

在本教程中,你将学到:
- 什么是 Flyte,以及它在 AI、数据与机器学习工作流方面的独特之处。
- 为什么在工作流中引入网页数据会让 Flyte 更加强大。
- 如何将 Flyte 与 Bright Data SDK 集成,构建一个用于 SEO 分析的 AI 工作流。
开始吧!
什么是 Flyte?
Flyte 是一个现代的开源工作流编排平台,帮助你创建可用于生产的 AI、数据与机器学习流水线。它的核心优势在于统一团队与技术栈,促进数据科学家、ML 工程师与开发者之间的协作。
Flyte 构建于 Kubernetes 之上,具备可扩展性、可复现性与分布式处理能力。你可以通过其 Python SDK 来定义工作流,然后将其部署到云端或本地环境,从而实现高效的资源利用与简化的工作流管理。
截至撰写时,Flyte 的 GitHub 仓库已获得超过 6.5k 颗星!
核心特性
Flyte 支持的主要特性包括:
- 强类型接口:在每个步骤定义数据类型,以确保正确性并建立数据护栏。
- 不可变性:不可变执行可通过防止工作流状态被更改来保证可复现性。
- 数据血缘:跟踪数据在整个工作流生命周期中的流转与变换。
- 映射任务与并行性:以最小配置高效地并行执行任务。
- 细粒度重跑与故障恢复:只重试失败的任务,或在不改变以往状态的前提下重跑特定任务。
- 缓存:缓存任务输出以优化重复执行。
- 动态工作流与分支:构建可根据需求演进的自适应工作流,并选择性执行分支。
- 语言灵活性:使用 Python、Java、Scala、JavaScript 的 SDK,或任意语言的原始容器来开发工作流。
- 云原生部署:在 AWS、GCP、Azure 或其他云提供商上部署 Flyte。
- 从开发到生产的简易性:几乎无成本地将工作流从开发或预发环境迁移至生产。
- 外部输入处理:在所需输入可用之前暂停执行。
要了解全部功能,请参考官方 Flyte 文档。
为什么 AI 工作流需要新鲜的网页数据
AI 工作流的能力取决于其处理的数据。公开数据固然有用,但从商业角度看,实时数据才是关键。那么最大、最丰富的数据来源是什么?当然是互联网!
将实时网页数据引入 AI 工作流,你可以获得更深入的洞察、提升预测准确性,并做出更明智的决策。比如,SEO 分析、市场调研或品牌情绪跟踪等任务都依赖不断变化的最新在线信息。
问题在于,获取新鲜网页数据并不容易。网站结构各异、需要不同的抓取方式,并且经常更新。这正是Bright Data Python SDK能发挥作用的地方!
该 SDK 让你可以以编程方式搜索、抓取并与在线网页内容交互。更具体地说,它通过几个简单的方法调用,就能访问Bright Data 基础设施中最实用的产品。这让访问网页数据既可靠又可扩展。
结合 Flyte 与 Bright Data 的网页能力,你可以创建能随网络变化而保持最新的自动化 AI 工作流。下一章将展示如何实现!
如何在 Flyte 与 Bright Data Python SDK 中构建 SEO AI 工作流
在本指南中,你将学习如何在 Flyte 中构建一个 AI 智能体,它可以:
- 接收关键字(或关键词短语)作为输入,并使用 Bright Data SDK 在网上搜索相关结果。
- 使用 Bright Data SDK 抓取该关键词的前 3 个页面。
- 将这些页面的内容传递给 OpenAI,生成包含 SEO 洞察的 Markdown 报告。
换言之,借助 Flyte + Bright Data 的集成,你将构建一个面向实际的 SEO 分析 AI 工作流。它能基于排名靠前的页面在做什么来提供可操作的内容相关洞察。
我们开始吧!
