Google AI 模式从根本上改变了搜索结果的呈现方式,提供由对话式 AI 驱动的回答,能够整合多个来源的信息。对于监测数字存在的企业、竞品情报团队以及 SEO 专业人士而言,这种新的搜索形式在数据提取方面既带来机遇,也带来挑战。
本综合指南将介绍什么是 Google AI 模式、为何抓取该数据能带来战略价值、你将面临的技术挑战,以及如何以手动与自动化方式在规模化场景下高效提取这些信息。
什么是 Google AI 模式?
Google AI 模式是 Google 新一代搜索体验,会在结果顶部提供经综合处理的对话式回答,允许用户自然地继续追问。每个回答都包含显著的来源链接,方便跳转到原始内容。
在底层,AI 模式与 Google 的搜索系统协同工作,并利用 Gemini 与“查询扇出(query fan-out)”方法。该技术将问题拆分为子主题并并行运行多个相关搜索,比传统的单次查询能挖掘出更相关的材料。
下面是 Google AI 模式在回答搜索查询时的示例,右侧展示可点击的引用来源:
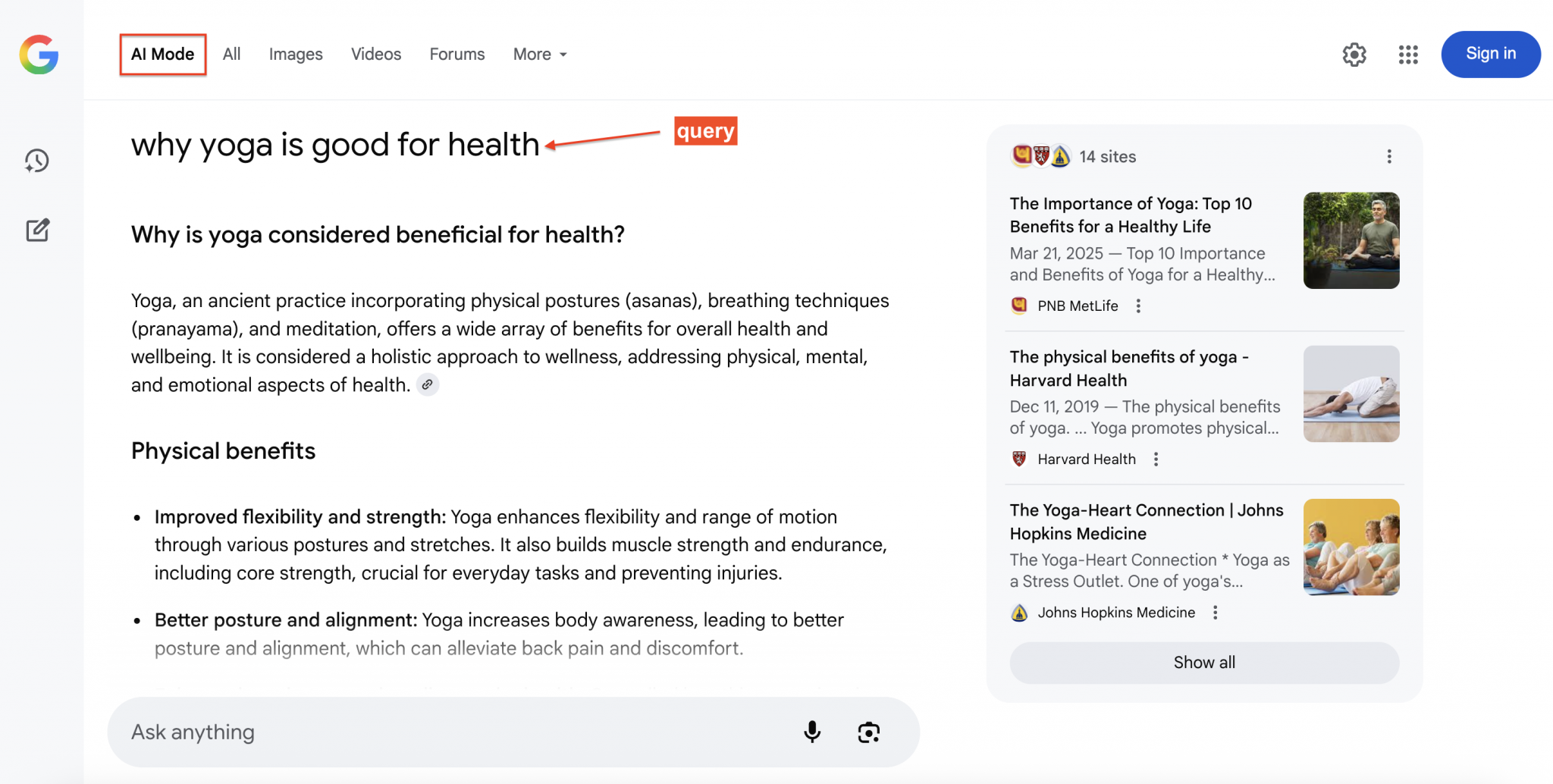
为什么要抓取 Google AI 模式数据?
