

传统的网页爬取方法在网站布局变化或反爬措施变得更加严格时往往会失效。在本指南中,您将学习一种更具弹性且由 LLaMA 3(Meta 强大的开源大语言模型)驱动的网页爬取新方法,来从几乎任何网站提取结构化数据并将其转换为干净、可用的 JSON。
让我们开始吧。
为什么使用 LLaMA 3 进行网页爬取?
LLaMA 3(于 2024 年 4 月发布)是 Meta 的开源大语言模型,参数规模从 8B 到 405B 不等,以满足各种不同的应用场景和硬件需求。随后推出的 LLaMA 3.1、3.2 和 3.3 显著提升了模型的性能与对上下文的理解能力。
传统的网页爬取方法主要依赖于像 XPath 与 CSS 这样的静态选择器,一旦网站结构发生变化,这些选择器就很容易失效。与之相对,LLaMA 3 能够通过类人理解的方式来解析内容,从而进行智能化数据提取。
这使它非常适合以下场景:
- 适应诸如 Amazon 等电商网站那些布局和元素经常改变的页面
- 解析复杂且非结构化的 HTML
- 减少为每个网站编写定制数据解析逻辑的需求
- 构建更具稳定性的爬虫,不会因网站更新而轻易崩溃
- 将爬取到的数据保存在内部环境中——这对敏感信息而言至关重要
详细了解 如何使用 AI 进行网页爬取。
先决条件
在开始 使用 LLM 进行网页爬取之前,请确保您具备以下条件:
- 已安装 Python 3
- 具有基本的 Python 知识(无需大师级别)
- 兼容的操作系统: – macOS(需要 macOS 11 Big Sur 或更高版本) – Linux – Windows(需要 Windows 10 或更高版本)
- 足够的硬件资源(详见下文中的模型选择说明)
安装 Ollama
Ollama 是一个轻量级工具,可简化本地下载、配置和运行大型语言模型。
开始使用:
- 访问 Ollama 官方网站
- 下载并安装适合您操作系统的应用程序
- 重要:在安装过程中,Ollama 会提示您运行一个终端命令——暂时不要运行。我们先选择合适的模型版本。
选择您的 LLaMA 模型
首先浏览 Ollama 的模型库,从中选择最符合您硬件和用例需求的 LLaMA 版本。
对大多数用户而言,llama3.1:8b 在性能和效率之间达到了最佳平衡。该模型轻量且功能强大,约占用 4.9 GB 的磁盘空间和 6–8 GB 的 RAM,大多数现代笔记本电脑都能运行。
如果您使用的机器功能更强,且需要更高的推理能力或更长的上下文长度,可考虑使用更大模型,如 70B 或 405B。但这类模型需要更多的内存和计算能力。
拉取并运行模型
若要下载并初始化 LLaMA 3.1(8B)模型,运行以下命令:
ollama run llama3.1:8b模型下载完成后,您将看到一个简单的交互式提示:
>>> Send a message (/? for help)您可以先用一个简单的查询来测试模型:
>>> who are you?
I am LLaMA, *an AI assistant developed by Meta AI...*出现类似上方的成功响应就说明模型已安装配置完成。输入 /bye 即可退出提示。
接下来,运行以下命令来启动 Ollama 服务器:
ollama serve该命令会在 http://127.0.0.1:11434/ 启动一个本地主机上的 Ollama 实例。请保持该终端窗口打开,服务器必须在后台持续运行。
若要验证是否成功运行,可在浏览器中打开该 URL——页面应显示“Ollama is running”。
构建基于 LLM 的亚马逊爬虫
在本节中,我们将构建一个从亚马逊网站提取商品详情的爬虫——由于其 动态内容和严格的反爬策略,亚马逊一直被认为是最具挑战性的目标之一。

我们将提取的主要信息包括:
- 商品标题
- 当前/原价
- 折扣
- 评分与评论
- 商品描述与功能列表
- 库存情况及 ASIN
AI 驱动的多阶段工作流程
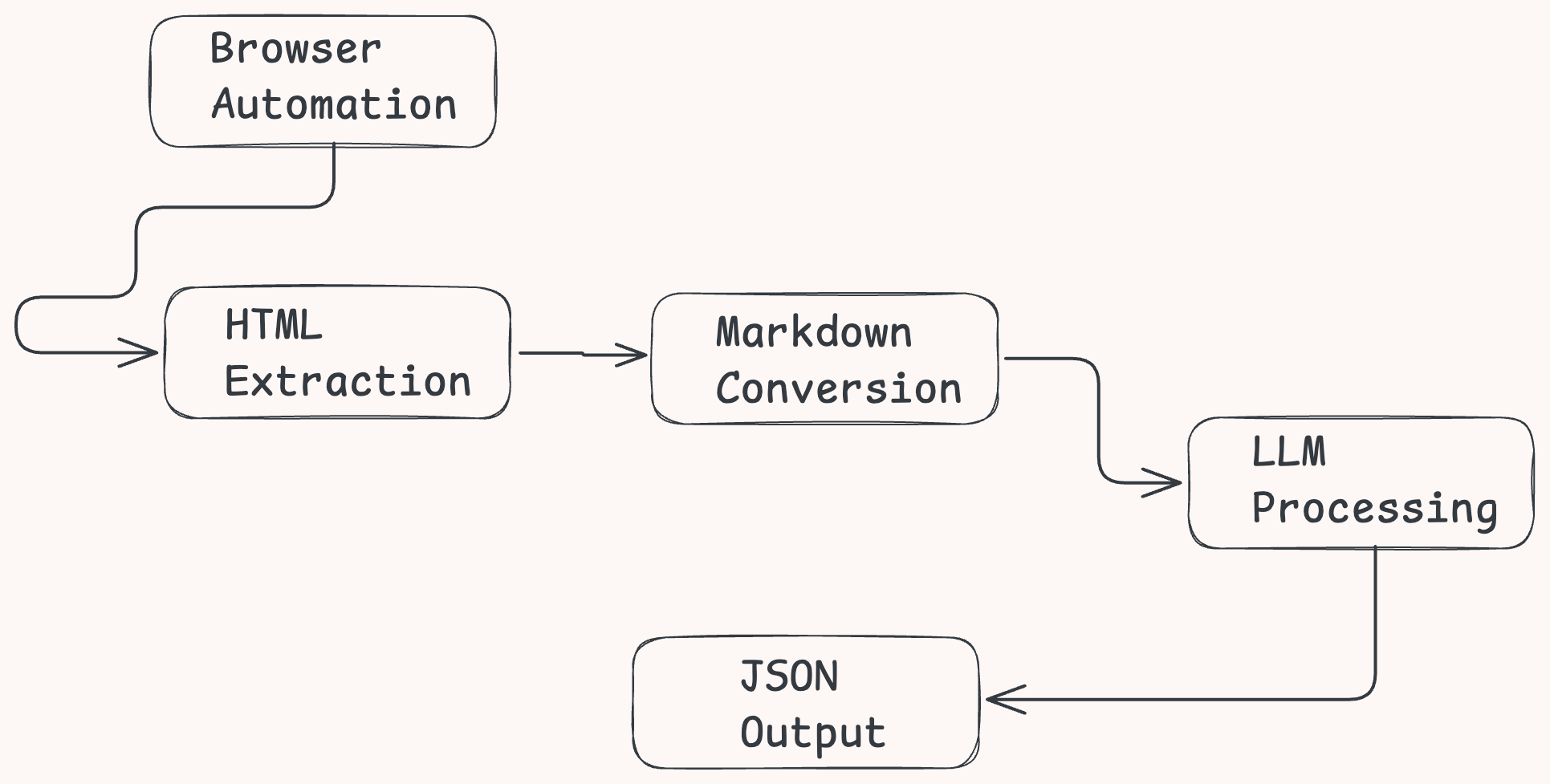
为了克服传统爬取方式的局限性——尤其是面对像亚马逊这样复杂的电商网站,我们的 LLaMA 驱动的爬虫将采用一个智能、多步骤的工作流程:
