

在本教程中,您将学到
- CrewAI 是什么,它与其他人工智能代理库有何不同。
- 其最大的局限性以及如何利用 RAG 工作流程克服这些局限性。
- 如何将其与抓取 API 集成,为人工智能代理提供 SERP 数据,以便做出更准确的回应。
让我们深入了解一下!
什么是 CrewAI?
CrewAI是一个开源 Python 框架,用于协调和管理协作完成复杂任务的自主人工智能代理。与Browser Use 等单个代理系统不同,CrewAI 是围绕 “船员”(即一组代理)建立的。
在一个团队中,每个代理都有明确的角色、目标和工具集。具体来说,您可以为人工智能代理配备定制工具,以执行专门任务,如网络搜索、数据库连接等。这种方法为人工智能驱动的专业化问题解决和有效决策打开了大门。
CrewAI 的多代理架构可提高效率和可扩展性。CrewAI 定期添加新功能,例如支持 Qwen 模型和并行函数调用,使其成为一个快速发展的生态系统。
CrewAI 的局限性以及如何利用最新网络数据克服这些局限性
CrewAI 是一个用于构建多代理系统的功能丰富的框架。不过,它也继承了其所依赖的 LLMs 的一些主要局限性。由于 LLM 通常是在静态数据集上预先训练的,因此它们缺乏实时意识,通常无法访问最新新闻或实时网络内容。
这会导致答案过时,甚至产生幻觉。如果在 “检索-增强生成 “设置中,代理没有受到限制或没有获得最新、可信的数据,这些问题就特别容易出现。
为了解决这些局限性,您应该为代理(以及他们的 LLM)提供可靠的外部数据。网络是最全面、最动态的数据源,因此是理想的目标。因此,一种有效的方法是让 CrewAI 代理能够在谷歌或其他搜索引擎等平台上执行实时搜索查询。
这可以通过构建一个定制的 CrewAI 工具来实现,该工具可以让代理检索相关网页,并从中学习。然而,由于需要 JavaScript 渲染、验证码解码、IP 轮换和不断变化的网站结构,因此从技术上讲,搜索 SERP(搜索引擎结果页面)是一项挑战。
内部管理所有这些工作可能比开发 CrewAI 逻辑本身还要复杂。更好的解决方案是依靠顶级的 SERP 抓取 API,如 Bright Data 的 SERP API。这些服务可以处理从网络中提取干净、结构化数据的繁重工作。
通过将此类 API 集成到 CrewAI 工作流程中,您的代理可以访问新鲜准确的信息,而无需承担运营开销。通过将代理与特定领域的抓取 API 相连接,同样的策略也可应用于其他领域。
如何将 CrewAI 与 SERP API 集成以实现实时数据访问
在本指导章节中,您将了解如何让使用 CrewAI 构建的人工智能代理能够通过Bright Data SERP API 直接从SERP 引擎获取数据。
这种 RAG 集成使您的 CrewAI 代理能够提供更符合实际情况的最新结果,并提供真实世界的链接供进一步阅读。
请按照以下步骤与 Bright Data 的 SERP API 集成,建立一个超级团队!
先决条件
要学习本教程,请确保您已安装了以下设备:
- 一个 Bright Data API 密钥。
- 连接到 LLM 的 API 密钥(本教程将使用 Gemini)。
- 本地已安装 Python 3.10 或更高版本。
有关详细信息,请查看 CrewAI 文档的安装页面,其中包含最新的先决条件。
如果您还没有 Bright Data API 密钥,请不要担心,我们将在接下来的步骤中指导您创建。至于 LLM API 密钥,如果您没有,我们建议您按照 Google 官方指南设置一个 Gemini API 密钥。
步骤 #1:安装 CrewAI
首先在终端运行以下命令,全局安装 CrewAI:
pip install crewai注意:这将下载和配置多个软件包,因此可能需要一点时间。
如果在安装或使用过程中遇到问题,请参阅官方文档中的故障排除部分。
安装完成后,您就可以使用crewaiCLI 命令。在终端运行以下命令进行验证:
crewai您应该会看到类似的输出结果:
Usage: crewai [OPTIONS] COMMAND [ARGS]...
Top-level command group for crewai.
Options:
--version Show the version and exit.
--help Show this message and exit.
Commands:
chat Start a conversation with the Crew, collecting...
create Create a new crew, or flow.
deploy Deploy the Crew CLI group.
flow Flow related commands.
install Install the Crew.
log-tasks-outputs Retrieve your latest crew.kickoff() task outputs.
login Sign Up/Login to CrewAI+.
replay Replay the crew execution from a specific task.
reset-memories Reset the crew memories (long, short, entity,...
run Run the Crew.
signup Sign Up/Login to CrewAI+.
test Test the crew and evaluate the results.
tool Tool Repository related commands.
train Train the crew.
update Update the pyproject.toml of the Crew project to use...