先决条件
要跟随本教程,请确保你具备:
- 本地已安装 Python
- Bright Data API 密钥(具有Admin权限)
- OpenAI API 密钥
你将会在指南中了解如何为 Bright Data Python SDK 设置你的 Bright Data 账户,因此现在不必担心。更多信息请查看文档。
官方 Flyte 安装指南推荐通过 uv 安装。因此,全局安装/更新 uv:
pip install -U uv步骤 #1:项目初始化
打开终端,为你的 SEO 分析 AI 项目创建一个新目录:
mkdir flyte-seo-workflowflyte-seo-workflow/ 文件夹将包含你的 Flyte 工作流的 Python 代码。
然后进入该目录:
cd flyte-seo-workflow截至目前,Flyte 仅支持 Python 版本 >=3.9 且 <3.13(推荐 3.12)。
通过以下命令为 Python 3.12 创建虚拟环境:
uv venv --python 3.12激活虚拟环境。在 Linux 或 macOS 上执行:
source .venv/bin/activate在 Windows 上等效命令:
.venv/Scripts/activate新增一个名为 workflow.py 的文件。此时你的项目结构应为:
flyte-seo-workflow/
├── .venv/
└── workflow.pyworkflow.py 是你的主 Python 文件。
在激活的虚拟环境中安装所需依赖:
uv pip install flytekit brightdata-sdk openai上述库的作用如下:
flytekit:用于编写 Flyte 的工作流与任务。brightdata-sdk:在 Python 中访问 Bright Data 的解决方案。openai:与 OpenAI 的 LLM 交互。
注意:Flyte 提供了官方的 ChatGPT 连接器(ChatGPTTask),但它依赖较旧的 OpenAI API 版本,并存在一些限制(例如严格的超时)。因此,通常更建议使用自定义集成。
使用你喜欢的 Python IDE 打开项目。我们推荐安装 Python 扩展的 Visual Studio Code,或PyCharm 社区版。
完成!你现在已拥有一个可在 Flyte 中进行 AI 工作流开发的 Python 环境。
步骤 #2:设计你的 AI 工作流
在开始编码前,先退一步想清楚你的 AI 工作流需要做什么。
首先记住,Flyte 工作流由以下部分组成:
- 任务(Tasks):使用
@task注解的函数。它们是 Flyte 的基本计算单元,具备独立可执行、强类型与容器化等特性,是构建工作流的积木块。 - 工作流(Workflows):使用
@workflow标注。通过将任务串联起来构建,前一任务的输出作为下一任务的输入,形成一个有向无环图(DAG)。
在本例中,你可以通过以下三个简单任务实现目标:
get_seo_urls:给定关键字或词组,使用 Bright Data SDK 获取对应Google SERP(搜索结果页)中的前 3 个 URL。get_content_pages:接收这些 URL 作为输入,使用 Bright Data SDK 抓取页面,并以 Markdown 格式返回其内容(非常适合 AI 处理)。generate_seo_report:将页面内容列表传递给提示词,生成一个包含 SEO 洞察的 Markdown 报告,例如常见做法、关键统计(字数、段落数、H1/H2 数量等)以及其他相关指标。
通过从 flytekit 导入以下装饰器,为实现 Flyte 任务与工作流做准备:
from flytekit import task, workflow很好!接下来就是实现实际的工作流了。
步骤 #3:管理 API 密钥
在实现任务之前,你需要处理 OpenAI 与 Bright Data 的 API 密钥管理。
Flyte 内置密钥管理系统,可在脚本中安全地处理 API 密钥与凭证等机密信息。在生产中,依赖 Flyte 的密钥管理系统是最佳实践且强烈推荐。
在本教程中,由于我们只是一个简单脚本,可以在代码中直接设置 API 密钥以简化流程:
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"将占位符替换为你的实际 API 密钥值:
<YOUR_OPENAI_API_KEY>→ 你的 OpenAI API 密钥。<YOUR_BRIGHT_DATA_API_TOKEN>→ 你的 Bright Data API Token(获取方式详见官方 Bright Data 指南)
请注意,建议使用具备管理员权限的 Bright Data API 密钥。这样 Bright Data Python SDK 在初始化客户端时,可自动连接你的账户并完成所需产品的设置。