- 浏览器自动化 – 使用 Selenium 加载页面并渲染动态内容
- HTML 提取 – 寻找并获取包含商品详情的容器
- Markdown 转换 – 将 HTML 转换成 Markdown,以减少 Token 数量并提升 LLM 效率
- LLM 处理 – 使用 LLaMA 的结构化提示提取干净、结构化的 JSON
- 输出处理 – 将提取到的 JSON 存储以供下游使用或分析
以下是该流程的可视化示意图:
接下来让我们逐步演示整个过程。需要注意的是,示例使用的是 Python,因为它简单且流行,但您也可使用 JavaScript 或其它语言实现类似的功能。
Step 1 —— 安装所需库
首先,安装所需的 Python 库:
pip install requests selenium webdriver-manager markdownifyrequests– 优秀的 Python HTTP 客户端,用来向 LLM 服务发送 API 请求selenium– 自动化浏览器,非常适合处理 JavaScript 内容丰富的网站webdriver-manager– 自动下载并管理相应版本的 ChromeDrivermarkdownify– 将 HTML 转换为 Markdown
Step 2 —— 初始化无头浏览器
使用 Selenium 设置一个无头浏览器:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)Step 3 —— 获取商品 HTML
亚马逊商品详情是动态渲染的,且被包裹在 <div id="ppd"> 容器中。我们会等待这部分内容加载完毕后再提取其 HTML:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 15)
product_container = wait.until(
EC.presence_of_element_located((By.ID, "ppd"))
)
# Extract the full HTML of the product container
page_html = product_container.get_attribute("outerHTML")这样做可以:
- 等待 JavaScript 渲染的内容(如价格和评分)
- 只针对与商品相关的核心区域,忽略页头、页尾和侧边栏
参考我们的完整指南:如何使用 Python 爬取亚马逊商品数据。
Step 4 —— 将 HTML 转换为 Markdown
亚马逊页面往往包含深度嵌套的 HTML,直接给 LLM 处理会效率很低。一个关键的优化是将其转换为简洁的 Markdown,从而大幅降低 Token 数量并提升模型理解能力。
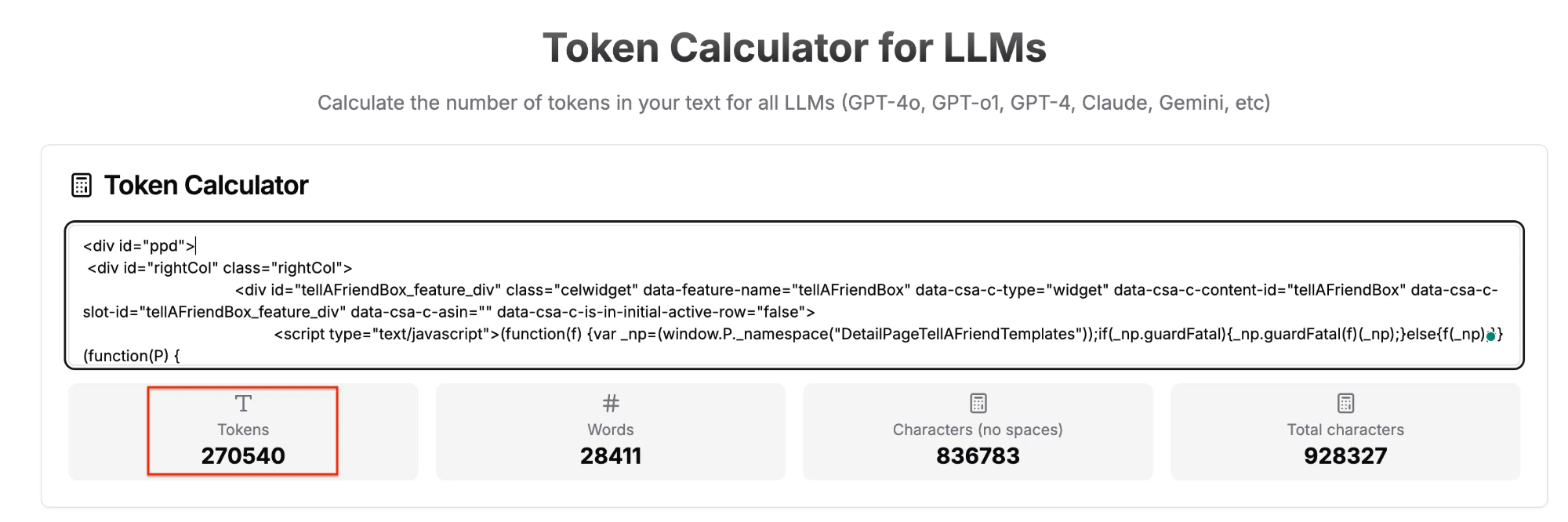
运行完整脚本后,会生成两个文件:amazon_page.html 和 amazon_page.md。您可以将它们分别粘贴到 Token Calculator Tool 中比较 Token 数量。
如下所示,HTML 约含有 270,000 个 token:
而 Markdown 版本仅为 ~11,000 个 token:
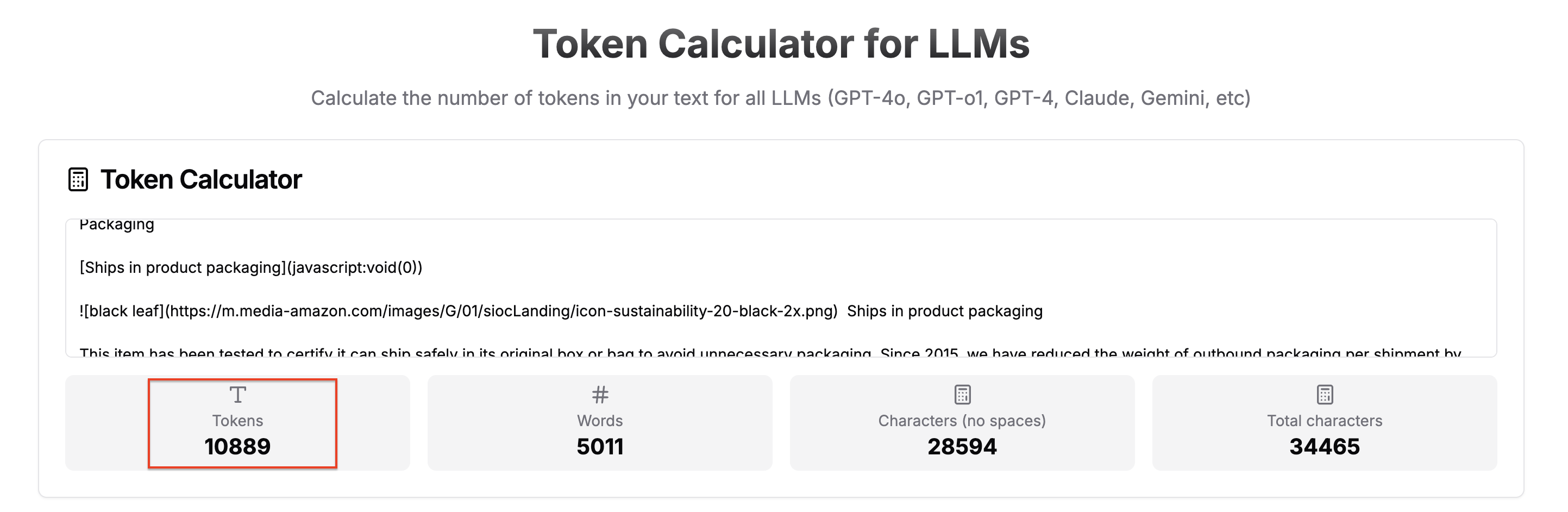
这意味着 96% 的减少,由此带来的好处包括:
- 成本更低 —— Token 更少意味着更低的 API 或计算费用
- 处理更快 —— 输入数据量更小,LLM 响应更快
- 准确率更高 —— 更干净、更平坦的文本能帮助模型更精准地提取结构化数据
了解更多:为什么新的 AI Agent 更倾向使用 Markdown 而非 HTML。
如下即为在 Python 中完成转换的示例:
from markdownify import markdownify as md
clean_text = md(page_html, heading_style="ATX")Step 5 —— 创建数据提取 Prompt
想要从 LLM 获取一致且干净的 JSON 输出,必须设计好一个结构化的 Prompt。下面的示例提示会指示模型只返回与指定格式严格匹配的有效 JSON:
PROMPT = (
"You are an expert Amazon product data extractor. Your task is to extract product data from the provided content. "
"Return ONLY valid JSON with EXACTLY the following fields and formats:nn"
"{n"
' "title": "string – the product title",n'
' "price": number – the current price (numerical value only)",n'
' "original_price": number or null – the original price if available,n'
' "discount": number or null – the discount percentage if available,n'
' "rating": number or null – the average rating (0–5 scale),n'
' "review_count": number or null – total number of reviews,n'
' "description": "string – main product description",n'
' "features": ["string"] – list of bullet point features,n'
' "availability": "string – stock status",n'
' "asin": "string – 10-character Amazon ID"n'
"}nn"
"Return ONLY the JSON without any additional text."
)Step 6 —— 调用 LLM API
在本地运行着 Ollama 的情况下,您可以通过其 HTTP API,将 Markdown 文本发送至 LLaMA 实例:
import requests
import json
response = requests.post(
"<http://localhost:11434/api/generate>",
json={
"model": "llama3.1:8b",
"prompt": f"{PROMPT}nn{clean_text}",
"stream": False,
"format": "json",
"options": {
"temperature": 0.1,
"num_ctx": 12000,
},
},
timeout=250,
)
raw_output = response.json()["response"].strip()
product_data = json.loads(raw_output)选项说明:
temperature—— 设置为 0.1 可使输出更具确定性(适合 JSON 格式)num_ctx—— 定义最大上下文长度。这里的 12,000 token 足以覆盖大多数亚马逊商品页面stream—— 当设为False时,API 会在处理完成后返回完整响应format—— 指定输出格式(JSON)model—— 指示要使用的 LLaMA 版本
由于转换后的 Markdown 通常包含大约 11,000 个 token,因此一定要相应地设置上下文窗口(num_ctx)。若想处理更长的输入,可以增大该值,但这会增加内存占用并降低处理速度。只有当商品页面特别长或您有足够的计算资源时,才建议调大该值。
Step 7 —— 保存结果
最后,将提取的商品数据保存为 JSON 文件:
with open("product_data.json", "w", encoding="utf-8") as f:
json.dump(product_data, f, indent=2, ensure_ascii=False)Step 8:执行脚本
若要运行爬虫,只需提供一个亚马逊商品链接并调用爬虫函数:
if __name__ == "__main__":
url = "<https://www.amazon.com/Black-Office-Chair-Computer-Adjustable/dp/B00FS3VJAO>"
# Call your function to scrape and extract product data
scrape_amazon_product(url)Step 9 —— 完整示例代码
以下是完整的 Python 脚本示例,将所有步骤组合在一起,实现从头到尾的完整流程:
import json
import logging
import time
from typing import Final, Optional, Dict, Any
import requests
from markdownify import markdownify as html_to_md
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
# Configuration constants
LLM_API_CONFIG: Final[Dict[str, Any]] = {
"endpoint": "<http://localhost:11434/api/generate>",
"model": "llama3.1:8b",
"temperature": 0.1,
"context_window": 12000,
"stream": False,
"timeout_seconds": 220,
}
DEFAULT_PRODUCT_DATA: Final[Dict[str, Any]] = {
"title": "",
"price": 0.0,
"original_price": None,
"discount": None,
"rating": None,
"review_count": None,
"description": "",
"features": [],
"availability": "",
"asin": "",
}
PRODUCT_DATA_EXTRACTION_PROMPT: Final[str] = (
"You are an expert Amazon product data extractor. Your task is to extract product data from the provided content. "
"Return ONLY valid JSON with EXACTLY the following fields and formats:nn"
"{n"
' "title": "string - the product title",n'
' "price": number - the current price (numerical value only),n'
' "original_price": number or null - the original price if available,n'
' "discount": number or null - the discount percentage if available,n'
' "rating": number or null - the average rating (0-5 scale),n'
' "review_count": number or null - total number of reviews,n'
' "description": "string - main product description",n'
' "features": ["string"] - list of bullet point features,n'
' "availability": "string - stock status",n'
' "asin": "string - 10-character Amazon ID"n'
"}nn"
"Return ONLY the JSON without any additional text."