version Show the installed version of crewai.太好了!现在,CrewAI CLI 已准备好初始化您的项目。
步骤 #2:项目设置
运行以下命令创建名为serp_agent 的新 CrewAI 项目:
crewai create crew serp_agent在设置过程中,系统会提示您选择首选的 LLM 提供商:
Select a provider to set up:
1. openai
2. anthropic
3. gemini
4. nvidia_nim
5. groq
6. huggingface
7. ollama
8. watson
9. bedrock
10. azure
11. cerebras
12. sambanova
13. other
q. Quit
Enter the number of your choice or 'q' to quit:在这种情况下,我们将选择 Gemini 的选项 “3”,因为其通过 API 的集成是免费的。
接下来,选择您要使用的特定双子座型号:
Select a model to use for Gemini:
1. gemini/gemini-1.5-flash
2. gemini/gemini-1.5-pro
3. gemini/gemini-2.0-flash-lite-001
4. gemini/gemini-2.0-flash-001
5. gemini/gemini-2.0-flash-thinking-exp-01-21
6. gemini/gemini-2.5-flash-preview-04-17
7. gemini/gemini-2.5-pro-exp-03-25
8. gemini/gemini-gemma-2-9b-it
9. gemini/gemini-gemma-2-27b-it
10. gemini/gemma-3-1b-it
11. gemini/gemma-3-4b-it
12. gemini/gemma-3-12b-it
13. gemini/gemma-3-27b-it
q. Quit在本例中,免费的gemini/gemini-1.5-flash型号就足够了。因此,可以选择 “1 “选项。
然后,系统会要求您输入双子座 API 密钥:
Enter your GEMINI API key from https://ai.dev/apikey (press Enter to skip):粘贴后,如果一切按预期进行,你应该会看到这样的输出结果:
API keys and model saved to .env file
Selected model: gemini/gemini-1.5-flash
- Created serp_agent.gitignore
- Created serp_agentpyproject.toml
- Created serp_agentREADME.md
- Created serp_agentknowledgeuser_preference.txt
- Created serp_agentsrcserp_agent__init__.py
- Created serp_agentsrcserp_agentmain.py
- Created serp_agentsrcserp_agentcrew.py
- Created serp_agentsrcserp_agenttoolscustom_tool.py
