

在本文中,你将学习:
- 什么是 Azure Synapse Analytics,以及它能提供什么。
- 为什么在 Azure Synapse Analytics 中集成 Bright Data 的 SERP API 是一种制胜策略。
- 如何构建一个 Azure Synapse 流水线,使用 Bright Data 的 SERP API采集、转换并分析网页搜索数据。
让我们开始吧!
什么是 Azure Synapse Analytics?
Azure Synapse Analytics 是一个基于云的分析平台,在同一工作区中整合了数据集成、企业数据仓库与大数据处理能力。它提供流水线编排、Apache Spark 池,以及专用和无服务器 SQL 池,使你能够在一个统一环境中以规模化方式摄取、转换并查询数据。
它的主要目标是帮助你从原始数据走向业务洞察。这通过将用于数据摄取的流水线引擎(基于 Azure Data Factory)、用于代码型转换的 Apache Spark Notebook,以及用于查询与对外提供可分析数据集的 SQL 池组合起来实现,从而将数据服务于仪表盘、机器学习模型与下游应用。
Azure Synapse Analytics vs Azure AI Foundry:有什么区别?
如果你已经读过我们关于 在 Azure AI Foundry 中集成 SERP API 的指南,你可能会好奇 Synapse Analytics 有何不同。这两者服务于完全不同的目的:
- Azure AI Foundry 是一个统一的 AI 开发平台,专注于构建、部署与管理 AI 应用、智能体与提示词流(prompt flows)。它提供对 LLM 目录的访问(来自 Azure OpenAI、Meta、Mistral 等),面向以 AI 为先的开发场景,包括提示词工程、模型微调与 RAG 工作流。
- Azure Synapse Analytics 是一个数据分析与数仓平台,专注于摄取海量数据、运行复杂转换,并以规模化方式提供结构化分析数据。它擅长 ETL/ELT 流水线、基于 Spark 的大数据处理,以及基于 SQL 的商业智能分析。
简而言之,Azure AI Foundry 是你构建 AI 驱动应用与提示词流的地方;而 Azure Synapse Analytics 是你构建数据流水线的地方,用于采集、转换并入仓数据,以支持分析与报表。
它们实际上是完美互补的。你可以用 Synapse 构建数据底座,大规模采集并入仓 Web 数据,然后将这些经过治理与整理的数据提供给 AI Foundry 进行基于 LLM 的分析。在本教程中,你将看到 Synapse Analytics 如何与 Bright Data 的 SERP API 集成,从而构建一条完整的 Web 数据流水线:采集搜索结果、用 Spark 进行转换,并通过 SQL 提供分析能力。
为什么要在 Azure Synapse Analytics 中集成 Bright Data 的 SERP API
Azure Synapse Analytics 的流水线引擎提供强大的 REST 连接器,可让你调用任何 REST API,并将结果直接落地到 Azure Data Lake Storage。这为将外部数据源摄入分析工作流打开了大门。但如果你希望把实时网页搜索数据注入到数据仓库中,你需要一个可靠、可扩展且结构化的数据源。
这就是 Bright Data 的 SERP API发挥作用的地方。SERP API 让你能够以编程方式在搜索引擎上发起查询(包括 Google、Bing、DuckDuckGo、Yandex 等),并获取完整的 SERP 内容。它以多种格式返回数据,包括解析后的 JSON、原始 HTML 与面向 AI 的 Markdown,为你提供可靠、最新且可验证的数据来源。
这种方式尤其适用于:
- SEO 关键词追踪流水线:每天监测数千个关键词在搜索中的排名,并识别随时间变化的趋势。
- 竞品情报数据仓库:采集竞争对手的可见性数据,并与内部指标进行关联,以支持战略分析。
- 市场研究数据集:按行业、地区与时间维度汇总搜索结果趋势,用于大规模报告与分析。
- 内容表现分析:追踪你的内容在目标关键词下的排名表现,并衡量 SEO 努力带来的影响。
将 Azure Synapse 的流水线编排与数仓能力和 Bright Data 的 SERP API 结合后,你可以创建能够持续采集、转换并分析网页搜索数据的数据流水线,并在无需维护任何抓取基础设施的情况下实现规模化运行。
如何在 Azure Synapse 中使用 Bright Data 构建 SERP 数据流水线
在本节的引导式步骤中,你将看到如何将 Bright Data 的 SERP API 集成到 Azure Synapse 流水线中,作为每日关键词排名追踪器的一部分。该流水线由五个主要步骤组成:
- 工作区设置:创建一个 Azure Synapse 工作区,并关联一个 Data Lake Storage 账户。
- 数据源配置:创建一个指向 Bright Data SERP API 的 REST linked service,并安全存储凭证。
- 摄取流水线:Synapse 流水线为一组被追踪关键词调用 SERP API,并将原始 JSON 结果落地到数据湖。
- Spark 转换:Apache Spark Notebook 将原始 SERP 数据打平并标准化为可分析的 Delta 表。
- SQL 分析:无服务器 SQL 查询分析排名趋势,并为 Power BI 仪表盘创建视图。
注意:这只是一个示例,你还可以在许多其他场景与用例中使用 SERP API。例如,你也可以为竞争性价格监控构建流水线,或将 SERP 数据输入到机器学习模型中。
按照下方步骤,在 Azure Synapse Analytics 中构建一条由 Bright Data SERP API 驱动的 Web 数据流水线吧!
