
构建适合-AI-的向量化数据集.svg)
大型语言模型(LLM)正在改变我们获取信息和构建智能应用的方式。要充分发挥 LLM 的潜力,尤其是在使用特定领域知识或专有数据时,创建高质量、结构化的矢量数据集至关重要。LLM 的性能和准确性与其输入数据的质量直接相关。准备不充分的数据集会导致不合格的结果,而精心编辑的数据集则能将 LLM 变成真正的领域专家。
在本指南中,我们将逐步介绍如何建立一个自动管道,生成可用于人工智能的向量数据集。
挑战:为法律硕士寻找和准备数据
虽然 LLM 是在庞大的通用文本语料库中训练出来的,但在应用于特定任务或领域(如回答与产品相关的查询、分析行业新闻或解释客户反馈)时,LLM 往往会力不从心。要让它们真正发挥作用,您需要根据您的使用案例量身定制的高质量数据。
这些数据通常分布在网络上,隐藏在复杂的网站结构之后,或受到反僵尸措施的保护。
我们的自动工作流程通过简化的管道解决了这一问题,该管道可处理数据集创建过程中最棘手的部分:
- 网络数据提取。使用Bright Data大规模提取数据,利用其以人工智能为重点的基础设施绕过验证码和IP 屏蔽等挑战。
- 数据结构。使用Google Gemini将原始内容解析、清理并转换为结构良好的 JSON。
- 语义嵌入。将文本转换为向量嵌入,捕捉丰富的上下文含义。
- 存储与检索。在快速、可扩展的语义搜索数据库Pinecone 中建立矢量索引。
- 人工智能就绪输出。生成的高质量数据集可用于微调、RAG 或其他特定领域的人工智能应用。
核心技术概述
在构建管道之前,让我们快速了解一下所涉及的核心技术,以及每种技术如何支持工作流程。
光明数据可扩展的网络数据收集
创建人工智能就绪矢量数据集的第一步是收集相关的高质量源数据。虽然其中一些数据可能来自知识库或文档等内部系统,但很大一部分数据通常来自公共网络。
然而,现代网站使用了复杂的反机器人机制,如验证码、IP 速率限制和浏览器指纹识别,这使得大规模刮擦变得十分困难。
Bright Data通过其网络解锁器 API 解决了这一难题,该API 将数据收集的复杂性抽象化。它能自动处理代理旋转、验证码求解和浏览器模拟,让您完全专注于数据而不是如何访问数据。
谷歌双子座:智能内容转型
Gemini 是谷歌开发的一系列强大的多模态人工智能模型,擅长理解和处理各种类型的内容。在我们的数据提取管道中,Gemini 有三个关键功能:
- 内容解析:处理原始 HTML 内容,最好是经过清理的 Markdown 内容。
- 信息提取:根据预定义模式识别和提取特定数据点。
- 数据结构化:将提取的信息转换为简洁、结构化的 JSON 格式。
与依赖脆弱的 CSS 选择器或脆弱的正则表达式的传统方法相比,这种人工智能驱动的方法具有很大的优势,尤其是在诸如以下的使用案例中:
- 动态网页– 布局或 DOM 频繁变化的网页(常见于电子商务网站、新闻门户网站和其他高速域)。
- 非结构化内容:从长格式或组织不佳的文本块中提取结构化数据。
- 复杂的解析逻辑:避免了为每个网站或内容变化维护和调试自定义刮擦规则的需要。
要深入了解人工智能如何改变数据提取流程,请访问Using AI for Web Scraping。如果您正在寻找在您的抓取工作流程中实施 Gemini 的实践教程,请查看我们的综合指南:使用 Gemini 进行网络抓取。
句子转换器:生成语义嵌入
嵌入是文本(或其他数据类型)在高维空间中的密集向量表示。这些向量能捕捉语义,通过余弦相似度或欧几里得距离等度量标准,用相近的向量来表示相似的文本片段。这一特性对于语义搜索、聚类和检索增强生成(RAG)等应用非常重要,在这些应用中,查找相关内容取决于语义的接近程度。