- Created serp_agentsrcserp_agenttools__init__.py
- Created serp_agentsrcserp_agentconfigagents.yaml
- Created serp_agentsrcserp_agentconfigtasks.yaml
Crew serp_agent created successfully!该程序将生成以下项目结构:
serp_agent/
├── .gitignore
├── pyproject.toml
├── README.md
├── .env
├── knowledge/
├── tests/
└── src/
└── serp_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yaml给你
main.py是项目的主要入口。crew.py是您定义船员逻辑的地方。config/agents.yaml定义了人工智能代理。config/tasks.yaml定义了代理将处理的任务。tools/custom_tool.py可让您添加代理可以使用的自定义工具。.env存储API密钥和其他环境变量。
导航至项目文件夹并安装 CrewAI 依赖项:
cd serp_agent
crewai install最后一条命令将在项目目录下创建本地虚拟环境.venv文件夹。这将允许您在本地运行 CrewAI。
完美!现在,您拥有了一个使用 Gemini API 完全初始化的 CrewAI 项目。您已经准备好构建和运行您的智能 SERP 代理。
步骤 #3:开始使用 SERP API
如前所述,我们将使用 Bright Data 的 SERP API 从搜索引擎结果页面获取内容,并将其反馈给我们的 CrewAI 代理。具体来说,我们将根据用户的输入进行准确的谷歌搜索,并利用实时抓取的数据来改进代理的响应。
要设置 SERP API,请参阅官方文档。或者,请按照以下步骤操作。
如果尚未注册,请在 Bright Data 上注册一个账户。否则,只需登录即可。登录后,进入 “我的区域 “部分,点击 “SERP API “行:
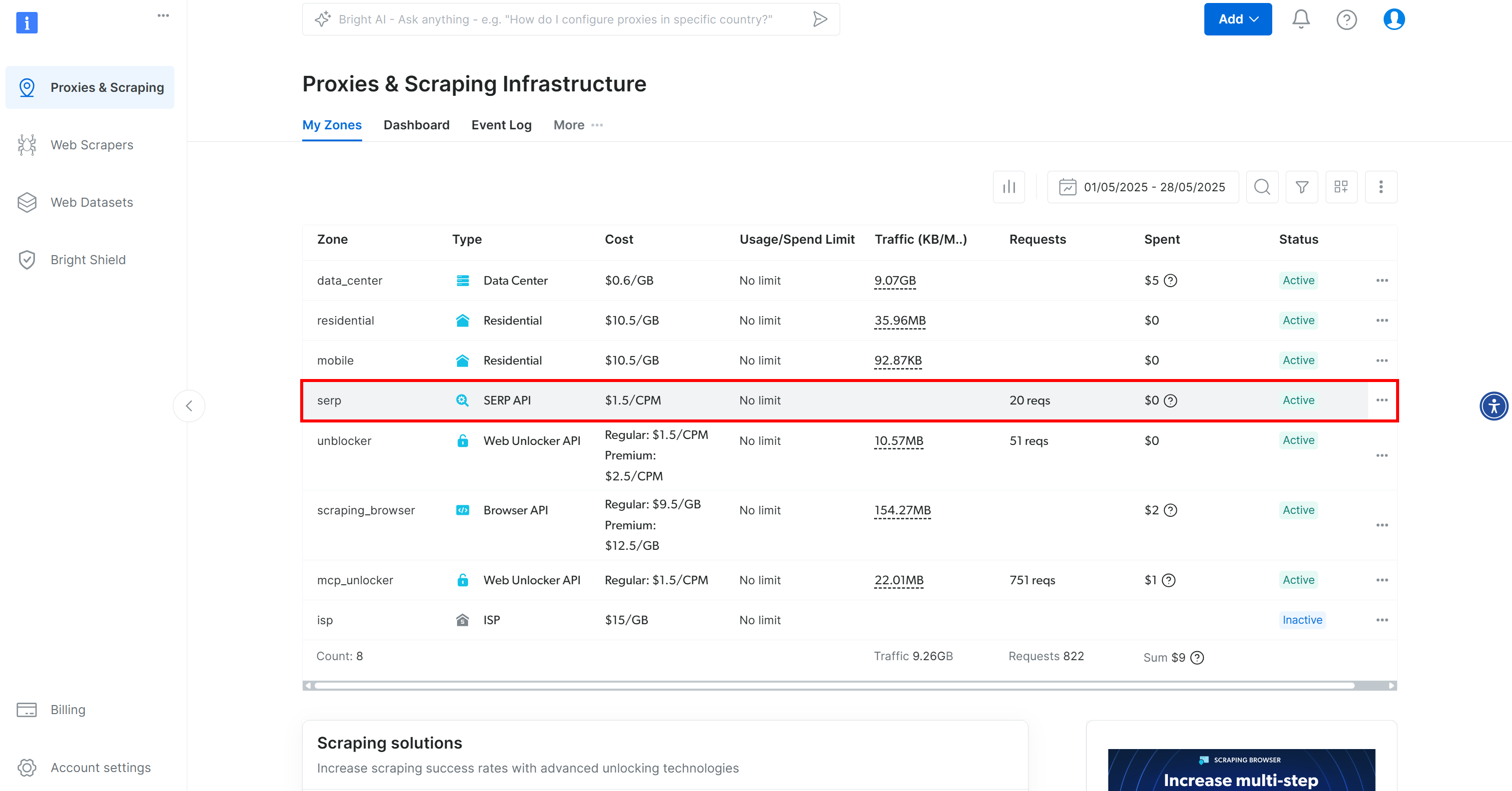
如果在表中没有看到该行,则表示您尚未配置 SERP API 区域。在这种情况下,向下滚动并单击 “SERP API “部分下的 “创建区域”:
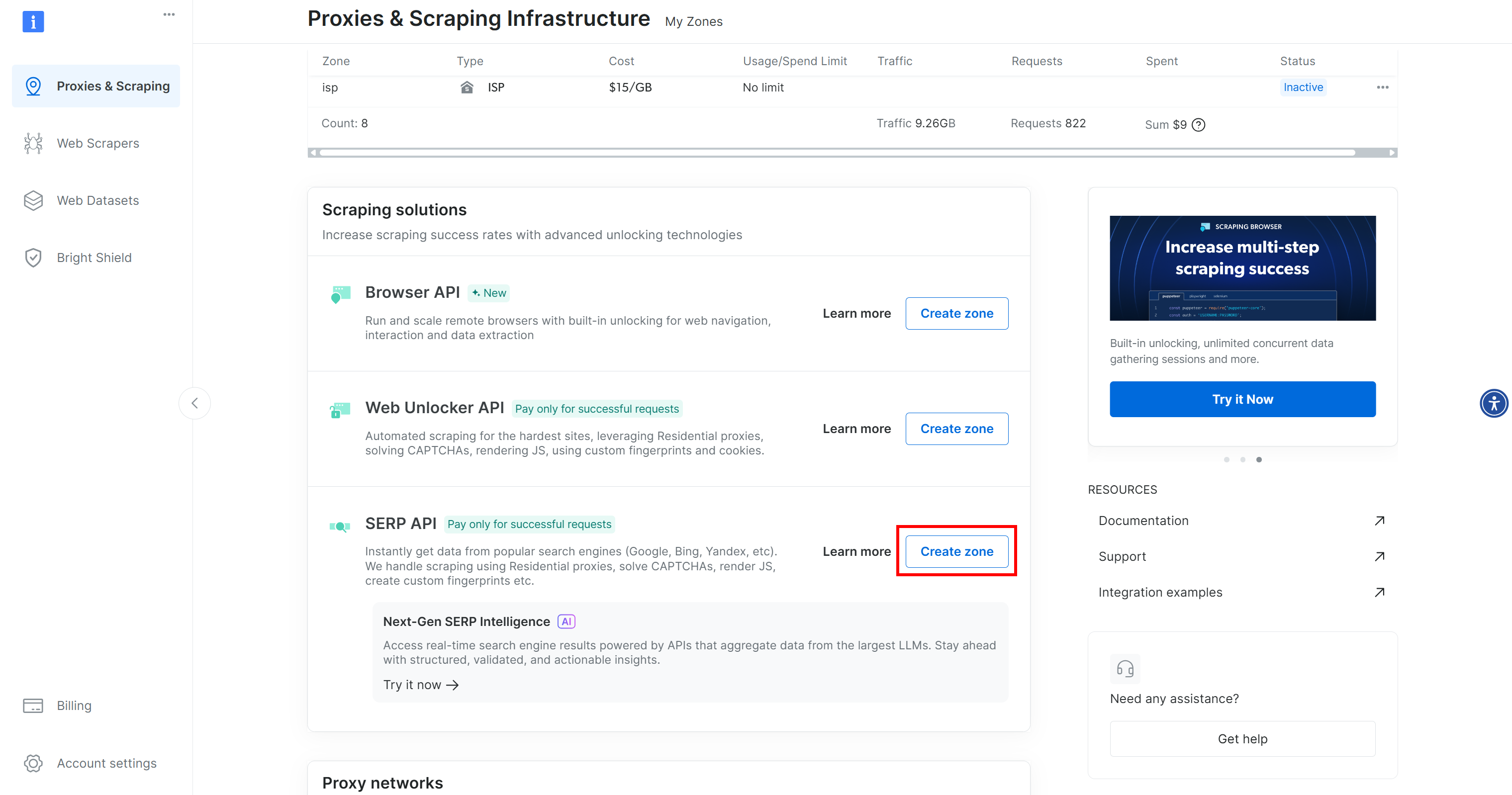
在 SERP API 产品页面上,切换 “激活 “开关以启用产品:
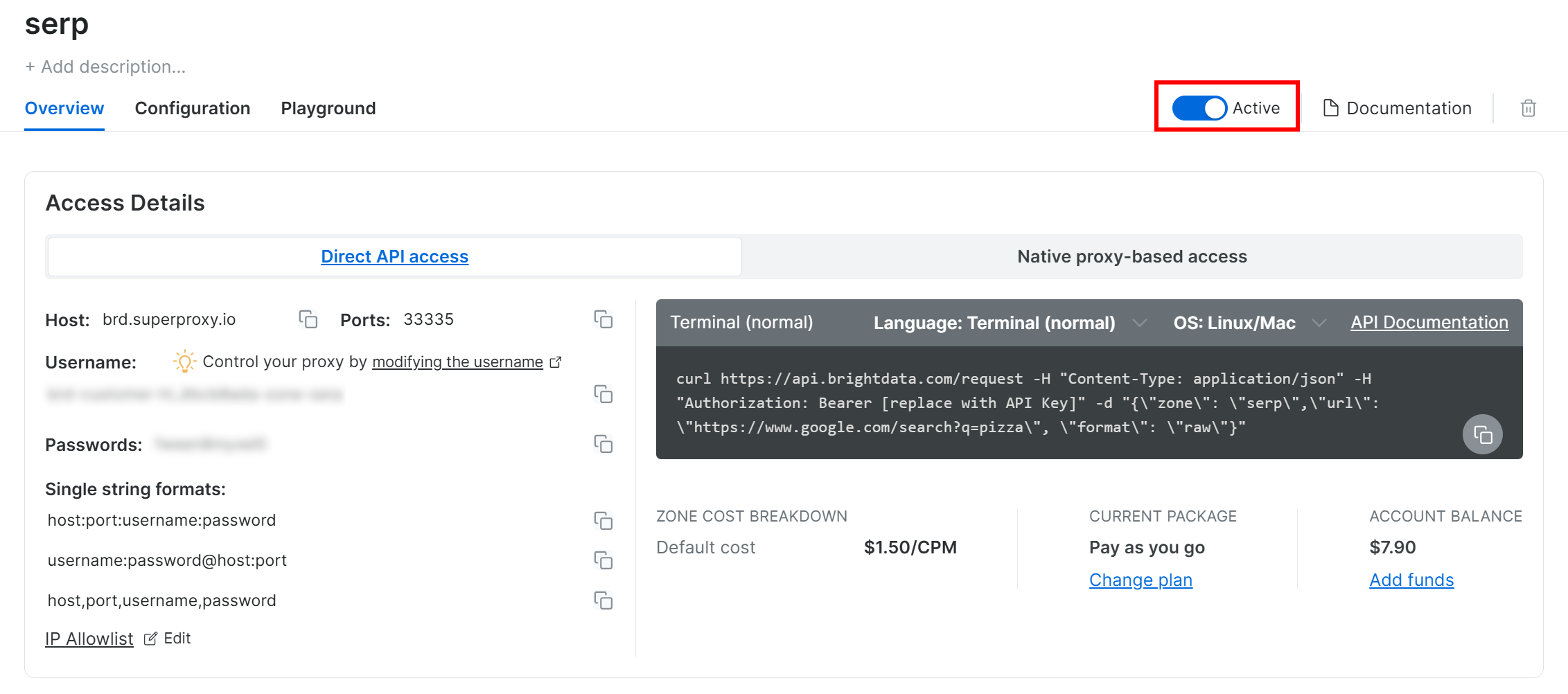
接下来,按照官方指南生成 Bright Data API 密钥。然后,将其添加到.env文件中,如下所示:
BRIGHT_DATA_API_KEY=<YOUR_BRIGHT_DATA_API_KEY>将 占位符替换为 Bright Data API 密钥的实际值。
就是这样!您现在可以在 CrewAI 集成中使用 Bright Data 的 SERP API。
步骤 #4:创建 CrewAI SERP 搜索工具
是时候定义一个 SERP 搜索工具了,您的代理可以使用该工具与 Bright Data SERP API 交互并检索搜索结果数据。
为此,请打开tools/文件夹中的custom_tool.py文件,并将其内容替换为以下内容:
