

在本教程中,你将学习:
- Mastra 作为构建 AI 智能体的解决方案是什么,以及它带来了什么。
- 为什么当 Mastra AI 智能体能够探索网络时会变得更强大。
- 如何借助与 Bright Data 工具的集成来构建一个具备 Web 访问能力的 Mastra AI 智能体。
- (可选)如何将 Mastra 连接到 Bright Data Web MCP。
让我们开始吧!
什么是 Mastra?
Mastra 是一个现代 TypeScript 框架,用于构建 AI 驱动的智能体和应用程序。它提供了一个 API,用于在统一系统中构建和管理智能体、工作流、RAG、记忆、MCP 以及可观测性。
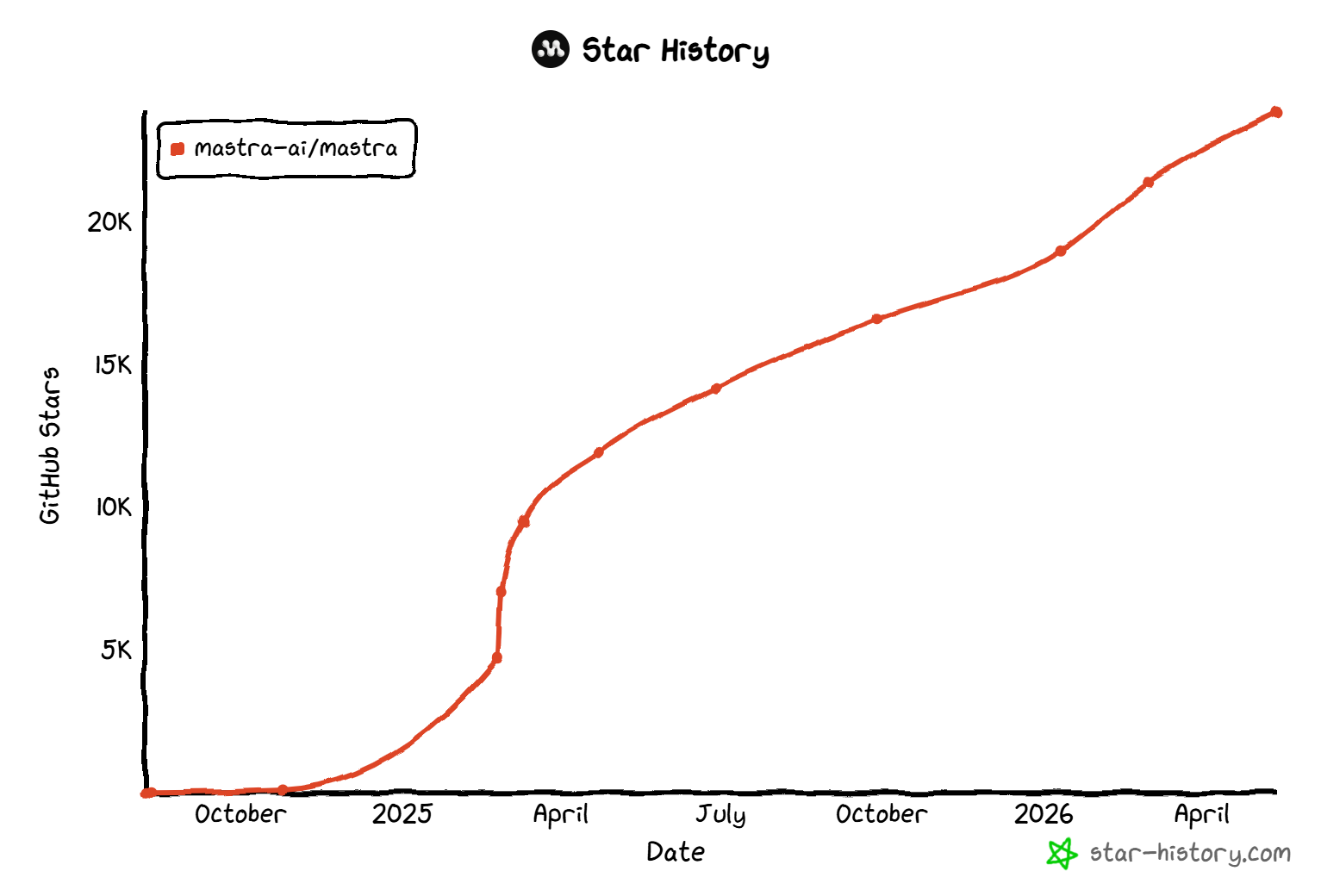
Mastra 是开源且被广泛采用,拥有超过 23.8k 个 GitHub stars。这反映了强大的社区信任和快速的生态系统增长。
该解决方案提供的主要功能包括:
- 智能体:构建自主 AI 智能体,它们能够推理、使用工具,并通过迭代完成复杂的用户定义任务。
- 工作流:使用结构化的基于图的执行来编排多步骤流程,支持分支、并行步骤以及受控的确定性逻辑。
- RAG:将智能体连接到外部知识源,通过检索增强生成管道提供有依据、具备上下文感知的响应。
- 记忆:维护短期和长期上下文,使智能体能够记住对话并提升跨交互的连续性。
- 工具:通过外部 API、函数和集成扩展智能体能力,实现真实世界的行动与动态数据访问。
- MCP: 集成 Model Context Protocol 服务器,以在系统之间暴露和消费工具、智能体以及结构化资源。
- 可观测性:使用日志、追踪、指标和性能评估工具来跟踪、评估和调试智能体行为。
在 官方文档 中了解更多。
为什么要用 Web 搜索和爬虫工具扩展 Mastra AI 智能体
Mastra 是一个用于构建 AI 驱动应用程序和智能体的丰富框架。然而,即使是设计良好的 AI 系统,在依赖过时或不完整信息时也可能发生漂移或产生低质量输出。
这是 LLM 的一个核心限制,它们在静态数据集上训练,因此缺乏实时感知能力。结果是,它们可能产生幻觉或基于陈旧上下文做出决策,从而降低准确性和可靠性。
为了解决这个问题,AI 应用程序需要访问一个实时 Web 数据基础设施。这正是 Bright Data 发挥作用的地方!
