
在本文中,您将了解以下内容:
- 什么是 Vertex AI 管道?
- 集成 Bright Data SERP API 实现事实核查(及更多应用场景)的技术原理。
- 如何使用 Bright Data SERP API 在 Vertex AI 构建事实核查管道,以实时检索网络搜索上下文。
现在就来一探究竟吧!
什么是 Vertex AI 管道?
Vertex AI 管道是 Google Cloud 的一项全托管服务,专为端到端机器学习工作流程提供自动化编排与复现能力。
这项服务可将复杂的机器学习流程(如数据预处理、训练与部署)解构为一系列模块化组件,支持在无服务器环境中实现版本化追踪与自动化运行。
简而言之,Vertex AI 管道通过简化机器学习操作(MLOp)的生命周期,让可复现、可扩展的机器学习系统构建变得高效便捷。
在 Vertex AI 中构建事实核查管道:原因与方法
大语言模型(LLM)虽具备强大能力,但其知识库存在静态局限性。以 2024 年的训练模型为例,其无法感知最新的股市波动、体育赛事结果等动态信息。 这将导致生成“信息过时”或“事实幻觉”的回复内容。
为解决此问题,可以通过实时网络数据构建一个为 LLM 提供“对接依据”的系统。在 LLM 生成回复前,可通过注入外部实时信息确保输出基于最新事实依据。这正是检索增强生成技术(RAG)的核心价值所在!
当前,Gemini 虽提供官方搜索对接工具,用于将 Gemini 模型与 Google 搜索连接起来。但该工具尚未达到生产就绪状态,存在扩展性限制,且不支持数据源的完全管控。具体应用案例可参阅我们的 GEO/SEO 内容优化智能体方案。
更专业灵活的替代方案是 Bright Data SERP API。该 API 支持通过编程方式在搜索引擎执行搜索查询,并获取完整的搜索结果页内容。这意味着您将获得可集成至 LLM 工作流程的新鲜、可验证的内容来源。欢迎查阅技术文档探索完整功能特性。
例如,您可将该 SERP API 集成至 Vertex AI 管道,以构建事实核查管道:其中包括三个步骤:
- 查询提取:LLM 解析输入文本并识别核心的事实主张,将其转化为 Google 上的可搜索查询。
- 网络搜索上下文获取:该组件接收查询并通过 Bright Data SERP API 获取实时搜索结果。
- 事实核查:最后的 LLM 步骤将结合原始文本与搜索上下文生成核查报告。
注:这仅是 SERP API 在数据/机器学习管道中的典型应用场景之一。
如何将 Bright Data 用于网络搜索的 SERP API 与 Vertex AI 管道集成
本节将逐步演示在 Vertex AI 管道中构建事实核查管道的完整流程。这将依赖于 Bright Data SERP API,以便获取实时网络搜索上下文。
请注意,事实核查仅是该 SERP API 在 Vertex AI 管道节点中的应用场景之一(其他包括新闻发现、内容摘要、趋势分析及研究辅助等)。因此,您可基于此基础架构快速适配多种业务场景。
请按照以下步骤进行操作!
环境准备
进行本阶段实践前,请确保以下条件已准备就绪:
- 有效的 Google Cloud 控制台账户。
- 配备有效 API 密钥的 Bright Data 账户(建议具备管理员权限)。
请参照 Bright Data 官方指南了解如何获取 API 密钥。妥善保管该密钥,后续步骤中将很快用到。
步骤 #1:创建并配置新的 Google Cloud 项目
登录 Google Cloud 控制台创建新项目。此外,确保已启用计费功能(免费试用版亦可)。
在本示例中, Google Cloud 项目命名为 “Bright Data SERP API 管道”,并将项目 ID 设置为 bright-data-pipeline:
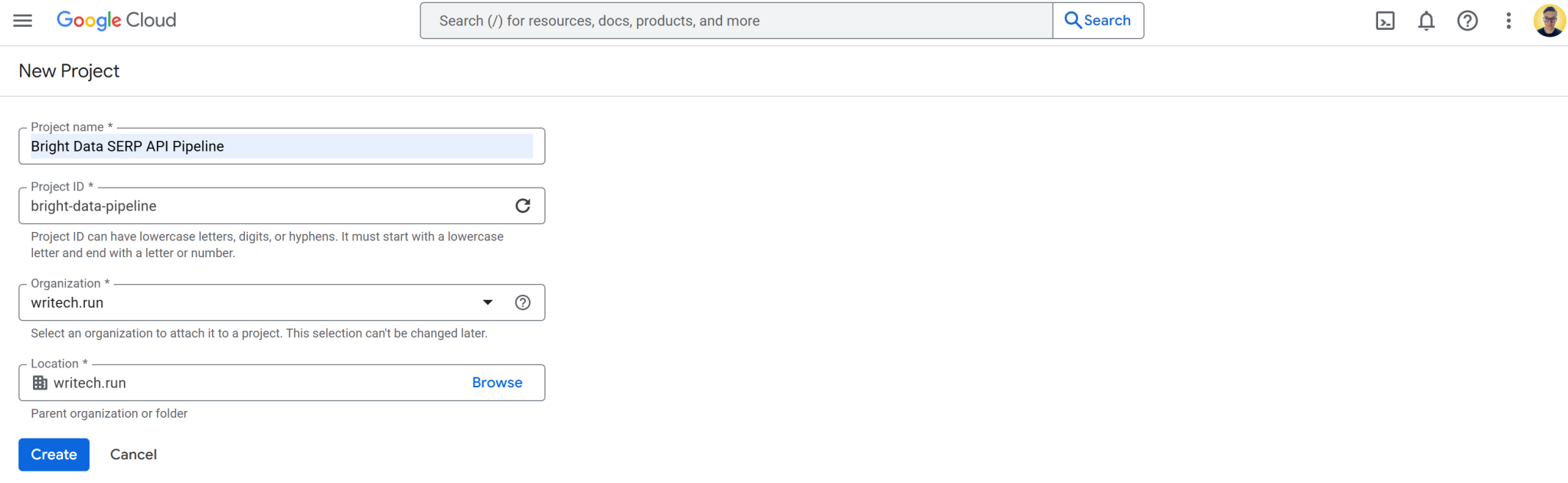
项目创建完成后,选择该项目即可开始工作。预期界面显示视图如下:
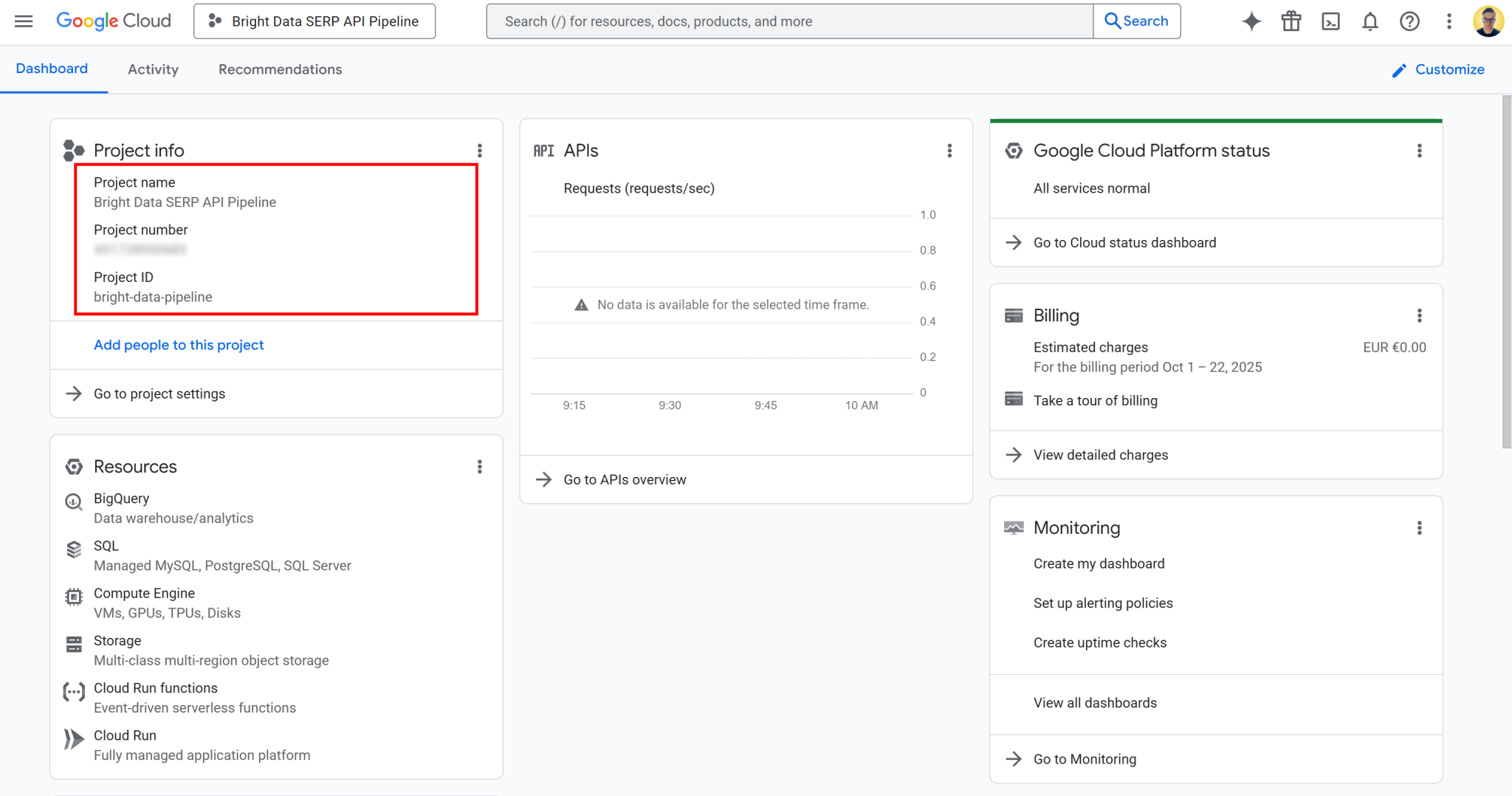
在此页面获取项目名称、项目编号与项目 ID。教程的后续内容中将使用项目编号与 ID,请妥善保存。
现在,您的 Google Cloud 项目已经准备就绪,下一步是激活所需 API。在搜索栏输入 “API 和服务”,进入页面后点击“启用 API 和服务”按钮:

搜索并启用以下 API:
这两项 API 是在 Vertex AI 工作台中进行 Vertex AI 使用与开发的基础前提。
注:管道同时依赖以下通常默认启用的 API 服务。如果出现问题,请验证下列功能是否也已启用:
- “云资源管理器 API”
- “云存储 API”
- “服务使用 API”
- “计算引擎 API”
- “Gemini 用于 Google Cloud API”
- “云日志 API”
如果其中任何功能被禁用,请手动启动后继续操作。
完成!现在您已成功创建 Google Cloud 项目。
步骤 #2:配置云存储桶
要运行 Vertex AI 管道,需预先配置云存储桶。这是由于 Vertex AI 需要存储管道运行过程中产生的各类管道工作产物,包括中间数据、模型文件、日志及元数据等。简而言之,已配置的存储桶将作为数据工作区,管道组件可在此读写数据。
要创建存储桶,请在 Google Cloud 控制台中搜索“云存储”。打开首条结果,在左侧菜单中选择“存储桶”,然后点击“创建”按钮:
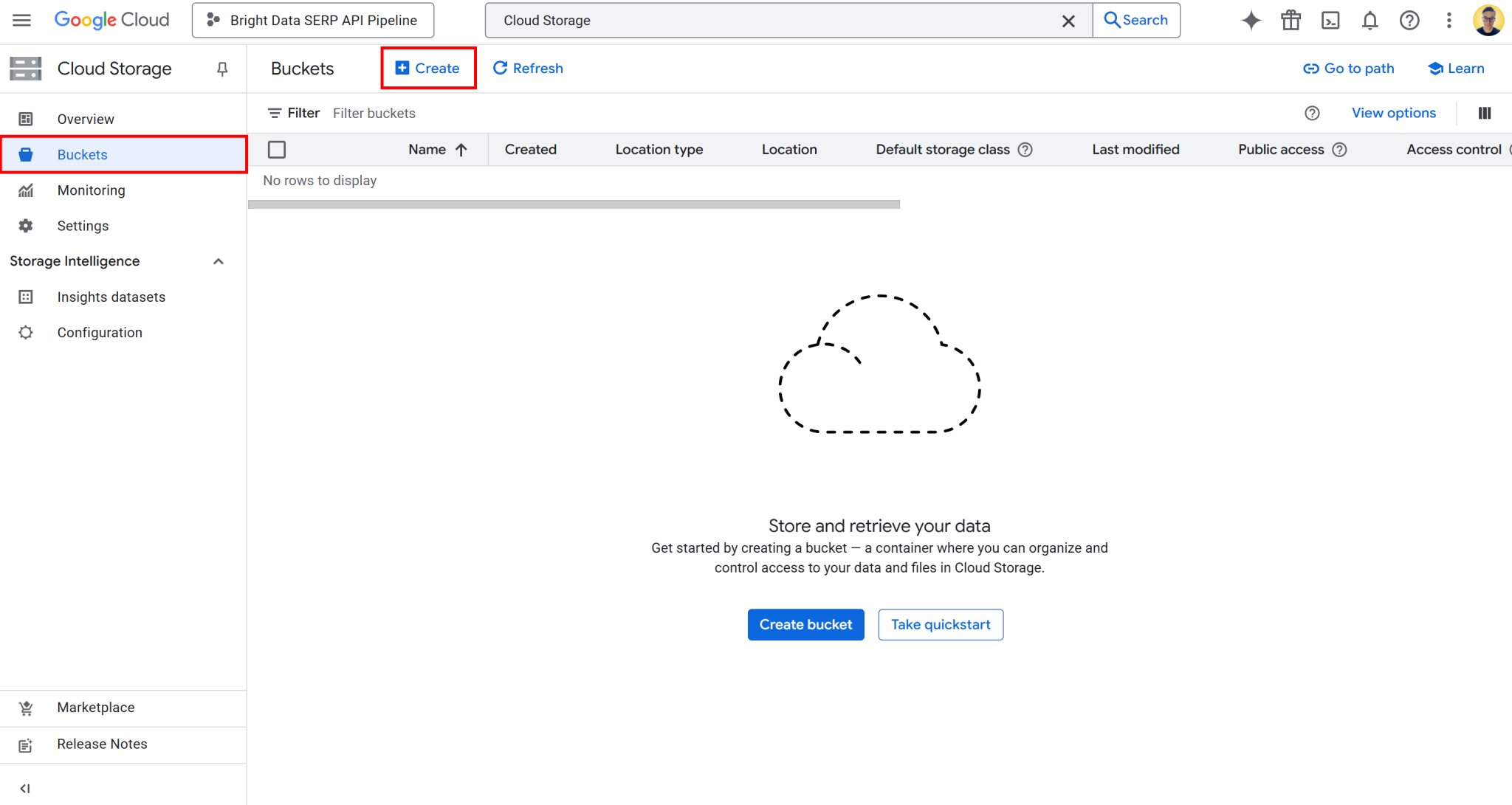
在存储桶创建表单中需完成以下配置:
- 设置全局唯一名称,例如:
bright-data-pipeline-artifacts。 - 选择位置类型和区域。建议选择 “us(美国多个地区)”选项以简化配置。
创建成功后,请记录存储桶名称,后续管道配置中将用到。预期界面显示视图如下:
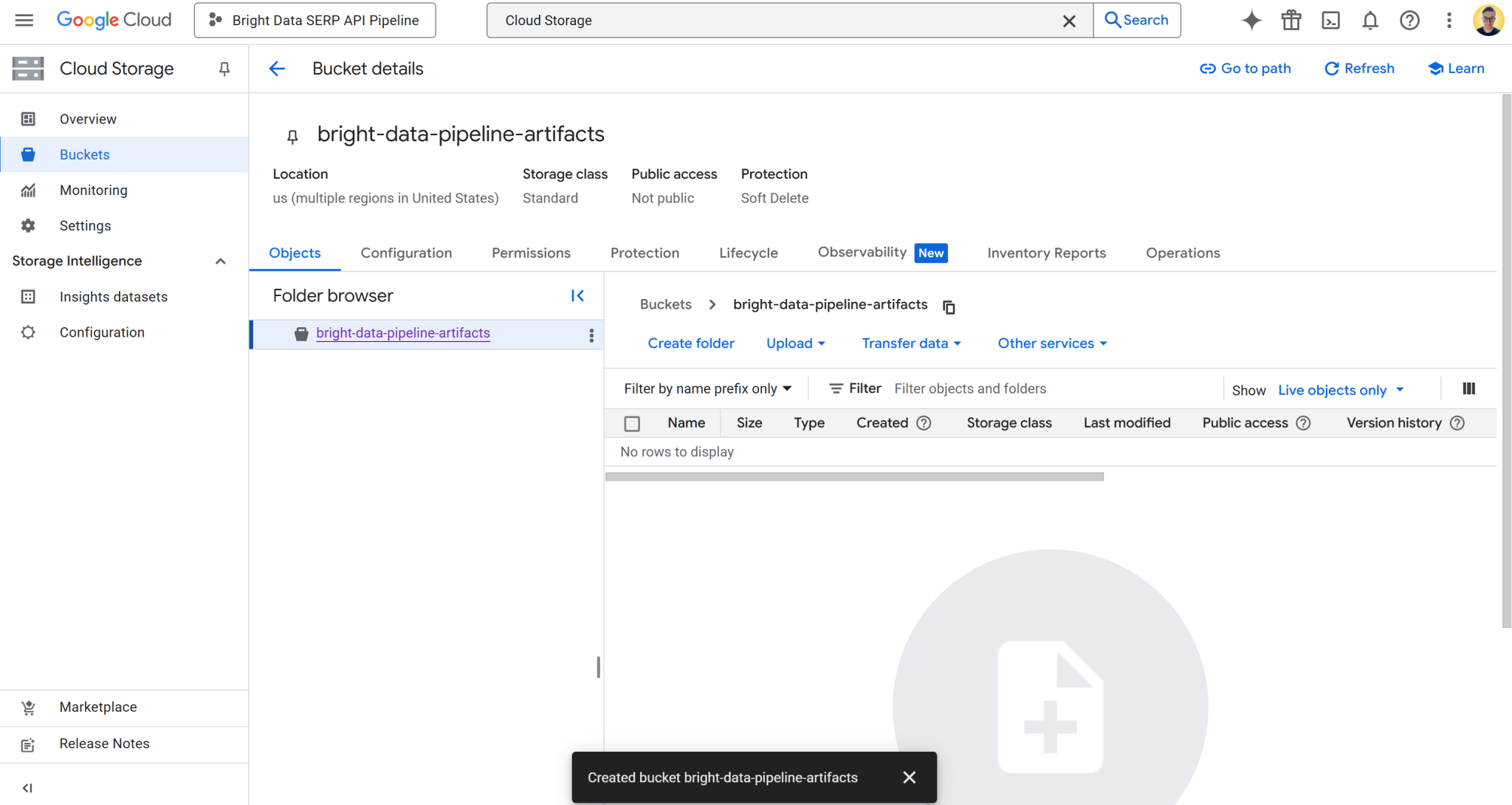
本示例存储桶名称:
bright-data-pipeline-artifacts 对应存储桶 URI:
gs://bright-data-pipeline-artifacts由于您选择的是 “us” 多个地区,因此可通过任意支持的 us-* 地区访问该存储桶。其中包括 us-central1、us-east1、……us-west1 等。 建议设置为 us-central1。
现在,需要为 Vertex AI 授予存储桶数据读写权限。为此,请点击存储桶名称打开其详细信息页面,然后转到“权限”选项卡:
点击“授予权限”按钮,添加新的权限规则,如下所示:
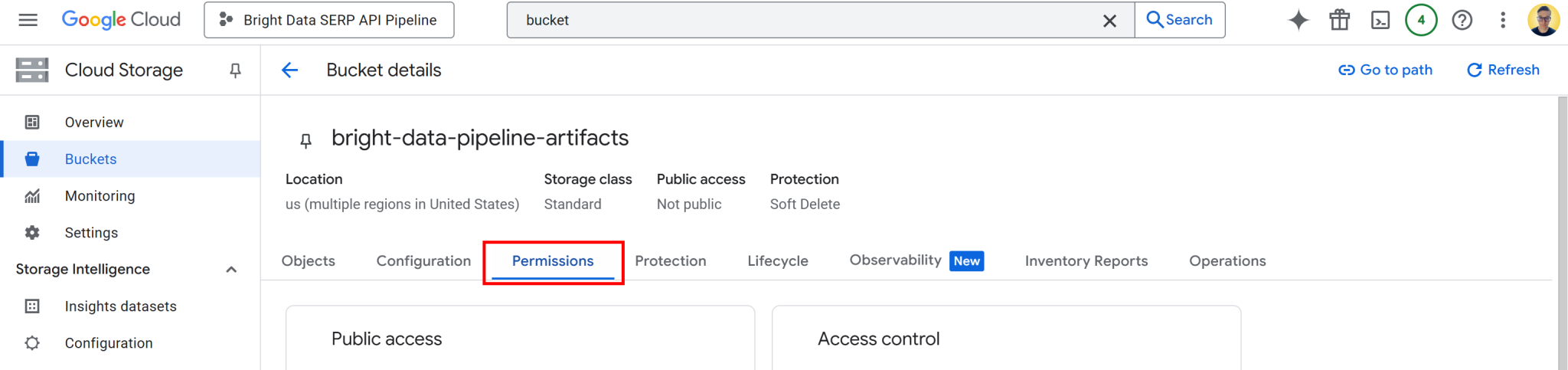
- 主体:
<YOUR_GC_PROJECT_NUMBER>[email protected] - 职能:
存储管理员
(重要提示:生产环境应遵循分配最低权限原则。在此设置中,使用完整“存储管理员”权限仅用于简化配置。)
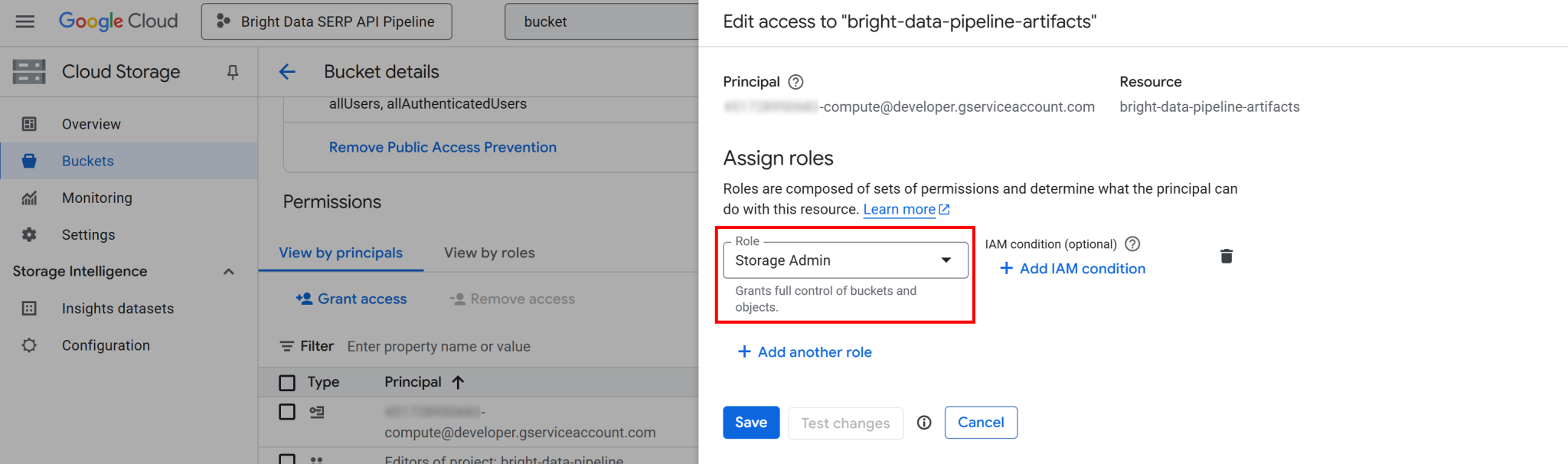
点击“保存”确认新的职能,该职能将授予项目计算引擎服务访问并管理云存储桶对象的完整权限。
如未配置此权限,Vertex AI 管道将无法在执行过程中读取或写入数据,从而导致 403 禁止访问错误。
google.api_core.exceptions.Forbidden: 403 GET https://storage.googleapis.com/storage/v1/b/bright-data-pipeline-artifacts?fields=name&prettyPrint=false: <YOUR_GC_PROJECT_NUMBER>[email protected] does not have storage.buckets.get access to the Google Cloud Storage bucket. Permission 'storage.buckets.get' denied on resource (or it may not exist).很棒!已配置 Google Cloud 存储桶。