前置条件
为了跟随本教程的这一部分,请确保你已具备:
- 一个 Microsoft 账号。
- 一个 Azure 订阅(即使是免费试用也足够)。
- 一个 Bright Data 账号,并且拥有已启用的 SERP API zone 与 API key(具备 Admin 权限)。
请参考 Bright Data 官方文档设置你的 SERP API zone 并获取 API key。请将 API key 与 zone 名称安全保存,因为你很快会用到它们。
步骤 1:创建 Azure Synapse 工作区
Azure Synapse 的流水线只在 Synapse 工作区内可用,因此第一步是创建一个工作区。
登录你的 Azure 账号,在 Azure Portal 顶部的搜索框中搜索 Azure Synapse Analytics:
在 Synapse Analytics 管理页面,点击 Create。填写创建表单:
- 选择你的 Azure subscription。
- 选择现有的 resource group 或创建一个新的。
- 为工作区取一个名称,例如
bright-data-serp-pipeline。 - 选择一个离你更近的 region。
- 在 Data Lake Storage Gen2 中选择 Create new,并提供存储账户名称(必须全小写,3–24 个字符,全局唯一,例如
serppipelinelake)。创建一个名为raw的新 file system。
点击 Review + Create,再点击 Create 开始部署。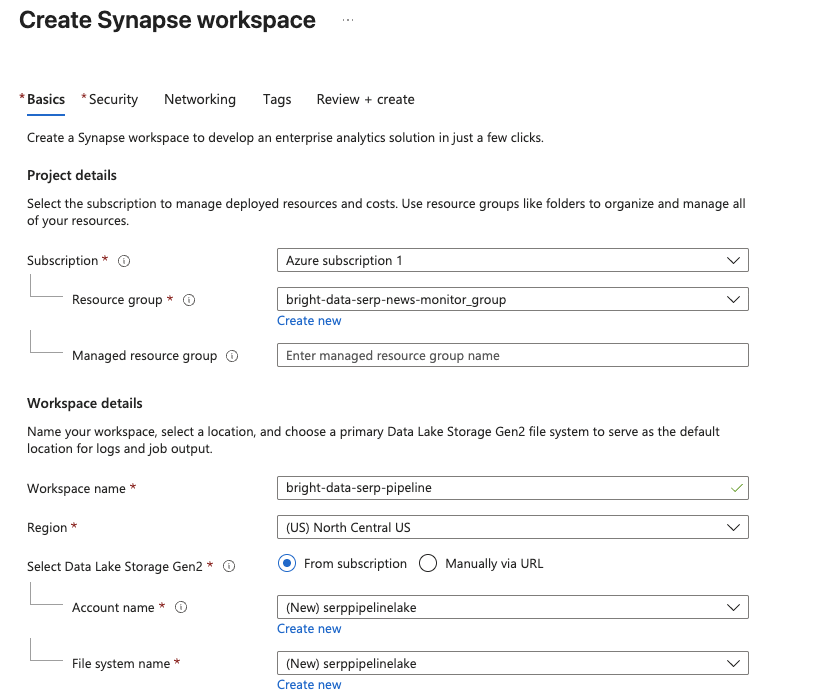
初始化过程可能需要几分钟。完成后你会看到确认页面。点击 Go to resource,然后点击 Open Synapse Studio 启动基于 Web 的开发环境。
现在你已经拥有一个 Synapse 工作区,可以在其中构建流水线、编写 Spark notebook,并运行 SQL 查询。
步骤 2:创建 Apache Spark Pool
为了在本教程后续运行转换 notebook,你需要在工作区中创建一个 Apache Spark pool。
- 在 Synapse Studio 中,进入 Manage > Apache Spark pools > New。
- 为 pool 命名,例如
sparkpool。 - 将 Node size 设置为 Small(4 vCores / 32 GB),这足以处理 SERP 数据转换。
- 启用 Autoscale 并将范围设置为 3–5 nodes。
- 点击 Review + Create,然后点击 Create。
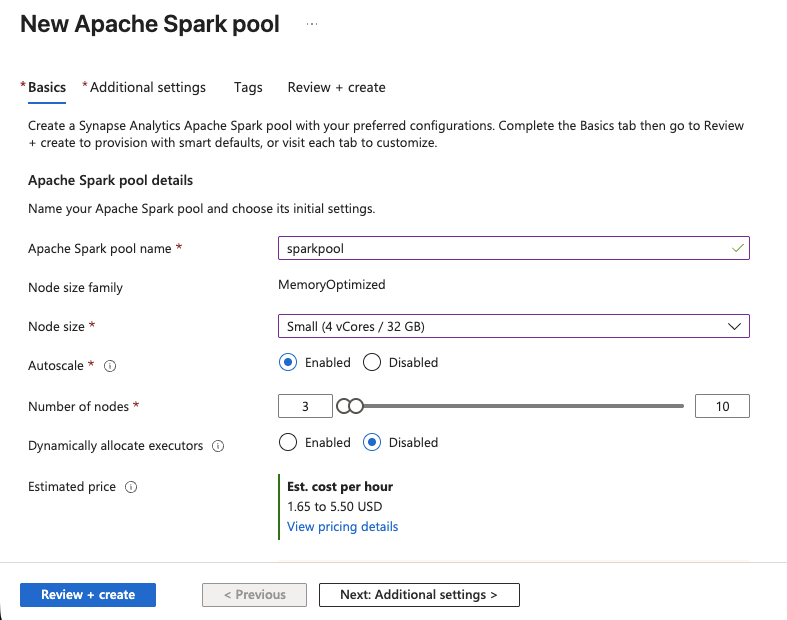
Spark pool 很快就会就绪。现在你已经拥有运行 PySpark notebook 的计算能力。
步骤 3:构建摄取流水线(Ingestion Pipeline)
