
网页爬虫工具会以三种方式失败:由于 JavaScript 渲染页面导致 HTML 为空、前端更新后 CSS 选择器不再匹配,以及请求被 Cloudflare 等反爬产品阻止。Scrapling 是一个开源 Python 库,能够处理这三种情况。本指南在真实网站上展示每个部分,以及在生产规模下何时需要托管代理服务。
TL;DR
Scrapling 将三种 fetcher 类(HTTP、Chromium、隐身 Firefox)、一个在类名重命名后重新定位元素的自适应解析器,以及一个类似 Scrapy 的 spider 集成在一个用于生产抓取的 Python 库中。
- 选择能工作的最便宜 fetcher;对受机器人保护的网站升级到 StealthyFetcher。
- 如果你先对一个已知正常的页面做指纹,自适应选择器可以从标记变更中恢复。
- 对于生产环境,将解析逻辑封装在带检查点和空结果告警的 Spider 中。
- 当本地隐身手段耗尽(IP 信誉、企业级反爬产品)时,切换到住宅代理或托管解锁端点。
为什么选择 Scrapling,而 requests + BS4 已经存在?
requests 与 BeautifulSoup 的组合仍然适用于标记稳定的静态页面。问题在于,一旦你部署了必须持续工作的爬虫工具,麻烦就开始了。
当一个前端团队重命名或重构元素时,选择器会停止匹配。本季度页面服务端渲染,下季度又变成客户端渲染。一个你抓取了一年的网站突然加入 Cloudflare Bot Management,每个请求都返回挑战页面。
这些都不是罕见问题,但每一个都需要各自的修复方式。把这些修复组合进一个 requests 脚本,往往会变成一堆脆弱的 try/except 块和选择器回退。(对于低量任务且选择器不断变化的情况,对渲染后的 HTML 进行一次 LLM 抽取现在是可行的替代方案。当单页成本很重要且你在规模化渲染时,Scrapling 值得其配置成本。)
Scrapling 将常见修复整合进一个库中:
- 三种 fetcher,一个 API。 一个带 TLS 指纹伪装的快速 HTTP 客户端(Fetcher)、一个由 Playwright 驱动的浏览器(DynamicFetcher),以及一个基于 Camoufox 的隐身浏览器——这是一个打过补丁的 Firefox 构建,用于掩盖常见自动化信号(StealthyFetcher)。它们都返回同一个解析器对象,因此切换 fetcher 不意味着重写你的选择器代码。
- 能在标记变更后仍然生存的选择器。 首次运行时保存元素的结构指纹,后续运行中即使 class、ID 或位置发生变化,Scrapling 也能定位到同一元素。
- 内置 Spider 框架。 并发请求、按域限速、暂停与恢复、robots.txt 遵从,以及 JSON/JSONL 导出,全部内置。
- 内置代理轮换。 一个 ProxyRotator 辅助工具与所有会话类型集成,并支持按请求覆盖。
三种 fetcher 对应三种难度级别,因此一旦你检查目标,通常很容易决定使用哪一个:
| 如果页面是… | 使用这个 fetcher | 单请求成本(时间、内存) |
|---|---|---|
| 静态 HTML,无反爬 | Fetcher | 毫秒级,无浏览器 |
| JavaScript 渲染,无反爬 | DynamicFetcher | 秒级,Chromium 内存 |
| 在 Cloudflare 或类似反爬之后 | StealthyFetcher | 秒级,Camoufox 内存 |
Scrapling 的解析器速度大致与 Parsel 和 lxml 相同,并且在大文档上比 BeautifulSoup 更快。对于一个 5,000 元素的文档,官方基准 显示其约为 2 ms,而 bs4 + lxml 超过 1.5 秒。小规模时可能无关紧要,但当你每月解析数百万页面时就会累积起来。
在选择任何抓取库之前,先快速检查:目标是否提供官方 API、RSS 或 Atom feed、sitemap、JSON-LD 嵌入,或公开数据 dump?当这些存在时,API 调用通常比抓取更快更便宜。抓取是正确答案的情况包括:没有 API、API 付费墙或限速超出用例可承受范围,或你需要的数据未通过 API 暴露。
Scrapling 并不适用于所有场景:
- 在分布式集群规模下,Scrapy 集群和框架特定的分布式运行器扩展性更好。
- 对于等同 curl 的抓取,如果 requests 和 5 行 BeautifulSoup 选择器已经能处理,就用它们。
- 当你需要一个无需写代码的托管抓取工具,无代码平台更合适。
最强的适配场景是必须周复一周持续工作的生产爬虫:复杂度足以让维护变得重要,但又不至于需要一个集群。
Scrapling 采用 BSD-3 许可;本指南基于 v0.4.7(2026 年 4 月)验证。指南中使用的 API 名称是稳定的;如果你的默认值不同,请查看更新版本的 changelog。类型提示覆盖公共 API,这在你将响应通过类型化流水线传递时很重要。
安装 Scrapling
fetcher 依赖是显式选择加入,因此你不会在只需要解析器的机器上安装 Playwright 和 Camoufox。使用 fetcher extras 和浏览器二进制文件进行安装:
# pip
pip install "scrapling[fetchers]"
# or with uv (faster, lockfile-aware)
uv pip install "scrapling[fetchers]"
