分散在多个平台上的客户评论为企业带来分析挑战。手动监测评论既耗时又容易忽略关键信息。本指南将演示如何构建一个 AI 智能体,自动从不同来源收集、分析并分类评论。
你将学到:
- 如何使用 CrewAI 和 Bright Data 的 Web MCP 构建点评情报系统
- 如何对客户反馈执行基于方面的情感分析
- 如何按主题对评论进行分类并生成可执行的洞察
在GitHub查看最终项目!
什么是 CrewAI?
CrewAI 是一个用于构建协作式 AI 智能体团队的开源框架。你可以定义智能体的角色、目标和工具来执行复杂工作流。每个智能体处理特定任务,并协同朝共同目标推进。
CrewAI 包括:
- Agent(智能体):具有明确职责与工具的 LLM 驱动“工作者”
- Task(任务):具备清晰输出要求的具体工作
- Tool(工具):智能体用于专业化工作的函数,如数据提取
- Crew(团队):共同协作的一组智能体
什么是 MCP?
MCP(Model Context Protocol,模型上下文协议)是一个基于 JSON-RPC 2.0 的标准,通过统一接口将 AI 智能体连接到外部工具与数据源。
Bright Data 的 Web MCP 服务器提供对具备反机器人保护的网页抓取能力的直接访问,拥有 1.5 亿+ 轮换住宅 IP、对动态内容的 JavaScript 渲染、从抓取数据输出干净的 JSON,以及 50+ 针对不同平台的现成工具。
我们要构建什么:多源点评情报智能体
我们将创建一个 CrewAI 系统,自动从 G2、Capterra、Trustpilot、TrustRadius 等多个平台抓取特定公司的评论,获取各平台评分与高赞评论,对评论进行基于方面的情感分析,将反馈归类为主题(支持、定价、易用性),为每个类别打分并生成可执行的业务洞察。
先决条件
准备你的开发环境:
- Python 3.11 或更高版本
- 用于 Web MCP 服务器的 Node.js 与 npm
- Bright Data 账号 – 注册并创建 API token(提供免费试用额度)。
- Nebius API Key – 在 Nebius AI Studio 创建密钥(点击 + Get API Key)。可免费使用,无需账单信息。
- Python 虚拟环境 – 用于隔离依赖;参见
venv文档。
环境配置
创建项目目录并安装依赖:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv pandas textblob创建名为 review_intelligence.py 的新文件并添加以下导入:
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
import json
import pandas as pd
from datetime import datetime
from dotenv import load_dotenv
from textblob import TextBlob
load_dotenv()Bright Data Web MCP 配置
创建包含你的凭据的 .env 文件:
BRIGHT_DATA_API_TOKEN="your_api_token_here"
WEB_UNLOCKER_ZONE="your_web_unlocker_zone"
BROWSER_ZONE="your_browser_zone"
NEBIUS_API_KEY="your_nebius_api_key"你需要:
- API token:在 Bright Data 控制台生成新的 API token
- Web Unlocker 区域(Zone):为房产类网站创建新的 Web Unlocker 区域
- Browser API 区域:为需要大量 JavaScript 渲染的房产网站创建新的 Browser API 区域
- Nebius API Key:已在“先决条件”中创建
在 review_intelligence.py 中配置 LLM 与 Web MCP 服务器:
llm = LLM(
model="nebius/Qwen/Qwen3-235B-A22B",
api_key=os.getenv("NEBIUS_API_KEY")
)
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)智能体与任务定义
