
在本教程中,你将了解:
- 什么是 Semantic Kernel、它提供的核心功能以及其工作方式。
- 为什么用 MCP 扩展它会更强大。
- 如何使用 Semantic Kernel 集成 Bright Data Web MCP 来构建一个 AI 代理。
让我们开始吧!
什么是 Semantic Kernel?
Semantic Kernel 是由微软开发的开源 SDK,帮助你将 AI 模型和大语言模型(LLM)集成到应用中,以构建 AI 代理和先进的生成式 AI 解决方案。它充当可用于生产的中间件,提供到多个 AI 服务的连接器,并支持语义(基于提示)和原生(基于代码)的函数执行。
该 SDK 提供 C#、Python 和 Java 版本。它是一个灵活的解决方案,可用于生成文本、执行聊天补全,或连接外部数据源与服务。截至撰写时,该项目的 GitHub 仓库已有超过 26k 颗星。
主要功能
Semantic Kernel 提供的主要特性包括:
- AI 模型集成:通过统一接口连接 OpenAI、Azure OpenAI 等服务,实现聊天补全、文本生成等。
- 插件系统:支持使用语义函数(提示)和原生函数(C#、Python 或 Java)的插件,扩展 AI 能力。
- AI 代理:让你构建能解释用户请求、协调多个插件与服务以解决复杂任务的代理。
- 规划与函数调用:帮助代理将多步骤任务拆解执行,并选择合适的插件或函数。
- 检索增强生成(RAG):通过搜索与数据连接器将真实数据注入提示,产出更准确、最新的响应。
Semantic Kernel 的工作原理
理解该库的运行方式,有助于了解其主要组件:
- 核心内核:编排 AI 服务与插件。
- AI 服务连接器:通过通用接口将应用代码连接到不同的 AI 模型与服务。
- 插件:包含扩展代理能力的语义与原生函数。
- AI 代理:构建在内核之上,利用插件处理请求并运行工作流。
为什么要通过 MCP 集成来扩展 Semantic Kernel
Semantic Kernel 是与模型无关的 SDK,允许你构建、编排并部署复杂的 AI 代理、工作流,甚至多代理系统。无论架构多么复杂,这些工作流与代理依然需要底层的 AI 模型来运行。
无论是 OpenAI、Azure OpenAI 还是其他 LLM,所有模型都存在同样的根本限制:它们的知识是静态的…
LLM 是在某一时间点的快照数据上训练的,这意味着其知识很快会过时。更重要的是,它们无法原生与在线网站或外部数据源互动。
这正是 Semantic Kernel 通过插件可扩展性带来不同之处的原因。通过集成 Bright Data 的 Web MCP,你可以让 AI 代理突破静态知识的限制,直接从网络检索最新、高质量的数据。
这个开源的 Web MCP 服务器提供对 60 多个开箱即用的 AI 工具 的访问,这些工具都由 Bright Data 的网页交互与数据采集基础设施驱动。
即使在免费层,你的 AI 代理也已可使用两个强大的工具:
| 工具 | 描述 |
|---|---|
search_engine |
从 Google、Bing 或 Yandex 获取搜索结果,格式为 JSON 或 Markdown。 |
scrape_as_markdown |
将任意网页抓取为干净的 Markdown 格式,绕过机器人检测与 CAPTCHA。 |
除此之外,Web MCP 还解锁数十种专用工具,可在 Amazon、LinkedIn、Yahoo Finance、TikTok 等平台进行结构化数据采集。更多信息可查看 官方 GitHub 页面。
简而言之,将 Semantic Kernel 与 Web MCP 结合,可把静态工作流转化为能与在线网站交互、访问网页数据并产出贴近真实世界洞见的动态 AI 代理。
如何在 Semantic Kernel 中构建连接 Bright Data Web MCP 的 AI 代理
在这一引导部分,你将学习如何将 Bright Data 的 Web MCP 连接到一个用 C# 编写的 Semantic Kernel AI 代理。具体而言,你将使用该集成来构建一个 Reddit 分析 AI 代理,它将:
- 利用 Bright Data Web MCP 工具检索来自 Reddit 帖子的信息。
- 使用 OpenAI 的 GPT-5 模型处理检索到的数据。
- 以 Markdown 报告的形式返回结果。
注意:以下代码使用 .NET 9 的 C# 编写。但你也可以轻松将其转换为 Python 或 Java,这两种语言同样受支持。
按如下步骤开始!