步骤 #3:配置 IAM 权限
与云存储桶配置类似,需要为项目的计算引擎服务账户授予适当的 IAM 权限。
这些权限使 Vertex AI 能代表您创建和管理管道任务。缺少权限将导致管道无法在 Google Cloud 项目中启动或控制其运行。
如需设置,需要在 Google Cloud 控制台搜索 “IAM 与管理员”并打开该页面。
点击“授予权限”按钮,然后为计算引擎默认服务账户添加以下两项职能(即 <YOUR_GC_PROJECT_NUMBER>[email protected]):
- “服务账户用户”
- “Vertex AI 用户”
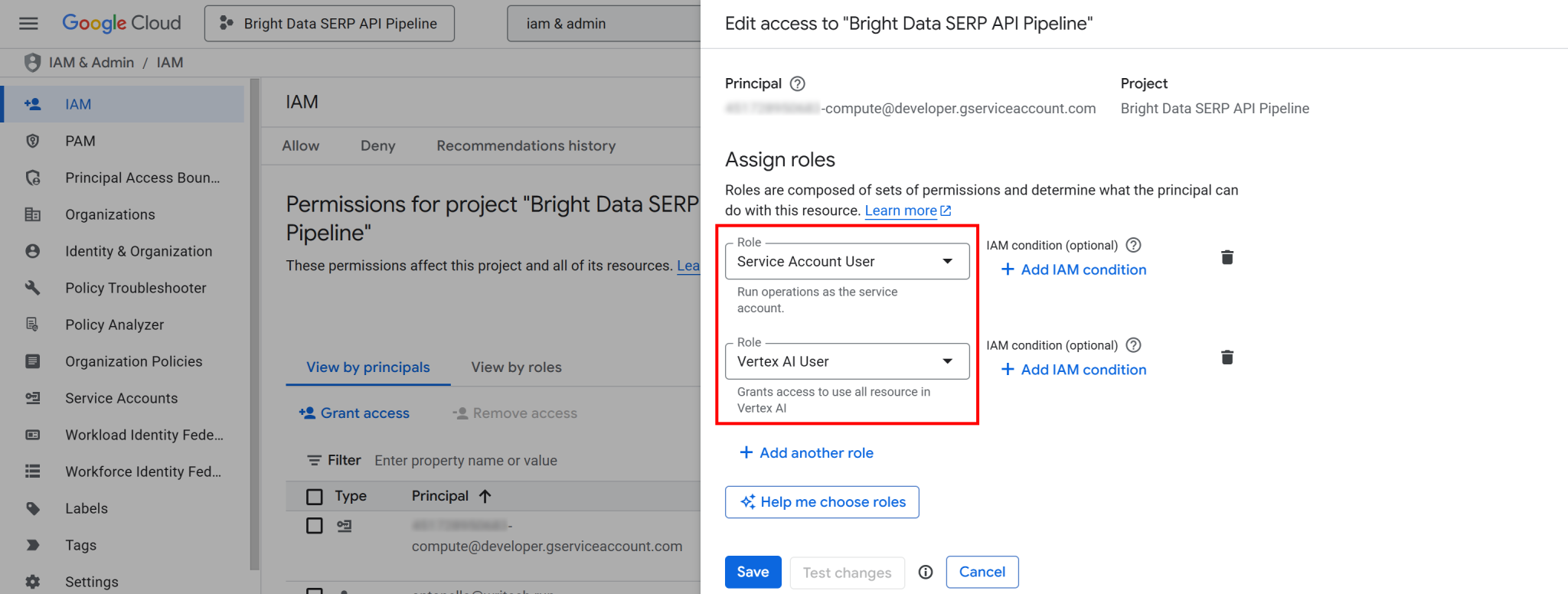
分配职能后,按“保存”按钮。此配置使 Vertex AI 管道能够调用项目计算资源运行托管工作负载。
其本质是向 Google Cloud 表明,Vertex AI 管道已获授权代表项目的计算服务账户执行操作。若未配置此类权限,尝试启动管道作业时将出现如下 403 禁止访问错误:
403 POST https://us-central1-aiplatform.googleapis.com/v1/projects/bright-data-pipeline/locations/us-central1/pipelineJobs?pipelineJobId=XXXXXXXXXXXXXXXXXXXXXXX&%24alt=json%3Benum-encoding%3Dint: Permission 'aiplatform.pipelineJobs.create' denied on resource '//aiplatform.googleapis.com/projects/bright-data-pipeline/locations/us-central1' (or it may not exist). [{'@type': 'type.googleapis.com/google.rpc.ErrorInfo', 'reason': 'IAM_PERMISSION_DENIED', 'domain': 'aiplatform.googleapis.com', 'metadata': {'resource': 'projects/bright-data-pipeline/locations/us-central1', 'permission': 'aiplatform.pipelineJobs.create'}}]配置完成! IAM 现已配置完毕,可随时执行 Vertex AI 管道。
步骤 #4:开始使用 Vertex AI 工作台
为简化开发,您将直接在云端构建 Vertex AI 管道,无需本地环境配置。
具体来说,您将使用 Vertex AI 工作台,它是 Google Cloud Vertex AI 平台中基于 JupyterLab 的完全托管开发环境。该环境支持从原型设计到模型部署的完整数据科学工作流程。
注:请确保已启用 “Notebooks API”,因为 Vertex AI 工作台需要该 API 方可运行。
要访问 Vertex AI 工作台,请在 Google Cloud 控制台中搜索 “Vertex AI 工作台”,然后打开页面。然后,在“实例”选项卡下点击“新建”,启动新的实例:
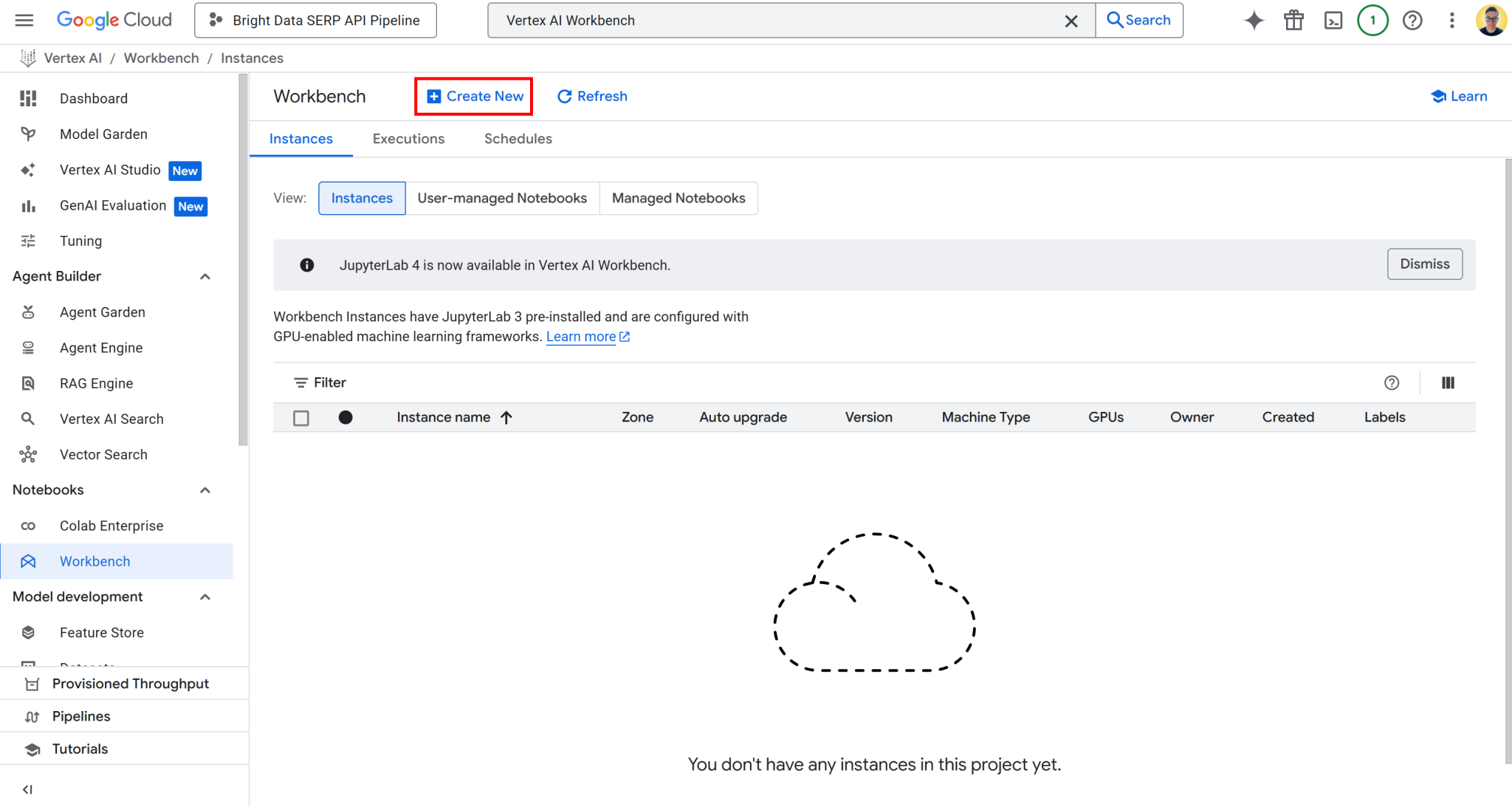
注:虽然 Vertex AI 工作台支持 Jupyter 4 新的实例,但所有环境当前默认使用 JupyterLab 3。该版本已预装最新的 NVIDIA GPU 和 Intel 程序库及驱动程序。因此,本教程推荐使用 JupyterLab 3。