scrapling install第一个命令安装库以及 HTTP 和浏览器 fetcher。第二个命令下载浏览器二进制文件(StealthyFetcher 的 Camoufox、DynamicFetcher 的 Chromium)以及它们所需的系统依赖。在 Windows 上,首次运行时以管理员身份运行终端,以便二进制文件可以在系统范围内安装。
验证是否全部干净安装:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])一个正常的安装会打印 200 和一个 Chrome 风格的 User-Agent 字符串。如果 User-Agent 看起来像 python-requests/x.x,则你运行的是仅解析器版本;请使用 [fetchers] extra 重新安装,以便 pip 同时安装 curl_cffi(为 Fetcher 提供 TLS 伪装的库)。
另外两个 extra 也值得了解:
- scrapling[shell] 添加一个交互式 IPython shell(scrapling shell)、一个 curl-to-Scrapling 转换器,以及一个 scrapling extract CLI,用一行从终端抓取内容。例如,scrapling extract get https://example.com out.md 会将页面(或其 CSS 选择器子集)写为 Markdown。
- scrapling[all] 安装所有内容,包括用于 AI-agent 集成的 MCP(Model Context Protocol)服务器;请参阅项目文档。
scrapling[fetchers] 覆盖下面的每个示例。
你的第一次抓取:从静态页面提取引言
标准沙盒是 quotes.toscrape.com,它以纯服务端渲染 HTML 每页展示十条引言。没有 JavaScript、没有反爬、也没有限速,因此它是 Fetcher 路径的良好首测:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get() 返回一个 Response 对象,它也充当解析器句柄。设置 stealthy_headers=True 会让 Scrapling 发送真实的浏览器头,包括 User-Agent、Accept、Accept-Language 和 sec-ch-ua,而不是默认的 python-requests 头集合。在沙盒上不必要,但生产站点通常会根据头一致性进行过滤。
page.css(‘.quote’) 返回一个包含所有匹配元素的 Selectors 容器。::text 伪元素是 Scrapy/Parsel 的约定,它直接提取文本节点而不是周围的标签。
输出如下所示:
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...如果你以前用过 Scrapy,这个 API 是刻意保持熟悉的。如果你用过 BeautifulSoup,Scrapling 也有 find_all 和 find_by_text:
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)抓取真实目标:Hacker News 首页
沙盒网站只是练习。同样的代码结构也适用于真实目标,只需两处变化:选择器来自检查实际标记,且数据需要更多清洗。Hacker News 是一个有用的首个真实目标(HTML 稳定、无反爬),其布局有一个值得了解的不寻常结构:每条故事是一行 **,而元数据(points、user、age)在紧随其后的兄弟行。爬虫工具如下:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# Metadata lives on the next sibling row
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")该片段使用了三个沙盒示例未展示的模式:
- athing.next 导航到下一个兄弟元素,当结构相关的行共享数据时很有用(旧式基于表格的标记中常见)。
- .attrib.get(‘id’) 在没有方便的 ::attr() 快捷方式时读取原始 HTML 属性。
- or ‘0 points’ 默认值覆盖招聘帖,它们在 Hacker News 首页出现时没有分数。
真实目标几乎总有这些小不规则性(缺失字段、混合条目类型、偶尔的畸形行)。调整选择器并添加小的默认值;代码结构保持不变。
使用 find_similar 编写无需选择器的爬虫工具
有时你甚至不需要写行选择器。从可见文本开始,向上移动到正确容器,然后让 Scrapling 找到每个结构相似的元素:
sample = page.find_by_text("1.") # the rank label on story #1
row = sample.find_ancestor(lambda e: e.tag == "tr") # walk up to the story row
peers = row.find_similar() # find every similar row