Google AI 模式数据能提供可量化的洞察,对 SEO、产品开发与竞品研究具有显著影响。
- 引用份额追踪。监控 Google AI 在目标查询中引用了哪些域名,包括排序与随时间的出现频率。这反映主题权威度,并帮助衡量内容优化是否提升了 AI 回答中的收录率。
- 竞品情报。捕获在推荐与对比类查询中出现的品牌、产品或地点。这揭示市场定位、竞争态势,以及 AI 回答所强调的属性。
- 内容缺口分析。将 AI 模式回答中的关键信息与现有内容对比,识别结构化内容(如 FAQ、指南或数据表)创作机会,以争取更多引用。
- 品牌监测。审阅关于你品牌或行业的 AI 生成回答,识别过时信息并相应更新内容。
- 研发支持。将 AI 模式回答与元数据(时间戳、位置、实体)一起存储,为内部 AI 系统、研究团队和 RAG 应用提供支撑。
方法一——使用浏览器自动化进行手动抓取
由于 AI 生成内容具有动态、JS 负载重的特性,抓取 Google AI 模式需要成熟的浏览器自动化。像 Playwright、Selenium 或 Puppeteer 这样的浏览器自动化框架,通过真实浏览器内核执行 JavaScript、等待内容加载并复现人类浏览行为——这对捕获动态生成的 AI 回答至关重要。
以下是 Google AI 模式在搜索结果中的展示:
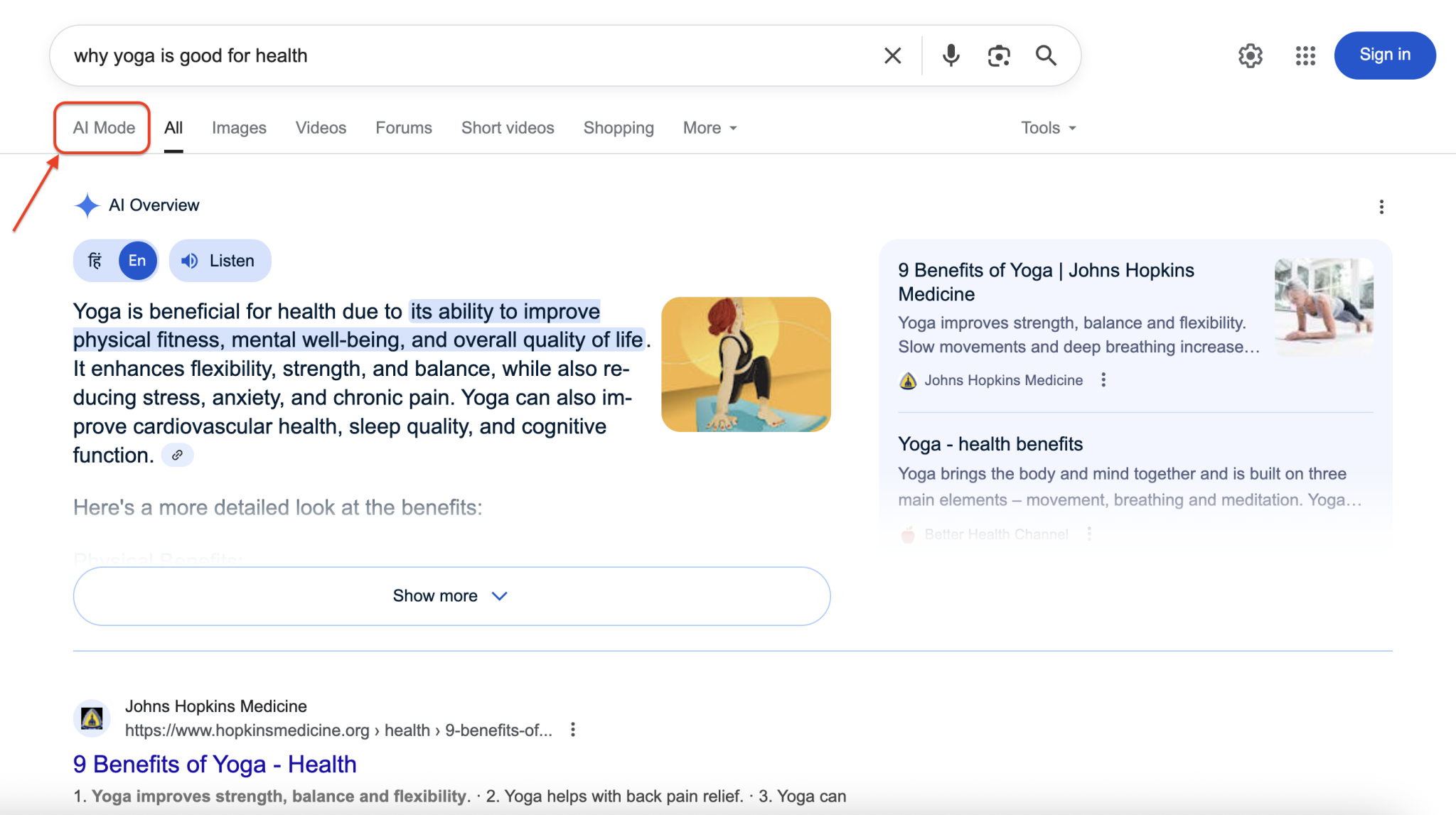
点击 AI 模式会展开完整的对话界面,包含详细回答与来源引用。我们的目标是以编程方式访问并提取这些丰富的结构化信息。
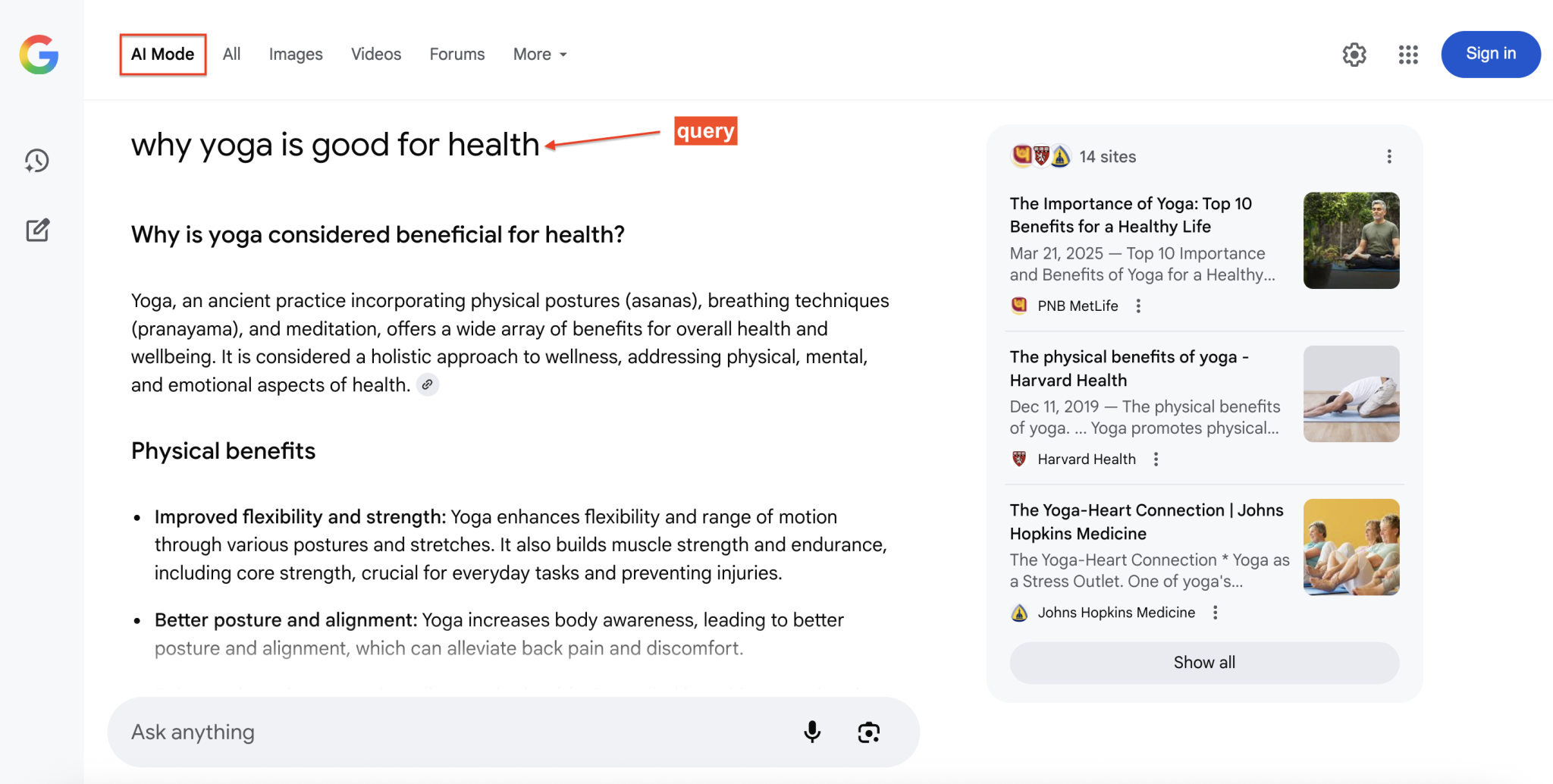
步骤 1——环境搭建与前提条件
安装最新版本的 Python,然后安装必要依赖。本教程以 Playwright 为例,在终端运行:
pip install playwright
playwright install该命令会安装 Playwright 并下载所需的浏览器二进制文件(用于自动化的浏览器可执行程序)。
步骤 2——导入依赖与初始化
导入抓取任务所需的基础库:
import asyncio
import urllib.parse
from playwright.async_api import async_playwright库功能说明:
- asyncio——支持异步编程,以提升性能与并发能力。
- urllib.parse——处理 URL 编码,确保查询参数对网页请求格式正确。
- playwright——提供浏览器自动化功能,像人类用户一样与 Google 交互。
步骤 3——函数结构与参数
定义主抓取函数,明确参数与返回值:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:函数参数:
- query——提交给 Google AI 模式的搜索词。
