
在本教程中,你将学到:
- 什么是 Cursor,以及它为何如此受欢迎。
- 为何要为 Cursor 添加像 Bright Data 这样的「改变游戏规则」的 MCP 服务器。
- 如何将 Cursor 连接到 Bright Data Web MCP。
- 如何在 Visual Studio Code 中实现同样的效果。
开始吧!
什么是 Cursor?
Cursor 是基于 Visual Studio Code 分叉而来的 AI 驱动代码编辑器。与任何文本编辑器一样,它的核心功能是提供编写代码的界面。但它的特别之处在于深度内置了 AI 集成。
Cursor 不只是基础的自动补全,它使用 LLMs 理解你的整个代码库与上下文,从而提供智能特性,例如:
- 对话式提示:用自然语言描述你的需求,Cursor 会为你编写或编辑代码。
- 多行自动补全:不仅补全单行,还能建议并完成整段代码块。
- AI 驱动的重构:基于项目全局上下文,智能优化、清理并修复你的代码。
- 调试协助:请 AI 查找并解释代码中的错误。
Cursor 将标准代码编辑器变成一个主动、智能的结对程序员。它支持来自多家供应商的多种 LLM,并内置了通过 MCP 使用工具的支持。
为什么要将 Bright Data 的 Web MCP 添加到 Cursor
在幕后,Cursor 依赖已知的 LLM 模型。尽管其集成比大多数工具更深入、更完善,但它仍然面临与任何 LLM 相同的核心限制:AI 的知识是静态的!
毕竟,AI 训练数据只是在某个时间点的快照。尤其在软件开发这类快速演进的领域,它很快就会过时。现在,想象一下,让Cursor 的 AI agent具备以下能力:
- 为RAG 工作流拉取最新的教程与文档,
- 在编写代码时参考实时指南,
- 像浏览本地文件一样轻松浏览实时网站。
这正是将 Cursor 连接到Bright Data 的 Web MCP后所解锁的能力!
Web MCP 提供对60+ 个面向 AI 的工具的访问,这些工具为实时网页交互与数据采集而构建,且由强大的 Bright Data AI 基础设施驱动。
即使在免费层,你的 Cursor agent 也能使用两个强大工具:
| 工具 | 描述 |
|---|---|
search_engine |
以 JSON 或 Markdown 形式从 Google、Bing 或 Yandex 获取搜索结果。 |
scrape_as_markdown |
将任意网页抓取为干净的 Markdown 格式,绕过机器人检测和 CAPTCHA。 |
除此之外,Web MCP 还包含用于云端浏览器自动化,以及从 Amazon、YouTube、LinkedIn、TikTok、Google 地图等平台提取结构化数据的工具。
以下是将 Cursor 与 Bright Data 的 Web MCP 扩展后能实现的部分示例:
- 获取最新的 API 参考或框架教程,然后自动生成可运行的代码或项目脚手架。
- 即时抓取最新搜索引擎结果,并将其嵌入文档或代码注释。
- 采集实时网页数据,生成逼真的测试 mock、分析仪表盘或自动化内容管线。
想要了解完整能力范围,请查阅 Bright Data MCP 文档。
如何将 Web MCP 集成到 Cursor,增强 AI 编码体验
本节将逐步演示如何将本地运行的 Bright Data Web MCP 服务器实例连接到 Cursor。完成后,你将在 IDE 内直接使用 60+ 个工具,获得超强 AI 体验。
我们将使用 Web MCP 工具创建一个 Express 后端,构建一个返回来自 Amazon 的真实世界数据的模拟 API。这只是该集成所支持的众多用例之一。
按以下步骤操作!
前置条件
要跟随本教程,请确保你具备:
- 一个 Cursor 账户(免费计划即可)。
- 一个拥有有效 API Key 的 Bright Data 账户。
现在无需着急完成 Bright Data 的设置。阅读过程中会一步步引导你!