Sentence Transformers库为生成高质量的句子和段落嵌入提供了一个易于使用的界面。它建立在 Hugging Face Transformers 的基础上,支持多种针对语义任务进行微调的预训练模型。
all-MiniLM-L6-v2 是这一生态系统中最受欢迎、最有效的型号之一。 这就是它脱颖而出的原因:
- 架构基于 MiniLM 架构,在保持强大性能的同时,对速度和尺寸进行了优化。
- 嵌入维度:将输入映射到 384 维向量空间,既高效又紧凑。
- 训练目标:使用对比学习方法对 10 亿多个句子对进行微调,以增强语义理解能力。
- 性能在句子相似性、语义聚类和信息检索等任务上取得最先进或接近最先进水平的结果。
- 输入长度:可处理多达 256 个词块(标记),较长的文本会自动截断–这在文本分块时是一个重要的考虑因素。
虽然更大的模型可能提供更细微的嵌入,但all-MiniLM-L6-v2在性能、效率和成本之间实现了出色的平衡。它的 384 维向量包括
- 计算速度更快。
- 资源消耗较少。
- 更易于存储和索引。
对于大多数实际用例,特别是在早期开发阶段或资源有限的环境中,这种模型绰绰有余。在边缘情况下,精确度的边际下降通常会被速度和可扩展性的显著提高所抵消。因此,在构建人工智能应用的第一次迭代时,或在适度的基础设施上优化性能时,建议使用all-MiniLM-L6-v2。
松果存储和搜索矢量嵌入
一旦文本转化为矢量嵌入,您就需要一个专门的数据库来高效地存储、管理和查询它们。传统数据库并非为此而设计–矢量数据库专门用于处理嵌入数据的高维特性,可进行实时相似性搜索,这对 RAG 管道、语义搜索、个性化和其他人工智能驱动的应用至关重要。
Pinecone是一种流行的矢量数据库,以其友好的开发人员界面、低延迟搜索性能和完全托管的基础架构而著称。它能有效管理复杂的矢量索引和大规模搜索,抽象出错综复杂的矢量搜索基础架构。其主要组件包括
- 索引:矢量的存储容器
- 向量:带有相关元数据的实际嵌入。
- 收集:用于备份和版本管理的索引静态快照。
- 命名空间:多租户索引内的数据分区。
Pinecone 提供两种部署架构:无服务器(Serverless)和基于 Pod 的部署架构。对于大多数使用案例,尤其是刚开始使用或处理动态负载时,由于其简单性和成本效益,无服务器是推荐的选择。
设置和先决条件
在构建管道之前,请确保以下组件已正确配置。
先决条件
- 系统中必须安装 Python 3.9 及以上版本
- 准备以下 API 凭证:
- Bright Data 的 API Key,以及 Web Unlocker 区域名称
- Google Gemini API Key
- Pinecone API Key
有关生成每个 API 密钥的说明,请参阅下面特定工具的设置部分。
安装所需程序库
为本项目安装 Python 核心库:
pip install requests python-dotenv google-generativeai sentence-transformers pinecone这些图书馆提供
请求:与应用程序接口交互的常用 HTTP 客户端(请求指南)python-dotenv:从环境变量中安全加载 API 密钥google-generativeai:谷歌官方双子座 SDK(也支持JavaScript、Go 和其他语言)句子转换器:生成语义向量嵌入的预训练模型pinecone:Pinecone 矢量数据库的 SDK(可用于 Python、Node.js、Go 等语言的 SDK)
