

在这篇关于托管式 vs 基于 API 的网页爬取文章中,你将看到:
- 托管式网页爬取服务与基于 API 的网页爬取方案的整体概览。
- 什么是托管式网页爬取、其工作原理、主要用例以及何时是最佳选择。
- 什么是网页爬取 API、其运作方式、核心用例以及在何种情况下价值最大。
- 最终的对比总结表,帮助你判断哪种方式更适合你的网页数据采集需求。
下面开始深入了解!
托管式网页爬取服务与网页爬取 API 简介
托管式网页爬取和基于 API 的网页爬取,是采集网页数据最常见的两种方式。在这两种模式下,网页爬取的主要技术难点(如浏览器指纹、JavaScript 渲染、TLS 指纹、请求频率限制、CAPTCHA 以及类似的反爬机制)都会被外包给第三方服务商。
在托管式服务中,整个爬取流程完全外包。服务商会和你一起梳理需求,并交付所需数据,通常还会附带洞察与定制化分析。从本质上看,这是一种端到端、交钥匙(turnkey)的解决方案。
而在基于 API 的网页爬取中,你需要构建自定义脚本、AI 代理或数据管道来连接爬取 API。这些 API 端点会从指定站点获取结构化网页数据,同时负责绕过反爬、扩展规模以及底层基础设施。但数据集成、存储及其它技术环节仍由你来负责。
无论采用哪种方式,选择一个可靠的服务商都至关重要。Bright Data 作为领先的网页爬取解决方案提供商,同时覆盖这两种方式:
- 托管式数据采集:通过企业级的全托管服务,在无需开发和维护投入的前提下直接获取数据和洞察。
- 网页爬取 API:为 120+ 热门平台提供丰富的爬取端点,支持自动代理轮换、反机器人绕过、JavaScript 渲染等能力。
Bright Data 的优势在于其企业级基础设施:为全球超过 20,000 家企业提供服务,具备 99.99% 在线率和成功率、7×24 小时专家支持、合规且道德来源的数据,以及覆盖 195 个国家、超过 1.5 亿真实用户 IP 的网络——是全球最大代理网络之一。
托管式网页爬取:深度解析
先从托管式网页数据采集服务开始,了解其适用场景。
概念说明
托管式网页爬取是一种端到端的数据采集服务,由服务商为你全权代劳。
这包括定位与获取网页、绕过反机器人系统、从目标页面解析数据、对结果进行验证和清洗、扩展底层基础设施,并交付符合你要求的结构化、可靠且合规的数据。
你无需构建和维护爬虫程序以及管理整个基础设施,只需向服务商描述自己的需求,服务商就会交付可直接使用的数据集、仪表盘或洞察结果。
托管式网页爬取的目标是节省时间、降低工程投入和运维成本,同时让你依然能够获得所需数据。
运作方式
选择托管式网页数据采集方案后,整个数据生命周期都会由服务商负责。从初始配置到最终交付,服务商会完成交付所需数据所涉及的各个环节,并按你期望的格式和呈现方式输出结果。
通常流程包括以下阶段:
- 项目启动:你先选择一个托管式数据采集服务,随后与服务商专家紧密合作,共同定义数据来源、所需字段、洞察维度和 KPI,并与业务目标对齐。
- 数据采集:托管服务商负责完整的数据采集流程。其团队会基于你的需求构建、自动化和扩展采集方案,并持续运行,由你的项目经理负责整体跟进。
此时,你已经能够访问所需数据。不过,优秀的服务商还会进一步执行以下步骤:
- 数据验证和富化:服务商会通过自动去重、交叉比对和持续质量监控来优化数据,目标是提供准确、一致、富化和高质量的数据。