换句话说,使用管理员 API 密钥的 Bright Data Python SDK 将自动为你的账户完成运行所需的一切设置。
务必记住:不要在生产脚本中硬编码机密!请始终在 Flyte 中使用密钥管理器。
步骤 #4:实现 get_seo_urls 任务
定义一个接收字符串关键字的 get_seo_urls() 函数,并用 @task 注解使其成为 Flyte 任务。在函数内部,使用search() 方法(Bright Data Python SDK)执行网页搜索。
在底层,search() 会调用 Bright Data SERP API,并以如下格式返回 JSON 字符串形式的搜索结果:
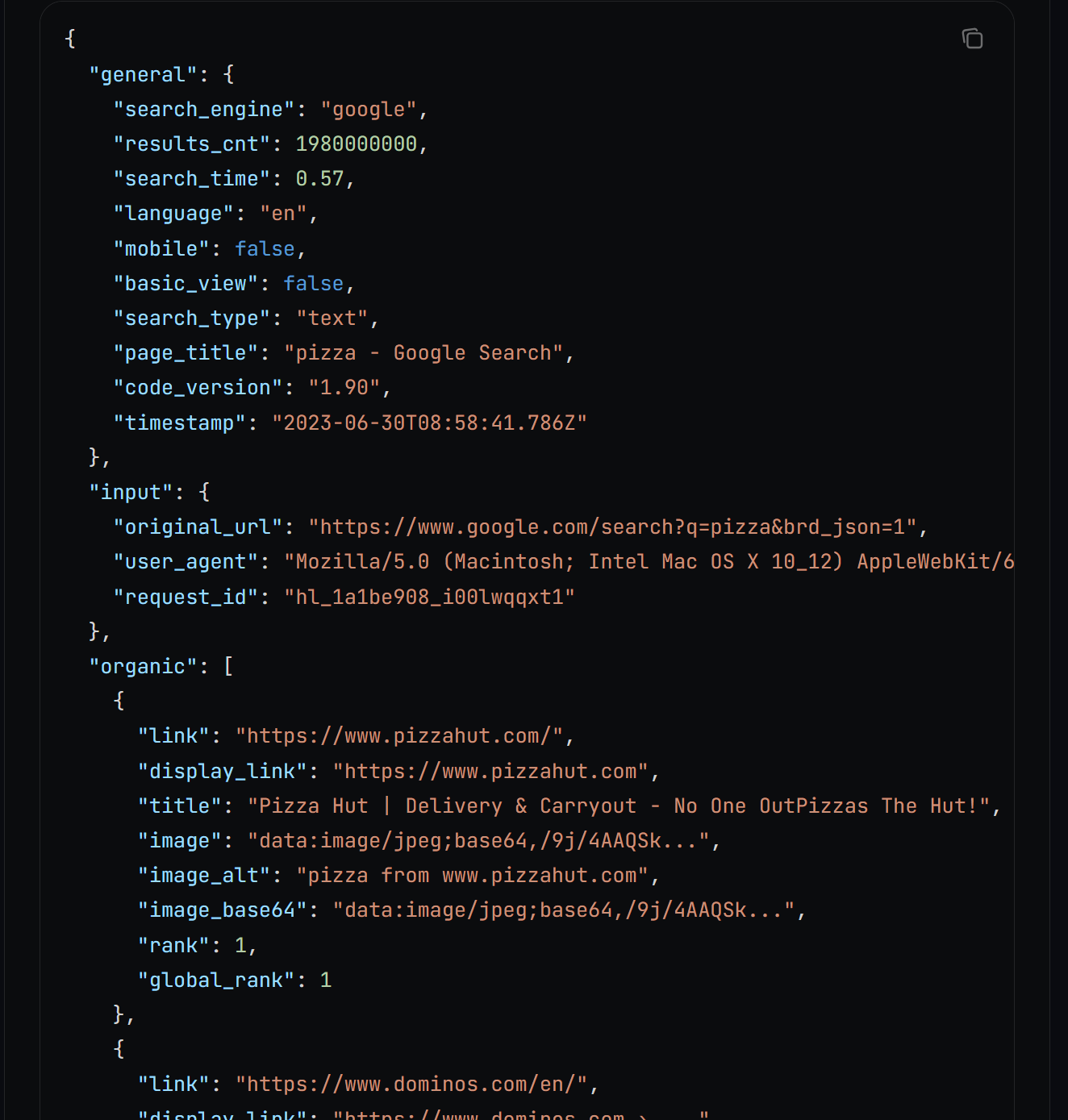
关于 JSON 输出功能,详见文档。
将 JSON 字符串解析为字典,并提取指定数量的 SEO URL。这些 URL 对应你在 Google 搜索该关键字时通常会得到的前 X 个结果。
任务实现如下:
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Google SERP for the given keyword as a parsed JSON string
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"]
data = json.loads(json_response)
# Extract the top "num_links" SEO page URLs from the SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls别忘了所需的类型提示导入:
from typing import List注意:你可能会好奇为什么在任务内部而不是全局导入 Bright Data Python SDK 客户端。这是有意而为之,因为 Flyte 任务应当独立可执行。换句话说,每个任务都应包含其自身运行所需的一切,而不依赖全局依赖项。
步骤 #5:实现 get_content_pages 任务
现在你已经拿到了 SEO URL,可以将它们传递给 scrape() 方法(Bright Data Python SDK)。该方法会并行抓取所有页面并返回其内容。若要以 Markdown 格式接收输出,只需设置 data_format="markdown" 参数:
@task()
def get_content_pages(page_urls:List[str]) -> List[str]:
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Markdown content from each page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list 将是一个字符串列表,其中每个字符串都是对应输入页面的 Markdown 表示。
在底层,scrape() 会调用 Bright Data Web Unlocker API。这是一个通用型抓取 API,无论页面的反爬策略如何,都能访问。
无论上一步得到哪些 URL,get_content_pages() 都能成功获取其内容,并将原始 HTML 转换为优化的、适合 AI 的 Markdown。
步骤 #6:实现 generate_seo_report 任务
使用合适的提示词调用 OpenAI API,根据抓取的页面内容生成 SEO 报告:
def generate_seo_report(page_content_list: List[str]) -> str:
# Initialize the OpenAI client to call the OpenAI APIs
from openai import OpenAI
openai_client = OpenAI()
# The prompt to generate the desired SEO report
prompt = f"""
# Given the content below for a few web pages,
# produce a structured report in Markdown format containing SEO insights obtained by analyzing the content of each page.
# The report should include:
# - Common topics and elements among all pages
# - Key differences between the pages
# - A summary table including statistics such as the number of words, number of paragraphs, counts of H2 and H3 headings, etc.
# CONTENT:
# {"nnPAGE:".join(page_content_list)}
# """
# Execute the prompt on the selected AI model
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text此任务的输出将是所需的 SEO Markdown 报告。