在实例创建表单中,保留所有默认配置值,包括默认机器类型(应为 n1-standard-4)。该机器配置完全满足本指南需求。
点击“创建”,请注意,实例配置和启动需要几分钟时间。准备就绪后,您会在“实例”列表中看到一个新条目,附有标注“打开 JupyterLab” 的链接。点击该链接:
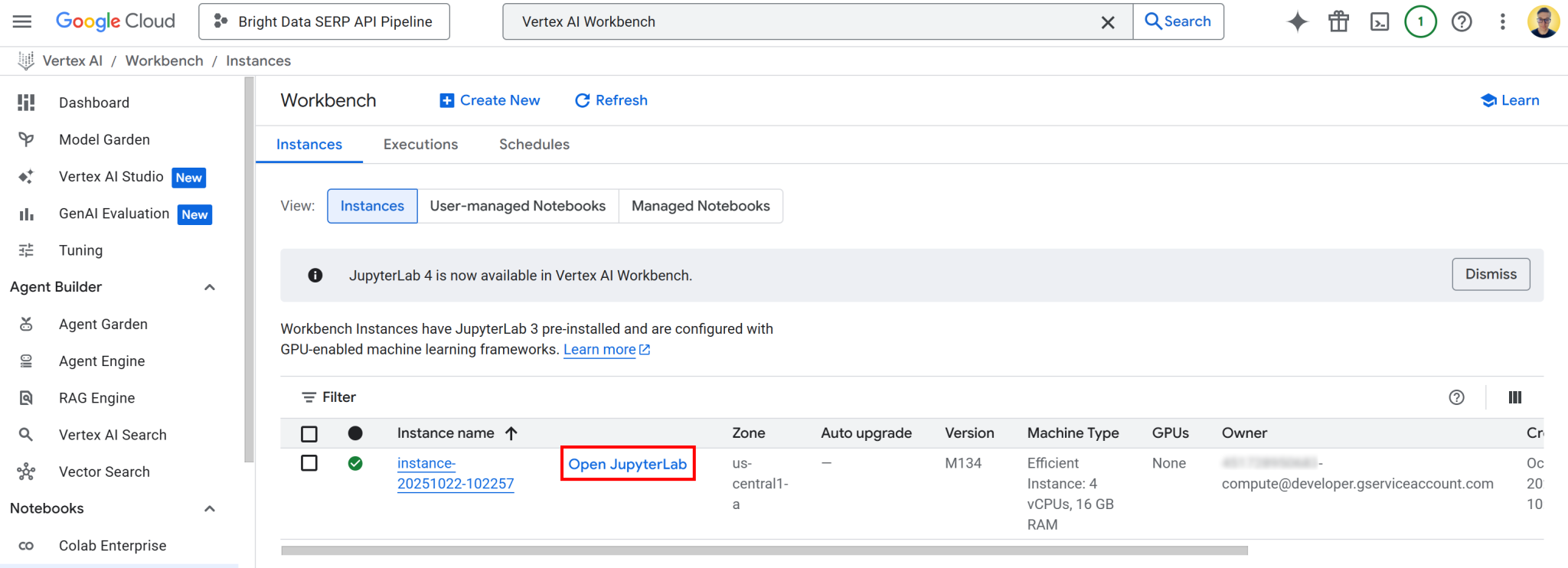
您将被重定向到完全托管在 Google Cloud 上的云端 JupyterLab 环境:
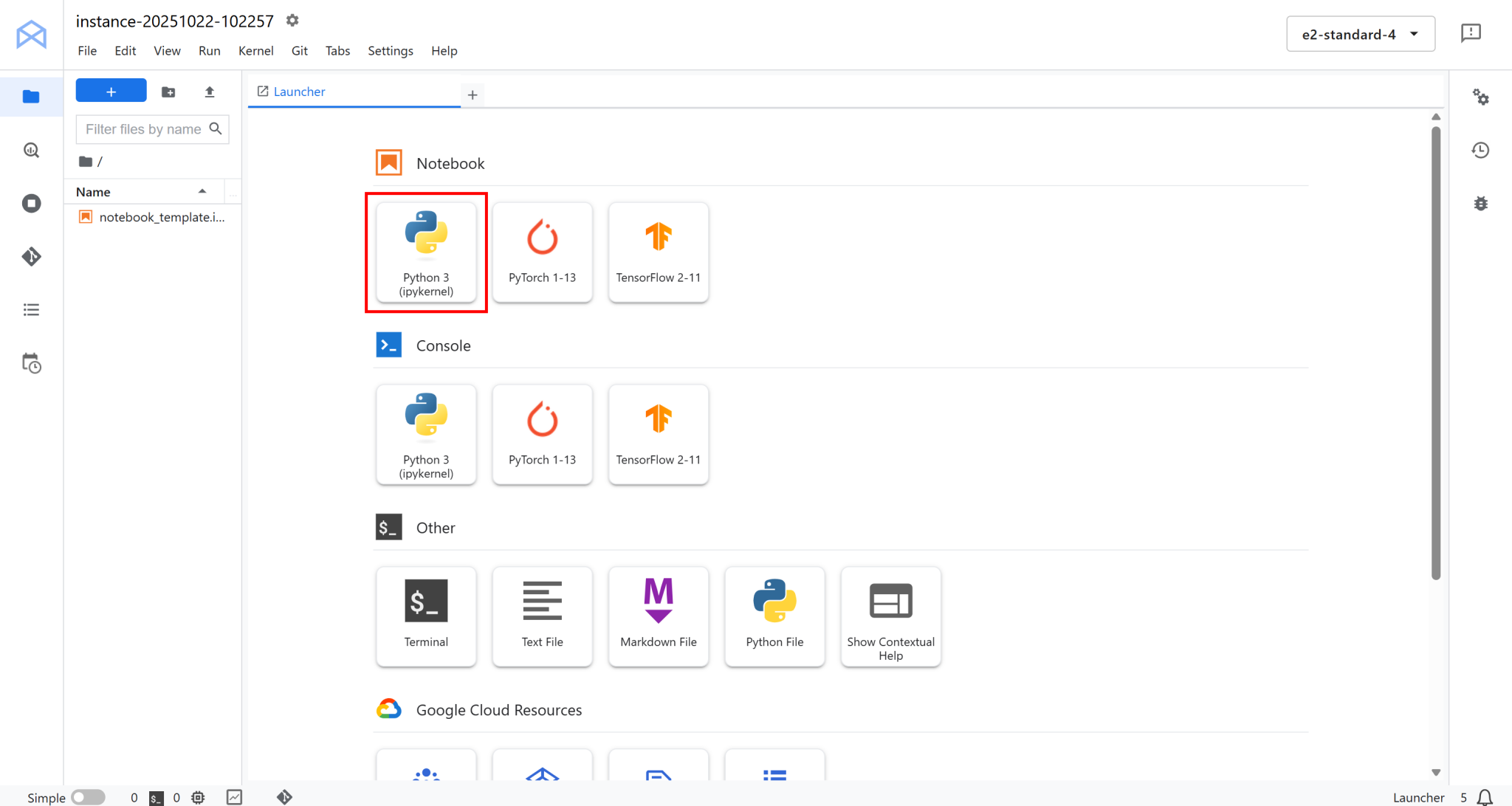
在此点击 “Notebook” 下的 “Python 3 (ipykernel)” 创建新笔记本。此笔记本将作为您的开发环境,用于编写和测试与 Bright Data 集成的 Vertex AI 管道:
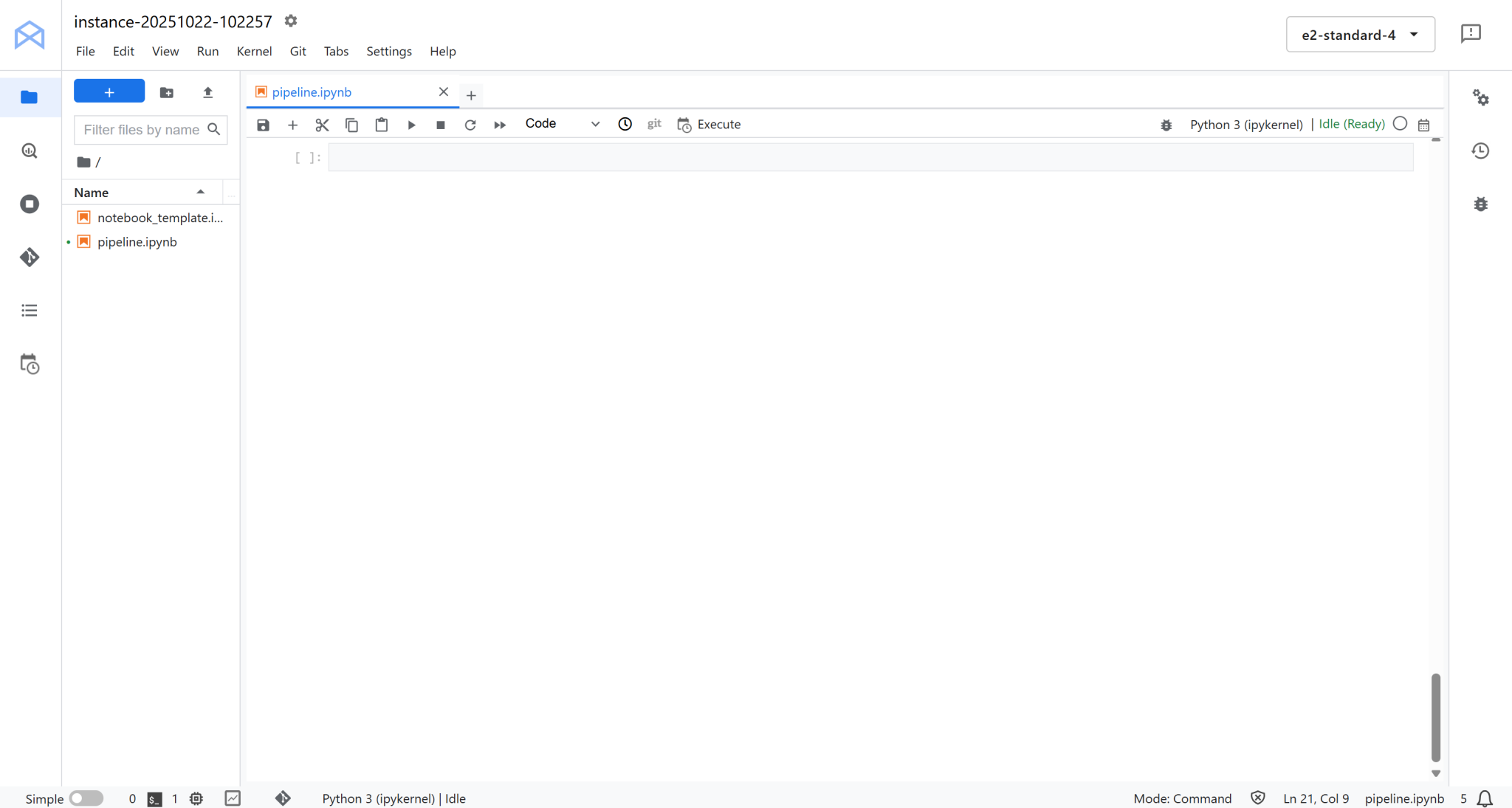
太棒了!您已准备好开始编码和构建 Vertex AI 数据管道逻辑。
步骤 #5:安装并初始化所需的 Python 库
在笔记本中,首先添加并运行以下代码单元,以安装本项目所需的所有 Python 库:
!pip install kfp google-cloud-aiplatform google-genai brightdata-sdk --quiet --upgrade此过程需要几分钟时间,请耐心等待环境配置完成。
各库的功能及必要性:
kfp:这是 Kubeflow Pipelines SDK,支持通过 Python 编程方式定义、编译和运行机器学习管道。它提供用于创建管道组件的装饰工具与类工具。google-cloud-aiplatform:用于 Python 的 Vertex AI SDK。提供与 Google Cloud Vertex AI 服务直接交互所需的功能,包括模型训练、端点部署和管道运行。google-genai:Google 的生成式 AI SDK,支持调用和编排 Gemini 和其他生成式模型(也包含在 Vertex AI 之中)。本管道包含 LLM 任务,该库至关重要(注意:Vertex AI SDK 现已弃用)。brightdata-sdk:Bright Data SDK,通过 Bright Data SERP API 或其他网络数据源,直接在管道中连接并获取实时数据。
安装所有库后,导入这些库并在专用代码单元中使用以下代码初始化 Vertex AI SDK:
import kfp
from kfp.dsl import component, pipeline, Input, Output, Artifact
from kfp import compiler
from google.cloud import aiplatform
from typing import List
# Replace with your project's secrets
PROJECT_ID = "<YOUR_GC_PROJECT_ID>"
REGION = "<YOUR_REGION>" # (e.g., "us-central1")
BUCKET_URI = "<YOUR_BUCKET_URI>" # (e.g., "gs://bright-data-pipeline-artifacts")
# Initialize the Vertex AI SDK
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=BUCKET_URI)aiplatform.init() 函数用于配置 Python 环境,以便与 Vertex AI 通信。通过设置项目、区域和暂存存储桶,确保所有后续 Vertex AI 操作(如创建管道、训练作业或部署模型)自动使用正确的上下文。
简而言之,此行代码用于建立笔记本会话与 Google Cloud 项目的连接,并指定 Vertex AI 管道工作产物和临时数据的存储位置。非常好!