对MCP 的工作方式、Cursor 的运行机制以及 Web MCP 提供的工具有基本了解会有所帮助。
步骤一:开始使用 Cursor
安装适用于你操作系统的Cursor 版本,打开并登录你的账户。
若是首次启动,请完成引导向导。
你将看到类似这样的界面:
很好!现在打开你的项目文件夹,准备使用集成了 Web MCP 的内置 AI 编码助手。
步骤二:配置你的 LLM
撰写本文时,Cursor 默认使用 Claude 4.5 模型(通过“Auto” 模式)。如果你不介意,直接跳到下一节即可。请记住,Claude 也可以与 Web MCP 集成。
若要更改默认模型,搜索“cursor settings”,并选择对应选项:
在打开的标签页中,切换到 “Models” 选项卡:
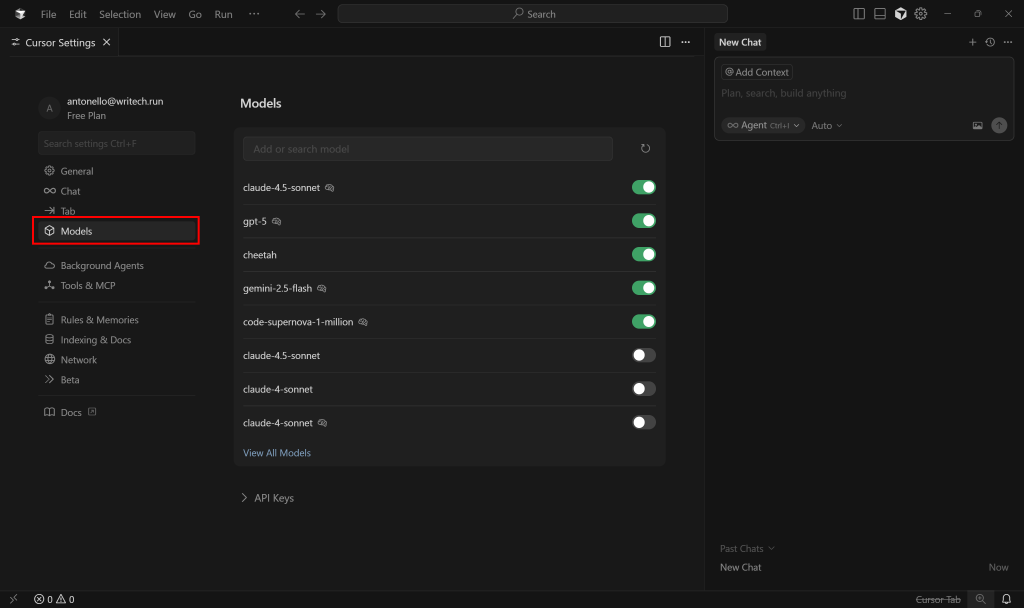
在这里,你可以配置 Cursor 的 AI agent 应使用哪种 LLM。请注意,免费用户作为高级模型只能在 GPT-4.1 和 “Auto” 之间选择。
要切换到 GPT‑4.1,搜索 “gpt”,找到 “gpt-4.1” 模型并启用:
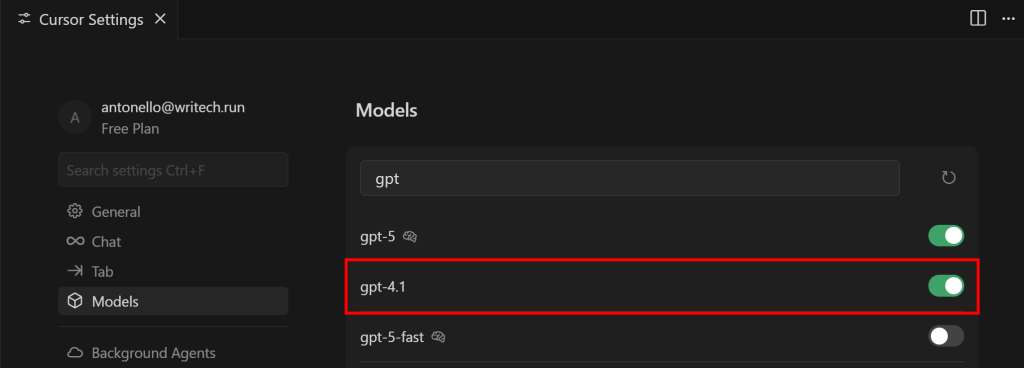
如果你拥有 Pro 或 Business 订阅,可以启用其他任一受支持的 LLM。此外,你还可以为所选提供商提供自己的 API Key。
接着,打开右侧的 “New Chat” 面板。点击 “Auto” 下拉开关,将其关闭,并选择 “gpt-4.1”:
