
Google 在 2025 年 9 月毫无预警地“杀死”了 num 参数。JavaScript 渲染变为强制要求,AI Overviews 也扩展到 200 个国家和地区。如果你在抓取 Google,你的原始 HTTP 请求现在会返回空结果或降级响应,基于 num 的分页失效,并且 AI 生成内容会把自然结果推到首屏以下。
每个 Google 搜索 URL 在 ? 后面都包含参数(例如 q 表示查询词、gl 表示国家、hl 表示语言、tbs 表示时间筛选,等等,还有几十个)。参数用错会导致你的爬虫返回错误国家的数据,或者返回空结果且难以排查。
下面列出所有真正重要的参数,并提供经过测试的代码与实用示例。所有代码都在真实的 Bright Data SERP API 上运行验证。
TL;DR:2026 年你需要知道的要点:
- 排名追踪:
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(去个性化、无 AI Overviews)- 分页:
start=10、start=20等(每页 10 条结果)。num已不再生效- 时间筛选:
tbs=qdr:d(过去一天)、tbs=sbd:1(按日期排序)、tbs=li:1(逐字匹配)- 新增:
udm扩展了tbm,新增模式如udm=14(仅 Web、无 AI)。两者目前都可用。建议同时支持。- 必需:JavaScript 渲染。自 2025 年 1 月起,直接
requests.get()会返回空结果
最小可用示例:
curl -X POST "https://api.brightdata.com/request" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <API_TOKEN>" \
-d '{"zone":"<ZONE_NAME>","url":"https://www.google.com/search?q=web+scraping+tools&gl=us&hl=en&brd_json=1","format":"raw"}'(URL 中的 brd_json=1 告诉 Bright Data 将 Google 的 HTML 解析为结构化 JSON。请求体中的 format: raw 表示按 Bright Data 基础设施“原样”返回响应——在这个例子里就是由 brd_json=1 生成的解析后 JSON。)
快速参考:Google 搜索参数速查表
| 参数 | 作用 | 状态 |
|---|---|---|
q |
搜索查询 | 可用 |
hl |
界面语言(en、fr、de) |
可用 |
gl |
地理位置 / 国家(us、gb、in) |
可用 |
lr |
限制结果为特定语言 | 可用 |
cr |
限制结果为托管在特定国家的页面 | 可用 |
num |
每页结果数 | 已失效(2025 年 9 月) |
start |
分页偏移量 | 可用 |
tbm |
搜索类型(isch、nws、shop、vid) |
可用 |
udm |
内容模式过滤(14、2、39、50) |
可用(新增) |
tbs |
时间与高级筛选(qdr:d、qdr:w) |
可用 |
safe |
SafeSearch 过滤 | 可用 |
filter |
重复结果过滤 | 可用 |
nfpr |
禁用自动纠错 | 可用 |
pws |
禁用个性化结果(pws=0) |
可用 |
uule |
编码位置(城市级定向) | 可用 |
sclient |
搜索客户端标识 | 可用(内部) |
kgmid |
知识图谱实体 ID | 可用 |
si |
知识图谱标签页(不透明编码字符串;无法由用户构造) | 可用(内部) |
ibp |
渲染控制(职位、商家列表) | 可用 |
ei、ved、sxsrf |
内部追踪 / 会话 token | 可用(内部) |
Google 搜索运算符(site:、filetype:、intitle: 等)在下方的运算符章节中介绍。
你可以在 SERP API Playground 里尝试基础搜索——无需登录。要使用完整参数集,请直接调用 API。
什么是 Google 搜索参数?
Google 搜索参数用于控制查询、位置、语言以及结果过滤。它们对 SEO 排名追踪、竞品分析、广告监控,以及将搜索结果喂给 LLM 应用都很关键。
2025 年一个变化是:Google 在 2025 年 4 月宣布,ccTLD(国家/地区顶级域,如 google.co.uk、google.de、google.ca)将重定向到 google.com。该变更是逐步推行的,有些 ccTLD 仍会直接提供结果。不管怎样,本地化请用 gl 和 hl,不要依赖域名。
核心搜索参数
这些参数几乎每次请求都会设置:查询、语言、国家、分页。
q – 搜索查询
你的搜索关键词放在 q 里。
https://www.google.com/search?q=bright+data+web+scraping查询中的空格会被编码为 + 或 %20。q 参数也支持 Google 的搜索运算符,例如:
https://www.google.com/search?q=filetype:pdf+web+scraping+guide
https://www.google.com/search?q=site:github.com+serp+api
https://www.google.com/search?q=intitle:proxy+rotation+tutorial请正确对查询字符串做 URL 编码,尤其是非拉丁字符(中文、阿拉伯语、日语、韩语等)——编码失败是出现意外结果或空结果的常见原因。如果你使用 Bright Data 的 SERP API,请务必把 q 参数放在 URL 的第一个。Bright Data 的文档要求如此。将其他参数放在 q 之前可能导致响应更慢、成功率更低。
通过 Bright Data 的 SERP API 代理方式:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=web+scraping+tools&brd_json=1"如果你需要在 JSON 里保留原始 HTML,请使用 brd_json=html,而不是 brd_json=1。Direct API 还支持更多输出格式,包括 Markdown、截图和轻量级解析输出。
JSON 响应大致如下(已截断):
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=web+scraping+tools&brd_json=1"
},
"organic": [
{
"link": "https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/",
"title": "Best web scraping tools I've tried (and what I learned from ...",