配置环境变量
在项目根目录下创建.env文件,并添加 API 密钥:
BRIGHT_DATA_API_KEY="your_bright_data_api_key_here"
GEMINI_API_KEY="your_gemini_api_key_here"
PINECONE_API_KEY="your_pinecone_api_key_here"明亮数据设置
要使用 Bright Data 的网络解锁程序,请执行以下操作
- 创建应用程序接口令牌
- 从 Bright Data 面板设置网络解锁区
有关实施示例和集成代码,请访问Web Unlocker GitHub 代码库。
如果您仍在比较解决方案,本人工智能搜索工具比较可让您深入了解 Bright Data 与其他平台的比较情况。
双子座设置
生成双子座 API 密钥:
- 转到谷歌人工智能工作室
- 点击“+ 创建 API 密钥
- 复制密钥并妥善保存
提示:免费层足以满足开发和小规模测试的需要。对于生产用途,您可能需要更高的吞吐量(RPM/RPD)、更大的令牌窗口(TPM)或企业级隐私保护和访问高级模型,请参阅费率限制和定价计划。
松果设置
- 在 Pinecone.io 注册并登录
- 从控制台复制您的 API 密钥
- 创建新索引的步骤:
- 进入 Indexes 页面,点击 Create index
- 进行如下设置:
- Index Name(索引名称): 选择一个清晰易懂的名称(例如
semantic-search-index) - Vector Type(向量类型): 选择 Dense
- Dimensions(维度): 设置为与您的嵌入模型输出维度相匹配(如
all-MiniLM-L6-v2模型对应的384) - Metric(度量方式): 选择 cosine(可选:
euclidean或dotproduct) - Capacity Mode(容量模式): 使用 Serverless
- Cloud & Region(云环境和地区): 选择您偏好的云服务商及地区(例如 AWS
us-east-1)
- Index Name(索引名称): 选择一个清晰易懂的名称(例如
- 点击 Create index
设置完成后,您会看到索引状态显示为绿色,且初始记录数为零。

建立管道:逐步实施
现在,我们的前提条件已经配置完毕,让我们以沃尔玛的MacBook Air M1产品评论为例,构建我们的数据管道。
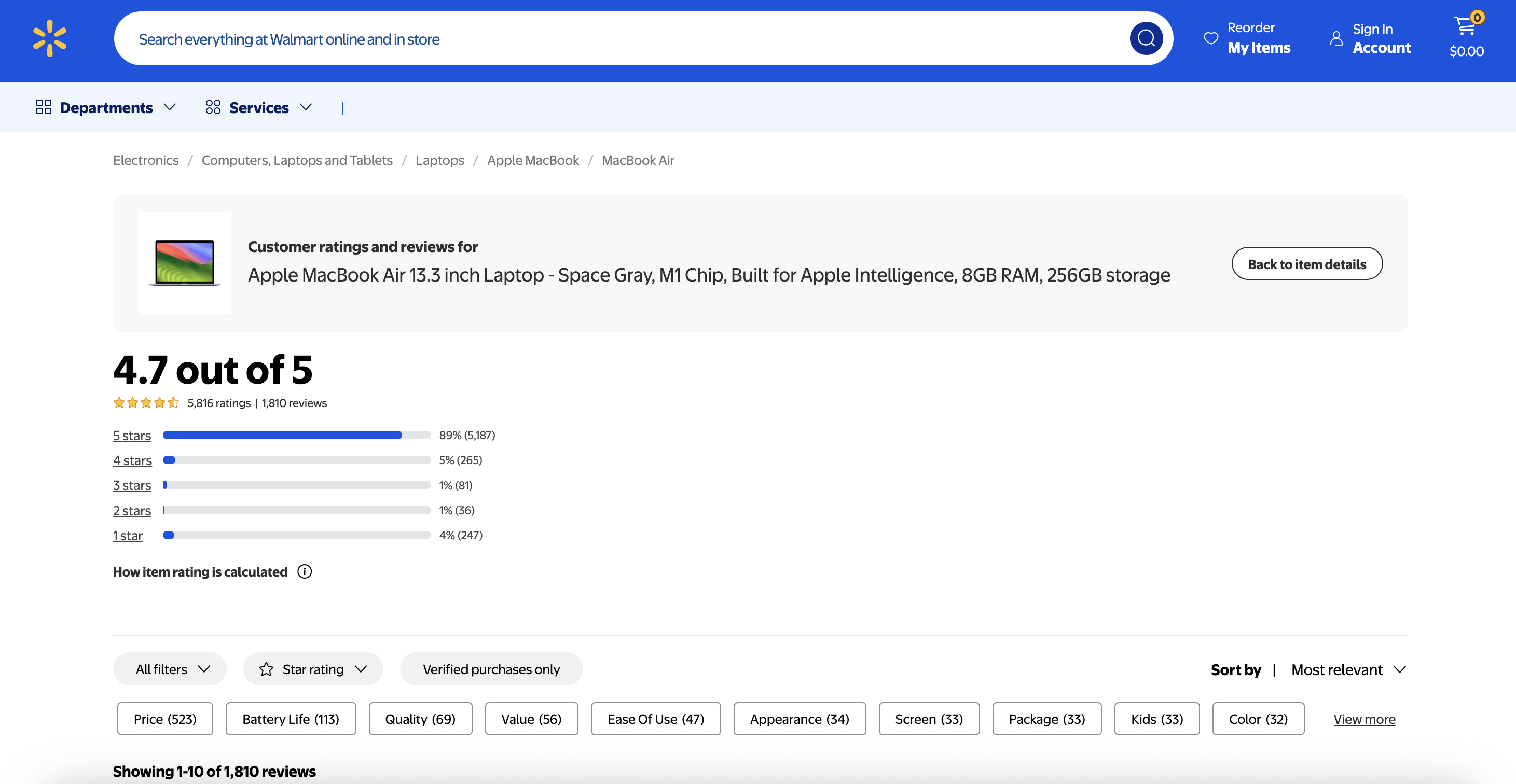
步骤 1:使用 Bright Data Web 解锁程序采集数据
我们管道的基础是从目标 URL 抓取原始 HTML 内容。Bright Data 的 Web Unlocker 擅长绕过沃尔玛等电子商务网站通常采用的复杂的反抓取措施。
让我们从获取网页内容的实现开始:
import requests
import os
from dotenv import load_dotenv
# Load API key from environment
load_dotenv()
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
def fetch_page(url: str) -> str:
"""Fetch page content using Bright Data Web Unlocker (Markdown format)"""