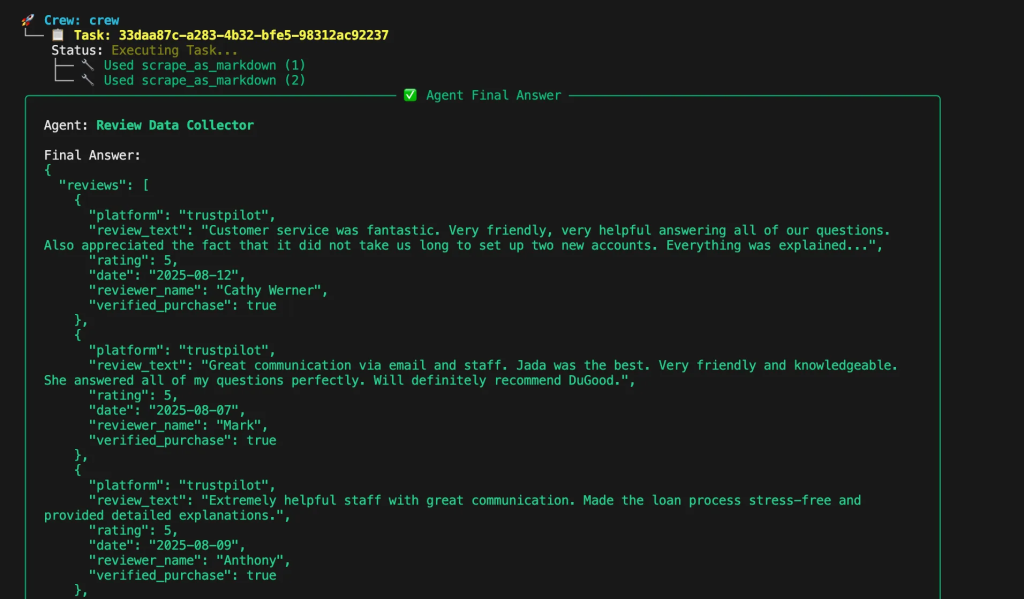
为评论分析的不同环节定义专门的智能体。评论抓取智能体从多个平台提取客户评论,并返回包含评论文本、评分、日期与来源平台的干净结构化 JSON。该智能体在网页抓取方面具备专家级能力,深谙各类点评平台结构,并能绕过反机器人机制。
def build_review_scraper_agent(mcp_tools):
return Agent(
role="Review Data Collector",
goal=(
"Extract customer reviews from multiple platforms and return clean, "
"structured JSON data with review text, ratings, dates, and platform source."
),
backstory=(
"Expert in web scraping with deep knowledge of review platform structures. "
"Skilled at bypassing anti-bot measures and extracting complete review datasets "
"from Amazon, Yelp, Google Reviews, and other platforms."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
情感分析智能体围绕三大方面分析评论情绪:支持质量、定价满意度与易用性。它为每个类别提供数值评分与详细理由。该智能体专长于自然语言处理与客户情绪分析,能够识别情绪指标与基于方面的反馈模式。
def build_sentiment_analyzer_agent():
return Agent(
role="Sentiment Analysis Specialist",
goal=(
"Analyze review sentiment across three key aspects: Support Quality, "
"Pricing Satisfaction, and Ease of Use. Provide numerical scores and "
"detailed reasoning for each category."
),
backstory=(
"Data scientist specializing in natural language processing and customer "
"sentiment analysis. Expert at identifying emotional indicators, context clues, "
"and aspect-specific feedback patterns in customer reviews."
),
llm=llm,
max_iter=2,
verbose=True,
)洞察生成智能体将情感分析结果转化为可执行的业务洞察。它能识别趋势、突出关键问题,并给出具体的改进建议。该智能体具备战略分析能力,擅长客户体验优化,并能将反馈数据转化为可落地的业务行动。
def build_insights_generator_agent():
return Agent(
role="Business Intelligence Analyst",
goal=(
"Transform sentiment analysis results into actionable business insights. "
"Identify trends, highlight critical issues, and provide specific "
"recommendations for improvement."
),
backstory=(
"Strategic analyst with expertise in customer experience optimization. "
"Skilled at translating customer feedback data into concrete business "
"actions and priority frameworks."