"description": "Playwright: Great for structured automation and testing, though a bit code-heavy for lightweight scraping.",
"rank": 1,
"global_rank": 5
}
]
}JSON 会按 SERP 区块对内容分组。organic 自然结果与 top_ads、bottom_ads 广告分开;knowledge 知识面板与 people_also_ask 分开;本地结果在 snack_pack;像 ai_overview 这样的新特性也各自在独立字段中。具体区块数量取决于查询词,总共可能超过十几个。
hl – host language(界面语言)
hl 是 “host language” 的缩写,用于控制 Google 界面语言,以及 Google 如何理解你的查询。
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=ja取值为 ISO 639-1 两位语言码,例如 hl=en(英语)、hl=fr(法语)、hl=de(德语);也可用 BCP 47 语言标签,例如 hl=en-gb(英式英语)、hl=pt-br(巴西葡萄牙语)、hl=es-419(拉丁美洲西班牙语)。
通过 SERP API,同一个搜索可以这样请求:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"这会抓取法语查询在法国的法语结果,就像你人在法国进行搜索一样。
gl – 地理位置(国家)
你的搜索位置会影响结果。gl 参数用于模拟你的地理位置(搜索看起来来自哪个国家)。它使用 ISO 3166-1 alpha-2 两位国家码。
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=in对比两个国家对同一查询的结果:
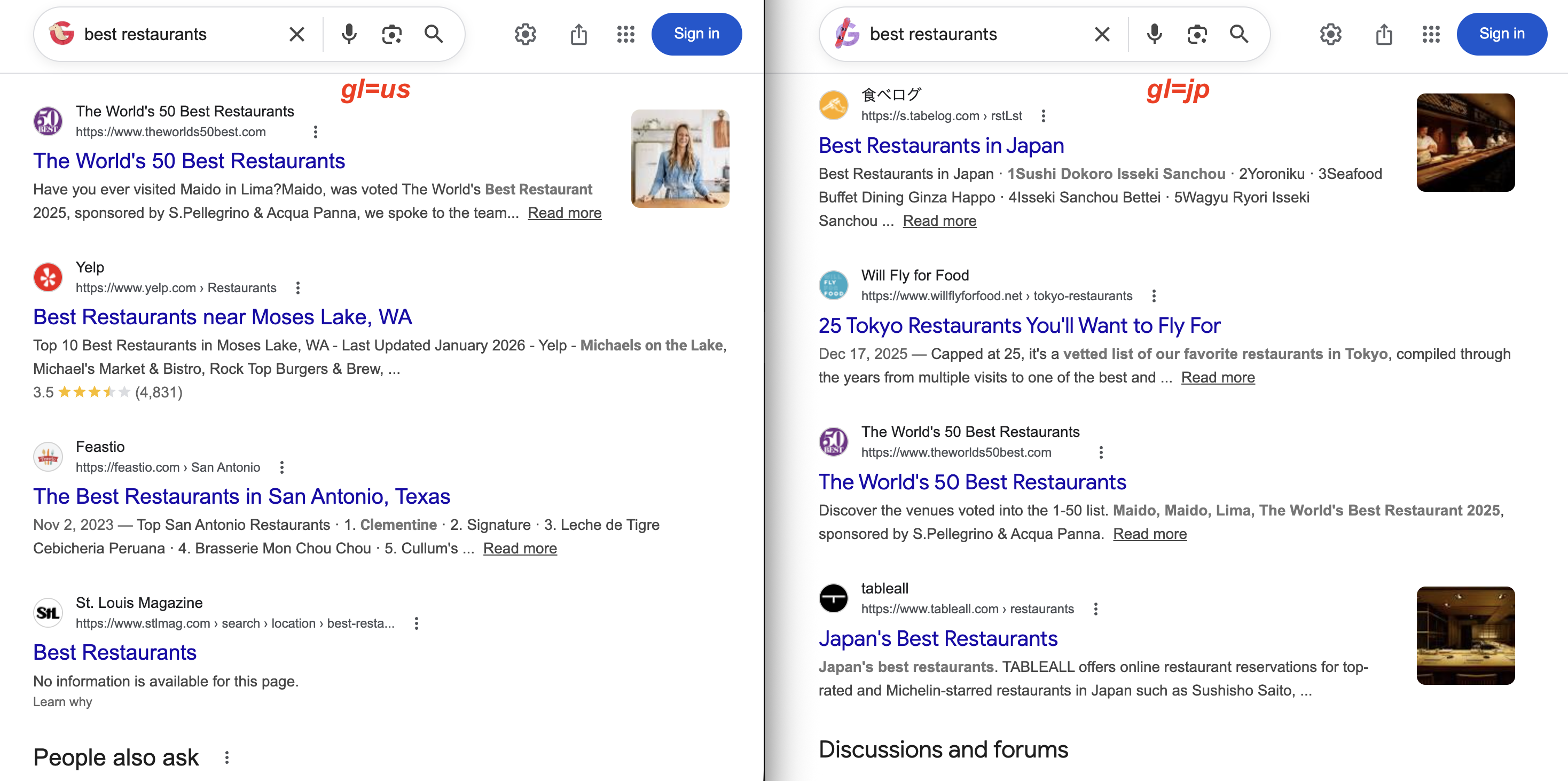
gl=us 返回 Yelp 和美国本地杂志网站;gl=jp 则返回食べログ(Tabelog)和东京餐厅指南。同一查询,结果差异很大。
lr – 语言限制
搜索 machine learning 时,即使设置了 hl=en,如果 Google 认为相关,仍可能返回中文、日文或德文论文。lr 参数可以解决这个问题:它会将结果限制为实际用指定语言编写的页面,而不仅仅是界面语言。
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_fr在语言码前加 lang_ 前缀(如英语为 lang_en,法语为 lang_fr)。用竖线 | 组合多种语言。
cr – 国家限制
类似 lr,但按托管国家过滤,而不是按内容语言。单个国家用 cr=countryUS,多个用 cr=countryUS|countryGB。与 gl 的关键区别是:gl 是把你的搜索“定位”为来自某个国家;cr 是过滤出实际托管在该国的页面。如果你需要精确过滤,建议两者一起用。
num – 结果数量
num 参数以前用于控制每页显示多少条结果(如 num=20、num=50、num=100)。
如果你的爬虫在 2025 年 9 月之后开始只返回 10 条结果,这就是原因。自 2025 年 9 月起,Google 悄悄禁用了 num 参数,现在它会被完全忽略。无论你传什么 num,Google 都固定每页返回 10 条结果,不报错也不重定向。这破坏了依赖该参数的 SEO 工具与 SERP 抓取流程。Google 发言人曾确认:“我们并不正式支持使用这个 URL 参数”。2025–2026 变化章节会介绍使用 Bright Data Top 100 Results 端点的替代方案。
你可以自行验证:URL 里有 num=100,但仍只返回 10 条结果:
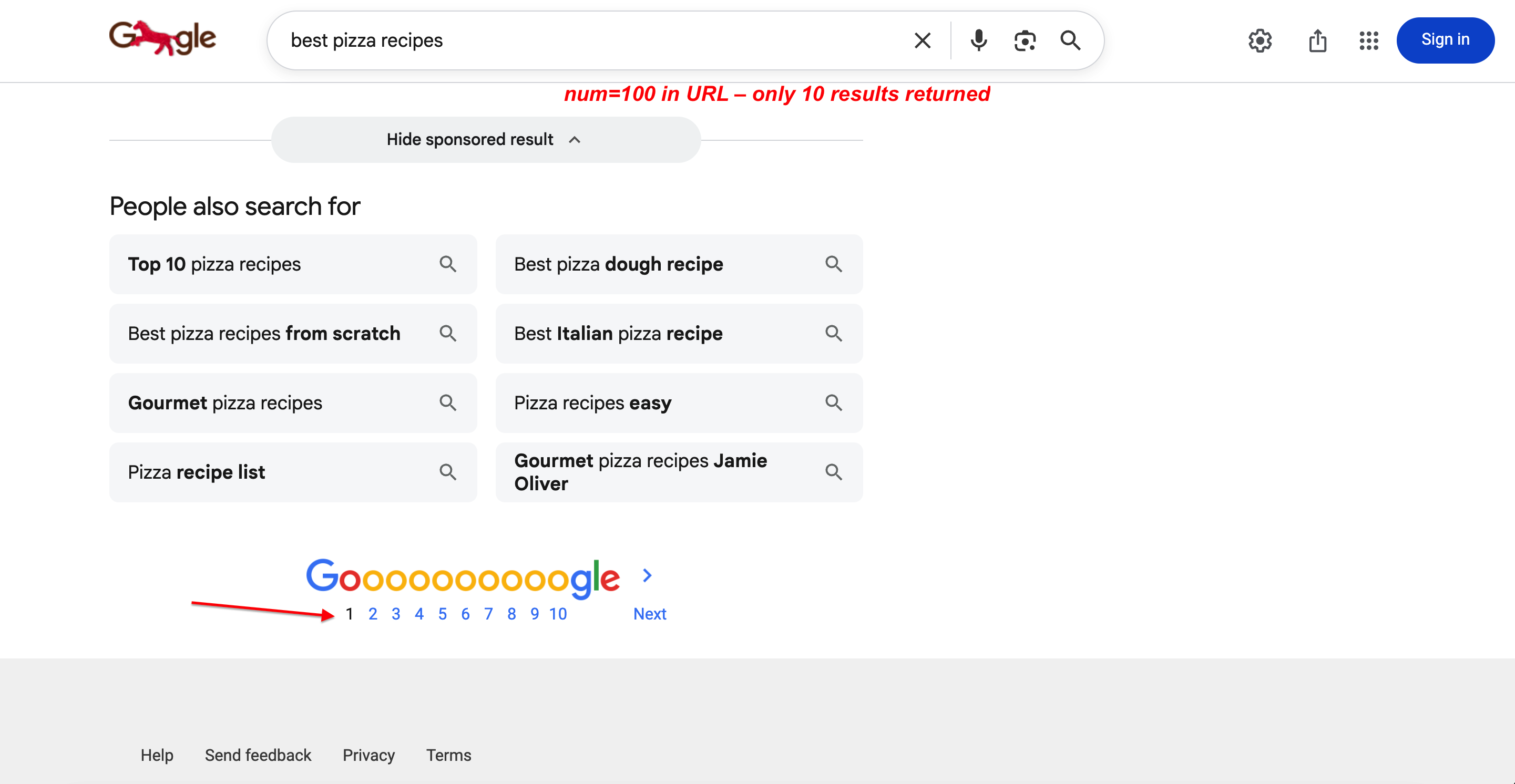
URL 中带 num=100 进行搜索。Google 仍只会每页返回 10 条结果并提供完整分页。该参数被完全忽略。
start – 结果偏移(分页)
自从 Google “杀死” num 之后,start 成了你唯一原生可用的分页选项。它设置结果偏移量,控制从第几条结果开始返回。
https://www.google.com/search?q=web+scraping&start=0
https://www.google.com/search?q=web+scraping&start=10
https://www.google.com/search?q=web+scraping&start=20start=0 是第 1 页(默认),start=10 是第 2 页,start=20 是第 3 页。
由于 Google 每页返回 10 条结果,所以 start=20 会得到第 21–30 条,start=30 得到第 31–40 条,以此类推。跨多页分页时,Google 可能在不同页之间返回部分重叠或轻微重排的结果。处理前请先按 URL 去重。
通过 SERP API 分页:
# Fetch page 3 of results
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"搜索类型参数
Google 有两个参数用于切换搜索垂类(图片、新闻、购物、视频):tbm 和 udm。
tbm – 搜索内容类型
tbm 参数(常被解释为 “to be matched”,但 Google 从未确认缩写含义)用于告诉 Google 你想要哪种类型的搜索结果。不设置时,默认是普通网页搜索。
| 值 | 搜索类型 | 示例 |
|---|---|---|
| (空) | 网页搜索 | q=coffee |
isch |
图片搜索 | tbm=isch&q=coffee |
vid |
视频搜索 | tbm=vid&q=coffee |
nws |
新闻搜索 | tbm=nws&q=coffee |
shop |
购物搜索 | tbm=shop&q=coffee |
bks |
图书搜索 | tbm=bks&q=coffee |
同一查询在三种搜索类型中的对比:
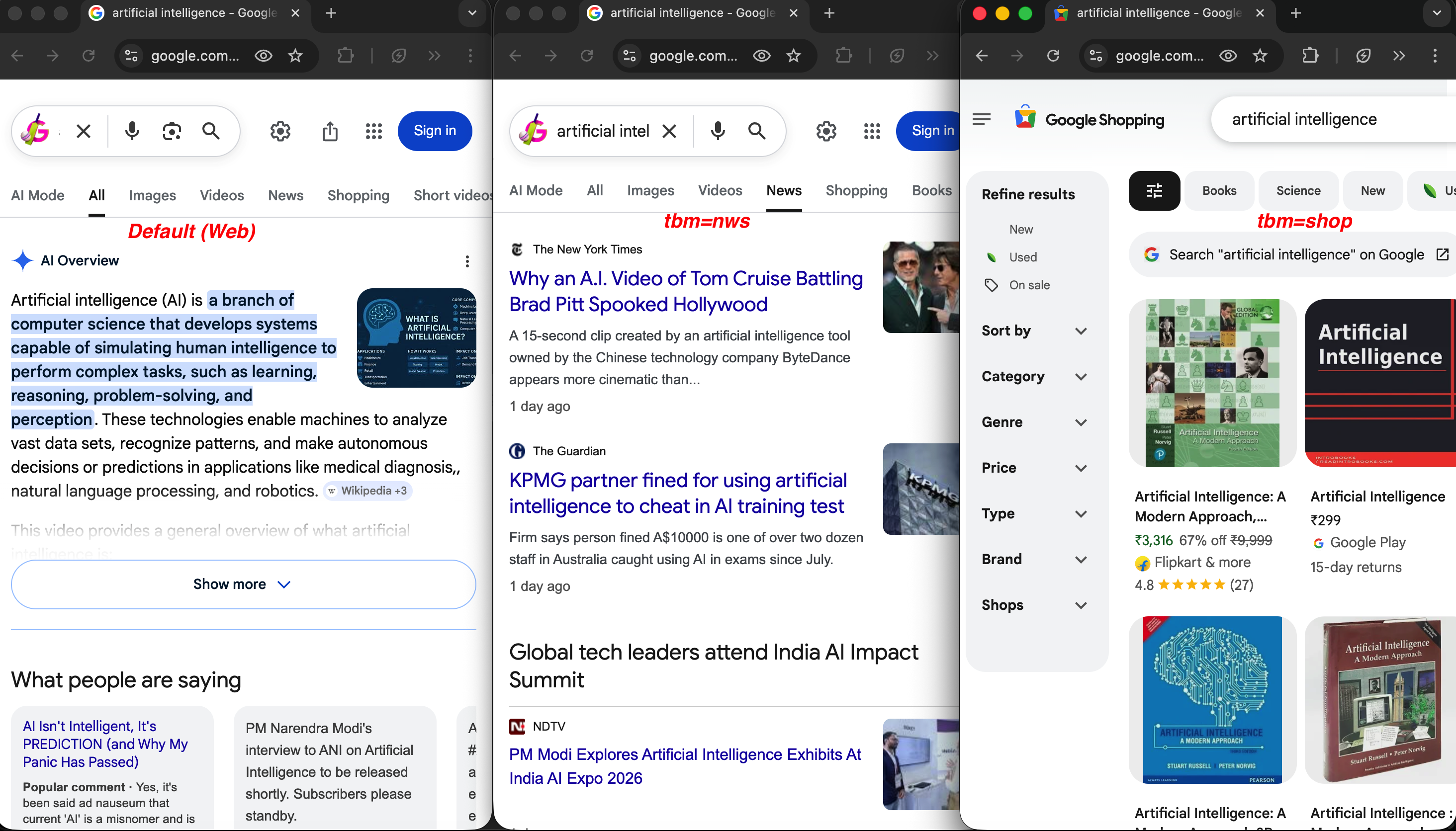
同一查询,不同 tbm 值:默认网页搜索(左)显示 AI Overview;tbm=nws(中)返回 NYT 与 The Guardian 等媒体新闻;tbm=shop(右)显示带价格与评分的商品列表。
关于人工智能的新闻搜索:
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=us机械键盘的购物搜索:
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=us这些搜索类型都原生可用。在解析 JSON 响应时,广告会分别出现在 top_ads 和 bottom_ads 字段,商品列表出现在 popular_products 下,且都与自然结果分离。若要专门做广告监测,请参见 Google Ads 抓取器。旅行与酒店参数(hotel_occupancy、hotel_dates、brd_dates、brd_occupancy、brd_currency 等)属于 Bright Data 特有参数,详见 SERP API 参数参考。
udm – user display mode
Google 较新的内容模式过滤参数是 udm,它在 tbm 的基础上扩展了更多结果类型,用来控制你看到哪种“模式”的搜索结果。所有 udm 取值都不在 Google 官方文档中,都是开发者社区通过测试逆向出来的。下面这些值目前稳定且被广泛使用,但 Google 可能随时变更而不另行通知。
| 值 | 结果模式 | 说明 |
|---|---|---|
udm=2 |
图片 | 图片搜索结果 |
udm=7 |
视频 | 视频结果;较新的 tbm=vid 等价模式 |
udm=12 |
新闻 | 新闻结果;较新的 tbm=nws 等价模式 |
udm=14 |
网页 | 经典网页结果,不含 AI 功能 |
udm=18 |
论坛 | 讨论区与论坛结果 |
udm=28 |
购物 | 购物/商品结果 |
udm=36 |
图书 | 图书结果;较新的 tbm=bks 等价模式 |
udm=39 |
短视频 | 短视频内容 |
udm=50 |
AI Mode | Google 的 AI 对话式搜索 |
最值得关注的是 udm=14。它会强制 Google 显示传统网页结果,不展示 AI Overviews 或其他 AI 生成内容:
https://www.google.com/search?q=web+scraping+tools&udm=14默认视图与 udm=14 的差异立刻可见:
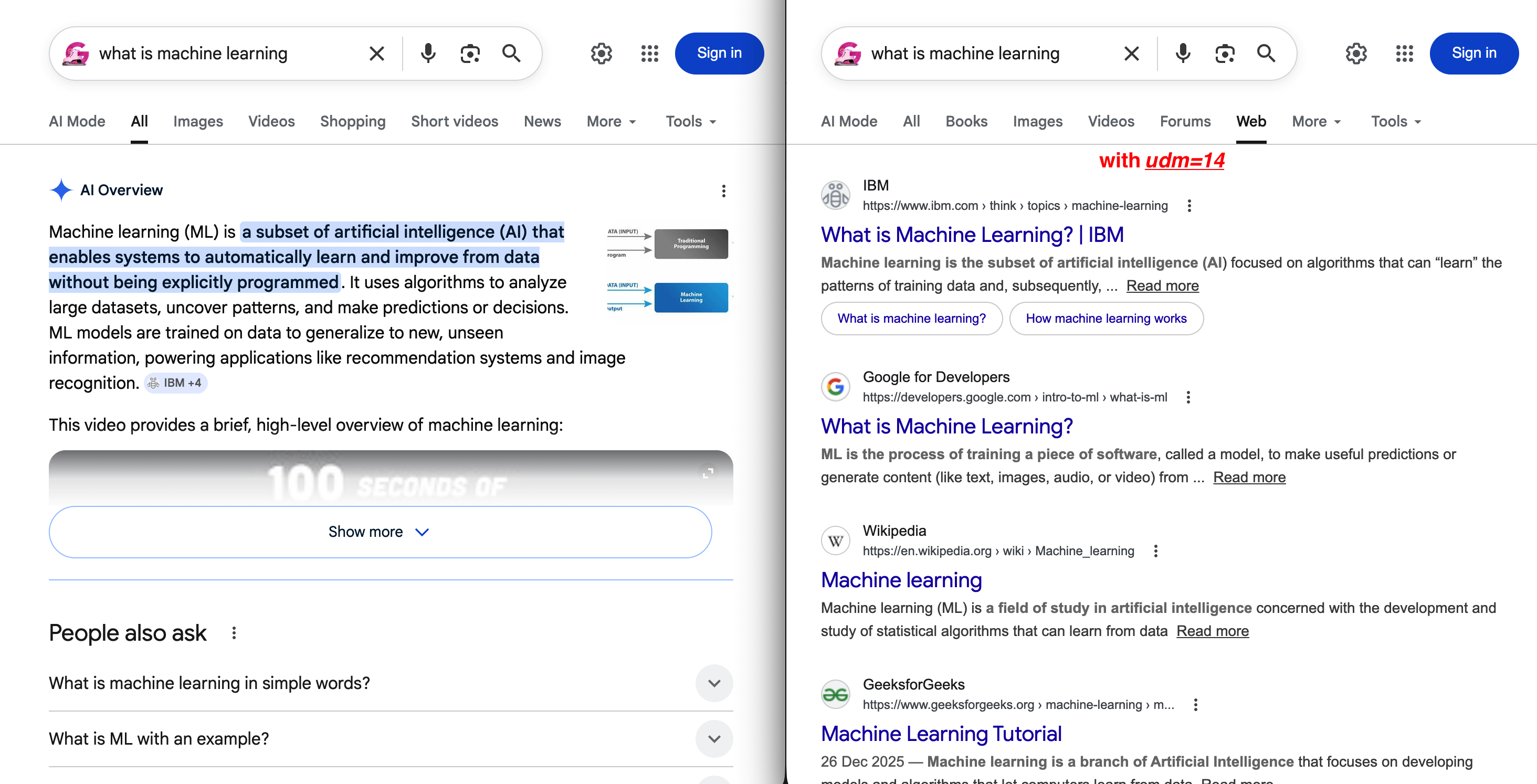
左:默认 SERP,AI Overview 把自然结果推到首屏以下。右:udm=14 移除这些内容,展示干净的“Web”标签页与传统蓝色链接。
短视频结果使用 udm=39(Google 未公开文档;表现可能因地区而异):
https://www.google.com/search?q=coffee+recipes&udm=39AI Mode(udm=50)是一种完全不同的搜索:
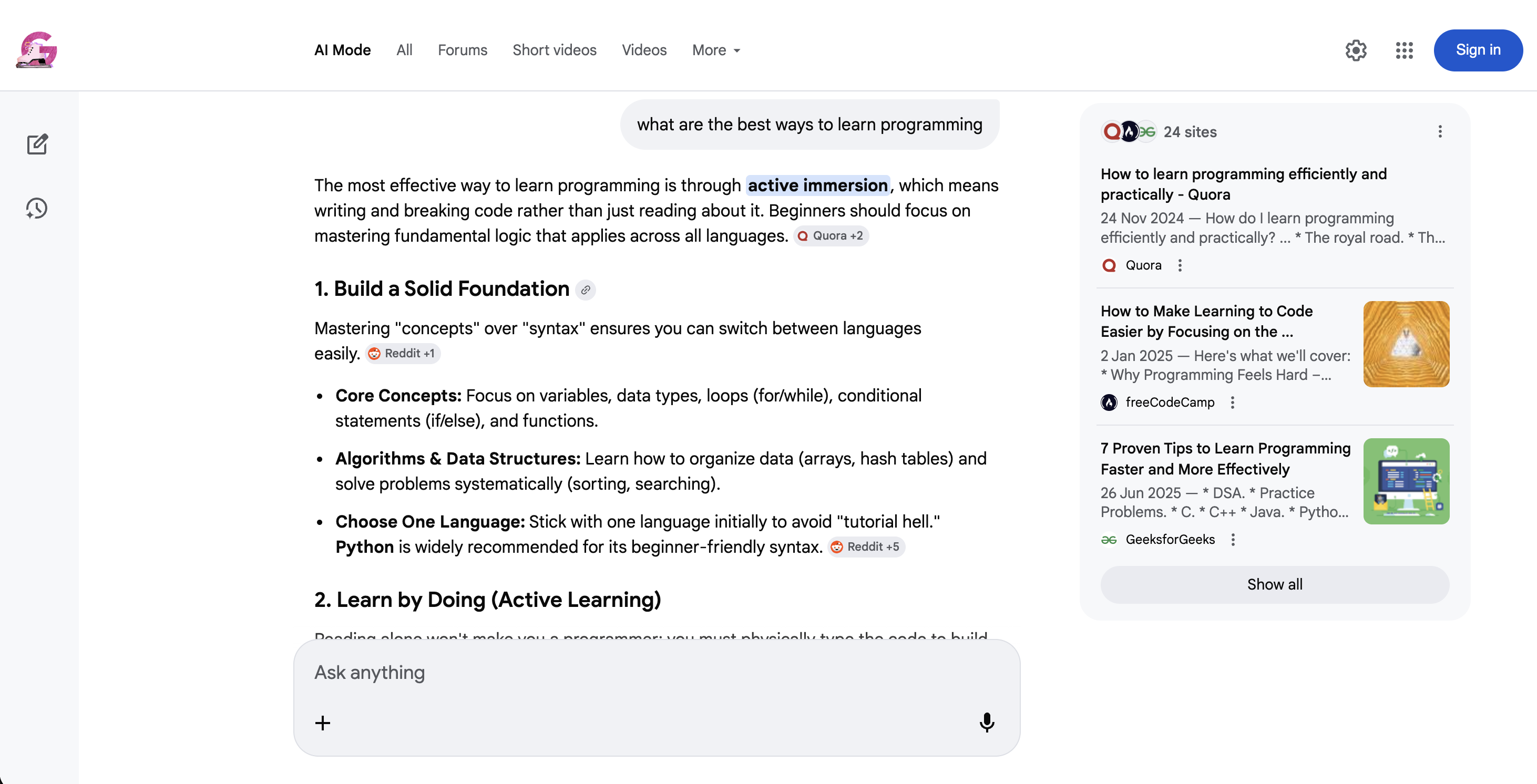
Google AI Mode(udm=50):不再是传统结果列表,而是对话式 AI 回答,带内联来源引用与后续提问建议。
tbm 与 udm 在图片、新闻、购物等模式上有重叠,但 udm 还覆盖了 tbm 不支持的模式(论坛、短视频、AI Mode、仅 Web)。两者目前都可用。如果你在构建新的抓取工作流,建议同时支持两种参数以获得最大兼容性。
过滤与排序参数
tbs – 基于时间与高级筛选
tbs 参数(常被解释为 “to be searched”,但无官方来源确认)用于控制时间筛选、按日期排序以及逐字匹配。
最常见用途是通过 qdr(query date range)进行时间筛选:
| 值 | 时间范围 |
|---|---|
tbs=qdr:h |
过去 1 小时 |
tbs=qdr:d |
过去 24 小时 |
tbs=qdr:w |
过去 1 周 |
tbs=qdr:m |
过去 1 个月 |
tbs=qdr:y |
过去 1 年 |
你也可以用 tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025 设置自定义日期范围,适合跟踪某段时间内搜索结果如何变化。
除了时间筛选,tbs 还有两个很实用的模式:tbs=sbd:1 强制按日期(最新优先)排序而不是按相关性,用于监控最新提及;tbs=li:1 启用逐字匹配,Google 会严格按你输入的内容搜索,不做自动纠错、同义词或相关词扩展。
监控某个话题的近期新闻:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=web+scraping+regulations&tbs=qdr:w&brd_json=1"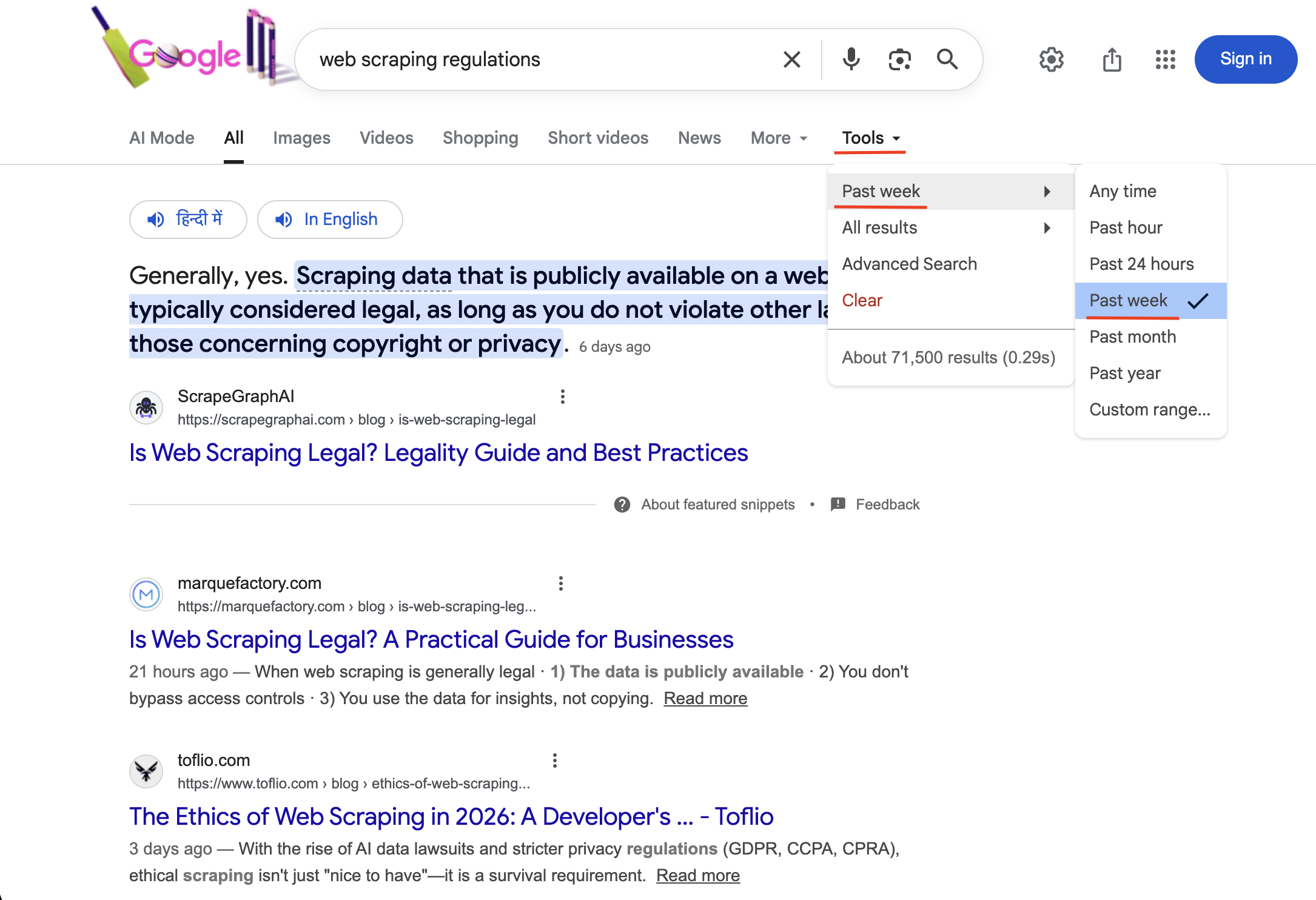
使用 tbs=qdr:w 搜索会激活“过去一周”时间筛选(在 Tools 下方可见勾选)。只返回近 7 天发布的结果。
提示:将 filter=0 与任意 tbs 时间筛选搭配使用,以获取全部结果。否则 Google 会聚类相似页面,你可能会漏掉相关报道。
safe – SafeSearch 过滤
safe=active 会过滤成人内容,safe=off 则关闭过滤。
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter – 重复结果过滤
filter 参数控制 Google 如何聚类相似或重复结果。
https://www.google.com/search?q=web+scraping&filter=0
https://www.google.com/search?q=web+scraping&filter=1filter=0 显示全部结果(包含重复)。filter=1(默认)会把相似页面聚在一起。与时间筛选搭配时尤其有用(见上面的 tbs 提示)。
nfpr – 禁用自动纠错
设置 nfpr=1 可阻止 Google 自动纠错你的查询。
https://www.google.com/search?q=scraping+brwser&nfpr=1当设置为 1 时,Google 会严格按你输入的内容搜索,而不会提示 “did you mean: scraping browser”。适用于你有意搜索拼写错误、被 Google 误判为拼写错误的品牌名,或可能被自动纠正的技术术语。注意:nfpr=1 只抑制自动纠错;tbs=li:1(逐字模式)更严格,还会禁用同义词、词干化与相关词扩展。要最严格匹配可同时使用两者。
pws – 个性化网页搜索
Google 默认会个性化搜索结果。pws 控制这种个性化是否启用。
https://www.google.com/search?q=web+scraping+tools&pws=0关闭个性化(pws=0)很重要,因为个性化结果会因用户而异,导致批量数据不一致。任何严肃的 SERP 数据采集都应始终包含 pws=0,以获得基准的、非个性化的排名结果。
位置参数
大多数排名追踪只需要用 gl 做国家级定向。但如果做本地 SEO,则需要更精细的定向。
uule – 编码位置
uule 可以在 gl 不够细时提供城市级精度。
uule 的值是基于 Google Ads API Geo Targets 的编码字符串。它可以使用规范名称编码(来自 Google 的地理定向数据库)或 GPS 坐标编码(纬度/经度)。