解决方案:用于 Mastra 的 Bright Data 工具
Bright Data 通过以下官方工具支持 Mastra:
webSearch:在 Google、Bing、Yandex 等引擎上执行 Web 搜索。它以 JSON 格式返回结构化的搜索引擎 API 结果,供 AI 智能体直接使用。由 Bright Data 的 搜索引擎 API 提供支持。webFetch:使用 Bright Data 的 网络解锁器 API 从任意网页检索内容。它绕过机器人防护和验证码系统,以访问来自任何域名的实时 Web 数据。
借助这一开源集成,Mastra 应用程序可以访问生产级 Web 数据基础设施。这使智能体能够发现新鲜来源、检索实时信息,并弥合训练数据与当前现实之间的差距。
Bright Data 的突出之处在于其庞大的全球基础设施,拥有超过 4 亿个覆盖 195 个国家的住宅 IP。它在保持 99.99% 正常运行时间和 99.95% 成功率的同时,实现无限并发。
如何构建一个连接到 Bright Data 以访问 Web 数据的 Mastra AI 智能体
本分步章节将引导你完成设置一个集成 Bright Data 工具的新 Mastra AI 智能体的过程。
请按照以下说明操作!
前置条件
要完成本教程,请确保你具备:
- 在本地安装 Git。
- 安装 Node.js v22.13.0 或更高版本(推荐最新的 LTS 版本)。
- 来自 Mastra 支持的 AI 模型提供商 的 API key(在本例中,我们将依赖 OpenAI API key)。
- 一个已设置 API key 的 Bright Data 账户。要创建 Bright Data 账户并配置 API key,请遵循官方文档指南。
第 1 步:初始化一个新的 Mastra 项目
注意:如果你已经有一个 Mastra 项目,可以跳过此步骤。
首先,使用 create-mastra 工具创建一个名为 mastra-bright-data-web-access-agent 的新 Mastra 项目:
npx create-mastra@latest mastra-bright-data-web-access-agent出现提示时,选择你的 AI 提供商。

在本例中,选择 “OpenAI”,然后选择手动输入 API key 的选项。出现提示时粘贴你的 OpenAI API key:

接下来,你将被询问是否启用 Mastra 可观测性。根据你的偏好进行选择,然后继续完成其余设置提示。
设置完成后,进入你的项目目录:
cd mastra-bright-data-web-access-agent你现在应该会看到类似这样的项目结构:
mastra-bright-data-web-access-agent/