- output_path——保存结果的文件路径(默认为 “ai_response.txt”)。
- 返回布尔值,指示提取是否成功(True)或失败(False)。
步骤 4——构造 URL 并激活 AI 模式
构建能触发 Google AI 模式界面的搜索 URL:
url = f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"关键参数:
- urllib.parse.quote_plus(query)——安全编码搜索词,将空格转为“+”并转义特殊字符。
- udm=50——激活 Google AI 模式界面的关键参数。
步骤 5——浏览器配置与反检测
以更接近真实用户的方式启动浏览器,降低被检测风险:
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)配置说明:
- headless=False——调试阶段显示浏览器窗口(生产可设为 True)。
- -disable-blink-features=AutomationControlled——去除自动化识别信号。
- User-Agent——模拟 macOS 上的 Chrome,降低机器人检测概率。
这些反检测措施有助于让抓取行为更像普通用户而非脚本。
步骤 6——导航与动态内容加载
访问 URL 并等待动态内容加载完成:
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)加载策略说明:
- wait_until=”networkidle”——等待网络活动结束,表示页面基本加载完成。
- wait_for_timeout——为 AI 内容生成预留缓冲时间。
步骤 7——定位内容与提取 DOM
定位承载 Google AI 模式内容的 DOM 容器:
container = await page.query_selector('div[data-subtree="aimc"]')CSS 选择器 div[data-subtree=”aimc”] 用于定位 Google 的 AIMC(AI 模式容器)。
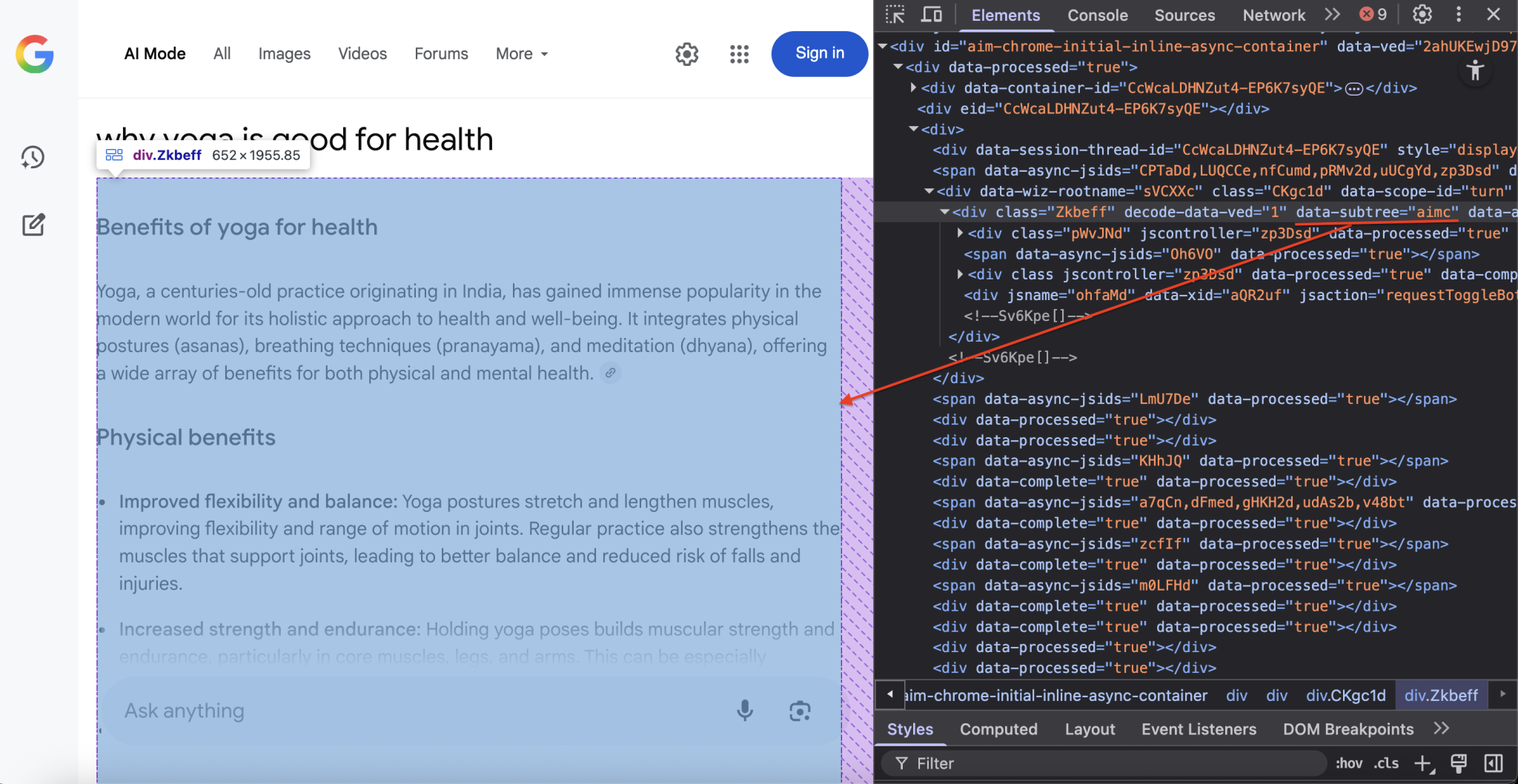
步骤 8——数据提取与存储
提取文本并保存到指定文件:
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f"Saved AI response to '{output_path}' ({len(text):,} characters)")
await browser.close()
return True
else:
print("AI Mode container found but contains no content.")
