

在本指南中,你将了解:
- 将网站抓取为 Markdown 的含义,以及为什么这样做很有用。
- 将网页 HTML 转换为 Markdown 的主要方法(适用于静态和动态站点)。
- 如何使用 Python 将网页抓取为 Markdown。
- 此方案的局限性,以及如何通过 Bright Data 来克服这些问题。
我们开始吧!
“将网站抓取为 Markdown”是什么意思?
“将网站抓取为 Markdown”指的是将其内容转换为 Markdown。
更具体地说,就是获取网页的 HTML,并将其转换为 Markdown 数据格式。
例如,连接到某个站点,打开开发者工具(DevTools),复制其 HTML:
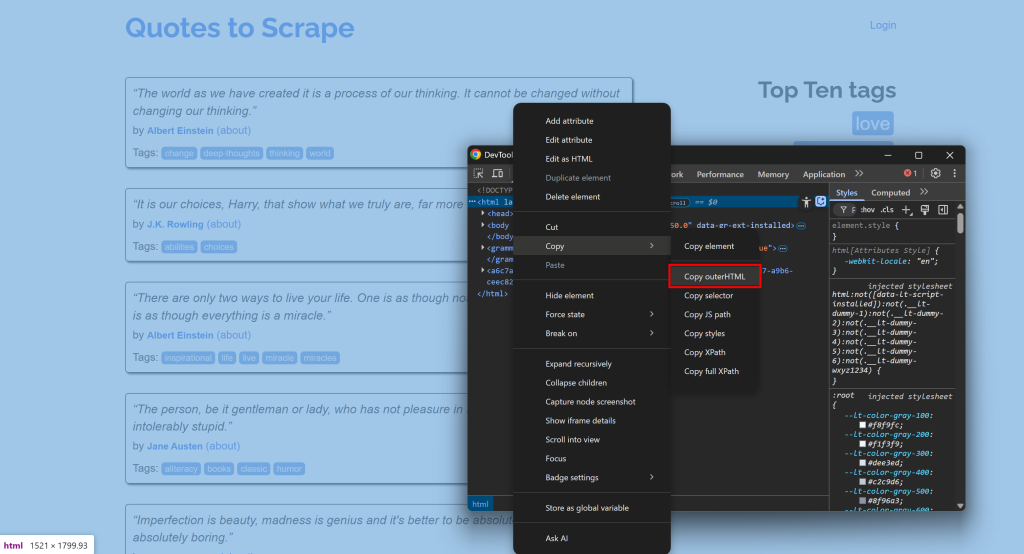
然后将其粘贴到一个HTML 转 Markdown 转换器中:
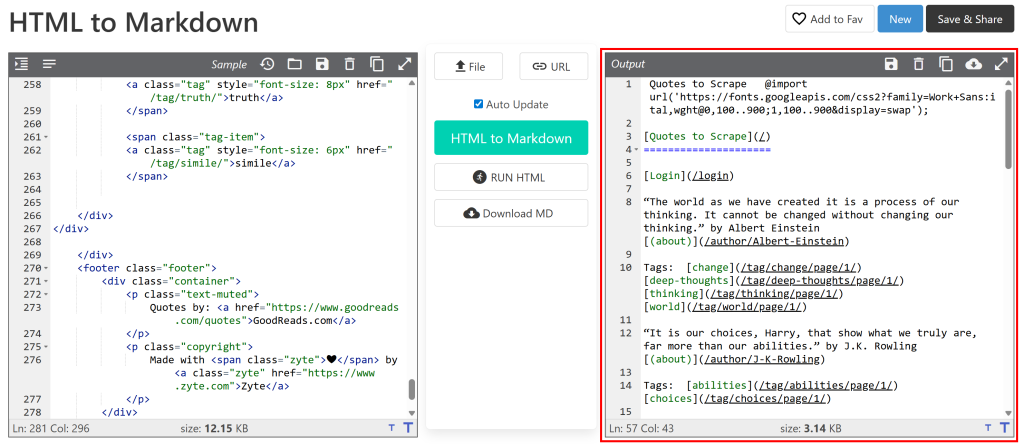
输出将与您希望通过网络爬取获得的 Markdown 文档类似。现在我们的目标是将这一过程自动化,而这正是本文要讲解的内容!
[加餐] 为什么选择 Markdown?