try:
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
},
json={
"zone": "web_unlocker2",
"url": url,
"format": "raw",
"data_format": "markdown", # Direct HTML-to-Markdown conversion
},
timeout=60,
)
if response.status_code == 200 and len(response.text) > 1000:
return response.text
except Exception as e:
print(f"Request failed: {str(e)}")
return None
# Example usage
walmart_url = "https://www.walmart.com/reviews/product/609040889?page=1"
page_content = fetch_page(walmart_url)
if page_content:
print(f"Success! Retrieved {len(page_content)} characters")
else:
print("Failed to fetch page")为什么使用 Markdown 而不是原始 HTML?在我们的管道中,我们请求 Markdown 格式(data_format: 'markdown')的内容有几个重要原因。Markdown 去掉了 HTML 标记、样式和其他杂音,降低了复杂性,只留下基本内容。这就大大减少了标记数,使 LLM 处理更加高效。它还以更简洁、更易读的格式保留了语义结构,从而提高了清晰度和处理速度。嵌入生成和矢量索引等操作也变得更快、更轻。
有关现代人工智能代理为何青睐 Markdown 的更多信息,请阅读《为什么新的人工智能代理选择 Markdown 而不是 HTML》。
步骤 2:处理分页
沃尔玛将产品评论分布在多个页面上。要捕获完整的数据集,需要实施分页处理。您需要
- 创建正确的页面 URL(
?page=1、?page=2等) - 获取每个页面的内容
- 检测是否有“下一页 “页面
- 继续,直到没有更多页面可用
下面是一个简单的分页循环,它可以获取内容,直到找不到page=n+1引用为止:
current_page = 1
while True:
url = f"https://www.walmart.com/reviews/product/609040889?page={current_page}"
page_content = fetch_page(url)
if not page_content:
print(f"Stopping at page {current_page}: fetch failed or no content.")
break
# Do something with the fetched content here
print(f"Fetched page {current_page}")
# Check for presence of next page reference
if f"page={current_page + 1}" not in page_content:
print("No next page found. Ending pagination.")