else:
print("No AI Mode content detected on page.")
await browser.close()
return False流程概览:
- 通过 DOM 查询确认 AI 容器存在。
- 用 inner_text() 抽取纯文本(不含 HTML)。
- 以 UTF-8 编码保存到目标文件。
- 关闭浏览器资源以防内存泄漏。
步骤 9——执行抓取函数
调用函数运行完整抓取流程:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))完整代码
下面是整合全部步骤的完整代码:
import asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query: str, output_path: str = "ai_response.txt"
) -> bool:
url = f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(
f"Saved AI response to '{output_path}' ({len(text):,} characters)"
)
await browser.close()
return True
else:
print("AI Mode container found but empty.")
else:
print("No AI Mode content found.")
await browser.close()
return False
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("why yoga is good for health"))脚本成功执行后,会生成包含提取 AI 回答的文本文件:

干得漂亮!你已成功抓取 Google AI 模式内容。
手动抓取的挑战与局限
手动抓取在规模化时会面临显著的运营挑战:
- 反机器人与验证码验证。Google 部署了复杂的检测机制识别自动化流量。请求次数稍多即可能触发验证码,从而阻断后续数据收集。
- 基础设施与维护复杂度。要在大规模下稳定运行,需要多种防封策略,如高质量住宅代理网络、User-Agent 轮换、浏览器指纹规避与智能请求分发。这会带来较高的技术与维护成本。
- 动态内容与布局变更。Google 频繁更新界面结构,可能让现有解析器一夜之间失效,要求立即修复以维持可用性。
- 解析复杂度。AI 模式回答包含嵌套结构、动态引用与多变的格式,需要复杂的解析逻辑。要在不同回答类型中维持准确性,需要大量测试与异常处理。
- 可扩展性限制。手动方法在批量处理、并发管理、跨地域与跨垂直的一致性能方面存在局限。
因此,许多组织更倾向于采用专业的解决方案来处理上述复杂性。接下来介绍 Bright Data 专为此场景打造的Google AI 模式抓取 API。
方法二——Google AI 模式抓取 API