为什么用 Markdown 而不是其他格式(如纯文本)?因为正如我们的数据格式基准测试所示,Markdown 是最适合大模型摄取的格式之一。主要有三点原因:
- 它能保留页面的大多数结构与信息(如链接、图片、标题等)。
- 它足够简洁,能降低 token 消耗并加快 AI 处理速度。
- 相比于原始 HTML,LLM 往往更容易理解 Markdown。
这也是最佳 AI 抓取工具默认使用 Markdown 的原因。
HTML 转 Markdown 的方法
你已经知道,将网站抓取为 Markdown 本质上就是把页面的 HTML 转换成 Markdown。从高层来看,流程如下:
- 连接目标站点。
- 以字符串形式获取 HTML。
- 使用 HTML 转 Markdown 库生成 Markdown 输出。
挑战在于,并非所有网页的内容传递方式都相同。前两步会因目标页面是静态还是动态而有较大差异。下面通过扩展必要步骤来说明如何处理这两种场景!
步骤一:连接到站点
在静态网页上,服务器返回的 HTML 文档就是你在浏览器中看到的内容。换句话说,一切都是固定的,并嵌入在服务器生成的 HTML 中。
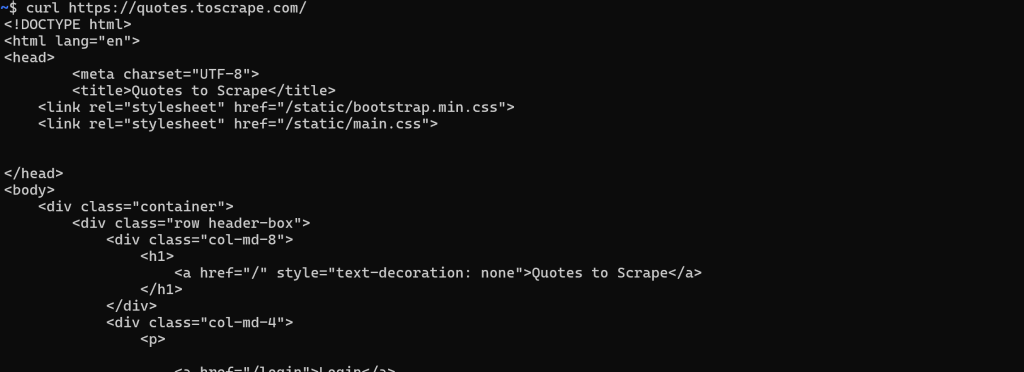
此时,获取 HTML 非常简单。你只需对页面 URL 执行一次GET HTTP 请求,使用任何 HTTP 客户端即可:
相比之下,在动态网站上,大部分(或部分)内容会通过AJAX 获取,并由 JavaScript 在浏览器中渲染。这意味着,Web 服务器最初返回的 HTML 文档仅包含最基本的结构。只有当客户端执行完 JavaScript 后,页面才会被填充为完整内容:

在这种情况下,你不能仅通过简单的 HTTP 客户端抓取 HTML。你需要能真正渲染页面的工具,比如浏览器自动化工具。Playwright、Puppeteer 或 Selenium 等方案可以让你以编程方式控制浏览器,加载目标页面并获取其完整渲染后的 HTML。