# src/search_agent/tools/custom_tool.py
import os
import json
from typing import Type
import requests
from pydantic import BaseModel, PrivateAttr
from crewai.tools import BaseTool
class SerpSearchToolInput(BaseModel):
query: str
class SerpSearchTool(BaseTool):
_api_key: str = PrivateAttr()
name: str = "Bright Data SERP Search Tool"
description: str = """
Uses Bright Data's SERP API to retrieve real-time Google search results based on the user's query.
This tool fetches organic search listings to support agent responses with live data.
"""
args_schema: Type[BaseModel] = SerpSearchToolInput
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Read the Bright Data API key from the envs
self._api_key = os.environ.get("BRIGHT_DATA_API_KEY")
if not self._api_key:
raise ValueError("Missing Bright Data API key. Please set BRIGHT_DATA_API_KEY in your .env file")
def _run(self, query: str) -> str:
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self._api_key}"
}
payload = {
"zone": "serp", # Replace with the name of your actual Bright Data SERP API zone
"format": "json",
"url": f"https://www.google.com/search?q={query}&brd_json=1"
}
try:
response = requests.post(url, json=payload, headers=headers)
# Raise exceptions in case of errors
response.raise_for_status()
# Parse the JSON response
json_response = response.json()
response_body = json.loads(json_response.get("body", "{}"))
if "organic" not in response_body:
return "The response did not include organic search results."