break
current_page += 1步骤 3:使用 Google 双子座提取结构化数据
有了上一步中干净的 Markdown 内容,现在我们将使用 Google 双子座从评论中提取特定信息,并将其结构化为 JSON。这样就能将非结构化文本转化为有组织的数据,我们的矢量数据库就能有效地索引这些数据。
我们将使用gemini-2.0 闪存型号,它为我们的使用案例提供了令人印象深刻的规格:
- 输入语境:1,048,576 个 token
- 输出限制:8,192 个代币
- 多模式支持:文本、代码、图像、音频和视频
在我们的案例中,沃尔玛评论页面的标记符文本通常包含约 3000 个标记符,完全在模型的限制范围内。这意味着我们可以一次性发送整个页面,而无需将其分割成小块。
如果你的文档超过了上下文窗口的容量,你就需要实施分块策略。但对于典型的网页,Gemini 的容量使其没有必要这样做。
下面是一个使用 Gemini 以结构化 JSON 格式提取评论的 Python 函数示例:
import google.generativeai as genai
import json
# Initialize Gemini with JSON output configuration
model = genai.GenerativeModel(
model_name="gemini-2.0-flash",
generation_config={"response_mime_type": "application/json"},
)
def extract_reviews(markdown: str) -> list[dict]:
"""Extract structured review data from Markdown using Gemini."""
prompt = f"""
Extract all customer reviews from this Walmart product page content.
Return a JSON array of review objects with the following structure:
{{
"reviews": [
{{
"date": "YYYY-MM-DD or original date format if available",
"title": "Review title/headline",
"description": "Review text content",
"rating": <integer from 1–5>
}}
]
}}
Rules:
- Include all reviews found on the page
- Use null for any missing fields
- Convert ratings to integers (1–5)
- Extract the full review text, not just snippets
- Preserve original review text without summarizing
Here's the page content:
{markdown}
"""
response = model.generate_content(prompt)
result = json.loads(response.text)
# Normalize and clean results
return [
{
"date": review.get("date"),
"title": review.get("title"),
"description": review.get("description", "").strip(),
"rating": review.get("rating"),
}
for review in result.get("reviews", [])
]在使用 LLM 时,及时的工程设计是关键。在我们的实现中,我们设置了response_mime_type:"application/json",以确保 Gemini 返回有效的 JSON 格式,从而无需进行复杂的文本解析。提示本身经过精心设计,指示 Gemini 完全依赖所提供的内容,以减少幻觉。它还执行严格的 JSON 模式以确保结构一致性,保留完整的评论文本而不进行摘要,并优雅地处理缺失字段。
处理沃尔玛评论页面后,您将收到这样的结构化数据:
[
{
"date": "Apr 13, 2026",
"title": "Better than buying OPEN BOX",
"description": "I bought an older product OPEN BOX (which I consider UNUSED) from another website. The battery was dead. Walmart offered NEW at a lower price. WOW!!!!",
"rating": 5
},
{
"date": "Dec 8, 2024",
"title": "No support",
"description": "The young man who delivered my laptop gave me the laptop with no receipt or directions. I asked where my receipt and some kind of manual were. He said it would be under my purchases. I would happily change this review if I knew where to go for help and support. The next day I went to the electronics department for help, and he had no idea.",
"rating": 3
}
// ... more reviews
]有关结合所有步骤(获取、处理和提取)的工作示例,请查看GitHub 上的完整实现。
步骤 4:利用句子变换器生成向量嵌入
有了干净、结构化的 JSON 格式评论数据,我们现在可以为每条评论生成语义向量嵌入。这些嵌入将用于下游任务,如语义搜索或在 Pinecone 等矢量数据库中编制索引。
为了捕捉客户评论的完整语境,我们在嵌入前将评论标题和描述合并为一个字符串。这有助于模型更有效地对情感和主题进行编码。
下面是示例代码:
from sentence_transformers import SentenceTransformer
# Load the embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
def generate_embeddings(reviews):
"""Generate 384-dimensional vector embeddings from review titles and descriptions."""