步骤二:以字符串形式获取 HTML
对于静态网页,这一步非常直接。Web 服务器对你的 GET 请求返回的响应已经包含整个 HTML 文档的字符串。大多数 HTTP 客户端(如 Python 的 Requests)都提供了可直接访问它的方法或字段:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Access the HTML content of the page as a string
html = response.text对于动态网站,事情要棘手得多。这一次,你并不关心服务器返回的原始 HTML 文档。相反,你需要等待浏览器渲染页面、DOM 稳定,然后再访问最终的 HTML。
这类似于你手动打开开发者工具并从 <html> 节点复制 HTML 的操作:
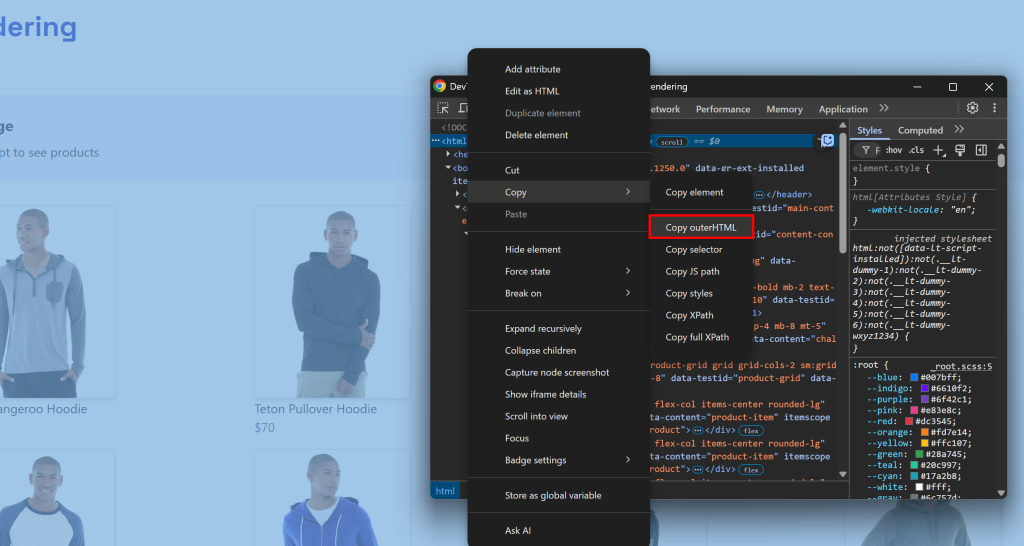
难点在于如何判断页面已完成渲染。常见策略包括:
- 等待
DOMContentLoaded事件:当初始 HTML 被解析且延迟加载的<script>已加载并执行后触发。Playwright 默认采用此策略。 - 等待
load事件:当整个页面(包括样式表、脚本、iframe 和图片(懒加载除外))加载完成时触发。 - 等待
networkidle事件:当一定时间内(例如在 Playwright 中为500ms)没有网络请求时,认为渲染完成。对实时更新内容的网站不可靠,因为该事件可能永远不会触发。 - 等待特定元素:使用浏览器自动化框架提供的自定义等待 API,直到某些元素出现在 DOM 中。
一旦页面完全渲染,你可以使用浏览器自动化工具提供的特定方法/字段提取 HTML。例如,在 Playwright 中:
html = await page.content()步骤三:使用 HTML 转 Markdown 库生成 Markdown 输出
当你已将 HTML 作为字符串获取后,只需将其传给众多 HTML 转 Markdown 库之一即可。较为流行的有:
| 库 | 编程语言 | GitHub Star 数 |
|---|---|---|
markdownify |
Python | 1.8k+ |
turndown |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-to-markdown |
Go | 3k+ |
html-to-markdown |
PHP | 1.8k+ |
将网站抓取为 Markdown:实用 Python 示例
本节将展示完整的 Python 代码片段,用于将网站抓取为 Markdown。以下脚本实现了前文讲解的步骤。你也可以轻松将其转换为 JavaScript 或其他编程语言。
输入为网页的 URL,输出为对应的 Markdown 内容!
静态站点
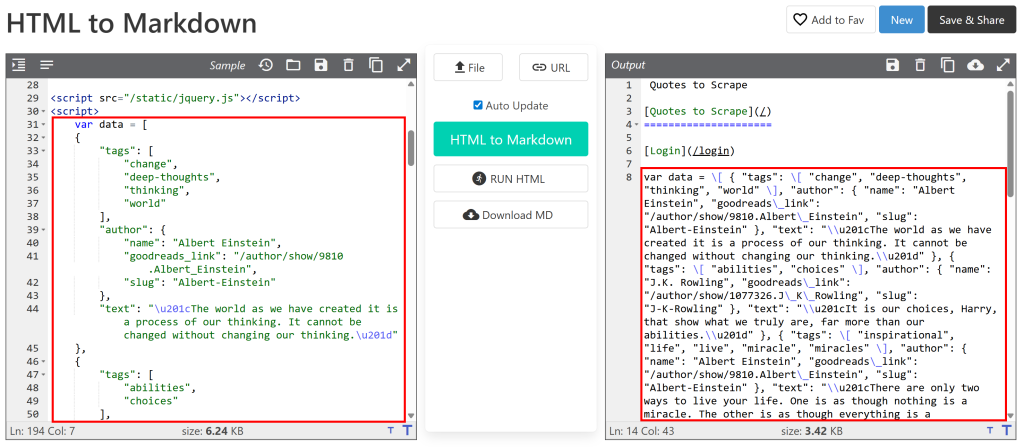
在本例中,我们将使用以下两个库:
requests:用于发起 GET 请求并以字符串形式获取页面 HTML。markdownify:用于将页面 HTML 转换为 Markdown。
使用以下命令安装:
pip install requests markdownify目标页面为静态的“Quotes to Scrape”。使用以下代码即可实现目标:
import requests
from markdownify import markdownify as md
# The URL of the page to scrape
url = "http://quotes.toscrape.com/"
# Retrieve the HTML content using requests
response = requests.get(url)
# Get the HTML as a string
html_content = response.text