前提条件
开始之前,请确保你已:
- 在本地安装了 .NET 8.0 或更高版本(本教程以 .NET 9 为例)
- 拥有一个 OpenAI API 密钥
- 拥有一个 Bright Data 账户并准备好 API 密钥
无需担心 Bright Data 账户的设置,我们会在后续步骤中引导你完成。
步骤 1:创建你的 .NET C# 项目
使用以下命令初始化一个名为 SK_MCP_Agent 的 .NET 控制台项目:
dotnet new console -n SK_MCP_Agent然后进入项目文件夹:
cd SK_MCP_Agent此时你应看到如下目录结构:
SK_MCP_Agent/
├── Program.cs
├── SK_MCP_Agent.csproj
└── obj/
├── project.assets.json
├── project.nuget.cache
├── SK_MCP_Agent.csproj.nuget.dgspec.json
├── SK_MCP_Agent.csproj.nuget.g.props
└── SK_MCP_Agent.csproj.nuget.g.targets具体来说,Program.cs 目前包含一个默认的 “Hello, World” 程序。你将把 Semantic Kernel AI 代理的逻辑写在这个文件中。
现在,在 .NET C# IDE(如 Visual Studio 或 Visual Studio Code)中打开项目文件夹。在 IDE 的终端中,通过以下命令安装所需依赖:
dotnet add package Microsoft.Extensions.Configuration
dotnet add package Microsoft.Extensions.Configuration.EnvironmentVariables
dotnet add package Microsoft.Extensions.Configuration.UserSecrets
dotnet add package Microsoft.SemanticKernel --prerelease
dotnet add package Microsoft.SemanticKernel.Agents.Core --prerelease
dotnet add package ModelContextProtocol --prerelease
dotnet add package System.Linq.AsyncEnumerable --prerelease所需的 NuGet 包包括:
Microsoft.Extensions.Configuration.*:提供基于键值的配置,支持从环境变量和 .NET 用户机密读取设置。Microsoft.SemanticKernel.*:一个将 AI LLM 与传统编程语言集成的轻量 SDK,包含代理开发工具。ModelContextProtocol:官方 MCP C# 客户端,用于连接 Bright Data Web MCP。System.Linq.AsyncEnumerable:为IAsyncEnumerable<T>提供完整的 LINQ 扩展方法集。
注意:--prerelease 标志告诉 .NET CLI 安装某个 NuGet 包的最新(预发布)版本。这对于仍在开发或实验阶段的部分包是必须的。
完成!你的 .NET 开发环境已准备好使用 Semantic Kernel 构建集成 Bright Data Web MCP 的 C# AI 代理。
步骤 2:配置机密加载