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXM手动生成 uule 很复杂。你需要先在 Google 的 Geo Targets 文档里查到地点的规范名称,再按 Google 期望的特定格式进行编码。
使用 Bright Data 的 SERP API,你可以完全跳过编码,直接传可读的地点名称字符串:
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesAPI 会自动完成查找与编码。
国家级定向用 gl,需要城市级精度时用 uule。对大多数排名追踪而言,gl 足够。把 uule 留给本地 SEO 审计——当同一国家内不同城市的结果差异明显时才使用。
设备与客户端参数
Google 对移动端与桌面端会返回不同结果。这些参数用于控制设备模拟与浏览器标识。
sclient – 搜索客户端
你几乎在每个 Google 搜索 URL 里都能看到 sclient。它用于标识发起搜索的搜索客户端。常见取值:gws-wiz(网页搜索)、gws-wiz-serp(从 SERP 发起)、img(图片搜索)、psy-ab(与 Google 的即时/预测搜索有关)。它用于 Google 内部分析,不影响搜索结果。
brd_mobile / brd_browser – 设备与浏览器模拟
SERP API 提供 brd_mobile 用于模拟来自特定设备的搜索:
| 值 | 设备 | User-Agent 类型 |
|---|---|---|
0 或省略 |
桌面端 | Desktop |
1 |
移动端 | Mobile |
ios 或 iphone |
iPhone | iOS |
ipad 或 ios_tablet |
iPad | iOS Tablet |
android |
Android | Android |
android_tablet |
Android 平板 | Android Tablet |
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"如果你在代理方式下使用
brd_mobile时遇到expect_body错误,请尝试改用 Direct API。Direct API 在设备模拟方面通常更可靠。LangChain 集成在这里也表现不错,因为它会通过 Direct API 自动传递device_type。
你也可以用 brd_browser 控制浏览器类型:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox,与brd_mobile=1不兼容)
如果不指定,API 会随机选择浏览器。组合这两个参数即可指定精确的设备 + 浏览器组合:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"高级与内部参数
你不需要设置这些参数。它们属于 Google 内部参数。不过,如果你想知道在 Google URL 中看到的 ei、ved、sxsrf 分别是什么意思,本节会解释。
kgmid – 知识图谱机器 ID
kgmid 参数用于从 Google 的知识图谱(Knowledge Graph)提供结果,甚至可以完全覆盖 q 参数。
https://www.google.com/search?kgmid=/m/07gyp7这会直接加载麦当劳(McDonald’s)的知识图谱面板。每个实体都有唯一的机器 ID,通过 kgmid 传入即可获取该实体的面板。
该 ID 返回的面板如下:
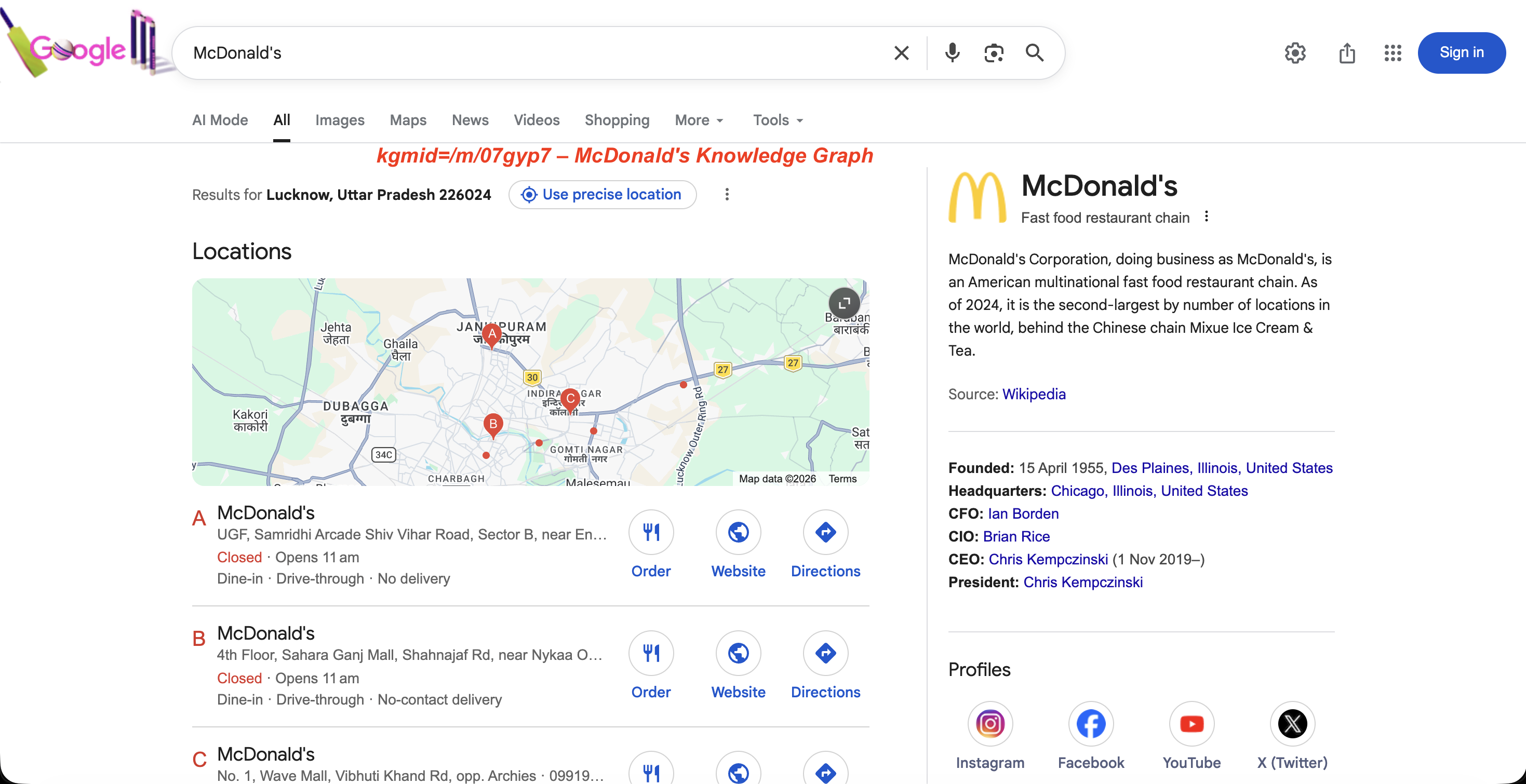
kgmid=/m/07gyp7 的知识图谱面板:实体描述、成立日期、管理层与社交账号。
品牌监测团队会用它来跟踪自家或竞争对手的知识图谱面板随时间的变化。
ibp – 渲染控制
Google 不会在常规搜索结果中使用 ibp。它用于控制 SERP 上某些元素的渲染,尤其是Google 商家列表(Google Business listings)和Google Jobs。
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531与 ludocid 参数(Google 商家列表的唯一 ID)配合时,ibp 可以触发该商家列表的整页视图。
对职位搜索而言,ibp=htl;jobs(URL 编码为 ibp=htl%3Bjobs)会触发 Google Jobs 面板并展示完整职位列表:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"ibp=htl%3Bjobs 触发的 Jobs 面板:
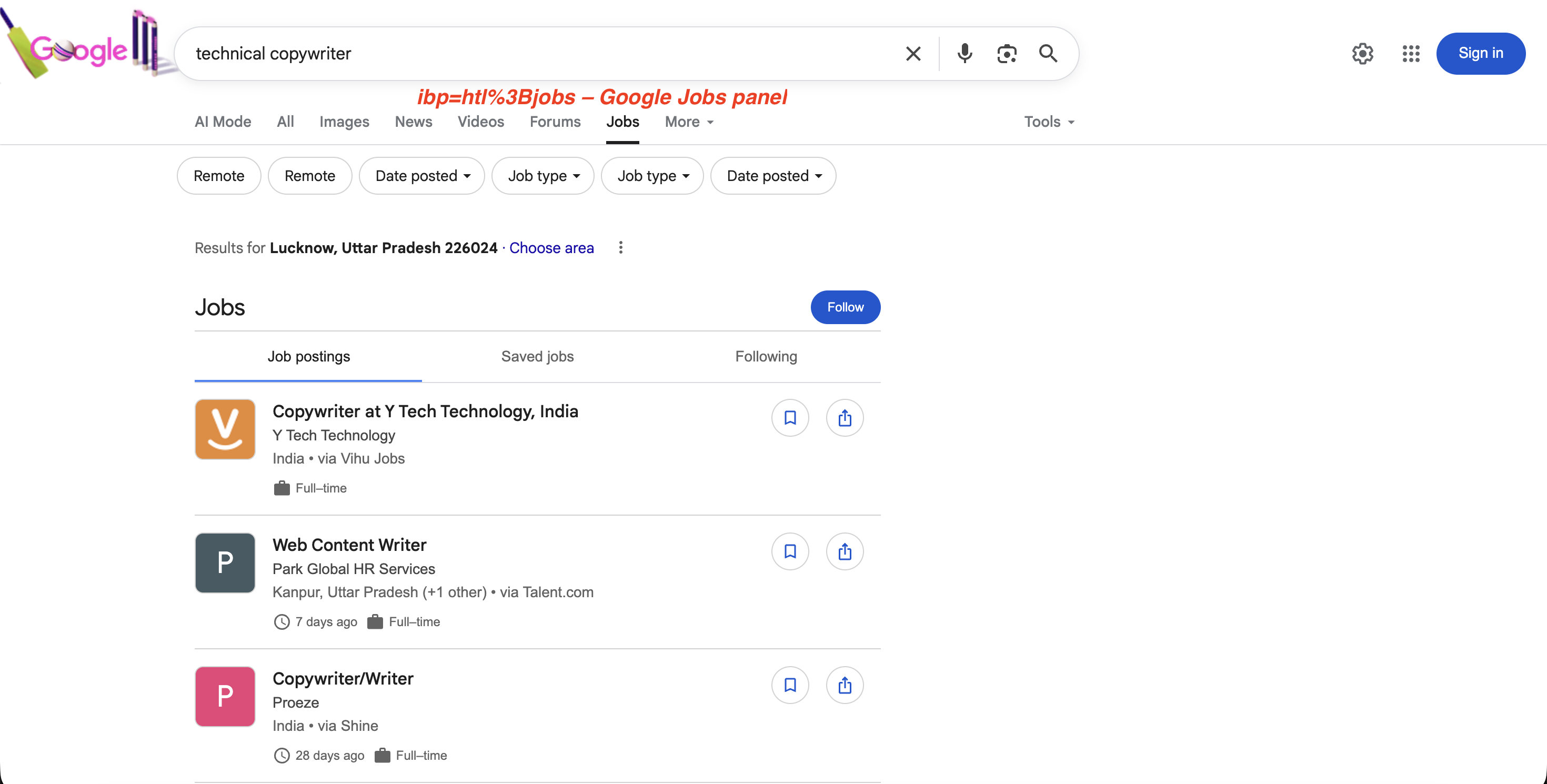
ibp=htl%3Bjobs 参数会触发 Google 的 Jobs 专用面板,包含职位信息、筛选项以及“关注(Follow)”选项,均可通过 SERP API 抽取。
htl;jobs中的分号必须 URL 编码为%3B(即ibp=htl%3Bjobs),在 curl 或任何 HTTP 客户端中都是如此。不正确编码可能导致请求返回空结果。
ei、ved、sxsrf、oq、gs_lp – 内部追踪参数
这些参数都不影响返回哪些结果,可以安全从 URL 中移除。下面是各自用途:
| 参数 | 用途 |
|---|---|
ei |
会话标识符,包含 Unix 时间戳与不透明值 |
ved |
点击追踪:编码被点击的 SERP 元素、其索引与类型 |
sxsrf |
带编码 Unix 时间戳的 CSRF token |
oq |
自动补全修改前的原始输入(例如 q=web+scraping+api 时,原始输入可能是 oq=web+scrap) |
gs_lp |
与搜索客户端状态相关的内部会话数据 |
ie / oe |
输入/输出字符编码(几乎总是 UTF-8;可忽略) |
client |
搜索客户端类型(如 firefox-b-d、safari),用于标识浏览器或应用 |
source |
搜索来源标识(如 hp 表示主页,lnms 表示模式切换) |
biw / bih |
浏览器内部宽/高(像素);可能影响 Google 返回的 SERP 布局变体 |
Google 搜索运算符
搜索运算符是写在 q 参数里的特殊命令,用于按域名、文件类型、标题、URL 或精确短语过滤结果。Google 在其搜索优化帮助页中记录了其中一部分。
它们与 URL 参数不同:运算符写在 q 的值内部;而参数是 URL 中独立的键值对。以下是对抓取与数据采集最有用的一些运算符:
| 运算符 | 功能 | 示例 |
|---|---|---|
site: |
限制到特定域名 | site:github.com python scraper |
filetype: |
