

在本文中,你将了解:
- 什么是 Anthropic 的 Web Fetch 工具及其主要限制。
- 它的工作原理。
- 如何在 cURL 与 Python 中使用它。
- Bright Data 提供哪些方案以实现类似目标。
- Anthropic Web Fetch 工具与 Bright Data 网络数据工具如何对比。
- 一张总结表,便于快速对比。
开始吧!
什么是 Anthropic Web Fetch 工具?
Anthropic 的 Web Fetch 工具允许 Claude 模型从网页和 PDF 文档中检索内容。该工具在 2026-09-10 的 Claude 测试版中免费推出。
在 Claude API 请求中包含此工具后,所配置的 LLM 可以从指定的网页或 PDF URL 获取并分析全文。这为 Claude 提供了最新、基于来源的信息,以生成更有依据的回答。
注意事项与限制
以下是与 Anthropic Web Fetch 工具相关的主要注意事项与限制:
- 在 Claude API 上可用且无需额外费用。你只需为被纳入会话上下文的抓取内容支付标准 Token 费用。
- 可从指定网页和 PDF 文档中获取完整内容。
- 当前处于测试阶段,需要设置测试版请求头
web-fetch-2026-09-10。 - Claude 无法动态构造 URL。你必须显式提供完整 URL,或者仅能使用此前通过网页搜索或抓取得到的 URL。
- 只能抓取已出现在会话上下文中的 URL。这包括来自用户消息、客户端工具结果,或之前的网页搜索与抓取结果中的 URL。
- 仅适用于以下模型:Claude Opus 4.1(
claude-opus-4-1-20260805)、Claude Opus 4(claude-opus-4-20260514)、Claude Sonnet 4.5(claude-sonnet-4-5-20260929)、Claude Sonnet 4(claude-sonnet-4-20260514)、Claude Sonnet 3.7(claude-3-7-sonnet-20260219)、Claude Sonnet 3.5 v2(已弃用)(claude-3-5-sonnet-latest)、Claude Haiku 3.5(claude-3-5-haiku-latest)。 - 不支持由 JavaScript 动态渲染的网站。
- 可选支持为抓取内容添加引用。
- 支持提示缓存(prompt caching),以在多轮对话中复用缓存结果。
- 支持
max_uses、allowed_domains、blocked_domains、max_content_tokens参数。 - 常见错误码包括:
invalid_input、url_too_long、url_not_allowed、url_not_accessible、too_many_requests、unsupported_content_type、max_uses_exceeded、unavailable。
Claude 模型中的 Web Fetch 工作原理
当你在 API 请求中添加 Anthropic Web Fetch 工具时,幕后会发生如下过程:
- Claude 会根据提示与提供的 URL 决定是否进行抓取。
- API 从指定 URL 检索全文内容。
- 对于 PDF,会自动执行文本提取。
- Claude 分析抓取内容并生成回答,可选择性包含引用。
生成的回答随后返回给用户,或被加入对话上下文以便进一步分析。
如何使用 Anthropic Web Fetch 工具
使用该工具的两种主要方式,是在请求中为受支持的 Claude 模型启用它。可以通过以下任一方式:
- 直接调用Anthropic API。
- 通过任一Claude 客户端 SDK,例如 Anthropic Python API 库。
接下来演示如何操作!
在这两种情况下,我们都将演示如何使用 Web Fetch 工具抓取Anthropic 首页,如下图所示:

前置条件
使用 Anthropic Web Fetch 工具的主要要求是拥有一个Anthropic API Key。这里假设你已有 Anthropic 账户及对应的 API Key。
通过直接 API 调用
通过向受支持模型发起Anthropic API 的直接请求启用 Web Fetch 工具,示例如下(cURL POST 请求):
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
"tools": [{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'注意,claude-sonnet-4-5-20260929 是受 Web Fetch 工具支持的模型之一。
同时需要两个特殊请求头:anthropic-version 与 anthropic-beta。
要在所配置的模型中启用 Web Fetch 工具,你必须在请求体的 tools 数组中加入如下项:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}type 与 name 字段是关键,max_uses 为可选,用于定义在单次迭代内最多可调用该工具的次数。
将 <YOUR_ANTHROPIC_API_KEY> 替换为你的真实 Anthropic API Key。随后执行请求,你应能得到类似如下的结果:
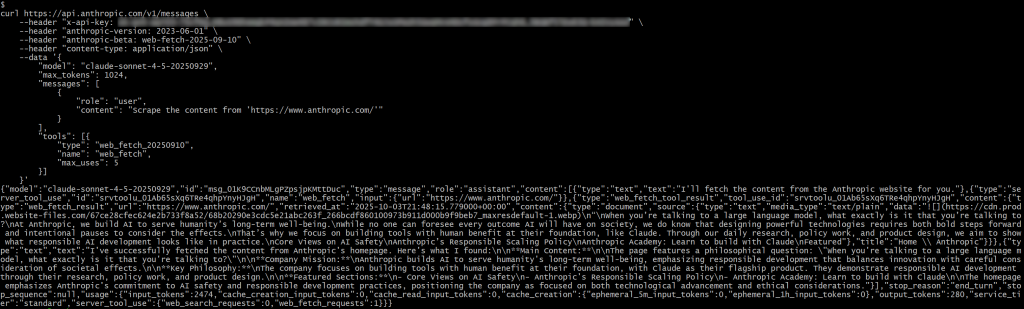
在响应中,你会看到:
{"type":"server_tool_use","id":"srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH","name":"web_fetch","input":{"url":"https://www.anthropic.com/"}}这表明 LLM 执行了一次对 web_fetch 工具的调用。
具体而言,该工具产生的结果类似于:

“When you’re talking to a large language model, what exactly is it that you’re talking to?