步骤 #6:定义查询提取组件
请记住,Vertex AI 管道由组件构建而成,而每个组件即是执行特定任务的 Python 函数。如前所述,本管道包含三个核心组件。
让我们从第一个组件 extract_queries 开始!
extract_queries 组件:
- 接收待核查文本作为输入。
- 使用 Gemini 模型(通过
google-genai库)生成 Google 可搜索的查询列表,以帮助验证该文本中的事实主张。 - 以 Python 字符串数组形式返回列表(
List[str])
具体实现如下:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def extract_queries(
input_text: str,
project: str,
location: str,
) -> List[str]:
from google import genai
from google.genai.types import GenerateContentConfig, HttpOptions
from typing import List
import json
# Initialize the Google Gen AI SDK with Vertex integration
client = genai.Client(
vertexai=True,
project=project,
location=location,
http_options=HttpOptions(api_version="v1")
)
# The output schema, which is an array of strings
response_schema = {
"type": "ARRAY",
"items": {
"type": "STRING"
}
}
# The query extractor prompt
prompt = f"""
You are a professional fact-checker. Your job is to read the following text and extract
a list of specific, google-able search queries that would be needed
to verify the main factual claims.
Return *only* a Python list of strings, and nothing else.
Example:
Input: "The Eiffel Tower, built in 1889 by Gustave Eiffel, is 300 meters tall."
Output: ["when was the eiffel tower built", "who built the eiffel tower", "how tall is the eiffel tower"]
Here is the text to fact-check:
---
"{input_text}"
---
"""
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
# Force the model to return a JSON array of strings
response_mime_type="application/json",
response_schema=response_schema,
),
)
# The 'response.text' will reliably contains a JSON string conforming to the schema (e.g., '["query_1", ..., "query_n"]')
query_list: List[str] = json.loads(response.text.strip())
return query_list请记住,KFP 组件必须是独立的。这意味着所有导入都必须在组件函数内部声明,而非全局声明。
请注意,vertexai=True, project=project, location=location 参数,均位于 genai.Client() 中,是连接 google-genai 客户端和 Vertex AI 环境所必需的。这些参数可确保配置的模型在与管道相同的区域和项目中运行。
至于模型选择,建议使用 Gemini 2.5 Flash,轻量快速。总之,如需更高精度,可切换其他 Gemini 模型。
第一个组件完成,继续构建剩余两个组件!
步骤 #7:创建 SERP API 驱动的网络搜索上下文检索器组件
现在,生成 Google 可搜索查询列表后,即可通过网络搜索获取上下文信息。要做到这一点,请使用 Bright Data 的 SERP API,可以让您以结构化和可扩展的方式对搜索结果(默认情况下为 Google)进行程序化抓取。
从 Python 访问 SERP API 最便捷的方法是通过官方开源的 Bright Data SDK。该库为您提供了调用 Bright Data 产品(包括 SERP API)的简易方法。更多详情请参见技术文档。
特别是 fetch_web_search_context 组件:
- 接收上一步生成的搜索查询列表。
- 使用 Bright Data SDK 为每次查询并行调用 SERP API。
- 检索搜索结果(默认情况下来自 Google)。
- 将所有结果保存为 JSON 文件,供管道中的其他组件使用。
专用笔记本代码单元中创建该组件:
@component(
base_image="python:3.10",
packages_to_install=["brightdata-sdk"],
)
def fetch_web_search_context(
queries: List[str],
api_key: str,
output_file: Output[Artifact],
):
"""
Takes a list of queries, searches each one using Bright Data SDK,
and writes all results as a JSON file artifact.
"""
from brightdata import bdclient
import json
# Initialize the Bright Data SDK client
client = bdclient(api_token=api_key)
# Call the SERP API on the input queries
results = client.search(
queries,
data_format="markdown"
)
# Write results to an artifact file
with open(output_file.path, "w") as f:
json.dump(results, f)请注意,SERP API 已配置并以 Markdown 格式返回内容,这种格式非常适合 LLM 采集。
此外,由于该组件输出规格可能较大,建议存储为工作产物文件。工作产物文件保存在 Google Cloud 存储桶中,使 Vertex AI 管道组件可以彼此高效传递数据,避免内存过载或超过数据传输限制。
部署完成!借助 Bright Data 强大的网络搜索功能,您已获得基于 Google 搜索的上下文内容,这些内容将作为下一个组件的输入,由 LLM 执行事实核查。
步骤 #8:实现事实核查组件
与查询提取组件类似,此步骤同样需要调用 LLM。但不同之处在于,本组件将利用前一步收集的网络搜索结果作为上下文证据,对原始输入文本进行事实核查。
本质上,这是运行基于 SERP 的 RAG 式工作流程,通过其中检索到的网络内容指导模型的验证过程。
在新笔记本代码单元中,定义 fact_check_with_web_search_context 组件,示例如下:
@component(
base_image="python:3.10",
packages_to_install=["google-genai"],
)
def fact_check_with_web_search_context(
input_text: str,
web_search_context_file: Input[Artifact],
project: str,
location: str,
) -> str:
import json
from google import genai
# Load the web search context from artifact
with open(web_search_context_file.path, "r") as f:
web_search_context = json.load(f)
client = genai.Client(
vertexai=True,
project=project,
location=location
)
prompt = f"""
You are an AI fact-checker. Compare the Original Text to the JSON Search Context
and produce a fact-check report in Markdown.
[Original Text]
"{input_text}"
[Web Search Context]
"{json.dumps(web_search_context)}"
"""
response = client.models.generate_content(
model="gemini-2.5-pro",
contents=prompt
)
return response.text此任务复杂度更高,需要基于多源证据进行推理。因此,建议使用性能更强大的模型,如 Gemini 2.5 Pro。
太棒了!现在您已经定义了构成 Vertex AI 管道的全部三个组件。
步骤 #9:定义并编译管道
将所有三个组件整合在完整的 Kubeflow 管道中。各组件按序执行,前一步骤的输出作为后续步骤的输入。
管道定义如下:
@pipeline(
name="bright-data-fact-checker-pipeline",
description="Fetches SERP context to fact-check a text document."
)
def fact_check_pipeline(
input_text: str,
bright_data_api_key: str,
project: str = PROJECT_ID,
location: str = REGION,
):
# Step 1: Extract Google-able queries from the input text to verify
step1 = extract_queries(
input_text=input_text,
project=project,
location=location
)
# Step 2: Fetch Bright Data SERP results on the search queries
step2 = fetch_web_search_context(
queries=step1.output,
bright_data_api_key=bright_data_api_key
)
# Step 3: Perform fact-check using the web search context retrieved earlier
step3 = fact_check_with_web_search_context(
input_text=input_text,
web_search_context_file=step2.outputs["output_file"],
project=project,
location=location
) 本质上讲,此函数将先前构建的三个组件进行串联。首先生成事实核查查询,然后使用 Bright Data SERP API 检索每个查询的搜索结果,最后运行 Gemini 模型,根据收集到的证据验证主张。
接下来,需要将管道编译为 Vertex AI 可执行的 JSON 规范:
compiler.Compiler().compile(
pipeline_func=fact_check_pipeline,
package_path="fact_check_pipeline.json"
)此命令将 Python 管道定义转换为 JSON 管道规范文件,文件名为 fact_check_pipeline.json。
该 JSON 文件是 Vertex AI 管道所信任的蓝图,用于了解如何协调工作流程。其中描述了每个组件、输入输出、依赖关系、容器镜像及执行顺序。
在 Vertex AI 中运行此 JSON 文件时,Google Cloud 将自动配置基础架构、按正确的顺序执行组件并处理步骤间的数据传递。管道配置完成!
步骤 #10:运行管道
假设您需要测试管道对明显错误陈述的核查能力:
“巴黎是德国的首都,该国使用日元作为法定货币。”
请在 Jupyter 笔记本中添加以下代码单元。该“添加”代码单元定义了启动管道的基本逻辑:
TEXT_TO_CHECK = """
Paris is the capital of Germany, which uses the yen as its currency.
"""
# Replace with your Bright Data API key
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
print("Starting the pipeline job...")
# Define the pipeline job
job = aiplatform.PipelineJob(
display_name="fact-check-pipeline-run",
template_path="fact_check_pipeline.json",
pipeline_root=BUCKET_URI,
parameter_values={
"input_text": TEXT_TO_CHECK,
"bright_data_api_key": BRIGHT_DATA_API_KEY
}
)
# Run the job
job.run()
print("\nJob submitted! You can view its progress in the Vertex AI UI.")此代码创建了新的 Vertex AI 管道任务,指定以下参数: 您先前编译的管道 JSON 文件(fact_check_pipeline.json),作为管道根目录的存储桶,以及本次特定运行所需的参数(即要验证的输入文本和 Bright Data API 密钥)。
运行此单元后,Vertex AI 将在云端自动编排整个管道。
安全提示:本示例为简化流程,将 Bright Data API 密钥直接硬编码在笔记本中,但这对生产环境并不安全。在实际部署中,应使用 Google Cloud 密钥管理器来存储和检索 API 密钥等敏感凭证,以避免意外暴露(例如在日志中)。
要运行管道,请选择所有代码单元并按下 Jupyter 笔记本中的 “▶” 按钮。您将在最后一个代码单元中得到以下输出结果:
这表明您的 Vertex AI 事实核查管道已成功运行。运行成功!