)
# Configure logging
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler()],
)
def initialize_web_driver(headless: bool = True) -> webdriver.Chrome:
"""Initialize and return a configured Chrome WebDriver instance."""
options = Options()
if headless:
options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
return webdriver.Chrome(service=service, options=options)
def fetch_product_container_html(product_url: str) -> Optional[str]:
"""Retrieve the HTML content of the Amazon product details container."""
driver = initialize_web_driver()
try:
logging.info(f"Accessing product page: {product_url}")
driver.set_page_load_timeout(15)
driver.get(product_url)
# Wait for the product container to appear
container = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.ID, "ppd"))
)
return container.get_attribute("outerHTML")
except Exception as e:
logging.error(f"Error retrieving product details: {str(e)}")
return None
finally:
driver.quit()
def extract_product_data_via_llm(markdown_content: str) -> Optional[Dict[str, Any]]:
"""Extract structured product data from markdown text using LLM API."""
try:
logging.info("Extracting product data via LLM API...")
response = requests.post(
LLM_API_CONFIG["endpoint"],
json={
"model": LLM_API_CONFIG["model"],
"prompt": f"{PRODUCT_DATA_EXTRACTION_PROMPT}nn{markdown_content}",
"format": "json",
"stream": LLM_API_CONFIG["stream"],
"options": {
"temperature": LLM_API_CONFIG["temperature"],
"num_ctx": LLM_API_CONFIG["context_window"],
},
},
timeout=LLM_API_CONFIG["timeout_seconds"],
)
response.raise_for_status()
raw_output = response.json()["response"].strip()
# Clean JSON output if it's wrapped in markdown code blocks
if raw_output.startswith(("```json", "```")):