├── .agents/ # Internal Mastra directory for agent skills, etc.
├── node_modules/
└── src/
│ └── mastra/
│ ├── index.ts # Entry point that initializes the Mastra setup
│ ├── agents/
│ │ └── weather-agent.ts # Defines the default Weather AI agent
│ ├── scorers/
│ │ └── weather-scorer.ts # Scoring logic to evaluate or rank agent outputs
│ ├── tools/
│ │ └── weather-tool.ts # External tool integrations used by the agent
│ └── workflows/
│ └── weather-workflow.ts # Logic combining tools and agents
├── .env # Environment variables (API keys, secrets, etc.)
├── .gitignore
├── AGENTS.md # Docs describing available agents and their behavior
├── package-lock.json
├── package.json
├── README.md # Main project documentation
└── skills-lock.json 该文件夹包含默认的 Mastra 天气 AI 智能体项目。这是一个最小模板,旨在演示如何在 Mastra 中构建智能体、工具、评分器和工作流。
浏览这些文件并熟悉它们。例如,打开 .env 文件。你应该会看到在设置期间配置的 OpenAI API key。也可以考虑使用以下命令运行智能体:
npm run dev做得好!你的 Mastra 项目现在已设置完成,并准备好使用 Bright Data 工具进行扩展。
第 2 步:安装并配置 Bright Data 工具
首先安装 Mastra Bright Data 工具以及所需的 zod 依赖:
npm install @mastra/brightdata zod@mastra/brightdata 包封装了 Bright Data JavaScript SDK,并将其用于抓取和 Web 搜索的方法暴露为与 Mastra 兼容的工具。
Bright Data JavaScript SDK 需要 BRIGHTDATA_API_TOKEN 环境变量才能工作。将其添加到你的 .env 文件中:
BRIGHTDATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 占位符替换为你实际的 Bright Data API key。该 API key 由 SDK 用于对 Bright Data APIs 的请求进行身份验证。
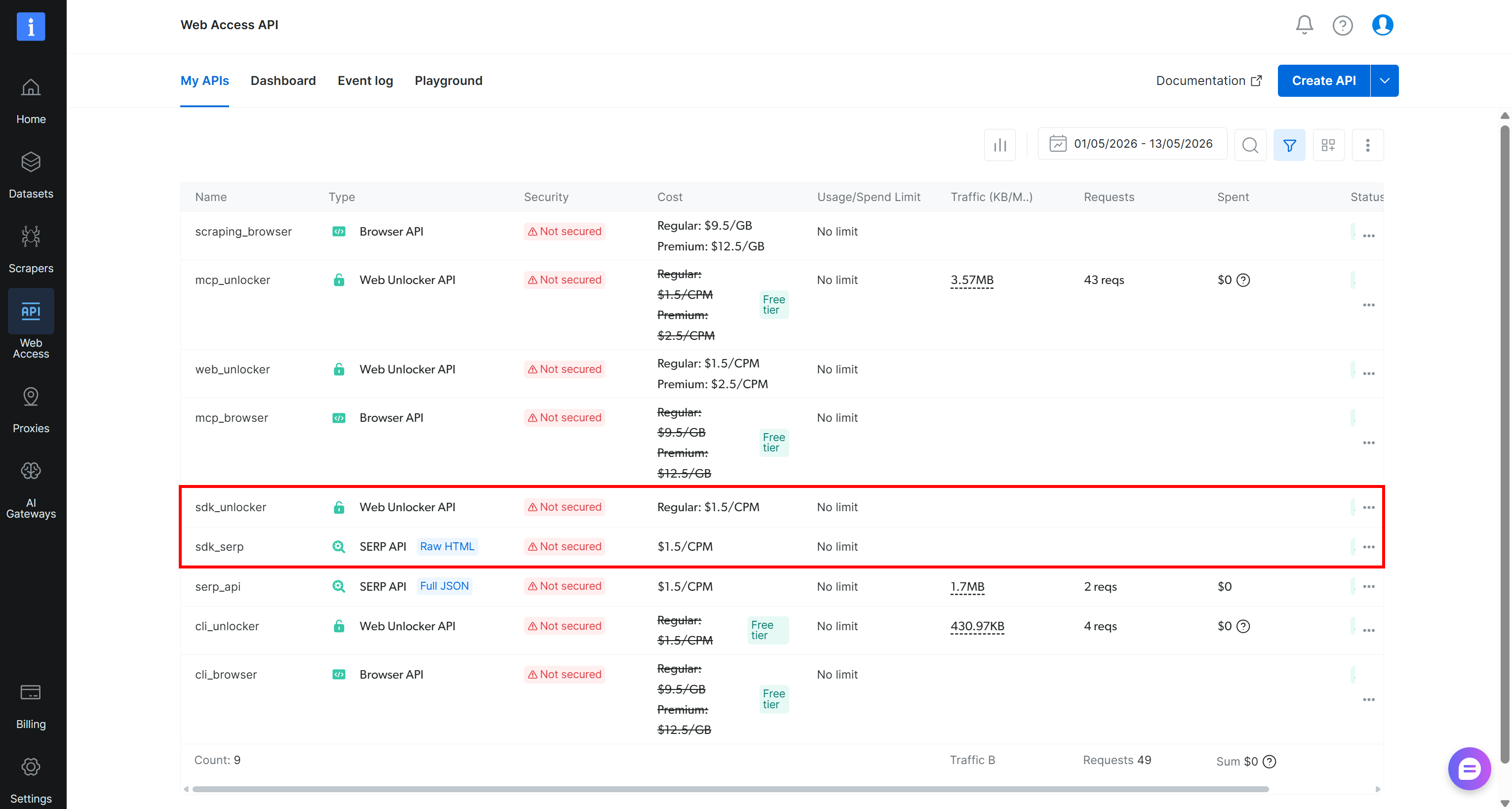
配置完成后,@mastra/brightdata 工具将能够连接到你的 Bright Data 账户。首次使用时,Bright Data SDK 将在你的 Bright Data 控制面板中自动配置所需的 API,包括所需的 网络解锁器 API 和 搜索引擎 API 区域:
第 3 步:添加 Bright Data 工具
此时,你已经安装了 Bright Data Mastra 工具。现在,你需要配置并将它们暴露给你的 AI 智能体。
为此,在 src/mastra/tools/ 内创建一个新的 web-access.ts 文件:
// src/mastra/tools/web-access.ts
import { createBrightDataTools } from '@mastra/brightdata'
// create the web search and web fetch tools using the BrightData client options
export const { webSearch, webFetch } = createBrightDataTools({
verbose: true, // enable verbose logging for debugging purposes
})这段代码使用自定义配置从 @mastra/brightdata 包中调用 createBrightDataTools()。请注意,所需的 Bright Data API key 会自动从 BRIGHTDATA_API_TOKEN 环境变量中读取。同样,区域名称会自动推断或默认创建。如有需要,你可以通过 createBrightDataTools() 中的附加选项显式配置 API key 和区域。
createBrightDataTools() 函数会生成两个与 Mastra 兼容的工具:
webSearch:使用 Bright Data 的 搜索引擎 API 为你的 AI 智能体启用 Web 搜索能力。webFetch:调用 Bright Data 的 网络解锁器 API 来获取并抓取任意网站的内容。
注意:或者,你也可以使用 createBrightDataSearchTool() 和 createBrightDataFetchTool() 分别创建并配置这些工具。如果你更偏好更细粒度的控制,这是推荐的方法。