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")在实时首页上,这会打印 30(每个故事行,通过与我们起始行的结构相似性定位)。find_similar 接受可选的 similarity_threshold(默认 0.2;值越低表示结构匹配越严格)以及一个 ignore_attributes 列表(默认 href 和 src),这样 URL 差异不会阻止匹配。对于标记变化快到你无法维护选择器的网站,将 find_by_text 与 find_similar 结合,比追逐 class 名更稳。
提取表格:来自 Wikipedia 的国家数据
表格是另一种常见的真实世界数据形式:财务数字、体育统计、参考列表。Wikipedia 将其数据表格放在单一的 table.wikitable class 下,这在整个百科中是一致的,因此同样的选择器模式几乎到处可用。国家人口抓取:
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # skip header and grouping rows
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")这里有两个模式很重要。cells[0].css(‘a::attr(title)’).get() 从链接的 title 属性中提取国家名称,这比 .text 更干净,因为它跳过了同一单元格中的旗帜图标杂项。if len(cells) < 3 守卫跳过了几乎所有第三方 HTML 表格中都会出现的不规则表头与分组行。
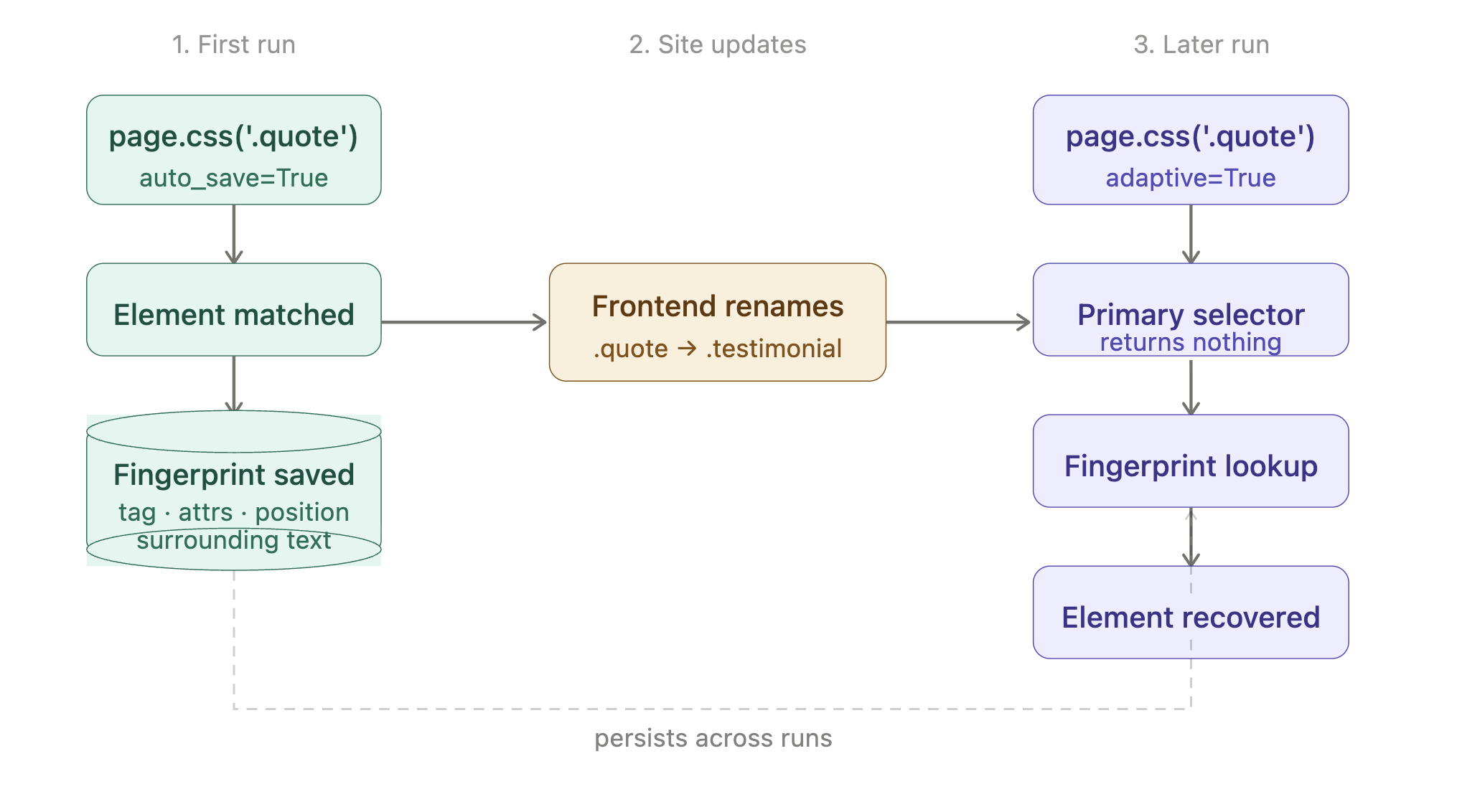
能在站点变更后仍然生存的选择器
一个站点把 class 从 .product-card 重命名为 .product-tile。你的爬虫工具开始返回空结果。你直到流水线后续步骤报告缺失数据才注意到。
Scrapling 的答案是一个配置选项加两个标志。每个只做一件事:
| 你写什么 | 你何时写 | 它做什么 |
|---|---|---|
| 在 fetcher 调用上写 selector_config={‘adaptive’: True} | 始终(首次与后续运行) | 打开该功能。没有它,Scrapling 会静默忽略另外两个标志。 |
| 在 .css() 上写 auto_save=True | 首次运行 | 将匹配元素的结构指纹(标签、属性、位置、周围文本)记录到一个小的本地 SQLite 文件。 |
| 在 .css() 上写 adaptive=True | 后续运行 | 如果选择器返回空,使用保存的指纹再次找到该元素。 |
端到端生命周期:
在代码中是这样:
from scrapling.fetchers import Fetcher
# First run: enable adaptive on the fetcher, save fingerprints with auto_save
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# Later run: same selector, plus adaptive=True for the fallback path.
# If the site renamed `.quote`, the fingerprint recovers the elements.
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")指纹数据库存储在你的脚本旁边,因此同一脚本会在多次运行中复用已保存的指纹。该模式在每个 fetcher 上都一样:在 fetch 调用上一次性传入 selector_config,然后在 .css() 调用上使用 auto_save 与 adaptive。
将指纹文件视为迁移产物:提交它以获得可复现的 CI 运行,在 Docker 中将其挂载为卷,并且 绝不要对你尚未验证的页面运行 auto_save=True。用 auto_save 抓取到的 CAPTCHA 墙会污染指纹,因此后续运行会恢复到错误元素。删除该文件以重置。
限制:自适应匹配仅在元素的 内容 大致稳定而只有 标记 变化时有效。如果站点用不同功能替换整个区块,任何算法都无法恢复。对空结果集保持告警,以便当站点以指纹无法处理的方式变化时你能注意到。
抓取 JavaScript 渲染页面
许多站点发送几乎为空的 HTML 骨架,然后在客户端渲染实际内容。该标准测试页是 quotes.toscrape.com/js,它提供与静态版本相同的引言,但通过 JavaScript 注入。如果你用 Fetcher 指向它,结果是可预期的:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []空。文本存储在一个 var data = […] JavaScript 变量中,浏览器在页面加载时执行它,而基础 HTTP 客户端从不运行该脚本。修复方式是使用 DynamicFetcher,它在内部控制一个真实的 Chromium 实例:
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())该片段中有两个标志很重要。headless=True 是你在服务器上想要的。network_idle=True 会等待网络活动停止后解析器再读取页面,这能覆盖大多数 JavaScript 渲染页面。对于 hydration 很重的 SPA(Next.js、Remix、SvelteKit),网络可能在 React 仍在 hydration 时就 idle;对这些,改为传入 wait_selector=”…” 并指定一个已知稳定元素,或同时使用。