你的 AI 代理将依赖第三方组件,如 OpenAI 模型与 Bright Data Web MCP 服务器。这两项集成都需要通过 API 密钥令牌进行身份验证。为避免在代码中直接暴露这些密钥,请使用 .NET 的用户机密存储系统或环境变量安全存储。
为此,先导入配置包:
using Microsoft.Extensions.Configuration;然后,将机密加载到一个 config 对象:
var config = new ConfigurationBuilder()
.AddUserSecrets<Program>()
.AddEnvironmentVariables()
.Build();你现在可以像这样访问代码中的机密:
config["<secret_name>"]在项目文件夹中运行以下命令初始化用户机密存储:
dotnet user-secrets init这会为你的机密(即 API 密钥)创建一个安全的本地存储。
很好!你的 C# 程序现已可以安全处理敏感凭据,而无需在源代码中暴露它们。
步骤 3:测试 Bright Data 的 Web MCP
在将 Bright Data 的 Web MCP 连接到你的代理之前,先验证你的机器可以运行 MCP 服务器。
如果你还没有 Bright Data 账户,请新建一个。如果已有账户,直接登录。为了快速设置,请进入控制台的 “MCP” 页面并按照指引操作:
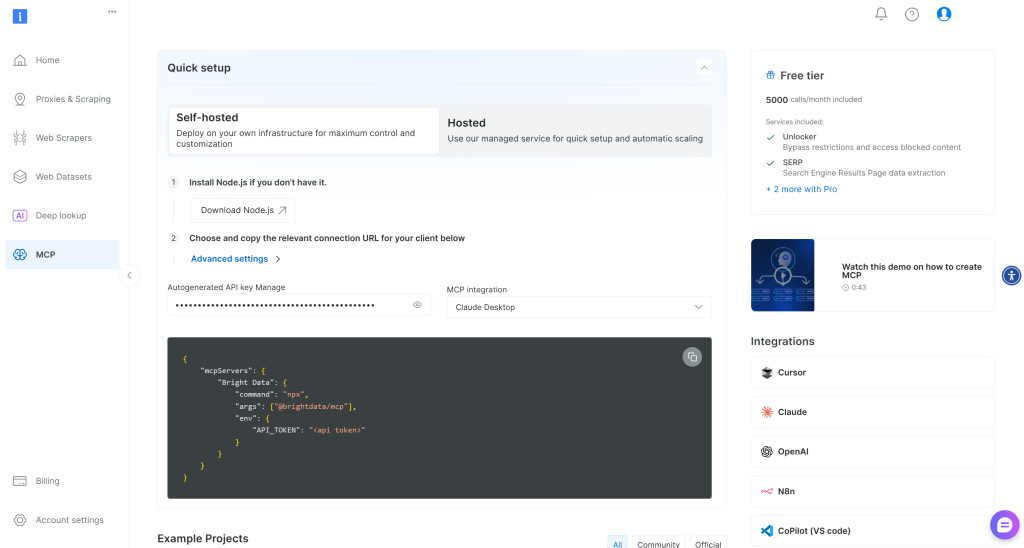
否则,请先生成一个 Bright Data API 密钥。然后将其妥善保存,稍后将用到。本节将假设该 API 密钥具有 Admin 权限,因为这能简化 Web MCP 的集成过程。
运行以下命令在系统中全局安装 Web MCP:
npm install -g @brightdata/mcp接着,通过执行以下命令检查本地 MCP 服务器是否工作正常:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp或在 Linux/macOS 上等效命令:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp将 <YOUR_BRIGHT_DATA_API> 替换为你的实际 Bright Data API 令牌。该命令会设置所需的 API_TOKEN 环境变量,并通过 @brightdata/mcp 包启动 Web MCP。
如果成功,你应看到类似如下的日志:

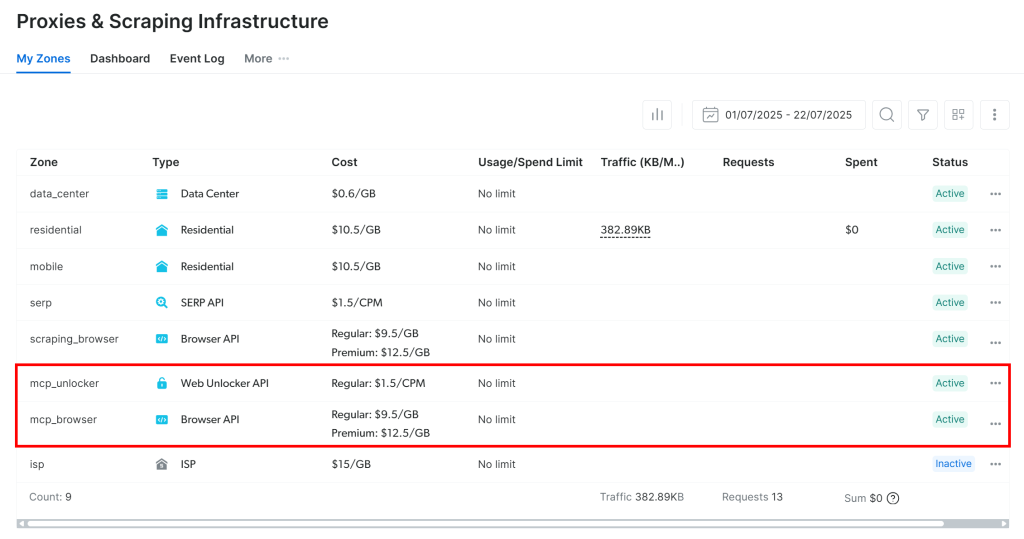
首次启动时,Web MCP 会在你的 Bright Data 账户中自动创建两个默认的 Zone:
mcp_unlocker:用于 Web Unlocker。mcp_browser:用于 Browser API。
MCP 服务器依赖这两个 Zone 来驱动全部 60+ 工具。
要确认这些 Zone 已创建,请登录 Bright Data 控制台,进入 “Proxies & Scraping Infrastructure” 页面,你应能在 Zone 列表中看到它们:
如果你的 API 令牌没有 Admin 权限,这些 Zone 将不会为你自动创建。在这种情况下,你需要在控制台中手动创建它们,并通过环境变量配置其名称(详见 GitHub 页面)。
重要:默认情况下,MCP 服务器只暴露 search_engine 与 scrape_as_markdown(及其批处理版本)这两个工具。这些工具包含在 Web MCP 免费层中。