# Return the SERP data as a JSON string
return json.dumps(response_body["organic"], indent=4)
except requests.exceptions.HTTPError as http_err:
return f"HTTP error occurred while querying Bright Data SERP API: {http_err}"
except requests.exceptions.RequestException as req_err:
return f"Network error occurred while connecting to Bright Data: {req_err}"
except (json.JSONDecodeError, KeyError) as parse_err:
return f"Error parsing Bright Data SERP API response: {parse_err}"此 CrewAI 工具定义了一个函数,该函数接收用户查询,并通过请求从Bright Data SERP API 获取SERP 结果。
请注意,当使用brd_json=1查询参数并将格式设置为json 时,SERP API 将以这种结构做出响应:
{
"status_code": 200,
"headers": {
"content-type": "application/json",
// omitted for brevity...
},
"body": "{"general":{"search_engine":"google","query":"pizza","results_cnt":1980000000, ...}}"
}特别是,在解析包含一个 JSON 字符串的body字段后,您将得到以下数据结构:
{
"general": {
"search_engine": "google",
"query": "pizza",
"results_cnt": 1980000000,
"search_time": 0.57,
"language": "en",
"mobile": false,
"basic_view": false,
"search_type": "text",
"page_title": "pizza - Google Search",
"timestamp": "2023-06-30T08:58:41.786Z"
},
"input": {
"original_url": "https://www.google.com/search?q=pizza&brd_json=1",
"request_id": "hl_1a1be908_i00lwqqxt1"
},
"organic": [
{
"link": "https://www.pizzahut.com/",
"display_link": "https://www.pizzahut.com",
"title": "Pizza Hut | Delivery & Carryout - No One OutPizzas The Hut!",
"rank": 1,
"global_rank": 1
},
{
"link": "https://www.dominos.com/en/",
"display_link": "https://www.dominos.com",
"title": "Domino's: Pizza Delivery & Carryout, Pasta, Chicken & More",
"description": "Order pizza, pasta, sandwiches & more online...",
"rank": 2,
"global_rank": 3
},
// ...additional organic results omitted for brevity
]
}因此,您主要感兴趣的是有机字段。这是在代码中访问、解析为 JSON 字符串并由工具返回的字段。
太棒了!您的 CrewAI 代理现在可以使用此工具检索新鲜的 SERP 数据。
步骤 #5:确定代理
要完成这项任务,您需要两个 CrewAI 代理,每个代理都有不同的用途:
- 研究员:从 Google 收集搜索结果并筛选有用的见解。
- 报告分析员:将研究结果汇编成结构化、可读性强的摘要。
您可以像这样在agents.yml文件中定义它们:
# src/search_agent/configs/agents.yml
researcher:
role: >
Online Research Specialist
goal: >
Conduct smart Google searches and collect relevant, trustworthy details from the top results.
backstory: >
You have a knack for phrasing search queries that deliver the most accurate and insightful content.
Your expertise lies in quickly identifying high-quality information from reputable sources.
reporting_analyst:
role: >
Strategic Report Creator
goal: >
Organize collected data into a clear, informative narrative that’s easy to understand and act on.
backstory: >
You excel at digesting raw information and turning it into meaningful analysis. Your work helps
teams make sense of data by presenting it in a well-structured and strategic format.请注意,这种配置捕捉到了每个代理应该做的事情–不多也不少。只需定义他们的角色、目标和背景故事。非常好!
步骤#6:为每个代理指定任务
准备好定义具体任务,明确概述每个代理在工作流程中的作用。根据 CrewAI 的文档,要获得准确的结果,任务定义比代理定义更重要。
因此,您需要在tasks.yml中明确告诉代理需要做什么,如下所示:
# src/search_agent/configs/tasks.yml
research_task:
description: >
Leverage SerpSearchTool to perform a targeted search based on the user's {query}.
Build API parameters like:
- 'query': develop a short, Google-like, keyword-optimized search phrase for search engines.
From the returned data, identify the most relevant and factual content.
expected_output: >
A file containing well-structured raw JSON content with the data from search results.
Avoid rewriting, summarizing, or modifying any content.
agent: researcher
output_file: output/serp_data.json
report_task:
description: >
Turn the collected data into a digestible, insight-rich report.
Address the user's {query} with fact-based findings. Add links for further reading. Do not fabricate or guess any information.
expected_output: >
A Markdown report with key takeaways and meaningful insights.
Keep the content brief and clearly, visually structured.
agent: reporting_analyst
context: [research_task]
output_file: output/report.md在此设置中,您要定义两个任务–每个代理一个:
research_task:告诉研究人员如何通过工具使用 Bright Data SERP API,包括如何根据查询动态建立 API 参数。report_task:指定最终输出应是一份可读的、内容翔实的报告,该报告完全由收集的数据构建而成。
该tasks.yml定义是您的 CrewAI 代理收集 SERP 数据并生成基于真实搜索结果的报告所需的全部内容。
是时候将 CrewAI 代理集成到您的代码中,让它们开始工作了!