导出这些工具使你能够稍后将它们导入到智能体定义中以启用 Web 访问。很好!Bright Data 工具现在已准备好在 Mastra AI 智能体中使用。
第 4 步:创建 Web 访问 AI 智能体
现在,是时候创建一个连接到 Bright Data 工具的 Mastra 智能体了。为此,在 src/mastra/agents/ 路径下添加一个 web-access-agent.ts 文件,并按如下方式填充:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { webFetch, webSearch } from '../tools/web-access'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
instructions: `
You are a helpful, general-purpose assistant with Bright Data web access capabilities.
Goals:
- Answer user questions by combining reasoning with fresh, tool-based information.
- Prefer tools when information may be outdated or when factual accuracy is required.
- Clearly reference tool outputs so users can trace where information comes from.
Tool usage guidelines:
- Start with the webSearch tool to gather relevant sources and context.
- Use the webFetch tool to retrieve and analyze detailed content from specific pages.
`,
model: 'openai/gpt-5-mini',
tools: {
webFetch,
webSearch,
},
memory: new Memory(),
})该片段定义了一个由 Bright Data 支持、具备 Web 搜索与抓取能力的 Mastra AI 智能体。它使智能体能够检索最新的在线信息并抓取网页。请注意,它还包含记忆支持,以便智能体能够在交互之间保持上下文。
太棒了!由 Bright Data 驱动的 Mastra AI 智能体已准备就绪。