要解锁高级工具(如浏览器自动化与结构化数据源),你需要启用 专业模式。方法是在启动 Web MCP 前设置 PRO_MODE="true" 环境变量:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcp或在 Linux/macOS 上:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp专业模式 会解锁全部 60+ 工具,但不包含在免费层内,并会产生额外费用。
成功!你刚刚验证了 Web MCP 服务器可以在你的机器上运行。先结束 MCP 进程,接下来你将配置 Semantic Kernel 代理来启动该服务器并连接到它。
步骤 4:配置 Web MCP 集成
既然你的机器可以运行 Web MCP,首先将之前获取到的 Bright Data API 密钥添加到用户机密中:
dotnet user-secrets set "BrightData:ApiKey" "<YOUR_BRIGHT_DATA_API_KEY>"将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你的实际 API 密钥。该命令会将密钥安全地存储在项目的机密存储中。
你也可以通过设置环境变量实现同样的效果:
$Env:BrightData__ApiKey="<YOUR_BRIGHT_DATA_API_KEY>"或在 macOS/Linux 上:
export BrightData__ApiKey="<YOUR_BRIGHT_DATA_API_KEY>"注意:Microsoft.Extensions.Configuration 会自动将 BrightData__ApiKey 转换为 BrightData:ApiKey。
接着,使用来自 ModelContextProtocol 包 的 McpClientFactory 来定义 MCP 客户端并连接到 Web MCP:
await using var mcpClient = await McpClientFactory.CreateAsync(new StdioClientTransport(new()
{
Name = "BrightDataWebMCP",
Command = "npx",
Arguments = ["-y", "@brightdata/mcp"],
EnvironmentVariables = new Dictionary<string, string?>
{
{ "API_TOKEN", config["BrightData:ApiKey"] },
// { "PRO_MODE", "true" }, // <-- Optional: enable Pro Mode
}
}));上述配置会生成与先前步骤相同的 npx 命令,并设置所需环境变量。注意 PRO_MODE 为可选,而 API_TOKEN 则从先前定义的 BrightData:ApiKey 机密中读取。
然后,加载所有可用的工具列表:
var tools = await mcpClient.ListToolsAsync().ConfigureAwait(false);脚本会执行 npx 命令以本地进程方式启动 Web MCP 并与其连接,从而访问其暴露的工具。
你可以通过日志打印所有工具来验证是否已成功连接到 Web MCP 且拥有对这些工具的访问权:
foreach (var tool in tools)
{
Console.WriteLine($"{tool.Name}: {tool.Description}");
}如果此时运行脚本,你应看到类似如下的输出:

这些是 Web MCP 在免费层中暴露的 2 个默认工具(加 2 个批处理版本)。在 专业模式 下,你将能访问全部 60+ 工具。
太棒了!上述输出表明 Web MCP 集成工作正常!