一旦浏览器拿到页面,其余 API 与静态 Fetcher 示例完全相同。
每个浏览器会话大约需要 1 GB 常驻内存(生产扩展部分有拆解)。每天几百页时,一个 2 GB worker 就能处理;超过每天数万页时,使用 DynamicSession 在请求间复用浏览器,或将工作迁移到运行在你自有服务器之外的托管抓取浏览器。
使用 StealthyFetcher 绕过反爬防护
现代反爬产品如 Cloudflare Turnstile、DataDome 和 HUMAN Bot Defender(前身 PerimeterX)会检查数十个信号来判断请求是否来自真实浏览器。列表包括 TLS 握手指纹(常见格式是 JA3 和 JA4)、HTTP/2 帧排序、navigator 属性(navigator.webdriver、插件列表、语言头)、canvas 与 WebGL 哈希,以及时序模式。一旦这些静态检查通过,行为层通常会接管(鼠标移动熵、滚动节奏、停留时间)。原生 Playwright 或 Selenium 会话默认暴露其中若干项,这就是为什么“我加了 Playwright 但仍然被封”是抓取论坛上的常见问题。
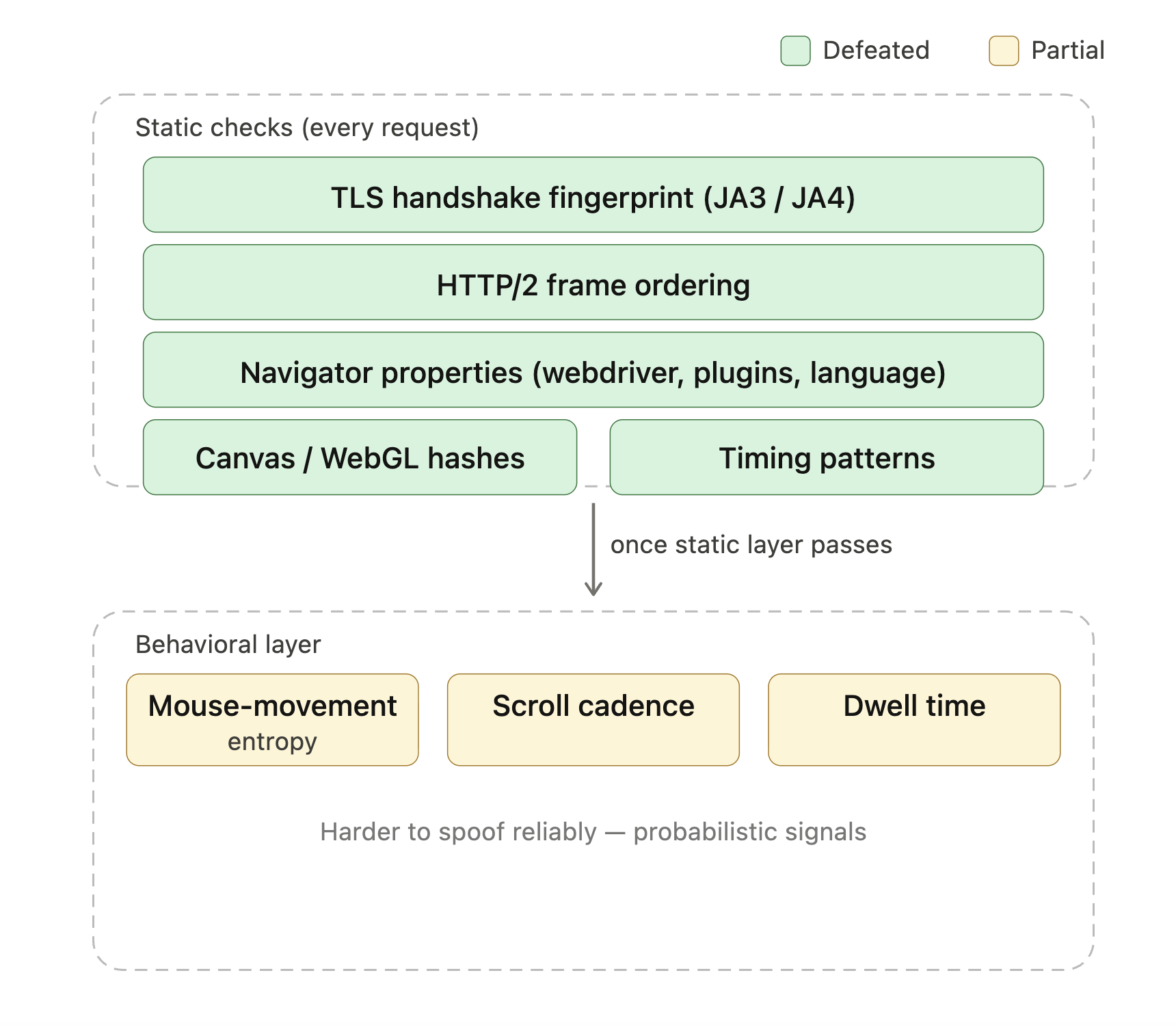
绿色层是 StealthyFetcher 的 Camoufox 基座可自行处理的;黄色是行为评分开始介入、托管解锁体现其成本价值的部分。
StealthyFetcher 使用 Camoufox——一个打过补丁的 Firefox 构建,用于掩盖常见自动化信号——来击败这些系统检查的无头浏览器与 Playwright 指纹。对于 Cloudflare 较轻量的 Bot Management 档位,这通常就足够了。将 Turnstile 与行为评分结合的企业级部署仍会阻止本地隐身方案;这时托管解锁成为更实际的答案(在生产扩展部分覆盖)。对于明确运行 Turnstile 挑战的网站,Scrapling 有一个 solve_cloudflare 标志,可自动通过挑战:
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")该示例中的页面是一个运行真实 Turnstile 挑战的公开 Cloudflare 演示。
有几个真实限制值得记住:
- solve_cloudflare 路径适用于托管的 Turnstile 挑战。它不承诺处理每一种验证码类别。图像网格挑战(旧版 reCAPTCHA、hCaptcha 图像谜题)需要要么通过页面动作接入一个第三方验证码破解服务(2Captcha、CapSolver),要么使用一个端到端处理挑战层的托管解锁端点。
- 隐身绕过技术经常变化。请为你的真实目标规划周期性验证,而不是一次性设置。
- 结果也取决于 IP 信誉。一个在目标站点已被标记的数据中心 IP 无论浏览器指纹多好都不会成功。
对于不使用 Cloudflare 的站点,在不启用挑战求解器的情况下获取隐身收益:
page = StealthyFetcher.fetch('https://example.com', headless=True)默认的指纹保护会生效,而如果没有挑战需要解决,solve_cloudflare 不会做任何事。
一个需要了解的模式:隐藏封禁
反爬系统有时会返回 200 OK 并附带伪装的封禁页面(CAPTCHA 墙、空结果页,或“正在验证你是人类”的中间页),而不是明确的 403 或 503。空结果检查(在生产就绪脚本中展示)能捕捉明显情况。对于结构完整但数据错误的隐藏封禁,你需要内容级检查:将响应长度与基线对比、查找提示性字符串(正文中的 “captcha”、“are you human”、“access denied”),或抽样一个已知稳定条目的预期字段。没有一种是完美的;组合起来能在坏数据流入下游前捕捉大多数静默封禁。
Spider 框架为此暴露了一个 is_blocked hook:重写它(也可以是 async def),Scrapling 会对被封禁的响应自动重试,最多 max_blocked_retries(默认 3):
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in body封禁重试次数会在爬取后出现在 result.stats.blocked_requests_count 中。将该计数器用作你的生产告警指标。
使用 FetcherSession 抓取登录后的页面
真实目标通常需要登录。使用 FetcherSession 的模式就是你用 requests + Session 写的标准 CSRF + cookie 流程,只是由 Scrapling 的解析器处理响应。Quotes-to-Scrape 沙盒在 /login 提供了可用登录,因此它是一个简单测试用例:
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. GET the login page to grab the CSRF token
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. POST credentials. Cookies persist on the session automatically.
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. Fetch a page that's gated behind the login.