At Anthropic, we build AI to serve humanity’s long-term well-being.
While no one can foresee every outcome AI will have on society, we do know that designing powerful technologies requires both bold steps forward and intentional pauses to consider the effects.
That’s why we focus on building tools with human benefit at their foundation, like Claude. Through our daily research, policy work, and product design, we aim to show what responsible AI development looks like in practice.
Core Views on AI Safety
Anthropic’s Responsible Scaling Policy
Anthropic Academy: Learn to build with Claude
Featured这代表了目标 URL 首页的一种“类 Markdown”版本。之所以说“类”,是因为有些链接被省略了,且除第一张图片外,输出主要聚焦文本——这正是 Web Fetch 工具的设计目标。
注意:整体结果较为准确,但确实遗漏了一些内容,可能在工具处理过程中丢失。事实上,原页面包含的文本比抓取结果更多。
使用 Anthropic Python API 库
或者,你也可以通过Anthropic Python API 库调用 Web Fetch 工具:
# pip install anthropic
import anthropic
# Replace it with your Anthropic API key
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
# Initialize the Anthropic API client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Perform a request to Claude with the web fetch tool enabled
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
# Print the result produced by the AI in the terminal
print(response.content)这一次,结果如下:
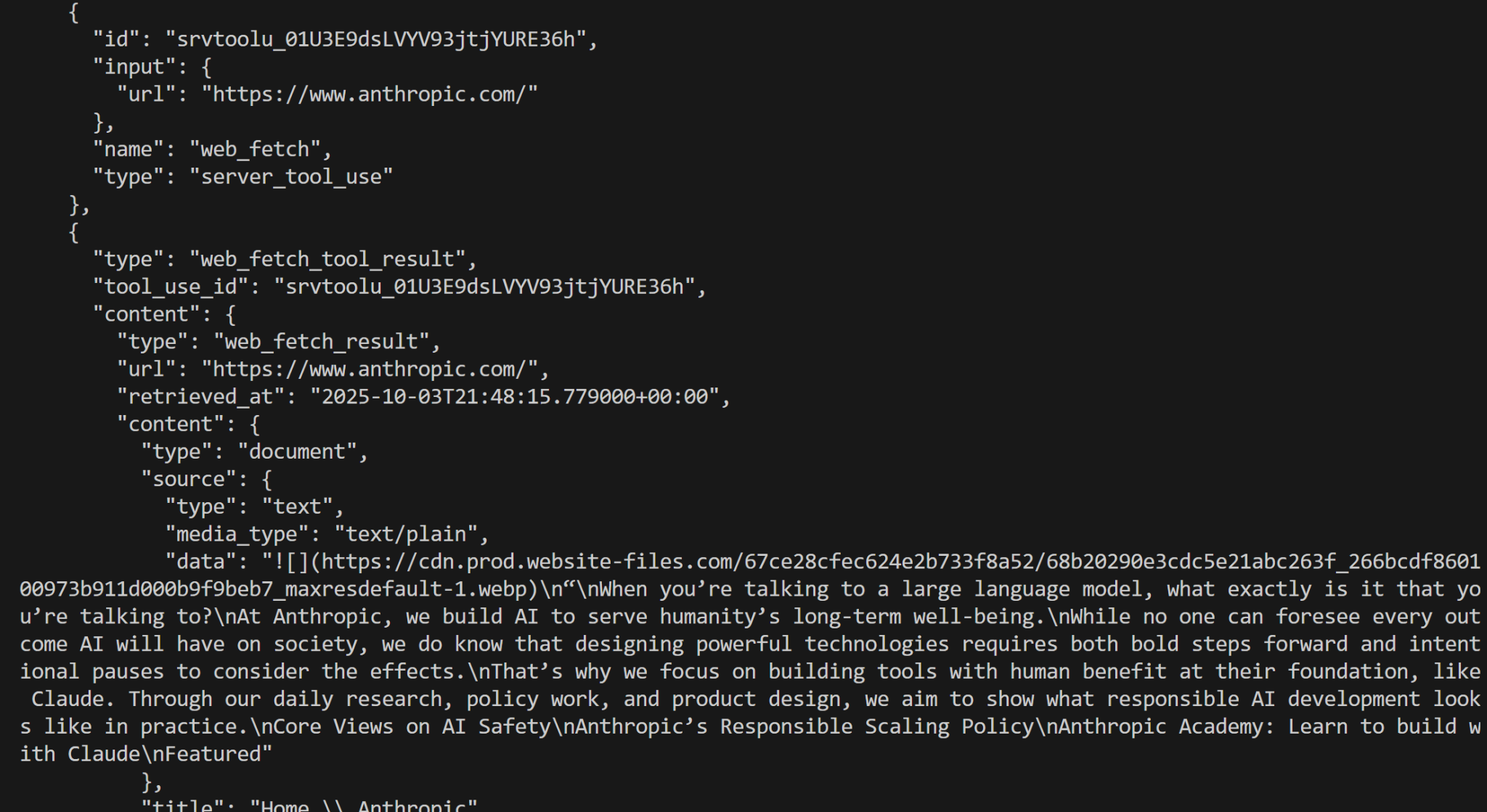
不错!这与前面的结果等效。
Bright Data 网络数据工具简介
Bright Data AI 基础设施提供丰富的解决方案,让你的 AI 可以自由搜索、抓取与浏览整个网络。包括:
- Unlocker API:可靠地从任意公开 URL 获取内容,自动绕过封禁并解决验证码。
- Crawl API:轻松抓取并抽取整站内容,输出为对 LLM 友好的格式,便于推理与分析。
- SERP API:收集实时、带地域属性的搜索引擎结果,为特定查询发现相关数据源。
- Browser API:让你的 AI 与动态站点交互,并使用远程隐身浏览器大规模自动化代理式工作流。
在 Bright Data 的众多网页数据检索工具、服务与产品中,我们将聚焦于Web MCP。它在 Bright Data 产品之上提供了可直接集成 AI 的工具,能与 Anthropic 提供的能力直接对比。请注意,Web MCP 也可作为Claude MCP 使用,能够与任何 Anthropic 模型完整集成。
在60+ 款可用工具中,scrape_as_markdown 是最契合对比的那一个。它可使用高级内容提取选项抓取单个网页 URL,并以 Markdown 格式返回结果。该工具可访问任何网页,即使其使用了机器人检测或验证码。
重要的是,该工具在 Web MCP 的免费层也可用,意味着你可以零成本使用。因此,它能实现与 Anthropic Web Fetch 工具类似的网页数据检索功能,非常适合直接对比。
Anthropic Web Fetch 工具 vs Bright Data 网络数据工具
本节我们将构建一个流程,对比 Anthropic Web Fetch 工具与 Bright Data 的网络数据工具。具体包括:
- 通过 Anthropic Python API 库使用 Web Fetch 工具。
- 使用 LangChain MCP 适配器连接 Bright Data 的 Web MCP(其他受支持集成也完全可行)。
我们将在相同的提示与相同 Claude 模型下,对以下四个输入 URL 同时运行这两种方案:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
这四个页面很好地覆盖了你可能希望 AI 自动抓取的真实场景:网站首页、G2 产品页、亚马逊商品页以及公开的 LinkedIn 个人资料。需要指出的是,G2 因为Cloudflare 保护而出了名地难抓,因此特意纳入比较。
让我们看看两种工具的表现!