texts = []
valid_indices = []
# Combine title and description into a single string for embedding
for idx, review in enumerate(reviews):
text_parts = []
if review.get("title"):
text_parts.append(f"Review Title: {review['title']}")
if review.get("description"):
text_parts.append(f"Review Description: {review['description']}")
if text_parts:
texts.append(". ".join(text_parts))
valid_indices.append(idx)
# Generate embeddings using batch processing
embeddings = model.encode(
texts, show_progress_bar=True, batch_size=32, convert_to_numpy=True
).tolist()
# Attach embeddings back to original review objects
for emb_idx, review_idx in enumerate(valid_indices):
reviews[review_idx]["embedding"] = embeddings[emb_idx]
return reviews该代码的作用
- 模型初始化:加载
all-MiniLM-L6-v2模型,该模型返回 384 维度的稠密向量。 - 输入预处理:将每条评价的
title与description合并为一个字符串。 - 批量编码(Batch Encoding):使用
model.encode()进行批量处理,以提升效率:batch_size=32:在速度和内存使用之间取得平衡show_progress_bar=True:在编码过程中显示进度条convert_to_numpy=True:将输出转换为 NumPy 数组,便于后续操作
- 向量注入(Embedding Injection):将每个向量附加回对应的评价对象中,并存储在
"embedding"键值下。
重要提示:Pinecone 不支持元数据中的空值。如果缺少任何字段,在上传到 Pinecone 时必须完全省略该关键字。请勿使用"N/A "或空字符串,除非它们在您的过滤逻辑中具有特定含义。
虽然这里没有显示清除功能(以保持代码的可读性),但最终的实现将包括摄取前的元数据清理。
嵌入生成后,每个评论对象都包含一个 384 维的向量:
{
"date": "Apr 9, 2024",
"title": "Amazing Laptop!",
"description": "This M1 MacBook Air is incredibly fast and the battery lasts forever.",
"rating": 5,
"embedding": [0.0123, -0.0456, 0.0789, ..., 0.0345] // 384 dimensions
}嵌入生成后,我们的评论就可以在 Pinecone 中进行矢量存储了。
步骤 5:在松果中存储嵌入和元数据
最后一步是将嵌入式评论上传到 Pinecone。
以下是向 Pinecone 上载数据的 Python 代码:
import uuid
from pinecone import Pinecone, Index
# Initialize Pinecone client with your API key
pc = Pinecone(api_key="PINECONE_API_KEY")
index = pc.Index("brightdata-ai-dataset") # Replace with your actual index name