现在你将创建一个 Synapse 流水线:为一组被追踪关键词调用 Bright Data 的 SERP API,并将结果落地到你的数据湖中。
创建一个新 Pipeline
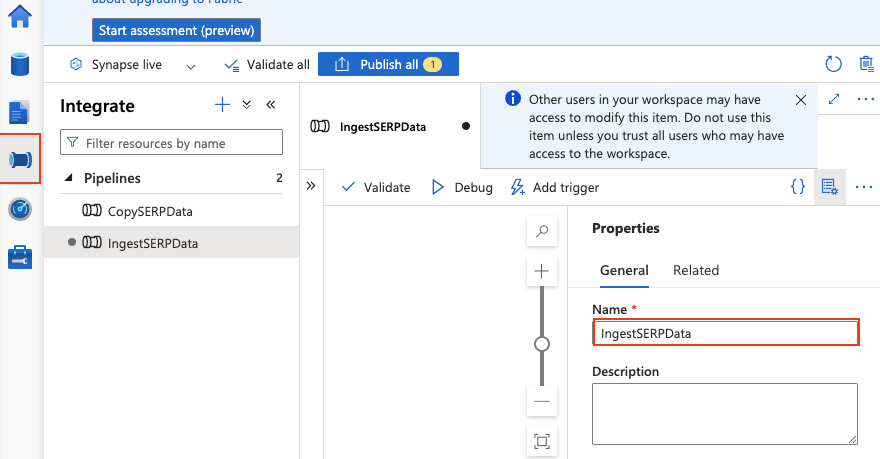
- 进入 Integrate > + > Pipeline。
- 将其命名为
IngestSERPData。
添加 Pipeline 参数
点击 pipeline 画布的空白处以打开 pipeline 属性。进入 Parameters 标签页并添加:
| Name | Type | Default value |
|---|---|---|
keywords |
Array | ["web scraping tools", "proxy service", "data extraction API"] |
这些就是你想要追踪排名的关键词。你可以随时修改这个列表。
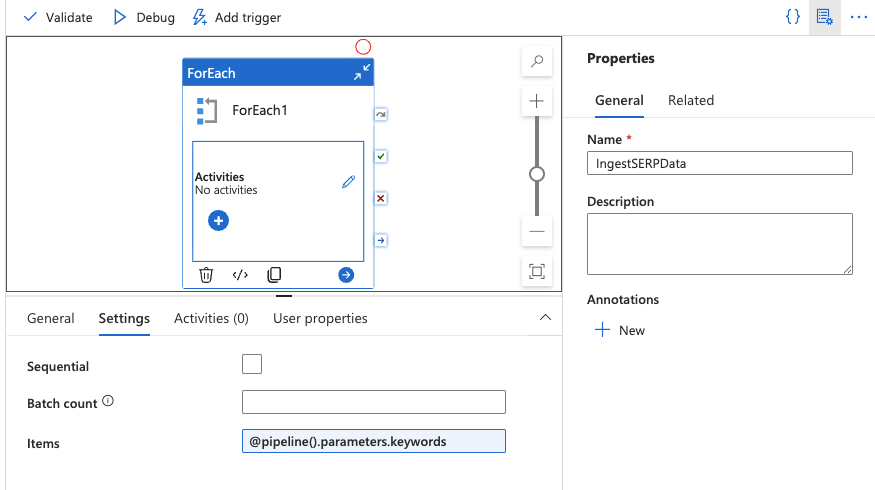
添加一个 ForEach 活动
- 从 Activities 面板将 ForEach 活动拖到画布上。
- 在 Settings 标签页,将 Items 字段设置为:
@pipeline().parameters.keywords
这会遍历数组中的每个关键词。
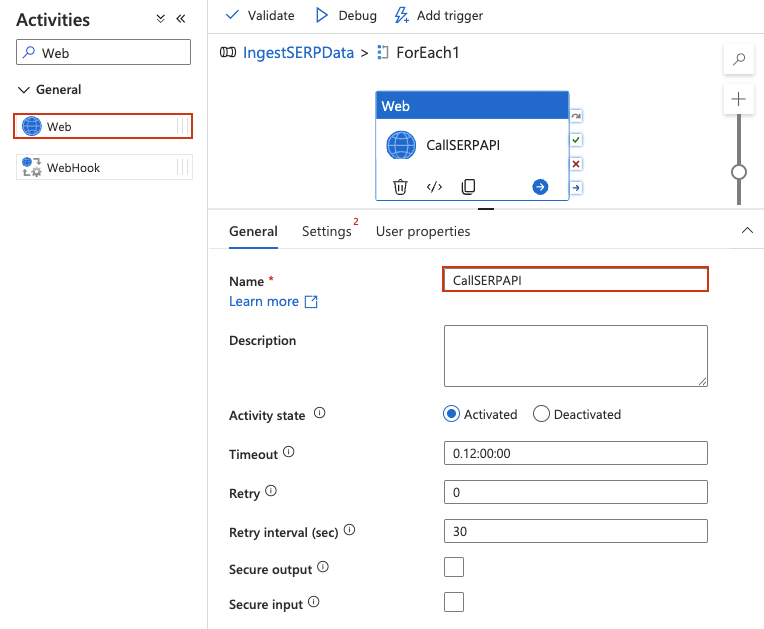
在 ForEach 内添加 Web 活动
Web activity 可以直接调用 REST API,本次请求本身不需要 datasets 或 linked services。
- 双击 ForEach 活动以进入其内部画布。你会看到设计器顶部标题改变,表明你处于 ForEach 作用域内(类似面包屑的
IngestSERPData > ForEach1)。 - 在左侧 Activities 面板中展开 General,将 Web 活动拖到内部画布。
- 为其命名,例如
CallSERPAPI。
配置 Web 活动
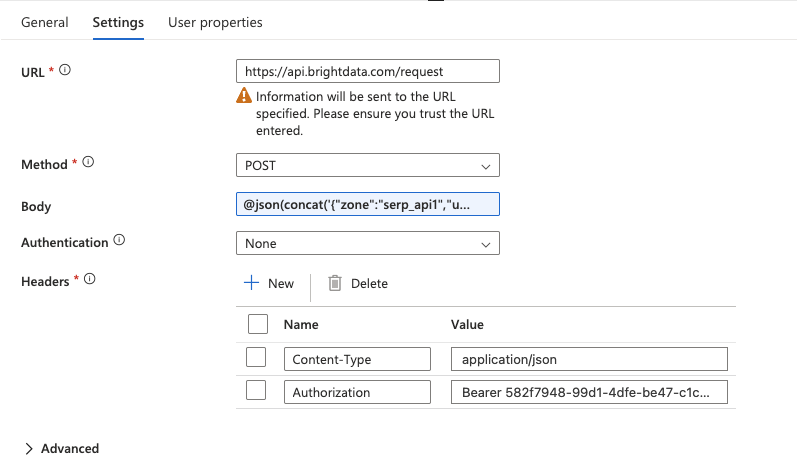
点击 Web 活动以选中它,然后进入 Settings 标签页并配置:
- URL:直接在字段中输入完整 API 端点:
https://api.brightdata.com/request- Method:从下拉框选择
POST。 - Headers:点击 + Add header 两次,添加:Name Value
Content-Typeapplication/jsonAuthorizationBearer YOUR_BRIGHT_DATA_API_KEY - Body:在这里传入 SERP API 请求,并使用 ForEach 循环中的当前关键词。请将以下表达式直接输入到 Body 字段(不要使用 “Add dynamic content” 弹窗):