- 报告与洞察:在数据采集和打磨完成后,服务商还能通过仪表盘、实时追踪以及专家指导,为你提供洞察,助力业务决策。
可以看到,这种方式真正实现了端到端覆盖,确保从数据获取、处理到结果交付的全过程都为你全权托管,将原始数据转化为可执行的知识。
前提与要求
使用托管式网页爬取服务,对你这边几乎没有技术要求。因为整个数据爬取过程都被外包出去,你无需具备构建爬虫、管理代理或维护基础设施的技术能力。
主要要求在于:对自身数据需求有清晰认识,例如目标站点、字段、记录数量以及更新频率等。当然,你也需要具备理解与利用交付结果的能力。
典型用例
托管式网页爬取可以支持几乎所有行业。服务商甚至可以同时聚合多个来源的数据,例如将多个电商平台的信息和社交媒体情绪分析数据合并在一起。
适用场景
当你缺乏相关技能、基础设施或人力来独立完成数据采集项目时,托管式网页爬取是理想选择。
原因在于,构建一条可靠的、由网页数据驱动的数据管道绝非易事。你需要选对爬取工具、整合代理,并实现各种反爬绕过机制,才能保证脚本在真实环境中有效运行。
除此以外,你还要持续监控目标网站的结构变化,确保自研软件长期稳定运行,并管理基础设施的扩展能力。而这些仅仅是打造和维护生产级网页爬取流程的一部分……
所有这些最终都会转化为在人员、服务器和第三方解决方案上的巨大时间与成本投入。通过选择托管式服务而不是完全自建,你可以避免这些投入,从而构建更高效的工作流,尤其适合缺乏网页爬取经验的团队,节省可观的资金。
例如,下图展示了选择 Bright Data 托管式网页爬取服务,而非自行实现和管理整个流程时的预估 ROI: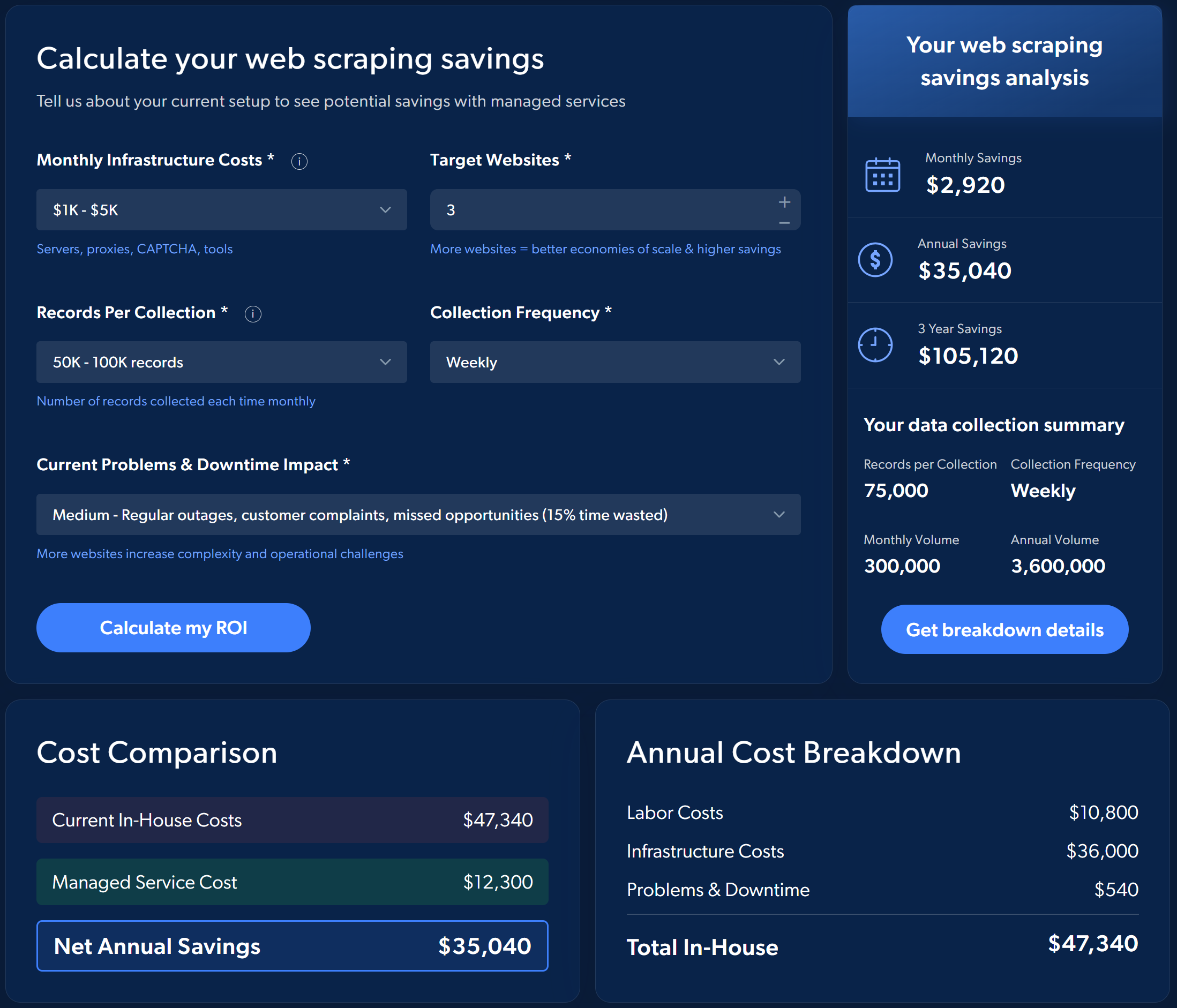
若想大致了解潜在节省空间,你可以直接在 Bright Data 托管式数据采集服务页面上运行一个简单的模拟计算。
简而言之,托管式服务非常适合希望获得可靠、最新、可扩展且经验证数据、又不打算投入专门团队的企业。
基于 API 的网页爬取:深入分析
接下来,通过对网页爬取 API 的介绍,继续本篇托管式 vs 基于 API 的网页爬取的探讨,涵盖你需要了解的关键信息。
概念说明
基于 API 的网页爬取,是指直接连接到爬取 API 解决方案来获取网页数据。这类 API 大致可以分为三种:
- 官方站点 API:由网站官方提供的接口,用于访问预定义的数据集。
- 通用 Web 解封 API:可绕过任意网页上的反机器人机制的端点。
- 特定站点网页爬取 API:针对特定域名进行爬取,并以约定好的结构化数据 schema 返回结果。
这里我们主要关注后两种网页爬取 API。原因在于,官方站点 API 通常价格较高、速率限制严格,而且你对数据暴露的控制权有限——网站随时可能停止对特定数据的开放。详细说明可以参考我们的 网页爬取 vs 官方 API 指南。
运作方式
基于 API 的网页爬取,介于完全自建与完全外包之间,是一个折中方案。
其核心思路是:你编写简单脚本连接到这些 API,由 API 来解决繁重任务,包括获取页面、处理 JavaScript 渲染、绕过反爬机制,并在部分场景中直接返回结构化数据。
你首先需要寻找合适的网页爬取 API 服务商。如果已有 API 能直接提供你想要的数据,应优先使用;否则可以选用 Web 解封 API,让其返回解封后的网页 HTML。