raw_output = raw_output.split("```")[1].strip()
if raw_output.startswith("json"):
raw_output = raw_output[4:].strip()
return json.loads(raw_output)
except requests.exceptions.RequestException as e:
logging.error(f"LLM API request failed: {str(e)}")
return None
except json.JSONDecodeError as e:
logging.error(f"Failed to parse LLM response: {str(e)}")
return None
except Exception as e:
logging.error(f"Unexpected error during data extraction: {str(e)}")
return None
def scrape_amazon_product(
product_url: str, output_file: str = "product_data.json"
) -> None:
"""Scrape an Amazon product page and save extracted data along with HTML and Markdown to files."""
start_time = time.time()
logging.info(f"Starting scrape for: {product_url}")
# Step 1: Fetch product page HTML
product_html = fetch_product_container_html(product_url)
if not product_html:
logging.error("Failed to retrieve product page content")
return
# Optional: save HTML for debugging
with open("amazon_product.html", "w", encoding="utf-8") as f:
f.write(product_html)
# Step 2: Convert HTML to Markdown
product_markdown = html_to_md(product_html)
# Optional: save Markdown for debugging
with open("amazon_product.md", "w", encoding="utf-8") as f:
f.write(product_markdown)
# Step 3: Extract structured data via LLM
product_data = (
extract_product_data_via_llm(product_markdown) or DEFAULT_PRODUCT_DATA.copy()
)
# Step 4: Save JSON results
try:
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=2, ensure_ascii=False)
logging.info(f"Successfully saved product data to {output_file}")
except IOError as e:
logging.error(f"Failed to save JSON results: {str(e)}")
elapsed_time = time.time() - start_time
logging.info(f"Completed in {elapsed_time:.2f} seconds")