),
llm=llm,
max_iter=2,
verbose=True,
)团队组装与执行
为分析流程的每个阶段创建任务。抓取任务从指定产品页面收集评论,并输出包含平台信息、评论文本、评分、日期与验证状态的结构化 JSON。
def build_scraping_task(agent, product_urls):
return Task(
description=f"Scrape reviews from these product pages: {product_urls}",
expected_output="""{
"reviews": [
{
"platform": "amazon",
"review_text": "Great product, fast shipping...",
"rating": 5,
"date": "2024-01-15",
"reviewer_name": "John D.",
"verified_purchase": true
}
],
"total_reviews": 150,
"platforms_scraped": ["amazon", "yelp"]
}""",
agent=agent,
)情感分析任务会处理评论,分析支持、定价与易用性三方面。它返回每个类别的数值评分、情绪分类、关键主题与评论数量。
def build_sentiment_analysis_task(agent):
return Task(
description="Analyze sentiment for Support, Pricing, and Ease of Use aspects",
expected_output="""{
"aspect_analysis": {
"support_quality": {
"score": 4.2,
"sentiment": "positive",
"key_themes": ["responsive", "helpful", "knowledgeable"],
"review_count": 45
},
"pricing_satisfaction": {
"score": 3.1,
"sentiment": "mixed",
"key_themes": ["expensive", "value", "competitive"],
"review_count": 67
},
"ease_of_use": {
"score": 4.7,
"sentiment": "very positive",
"key_themes": ["intuitive", "simple", "user-friendly"],
"review_count": 89
}
}
}""",
agent=agent,
)洞察任务基于情感分析结果生成可执行的商业智能,包含管理摘要、优先行动、风险领域、优势识别与战略建议。
def build_insights_task(agent):
return Task(
description="Generate actionable business insights from sentiment analysis",
expected_output="""{
"executive_summary": "Overall customer satisfaction is strong...",
"priority_actions": [
"Address pricing concerns through value communication",
"Maintain excellent ease of use standards"
],
"risk_areas": ["Price sensitivity among new customers"],
"strengths": ["Intuitive user experience", "Quality support team"],
"recommended_focus": "Pricing strategy optimization"
}""",
agent=agent,
)基于方面的情感分析
添加情感分析函数,用于识别评论中提及的具体方面,并计算各关注领域的情感分数。
def analyze_aspect_sentiment(reviews, aspect_keywords):
"""Analyze sentiment for specific aspects mentioned in reviews."""
aspect_reviews = []
for review in reviews:
text = review.get('review_text', '').lower()
if any(keyword in text for keyword in aspect_keywords):
blob = TextBlob(review['review_text'])
sentiment_score = blob.sentiment.polarity
aspect_reviews.append({
'text': review['review_text'],
'sentiment_score': sentiment_score,
'rating': review.get('rating', 0),
'platform': review.get('platform', '')
})
return aspect_reviews将评论归类为主题(支持、定价、易用性)
分类函数会基于关键词匹配将评论整理为“支持”“定价”“易用性”三类。支持关键词涵盖与客服与协助相关的术语;定价关键词涵盖成本、价值与可负担性相关描述。
def categorize_by_aspects(reviews):
"""Categorize reviews into Support, Pricing, and Ease of Use topics."""