第 5 步:将智能体添加到索引中
完成 Mastra 应用程序的最后一步是在 src/mastra/index.ts 文件中注册 webAccessAgent:
// src/mastra/index.ts
import { Mastra } from '@mastra/core/mastra'
import { PinoLogger } from '@mastra/loggers'
import { LibSQLStore } from '@mastra/libsql'
import { DuckDBStore } from '@mastra/duckdb'
import { MastraCompositeStore } from '@mastra/core/storage'
import { Observability, MastraStorageExporter, MastraPlatformExporter, SensitiveDataFilter } from '@mastra/observability'
import { webAccessAgent } from './agents/web-access-agent'
export const mastra = new Mastra({
agents: { webAccessAgent },
storage: new MastraCompositeStore({
id: 'composite-storage',
default: new LibSQLStore({
id: 'mastra-storage',
url: 'file:./mastra.db',
}),
domains: {
observability: await new DuckDBStore().getStore('observability'),
}
}),
logger: new PinoLogger({
name: 'Mastra',
level: 'info',
}),
observability: new Observability({
configs: {
default: {
serviceName: 'mastra',
exporters: [
new MastraStorageExporter(),
new MastraPlatformExporter(),
],
spanOutputProcessors: [
new SensitiveDataFilter(),
],
},
},
}),
})上述片段通过注册先前定义的 Web 访问 AI 智能体来初始化一个 Mastra 应用程序。然后,它配置复合存储,使智能体的记忆使用一个 LibSQL 存储持久化到本地 mastra.db 文件中。它还通过 Pino 启用结构化日志记录,并使用导出器与敏感数据过滤设置可观测性,以便进行监控和可追溯性。