# Convert the HTML content to Markdown
markdown_content = md(html_content)
# Print the Markdown output
print(markdown_content)可选:你可以将内容导出到 .md 文件:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)脚本的结果如下所示:
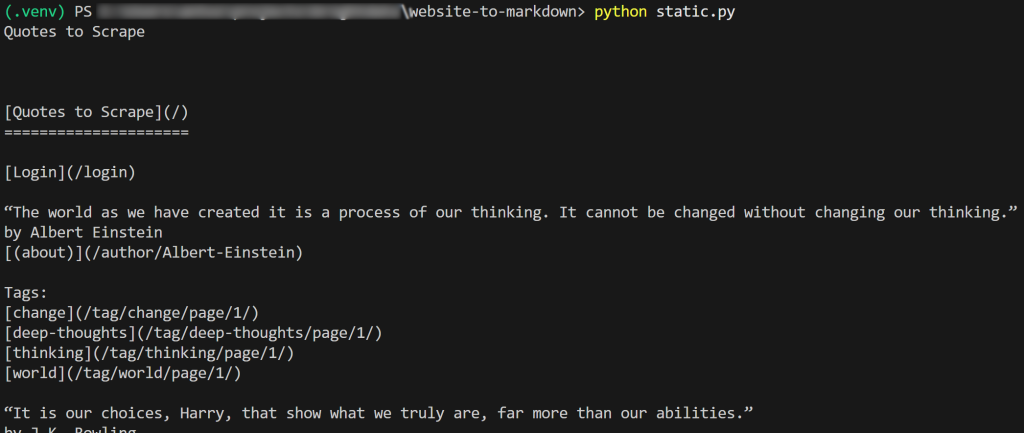
如果你将输出的 Markdown 复制并粘贴到 Markdown 渲染器中,将会看到:
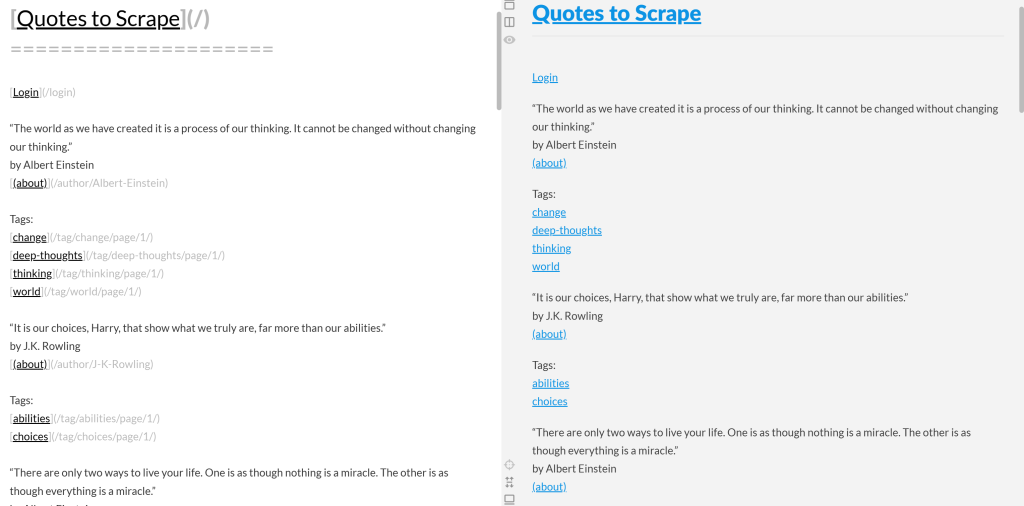
可以看到,它看起来像“Quotes to Scrape”页面原始内容的简化版本:
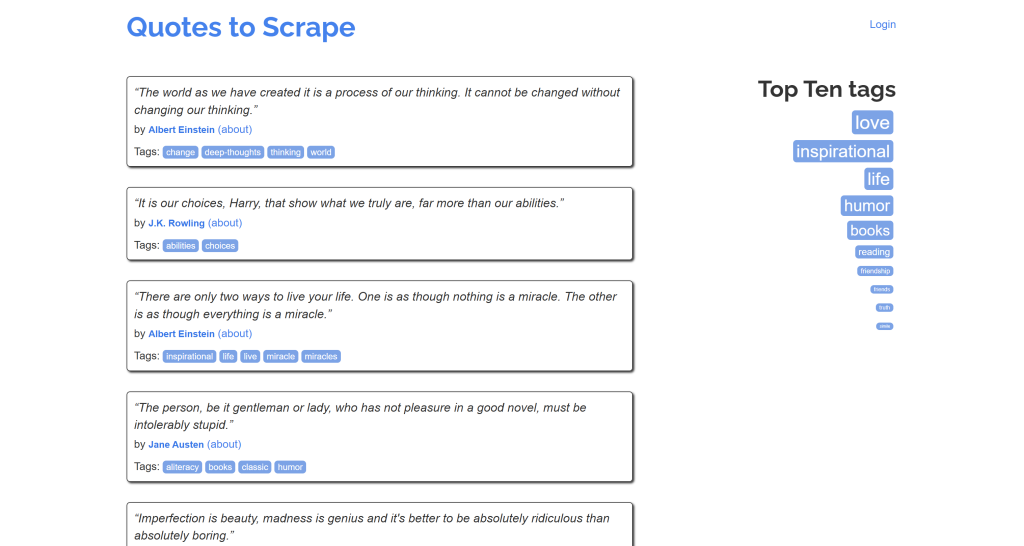
任务完成!
动态站点
这里我们将使用以下两个库:
playwright:在受控的浏览器实例中渲染目标页面。markdownify:将页面渲染后的 DOM 转换为 Markdown。
用以下命令安装上述依赖:
pip install playwright markdownifypython -m playwright install本例的目标是 ScrapingCourse.com 上的动态页面“JavaScript Rendering”:
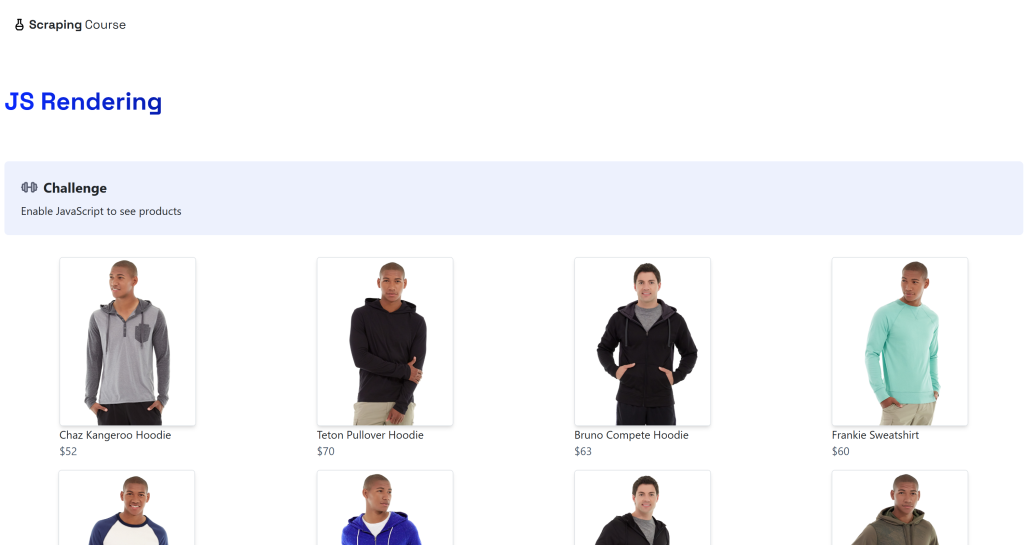
该页面通过 AJAX 在客户端获取数据,并使用 JavaScript 进行渲染:
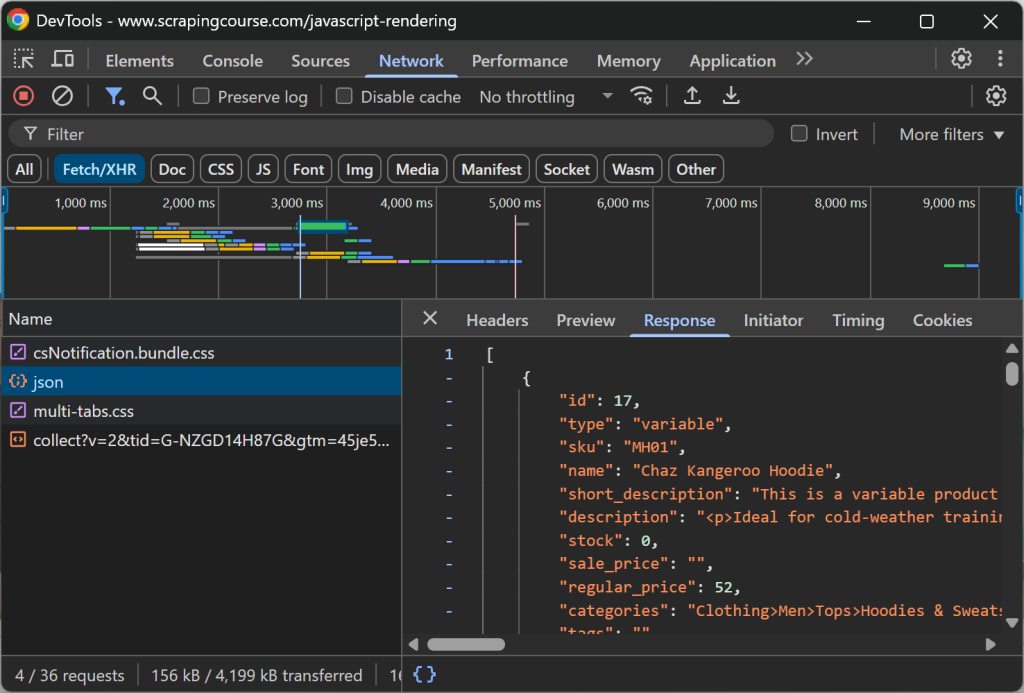
按如下方式将动态网站抓取为 Markdown:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Launch a headless browser