步骤 #7:创建你的团队
现在,所有组件都已就位,将crew.py文件中的所有内容连接起来,就能创建一个功能齐全的船员团队。具体来说,您可以这样定义crew.py:
# src/search_agent/crew.py
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from .tools.custom_tool import SerpSearchTool
from crewai.agents.agent_builder.base_agent import BaseAgent
from typing import List
@CrewBase
class SerpAgent():
"""SerpAgent crew"""
agents: List[BaseAgent]
tasks: List[Task]
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config["researcher"],
tools=[SerpSearchTool()],
verbose=True
)
@agent
def reporting_analyst(self) -> Agent:
return Agent(
config=self.agents_config["reporting_analyst"],
verbose=True
)
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config["research_task"],
output_file="output/serp_data.json"
)
@task
def report_task(self) -> Task:
return Task(
config=self.tasks_config["report_task"],
output_file="output/report.md"
)
@crew
def crew(self) -> Crew:
"""Creates the SerpAgent crew"""
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)在crew.py 中,您需要使用CrewAI 装饰器(本例中为@agent、@task 和@crew)来连接 YAML 文件中的逻辑和实际功能。
在这个例子中
研究人员代理可以访问SerpSearchTool,从而使用 Bright Data 的 SERP API 执行真正的 Google 搜索查询。报告分析器代理被配置为使用研究人员的输出结果生成最终报告。- 每个任务都与