support_keywords = ['support', 'help', 'service', 'customer', 'response', 'assistance']
pricing_keywords = ['price', 'cost', 'expensive', 'cheap', 'value', 'money', 'affordable']
usability_keywords = ['easy', 'difficult', 'intuitive', 'complicated', 'user-friendly', 'interface']
categorized = {
'support': analyze_aspect_sentiment(reviews, support_keywords),
'pricing': analyze_aspect_sentiment(reviews, pricing_keywords),
'ease_of_use': analyze_aspect_sentiment(reviews, usability_keywords)
}
return categorized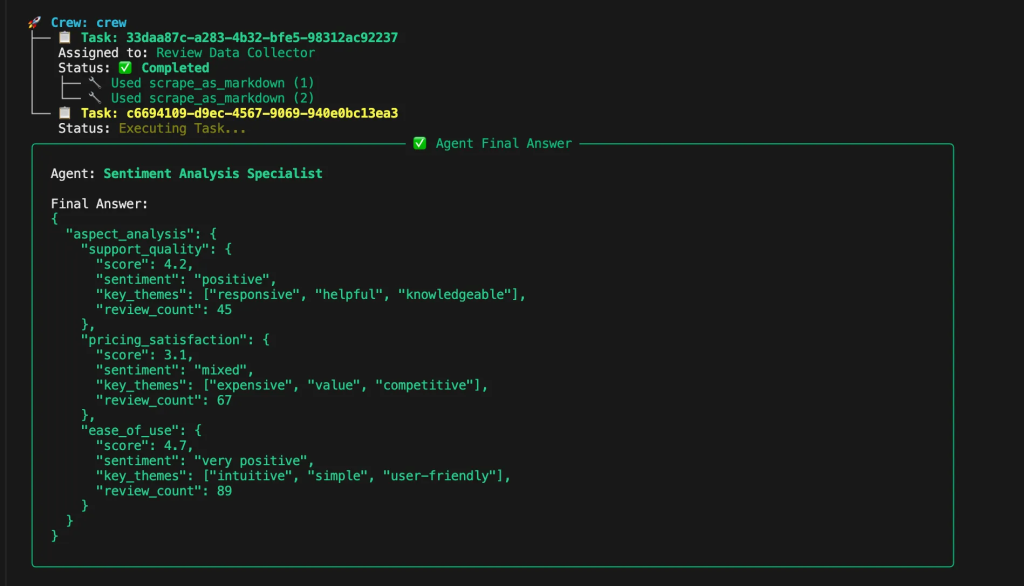
为每个主题打分
实现评分逻辑,将情感分析结果转换为数值评分与有意义的分类。
def calculate_aspect_scores(categorized_reviews):
"""Calculate numerical scores for each aspect category."""
scores = {}
for aspect, reviews in categorized_reviews.items():
if not reviews:
scores[aspect] = {'score': 0, 'count': 0, 'sentiment': 'neutral'}
continue
# Calculate average sentiment score
sentiment_scores = [r['sentiment_score'] for r in reviews]
avg_sentiment = sum(sentiment_scores) / len(sentiment_scores)
# Convert to 1-5 scale
normalized_score = ((avg_sentiment + 1) / 2) * 5
# Determine sentiment category
if avg_sentiment > 0.3:
sentiment_category = 'positive'
elif avg_sentiment < -0.3:
sentiment_category = 'negative'
else:
sentiment_category = 'neutral'
scores[aspect] = {
'score': round(normalized_score, 1),
'count': len(reviews),
'sentiment': sentiment_category,
'raw_sentiment': round(avg_sentiment, 2)
}
return scores生成最终洞察报告
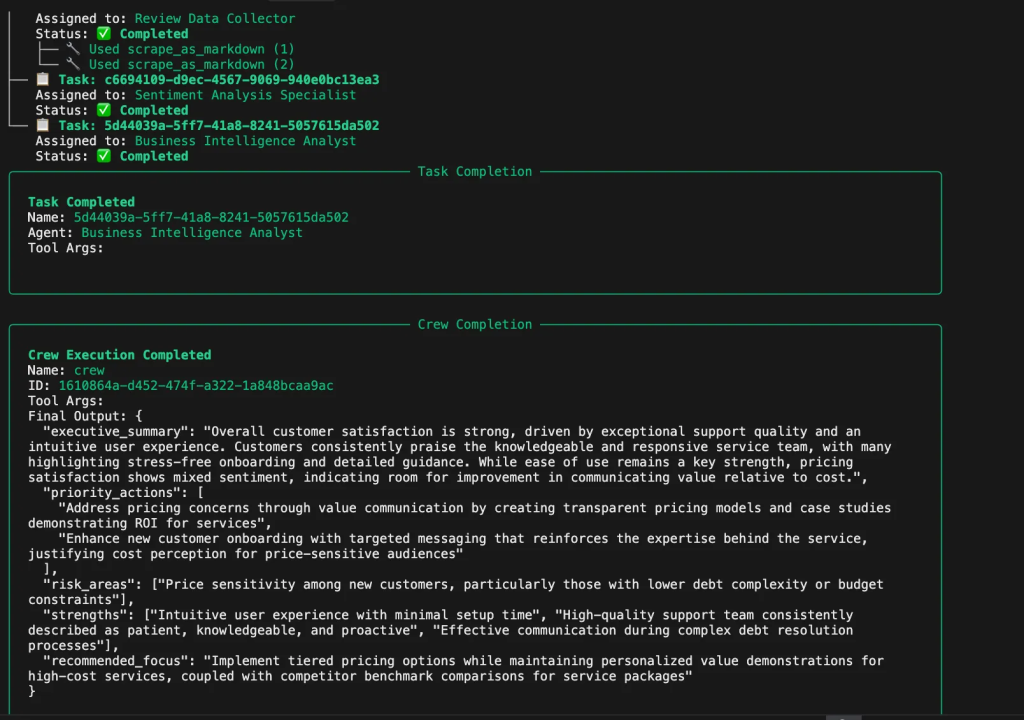
通过按序编排所有智能体与任务来完成整个工作流。主函数会创建用于抓取、情感分析与洞察生成的专门智能体,并将其组装为按顺序处理任务的团队。
def analyze_reviews(product_urls):
"""Main function to orchestrate the review intelligence workflow."""