注意:为了保持你的 Mastra 应用程序精简,考虑移除初始的与天气相关的工具、工作流和评分器。
第 6 步:测试 Web 访问智能体
使用以下命令运行你的 Mastra 应用程序:
npm run dev你应该会看到类似这样的输出:
这表明 Mastra 本地服务器正在 http://localhost:4111 运行。在浏览器中打开该 URL,你应该会看到 Mastra 控制面板:
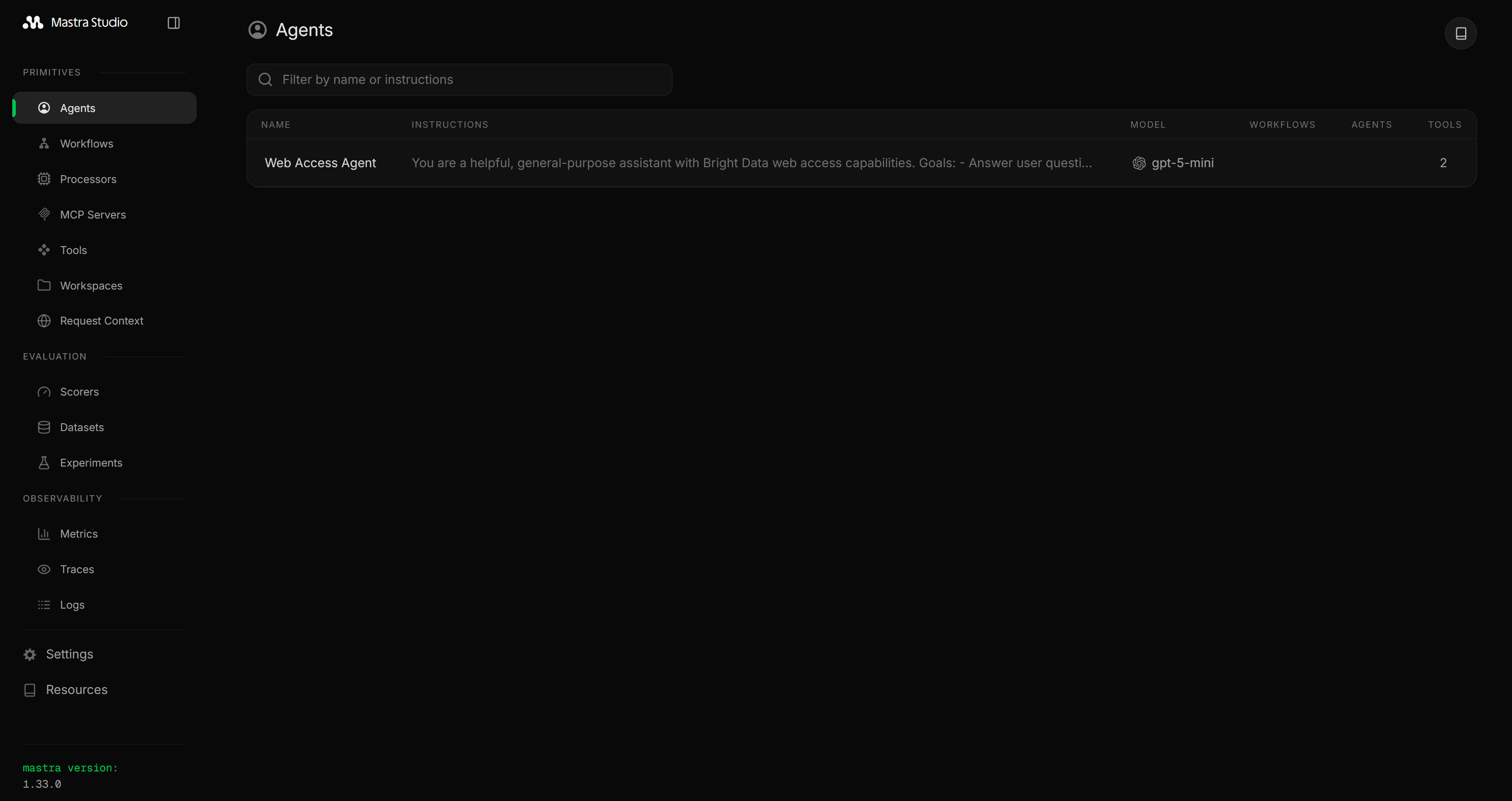
导航到 “Tools” 部分,你将看到从 src/mastra/tools/web-access.ts 暴露的两个 Bright Data 工具:
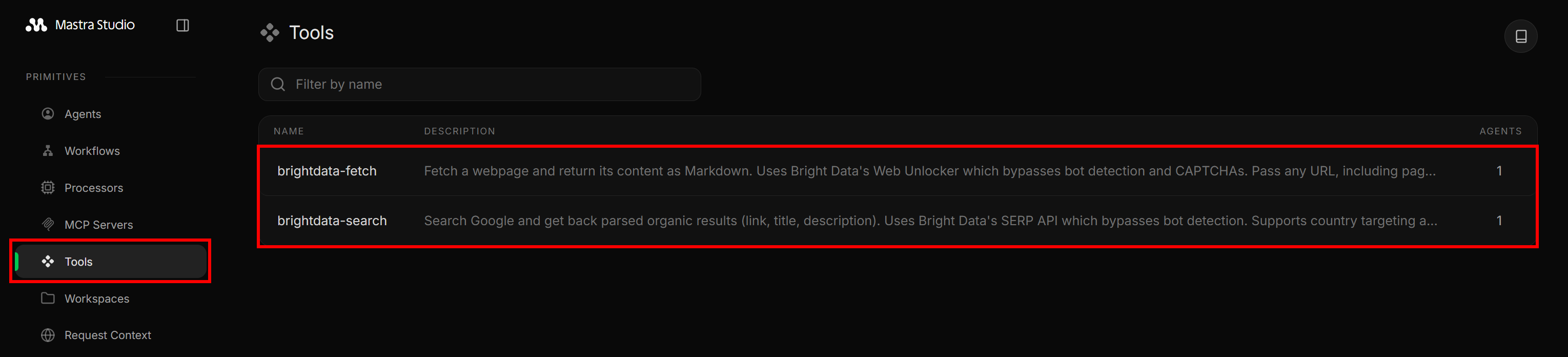
然后,前往 Agents 页面并点击 “Web Access Agent” 条目:

这将打开智能体的提示 UI,你可以与它聊天。为了验证智能体的 Web 探索能力,发起一个类似这样的提示:
Search for the latest stock market news on Google. Select the most relevant articles, extract and analyze their content, and return a structured Markdown report summarizing the key information, including links to learn more.运行它,你应该会看到类似这样的输出:
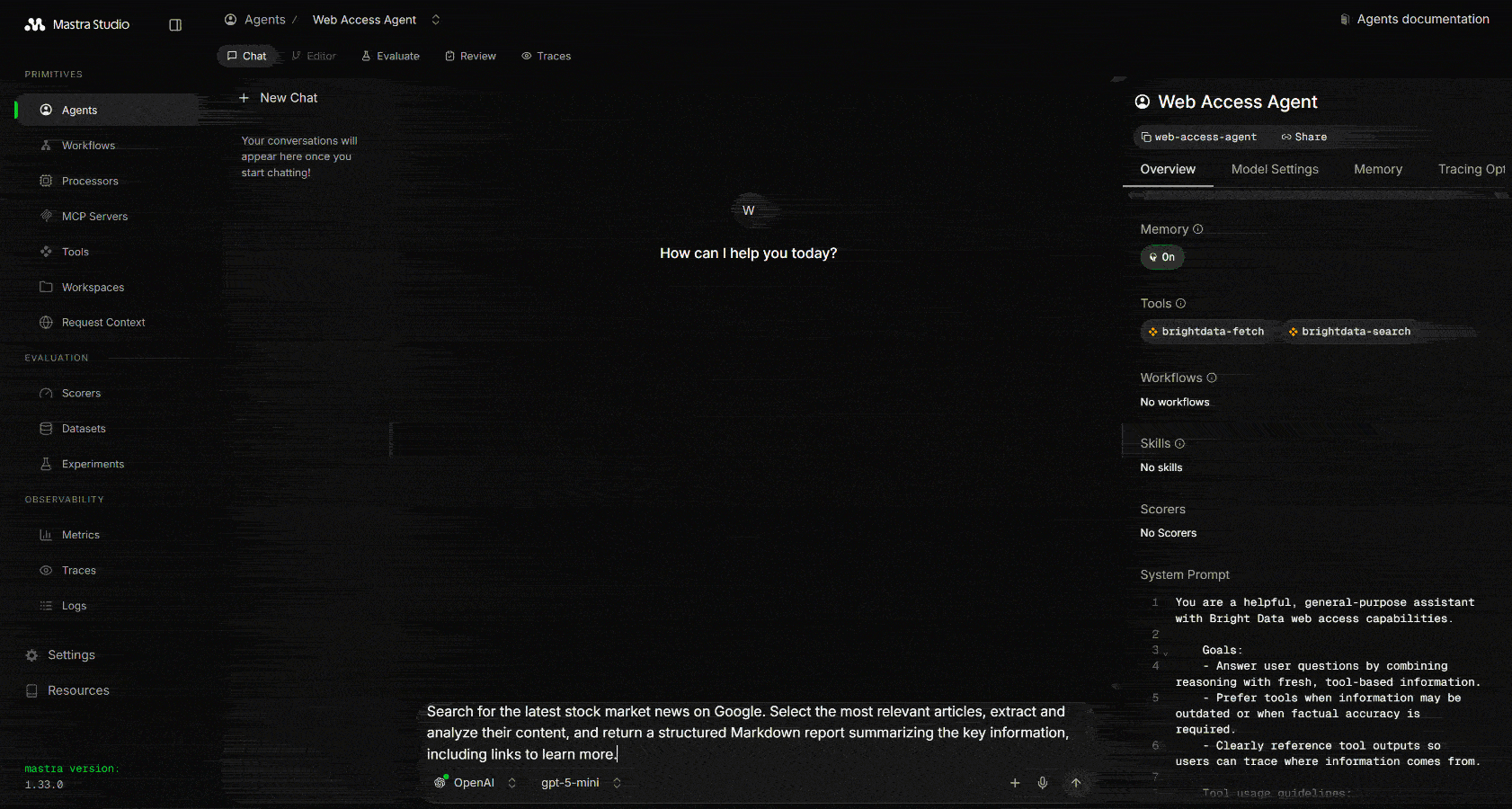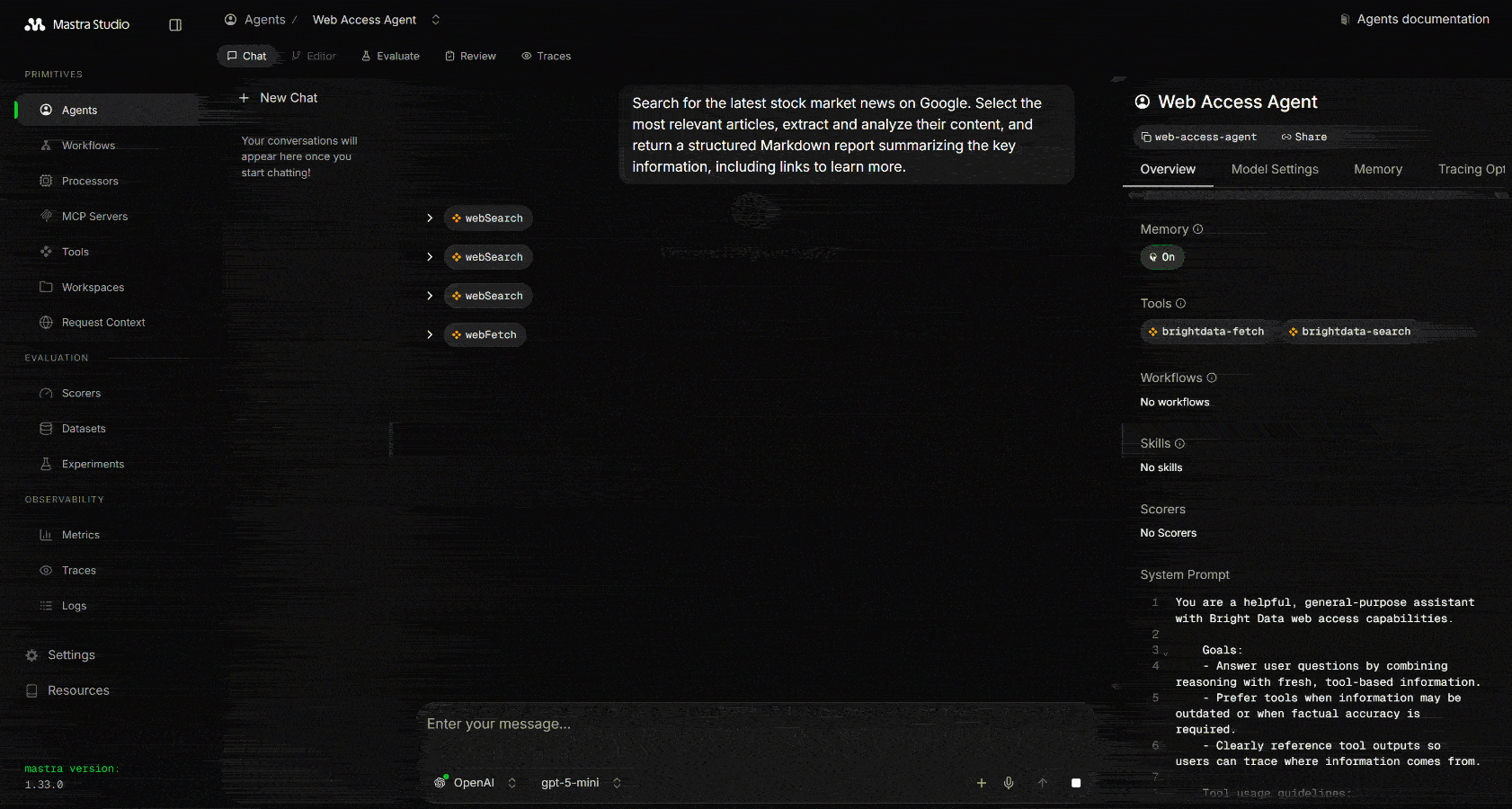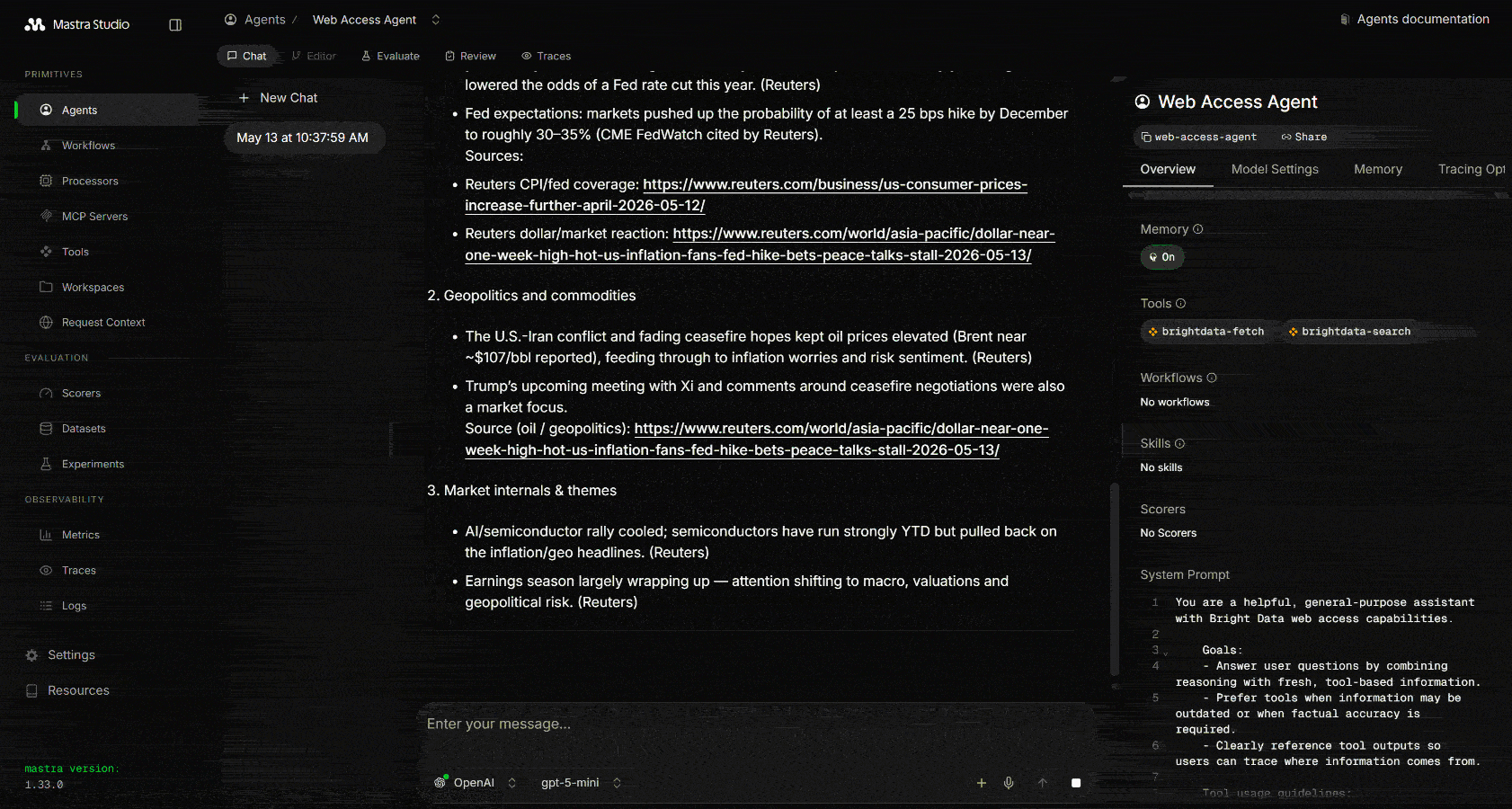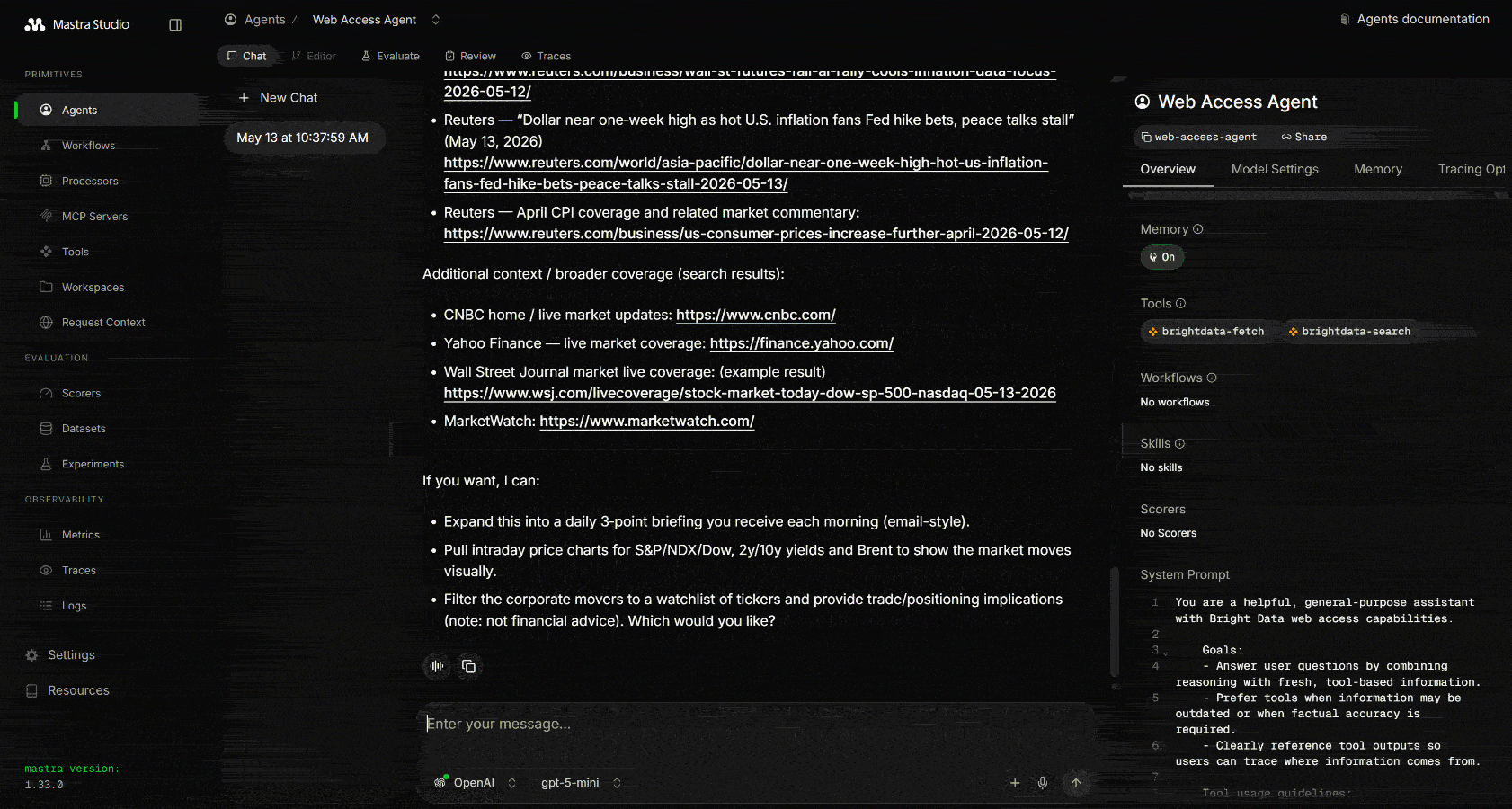
注意,Mastra 调用了 Web 搜索工具三次来执行相关的 Google 搜索查询。这些返回从 Google 抓取的、以 JSON 结构化的搜索引擎 API 结果:
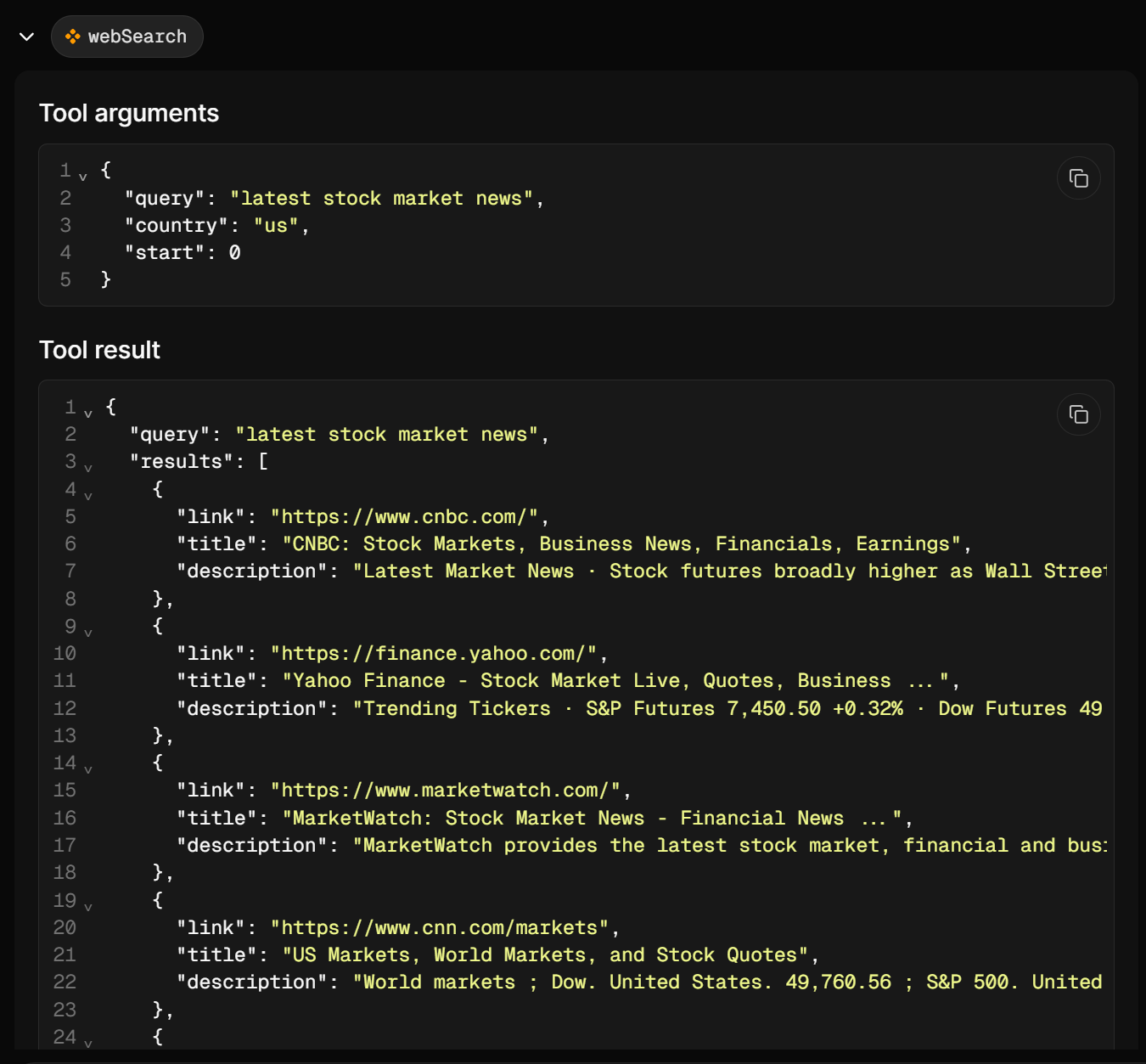
基于这些结果,智能体选择最相关的链接并使用 webFetch 抓取其内容。最后,它将所有内容聚合为一个结构化的 Markdown 报告,总结今天的股市新闻。
就是这样!得益于 Bright Data 集成,你的 Mastra AI 智能体现在具备企业级 Web 搜索和爬虫能力,从而能够给出更有依据的响应。尝试不同的提示并测试所有支持的场景和用例!