tasks.yml中定义的内容相对应,并与相应的输出文件明确绑定。 - 进程设置为
顺序运行,确保研究员首先运行,然后将数据传递给reporting_analyst。
开始了您的SerpAgent团队已经准备就绪,可以开始执行任务了。
步骤 #8:创建主循环
在main.py 中,将用户的查询作为输入,触发机组人员:
# src/search_crew/main.py
import os
from serp_agent.crew import SerpAgent
# Create the output/ folder if it doesn"t already exist
os.makedirs("output", exist_ok=True)
def run():
try:
# Read the user's input and pass it to the crew
inputs = {"query": input("nSearch for: ").strip()}
# Start the SERP agent crew
result = SerpAgent().crew().kickoff(
inputs=inputs
)
return result
except Exception as e:
print(f"An error occurred: {str(e)}")
if __name__ == "__main__":
run()任务完成!您的 CrewAI + SERP API 集成(使用双子座作为 LLM)现在已完全正常运行。只需运行main.py,输入搜索查询,就能看到工作人员收集和分析 SERP 数据并生成报告。
步骤 #9:运行人工智能代理
在项目文件夹中,使用以下命令运行 CrewAI 应用程序:
crewai run现在,输入一个查询,例如
"What are the new AI protocols?"这是一个典型的 LLM 可能很难准确回答的问题。原因是大多数最新的人工智能协议,如 CMP、A2A、AGP 和 ACP,在最初训练模型时并不存在。
以下是详细情况:
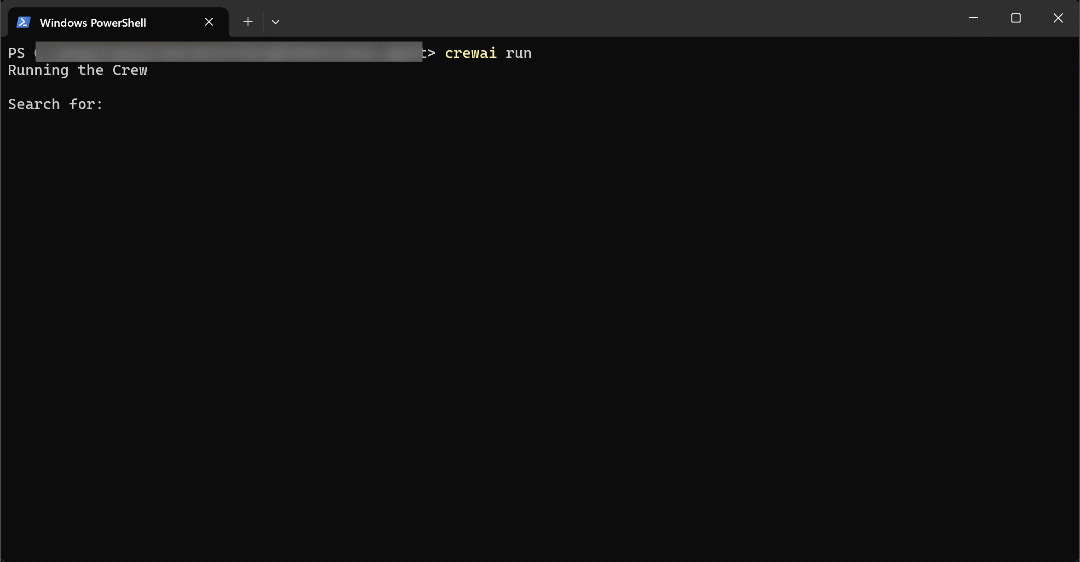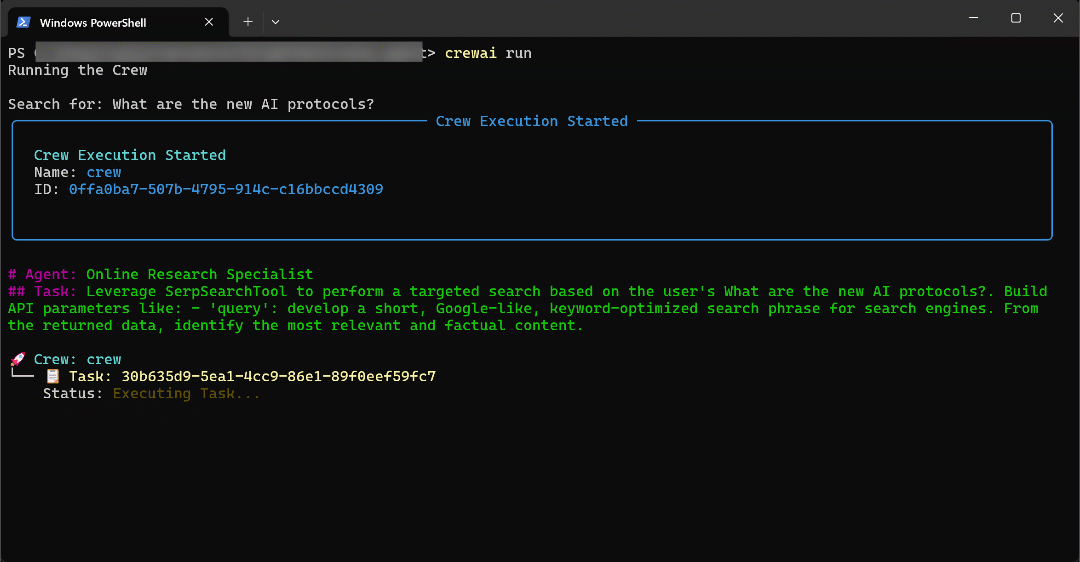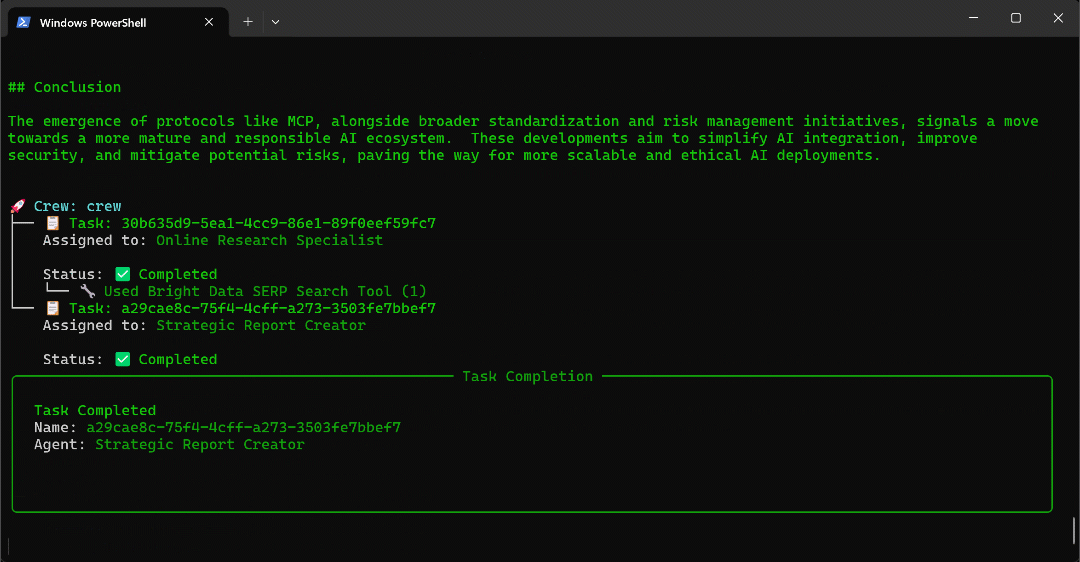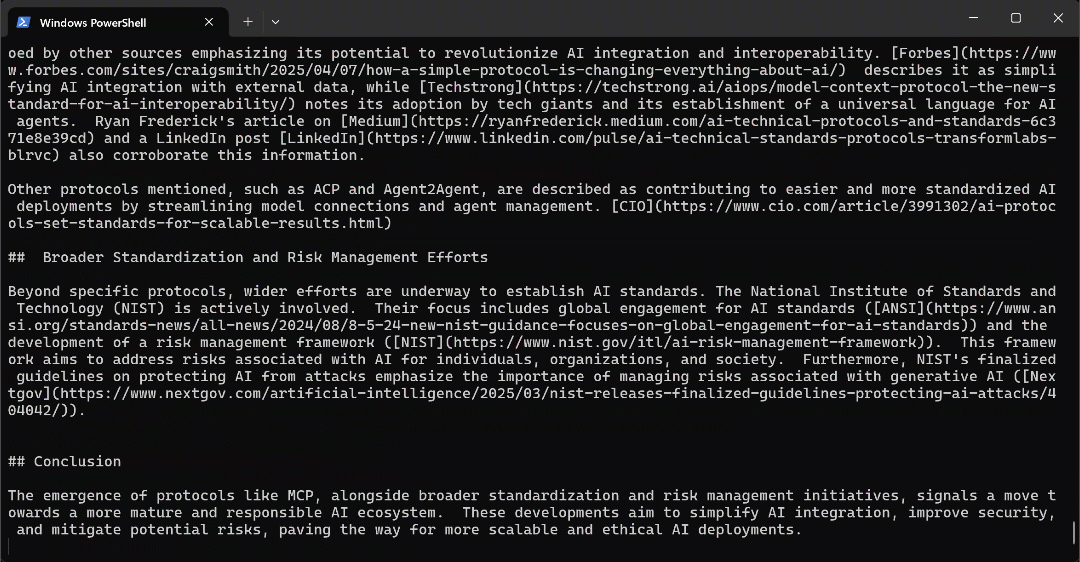
如上图所示,CrewAI 是这样处理请求的:
- 执行
研究代理:- 将用户输入转化为结构化查询
"新人工智能协议" - 通过
SerpSearchTool向 Bright Data 的 SERP API 发送查询。 - 接收来自 API 的结果,并将其保存到