with MCPServerAdapter(server_params) as mcp_tools:
# Create agents
scraper_agent = build_review_scraper_agent(mcp_tools)
sentiment_agent = build_sentiment_analyzer_agent()
insights_agent = build_insights_generator_agent()
# Create tasks
scraping_task = build_scraping_task(scraper_agent, product_urls)
sentiment_task = build_sentiment_analysis_task(sentiment_agent)
insights_task = build_insights_task(insights_agent)
# Assemble crew
crew = Crew(
agents=[scraper_agent, sentiment_agent, insights_agent],
tasks=[scraping_task, sentiment_task, insights_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
product_urls = [
"<https://www.amazon.com/product-example-1>",
"<https://www.yelp.com/biz/business-example>"
]
try:
result = analyze_reviews(product_urls)
print("Review Intelligence Analysis Complete!")
print(json.dumps(result, indent=2))
except Exception as e:
print(f"Analysis failed: {str(e)}")运行分析:
python review_intelligence.py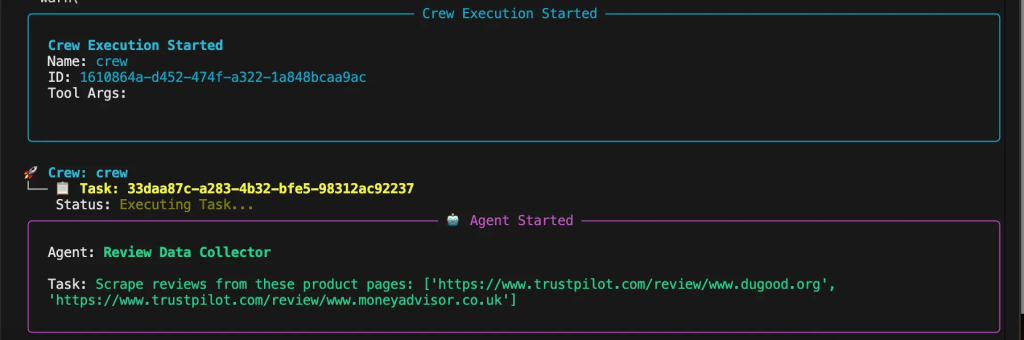
你将在控制台看到智能体在规划与执行任务时的思考过程。系统将展示它如何:
- 从多个平台提取全面的评论数据
- 分析竞争差距与市场定位
- 处理情绪模式并对评论质量打分
- 识别功能提及与定价情报
- 提供战略建议与风险预警
总结
通过使用 CrewAI 与 Bright Data 强大的网络数据平台自动化点评情报,你可以挖掘更深层次的客户洞察,简化竞品分析,并做出更明智的业务决策。借助 Bright Data 的产品与业内领先的反机器人网页抓取方案,你可以在任何行业规模化地进行评论采集与情感分析。获取最新策略与更新,请访问 Bright Data 博客,或阅读我们详细的网页抓取指南,立即开始最大化你的客户反馈价值。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。