browser = p.chromium.launch()
page = browser.new_page()
# URL of the dynamic page
url = "https://scrapingcourse.com/javascript-rendering"
# Navigate to the page
page.goto(url)
# Wait up to 5 seconds for the first product link element to be filled out
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Get the fully rendered HTML
rendered_html = page.content()
# Convert HTML to Markdown
markdown_content = md(rendered_html)
# Print the resulting Markdown
print(markdown_content)
# Close the browser and release its resources
browser.close()在上述代码中,我们选择了第 4 种方式(“等待特定元素”),因为它最可靠。具体来说,请看这行代码:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)它会最多等待 5000 毫秒(5 秒),直到 .product-link 元素(一个 <a> 标签)拥有非空的 href 属性。这足以表明页面上的第一个产品元素已被渲染,意味着数据已获取且 DOM 现在稳定。
结果如下:
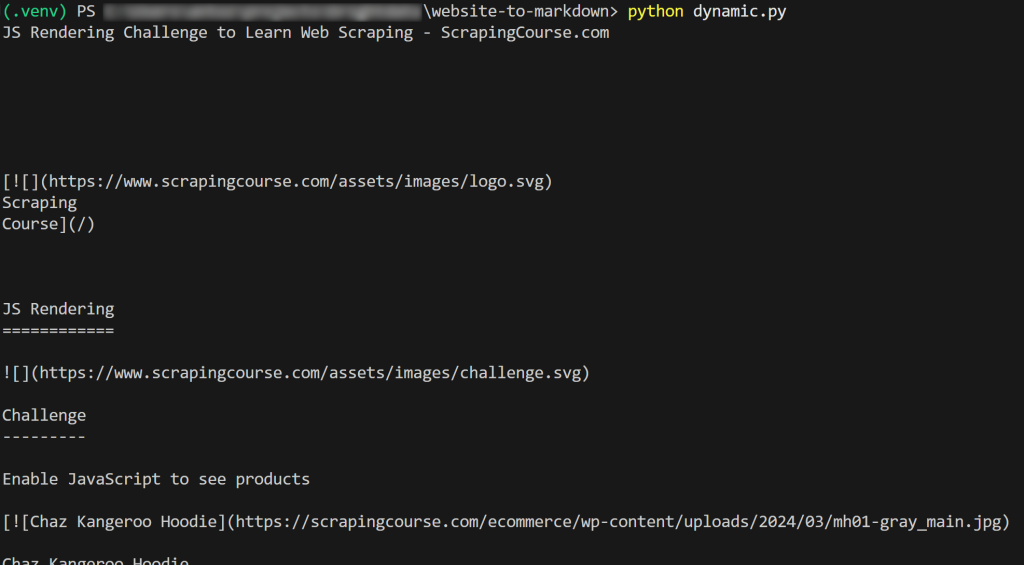
大功告成!你刚刚学会了如何将网站抓取为 Markdown。
这些方法的局限性与解决方案
本文中的所有示例有一个共同点:它们针对的页面都很容易被抓取!