步骤 #11:监控管道执行情况
要查看管道任务状态,请访问项目 Google Cloud 控制器中的 Vertex AI 管道页面:
https://console.cloud.google.com/vertex-ai/pipelines?project={PROJECT_ID}因此,本示例具体 URL 为:
https://console.cloud.google.com/vertex-ai/pipelines?project=bright-data-pipeline将 URL 粘贴到浏览器中,将看到如下页面:
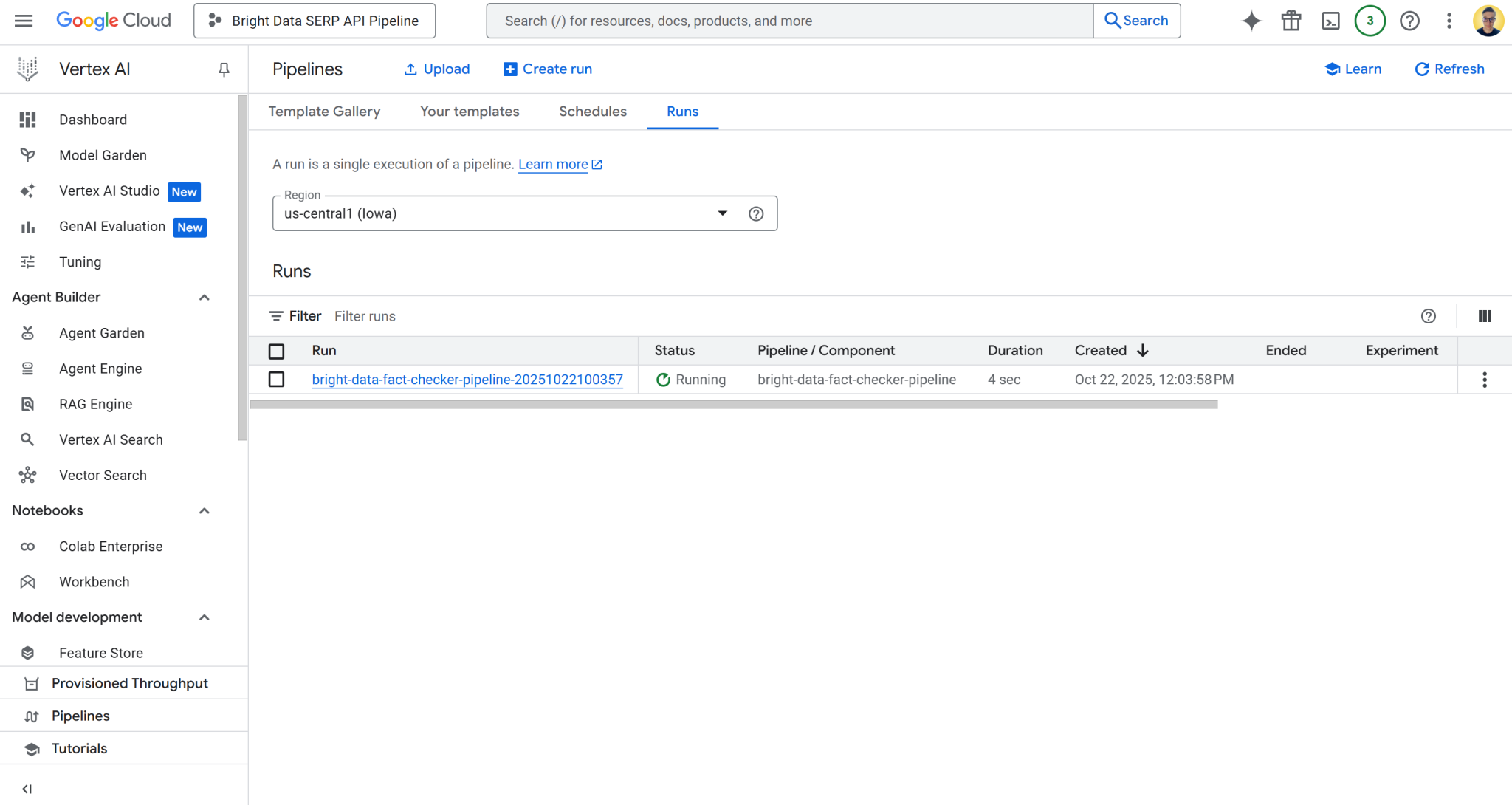
点击“运行”表格中的首条记录,打开管道任务执行页面:
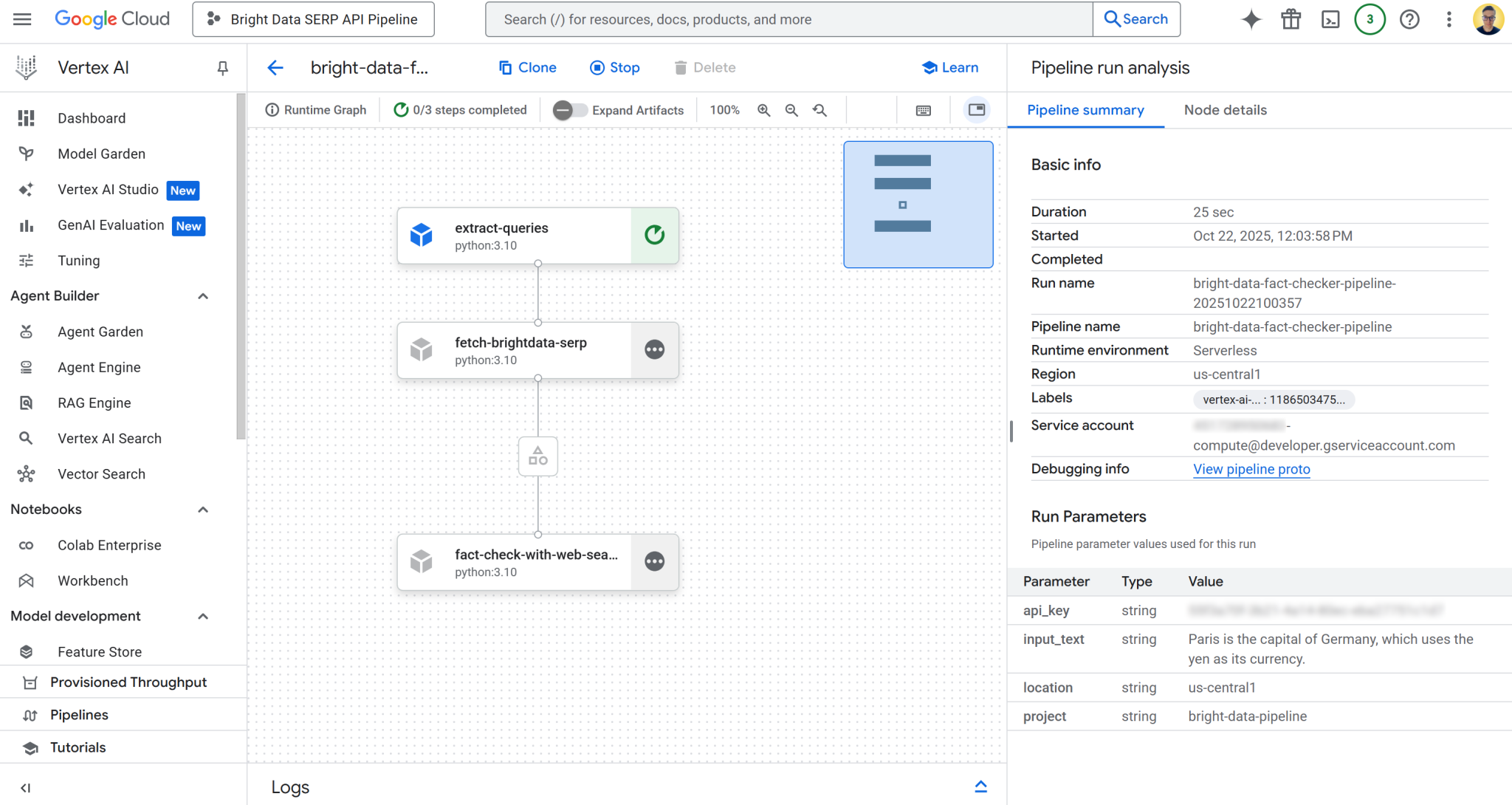
在此页面可直观查看管道组件结构。您还可以检查每个节点的状态,查看日志详情,并在管道执行过程中观察从起点到终点的数据流。
步骤 #12:查看输出结果
管道执行完成后,各节点均会显示绿色对勾标识,表示成功完成:
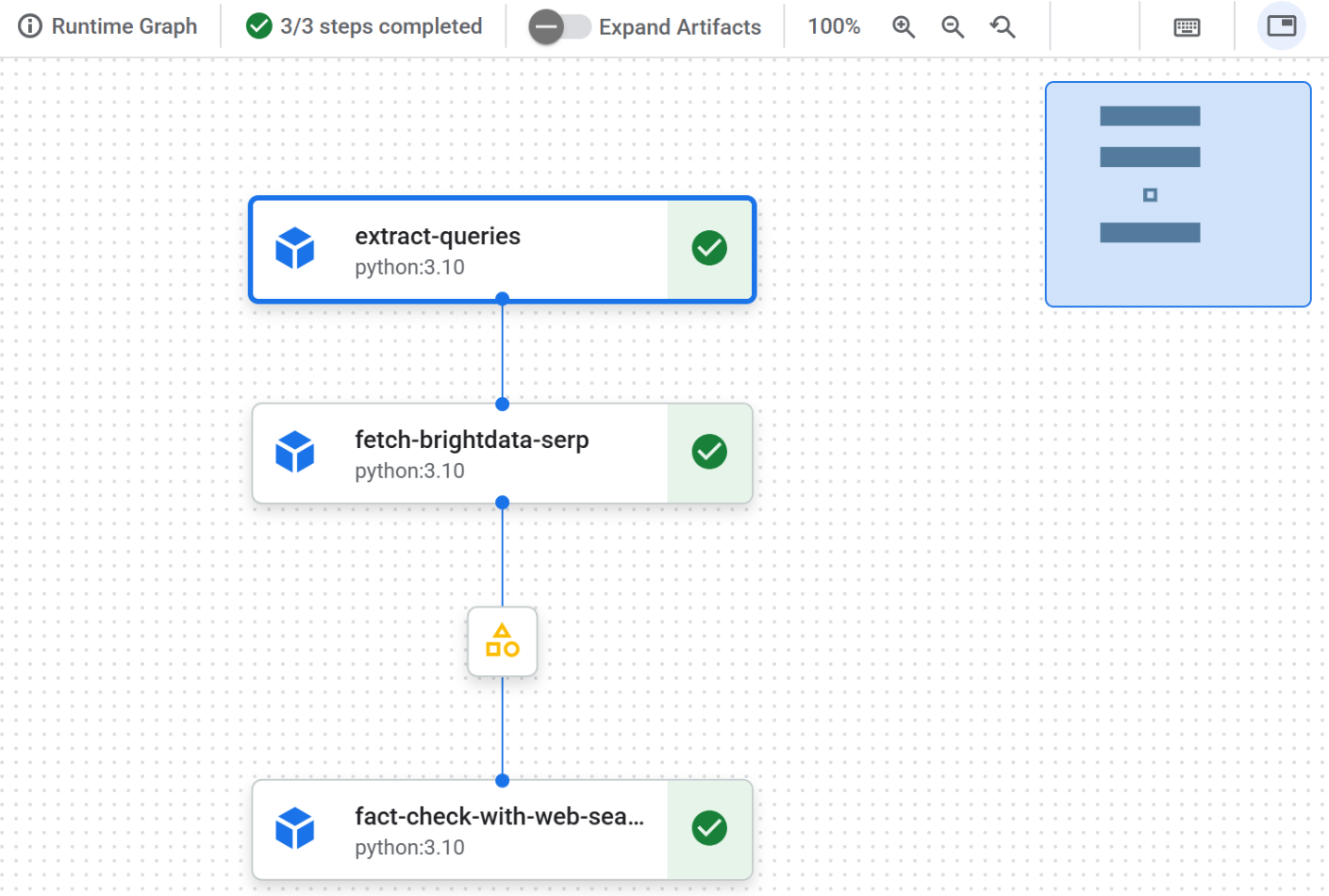
点击首个节点,查看从输入文本中提取的 Google 可搜索查询。本示例生成的查询包括:
“德国的首都是哪里”“德国使用什么货币”
这些查询能精准验证输入语句中的事实陈述:
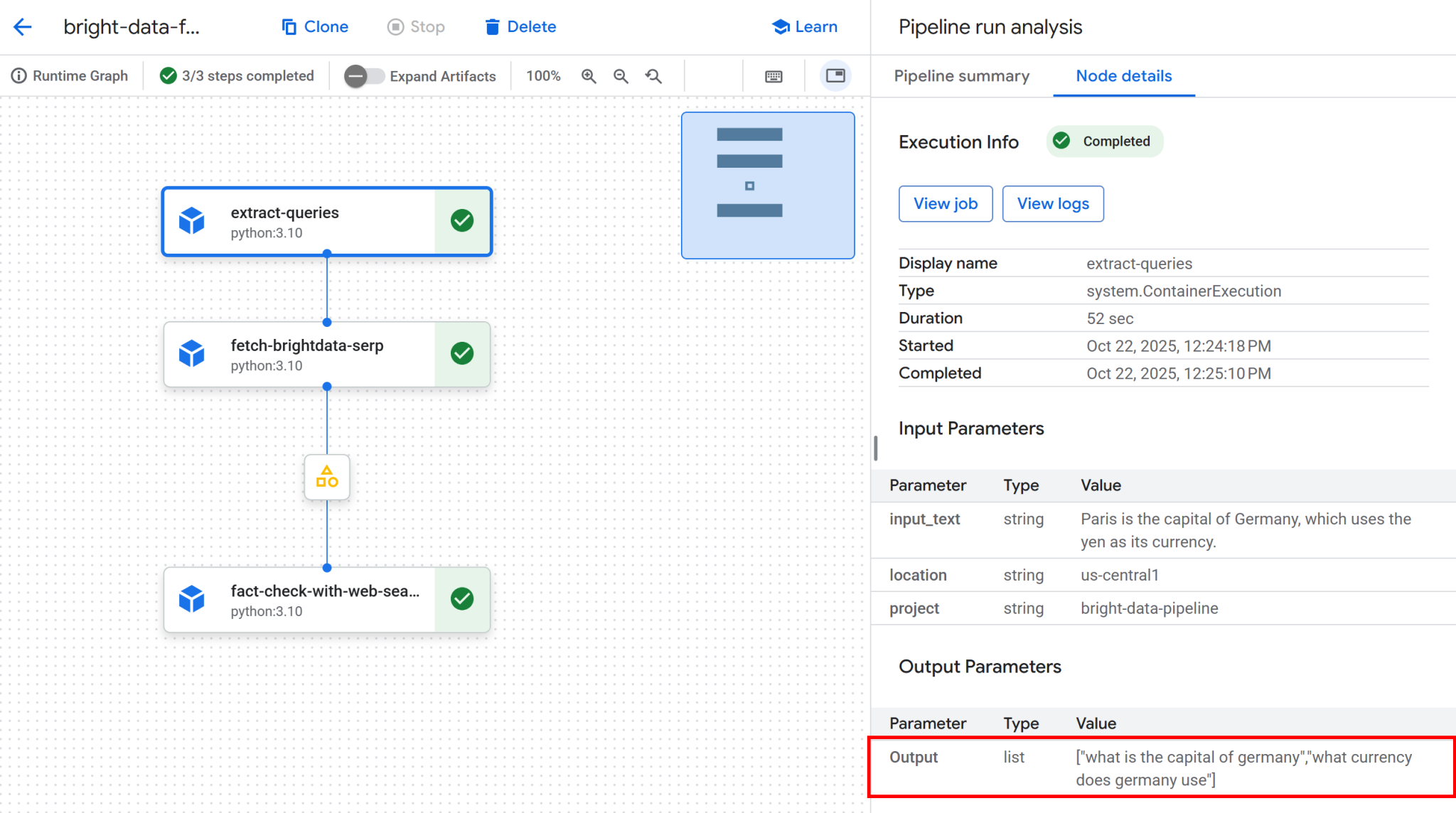
