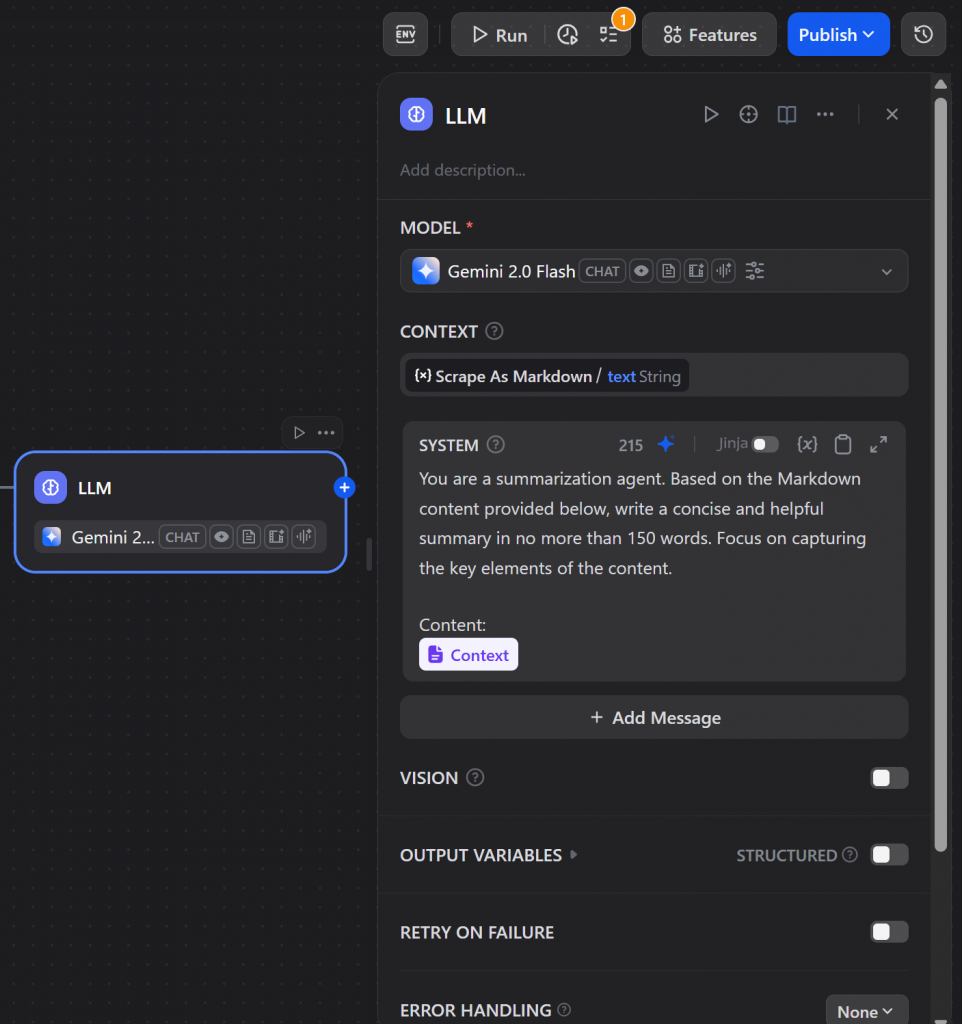
LLM “节点充当 Dify 人工智能代理的大脑,处理数据并生成摘要。太棒了!人工智能代理的构建逻辑已经基本完成。
步骤 #8:返回摘要
作为无代码 Dify 人工智能代理工作流程的最后一步,添加一个 “结束 “节点:

配置 “END “节点,使用 LLM 节点的文本输出:
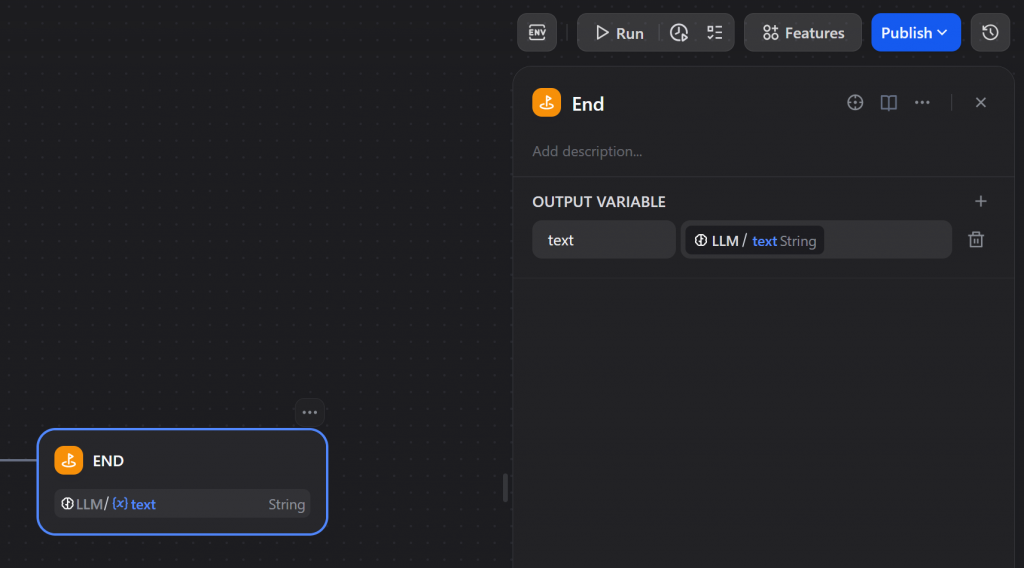
该节点将负责把最终汇总的内容返回给用户。任务完成!您的无代码人工智能摘要代理已经可以使用了。
步骤 #9:测试人工智能代理
这就是您完成的 Dify 人工智能代理工作流程:
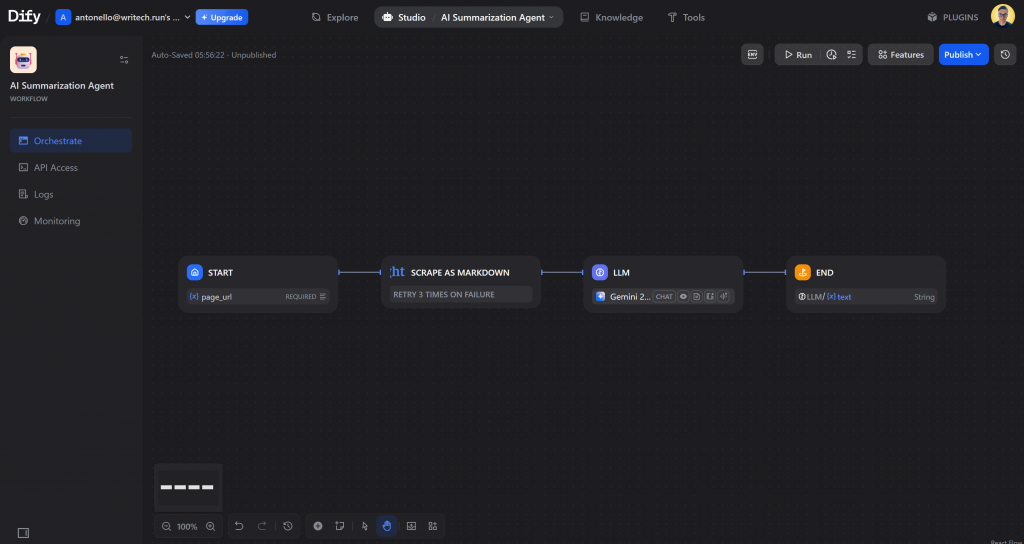
仅用四个节点,您就构建了一个具有精确总结能力的真实世界人工智能代理。
要进行测试,请点击右上角的 “运行 “按钮:
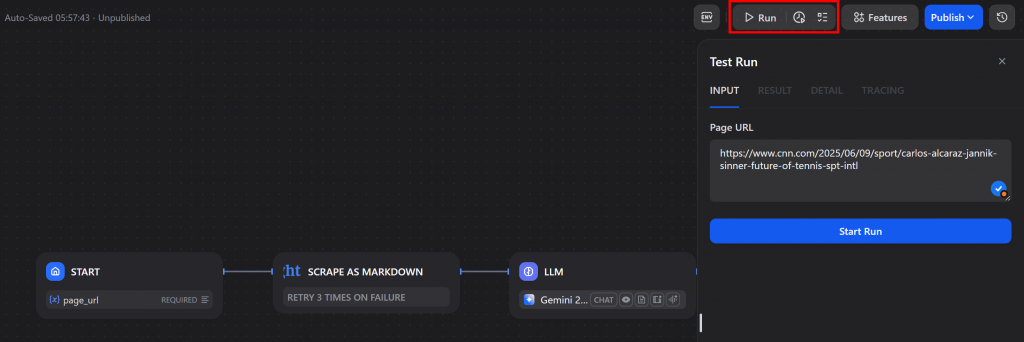
接下来,输入您要摘要的页面的 URL。在本例中,您必须使用CNN 体育频道的一篇文章。
按下 “开始运行 “按钮,你会看到每个节点依次执行,并变成绿色表示成功:
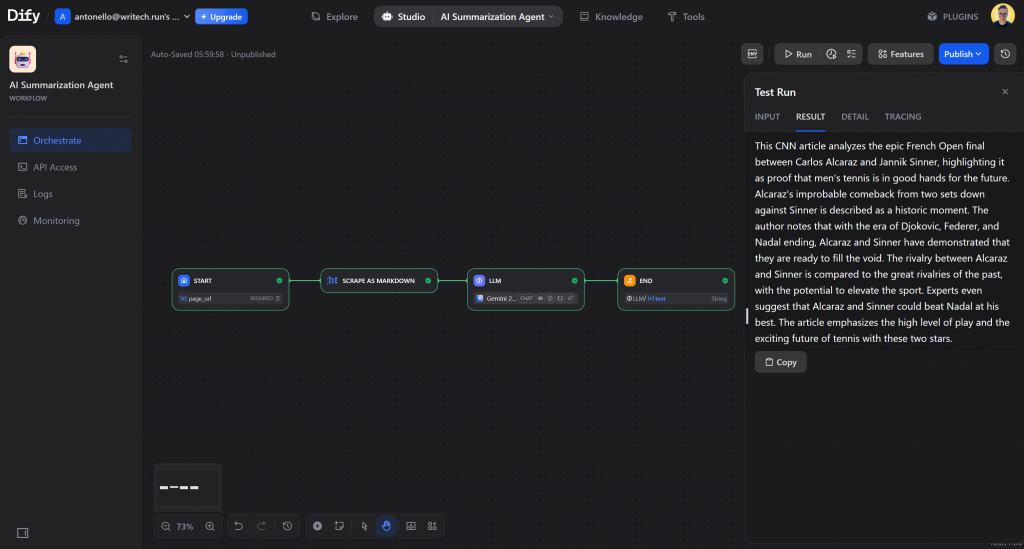