前置条件
在开始本节前,你应具备:
- 本地已安装 Python。
- 一个 Anthropic API Key。
- 一个带 API Key 的 Bright Data 账户。
要注册 Bright Data 账户并生成 API Key,请遵循官方指南。也建议先阅读Web MCP 官方文档。
此外,了解LangChain 集成的工作机制,以及熟悉 Web MCP 提供的工具,会很有帮助。
Web Fetch 工具集成脚本
要在选定的输入 URL 上通过 Anthropic Web Fetch 工具运行,你可以编写如下 Python 逻辑:
# pip install anthropic
import anthropic
Replace it with your Anthropic API key
ANTHROPIC_API_KEY = ""
Initialize the Anthropic API client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": f"Scrape the content from '{url}'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)然后,你可以这样对某个输入 URL 调用该函数:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")Bright Data 网络数据工具集成脚本
Web MCP 可与多种技术集成,详见我们的博客。这里我们演示与 LangChain 的集成,因为它简单且广受欢迎。
在开始之前,建议阅读教程:“使用 Bright Data 的 Web MCP 集成 LangChain MCP 适配器”。
在本例中,你应得到如下 Python 代码片段:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# Replace with your API keys
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# Agent task description
input_prompt = f"Scrape the content from '{url}'"
# Execute the request in the agent, stream the response, and return it as a string
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
async def main():
# Initialize the LLM engine
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Configuration to connect to a local Bright Data Web MCP server instance
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Optionally set to "true" for Pro mode
}
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the MCP client session
await session.initialize()
# Get the Web MCP tools
tools = await load_mcp_tools(session)
# Create the ReAct agent with Web MCP integration
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())该脚本定义了一个可使用 Web MCP 工具的ReAct 代理。
请记住:Web MCP 提供专业模式(Pro),可访问高级工具。本例并不强制需要 Pro 模式,因此你可以只使用免费层工具。免费工具包含 scrape_as_markdown,足以完成本次基准测试。
简而言之,从成本角度看,免费模式下使用 Web MCP 的费用不会超过 Claude 模型本身的 Token 使用(两种方案相同)。本方案的成本结构与直接通过 API 连接 Claude 基本一致。
基准测试结果
现在,使用如下逻辑分别运行代表两种 AI 网页数据检索方法的两个函数:
# Where to store the benchmark results
benchmark_results = []
# The input URLs to test the two approaches against
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Test each URL
for url in urls:
print(f"Testing the two approaches on the following URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url": url,
"anthropic": {
"execution_time": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Export the benchmark data
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)结果可总结如下表:
| Anthropic Web Fetch 工具 | Bright Data 网络数据工具 | |
|---|---|---|
| Anthropic 首页 | ✔️(部分文本信息) | ✔️(完整 Markdown 信息) |
| G2 评价页面 | ❌(工具约 10 秒后失败) | ✔️(页面的完整 Markdown 版本) |
| 亚马逊商品页 | ✔️(部分文本信息) | ✔️(完整 Markdown 版本,或在 Pro 模式下返回结构化 JSON 商品数据) |
| LinkedIn 个人资料页 | ❌(工具立即失败) | ✔️(完整 Markdown 版本,或在 Pro 模式下返回结构化 JSON 资料数据) |
如你所见,Anthropic 的 Web Fetch 工具不仅不如 Bright Data 的网络数据工具有效,即便成功运行,产出的结果也不够完整。
Anthropic 工具主要聚焦文本,而 Web MCP 中的 scrape_as_markdown 等工具会返回完整的页面 Markdown。此外,借助 web_data_amazon_product 等 Pro 工具,你还能从亚马逊等热门网站获得结构化数据源。
总体而言,在准确性与执行时间上,Bright Data 网络数据工具都是明显的赢家!
总结:对比表
| Anthropic Web Fetch 工具 | Bright Data 网络数据工具 | |
|---|---|---|
| 内容类型 | 网页、PDF | 网页 |
| 能力 | 文本提取 | 内容抽取、网页抓取、网站爬取等 |
| 输出 | 以纯文本为主 | Markdown、JSON 及其他对 LLM 友好的格式 |
| 模型集成 | 仅适用于特定 Claude 模型 | 可与任意 LLM 完整集成,并支持70+ 技术 |
| 对 JS 渲染站点的支持 | ❌ | ✔️ |
| 反机器人与验证码处理 | ❌ | ✔️ |
| 成熟度 | 测试版 | 生产可用 |
| 批量请求支持 | ✔️ | ✔️ |
| 代理集成 | 仅限 Claude 相关方案 | ✔️(适用于任何支持 MCP 或官方 Bright Data 工具的 AI 代理构建方案) |
| 可靠性与完整性 | 内容不完整;复杂页面可能失败 | 完整内容抽取;可处理复杂站点与带防护的页面 |
| 成本 | 仅标准 Token 费用 | 免费模式仅标准 Token 费用;Pro 模式有额外成本 |



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