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# Logged-in pages on this sandbox show extra Goodreads links per quote
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())这里有三点很重要:
- 使用会话,而不是单独的 Fetcher.get() 调用。 FetcherSession 在请求之间持久化 cookie(以及服务器返回的任何 Set-Cookie);单独的 Fetcher.get() 调用不共享状态。
- 从登录表单读取 CSRF token。 大多数现代框架都包含一个,并拒绝没有它的 POST 请求。字段名因框架而异:Django 使用 csrfmiddlewaretoken,Rails 使用 authenticity_token,许多 SPA 则在 header 中发送 token,因此在假设名称前先检查表单。
- 在继续之前验证登录成功。检查是否有退出链接、导航栏中的用户名,或登录表单是否消失。如果登录失败但没有错误而你抓取了公开页面,你会得到看似正确但实际上错误的数据。
对于带 2FA、OAuth 或发放长生命周期 token 的登录流程,最简单的方法是手动登录一次(或通过站点 API),捕获得到的 cookie 或 token 并复用。FetcherSession 在构造时接受一个 cookies={…} dict,因此你可以用保存的 cookie 填充会话。
使用 AsyncFetcher 并发抓取
当你有一个 URL 列表并需要全部抓取时,同步 Fetcher 会串行执行。AsyncFetcher 以协程形式暴露相同 API,因此你可以用 asyncio.gather 并发发出所有请求,让多个网络往返并行运行(与使用 AIOHTTP 的异步抓取相同模式,但解析器已附带):
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")对同样的 10 个引言页面,这会将顺序 9 秒的抓取降到典型家庭网络上的约 1 秒。FetcherSession 本身也能在 async with 下工作,因此你可以像同步代码一样在异步调用间复用 cookie 和 header。对于带限速、去重与恢复的完整爬取,Spider 框架通常是更好的选择。AsyncFetcher 的意义在于你有一份已知 URL 列表,只想并行获取它们。
一个陷阱:裸 asyncio.gather(\tasks)* 会立即重新抛出第一个异常,但其他任务仍在后台运行;你在不停止工作的情况下会失去访问它们结果的能力。对于希望部分成功的生产列表,传入 return_exceptions=True 并过滤结果,或使用 asyncio.TaskGroup(3.11+),它会在首次失败时取消兄弟任务并提供显式的逐任务错误处理。
使用 Spider 框架构建多页爬虫
真实抓取任务很少只有一页。你会跟随分页、跟随产品链接、去重 URL、限制请求速率、将所有内容写入磁盘,并在任何失败时优雅恢复。Scrapling 为此提供了一个 Spider 框架,具有 Spider/parse/yield 形状,Scrapy 用户会很熟悉。不依赖 Scrapy 的 middlewares、pipelines 或 signals 的 spider 大多可以机械式迁移;其余需要针对 Scrapling 的 hooks 与 async parse 签名重写。
一个对 books.toscrape.com 的简单爬虫工具,它有一个约一千本书的五十页分页目录:
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # seconds between requests per domain
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")该片段做了几件你否则需要手工构建的事。concurrent_requests 同时运行八个请求,在 books.toscrape.com 上将完整爬取从分钟级降到秒级。download_delay 强制每域间隔,避免压垮单一主机。response.follow() 将相对 URL 相对于当前页面解析,消除最常见的分页 bug 之一(忘记拼接相对 next 链接)。async parse 签名允许你进行逐页 I/O(抓取详情页、调用外部 API)而不阻塞爬取循环。
两个解析器方法值得了解。对 .css() 结果调用 .re_first(pattern) 会返回第一个正则匹配,适合从格式化文本中提取数值:
# turns '£51.77' into 51.77 in one expression
price = float(book.css('.price_color::text').re_first(r'[\d.]+'))并且 .css() 返回的 Selectors 容器有一个 .filter() 方法,接受一个谓词,因此你可以在不写第二个循环的情况下缩小 Scrapling 已有的数据:
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[\d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}当站点不为你想按字段过滤的内容暴露 URL 过滤参数时很有用。
末尾的导出会每行写一个 JSON 对象,这是大多数下游流水线所期望的。你也可以用 .to_json() 输出单个 JSON 数组,或通过重写 process_item hook 编写你自己的 pipeline。
对于需要在抓取时就获取条目而不是等待整个爬取结束的流水线,Spider 将 .stream() 暴露为一个 async generator:
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # or any other downstream sink
asyncio.run(main())对于更长的爬取,从一开始就设置暂停与恢复机制是值得的:
result = BooksSpider(crawldir="./crawl_data").start()传入一个 crawldir,Scrapling 会将已访问 URL 与待处理请求检查点写入磁盘。按 Ctrl+C,爬取会优雅关闭。再次用相同 crawldir 运行,它会从停止处恢复。对五十页爬取这不必要,但对长时间运行的生产爬取(目录刷新、市场研究、价格监控)而言,这是丢失一天进度与什么都不丢的区别。
如果你的目标需要更资源密集的 fetcher,spider 可以按 URL 将请求路由到不同会话:
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}可视化为路由图:
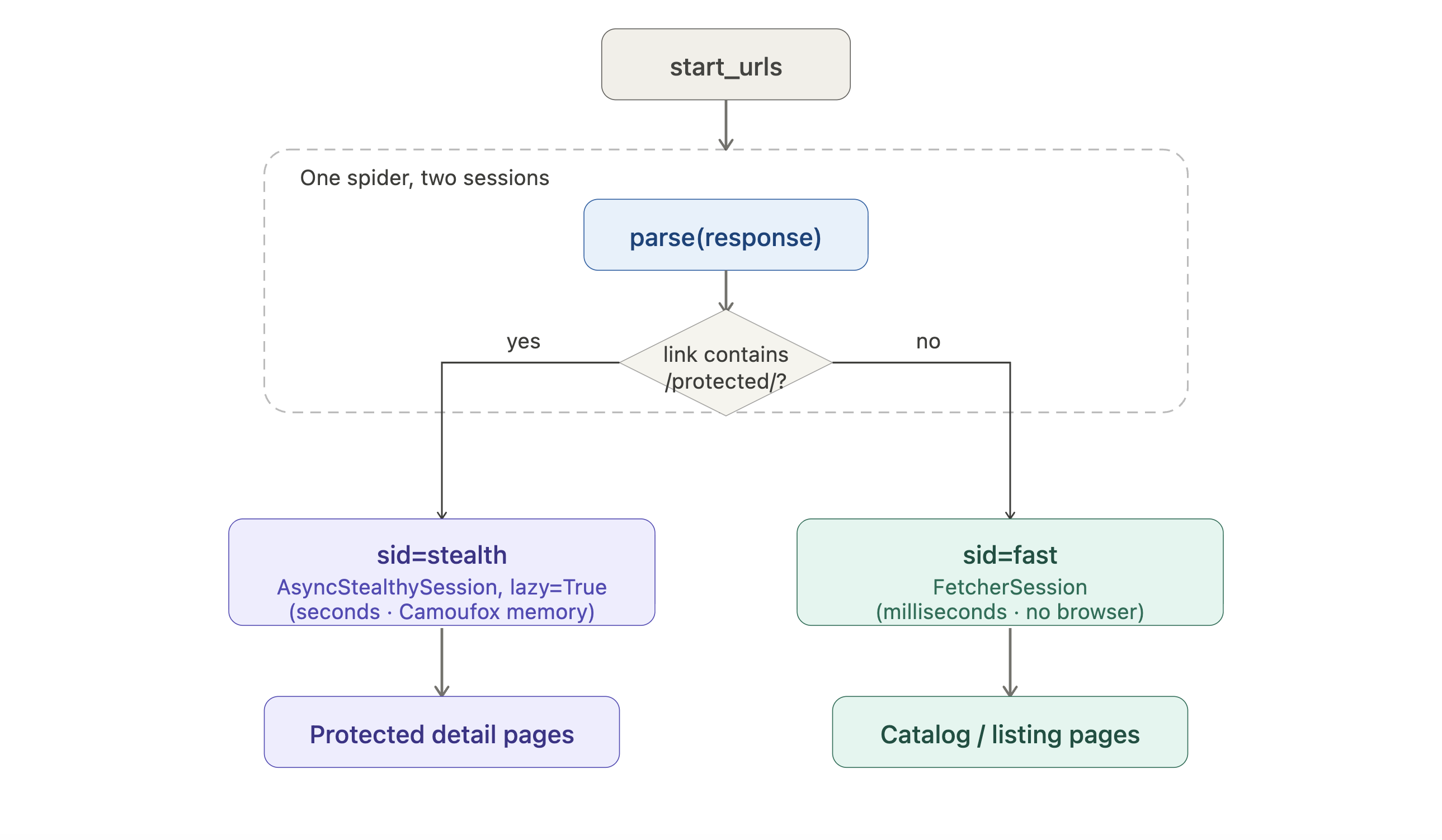
列表页走便宜的 HTTP 路径;只有受保护的详情页才支付浏览器成本。lazy=True 将浏览器启动推迟到第一个隐身请求真正发出时,因此最终只命中列表页的爬取永远不会打开 Camoufox。
该示例中有一些细节从代码里并不明显。AsyncStealthySession 与 AsyncDynamicSession 是长生命周期浏览器会话。跨多个请求复用它们,而不是使用每次调用都启动新浏览器的 StealthyFetcher.fetch() 或 DynamicFetcher.fetch()。
configure_sessions 接收一个 manager(Spider 的会话注册表);manager.add(name, session) 以名称注册会话,之后你可以用 Request(url, sid=name) 路由到它。隐身会话上的 lazy=True 标志会延迟打开浏览器直到你发出第一个隐身请求,因此只请求公开页面的爬取永远不会产生浏览器启动开销。
fast 会话对列表页使用便宜的 HTTP fetcher,而只有受保护详情页需要真实浏览器。这种路由很难在后期再添加到通用爬虫中。
真实网站上的分页
真实目标很少像 books.toscrape.com 那样有简单的 .next 链接。你会看到的大多数情况可用三种模式处理:
- 编号分页(例如 ?page=1, 2, 3…)最简单。直接在 start_urls 中生成 URL,或在 parse 中循环 yield Request 对象。
- 无限滚动 通常依赖一个 JSON XHR 端点。打开 DevTools → Network,滚动页面,寻找返回下一批条目的请求。然后用 Fetcher 调用该端点(比在浏览器中渲染每次滚动便宜得多)。
- “加载更多”按钮 需要在浏览器内真实点击。DynamicFetcher 与 StealthyFetcher 接受一个 page_action callable,它接收底层 Playwright page;在那里点击按钮,等待新内容,然后在函数返回时让解析器读取页面:
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` is the underlying Playwright sync Page.
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")根据目标调整选择器与点击次数。异步会话类(AsyncDynamicSession、AsyncStealthySession)接受同一 callable 的 async 等价形式。
为生产扩展 Scrapling:代理与解锁
当你以规模抓取真实生产目标时,架构会发生变化。通常会同时出现三个约束:
- IP 信誉。 一个住宅或数据中心 IP 每小时向同一站点发送一千个请求并不像真实用户。大多数生产目标会先限速,然后节流,再封禁。解决方案是一个 IP 池,最好是住宅(真实消费者连接)或 ISP(运营商分配的数据中心 IP,在反爬评分中看起来像住宅)类型,并按请求或按会话轮换。
- 地理定位。 一些站点按国家、州或城市提供不同内容(或不同价格)。复现这些视图需要对应位置的代理。
- CDN 级反爬。 超过 Cloudflare 的基础 Turnstile 后,Akamai Bot Manager(以及严格模式下的 DataDome 或 HUMAN)往往会封禁本地隐身方案。此时,一个维护自有浏览器池与挑战求解器的托管解锁端点通常比自定义方案更好用。
重试、超时与瞬态错误
在规模化时网络错误不可避免:连接重置、负载下偶发 503、被限速时的 429。FetcherSession 在构造时接受 retries=, retry_delay=, timeout=(v0.4.7 默认值:3、1 秒、30 秒;请用 help(FetcherSession) 在你的安装版本上确认)。浏览器 fetcher(StealthyFetcher、DynamicFetcher)则在每次 .fetch() 调用中按 fetch 传入相同参数。
对于服务器在 429 上发送 Retry-After header 的按目标限速,在你的 parse 方法中读取该 header,并带延迟重新 yield Request。默认重试不遵从 Retry-After,因此依赖它会让你再次得到同样的 429。
浏览器内存:具体容量数字
运行真实浏览器是使用 DynamicFetcher 与 StealthyFetcher 的成本。在典型内容页(~200 KB HTML、非媒体密集 SPA)上,一个 Camoufox 或 Chromium 会话在 Linux x86_64 的无头模式下使用约 700-900 MB RAM。该大小在同一会话的多次抓取之间几乎不变,因此在容器容量规划时按 每个并发浏览器会话约 1 GB 计算:4 GB worker 可舒适运行 3-4 个并发会话,8 GB worker 可处理 6-8 个。更重的目标(图片丰富页面、密集 SPA、加载数十个分析脚本的网站)会将每会话成本推到 1.2-1.5 GB。复用会话而不是一次性 .fetch() 调用,这样你不会在每个请求上都承担浏览器启动延迟。
在生产量级下有两个浏览器 fetcher 标志很重要。block_ads=True 启用 Scrapling 内置的 blocklist(约 3,500 个广告与追踪域名),通过跳过无关网络请求减少广告重站点的抓取时间。dns_over_https=True 通过 Cloudflare 的 DoH(DNS over HTTPS)端点路由 DNS 查询,并有助于在你通过住宅代理路由流量时防止 DNS 泄漏。两者都适用于 DynamicFetcher 与 StealthyFetcher(HTTP fetcher 请求不加载页面资源,因此不需要这两个标志)。
自管理代理轮换
Scrapling 有一个 ProxyRotator 辅助工具,可直接处理基础轮换场景:
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)对于只有少量静态代理的小项目,这就够了。对于更大的项目,你通常希望一个单一端点为每个请求提供一个新 IP(或为每个用户提供粘性会话),这时为商业提供商付费就有意义。
Bright Data 的 住宅代理 网络 使用同样的代理 URL 模式与 Scrapling 集成:它是一个带用户名与密码认证的单一 HTTP 代理端点,而用户名包含网络所需的路由参数,包括国家与粘性会话 ID。这些值来自 Bright Data 控制面板中该 区域 的 Access parameters 页面。