Bright Data 的 Google AI 模式抓取 API 提供生产级方案,免去自建抓取基础设施的复杂性,同时具备企业级的可靠性与性能。该 API 可提取全面数据点,包括回答 HTML、回答文本、附加链接、引用来源等在内的 12+ 字段。
核心特性
- 自动化反封与代理管理。基于 Bright Data 覆盖 1.5 亿+ IP 的住宅代理网络与先进的反检测技术,规避验证码与 IP 封禁。
- 结构化数据输出。稳定一致的数据格式,支持 JSON、NDJSON、CSV 多种导出,便于集成。
- 企业级可扩展性。为高并发设计,能高效处理海量查询,并通过“按成功结果计费”实现可预测的成本扩展。
- 地域定制化。可指定目标国家,分析不同市场与人群下 AI 回答的差异。
- 零维护。我们团队持续监控并适配 Google 的变更。当 Google 更新 AI 模式界面或反爬策略时,系统自动升级,无需你的研发介入。
结果如何?以企业级可靠性、零基础设施负担,全面提取 Google AI 模式数据。
开始使用 Google AI 模式抓取 API
新用户需完成账号创建与 API Key 生成,然后选择偏好的集成方式。创建免费的 Bright Data 账号,并按4 个简单步骤生成 API 鉴权令牌。
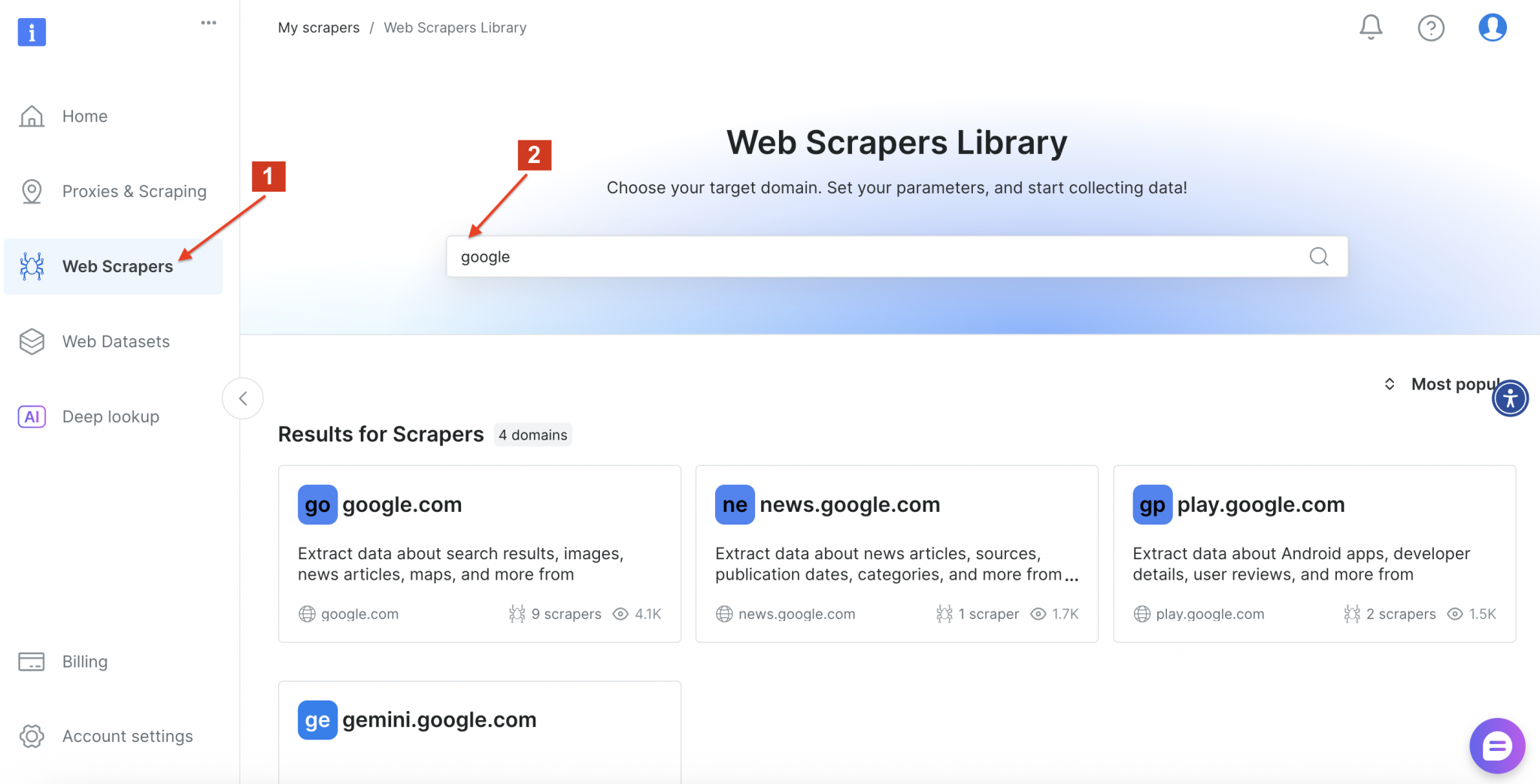
随后进入 Bright Data 的Web 抓取器库搜索“google”,找到可用的抓取器并点击“google.com”。