if __name__ == "__main__":
# Example usage
test_url = (
"<https://www.amazon.com/Black-Office-Chair-Computer-Adjustable/dp/B00FS3VJAO>"
)
scrape_amazon_product(test_url)脚本运行成功后,会将提取到的商品数据保存到名为 product_data.json 的文件中。输出大致如下:
{
"title": "Home Office Chair Ergonomic Desk Chair Mesh Computer Chair with Lumbar Support Armrest Executive Rolling Swivel Adjustable Mid Back Task Chair for Women Adults, Black",
"price": 36.98,
"original_price": 41.46,
"discount": 11,
"rating": 4.3,
"review_count": 58112,
"description": 'Office chair comes with all hardware and tools, and is easy to assemble in about 10–15 minutes. The high-density sponge cushion offers flexibility and comfort, while the mid-back design and rectangular lumbar support enhance ergonomics. All components are BIFMA certified, supporting up to 250 lbs. The chair includes armrests and an adjustable seat height (17.1"–20.3"). Its ergonomic design ensures a perfect fit for long-term use.',
"features": [
"100% mesh material",
"Quick and easy assembly",
"High-density comfort seat",
"BIFMA certified quality",
"Includes armrests",
"Ergonomic patented design",
],
"availability": "In Stock",
"asin": "B00FS3VJAO",
}就是这样!杂乱无章的 HTML 由 LLM 变成了整洁的 JSON 数据。
应对反爬措施
在运行上述 网页爬虫时,您很可能会遇到亚马逊的各种反爬手段,如 CAPTCHA 验证:
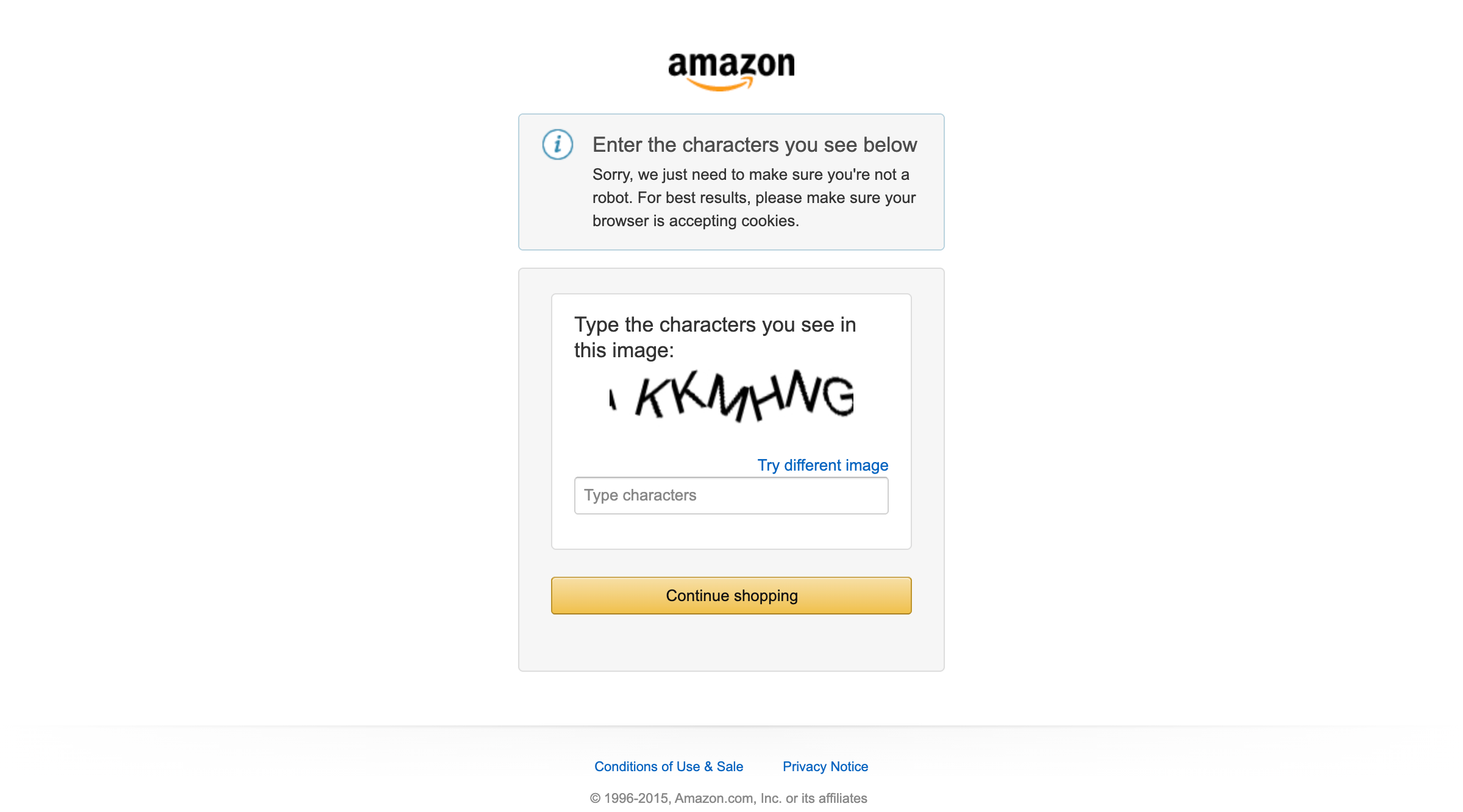
这凸显了一个重要的限制:虽然我们基于 LLaMA 的流程在解析 HTML 方面表现出色,但在访问部分内容时,仍然需要应对这些更复杂的反爬机制。
要想成功绕过这类 亚马逊 CAPTCHA 问题以及其它类似的网页爬取挑战,您需要额外的技术支持。
这就是 Bright Data 抓取浏览器的用武之地——一款专门针对现代网络环境而设计的解决方案,能够覆盖几乎所有形态的网站;相比传统工具,更轻松地应对复杂的反爬策略。
了解更多:抓取浏览器与无头浏览器对比
为何选择 Bright Data 抓取浏览器
Bright Data 抓取浏览器是一个云端、无头浏览器,内置代理基础设施和强大的自动化解封(unblocking)能力——专为现代大规模爬虫而设计。它是 Bright Data Unlocker 爬取套件的一部分。
开发者和数据团队选择它的原因包括:
- 可靠的 TLS 指纹与高级隐藏(stealth)技术
- 基于拥有逾 1.5 亿 IP 地址的代理网络自动切换 IP