这是您可能得到的输出结果:
This CNN article analyzes the epic French Open final between Carlos Alcaraz and Jannik Sinner, highlighting it as proof that men's tennis is in good hands for the future. Alcaraz's improbable comeback from two sets down against Sinner is described as a historic moment. The author notes that with the era of Djokovic, Federer, and Nadal ending, Alcaraz and Sinner have demonstrated that they are ready to fill the void. The rivalry between Alcaraz and Sinner is compared to the great rivalries of the past, with the potential to elevate the sport. Experts even suggest that Alcaraz and Sinner could beat Nadal at his best. The article emphasizes the high level of play and the exciting future of tennis with these two stars.这是一篇不到 150 字的简明扼要、联系上下文的摘要,符合要求。请注意,法学硕士也承认文章来源是 CNN。
就是这样!您刚刚在 Dify 中构建了一个功能齐全的人工智能摘要代理,无需编写任何代码。该代理能够处理和总结任何网页。
结论
在本文中,您将学习如何使用 Dify 构建一个无代码工作流的人工智能摘要代理。该代理需要访问公共网络数据才能投入生产。这要归功于Bright Data Dify 插件,它为人工智能就绪数据检索提供了高级工具。
现在,这只是一个简单的工作流程示例,但你可能想建立更复杂的人工智能代理。为此,您需要检索、验证和转换网络内容的工具。这正是Bright Data 的人工智能基础架构所能提供的。
创建一个免费的 Bright Data 账户,开始尝试使用我们的人工智能就绪数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