不幸的是,大多数真实世界的网页并不会对爬虫如此“友好”。恰恰相反,许多站点会实施反爬措施,如 CAPTCHA、人机验证、IP 封禁、浏览器指纹等。
换句话说,你不能指望一个简单的 HTTP 请求或 Playwright 的 goto() 指令就能按预期工作。针对大多数真实网站时,你可能会遇到403 Forbidden 错误:

或错误/人机验证页面:
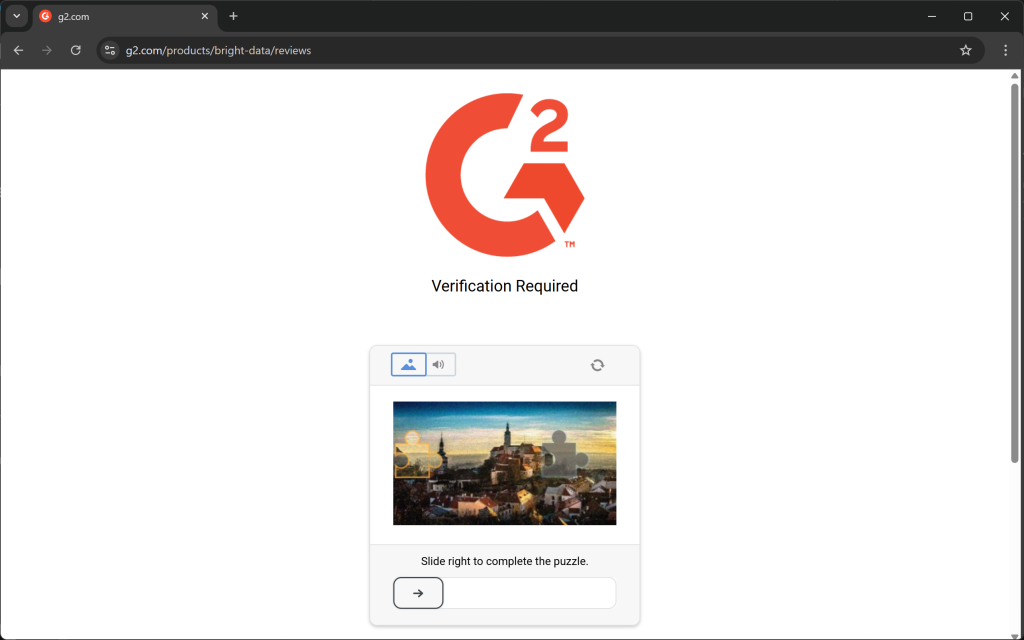
另一个关键点是,大多数 HTML 转 Markdown 库执行的是原始数据转换。这可能导致不理想的结果。例如,如果页面包含直接嵌入在 HTML 中的 <style> 或 <script> 元素,它们的内容(即 CSS 和 JavaScript 代码)会被包含在 Markdown 输出中:
通常这并不是我们想要的,尤其当你计划将 Markdown 提供给 LLM 进行数据处理时。这些文本元素只会增加噪音。
解决方案?使用专门的 Web Unlocker API,无论站点的保护措施如何,都能访问任意网站,并直接产出适合 LLM 的 Markdown。这可以确保提取的内容干净、结构化,并能直接用于后续的 AI 任务。
使用 Web Unlocker 抓取为 Markdown
Bright Data 的 Web Unlocker 是一款云端 Web 抓取 API,能够返回任意网页的 HTML。无论是否存在反爬/反机器人保护,也无论页面是静态还是动态,这都成立。
该 API 由一个超过 1.5 亿 IP 的代理网络提供支持,你只需专注于数据采集,Bright Data 会为你处理完整的解封基础设施、JavaScript 渲染、CAPTCHA 解决、扩展与维护更新等。
使用非常简单。向 Web Unlocker 发送带有正确参数的 POST HTTP 请求,你就会得到已解封的完整网页。你还可以将 API 配置为返回为经过 LLM 优化的 Markdown 格式。
按照初始设置指南操作,然后仅用几行代码即可使用 Web Unlocker 将网站抓取为 Markdown:
# pip install requests
import requests
# Replace these with the right values from your Bright Data account
BRIGHT_DATA_API_KEY= "<YOUR_BRIGHT_DATA_API_KEY>"
WEB_UNLOCKER_ZONE = "<YOUR_WEB_UNLOCKER_ZONE_NAME>"
# Replace with your target URL
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Prepare the required headers