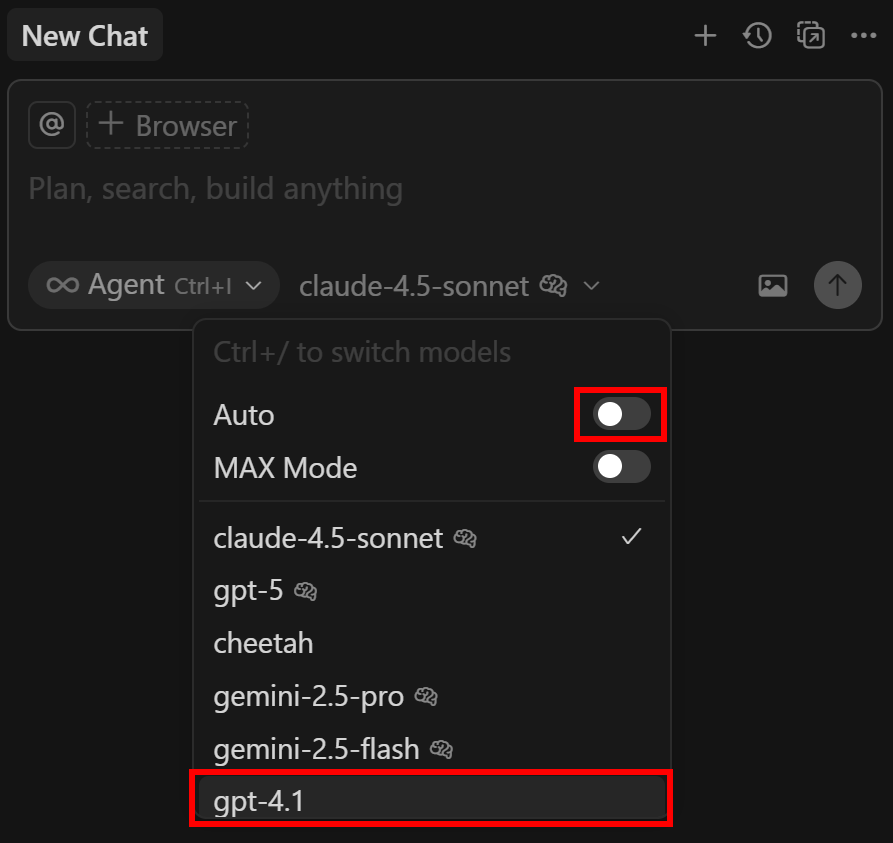
很好!Cursor 现在已通过你配置的 LLM 运行。
步骤三:在本机测试 Bright Data 的 Web MCP
在将 Cursor 连接到 Bright Data Web MCP 之前,先确认你可以在本地运行该服务器。因为 MCP 服务器将通过 STDIO 配置。
首先注册 Bright Data。如果你已有账户,直接登录即可。快速设置可按照控制台中 “MCP” 部分的指引:
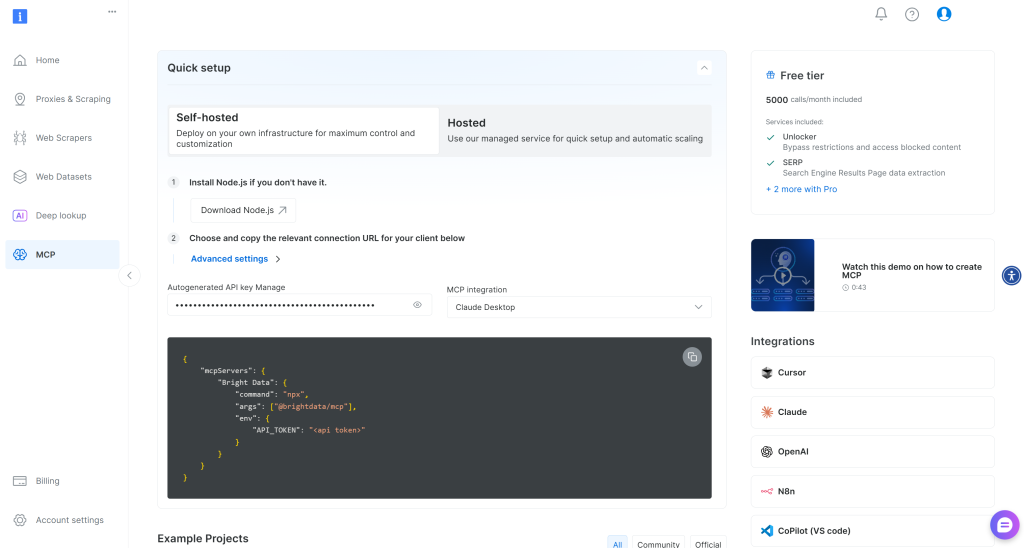
想要更多引导,请参阅下方步骤。
首先生成你的 Bright Data API Key 并妥善保存。下一步会用到。我们假定你的 API Key 拥有 Admin 权限,以便简化 Web MCP 集成。
现在,通过以下 npm 命令在你的机器上全局安装 Web MCP:
npm install -g @brightdata/mcp通过启动它来验证 MCP 服务器是否正常工作:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcp或在 PowerShell 中等效地:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 占位符替换为你的 Bright Data API Token。上述命令会设置必需的 API_TOKEN 环境变量,并通过 @brightdata/mcp 包在本地启动 Web MCP。
如果成功,你会看到类似如下输出:

首次启动时,Web MCP 会在你的 Bright Data 账户中创建两个默认的 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
Web MCP 依赖这两项 Bright Data 服务来驱动其 60+ 个工具。
如果你想检查这些 Zone 是否已设置,请访问 Bright Data 账户中的 “Proxies & Scraping Infrastructure” 页面。你应能在表格中看到这两个 Zone:
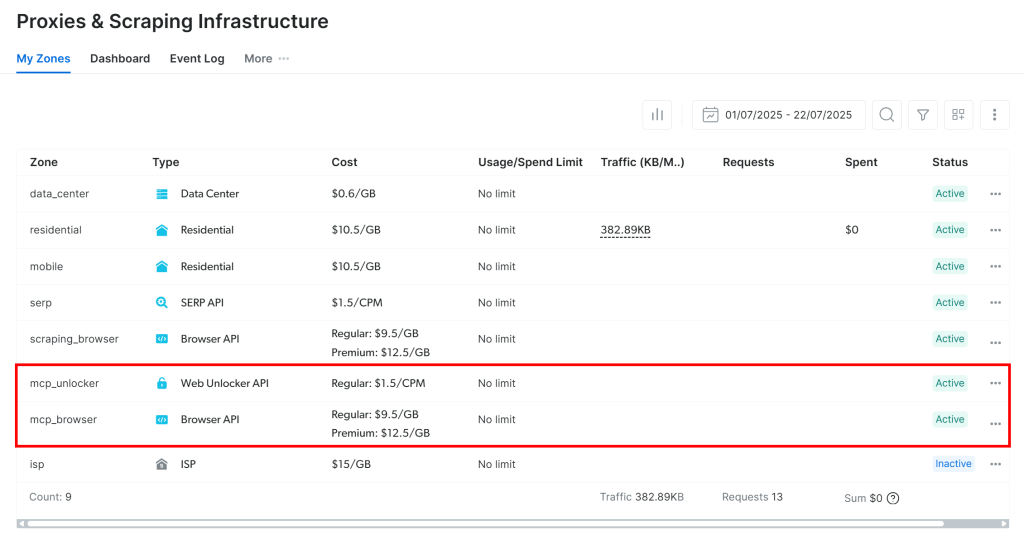
注意:如果你的 API Token 没有 Admin 权限,这两个 Zone 将不会自动创建。此时请手动创建,并按照 GitHub 文档所述通过环境变量进行设置。
请记住,在免费层,Web MCP 仅开放 search_engine 与 scrape_as_markdown(及其批量版本)。若要解锁其他工具,请启用 Pro 模式 **通过设置 PRO_MODE="true" 环境变量:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp或在 Windows 上:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpPro 模式将解锁全部 60+ 个工具,但不包含在免费层中,也就是说会产生额外费用。
太棒了!你刚刚确认了 Web MCP 服务器在本地可以正常工作。结束该 MCP 进程,因为接下来将配置由 Cursor 来启动并连接它。