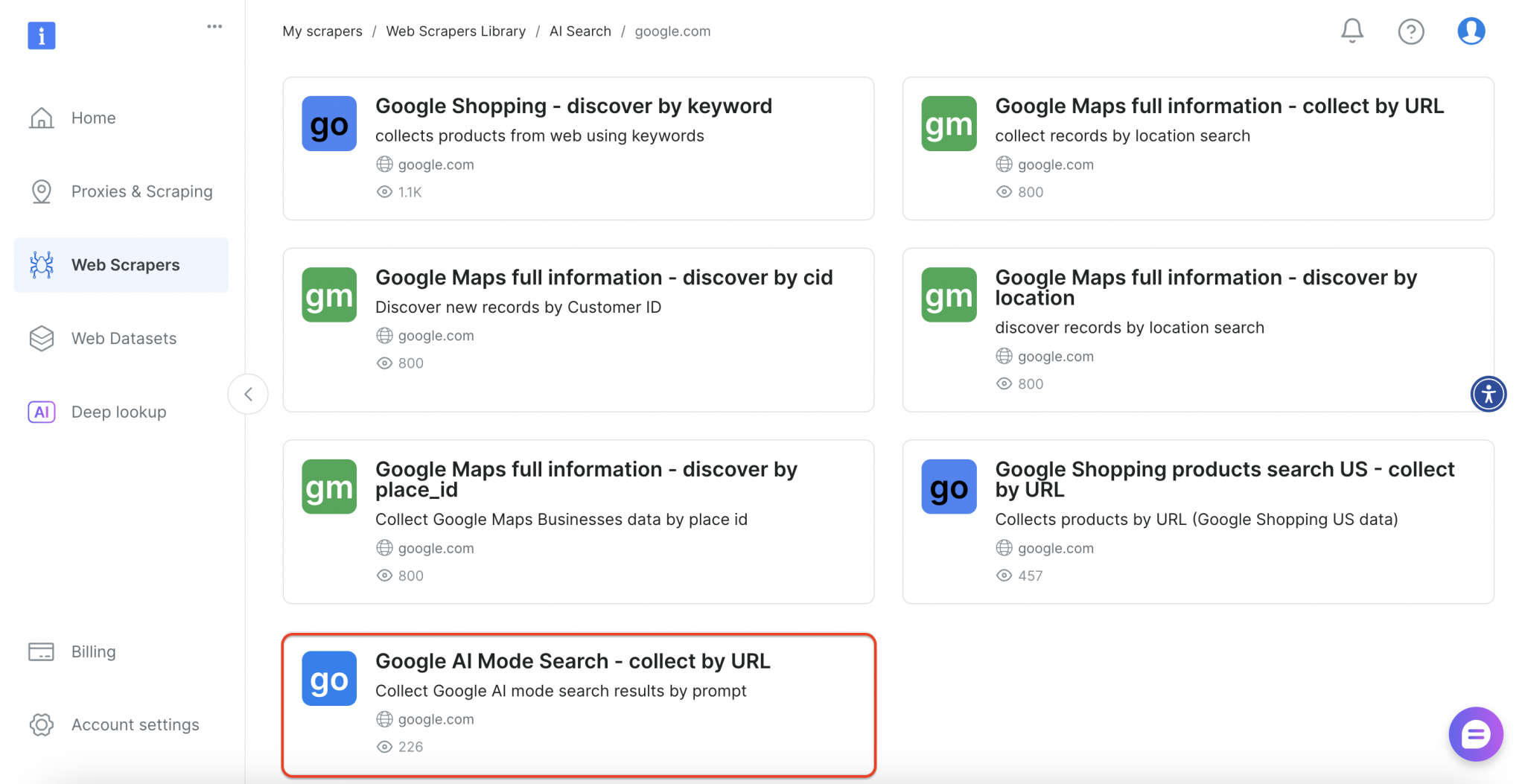
在界面中选择“Google AI Mode Search”。
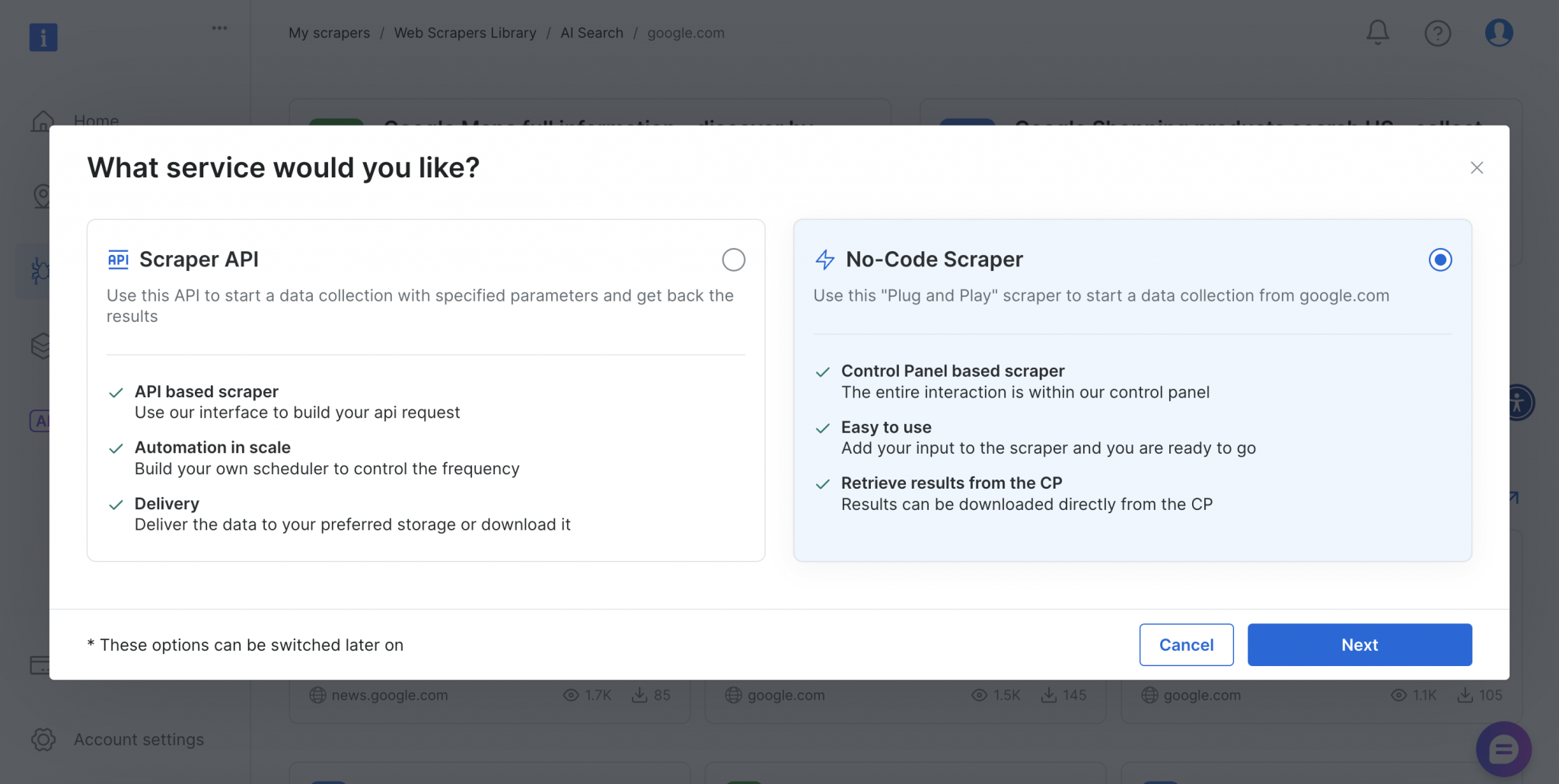
该抓取器同时支持零代码与基于 API 的实现方式,满足不同团队与技术需求。
下面分别介绍。
交互式抓取(零代码抓取器)
基于网页的操作界面适合不想写代码的用户。你可以在控制台直接输入查询或上传包含多条查询的 CSV 批量处理。平台自动执行并提供可下载的结果文件。
必填参数:
- URL——默认 https://google.com/aimode(保持不变)。
- Prompt——提交给 Google AI 分析的搜索问题。
- Country——地域定向(可选)。
其他设置:
- 交付设置——选择输出格式与交付方式。
- 自定义 schema——勾选要导出的数据字段。
- 批处理——通过 CSV 同时处理多条查询。
示例:使用“how meditation helps mental health”作为 Prompt,将目标国家设为“India”。点击“Start collecting”开始。
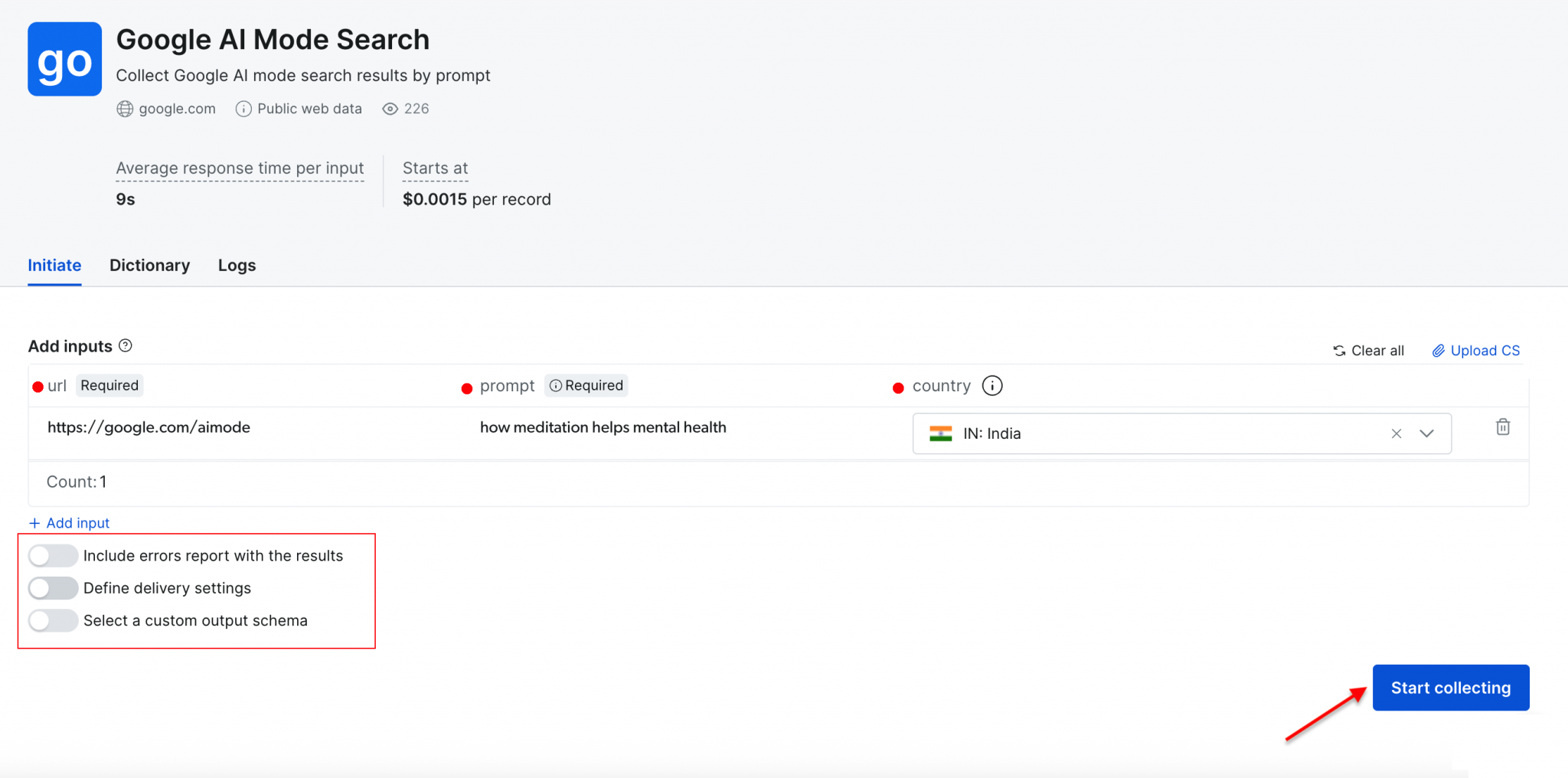
控制台会实时显示进度(Ready、Running),完成后即可按所选格式下载结果。
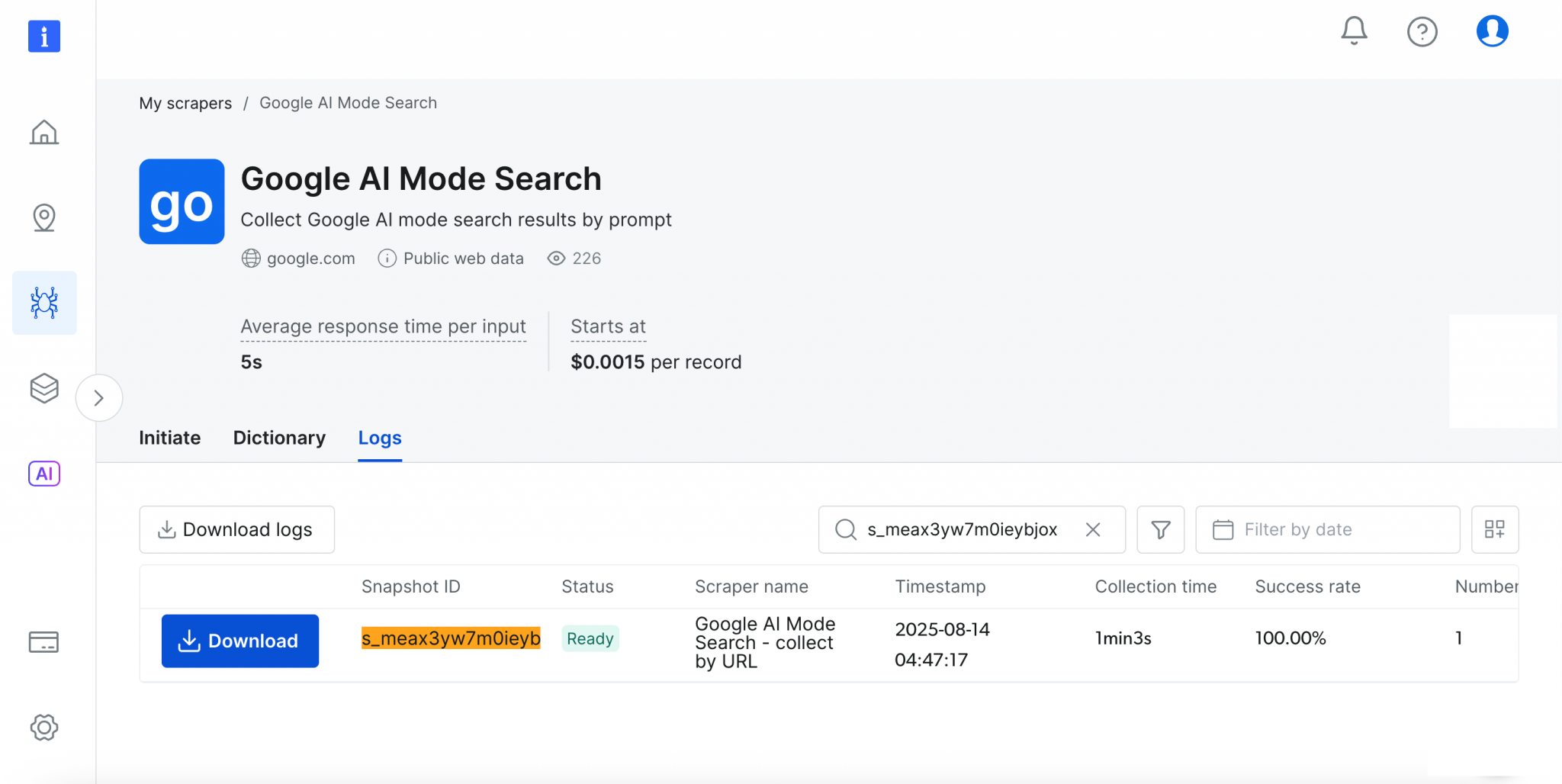
是不是很方便?
