
FlareSolverr 是一个开源工具,可用于绕过 Cloudflare 挑战及 DDoS-Guard 防护。它通过在您的请求间设置代理服务器,模拟 Chrome 浏览器来通过安全检查,并展示网站内容。
在本文中,您将学习如何设置 FlareSolverr 并在网络爬取流程中配置此工具。您还将探索一些绕过网站安全挑战的可选方法。
FlareSolverr 的实现
FlareSolverr 提供了多种安装方式。然而,推荐使用 Docker 来保证一致性部署,因为它会将所有依赖项和配置都打包进您的 Docker 容器中。
使用 Docker 设置 FlareSolverr
在您的设备上安装了Docker后,您即可下载最新版本的 FlareSolverr。该版本可从DockerHub、GitHub Registry以及社区更新的仓库获取。以下 shell 命令会拉取最新的 FlareSolverr Docker 镜像:
docker pull 21hsmw/flaresolverr:nodriver您可以运行 docker image ls 命令来确认该镜像是否已存在于您的系统:

FlareSolverr 在您的设备上以代理服务器的形式运行,因此您需要指定可供其服务并访问的端口。下面的命令将 8191 设置为 FlareSolverr 的端口,并基于该服务创建一个容器:
docker run -d --name flaresolverr -p 8191:8191 21hsmw/flaresolverr:nodriver您也可以在 Docker 运行时配置环境变量。FlareSolverr 提供选项来设置服务器的日志记录跟监控、所使用的时区和语言,以及您想要启用的任何 CAPTCHA 解题机制。对于本教程,默认的 Docker 设置已经足够。
您可以在浏览器中访问 http://localhost:8191 来确认 FlareSolverr 是否正在运行:
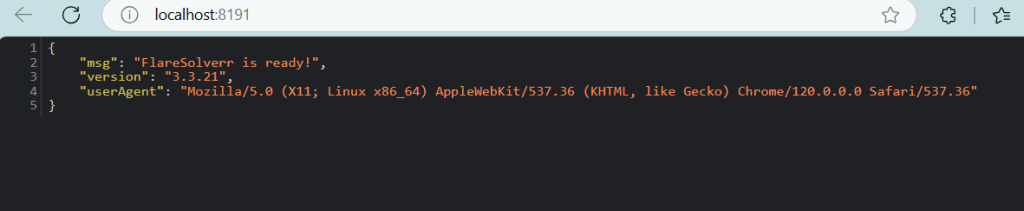
获取前置条件
本教程针对 Python 环境编写。除了安装 FlareSolverr 和 Docker 之外,您可能还需要安装一些 Python 包,比如 Beautiful Soup。
点击此处,了解更多关于使用 BeautifulSoup 进行网络爬取的内容。
使用 FlareSolverr 进行数据爬取
注意:始终遵守您要爬取的网站的服务条款。不当使用公开可获取的数据,可能会引发 IP 封禁等问题,甚至带来法律后果。
使用 FlareSolverr 进行爬取与常规的爬取流程非常相似,只不过您的目标网站与请求参数将发送到 FlareSolverr 服务器。该服务器会启动一个带有网站参数的浏览器实例,并在通过 Cloudflare 验证后向您返回网站内容。您可以通过curl 执行、Python 脚本或第三方程序向 FlareSolverr 服务器发送请求。
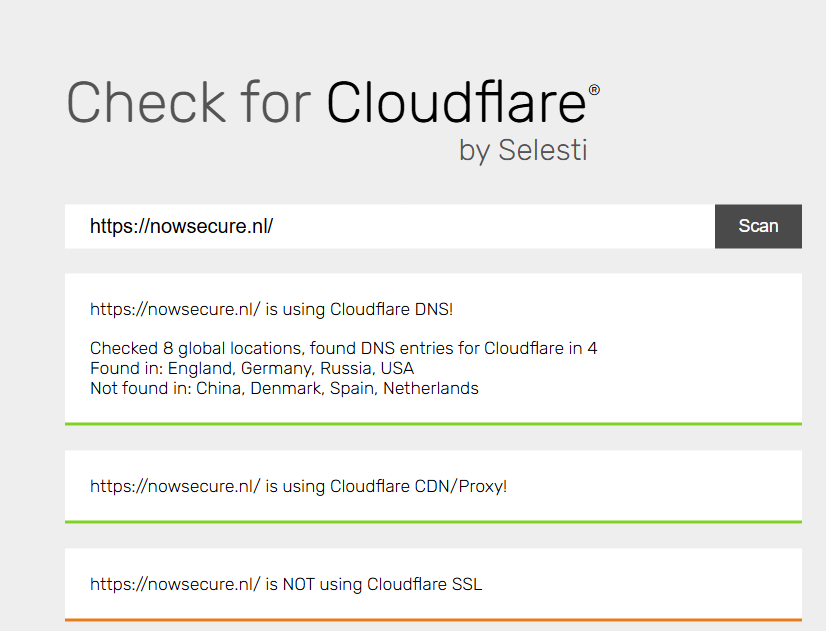
您可以通过在其 HTML 代码、响应头或 DNS 记录中查找对 Cloudflare 的引用,来确认一个网站是否使用了 Cloudflare 防护。您也可以使用例如Check for Cloudflare等第三方工具进行检测:
让我们用 Python 测试 FlareSolverr 的流程。请在您的环境中新建一个 Python 文件,并复制以下脚本。该示例脚本将从一个受 Cloudflare 保护的网站获取 HTML 内容:
# import Requests python library
import requests
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))此脚本会向您的 FlareSolverr 服务器发送请求来爬取 Temu 网站。FlareSolverr 检测到目标网站上的 Cloudflare 验证后通过挑战,然后向您返回 HTML 内容和会话信息。