# Sample review data (with embeddings already attached)
reviews_with_embeddings = [
{
"date": "Apr 9, 2024",
"title": "Amazing Laptop!",
"description": "This M1 MacBook Air is incredibly fast and the battery lasts forever.",
"rating": 5,
"embedding": [0.0123, -0.0456, ..., 0.0789], # 384-dimensional vector
}
# ... more reviews
]
# Prepare vector records for upload
vectors = []
for review in reviews_with_embeddings:
if "embedding" not in review:
continue # Skip entries without embeddings
vectors.append(
{
"id": str(uuid.uuid4()), # Unique vector ID
"values": review["embedding"],
"metadata": {
"title": review.get("title"),
"description": review.get("description"),
"rating": review.get("rating"),
# Add more metadata fields if needed
},
}
)
# Batch upload to Pinecone (100 vectors per request)
for i in range(0, len(vectors), 100):
batch = vectors[i : i + 100]
index.upsert(vectors=batch)您上载到 Pinecone 的每个矢量都应包括
id:唯一字符串标识符(必填)值:矢量本身(浮点数列表,例如 384 维)元数据:用于筛选和上下文的可选键值对(与 JSON 兼容)
向量结构示例:
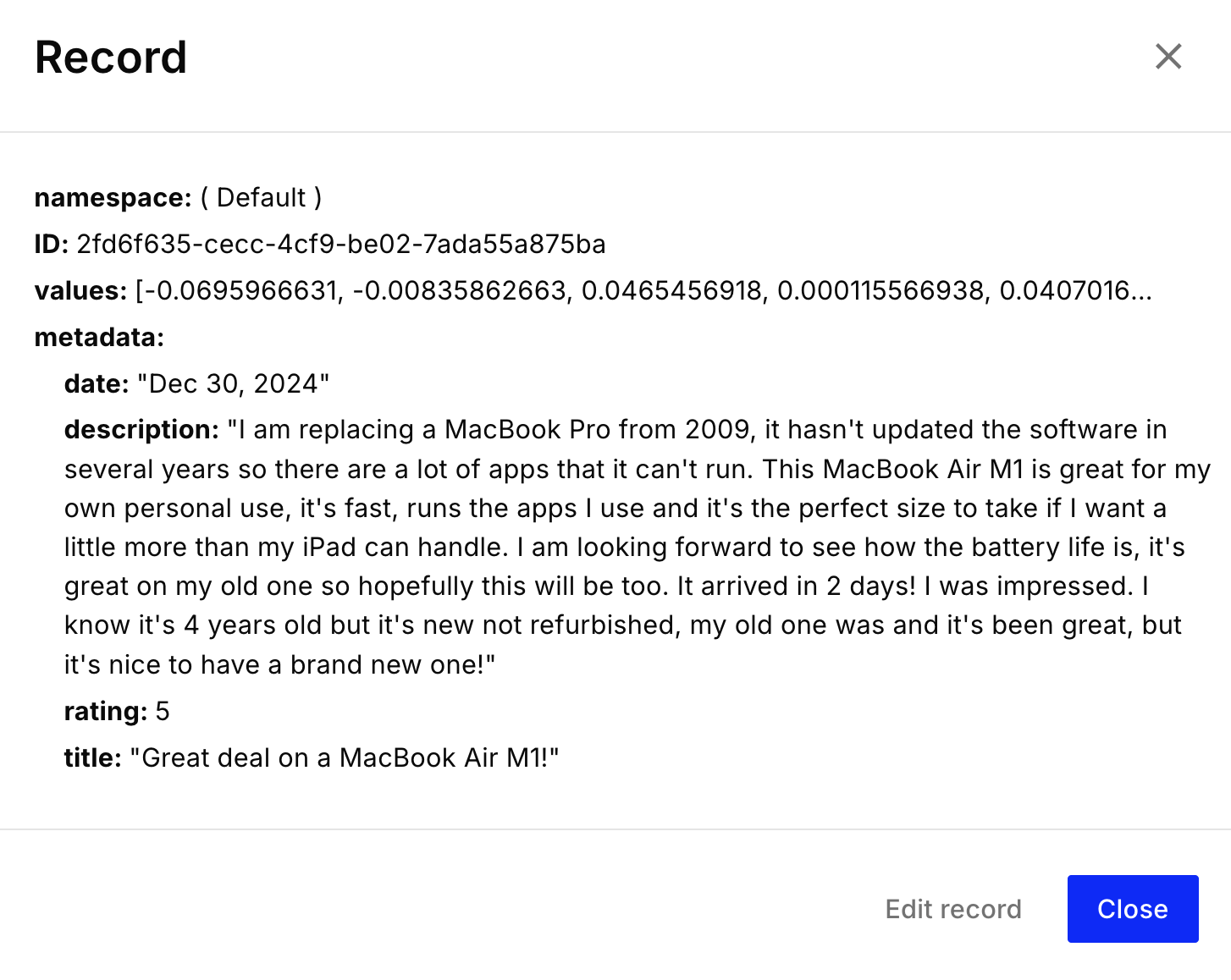
上传完成后,您的 Pinecone 索引中就会出现审查矢量:
您的人工智能就绪矢量数据集已存储在 Pinecone 中,可以进行下一步操作 🔥
有关结合所有步骤(嵌入生成、Pinecone 上传)的工作示例,请查看GitHub 上的完整实现。
(可选但建议)利用人工智能就绪数据集
有了 Pinecone 中的嵌入索引,您就可以为语义搜索和 RAG 系统等应用提供支持。本步骤展示了如何查询矢量数据库并生成智能响应。
语义搜索
利用矢量化数据集的最简单方法就是语义搜索。与关键字搜索不同,语义搜索允许用户使用自然语言进行查询,并检索概念上相似的内容,即使它们不共享相同的单词。
让我们用自然语言查询来测试一下该系统:
queries = [
"good price for students",
"lightweight and good for travel",
]对于 “学生的好价格 “这一查询,您可能会看到:
#1 (Score: 0.6201)
ID: 75878bdc-8d96-416a-8292-484971c3bd61
Date: Aug 3, 2024
Rating: 5.0
Description: Just what my daughter needed for college and the price was perfect
#2 (Score: 0.5868)
ID: 758963ae-0927-4e82-bece-d098991f5a73
Date: Jun 13, 2024
Rating: 5.0