步骤四:在 Cursor 中配置 Web MCP
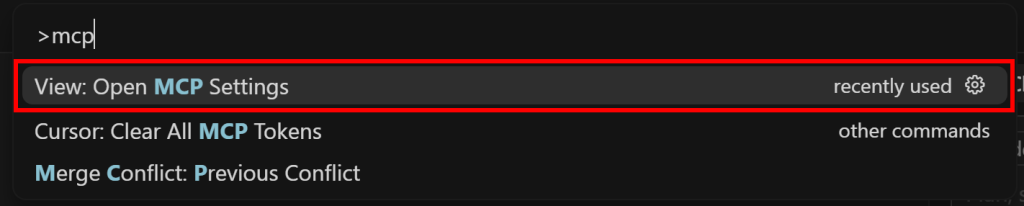
先搜索 “>mcp”,并选择 “View: Open MCP Settings” 选项:
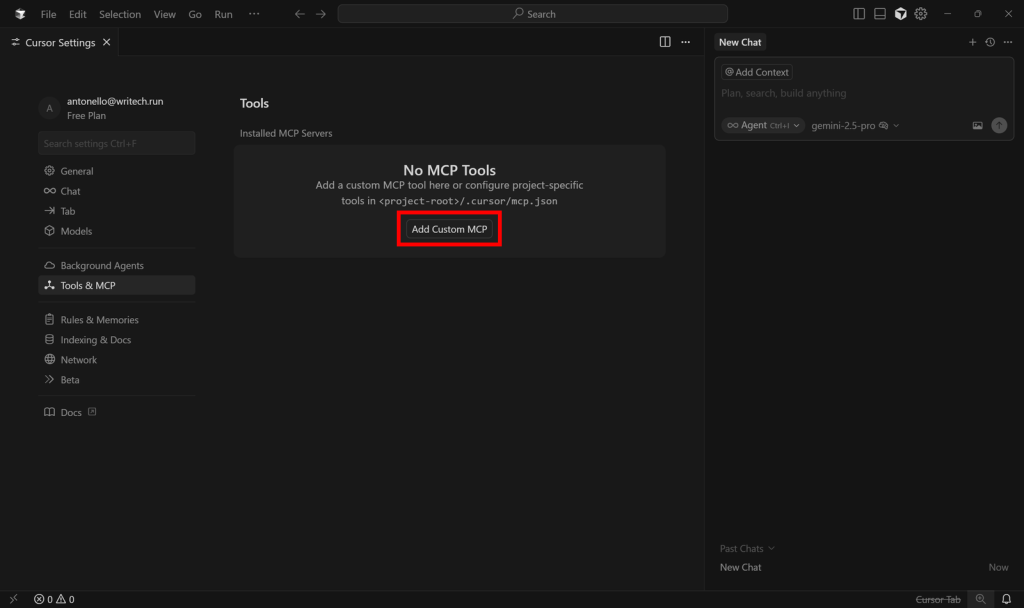
在 “Tools & MCP” 区域,点击 “Add Custom MCP” 按钮:
这将打开如下的 mcp.json 配置文件:
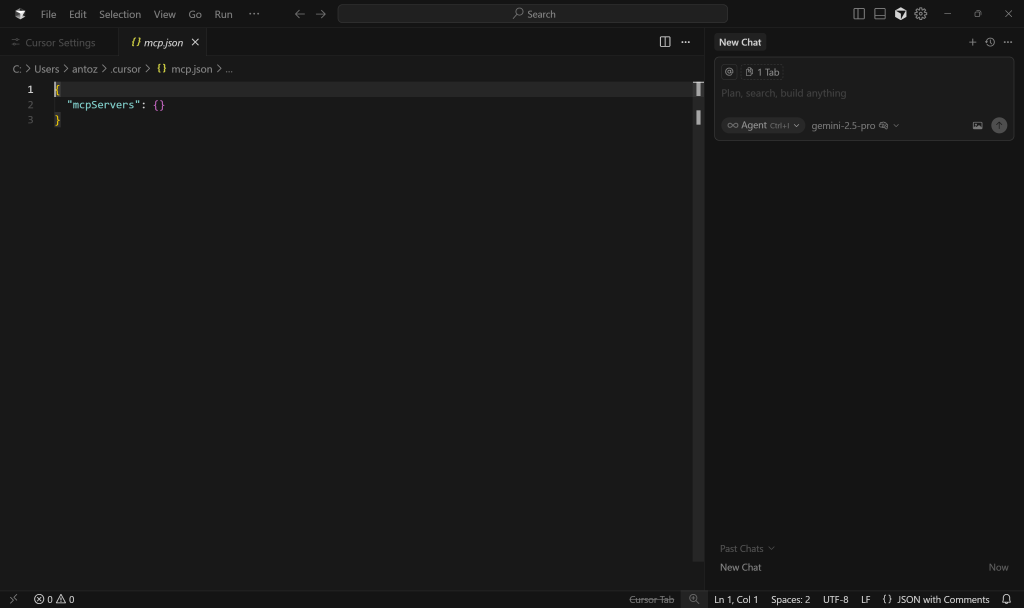
如你所见,默认是空的。针对 Bright Data 的 Web MCP,按如下填写:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}然后使用 Ctrl + S(macOS 为 Cmd + S)保存:
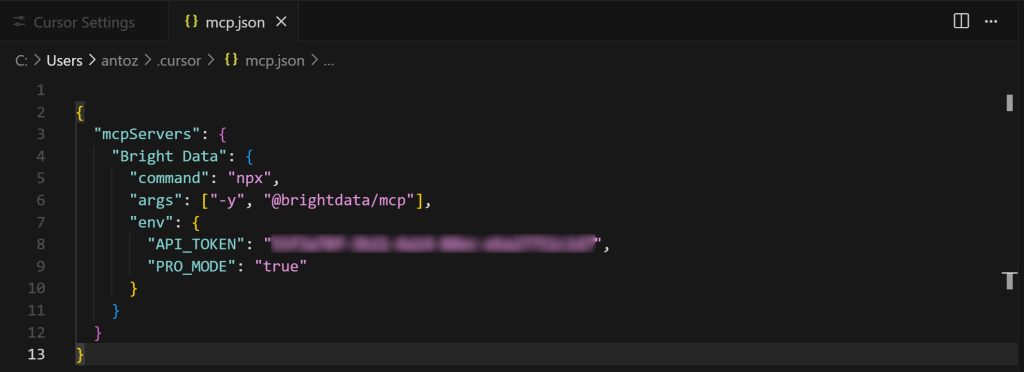
上述配置等同于我们先前测试的 npx 命令,通过环境变量传入凭据与设置:
API_TOKEN为必填。设为你之前生成的 Bright Data API Key。PRO_MODE为可选。如果不打算启用 Pro 模式可移除。
换言之,Cursor 会根据 mcp.json 的配置执行之前的 npx 命令:在本地运行一个 Web MCP 进程、连接它并获取所暴露的工具。
关闭 mcp.json 标签页,至此 Cursor + Bright Data Web MCP 集成完成!