@concat('{"zone":"YOUR_SERP_API_ZONE","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')将 YOUR_SERP_API_ZONE 替换为 Bright Data 控制台中的真实 zone 名称。
重要:
@必须是字段中的第一个字符,前面不能有任何空格。这会告诉 Synapse 将该文本作为表达式进行计算。如果输入正确,该字段会高亮表达式;如果显示为普通文本,请删除并重新输入,确保@在第 0 个位置。这段表达式做了什么:
item()会返回 ForEach 循环中的当前关键词(例如"web scraping tools")。replace()将空格替换为+,以形成合法的 URL 查询参数。concat()将完整 JSON 请求体拼接为一段字符串。
- Authentication:设置为
None(认证已通过 Authorization header 处理)。
添加一个定时触发器
- 回到主 pipeline 画布,点击 Add trigger > New/Edit。
- 选择 New 并设置每天一次的触发(例如 UTC 时间 06:00)。
- 点击 OK,然后点击 Publish all 以保存并部署 pipeline。
要立即测试,点击 Trigger now > OK。进入 Monitor > Pipeline runs 观察执行情况。你应该会看到 pipeline 运行成功,并在数据湖的 raw/serp/ 路径下看到 JSON 文件。
返回主 Pipeline 画布
点击设计器顶部面包屑中的 pipeline 名称(IngestSERPData)返回主画布。你应该会看到 ForEach 活动,并带有标识,表明其中包含子活动。
添加一个定时触发器
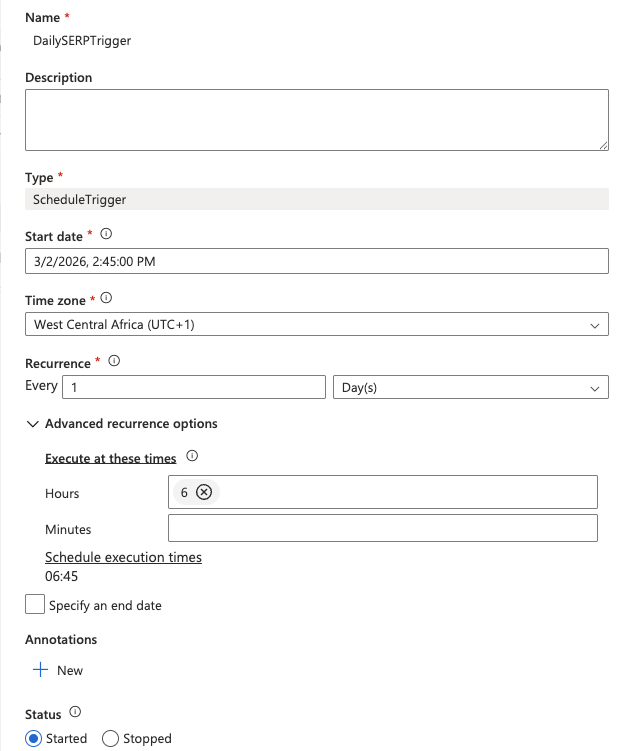
- 在 pipeline 设计器顶部点击 Add trigger > New/Edit。
- 在下拉框中选择 New。
- 为触发器命名(例如
DailySERPTrigger),将 Type 设置为 Schedule,并配置:
- Start date:今天日期
- Recurrence:每
1Day - At these hours:
6(UTC 时间 06:00)
- 点击 OK,然后确认触发器参数。
- 点击 Synapse Studio 顶部的 Publish all 保存并部署所有内容。
测试 Pipeline
若要立即运行 pipeline 而不等待定时触发器:
- 在 pipeline 设计器顶部点击 Trigger now > OK。
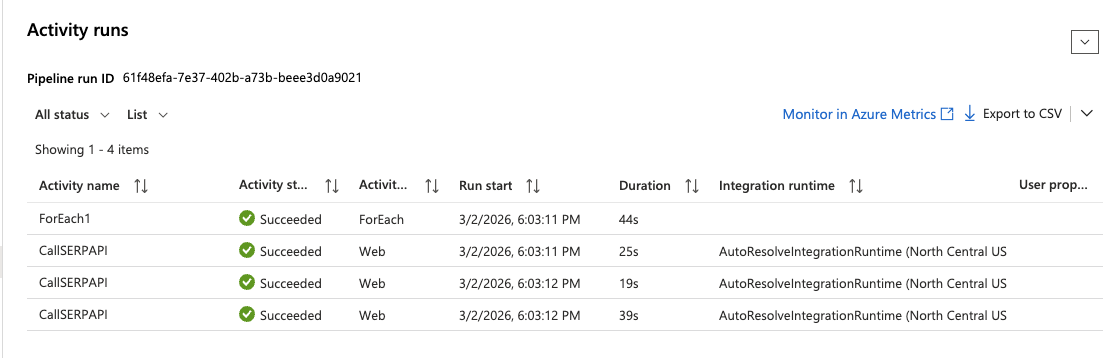
- 在左侧菜单进入 Monitor > Pipeline runs。
- 等待运行完成,你应该会看到绿色的 Succeeded 状态。
- 点击该 run,并展开 ForEach 活动以检查每次 Web activity 的执行情况。点击任意
CallSERPAPI迭代,即可在 Output 区域查看完整 API 响应。
