立即注册,首次充值,即可获赠相应奖励,最高可达 $500。
马上开始
免费试用
产品
网页数据抓取 API
网页解锁 API
告别封锁和验证码
网页抓取 API
将整个网站转化为可用于 AI 训练的数据
搜索引擎结果页 API
按需获取多引擎搜索结果
抓取浏览器
键启动内置隐匿模式的远程浏览器
数据源
抓取APIs
从250多个热门网站实施抓取数据 领英 | 电商 | 社交媒体 | 定制数据集
领英
电商
社交媒体
定制数据集
爬虫工作室
将任何网站转化为数据管道
数据集
从250多个热门网站预收集数据 领英 | 电商 | 社交媒体 | 定制数据集
领英
电商
社交媒体
房地产
缓存速递
实时网页数据,采集即交付
数据与洞察
零售情报
解锁实时电商洞察与AI驱动的业务推荐
企业级数据服务
为企业级数据收集量身定制
Deep Lookup
测试版
在海量级网页数据上运行复杂查询
代理服务
动态代理
5折
超40000万 万高速真人住宅代理
静态ISP代理
130万+ 超高速静态住宅代理
数据中心代理
用于数据获取的高速代理
人工智能训练的数据
多模态训练
视频与媒体数据
获得取之不尽的视频,图片及更多内容
视频信息流——为 VLA 准备就绪
获取持续、定向的网页视频,用于训练人形机器人策略
数据包
为各行各业生成可直接用于LLM的数据集
智能体 Web 执行
搜索及提取
让 AI 应用具备搜索与爬取整个网络的能力
智能体浏览器
让智能体浏览网站并自动执行任务
亮数据 MCP
免费
站式工具包,全面解锁网页
资源
资源
初创企业计划
新
演示智能体
集成
价格
网页数据抓取 API
网页解锁 API
起价
$1/ 每1 次请求
爬虫 API
起价
$1/1k请求
搜索引擎 API
起价
$1/ 每1 次请求
抓取浏览器 API
起价
$5/GB
数据源
抓取APIs
七五折
起价
$1
$0.75/1k 记录条
爬虫工作室定价
起价
$1/1k请求
数据集
起价
$250/100K 记录条
缓存速递
起价
$0.2/1k HTML
数据及洞察
零售
洞察
起价
$250/月
定制
抓取器
起价
$400/月
代理基础设施
动态代理
5折
起价
$5
$2.5/GB
数据中心代理
起价
$0.9/IP
ISP 代理
起价
$1.3/IP
资源
工具
第三方工具集成
浏览器扩展
代理网络检查
网站地图
学习中心
博客
案例研究
网络研讨会
代理位置
产品技术视频
公司
联盟推荐
信任中心
Bright SDK
帮助文档
登录
用户控制面板
联系销售
免费试用
Account
更改密码
登出
代理101
2026 年最佳 SOCKS5 代理服务商:权威对比
通过我们的专家指南探索最佳 SOCKS5 代理。查看顶级服务商、关键功能与价格,帮助你为自身需求选择合适的解决方案。
2 分钟阅读
Antonello Zanini
技术写作
AI
使用 GPT Vision 的可视化网页抓取:完整教程 2026
快速学习使用 GPT Vision 与 Python 在 2026 年从网站截图中提取数据的可视化网页抓取。
1 分钟阅读
Antonello Zanini
技术写作
AI
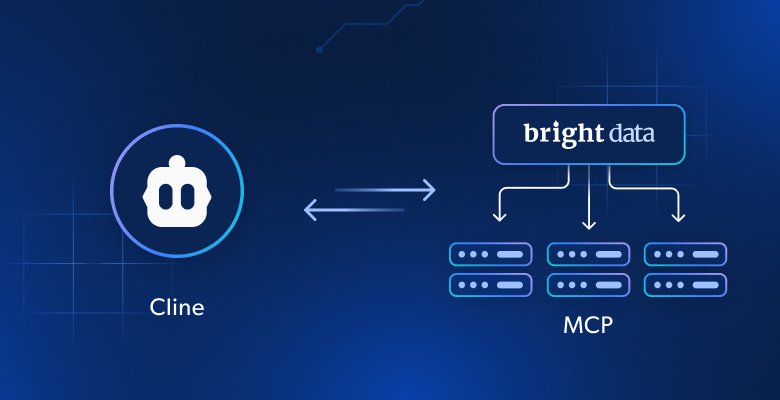
在 Cline 中使用 Bright Data 的 MCP 服务器进行网页抓取