注意:上方使用的 OpenAI 模型是 GPT-5-mini,你也可以替换为其他 OpenAI 模型。同样地,你也可以替换 OpenAI,改用其他任何 LLM 提供商。
太棒了!任务已经就绪,现在是时候将它们组合为一个 Flyte AI 工作流。
步骤 #7:定义 AI 工作流
创建一个按顺序编排任务的 @workflow 函数:
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return report在该工作流中:
get_seo_urls任务为关键词 “best llms” 获取前 3 个 SEO URL。get_content_pages任务抓取这些 URL 的内容并转换为 Markdown。generate_seo_report任务接收上述 Markdown 内容并生成最终的 SEO 洞察报告(Markdown 格式)。
大功告成!
步骤 #8:整合全部代码
你的最终 workflow.py 文件应如下所示:
from flytekit import task, workflow
import os
from typing import List
# Set the required secrets (replace them with your API keys)
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Google SERP for the given keyword as a parsed JSON string
res = bright_data_client.search(kw, response_format="json", parse=True)
# Parse the JSON string to convert it into a dictionary
json_response = res["body"]
data = json.loads(json_response)
# Extract the top "num_links" SEO page URLs from the SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@task()
def get_content_pages(page_urls: List[str]) -> List[str]:
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Markdown content from each page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@task
def generate_seo_report(page_content_list: List[str]) -> str:
# Initialize the OpenAI client to call the OpenAI APIs
from openai import OpenAI
openai_client = OpenAI()
# The prompt to generate the desired SEO report
prompt = f"""
# Given the content below for a few web pages,
# produce a structured report in Markdown format containing SEO insights obtained by analyzing the content of each page.
# The report should include:
# - Common topics and elements among all pages
# - Key differences between the pages
# - A summary table including statistics such as the number of words, number of paragraphs, counts of H2 and H3 headings, etc.