限制文件类型 | filetype:pdf web scraping guide |
intitle: |
在页面标题中搜索 | intitle:serp api comparison |
inurl: |
在 URL 中搜索 | inurl:api documentation |
intext: |
在正文中搜索 | intext:proxy rotation |
allintitle: |
标题包含所有词 | allintitle:web scraping python |
allinurl: |
URL 包含所有词 | allinurl:api docs scraping |
related: |
查找相似网站 | related:brightdata.com |
OR |
匹配任一词 | web scraping OR web crawling |
"精确短语" |
精确匹配 | "serp api for python" |
- |
排除词 | web scraping -selenium |
before: / after: |
日期范围 | AI overview after:2025-01-01 |
AROUND(n) |
邻近搜索 | scraping AROUND(3) python |
define: |
词典释义 | define:web scraping |
* |
通配符 | "best * for web scraping" |
这些运算符在 API 请求中同样可用。例如:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=site:reddit.com+web+scraping+tools+2026&brd_json=1"这会只搜索 Reddit 上关于 2026 年网页抓取工具的讨论,并返回结构化 JSON 输出。
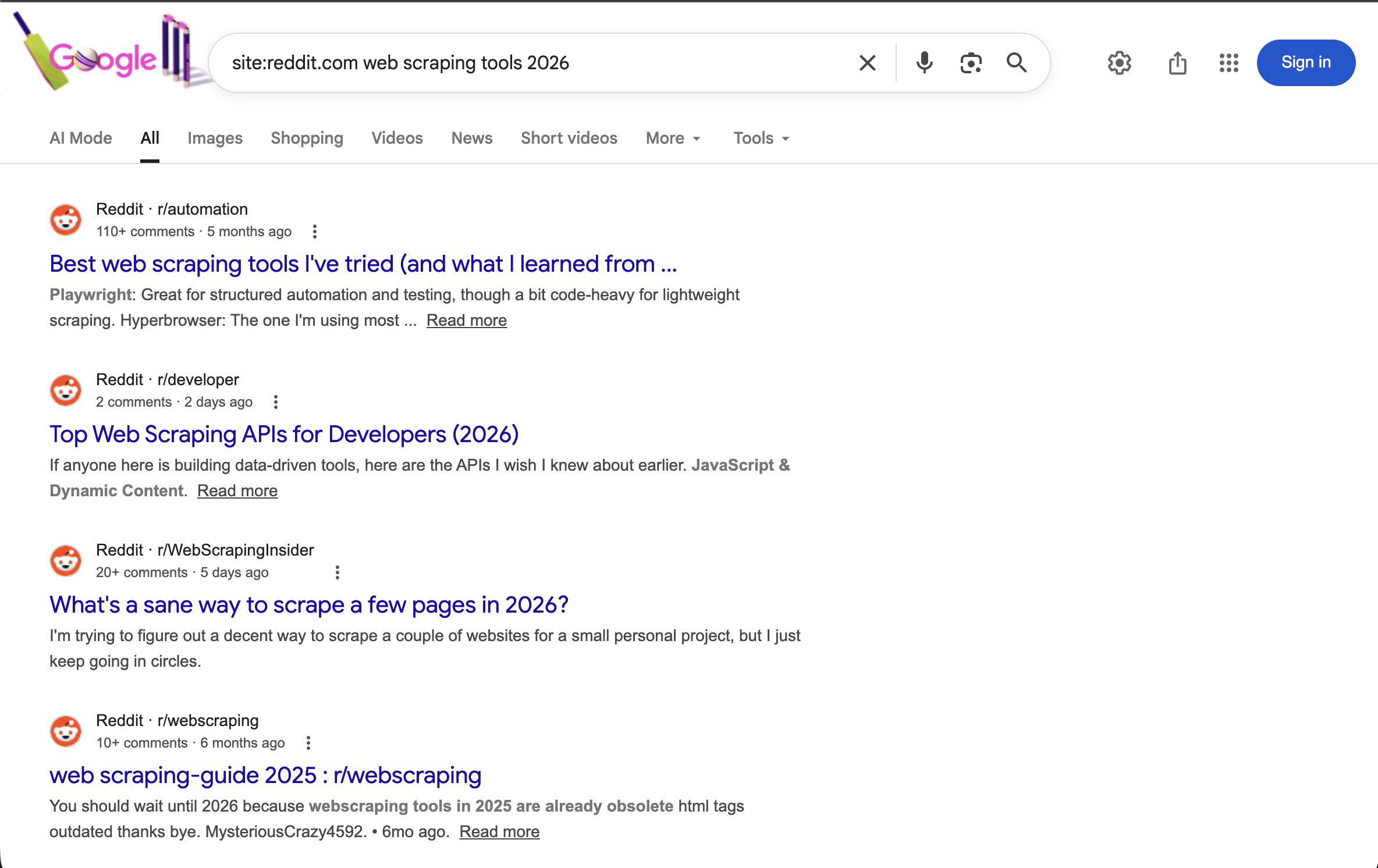
site:reddit.com 运算符会把所有结果限制在 Reddit。结合年份关键词,可看到近期社区关于网页抓取工具的讨论。
运算符可组合使用:
site:github.com filetype:pdf machine learning只返回托管在 GitHub 上且匹配 “machine learning” 的 PDF 文件。
as_* – 高级搜索参数
Google 的高级搜索表单会生成以 as_ 开头的参数(as_q、as_epq、as_sitesearch、as_filetype 等),它们与上述运算符一一对应。大多数工程师更倾向于直接在 q 中使用运算符。这些参数主要适用于你在构建搜索表单 UI 时,将表单字段映射到 URL 参数而无需拼接运算符字符串。
你需要了解的 2025–2026 年变化
Google 在 2025–2026 年做了三项改变,导致现有抓取方案失效:强制 JavaScript 渲染(2025 年 1 月)、移除 num 参数(2025 年 9 月),以及 AI Overviews 扩展到 200+ 个国家。
Google 现在要求 JavaScript 渲染
自 2025 年 1 月起,Google 不会在不进行 JavaScript 渲染的情况下提供搜索结果。如果你一直在运行 requests + BeautifulSoup 爬虫,这就是原因。现在任何 requests.get('https://google.com/search?q=...') 都会返回空结果或降级响应。你需要完整的浏览器渲染,或使用能替你处理的 SERP API。
SERP API 会自动完成 JavaScript 渲染,因此你的 API 调用方式不需要改变。
num 参数不再可用
在 2025 年 9 月 12–14 日之间,Google 悄悄禁用了 num。影响范围很广:一项涵盖 319 个站点资产的研究显示,87.7% 的被追踪站点在 Google Search Console 中出现展示量下降。
要一次获取超过 10 条结果,Bright Data 的 SERP API 提供 Top 100 Results 端点,可在一次请求中返回第 1–100 名。它使用不同的 API(/datasets/v3/trigger,dataset ID 为 gd_mfz5x93lmsjjjylob),并提供 start_page 与 end_page 参数来控制分页深度:
curl -X POST "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mfz5x93lmsjjjylob&include_errors=true" \
-H "Authorization: Bearer <API_TOKEN>" \
-H "Content-Type: application/json" \
-d '[{
"url": "https://www.google.com/",
"keyword": "web scraping tools",
"language": "en",
"country": "US",
"start_page": 1,
"end_page": 10
}]'页码范围:1..2 = Top 20,1..5 = Top 50,1..10 = Top 100(每页 10 条)。响应包含 AI Overview 文本(字段 aio_text,当 SERP 展示 AI Overview 时),你还可以添加 "include_paginated_html": true 来同时捕获原始 HTML 与解析数据。也支持批处理:传入一个查询对象数组即可在一次请求中搜索多个关键词。
搜索结果中的 AI Overviews
Google 的 AI Overviews(搜索结果顶部的 AI 生成摘要)现已覆盖 200+ 个国家与 40+ 种语言。2026 年 1 月,Google 将 AI Overviews 升级为 Gemini 3,并新增从 AI Overviews 过渡到 AI Mode(udm=50)对话的入口。要捕获这些内容,需要 JavaScript 渲染与特定的抽取逻辑。一个真实 SERP 上的 AI Overview 示例:
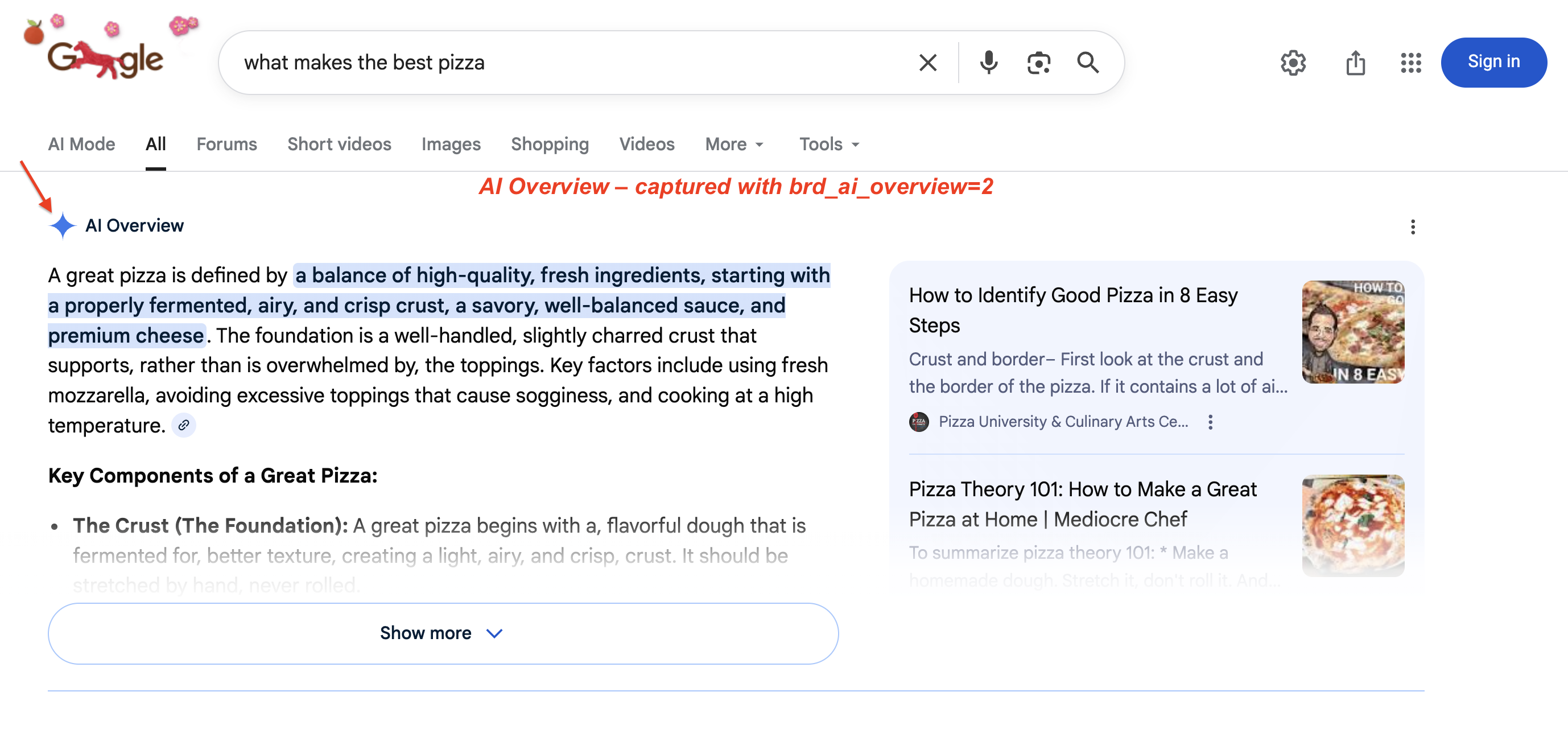
典型 AI Overview:Google 生成多段摘要,突出显示关键短语,并在右侧给出来源卡片。该模块会把自然结果推到首屏以下。通过 SERP API 使用 brd_ai_overview=2 来抓取它。
AI Overview 抓取器通过 brd_ai_overview 参数工作。设置 brd_ai_overview=2 可提高在结果中获得 AI 生成 Overview 的概率:
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"在我们的测试中(美国查询),启用 AI Overview 捕获会将响应时间增加 5–10 秒。额外延迟来自于需要等待 Google 动态加载的 AI 内容在无头浏览器中完成渲染。