output/serp_data.json文件中。
- 将用户输入转化为结构化查询
- 然后触发
reporting_analyst代理,该代理的功能是- 从
serp_data.json文件读取结构化数据。 - 利用这些新信息,用 Markdown 生成上下文感知报告。
- 将最终结构化报告保存为
output/report.md。
- 从
如果使用 Markdown 查看器打开report.md,会看到类似下面的内容:
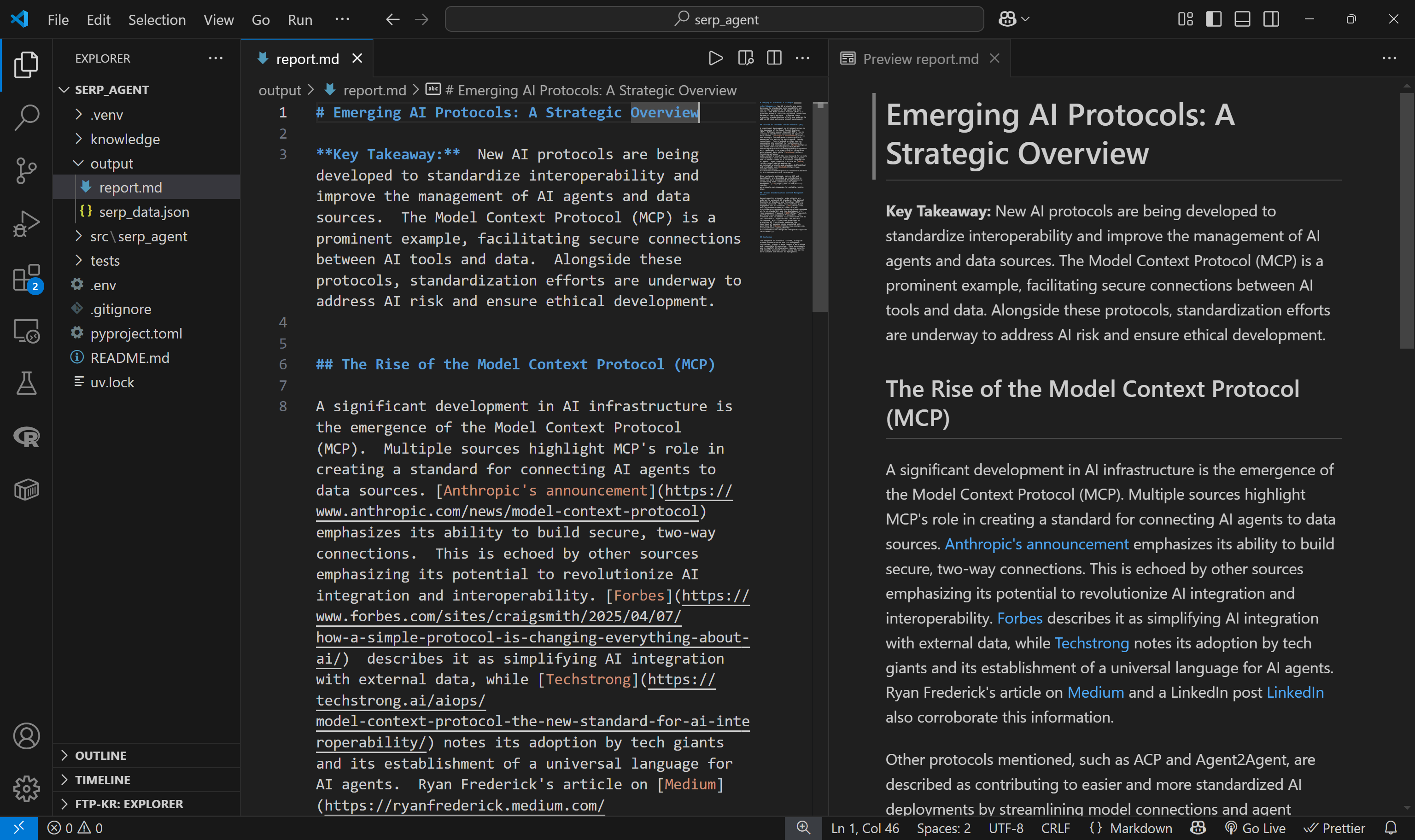
报告包括相关的背景信息,甚至还有帮助您深入研究的链接。
就是这样!通过与 SERP API 集成,您刚刚在 CrewAI 中实施了 RAG 工作流程。
下一步工作
集成到 Crew 中的 Bright Data SERP API 工具可以让代理接收到最新的搜索引擎结果。有了这些 SERP 的 URL,您就可以使用它们调用其他刮削 API,从链接的页面中提取原始内容–既可以是未经处理的形式(转换成 Markdown 并提供给代理),也可以是已经解析过的 JSON。
这个想法可以让代理自动发现一些可靠的信息源,并从中获取最新信息。此外,您还可以集成Agent Browser等解决方案,让座席人员与任何实时网页进行动态交互。
以上只是几个例子,但潜在的场景和用例几乎是无限的。
结论
在这篇博文中,您将了解如何通过使用 Bright Data 的 SERP API 集成 RAG 设置,使 CrewAI 代理更具上下文感知能力。
正如所解释的那样,通过将代理与外部搜索 API 或自动化工具连接起来,这只是您可以探索的众多可能性之一。特别是,Bright Data 的解决方案可以作为智能人工智能工作流的强大构建模块。
利用 Bright Data 的工具提升您的人工智能基础架构:
- 自主人工智能代理:使用一套功能强大的应用程序接口,实时搜索、访问任何网站并与之互动。
- 垂直 AI 应用程序:建立可靠的自定义数据管道,从特定行业来源提取网络数据。
- 基础模型:访问符合要求的网络规模数据集,以便进行预训练、评估和微调。
- 多模态人工智能:利用世界上最大的图像、视频和音频资源库,为人工智能进行优化。
- 数据提供商:与值得信赖的提供商建立联系,大规模获取高质量的人工智能就绪数据集。
- 数据包:获取精心策划、随时可用、结构化、丰富和注释的数据集。
如需了解更多信息,请访问我们的人工智能中心。
创建 Bright Data 帐户,试用我们为人工智能代理开发提供的所有产品和服务!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