接下来,点击第二个和第三个节点之间的产物节点。您将获得存储在 Google Cloud 存储桶中 JSON 文件的访问链接,本示例为 bright-data-pipeline-artifacts。
您也可以导航到云控制台中的存储桶,直接访问所需页面:
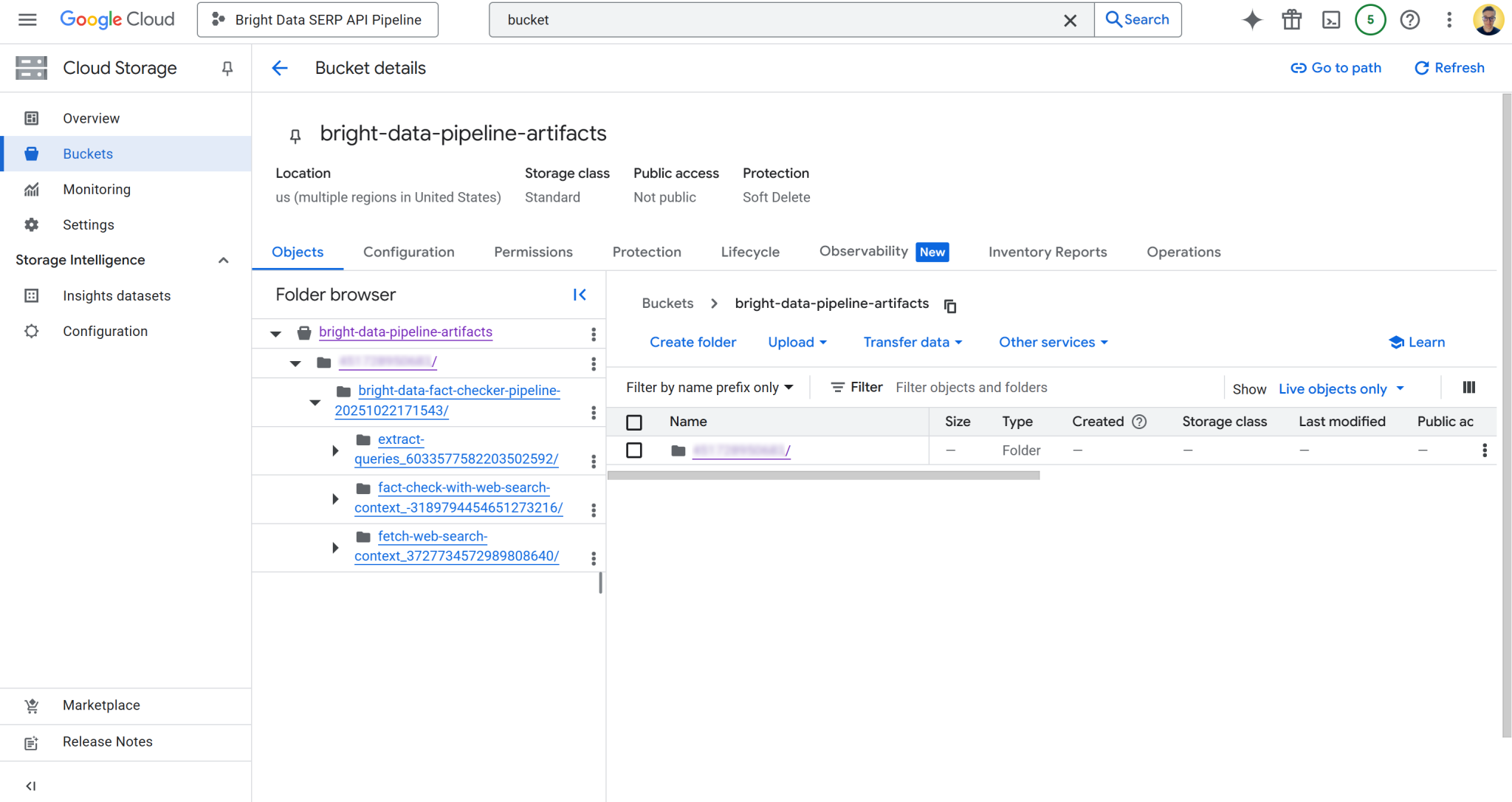
存储桶内包含每个组件的独立文件夹。具体而言, fetch_web_search_context 组件包含一个 JSON 文件,其中包含通过 SERP API 获取的网络搜索上下文,并以 Markdown 格式字符串数组的形式存储:
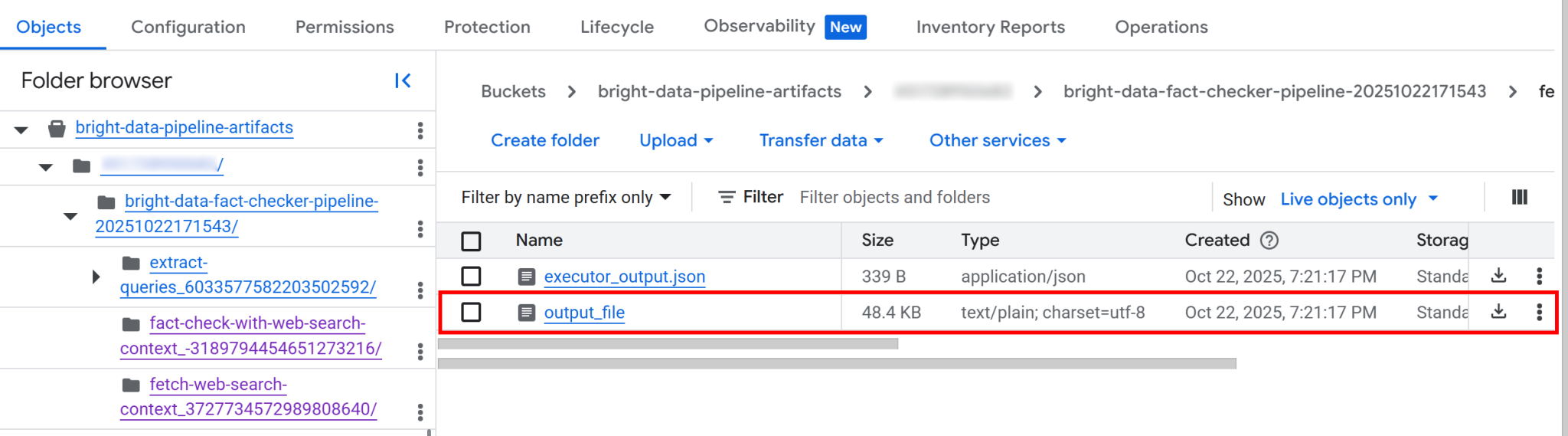
如果您下载并打开该文件,将看到类似以下内容:
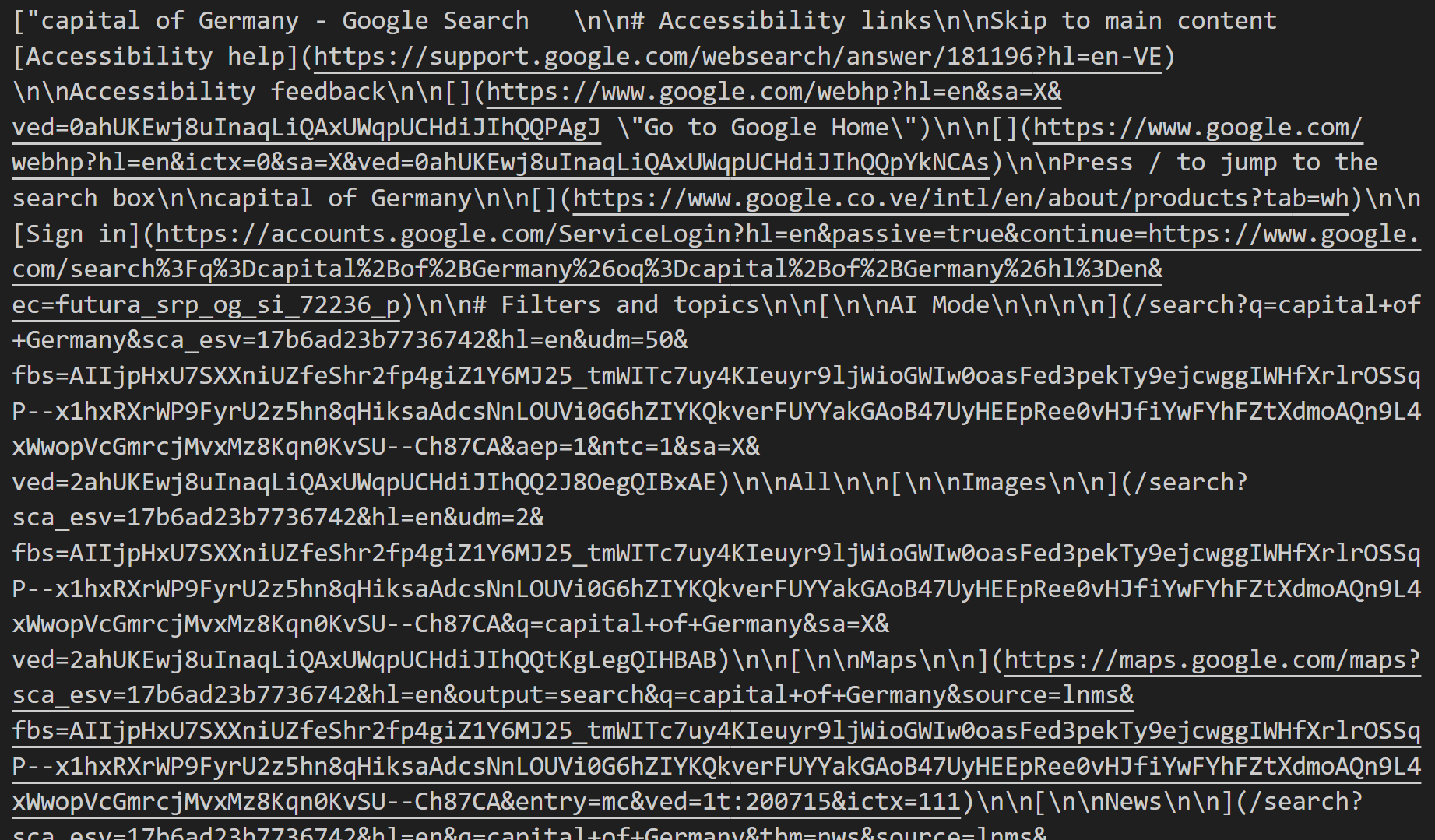
此内容针对每个搜索查询所获取的 SERP 结果页,以 Markdown 格式呈现。
返回 Vertex AI 管道用户界面,点击输出节点查看总体结果:
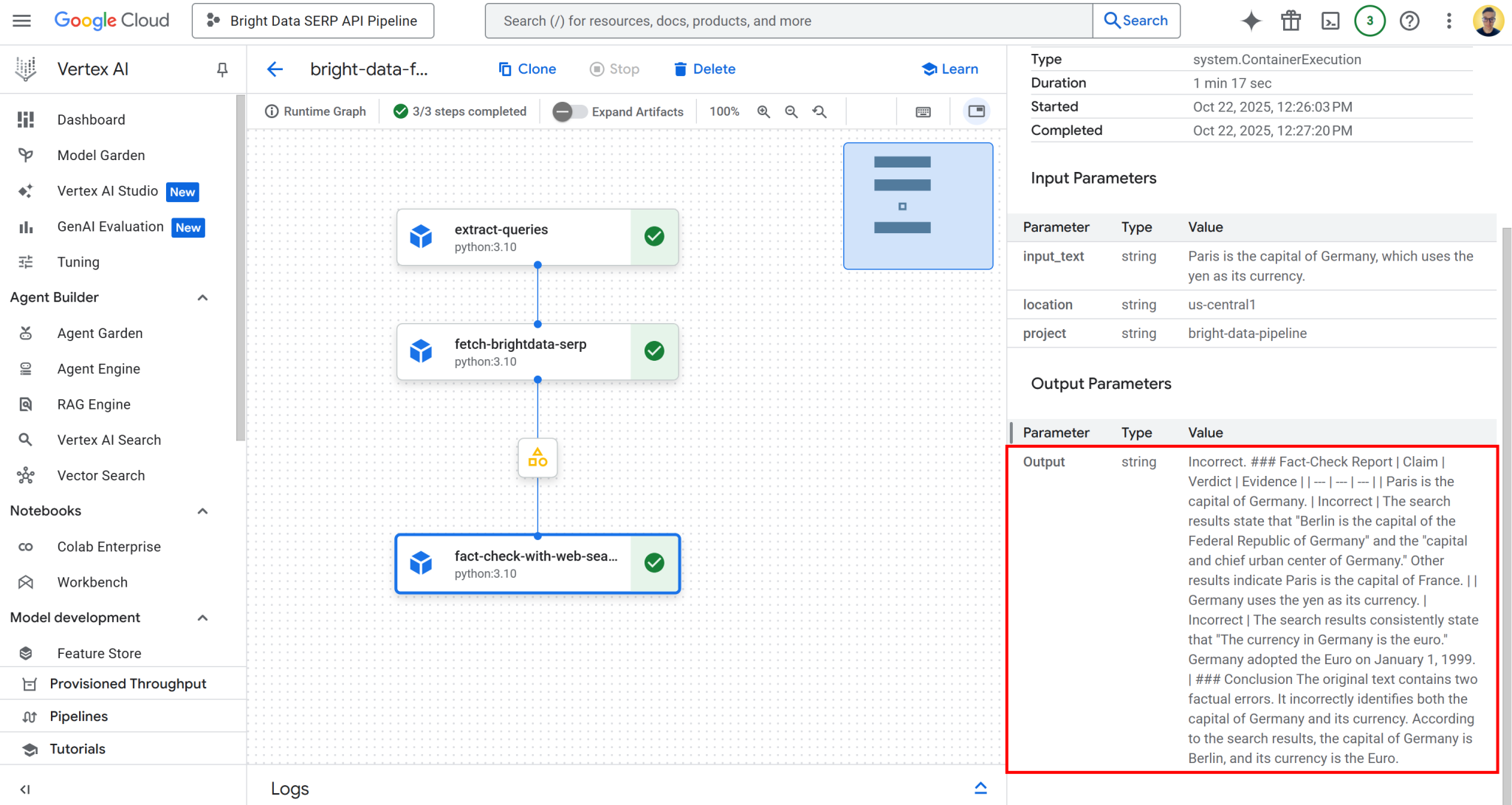
可以看到,输出内容是一份 Markdown 格式的详细事实核查报告。相同的输出也保存在管道运行对应存储桶文件夹的 executor_output.json 文件中。下载该文件并在 Visual Studio Code 等集成开发环境(IDE)中打开查看:
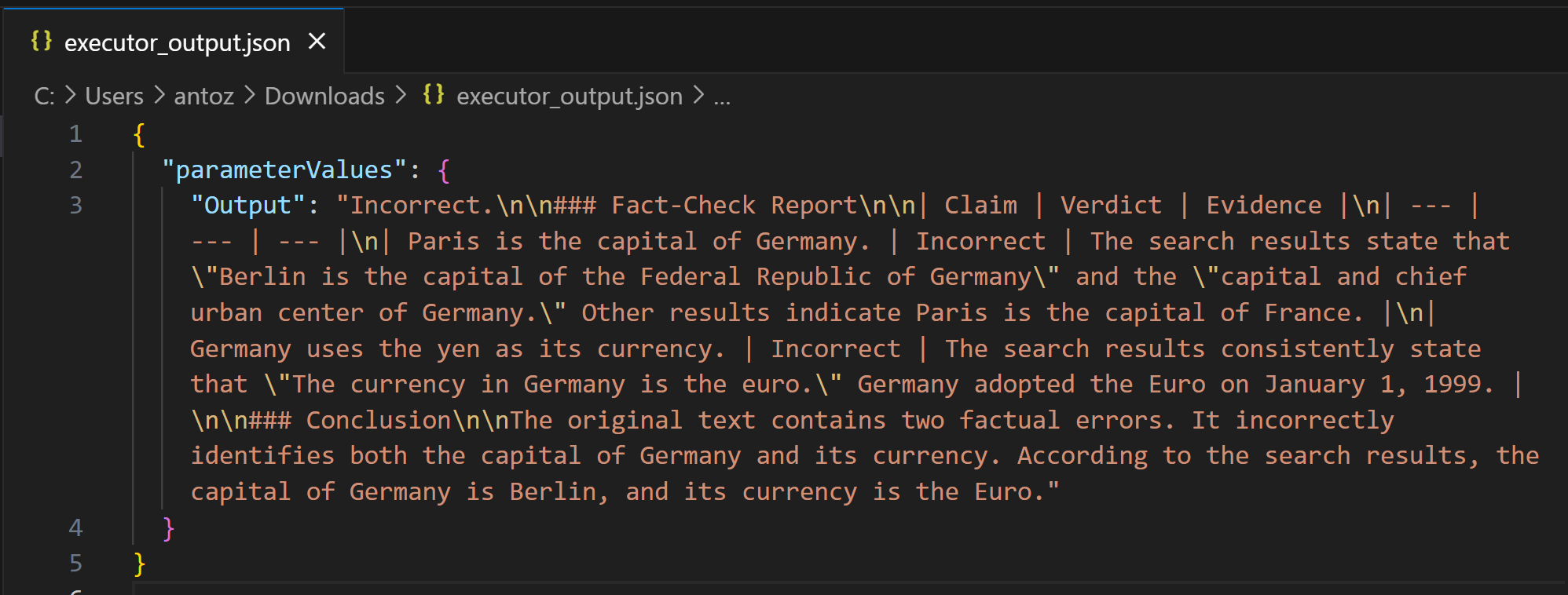