要运行下面的示例:在 brightdata.com 注册(免费试用,开始无需绑卡),在 控制面板 中创建一个住宅代理 区域,并将你的 id、区域 和 password 复制到代理 URL 中。住宅代理在 区域 激活前需要一次性 KYC 验证。以下是一个按请求轮换的典型设置:
from scrapling.fetchers import FetcherSession
# Replace <id>, <zone>, and <password> with the values from your dashboard.
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)关于该设置的两点说明:
- 按请求传入 proxy=,而不是在 FetcherSession 构造器上。 按请求的 proxy= 在各 fetcher 类型间表现一致,也是最容易按调用覆盖的路径。这适用于任何提供商,不仅是 Bright Data。
- 在会话上设置 verify=False。 Bright Data 住宅网络用自签名证书链终止代理跳(住宅代理服务的标准做法)。验证仅对到代理的本地跳禁用;目标连接仍通过代理的 CONNECT 方法实现端到端 TLS。生产环境更干净的模式是在你的信任存储中安装 Bright Data 的 CA 证书,并完全移除 verify=False;避免将其复制粘贴到不经过住宅代理的代码路径中。
对于粘性会话(多次请求使用同一 IP 以保持购物车或登录状态),用户名包含会话 ID,例如 brd-customer–区域–session-rand123。轮换逻辑在提供商侧运行,而库将该 URL 视为常规 HTTP 代理。
同样的 Scrapling 集成也适用于 Bright Data 的其他代理类型(用于更高量住宅质量 IP 的 ISP 代理、用于仅移动端视图的移动代理),只需更改 URL 中的 区域 名称。
对于最困难的目标,网络解锁器 模式值得了解。你不再运行自己的隐身浏览器并在供应商发布新检测检查时更新指纹,而是将 fetcher 指向一个单一端点;渲染、指纹、IP 轮换与挑战求解都在远端完成。Bright Data 的 网络解锁器 围绕该模式构建,提供国家级定位与由供应商维护的按域解锁逻辑。你的解析代码保持不变;只有 fetch 行发生变化。
同样的权衡也适用于 JavaScript 很重的目标。本地运行 Camoufox 或 Chromium 适用于中等量。一旦你在管理许多浏览器容器,一个托管的 Bright Data 抓取浏览器 会将解锁与指纹维护从你的团队中移除。抓取浏览器 是一个你通过 WebSocket 连接的远程浏览器,使用与 Playwright 内部相同的协议,因此它可以插入与本地 Chromium 浏览器相同的代码路径。
在这两者之间选择时有两点实用说明:
- 如果你的问题是“我需要每个请求一个不同 IP 来避免限速”,住宅代理加本地 Fetcher 或 StealthyFetcher 通常就够了。你是在为 IP 付费,而不是为绕过封禁的工作付费。
- 如果你的问题是“我遇到无法解决的 CAPTCHA 挑战,而且站点每隔几周就改变其防护”,托管解锁端点通常能节省足够工程时间,从而证明更高的单请求成本是合理的。
一个完整的生产就绪 Scrapling 脚本
一个基础 BooksSpider 在沙盒上运行良好。五项补充使其生产就绪,下面用编号注释标出:
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. respect robots.txt and Crawl-delay
async def parse(self, response: Response):
if response.status != 200: # 2. handle non-200 responses explicitly
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. detect outdated selectors early
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. timestamp every row
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. checkpoint for pause/resume
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")每项补充带来的收益:
- robots_txt_obey 自动遵从 robots.txt 与 Crawl-delay 指令。
- 状态检查 让 spider 明确记录服务端失败,而不是将其当作“未找到条目”。
- 空结果检查 能在第二天早晨捕捉过期选择器,而不是三周后下游报告显示无数据时才发现。
- 时间戳 记录每行抓取时间,因此跨天重跑不会混在一起。
- crawldir 意味着 Ctrl+C、内核崩溃或网络连接丢失都不会破坏爬取进度。
要将同一脚本切换到住宅代理,唯一变化是 fetcher 会话。要切换到 网络解锁器 端点,将代理 URL 改为解锁服务即可。解析逻辑与 spider 行为保持完全一致。
按计划运行
用 cron、systemd timer,或 Airflow、Prefect 等编排器包装脚本。使用每次运行独立的 crawldir(例如 ./crawl_data/$(date +%Y%m%d)),这样上一次运行的恢复状态不会带入新一次运行,并将输出发送到持久存储,而不是留在 worker 机器磁盘上。常见落地:S3 或 GCS 上的 Parquet(由 polars 或 DuckDB 用于临时分析读取),或当你需要关系型查询时写入 Postgres 表。
对于超出 JSONL 文件的目的地,重写 Spider 的 on_start、on_scraped_item 与 on_close hooks(三者都是 async def)。在 on_start 中打开一次数据库连接或消息队列生产者。在 on_scraped_item 中在条目 yield 时写入(返回该条目以转发,返回 None 以丢弃)。在 on_close 中清理。
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # forward downstream too
async def on_close(self) -> None:
await self.db.close()当抓取失效时:调试清单
生产爬虫工具会以单元测试检测不到的方式失败。几个快速检查能处理大多数情况。