如何结合 SERP API 使用 Google 搜索参数
只要抓取量稍大,你就会遇到验证码、IP 封锁、强制 JavaScript 渲染,以及 Google 基础设施变化导致解析器悄然失效。我们已用真实 API 测试下述每种方法,确保按文档所述可用。
使用 Bright Data SERP API 的四种方式,从最简单到最高级:如果你只是入门,建议从方法 1(Direct API)开始;如果要集成到已有代码并需要自定义 header,请选方法 2(Proxy);如果是 AI agent 工作流,直接看方法 4(LangChain)。配置流程可参考入门指南。
| 方法 | 适用场景 | 响应 | 复杂度 |
|---|---|---|---|
| Direct API | 入门、单次查询 | 同步 | 低 |
| Proxy Routing | 现有 HTTP 工作流、自定义请求头 | 同步 | 低 |
| Async Batch | 高并发(1000+ 查询)、分页扫库 | 排队 | 中 |
| LangChain | AI agents、RAG 流水线、多工具工作流 | 同步 | 低 |
方法 1:Direct API 请求
最简单的方法:POST 你的搜索 URL,拿到结构化数据:
import requests
import json
from urllib.parse import urlencode
# Build the Google search URL with proper encoding (handles non-latin characters, special chars)
params = urlencode({"q": "web scraping api", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"zone": "<ZONE_NAME>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Validate response before processing
if "organic" not in data or len(data.get("organic", [])) == 0:
print("Warning: no organic results returned (possible soft block or empty SERP)")
print(json.dumps(data, indent=2))默认 zone 名通常是 "serp"。解析后的响应大致如下:
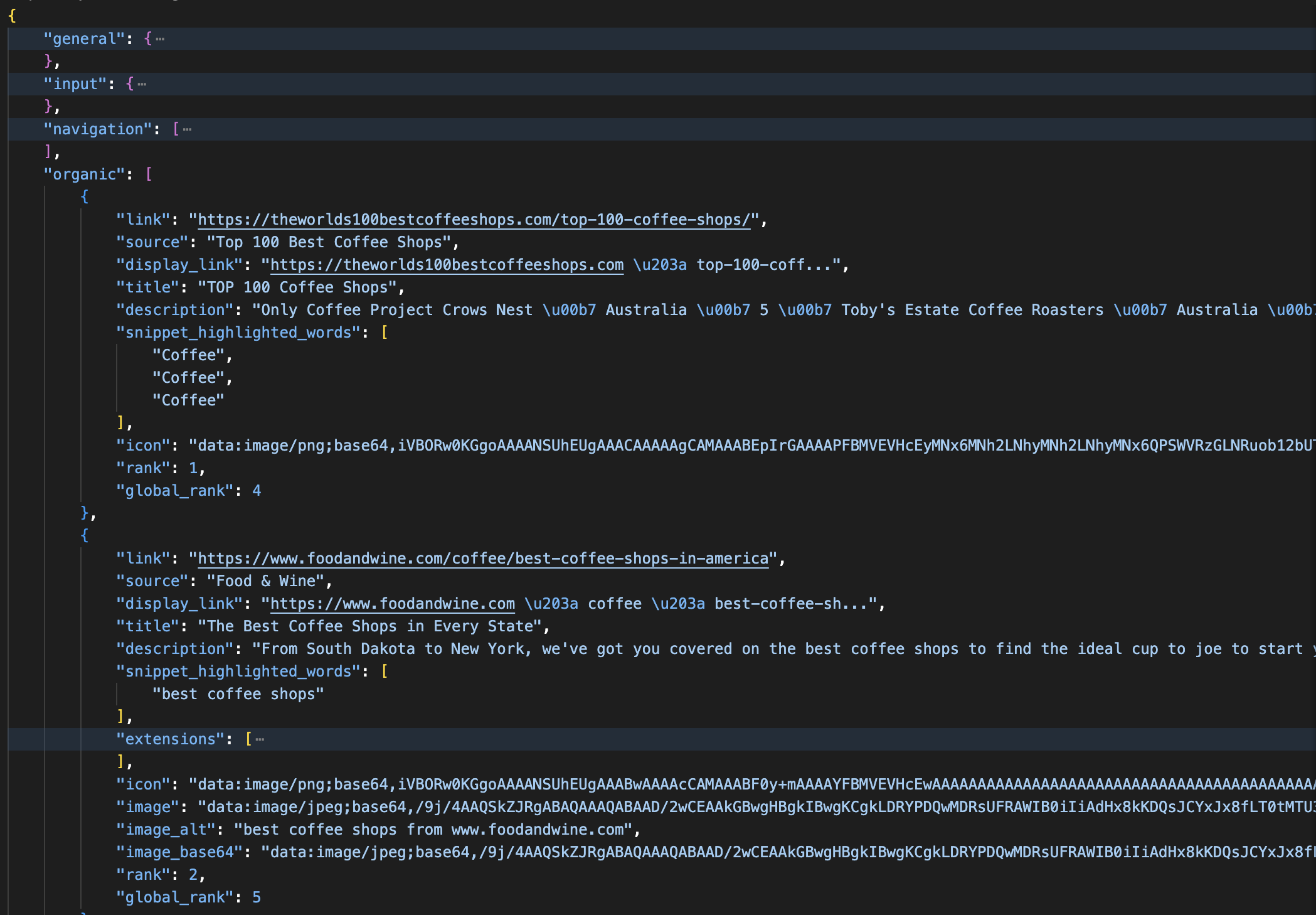
SERP API 的解析后 JSON 响应:每条自然结果包含 title、link、description、rank 与 global_rank 字段;同时也把广告、知识面板与 AI Overviews 等区块分到各自命名的 section 中。
Direct API 还支持在请求体中传 "data_format" 字段(不同于 "format"):可用 "markdown" 供 LLM/RAG(检索增强生成)流水线使用,"screenshot" 返回 PNG 截图,或 "parsed_light" 只返回 Top 10 自然结果。如果你希望在 JSON 中保留原始 HTML,请在 URL 中使用 brd_json=html。
请求体中的
country与 URL 中的gl不是一回事。"country": "us"控制的是代理出口节点(请求 IP 的地理位置);gl=us是告诉Google展示哪个国家的结果。要获得准确的地理定向结果,请两者都设置。
方法 2:代理路由(Proxy Routing)
把请求走 Bright Data 的代理基础设施。代理会在其侧完成 JavaScript 渲染,因此即使你的代码发的是标准 HTTP 请求,也能拿到完整渲染后的结果。该方式兼容任何 HTTP 客户端,并允许你设置自定义 headers、cookies 与请求级选项(这些 Direct API 不一定暴露)。在代理方式下,你通过 URL 参数控制输出格式:追加 brd_json=1 可返回解析后的 JSON,而不是原始 HTML:
import requests
# Use a Session for connection pooling (reuses TCP connections across requests)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335"
}
session.verify = False # for testing; load Bright Data's TLS/SSL cert in production
url = "https://www.google.com/search?q=serp+api+comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())凭据可在 Dashboard 中 SERP API zone 的 “Access Details” 里找到。务必在处理前校验响应。Google 的 soft block 可能返回合法 JSON,但结果集为空或被削减。如果 general.results_cnt 显示估算结果数为数百万,但 organic 数组为空或只有 1–2 条,通常意味着是 soft block,而不是真正的空 SERP。
verify=False(或 curl 的-k)会跳过 TLS/SSL 校验,适合测试。生产环境请改为加载 Bright Data 的 SSL 证书。
方法 3:异步批处理(Async)
高并发场景(1000+ 查询)建议用异步模式。尤其适用于使用 start、gl、hl 扫大量关键词 + 地域组合(例如:在 10 个国家追踪 500 个关键词)。计费只发生在发送请求时;收取结果是免费的。回调时间取决于请求量与峰值负载。
首先,在你的 zone 的 Advanced settings 里打开 Asynchronous requests 开关。然后使用 /unblocker/req 端点:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=web+scraping+tools&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"Queued. Response ID: {response_id}")
# Poll for results (for production, configure a webhook URL in your zone settings instead)
# Total polling window: 30 attempts × 10s = 300s. Increase range() for large batches.
for attempt in range(30):