步骤 4:使用 Apache Spark 采集并转换数据
步骤 3 的 Web activity 验证了 SERP API 集成可用,并展示了带定时调度的流水线编排。接下来在数据采集与转换环节,你将使用一个 Apache Spark notebook:通过 Python 直接调用 SERP API,把原始响应保存到数据湖,并将其转换为可分析的 Delta 表。
这在数据工程中是标准做法:pipeline 负责编排与调度,而 notebook 负责具体的数据处理逻辑。
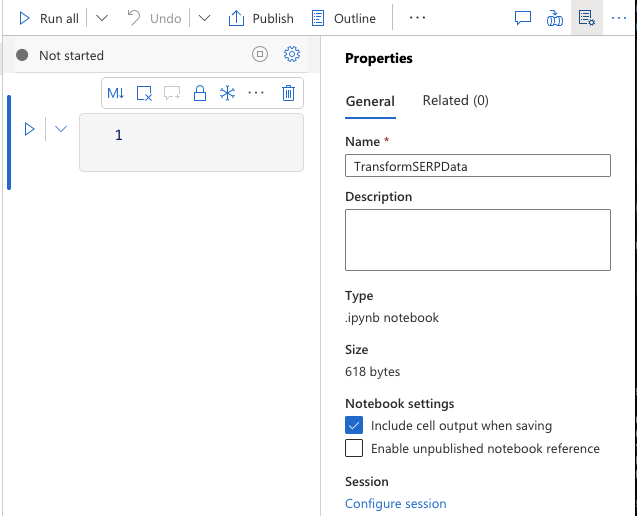
创建一个 Spark notebook
- 进入 Develop > + > Notebook。
- 将其命名为
TransformSERPData。 - 将其绑定到你的
sparkpoolApache Spark pool。 - 确保语言选择为 PySpark (Python)。
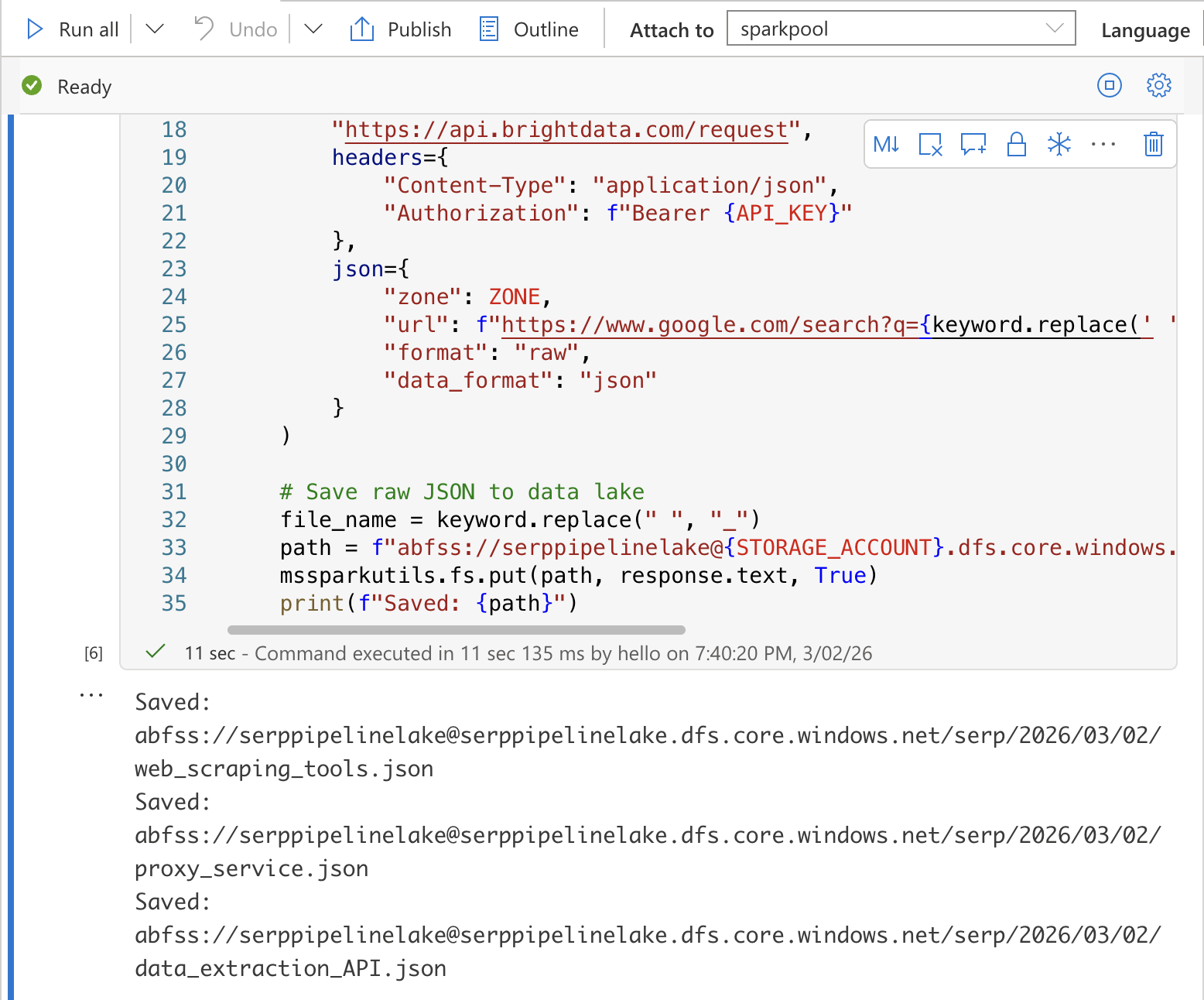
Cell 1:采集 SERP 数据并保存到数据湖
在第一个单元格中添加以下代码。它会针对每个关键词调用 Bright Data SERP API,并将原始 JSON 响应保存到数据湖:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Configuration
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
ZONE = "YOUR_SERP_API_ZONE"
STORAGE_ACCOUNT = "YOUR_STORAGE_ACCOUNT"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Collect SERP data for each keyword
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Call the Bright Data SERP API
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zone": ZONE,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# Save raw JSON to data lake
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"Saved: {path}")将 YOUR_BRIGHT_DATA_API_KEY、YOUR_SERP_API_ZONE 和 YOUR_STORAGE_ACCOUNT 替换为你的实际值。
安全提示:在生产环境中,请将 API key 存储在 Azure Key Vault 中,并使用
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")获取,而不是硬编码在代码里。