- 自动解决 CAPTCHA
- 减少基础设施成本 – 无需昂贵的云端部署与繁琐维护
- 原生支持 Playwright、Puppeteer 与 Selenium
- 大规模并发数据采集能力
最妙的是,您只需几行代码就能将其整合进现有的工作流程。
了解更多企业 为何转向云端网页爬取。
配置抓取浏览器
如需使用抓取浏览器:
创建一个 Bright Data 账户(新用户在添加支付方式后会获得 5 美元信用额度),进入仪表板并点击 “Proxies & Scraping” 的 “Get started”。
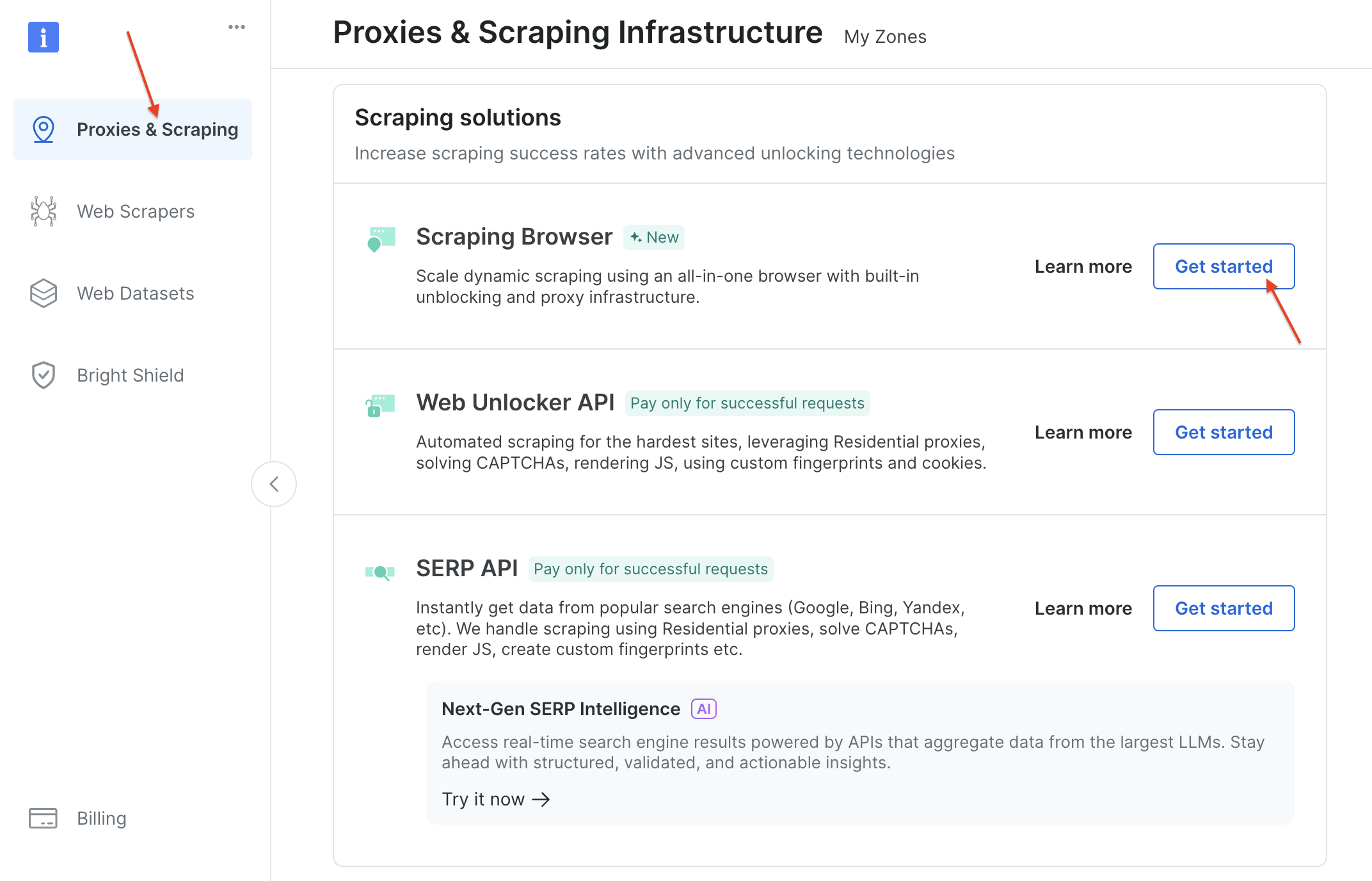
创建一个新的 Zone(例如 test_browser),并启用 Premium domains 和 CAPTCHA solver 等功能。
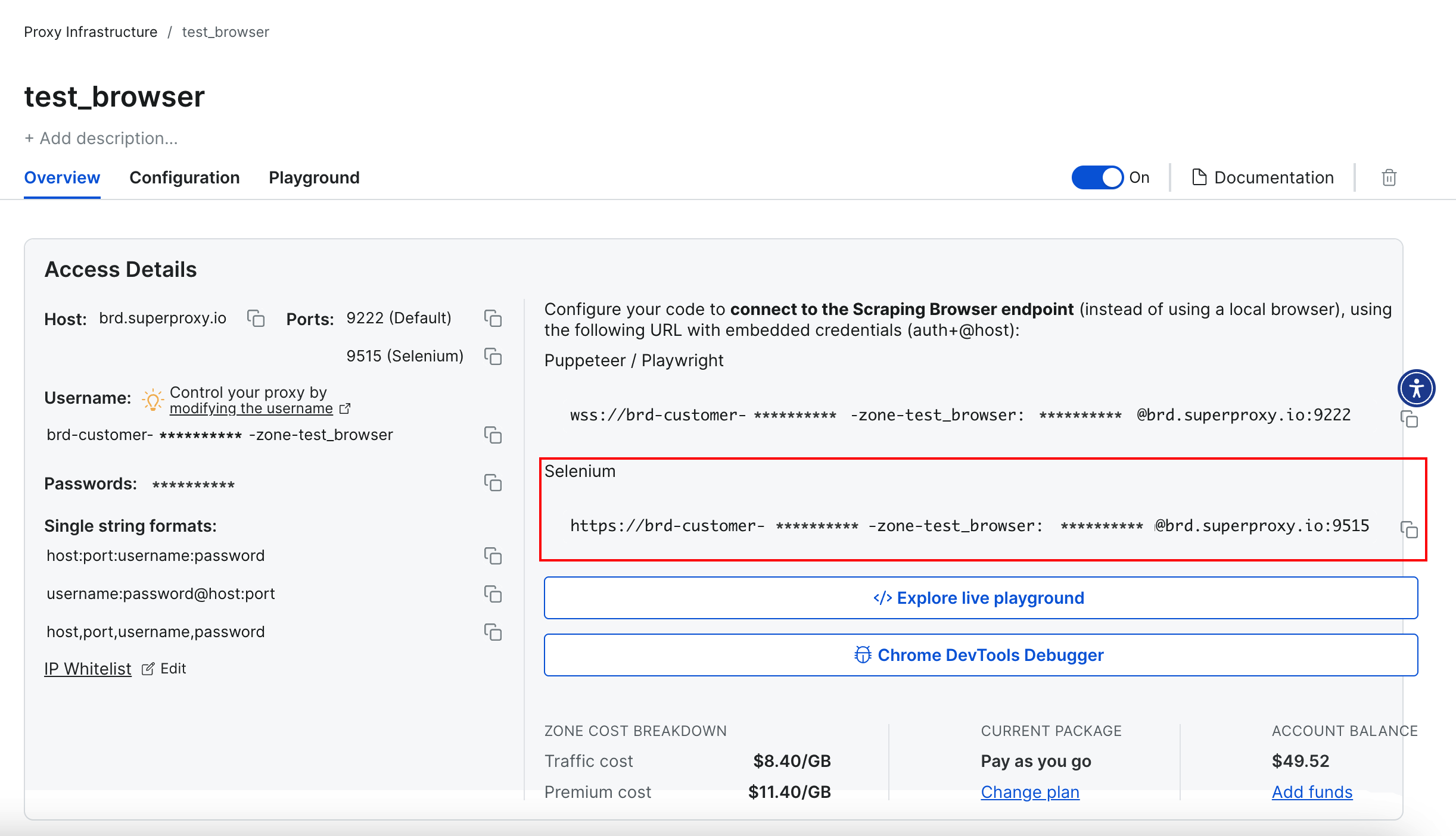
接着,在仪表板中复制用于 Selenium 连接的 URL。
修改代码以使用抓取浏览器
在 initialize_web_driver 函数中增加对抓取浏览器的连接:
from selenium.webdriver import Remote
from selenium.webdriver.chrome.options import Options as ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = "<https://username:password@host>:port"
def initialize_web_driver():
options = ChromeOptions()
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
driver = Remote(sbr_connection, options=options)
return driver这就完成了——您的爬虫现在可通过 Bright Data 的基础设施进行访问,并能轻松应对亚马逊及其它反爬措施。
更多高级功能可在抓取浏览器 文档中查看。
后续步骤与可替代方案
若想扩展您的 LLaMA 爬虫功能,或探索其它实现方式,可考虑以下改进和替代方案:
- 让脚本更可复用:把 URL 和提示信息作为命令行参数,使脚本适应更多场景
- 保护凭证安全:将抓取浏览器凭证存储在
.env文件中,并通过python-dotenv安全加载 - 添加多页支持:编写逻辑以爬取多个页面并处理分页
- 爬取更多网站 – 借助抓取浏览器的防检测功能,爬取其它电商平台
- 从 Google 服务中提取数据 – 可搭建专门的爬虫来爬取 Google Flights、Google Search、Google Trends;或者直接使用 Bright Data 的 SERP API 获取现成的搜索数据
如果您更青睐托管式解决方案或想试试其它 LLM 驱动的方法,可参考以下文章:
结论
本指南为您介绍了如何使用 LLaMA 3 构建具有高鲁棒性的网页爬虫。通过将大型语言模型的推理能力与先进的爬取工具结合,您可以更加轻松地从复杂的网站中提取出结构化数据。
在网页爬取中,规避识别与封锁是最具挑战的一环。Bright Data 抓取浏览器可以帮助应对这一难题,自动处理动态渲染、指纹识别和反爬保护。它属于一个更广泛的工具套件,专门为大规模数据提取提供支持:
- 代理服务 – 通过 1.5 亿+的住宅 IP 绕过地理区域限制
- 网络抓取APIs – 针对 100+ 个热门网站的专用端点来获取结构化数据
- 网络解锁器 API – 从任何 URL 获取完整渲染的 HTML,绕过反爬系统
- SERP API – 从各大搜索引擎实时采集搜索结果
立即注册,免费试用 Bright Data 全套爬取与代理工具吧!



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