通过集成 Bright Data MCP,为你的 Cline AI 编码代理解锁网页抓取能力,在 VS Code 中实现更智能、更数据驱动的开发。
3 分钟阅读
Antonello Zanini
技术写作
AI
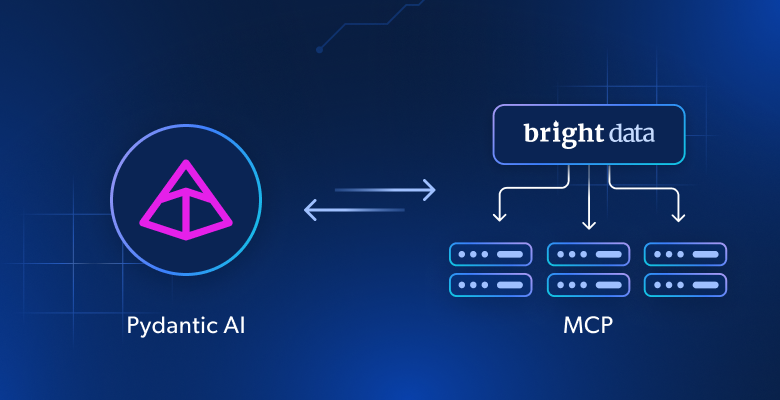
将 Pydantic AI 与 Bright Data 的 Web MCP 结合,为代理赋予数据访问能力
了解如何将 Pydantic AI 与 Bright Data MCP 结合,构建能实时访问和提取网页数据的 Python AI 代理。
2 分钟阅读
Antonello Zanini
技术写作
AI
使用 Pipedream 与 Bright Data 的网页爬取工作流
通过 Bright Data 的便捷集成,快速在 Pipedream 中搭建自动化、AI 驱动的网页爬取工作流。
6 分钟阅读
Federico Trotta
技术写作者
AI
使用 Lovable、Supabase 和 Bright Data 构建网页数据提取应用
创建一款现代应用,借助 Lovable、Supabase、Bright Data 和 Gemini AI,全自动提取干净、结构化的网页数据。
6 分钟阅读
Satyam Tripathi
技术写作者
AI
将 Gemini CLI 接入 Bright Data 的 Web MCP 服务器
了解如何将 Gemini CLI 与 Bright Data 的 Web MCP 集成,在终端中实现高级的网页增强型 AI 编码体验。
3 分钟阅读
Antonello Zanini
技术写作
AI
使用 CrewAI 与 Bright Data 构建房地产智能体
探索如何利用 CrewAI 与 Bright Data 的 MCP 服务器,自动化房地产数据采集、市场分析与客户互动。
11 分钟阅读
Arindam Majumder
AI 内容创作者
AI
使用 Bright Data 构建 Agentic RAG
了解如何将 Bright Data、向量数据库与 AI 代理相结合,构建强大、自治的 Agentic RAG 系统,实现实时知识检索。
13 分钟阅读
Arindam Majumder
AI 内容创作者
AI
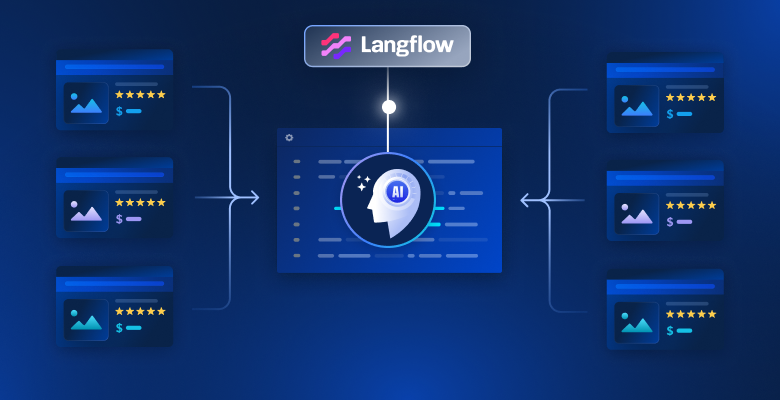
如何在 Langflow 中构建具有网络数据访问的 AI 应用
了解如何将 Langflow AI 应用连接到 Bright Data 的实时网络数据,实现实时、AI 驱动的工作流,以及简便的集成方式。
4 分钟阅读
Antonello Zanini
技术写作
AI
使用 Pica 和 Bright Data 构建 AI 代理
探索如何通过集成 Bright Data,将 Pica 用于实时网页数据检索,为 AI 代理注入强大动力,生成最新且可靠的响应。
1 分钟阅读
Antonello Zanini
技术写作
网络数据
2026 年15个顶级数据交易市场
了解 2026 年最值得关注的 15 个数据交易市场,并学习如何为你的数据获取与共享选择合适的平台。
3 分钟阅读
Jake Nulty
技术写作者
文章分页
1
…
13
14
15
16
17
18
19
…
41