按 Shift + Enter 运行该单元格。你应当看到输出确认每个文件都已保存到数据湖。
Cell 2:转换并打平 SERP 数据
在新的单元格中添加转换代码:读取原始 JSON,并将其打平成结构化表:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# Read raw SERP data from the data lake
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json"
)
# Flatten: extract the keyword from general.query and explode organic results
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at")
)
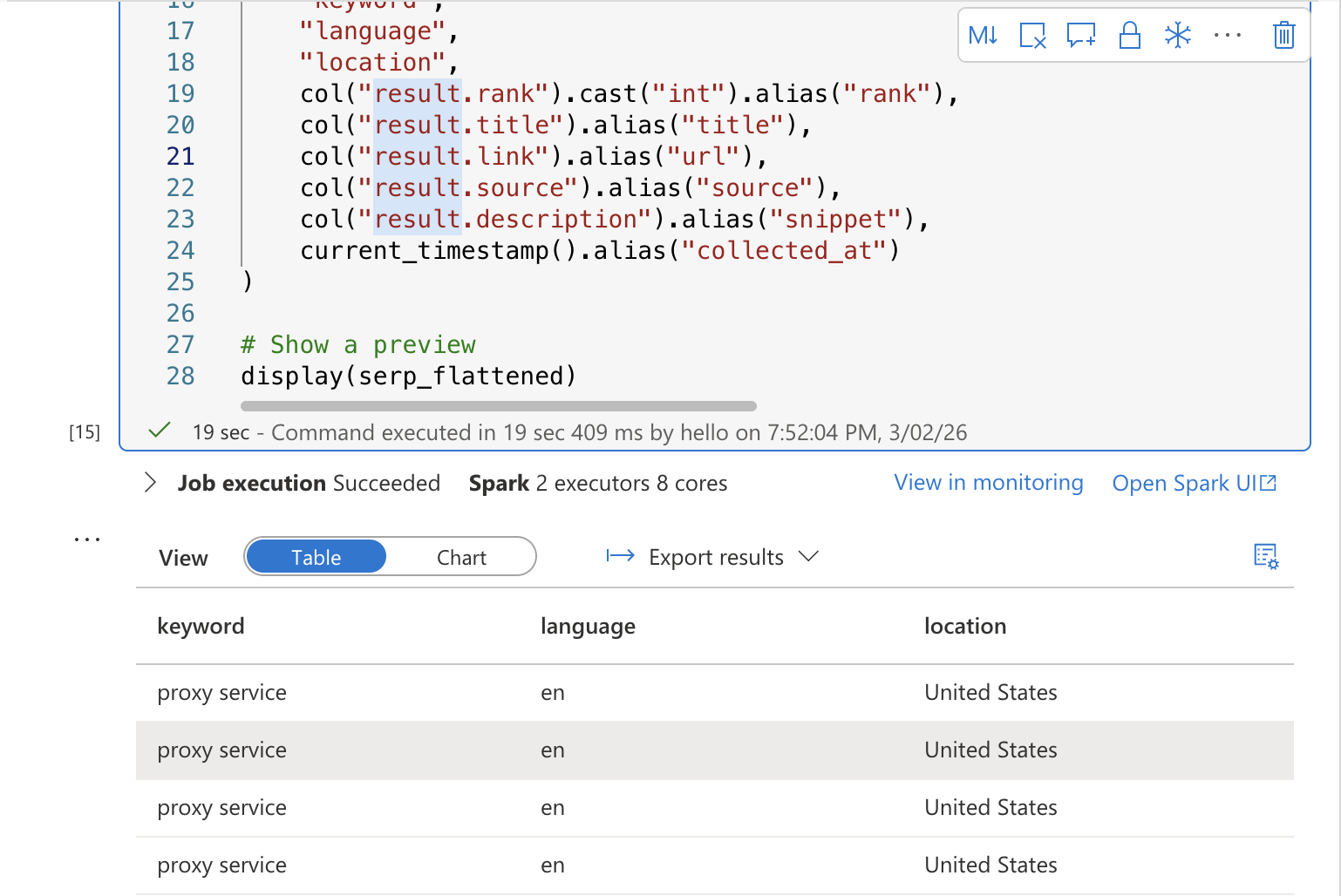
# Show a preview
display(serp_flattened)运行该单元格。你应当会看到一个预览表格,展示打平后的 SERP 结果,并包含关键词、排名、标题、URL、摘要片段与采集时间戳等列。
Cell 3:保存到 Delta 表
在第三个单元格中,将转换后的数据写入 Delta 表以便进行 SQL 分析:
# Write transformed data as a Delta table to your data lake
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("Data written to curated/serp_rankings") 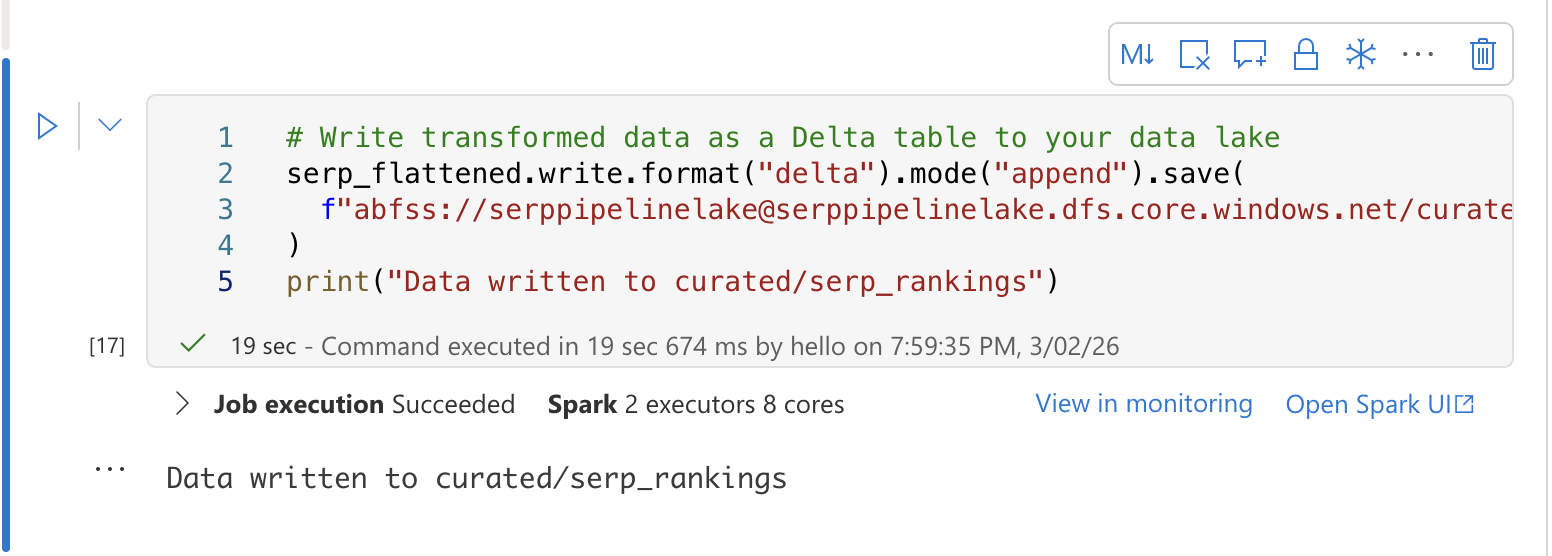
将 Notebook 添加到 Pipeline 中
- 回到 Integrate hub 中的
IngestSERPDatapipeline。 - 将 Notebook 活动拖到画布上,放在 ForEach 活动之外并位于其后。
- 在 Settings 标签页选择
TransformSERPDatanotebook,并将其绑定到sparkpool。 - 将 ForEach 活动通过 Success 依赖关系(拖动绿色箭头)连接到 Notebook 活动。
- 点击 Publish all 保存。
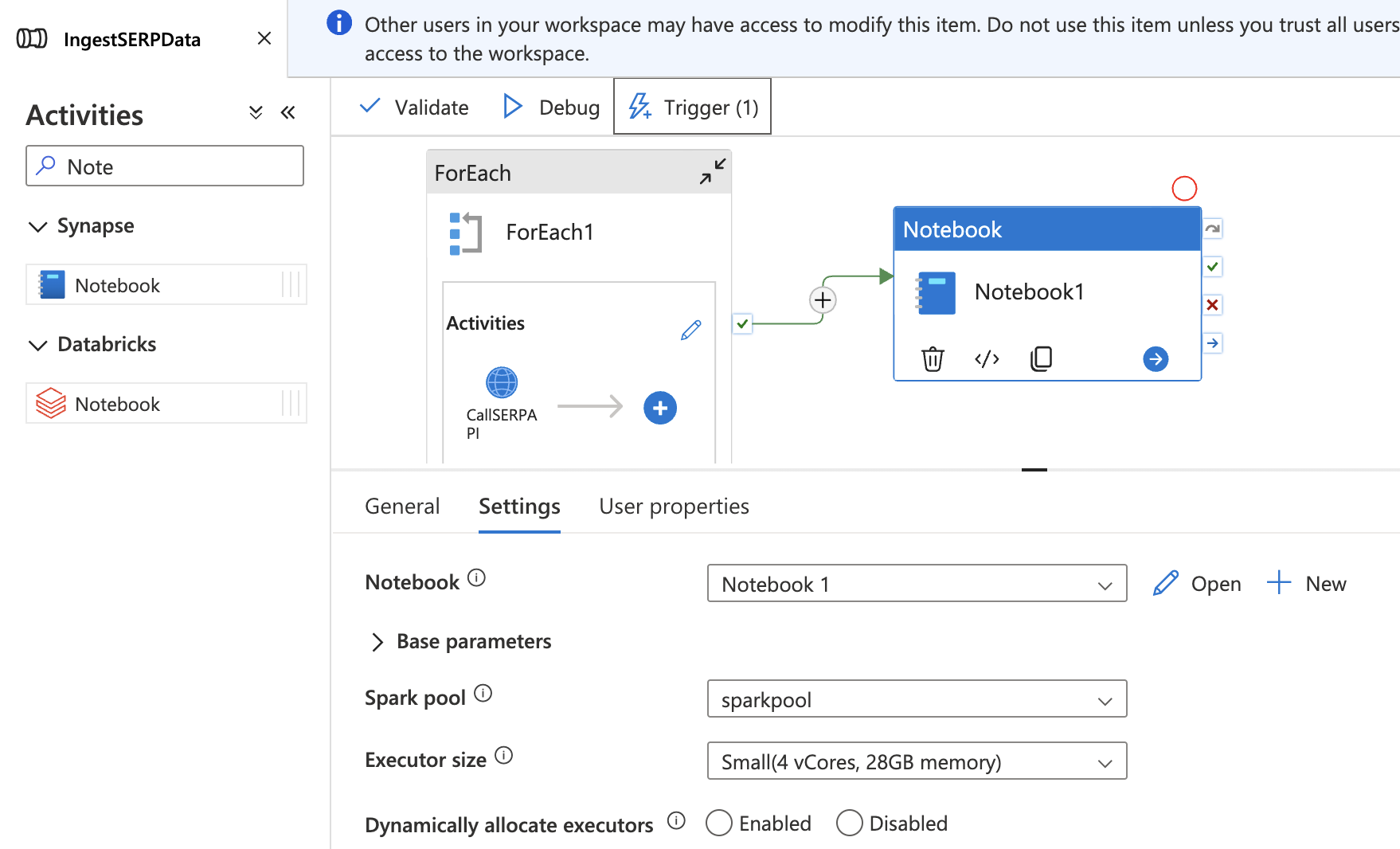
现在整条 pipeline 就实现了端到端运行:采集 SERP 数据 → 落地到数据湖 → 转换为 Delta 表。
步骤 5:使用 SQL 分析排名
当数据进入 Delta 表后,你可以直接使用 Synapse 的无服务器 SQL 池(serverless SQL pool)进行查询——无需额外资源预配。无服务器 SQL 池通过 OPENROWSET 函数直接读取数据湖中的 Delta 文件。