注意:若你不想使用 STDIO,而是想用 SSE 或可流式的 HTTP,请注意 Bright Data 的 Web MCP 也提供远程服务器选项。
步骤五:验证 MCP 集成的工具可用性
现在检查 Cursor 是否已成功连接到 Web MCP 服务器并能访问其所有工具。
返回 “Cursor Settings” 标签页中的 “Tools & MCP” 区域。你现在应能看到已配置的 “Bright Data” 选项,并列出所有可用工具:
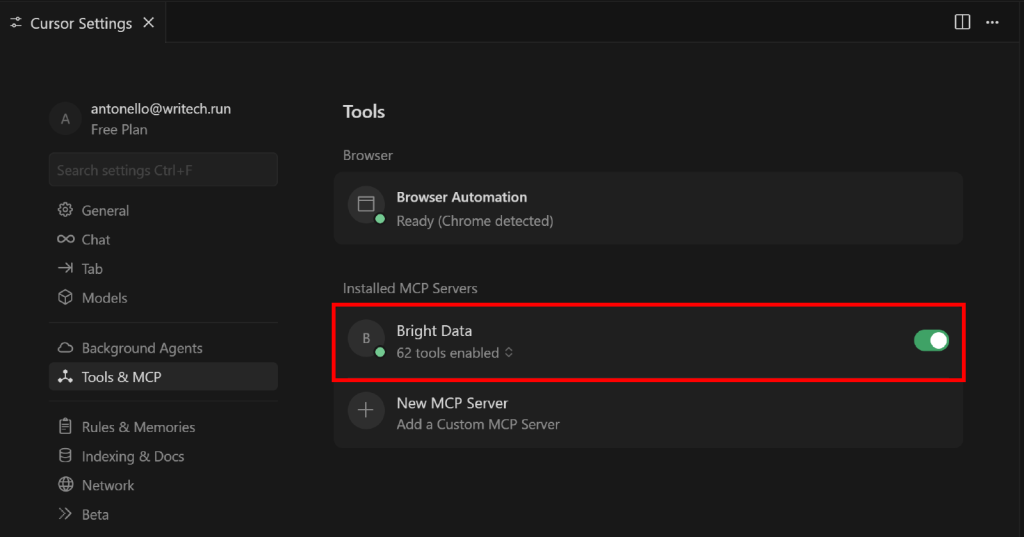
展开 “N tools enabled”(其中 N 为已启用工具的数量)下拉菜单,查看全部可用工具:
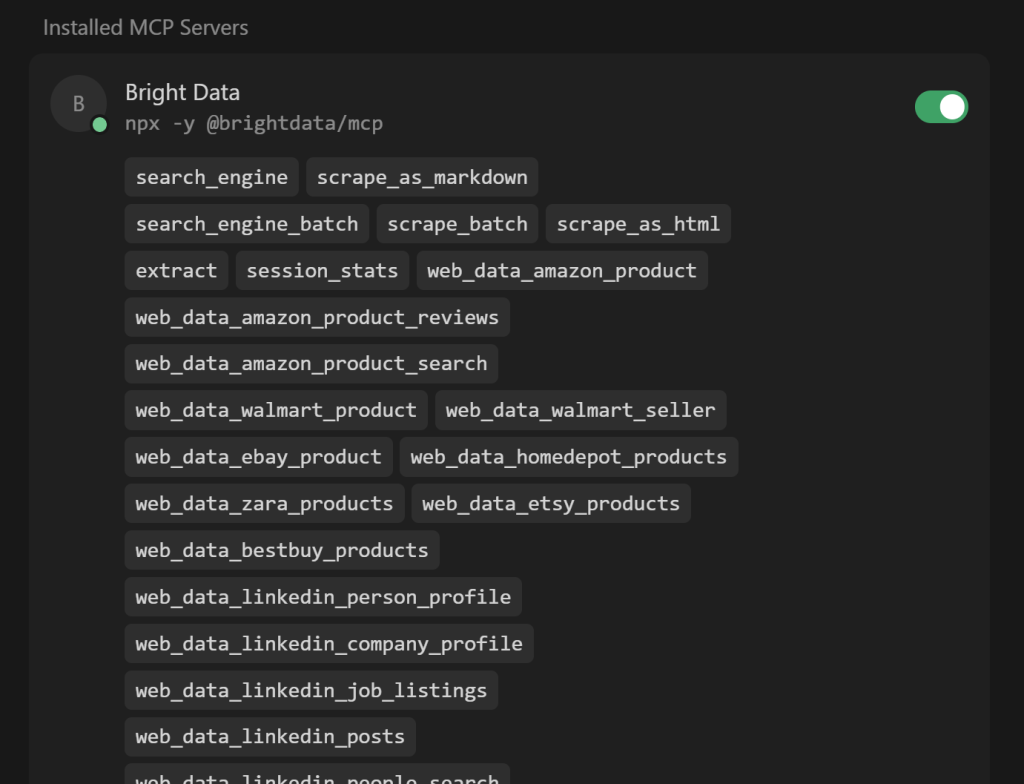
注意,Cursor 会自动连接到服务器并获取其 60+ 个工具。
如果未启用 Pro 模式,你只会看到 4/5 个免费工具。在此也可根据需要启用或禁用工具。默认均为启用状态。
确认无误后,关闭 “Cursor Settings” 标签页。准备好利用这些工具,获得更强大的 AI 编码体验!