time.sleep(10) # wait before checking - results are never ready immediately
result = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
print(json.dumps(data, indent=2))
else:
print("Warning: response returned but contains no organic results")
break
elif result.status_code == 202:
continue # results not ready yet
else:
print(f"Timed out after 300s waiting for response_id={response_id}")除了轮询,你也可以配置webhook URL(可在 zone 设置里设为默认,或每次请求用 webhook_url 参数单独指定)。结果就绪后,Bright Data 会向你的端点发送通知(含 response_id 与状态),你无需手动轮询 /get_result。响应最多保留 48 小时。
即使使用托管 API,也要遵守 zone 的速率限制。默认配置支持高吞吐,但如果不做节流就突发上千个同步并发请求,可能触发 HTTP 429。异步模式可避免这一点,因为 API 会在内部排队并自动节流。
方法 4:LangChain 集成(AI 工作流)
如果你在构建需要实时搜索数据的 AI agents,有官方 LangChain 集成(langchain-brightdata),可以把实时搜索作为 agent 工具使用:
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # must match the zone name in your Bright Data dashboard
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True
)
# Override constructor defaults for this specific request:
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
"country": "de",
"language": "de",
"search_type": "shop",
"device_type": "mobile",
})使用该集成时需要注意几点:
results_count内部映射为 Google 的num。由于num已失效(见 num 章节),设置为大于 10 不会生效。country与language映射为gl与hl(展示哪个国家的结果、界面语言)。不同于 Direct API(其中"country"控制代理出口),LangChain 会自动处理代理路由。zone默认是"serp"。如果你的 zone 名不同(例如"serp_api1"),请显式设置,否则会报 “zone not found”。
除了 LangChain,还可参考 CrewAI、AWS Bedrock、Google Vertex AI 的集成指南。非搜索类的数据采集可参见 Bright Data 的 AI web access 工具。
完整参数列表请见:SERP API 文档
为什么要使用托管 SERP API?
SERP API 可处理 JavaScript 渲染、代理轮换、验证码解决与地理定向:
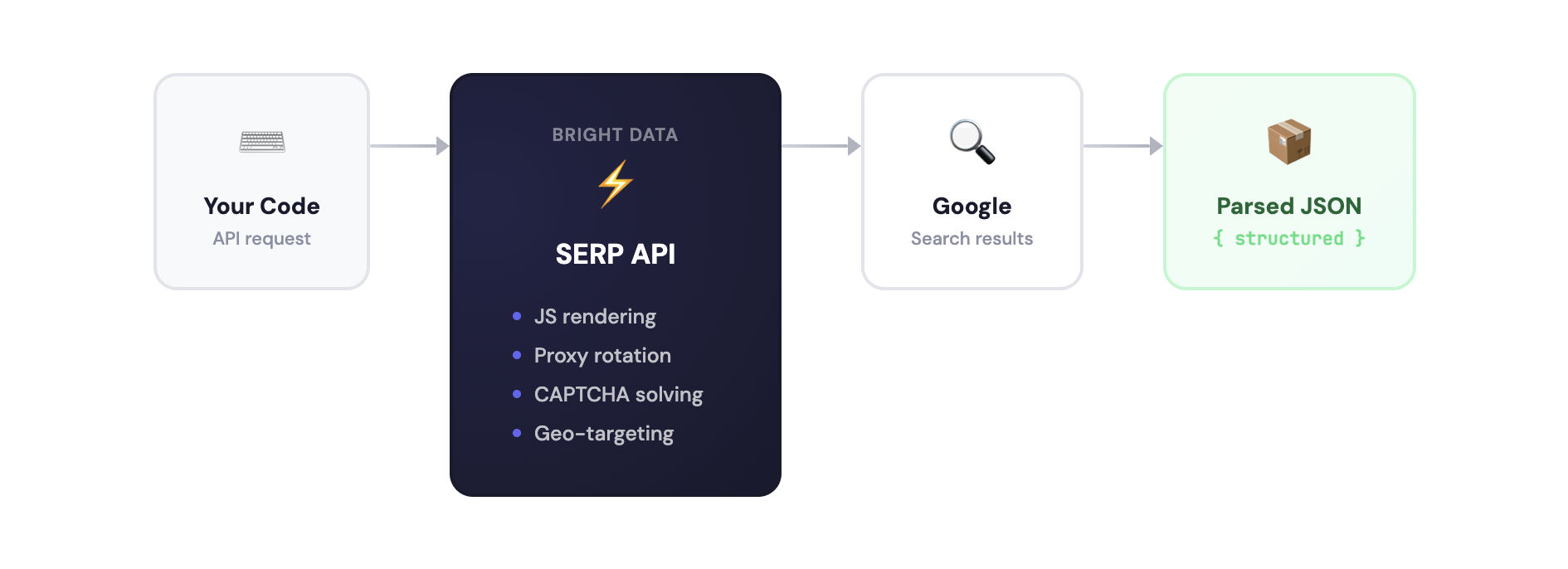
你也可以用 Playwright、Selenium 或 Bright Data 自家的 Browser API 自己搭建。但维护一个 Google 爬虫意味着要处理验证码、IP 封锁、住宅代理、JavaScript 渲染,以及 Google 每次更新 HTML 标记就会导致解析器失效的问题。对比可参考 托管抓取 vs API 抓取。
使用 SERP API,你只需提交搜索 URL,就能获得结构化 JSON。它支持 Google、Bing、DuckDuckGo、Yandex 等。当前价格请见 定价页。
SERP API Playground 支持无需写代码运行基础搜索,Postman workspace 也有预置请求。下面是 Playground:
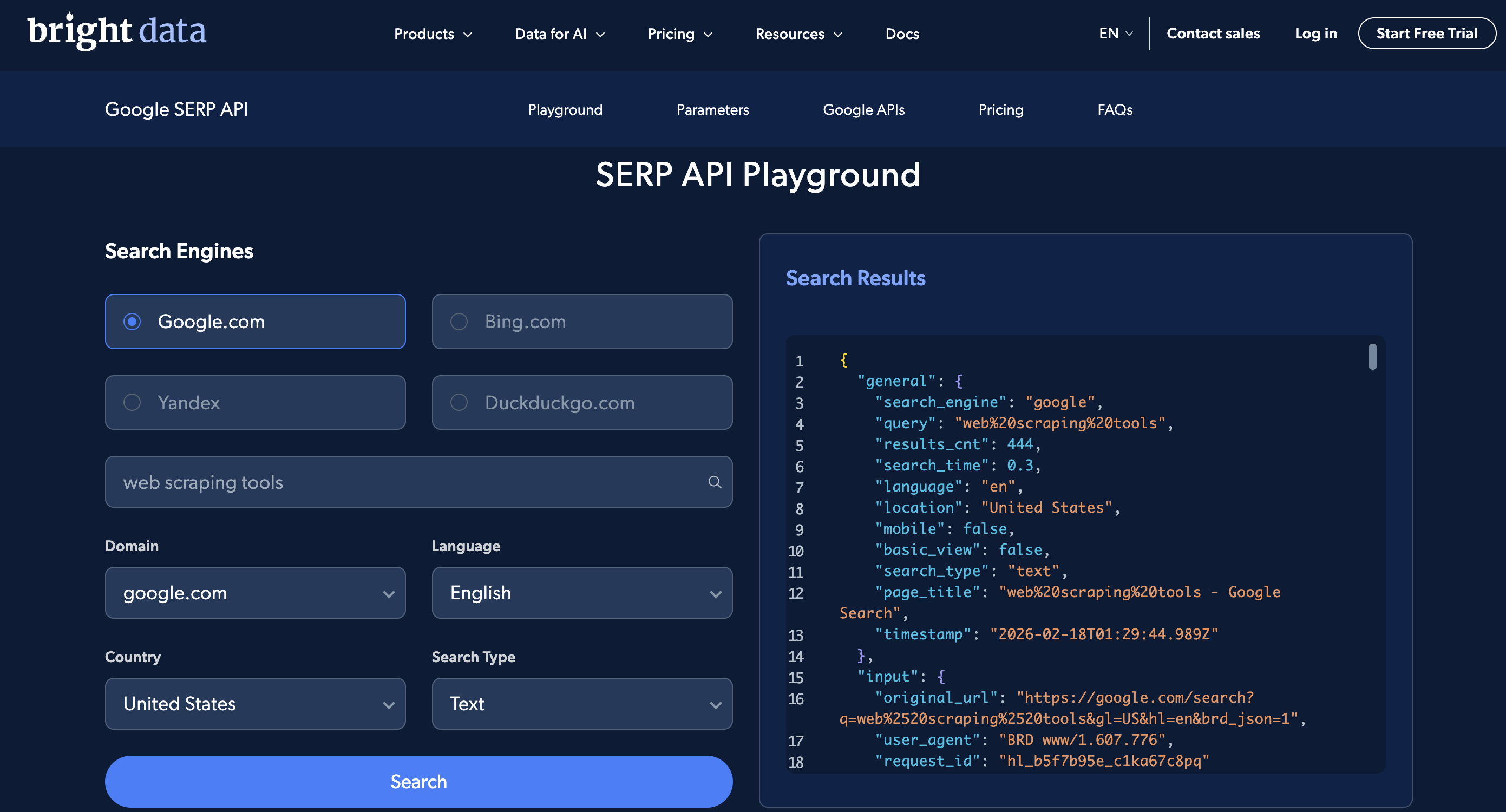
Playground 界面:选择搜索引擎、国家与语言,输入查询词,即可在右侧看到解析后的 JSON 响应。
创建账号即可运行上面的示例(新账号有免费额度用于测试)。
真实场景用例
下面这些参数组合会在生产级抓取工作流中反复出现。
SEO 排名追踪
通过组合 q、gl、hl、pws=0、udm=14 与 start 来跨地区追踪关键词排名:
# Check "web scraping tools" ranking in US, UK, and Germany
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=web+scraping+tools&gl=us&hl=en&pws=0&udm=14&brd_json=1"
# Then repeat with gl=gb and gl=de
# Use start=10, start=20 to check positions beyond page 1完整教程见 如何用 v0 与 SERP API 构建 SEO 排名追踪器。
竞品广告监测
竞品的广告位每天都在变化。将品牌词与 tbs=qdr:d 组合可发现近期变化:
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1JSON 响应会将 top_ads、bottom_ads 与 popular_products(PLA 商品广告)从自然结果中分离出来。
比价与电商情报
要跨市场比价,可保持 tbm=shop 不变、只更换 gl:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1新闻监测与情绪分析
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1。用 tbm=nws 获取新闻,用 tbs=qdr:h 获取过去 1 小时,用 filter=0 防止 Google 把相似文章聚类。用 cron 每小时跑一次即可做小时级覆盖监控。
AI 搜索与 RAG 应用