创建数据库
进入 Develop > + > SQL script。确保在脚本编辑器顶部选择的是 Built-in(serverless)SQL pool。运行以下语句,为 SERP 分析创建一个专用数据库:
CREATE DATABASE serp_analytics;数据库创建后,在脚本编辑器顶部的数据库下拉菜单中选择 serp_analytics 以切换到该数据库。
追踪随时间变化的排名波动
创建一个新的 SQL 脚本(或清空之前的脚本)并运行下面的查询。该查询通过 OPENROWSET 直接从数据湖读取 Delta 表:
-- See how rankings shift day over day for each keyword and URL
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA'
) AS serp_rankings
WHERE keyword = 'web scraping tools'
ORDER BY collected_at DESC, rank ASC;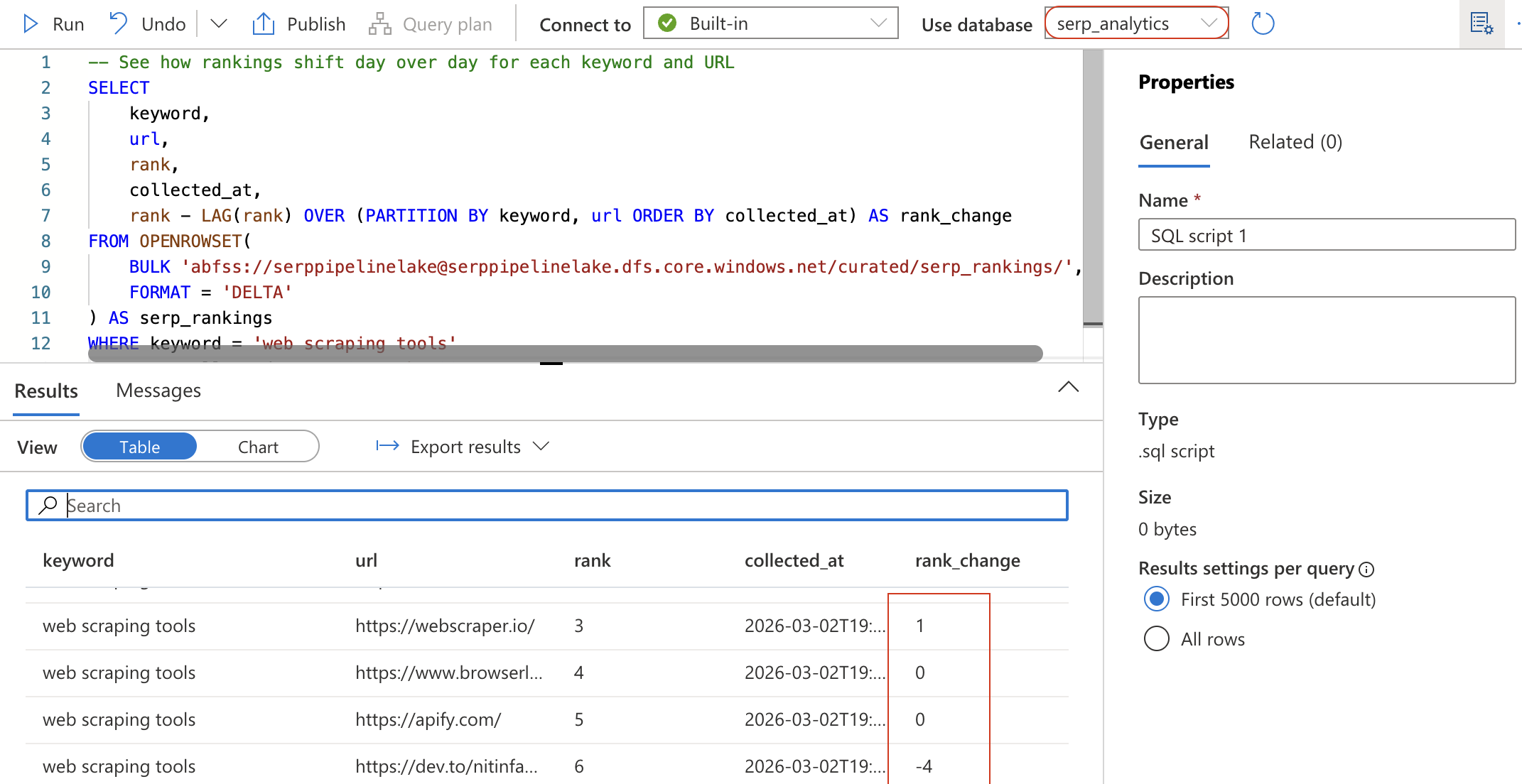
该查询使用 LAG 窗口函数来计算每个 URL 相比上一次采集时的排名变化。rank_change 为负值表示该 URL 排名上升(位置更靠前)。
为 Power BI 创建汇总视图
为了让 Power BI 更容易消费数据,可以创建一个视图来按关键词汇总每日排名:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA'
) AS serp_rankings
GROUP BY keyword, CAST(collected_at AS DATE);点击 Run。这会创建一个视图——即一个可以按名称引用的已保存查询。通过运行以下语句验证它是否可用:
SELECT * FROM daily_serp_summary;你应该会看到每个关键词每天一行数据,包含总结果数、平均排名与最佳排名。
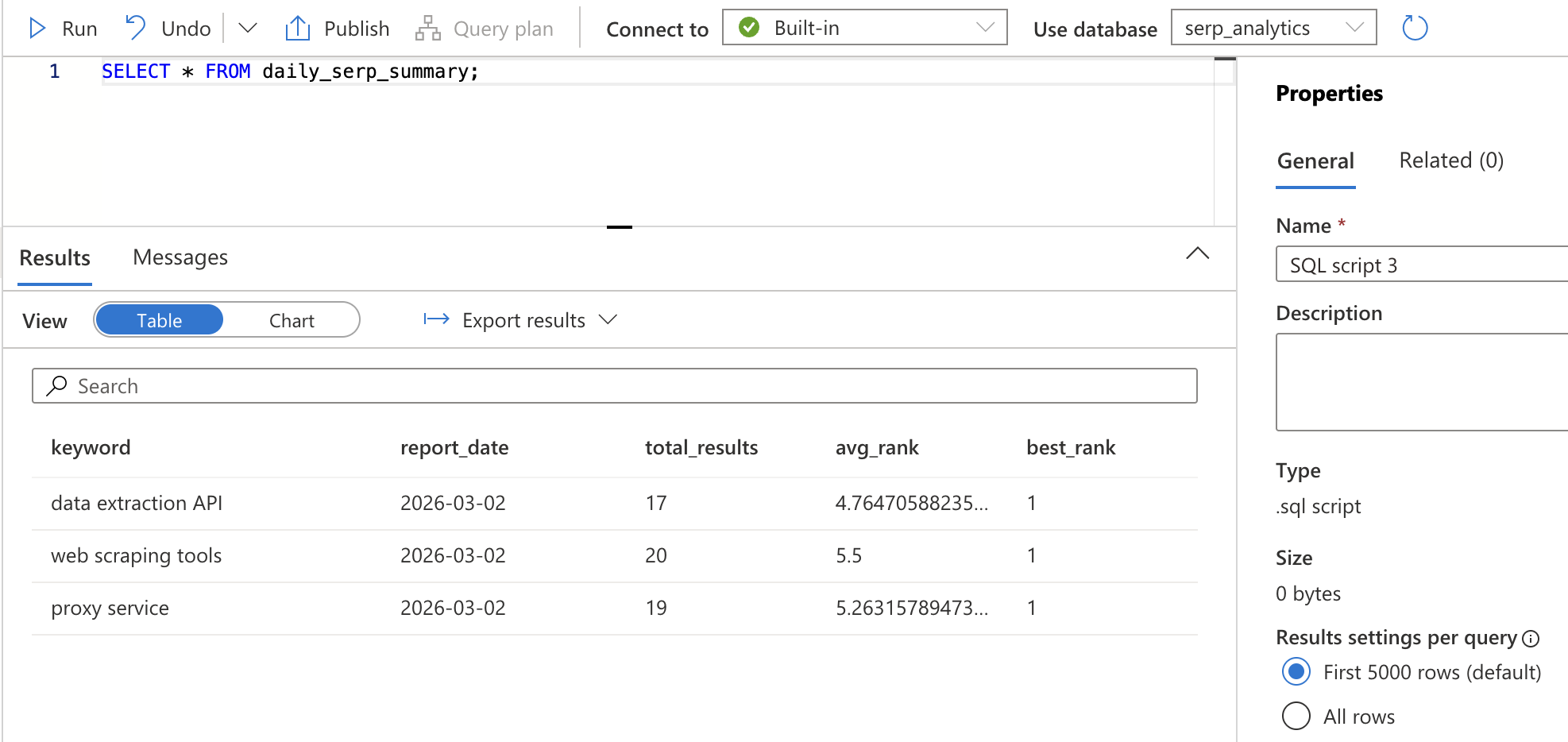
步骤 6:检查结果
当整条 pipeline 运行完成后,你可以在 Synapse Studio 中检查每一个阶段。
进入 Monitor > Pipeline runs 并点击最近一次运行进行检查。你会看到每一步的可视化展示,其中包括:
- ForEach 活动:显示每个关键词的迭代与 Web 活动结果。
- Notebook 活动:显示 Spark 作业执行详情。
展开 ForEach 活动,验证是否已为每个关键词成功拉取 SERP 数据。进入任意 CallSERPAPI Web 活动运行,可以在 Input 与 Output 区域查看请求/响应详情。
进入 Data > Linked > 你的存储账户,浏览 raw/serp/ 文件夹中的原始 JSON 文件。你应当能看到按日期分区的文件夹,并且每个关键词对应一个 JSON 文件。