使用爬取 API 时,你只需编写简单脚本调用 API、在出现偶发错误时通过重试逻辑进行错误处理,并将返回数据存储到数据库、本地文件、云存储或你偏好的存储方案中。
若使用的是 Web 解封 API,则需要自行实现数据解析逻辑,可以依靠CSS 选择器 / XPath 表达式或人工智能,从解封的 HTML 中提取所需数据,然后再按前面提到的方式进行存储。
最后,数据还必须经过验证、清洗、处理和分析,才能产出真正的业务洞察。
前提与要求
虽然基于 API 的网页爬取比完全从零构建爬虫轻量得多,但仍需要一定的技术配置。
你需要具备基础编程能力,能够在自己熟悉的编程语言中编写脚本以编程方式调用 API。同时也要了解如何进行鉴权、管理并发 HTTP 请求并处理常见错误。
注意:顶级服务商通常还会提供无代码工具,让你在不写代码、无技术背景的情况下也能使用网页爬取 API。
为了保存采集的数据,你需要熟悉常见的数据存储方案。同时还必须具备数据管理能力,以避免重复数据、确保定期更新并保证正确的版本管理。
如果你选择的是 Web 解封 API 而非专用的网页爬取 API,还需要具备额外的 HTML 解析技能,将数据按需结构化。最后,在数据处理、可视化和分析阶段也需要一定的数据相关能力。
典型用例
网页爬取 API 支持的用例非常广泛,例如:
- 电商:从 Amazon、eBay、Walmart 等站点获取商品信息、价格、评论和卖家数据。
- 金融:从 Yahoo Finance、Nasdaq 等平台获取股价数据、财报、市场趋势等信息。
- 招聘与职场:从 LinkedIn、Indeed 等平台采集职位信息和公司数据。
- 旅游:从 Expedia、Booking.com 等网站追踪机票、酒店可用性和价格。
- B2B:从 Crunchbase、ZoomInfo 等来源获取公司信息。
- 社交媒体:从 X、Instagram、TikTok 等平台监测帖子、话题和互动情况。
- 搜索引擎:使用专业 SERP 与搜索 API,在 Google、Bing、Yandex 等搜索引擎上进行程序化搜索。
借助 Web 解封 API,你几乎可以从任意网站(即便该站点没有专门的爬取 API)获取结构化数据。
适用场景
基于 API 的爬取适用于需要稳定、结构化网页数据,又不希望将整个流程完全外包的场景。它在自建与托管之间取得了平衡——你可以保留对数据采集的控制权,而 API 则解决主要技术难题。
托管式 vs 基于 API 的网页爬取:正面对比
现在你已经了解了这两种获取网页数据的方式,接下来进入托管式 vs 基于 API 的对比环节。
如何选择合适的爬取方式
请参考下表,对比托管式网页爬取与基于 API 的网页爬取:
| 托管式网页爬取 | 基于 API 的网页爬取 | |
|---|---|---|
| 描述 | 你向服务商说明需求,由其从选定来源中提取数据并交付。 | 你连接到 API 来获取网页数据,由 API 处理页面抓取、反机器人绕过、代理集成等工作。 |
| 适用人群 | 缺乏内部技术能力或基础设施、需要“开箱即用”方案的企业。 | 拥有内部工程师或技术资源、希望在保留采集控制权的同时外包技术难点的团队。 |
| 配置与维护 | 由服务商端到端全程托管,你无需进行任何技术配置。 | 需要基础编程能力,并自行搭建脚本、错误处理和存储逻辑。 |
| 反机器人应对 | 完全由服务商负责。 | 完全由 API 服务商负责。 |