步骤六:运行一个由增强型 AI 编码助手驱动的任务
为了测试你在 Cursor 中的编码助手能力,你需要一个能运用新配置的网页数据获取能力的提示词。
例如,你正在为电商应用构建一个 Express.js 后端,想要模拟一个返回 Amazon 商品真实数据的 API。
使用如下提示词即可实现:
Scrape the data from the following Amazon products:
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
Then, save the scraped data to a local JSON file. Next, create a simple Express.js project with an endpoint that accepts an ASIN (representing an Amazon product) and returns the corresponding data read from the JSON file.假设你处于 Pro 模式。在 Cursor 中执行上述提示词。
随后会发生如下步骤:
- Cursor 中配置的 LLM 识别到
web_data_amazon_product是用于获取 Amazon 商品数据的工具。 - 对于提示中三个 Amazon 商品中的每一个,系统会请求你授权运行
web_data_amazon_product以抓取数据。 - 你为每次调用授予权限,从而触发异步数据采集任务(其底层调用 Bright Data Amazon Scraper)。
- 每个商品的返回数据会以 JSON 格式展示。
- GPT‑4.1 处理获取到的数据,并将其写入
products.json文件。 - Cursor 创建 npm 项目结构,定义
package.json与包含 Express 服务逻辑的index.js。 - 系统会请求你授权通过
npm install安装项目依赖。完成后会生成package.json与node_modules/文件夹。 - 系统会请求你授权通过
npm start运行服务器。
注意:即使提示词未明确要求,GPT‑4.1 也会请求安装依赖并启动服务器。这是一个很贴心的补充!
在本例中,最终生成的项目结构如下:
your-project/
├── node_modules/
├── index.js
├── package.json
├── package-lock.json
└── products.json完美!让我们检查一下结果是否达到了预期目标。
步骤七:查看产出的项目
AI 编码助手生成文件的同时,它们会出现在 Cursor 左侧的文件栏中。
声明:你的文件可能与下图有所不同,因为不同的 AI 运行可能会生成不同的结果。
首先查看 products.json 文件:
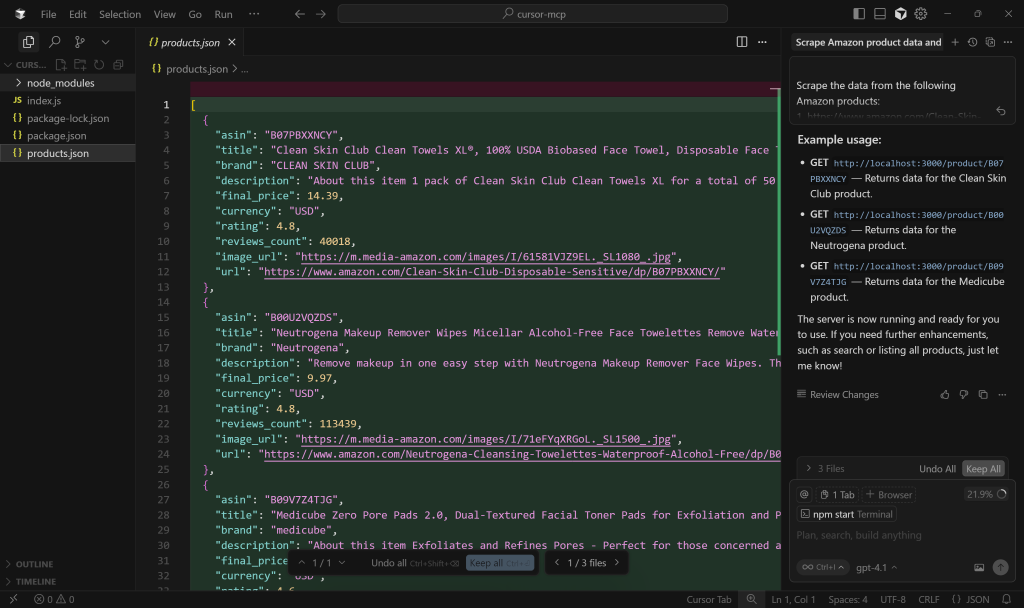
可以看到,它包含了 web_data_amazon_product 工具返回的抓取数据的简化版本:
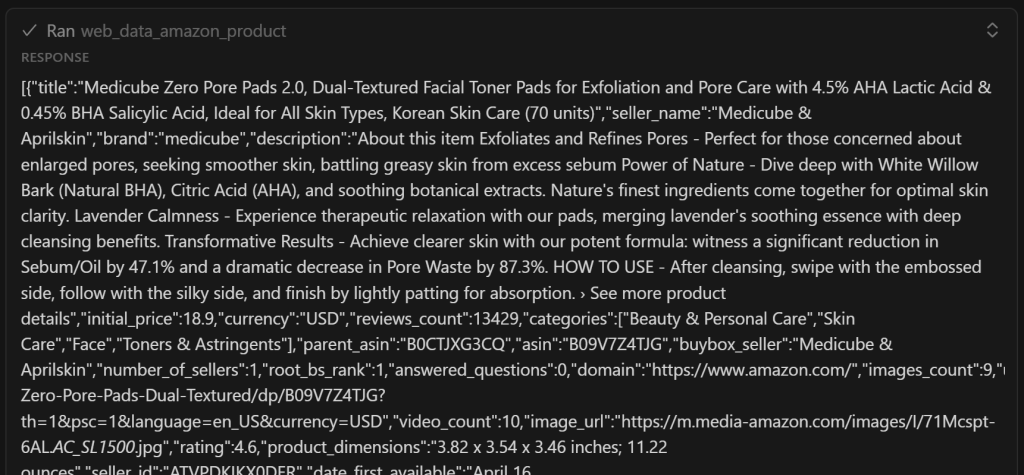
重要:web_data_amazon_product 实际上会返回该 Amazon 页面上的所有商品数据,而不只是少数字段。不过,AI 选择只保留最相关的字段。通过优化提示词,你也可以指示 AI 包含全部字段。
接着打开 index.js,查看 Express.js 服务器逻辑:
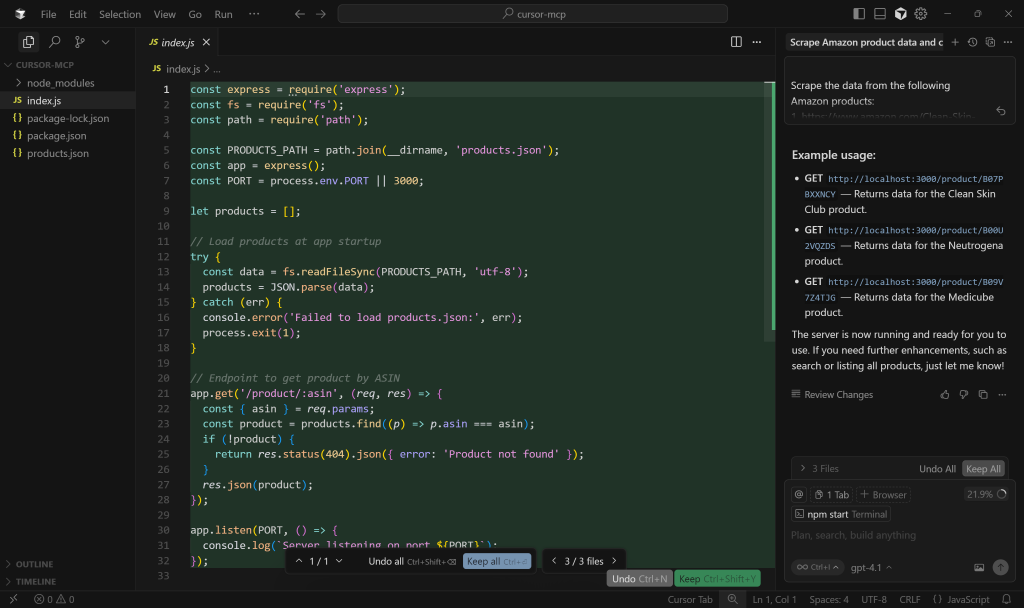
其中,获取商品数据的模拟端点路径为 /product/:asin。
继续检查其他文件,通常都没有问题。点击 “Keep All” 按钮确认 AI 生成的输出,准备开始测试你的项目!
步骤八:测试生成的项目
你的 Express.js 应用应该已经在运行,因为 GPT‑4.1 已请求通过 npm start 启动。如果还未运行,可手动执行:
npm start你的 Express.js 后端现在应在 http://localhost 运行。
接下来运行以下cURL 命令,测试 GET /product/:asin 端点:
curl "http://localhost/ product/B07PBXXNCY其中 B07PBXXNCY 是提示词中某个 Amazon 商品的 ASIN。
你应能看到如下所示的结果:

太好了!数据已正确写入生成的 products.json 文件。该结果对应于原 Amazon 页面数据的(简化版)。
如果你曾尝试抓取 Amazon 的商品数据,就会知道由于其著名的CAPTCHA 与其他反爬策略,这并不容易。显然,单靠普通的 GPT‑4.1 无法即时从 Amazon 获取数据。
这正体现了将 Web MCP 与 Cursor 结合的威力。当然,上面的示例非常基础。不过借助 60+ 个可用工具与合适的提示词,你可以直接在 IDE 中处理更复杂的场景!
搞定!借助 Cursor + Bright Data Web MCP 集成,我们成功创建了一个带有模拟 API 端点的 Express 后端。
【额外】在 Visual Studio Code 中的替代方案
如果你希望在 Visual Studio Code 中实现类似 Cursor 的体验,可以使用 Cline 或 Roo Code 等扩展。
特别是,关于在 VS Code 中集成 Web MCP,可参考以下指南:
结论
本文介绍了如何在 Cursor 中充分利用 MCP 集成。IDE 内置的 AI 编码助手本已十分好用,但连接 Bright Data 的 Web MCP 后,它会变得更加强大、更加机敏。
该集成让 Cursor 能够执行实时网页搜索、提取结构化数据、消费动态数据源,甚至自动化浏览器交互——这一切都在你的编码环境中完成。
若想构建更高级的 AI 工作流,请探索 Bright Data 的 AI 生态中提供的全套服务与数据方案。
立即创建一个免费的 Bright Data 账户,开始体验我们的面向 AI 的网页数据工具吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