最后,打开 Develop hub,进入你的 TransformSERPData notebook,并通过运行以下语句检查 Delta 表:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;你应该会看到结构化的数据行,包含关键词、排名、标题、URL、摘要片段与采集时间戳——这些是由原始 SERP 结果构建出来的干净、可分析数据。Bright Data 的 SERP API 负责了最难的部分:以规模化方式可靠获取 Google 搜索结果、绕过反爬机制与限流器,并返回可直接用于流水线的结构化数据。
更进一步
这个示例展示了关键词排名追踪器,但你可以从多个方向扩展你的 Synapse pipeline:
- 将 SERP API 调用替换为 Bright Data 的 Web Scraper API,采集商品价格、评论或职位列表,并构建竞争性价格情报仪表盘。
- 添加第二个 Spark notebook,对 SERP 摘要片段运行情绪分析,为每条结果打分以判断正负向表述。
- 将 curated Delta 表连接到 Azure Machine Learning 做预测分析,例如预测排名变化或识别新兴搜索趋势。
- 构建混合云架构:SERP 数据落地到 Azure Data Lake,而敏感内部数据保留在本地,通过 Synapse 联邦查询同时查询两端数据。
- 将转换后的数据转发到 Azure AI Foundry 的 prompt flow 做基于 LLM 的分析,将 Synapse 的数据工程能力与 AI Foundry 的 AI 能力结合起来。
- 与 LangChain 或 CrewAI 等工具集成,构建可消费 curated SERP 数据的 agentic 工作流。
可能性几乎是无限的!
结论
在这篇博客文章中,你学习了如何使用 Bright Data 的 SERP API 从 Google 获取最新搜索结果,并将其集成到 Azure Synapse Analytics 的完整数据流水线中。
这里展示的 pipeline 非常适合想要构建自动化关键词排名追踪器的人:它能够持续采集 SERP 数据,将其转换为可分析表,并通过 SQL 查询与 Power BI 仪表盘输出洞察。不同于更适合 AI 优先的提示词工程与 RAG 工作流的 Azure AI Foundry,Azure Synapse Analytics 更擅长面向商业智能与分析场景的大规模数据摄取、转换与入仓。
若要创建更高级的数据流水线,请探索 Bright Data 的完整网页抓取工具套件,用于检索、校验与转换实时 Web 数据。关于数据流水线架构模式的更深入内容,Bright Data 博客也覆盖了相关基础知识。
立即免费注册 Bright Data 账号,开始体验我们面向 AI 的 Web 数据解决方案!



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。