# CONTENT:
# {"nnPAGE:".join(page_content_list)}
# """
# Execute the prompt on the selected AI model
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms" # Change it to match your SEO analysis goals
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return report
if __name__ == "__main__":
seo_ai_workflow()哇!不到 80 行 Python 代码,你就构建了一个完整的 SEO AI 工作流。如果没有 Flyte 和 Bright Data SDK,这是很难做到的。
你可以通过 CLI 运行该工作流:
pyflyte run workflow.py seo_ai_workflow该命令会从 workflow.py 文件中启动 seo_ai_workflow 这个 @workflow 函数。
注意:由于涉及网页搜索、抓取与 AI 处理,结果可能需要一些时间才能出现。
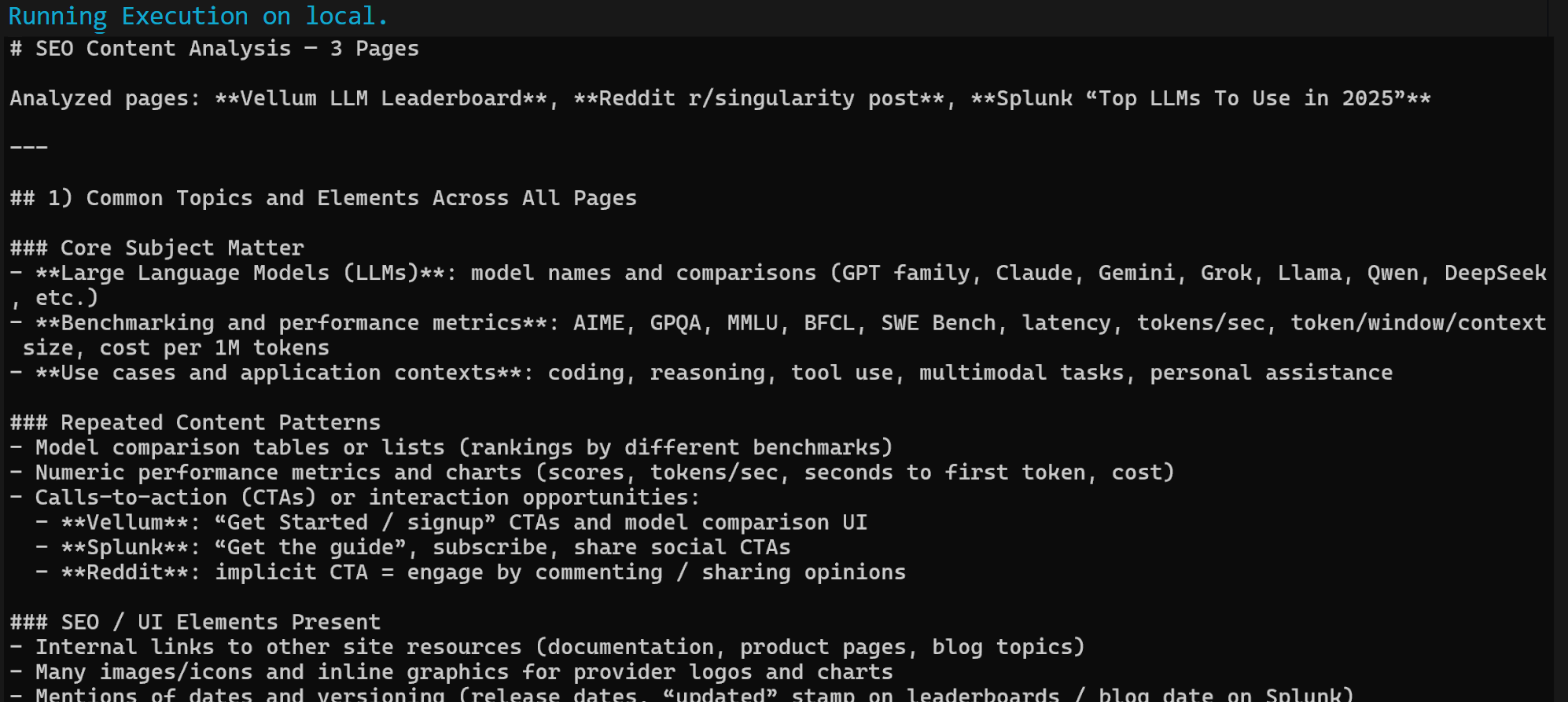
当工作流完成后,你应当会得到类似如下的 Markdown 输出:
将该 Markdown 输出粘贴到任意 Markdown 查看器中进行浏览与探索。效果类似如下:
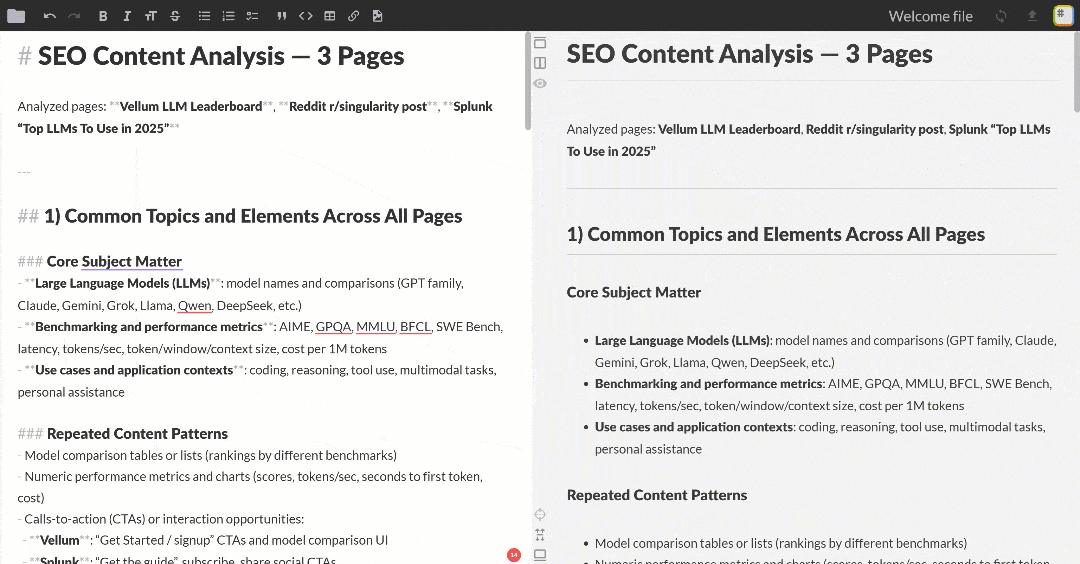
输出包含多个 SEO 洞察与一个汇总表,正如我们对 OpenAI 的请求所述。这只是 Flyte + Bright Data 集成威力的一个简单示例!
就是这样!欢迎继续定义其他任务,尝试不同的 LLM,以实现更多有用的Agent 化与 AI 工作流用例。
后续步骤
这里提供的 Flyte AI 工作流实现仅为示例。若要将其用于生产或进行更规范的实现,建议的后续步骤包括:
- 集成 Flyte 支持的密钥管理系统:避免在代码中硬编码 API 密钥。使用Flyte 任务密钥或其他受支持系统来安全且优雅地处理凭证。
- 提示词管理:在任务中生成提示词可行,但为确保可复现性,建议对提示词进行版本管理或外部存储。
- 部署工作流:按照官方指引对工作流进行容器化,并利用 Flyte 的能力为部署做好准备。
总结
本文介绍了如何在 Flyte 中使用 Bright Data 的网页搜索与抓取能力,创建一个 AI 驱动的 SEO 分析工作流。得益于Bright Data SDK 简洁的 API 调用方式,实现过程更为简单。
要构建更复杂的工作流,欢迎探索 Bright Data AI 基础设施中用于获取、校验与转换在线实时网页数据的完整方案。
免费注册 Bright Data 账户,开始体验我们的面向 AI 的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