以可见模式打开浏览器。 向 StealthyFetcher.fetch() 或 DynamicFetcher.fetch() 传入 headless=False 并观察页面渲染。CAPTCHA 挑战、重定向链、geo-IP 重定向与反爬检测页面通常只有在你能看到发生了什么时才明显。在本地运行;对于无头服务器,通过 page_action 保存截图代替。
将响应 HTML 保存到磁盘。 当选择器返回空时,保存原始响应并在浏览器中打开:
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)然后对比解析器收到的内容与你预期的内容。最常见的是,你抓取到的其实是 CAPTCHA 墙、不同语言的重定向,或一个乍看与成功案例相同的空结果页。即使状态码具有误导性,HTML 也会揭示真相。
使用交互式 shell。 安装 scrapling[shell] 并运行 scrapling shell。它会加载一个预先导入 Scrapling 的 IPython 会话,并提供两个有用的辅助工具:uncurl(…) 将一个 curl 命令(来自 DevTools 的 Copy as cURL)解析为 Scrapling Request 对象,以便你检查实际发送了什么;curl2fetcher(…) 解析并执行它,返回一个已解析的 Response。在 DevTools 中右键任意 XHR 调用,复制为 cURL,将其粘贴进 shell,你就得到一个可用的 Scrapling 抓取。
从你已有的元素反向生成选择器。 如果你通过 find_by_text、导航或其他方式找到了一个元素,.generate_css_selector 与 .generate_xpath_selector 属性(注意:是属性,不是方法)会为它提供一个可复用的选择器:
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > small输出并不易读,但可复用,并能在不移动元素的内容变更下保持稳定。
关于先检查什么的说明。 当一个昨天还能工作的爬虫工具今天坏了,从最快的检查做到最慢的:空结果检查(“selector returned nothing”)、保存的 HTML(“did the page even render?”),然后 headless=False(“is the site challenging the browser?”)。
在不向目标再发送一次请求的情况下迭代 parse()。 在你的 Spider 类上设置 development_mode = True 与 development_cache_dir = “./_dev”:
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...第一次运行会命中网络并将每个响应缓存到磁盘;后续运行从缓存回放(在沙盒站点上约 50 ms 对比 1.2 秒,约 24 倍加速)。当你在调整选择器与清洗数据时,你不再需要在每次测试运行中等待网络。部署前将 development_mode 设回 False。
下一步
选择一个你一直想抓取的真实目标,并从能工作的最轻量 fetcher 开始。Fetcher 处理静态 HTML;当内容由 JavaScript 渲染时使用 DynamicFetcher;当站点在 Cloudflare 或类似反爬供应商之后时使用 StealthyFetcher。
对于任何你计划持续运行的任务,从一开始就设置这些默认值:
- 用带 crawldir、robots_txt_obey=True,并在每个页面做空结果检查的 Spider 包装解析逻辑。
- 打开 selector_config={‘adaptive’: True},并在首次运行时使用 auto_save=True,这样在站点更改标记之前结构指纹就已落盘。
- 在共享基础设施上将 download_delay 设为至少 0.5,1 s,并在你的 parse 方法中读取任何 429 响应的 Retry-After header。
当本地隐身不再足够(IP 信誉、并发扩展、CDN 级反爬)时,通过在每次 fetch 调用上添加一个 proxy= 参数切换到一个住宅代理或托管解锁端点。任何暴露带基础认证的 HTTP 代理的提供商都以同样方式工作。
完整参考请见 官方文档。
FAQ
我可以在商业产品中使用 Scrapling 吗?
可以。Scrapling 是 BSD-3-Clause,因此你可以在商业产品、SaaS 后端或内部工具中打包发布,无需版税或付费档位。你只需为你选择的可选第三方服务付费,例如住宅代理或验证码破解。Scrapling 本身没有任何功能受许可限制。
Scrapling 与 Playwright 或 Selenium 相比如何?
Scrapling 是为抓取而专门构建的;Playwright 与 Selenium 是通用浏览器自动化工具。Scrapling 封装了隐身补丁的 Camoufox 构建(通过 Playwright 驱动)、重试、会话复用与自适应选择器,因此你需要写更少胶水代码,并避免原生 Playwright 暴露的 Chromium-CDP 指纹。
Scrapling 能解决 CAPTCHAs 吗?
部分可以。StealthyFetcher 在 solve_cloudflare=True 时可通过托管的 Cloudflare Turnstile 挑战。其他类别(图像网格 hCaptcha、音频 CAPTCHA、自定义企业级)需要第三方 CAPTCHA 破解(2Captcha、CapSolver)或一个端到端处理挑战层的托管解锁端点。
Scrapling 能与 Scrapy 一起工作吗?
可以。Scrapling 的解析器使用与 Parsel 相同的伪元素语法(::text、::attr(href)),因此 Scrapling Selector 可以在 Scrapy 回调中使用,且大多数选择器无需更改。Spider/parse/yield 形状也可沿用;不重度依赖 middlewares 或 pipelines 的 spider 大多可以机械式迁移。
使用 Scrapling 需要代理服务吗?
不需要,Scrapling 在小任务中无需代理也能工作。在生产量级下,当你想完全控制时使用 Scrapling 内置的 ProxyRotator 配合静态列表,或当你需要按请求获取新 IP 或国家级定位时使用托管的住宅、ISP 或移动端点。
Scrapling 能在 Docker 中运行吗?
可以。项目提供官方 Docker 镜像,预装所有浏览器依赖。对于 StealthyFetcher 与 DynamicFetcher,官方镜像能节省约一小时在自定义容器中让 Camoufox 与 Chromium 正常工作的时间。对于基础 Fetcher,任何标准 Python 镜像都可以。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。