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # For authentication
"Content-Type": "application/json"
}
# Prepare the Web Unlocker POST payload
payload = {
"url": url_to_scrape,
"zone": WEB_UNLOCKER_ZONE,
"format": "raw",
"data_format": "markdown" # To get the response as Markdown content
}
# Make a POST request to Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
# Get the Markdown response and print it
markdown_content = response.text
print(markdown_content)
# 获取 Markdown 响应并打印
markdown_content = response.text
print(markdown_content)执行脚本后,你会得到:
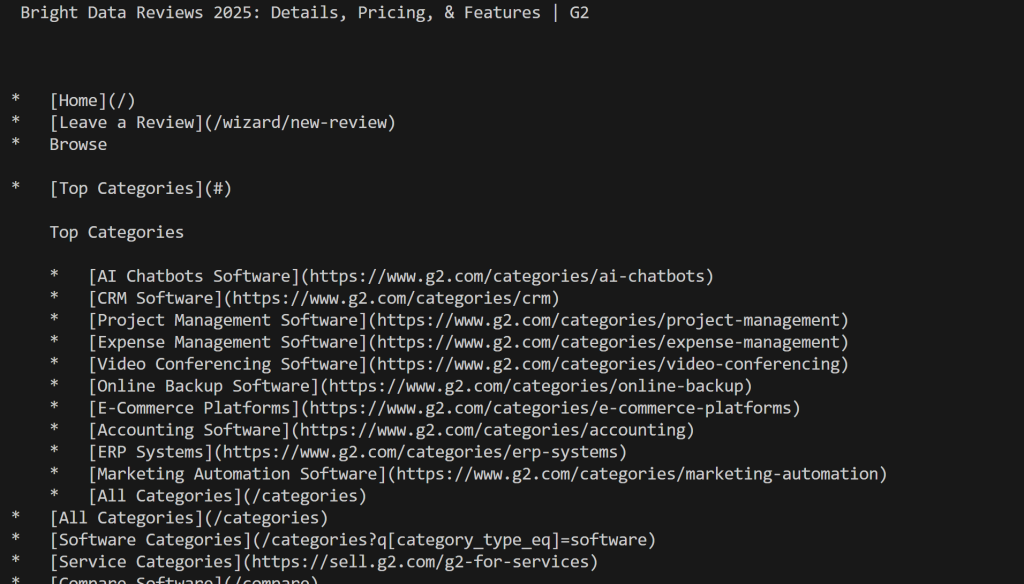
请注意,这一次你没有被 G2 屏蔽,而是如愿获得了真正的 Markdown 内容。
完美!将网站转换为 Markdown 从未如此简单。
注意:该方案已通过75+ 种与 AI 代理工具的集成(如 CrawlAI、Agno、LlamaIndex、LangChain 等)提供。此外,你也可以通过 Bright Data Web MCP 服务器上的 scrape_as_markdown 工具直接使用。
结论
在本文中,你了解了为什么以及如何将网页转换为 Markdown。正如所讨论的,由于反爬保护以及 Markdown 结果可能不理想等挑战,HTML 转 Markdown 并不总是那么简单。
Bright Data 为你提供了Web Unlocker,这是一款云端 Web 抓取 API,能够将任何网页转换为经过 LLM 优化的 Markdown。你可以手动调用该 API,或将其直接集成到各类 AI 代理构建方案中,或通过 Web MCP 集成使用。
请记住,Web Unlocker 只是 Bright Data AI 基础设施中众多 Web 数据与抓取工具之一。
立即注册免费 Bright Data 账户,开始探索我们的面向 AI 的 Web 数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