将 Markdown 字符串复制到 .md 文件中,(例如,report.md),以便更清晰地查看:
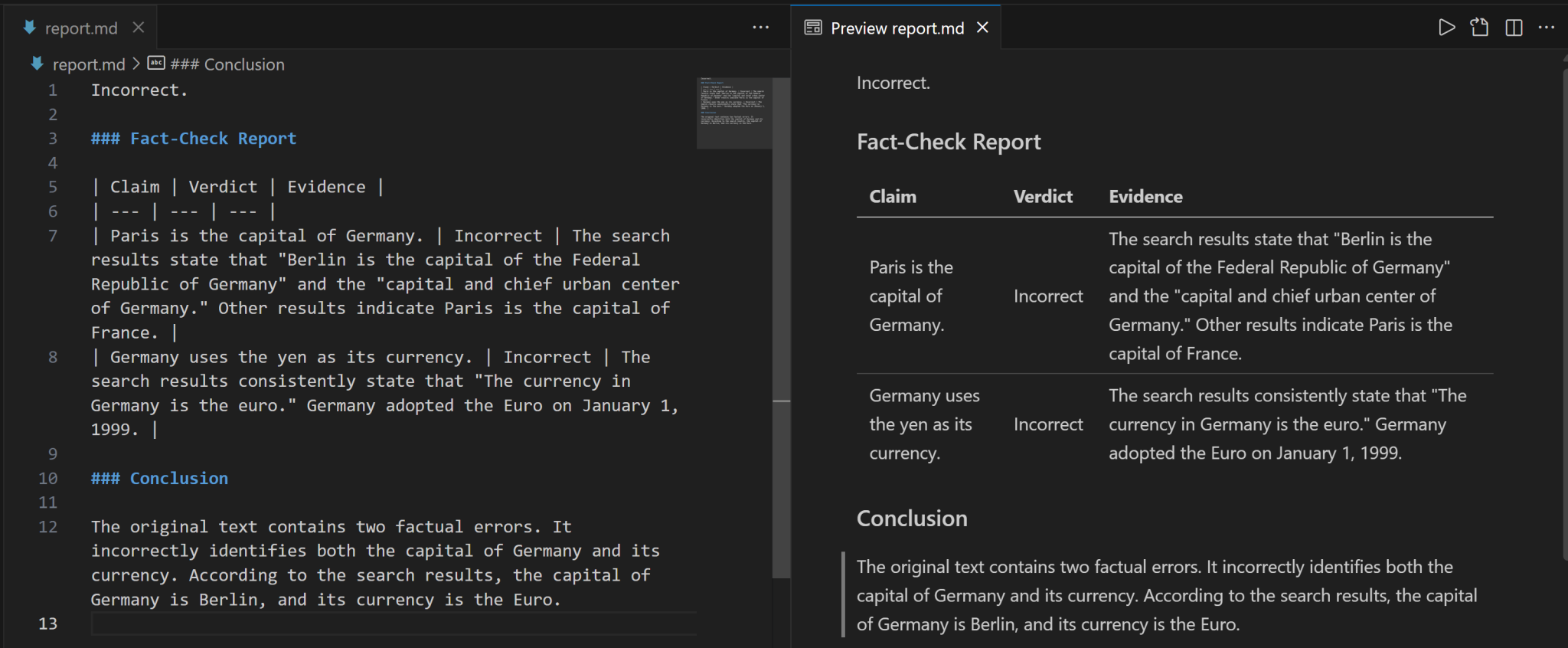
报告详细指出输入陈述中的错误内容,并提供经核实的正确事实。
核查完成!这充分证明了在基于 RAG 的 Vertex AI 管道中,Bright Data 网络搜索集成检索上下文信息的强大功能。
后续步骤
请谨记,本示例仅为基础演示,用来验证在 Vertex AI 管道中使用 Bright Data 网络数据检索的可行性。在实际应用场景中,这些组件通常被整合到更庞大、更复杂的管道体系之中。
输入数据可来自多种渠道,如业务文档、内部报告、数据库及其他文件类型。此外,工作流程可能包含更多处理环节,最终输出也不仅限于事实核查报告。
结语
通过本文,您已掌握如何在 Vertex AI 管道中运用 Bright Data SERP API 检索网络搜索上下文。这套 AI 工作流程方案非常适合需要构建程序化、高可靠性事实核查管道以确保数据准确性的应用场景。
如需创建类似的高级 AI 工作流程,欢迎探索 Bright Data AI 基础架构提供的全系列实时网络数据检索、验证与转换解决方案。
立即创建免费 Bright Data 账户,开始体验我们为 AI 场景量身打造的网络数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