使用 SERP API 作为检索层,让 LLM 应用基于实时搜索数据做 grounding。LangChain 集成(方法 4)、MCP server 与 Direct API 调用都可行。可参考 如何用 SERP API 构建 RAG 聊天机器人 获取可运行示例。
本地 SEO 与多地点监控
本地排名在同一国家不同城市之间差异可能很大。使用 uule 搭配 gl 与 pws=0 做对比:
# Check rankings for "plumber near me" in 3 cities
curl --proxy brd.superproxy.io:33335 \
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k \
"https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1"
# Repeat with uule=Miami,Florida,United+States and uule=Seattle,Washington,United+States对比不同地点的 snack_pack(本地 3-pack)与 organic 结果,以定位哪些地区的商家信息需要优化。
学术与市场调研
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1组合 site:、lr 与带日期范围的 tbs 筛选,可构建更聚焦的研究数据集。你可以把 arxiv.org 替换为 scholar.google.com、pubmed.ncbi.nlm.nih.gov 或任意域名。
结论
上面内容里真正重要的是:
- 用
gl+hl+pws=0+udm=14做跨市场一致、非个性化的排名追踪 num已死。用start分页,或用 Bright Data 的 Top 100 端点批量获取结果udm=14可移除 AI Overviews,返回经典自然结果;udm在tbm基础上扩展了更多模式tbs负责时间筛选、按日期排序(sbd:1)与逐字搜索(li:1)- 特殊字符需要 URL 编码。最常见的编码错误是
ibp=htl%3Bjobs里的分号,以及非拉丁查询词未编码
Google 会持续更改这些参数。他们毫无预警移除了 num,也可能对 start 做同样的事,或用 udm 取代 tbm。如果你有任何规模的抓取需求,Bright Data SERP API 能处理渲染、轮换与解析。用上面的示例试用即可。
下一步
根据你的用例推荐阅读:
如果你想现在就开始抓取 Google:
- 如何用 Python 抓取 Google 搜索结果:完整 Python 教程与可用代码
- 如何抓取 Google AI Overview:抽取 AI 生成摘要
- 如何抓取 Google AI Mode:抓取 Google 的对话式 AI 搜索
如果你在构建 AI 应用:
- 用 SERP API 构建 RAG 聊天机器人:用实时搜索数据为 LLM 输出做 grounding
- 用 v0 与 SERP API 构建 SEO 排名追踪器:一步步指南
- GEO & SEO AI Agent:为 AI 搜索引擎优化内容
- CrewAI + SERP API:多代理 AI 工作流
如果你在评估 SERP API 供应商:
- 2026 年最佳 SERP 与 Web Search APIs:主流供应商横向对比
- 托管抓取 vs API 抓取:托管服务与 API 方案对比
其他 Google 数据源:
- 如何抓取 Google Trends 数据
- 最佳酒店数据供应商:酒店数据采集服务对比
- 最佳航班数据供应商:航班数据采集服务对比
外部参考:
- 优化 Google 搜索:Google 官方搜索优化指南
参考资料:
常见问题
什么是 Google 搜索参数?
Google 搜索参数是附加在 https://www.google.com/search? 后的键值对,用于控制搜索结果的生成与展示方式。例如 q=pizza 设置查询词,gl=us 定向美国,hl=en 设置界面语言为英语。它们通过 & 分隔,位于 URL 的 ? 之后。
Google 搜索中 gl 与 hl 有何区别?
gl 控制地理位置(搜索看起来来自哪个国家),从而影响结果展示;hl 控制界面语言(Google 界面显示的语言)。例如 gl=de&hl=en 会返回与德国相关的结果,但界面显示为英语。
Google 的 num 参数被弃用了吗?
不仅是弃用——它已经完全不可用。Google 在 2025 年 9 月 12–14 日之间悄悄禁用了它。传 num=100 不会产生任何效果,Google 始终返回 10 条结果。请用 start 做分页,或使用 Bright Data 的 Web Scraper API Top 100 端点 一次获取第 1–100 名。
Google 的 udm 参数是什么?
udm 很可能代表 User Display Mode(基于社区逆向推测,Google 未确认缩写含义)。你最常用的是 udm=14,它会移除 AI Overviews 并返回经典自然结果。其他值包括 udm=2(图片)、udm=39(短视频)、udm=50(AI Mode)。udm 扩展了 tbm,两者目前都可用。所有取值都在 udm 章节列出。
tbm 与 udm 有何区别?
tbm 是较旧参数,udm 是更新的扩展。它们在图片、新闻、购物等模式上重叠(tbm=isch ≈ udm=2),但 udm 还包含 tbm 不支持的功能:AI Mode(udm=50)、论坛(udm=18)、短视频(udm=39)。两者目前都可用。新代码建议以 udm 为主,保留 tbm 作为回退。
num 失效后,如何对 Google 结果分页?
使用 start 参数。start=0(或省略)返回第 1–10 条,start=10 返回第 11–20 条,以此类推。每页固定 10 条。若要一次获取第 1–100 名,可用 Bright Data Top 100 端点的 start_page 与 end_page 参数。
如何按日期筛选 Google 结果?
使用 tbs 参数。tbs=qdr:h = 过去 1 小时,tbs=qdr:d = 过去 1 天,tbs=qdr:w = 过去 1 周,tbs=qdr:m = 过去 1 个月,tbs=qdr:y = 过去 1 年。自定义日期范围:tbs=cdr:1,cd_min:MM/DD/YYYY,cd_max:MM/DD/YYYY。加上 tbs=sbd:1 可按日期排序而非相关性排序。
如何抓取 Google 搜索结果而不被封锁?
规模化维护 Google 爬虫需要在 Google 更新标记时持续修复 HTML 解析器、解决验证码、轮换 IP,并且自 2025 年 1 月起每个请求都要进行 JavaScript 渲染。托管的 SERP API 可以处理这套基础设施:你提交 URL,拿到结构化 JSON,无需维护解析器。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。