Description: The price was right. Perfect graduation present for my grandson🙌它运行良好!自然语言查询会返回高度相关的结果。
这就是语义搜索的工作原理:
- 查询嵌入:使用与索引相同的
全 MiniLM-L6-v2模型将搜索查询转换为矢量。 - 向量搜索Pinecone 使用余弦相似度查找最相似的向量。
- 元数据检索:结果包括相似性得分和相关元数据。
有关完整的工作实现,请查看语义搜索客户端Python 文件。
超越搜索:检索增强生成(RAG)
一旦语义搜索开始工作,您就离建立一个由 LLM 驱动的 RAG 系统仅一步之遥了。检索增强生成(RAG)可让您的 LLM 利用外部上下文(如您的矢量化数据集)生成接地气的响应。
RAG 流程:
- 用户提问(如“这款 MacBook 适合大学生使用吗?)
- 语义搜索可从 Pinecone 中检索相关文件。
- 检索到的上下文和问题会被发送到像 Google Gemini 这样的 LLM。
- LLM 用你的数据集中的事实做出回应。
RAG 答复示例:
🤔 User: Is the battery life good for college use?
🤖 Assistant: Yes, users report long battery life—enough to last through full days of classes and study.
🤔 User: How does this compare to a Chromebook?
🤖 Assistant: One review says the MacBook Air "works so smoothly compared to a Chromebook".查看用于 RAG 和语义搜索的完整代码:RAG 聊天机器人实现。
下一步工作
您已经成功建立了一个完整的管道,用于创建可用于人工智能的矢量数据集。下面介绍如何扩展和优化您的实施:
- 大规模数据采集:对于更广泛的数据需求,请探索 Bright Data 的完整AI-Ready Web 数据基础架构,以实现针对 AI 模型和代理优化的无限、合规 Web 数据访问。
- 尝试嵌入模型:虽然
all-MiniLM-L6-v2效率很高,但在某些使用案例中,换用更大或多语言模型可能会获得更好的效果。您还可以尝试嵌入来自Google Gemini和OpenAI 的 API。 - 完善提取提示:针对需要提取的不同网站结构或数据模式,定制 Gemini 提示。
- 利用高级 Pinecone 功能:深入Pinecone 官方文档,探索过滤、命名空间、元数据索引和混合搜索。
- 将管道自动化:使用 Apache Airflow 或 Prefect 等工具进行协调,使用 AWS Step Functions 或 Google Cloud Workflows 等工具进行云原生调度,将此管道集成到生产工作流中。
- 构建人工智能驱动的应用程序:使用语义搜索或 RAG 组件创建真实世界的工具,如客户支持聊天机器人、知识库搜索和推荐引擎。
结论
您已经成功构建了一个完整、强大的管道,用于创建和管理人工智能就绪向量数据集,将原始网络数据转化为大型语言模型的宝贵资产。通过将 Bright Data(用于可扩展的网络搜刮)、Google Gemini(用于智能结构化提取)、Sentence Transformers(用于生成语义嵌入)和 Pinecone(用于矢量存储和检索)结合起来,您已经有效地准备好了您的自定义数据,以增强 LLM 应用程序。
这种方法使 LLM 具备特定领域的知识,从而提供更准确、更相关、更有价值的人工智能解决方案。
更多阅读和资源
探索这些资源,加深对人工智能、法学硕士和网络数据提取的理解:
- RAG & 聊天机器人:
- AI & 网络爬虫技巧:
- 微调 & 数据集:
- 核心概念:



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