步骤 5:构建可访问 MCP 工具的 Kernel
在 Semantic Kernel 中,内核(kernel) 充当一个依赖注入容器,用于管理运行你的 AI 应用所需的全部服务与插件。一旦你将服务与插件提供给内核,AI 就可以在需要时调用它们。
现在是时候创建一个支持通过 MCP 调用工具的 OpenAI 集成内核了。先把你的 OpenAI API 密钥加入用户机密:
dotnet user-secrets set "OpenAI:ApiKey" "<YOUR_OPENAI_KEY>"如前所述,你也可以设置同名环境变量 OpenAI__ApiKey。
然后,定义一个连接到 OpenAI 的新内核:
var builder = Kernel.CreateBuilder();
builder.Services
.AddOpenAIChatCompletion(
modelId: "gpt-5-mini",
apiKey: config["OpenAI:ApiKey"]
);
Kernel kernel = builder.Build();在该示例中,内核使用存储在用户机密中的 API 密钥连接到 gpt-5-mini 模型(你也可以配置为其他任意 OpenAI 模型)。
随后,为内核添加一个用于调用工具的插件:
kernel.Plugins.AddFromFunctions("BrightData", tools.Select(aiFunction => aiFunction.AsKernelFunction()));这行代码会将你的 MCP 工具转换为内核可调用的函数,从而由指定的 AI 模型调用。
本节所需的导入如下:
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;完美!现在你已经拥有一个完全配置好的内核,它是你的 Semantic Kernel AI 应用的核心。
步骤 6:定义 AI 代理
先从 SemanticKernel 导入 Agents 类:
using Microsoft.SemanticKernel.Agents;接着,使用内核初始化一个自动调用工具的 AI 代理:
var executionSettings = new OpenAIPromptExecutionSettings()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto() // Enable automatic function calling for the LLM
};
var agent = new ChatCompletionAgent()
{
Name = "RedditAgent",
Kernel = kernel,
Arguments = new KernelArguments(executionSettings),
};本质上,这个代理可以在 AI 模型判断需要一个或多个工具来完成输入提示描述的目标时,执行 Bright Data Web MCP 暴露的工具。
注意我们将该代理命名为 “RedditAgent”,因为本教程聚焦于构建一个面向 Reddit 的代理。如果你要为其他目的创建 Semantic Kernel AI 代理,请根据项目需要调整名称。
很好!下一步就是使用该代理执行一个提示。
步骤 7:在代理中执行任务
要测试由 Bright Data Web MCP 提供工具增强后的 AI 代理的网页数据检索能力,你需要一个合适的提示。例如,你可以让 AI 代理从特定 subreddit 检索信息,如下:
var prompt = @"
Scrape pages from the following subreddit:
https://www.reddit.com/r/webscraping/
From the scraped content, generate a Markdown report that includes:
- The official description of the subreddit and key stats (community type, creation date)
- A list of URLs for the ~10 most recent posts