[额外] 将 Mastra AI 智能体连接到 Bright Data Web MCP
请记住 Mastra 也支持 MCP 集成。因此,你可以将你的 Mastra AI 智能体连接到 Bright Data Web MCP。
Web MCP 服务器提供对 70+ 工具的访问,用于 Web 搜索、抓取、数据提取、数据源检索以及浏览器自动化。请记住,它提供一个免费计划(每月 5k 次请求)。
要在 Mastra 中使用 MCP,首先安装所需依赖:
npm install @mastra/mcp@latest然后,添加一个包含如下内容的 src/mastra/mcp/bright-data-mcp-client.ts 文件:
// src/mastra/mcp/bright-data-mcp-client.ts
import { MCPClient } from '@mastra/mcp'
export const brightDataMcpClient = new MCPClient({
id: 'bright-data-mcp-client',
servers: {
'bright-data': {
command: 'npx',
args: ['-y', '@brightdata/mcp'],
env: {
'API_TOKEN': process.env.BRIGHTDATA_API_TOKEN || '',
'PRO_MODE': 'true' // remove to enable free mode
},
},
},
})这会通过 @brightdata/mcp 包启动 Bright Data MCP。服务器使用 API_TOKEN 环境变量对与你账户的连接进行身份验证,该变量应通过 .env 文件中的 BRIGHTDATA_API_TOKEN 设置为你的 Bright Data API key。
注意,'PRO_MODE': 'true' 设置是可选的。启用后,它会提供对完整 70+ 工具集合的访问,但也可能产生基于用量的费用。
在你的 Mastra 智能体文件中,通过导入 MCPClient 并在 tools 参数中调用 .listTools() 来使用来自 MCP 服务器的工具:
// src/mastra/agents/web-access-agent.ts
import { Agent } from '@mastra/core/agent'
import { Memory } from '@mastra/memory'
import { brightDataMcpClient } from '../mcp/bright-data-mcp-client'
export const webAccessAgent = new Agent({
id: 'web-access-agent',
name: 'Web Access Agent',
// omitted for brevity...
tools: {
...await brightDataMcpClient.listTools(),
},
memory: new Memory(),
})如果你现在运行 Mastra 应用程序,你将看到 Bright Data Web MCP 工具:
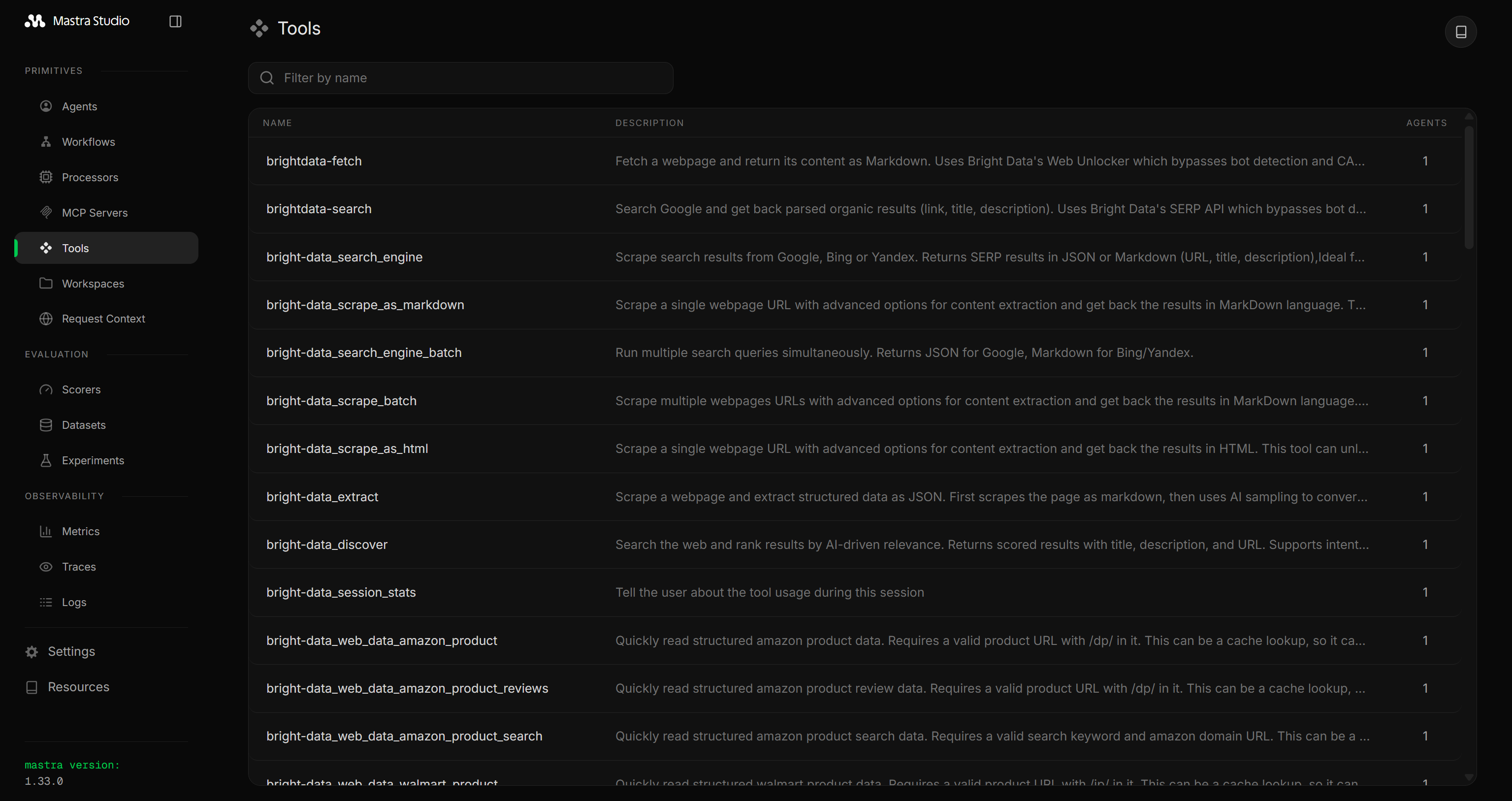
当在 Pro 模式下配置时,Web MCP 会暴露 70+ 工具,或者在 Rapid(免费层)模式下暴露可用的 5 个工具。
任务完成!你的 Mastra AI 智能体现在已通过 MCP 连接到 Bright Data 基础设施。
结论
在这篇博客文章中,你了解了 Mastra 是什么以及它提供的关键功能。特别是,你看到了如何以及为什么使用官方 Bright Data 工具或通过 Web MCP 来扩展它。
该集成将 Mastra 智能体提升到一个全新的水平。AI 智能体现在可以执行 Web 搜索、发现并提取结构化数据,并与真实世界的网站交互。
立即创建一个免费的 Bright Data 账户并开始集成我们为 AI 准备的 Web 数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