| 基础设施 | 完全由服务商管理。 | 底层由 API 服务商管理,但脚本的部署与集成由你负责。 |
| 数据交付 | 按你所需的格式和方式交付数据。 | 由爬取 API 以 HTML、JSON 或 Markdown 格式返回数据。 |
| 数据清洗与质检 | 由服务商执行自动验证、去重、富化及持续质量检查。 | 你需要对数据进行进一步验证、清洗和处理。 |
| 洞察与仪表盘 | 服务商可提供定制仪表盘、报告、分析和可执行洞察。 | 不包含。 |
| 咨询与策略 | 包含专家建议和指导,帮助优化数据采集与使用策略。 | 不包含。 |
| 支持 | 专属支持团队,包括数据礼宾(concierge),负责故障排查与项目管理。 | 通常仅限于 API 文档与基础技术支持。 |
托管式网页爬取
👍 优点:
- 可直接使用的结构化数据、仪表盘或洞察结果。
- 涵盖数据采集、验证、富化及交付的端到端服务,无需任何技术能力。
- 降低运营成本与工程投入。
- 几乎适用于任何用例、行业或场景。
- 由多领域专家团队提供支持和建议。
👎 缺点:
- 对爬取过程的可控性较低。
- 对某一第三方服务商存在较强依赖。
基于 API 的网页爬取
👍 优点:
- 易于集成到现有系统。
- 高吞吐和高并发,支持大量并行请求。
- 无需担心封禁或反机器人限制。
- 无需自行管理或维护底层基础设施。
- 非常适合为 AI 代理或自动化流程构建自定义爬取工具。
👎 缺点:
- 需要技术能力。
- 数据的验证、清洗和结构化工作由你负责。
总结点评
托管式网页服务和网页爬取 API 的目标都是交付网页数据,但解决问题的方式截然不同。
网页爬取 API 是面向开发者的数据获取端点,可直接集成到脚本、管道乃至 AI 代理与工作流中。当你只需要特定数据点(如商品价格、评论、搜索结果),又不想自建基础设施时,API 是理想选择。不过,它仍然需要一定的前期配置与技术能力。
相比之下,托管式网页数据采集服务则负责整个数据生命周期——从数据采集到验证、富化再到交付,全程无需内部工程团队或后续维护。
其中,Bright Data 的 Managed Data Acquisition(托管式数据采集) 方案正是这一模式的典型代表。它提供企业级数据管道、自动化质量检查、符合隐私法规的全流程合规,以及实时洞察仪表盘。你只需定义目标和 KPI,剩下的扩展、监控和交付可直接使用的结构化数据,全部交由 Bright Data 完成,助你最大化投资回报。
可以这样理解:API 给你的是“工具”,而托管式服务给你的是“成品”。
结论
在本指南中,我们详细分析了当前最主流的两种网页爬取方式:托管式服务与基于 API 的解决方案。
你已经了解到,当你希望获得完全“免操心”的体验时,托管式网页爬取是理想选择——不仅提供数据本身,还会交付验证过的数据集和有价值的业务洞察,而且无需处理复杂的技术细节。相对地,网页爬取 API 则提供更高的灵活性与控制权,但通常需要一定的编码经验。
无论你选择哪种方式,Bright Data 都能满足需求。我们既提供业界领先的网页爬取 API(例如 Unlocker API 和面向特定域名的 Scraper APIs),也提供企业级的托管式数据采集服务。
立即免费注册 Bright Data,开始体验我们的网页爬取解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