";这是一个用于测试网页检索能力的理想任务。标准的 OpenAI 模型在面对这样的提示时会失败,因为它们无法以编程方式访问 Reddit 页面以获取实时数据:

注意:上述输出并不可靠,其中大多数内容要么是错误的,要么完全是捏造的。没有像 Bright Data 这类外部工具的帮助,OpenAI 模型无法可靠地从网络抓取最新数据。
得益于 Web MCP 提供的工具,你的代理将能够检索所需的 Reddit 数据,并呈现准确的结果。使用以下代码执行任务并在终端打印结果:
ChatMessageContent response = await agent.InvokeAsync(prompt).FirstAsync();
Console.WriteLine($"\n\nResponse:\n{response.Content}");这已经足以测试单个提示。在真实场景中,你通常希望让代理持续运行并具备上下文感知能力,可通过实现带有记忆的 REPL 循环来跟踪历史交互。
大功告成!你基于 Semantic Kernel 并集成 Bright Data Web MCP 的 Reddit 专家型 AI 代理现已可以正常工作。
步骤 8:整体整合
Program.cs 中的最终代码如下:
using Microsoft.Extensions.Configuration;
using ModelContextProtocol.Client;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Microsoft.SemanticKernel.Agents;
// Load user secrets and environment variables for API keys
var config = new ConfigurationBuilder()
.AddUserSecrets<Program>()
.AddEnvironmentVariables()
.Build();
// Create an MCP client for the Bright Data Web MCP server
await using var mcpClient = await McpClientFactory.CreateAsync(new StdioClientTransport(new()
{
Name = "BrightDataWebMCP",
Command = "npx",
Arguments = ["-y", "@brightdata/mcp"],
EnvironmentVariables = new Dictionary<string, string?>
{
{ "API_TOKEN", config["BrightData:ApiKey"] },
// { "PRO_MODE", "true" }, // <-- Optional: enable Pro Mode
}
}));
// Retrieve the list of tools available on the Bright Data Web MCP server
var tools = await mcpClient.ListToolsAsync().ConfigureAwait(false);
// Build a Semantic Kernel and register the MCP tools as kernel functions
var builder = Kernel.CreateBuilder();
builder.Services
.AddOpenAIChatCompletion(
modelId: "gpt-5-mini",
apiKey: config["OpenAI:ApiKey"]
);
Kernel kernel = builder.Build();
// Create a plugin from the MCP tools and add it to the kernel's plugin collection
kernel.Plugins.AddFromFunctions("BrightData", tools.Select(aiFunction => aiFunction.AsKernelFunction()));