基于 API 的抓取(Scraper API)
通过 RESTful API 端点实现更强的灵活性与自动化。完善的请求构建与管理界面让你对抓取全流程实现精细控制:
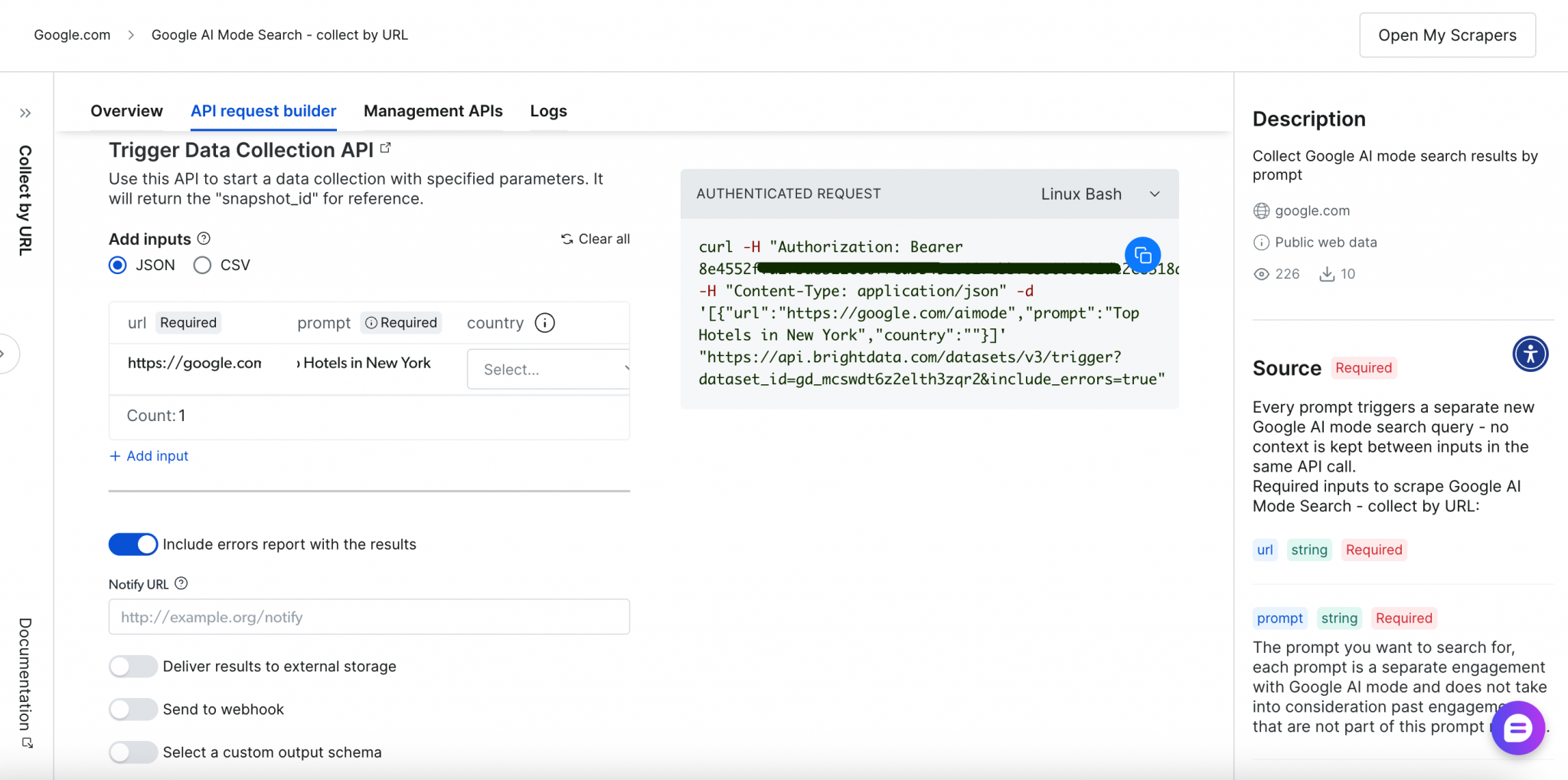
以下是 API 抓取流程:
步骤 1——触发数据采集
首先通过以下方式之一触发采集:
单条查询执行:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-H "Content-Type: application/json"
-d '[
{
"url": "https://google.com/aimode",
"prompt": "health tips for computer users",
"country": "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"CSV 批量上传:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"请求要点:
- 鉴权——在 Header 中携带 Bearer Token。
- Dataset ID——Google AI 模式抓取器的专属标识。
- 输入格式——JSON 数组或包含查询参数的 CSV。
- 错误处理——建议开启 include_errors 获取完整反馈。
你也可以选择通过 Webhook 的交付方式以自动处理结果。
步骤 2——监控任务进度
使用返回的Snapshot ID追踪进度:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"采集中返回“running”,完成后为“ready”。
步骤 3——下载结果
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"API 会为每个查询返回完整的结构化数据:
{
"url": "https://www.google.co.in/search?q=health+tips+for+computer+users&hl=en&udm=50&aep=11&...",
"prompt": "health tips for computer users",
"answer_html": "<html>...complete HTML response...</html>",
"answer_text": "Health tips for computer usersnnSpending extended periods in front of a computer can lead to various health concerns, including eye strain, musculoskeletal pain, and reduced physical activity...",
"links_attached": [
{
"url": "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text": null,
"position": 1
},
{
"url": "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text": null,
"position": 2
}
],
"citations": [
{
"url": "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title": null,
"description": "Ramsay Health Care",
"icon": "https://...icon-url...",
"domain": "https://www.ramsayhealth.co.uk",
"cited": false
},
{
"url": "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title": null,
"description": "Cleveland Clinic",
"icon": "https://...icon-url...",
"domain": "https://my.clevelandclinic.org",
"cited": false
}
],
"country": "IN",
"answer_text_markdown": "Health tips for computer users...",
"timestamp": "2026-08-07T05:02:56.887Z",
"input": {
"url": "https://google.com/aimode",
"prompt": "health tips for computer users",
"country": "IN"
}
}就是这么简单高效!
该 API 流程能无缝集成至任何应用或项目。Bright Data 的请求构建器还提供多语言代码示例,便于快速上手。
总结
我们介绍了两种路径:使用 Python + Playwright 的自助方案,以及 Bright Data 的即用型 Google AI 模式抓取 API。
在算法与界面频繁变化的搜索环境中,拥有稳健、持续维护的抓取基础设施至关重要。通过 API,你无需反复维护解析逻辑或处理 IP 限制,可把精力完全放在分析 Google 搜索结果中的 AI 洞察,从数据中获取最大价值。
下一步行动
- 扩展你的 Google 数据采集。既然已经在使用 Google AI 模式,建议进一步探索更多 Google 数据来源。我们还提供关于抓取 Google AI Overviews的完整指南。你也可以使用面向 Google 新闻、地图、搜索、趋势、评论、酒店、视频 与 航班 的专项能力。
- 零风险试用。所有主力产品均提供免费试用,我们还为首笔充值提供最高 $500 的配比赠金。便于在承诺前充分体验更广功能。
- 用集成方案扩展规模。随着需求增长,考虑使用 Web MCP 服务器,让 AI 应用无需为每个站点单独开发即可直连网页数据。立即开启,享受每月 5,000 次请求的免费计划!
- 随时升级为企业级基础设施。许多团队从个人/小项目起步,随后需要更强的基础设施以支持更大规模。我们的完整平台能在你准备扩展时提供底层能力。
不确定下一步?联系我们,我们会为你制定路径。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。