// Enable automatic function calling for the LLM
var executionSettings = new OpenAIPromptExecutionSettings()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Define the AI agent with MCP integration
var agent = new ChatCompletionAgent()
{
Name = "RedditAgent",
Kernel = kernel,
Arguments = new KernelArguments(executionSettings), // Pass settings for MCP tool calls
};
// Test the AI agent with a subreddit scraping prompt
var prompt = @"
Scrape pages from the following subreddit:
https://www.reddit.com/r/webscraping/
From the scraped content, generate a Markdown report that includes:
- The official description of the subreddit and key stats (community type, creation date)
- A list of URLs for the ~10 most recent posts
";
ChatMessageContent response = await agent.InvokeAsync(prompt).FirstAsync();
Console.WriteLine($"\n\nResponse:\n{response.Content}");哇!仅用大约 65 行 C# 代码,你就构建了一个集成 Bright Data Web MCP 的 Semantic Kernel AI 代理。
通过以下命令运行你的代理:
dotnet run输出应类似如下:
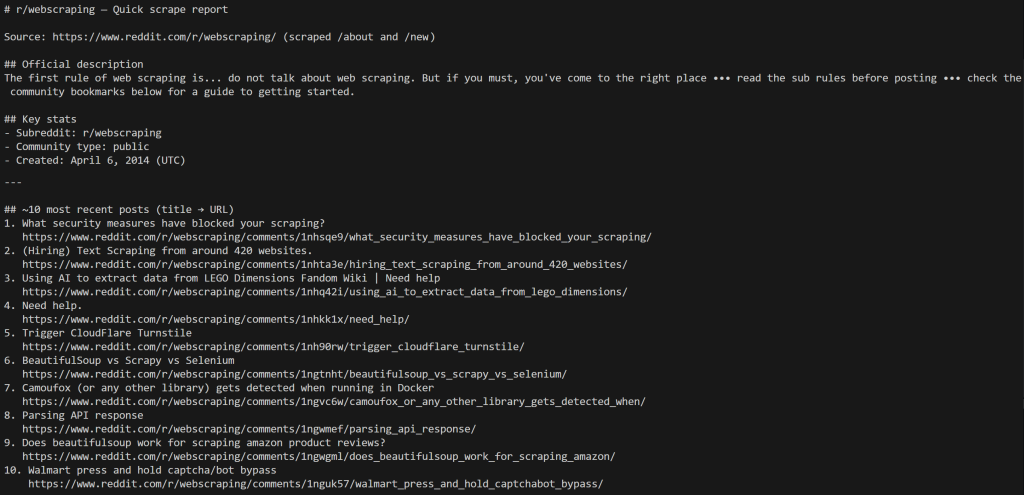
注意代理如何抓取 /about 页面以获取 subreddit 信息,然后抓取 /new 页面以获取最新帖子。
输出中显示的所有数据都是准确的,你可以访问该 subreddit 的 /about 页面进行验证:
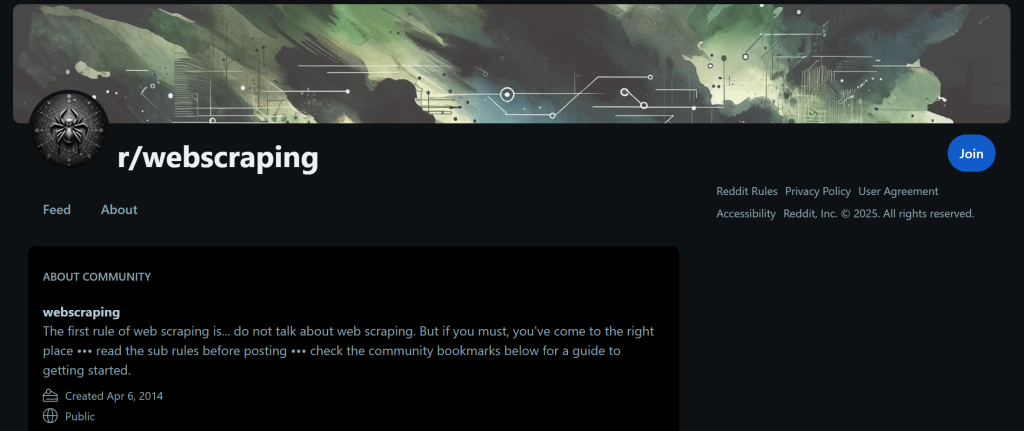
AI 代理输出中的数据与该页面显示完全一致。对最新帖子同样适用,你可以在该 subreddit 的 /new 页面找到它们。
唯一的差异在于帖子顺序,其由 Reddit 的前端决定,这里无需关心。
抓取 Reddit 具有挑战性,因为其由反机器人系统保护,会阻断自动化请求。借助 Bright Data Web MCP 服务器提供的具备反机器人绕过能力的网页抓取功能,你的 AI 代理可以使用强大的网页数据检索、交互与搜索工具集。
此示例仅展示了诸多可能场景中的一个。通过 Semantic Kernel 获取的广泛 Bright Data 工具,你可以构建更复杂的代理,覆盖更多用例。
大功告成!你已经在 C# 的 Semantic Kernel AI 代理中体验了 Bright Data Web MCP 集成的强大能力。
结论
在这篇博文中,你看到了如何将使用 Semantic Kernel 构建的 AI 代理连接到 Bright Data 的 Web MCP(现已提供免费套餐!)。这种集成为你的代理带来更强的能力,包括网页搜索、数据提取以及实时交互。
若要构建更高级的 AI 代理,欢迎探索更广泛的产品与服务——Bright Data 的 AI 基础设施。这些工具旨在为多样化的 AI 工作流和代理型用例提供动力。
立即注册免费的 Bright Data 账户,开始体验面向 AI 的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