要执行您的 Python 脚本,可以使用如下 CLI 命令:python3 <scriptname>.py:
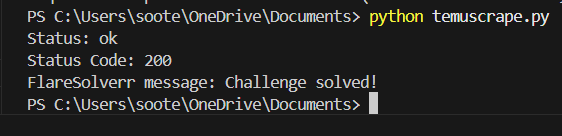
是否会触发 Cloudflare 验证在一定程度上取决于您的 IP 以及目标网站的安全设置。在绕过 Cloudflare 验证后,您可以使用 Beautiful Soup 或其他 Python 库照常解析 HTML 内容。
请确保您的环境中已安装所需的 Python 包。您可以使用pip 包管理器执行 pip install bs4 命令来进行安装。
让我们来演示一下爬取过程。首先,获取所需信息的正确 HTML 标签。这里展示了文章标题和作者姓名:
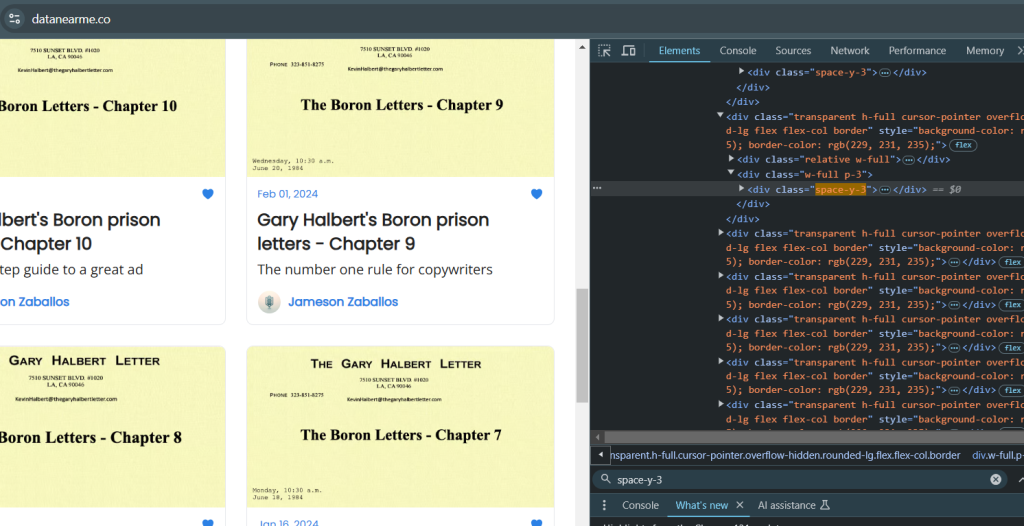
基于这些信息,您可使用对应的标签编写脚本来解析数据:
# import python libraries
import requests
from bs4 import BeautifulSoup
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))
# parse logic
page_content = response.json().get('solution', {}).get('response', '')
soup = BeautifulSoup(page_content, 'html.parser')
# find the div with class 'space-y-3'
target_div = soup.find('div', class_='space-y-3')
# article author
spans = target_div.find_all('span')
span_element = spans[-1]
span_text = span_element.get_text(strip=True)
# article title
h2_element = target_div.find('h2', class_=['font-semibold', 'font-poppins'])
h2_text = h2_element.get_text(strip=True)
print(f"article author: ",span_text, " article title: ", h2_text)
该脚本首先绕过站点的 Cloudflare 挑战,返回 HTML 内容后,再使用 Beautiful Soup 解析所需信息。您可使用 python <scriptname>.py 命令来执行更新后的 Python 文件:
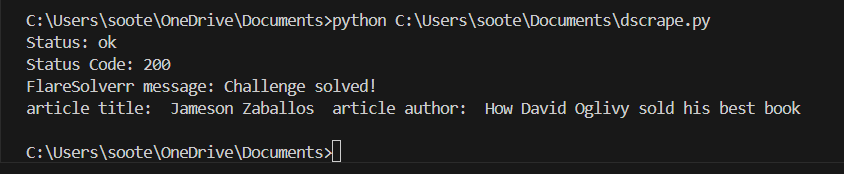
FlareSolverr 是一个灵活的工具,可以集成到您的爬取流程中并可扩展以适应更复杂的使用场景。对于存在地域封禁和限制的网站,您还可以结合 FlareSolverr 的代理支持功能进行使用。下一节将详细介绍如何操作。
在 FlareSolverr 中使用代理
在网络爬取策略中使用代理可以提升效率,并使爬取更加可持续。代理可以帮助您绕过地理限制和 IP 封禁,隐藏您的网络身份以获得更好的匿名性,也便于大规模爬取时进行并发请求,从而避免触发网站的速率限制。根据代理的质量,您的请求能够更好地模拟真实用户行为,从而降低被网站监测系统阻断的概率。
按照用途和功能,您可以使用移动代理、住宅代理或数据中心代理等。移动代理使用电信公司分配的真实 IP,通过移动网络(3G、4G、5G)路由流量。因为同一 IP 会被大量用户在不同时段共享,这类代理难以被精准追踪,也不太容易触发 CAPTCHA、Cloudflare 或其他安全挑战,但它通常成本较高,速度也会相对较慢。
住宅代理则利用了真实的用户 IP,能够更好地伪装爬取行为。它同样费用较高,但不具备移动代理那般高度匿名性;如果过度使用或行为可疑,住宅 IP 依旧可能被封禁。它最适合绕过地理限制和监控。数据中心代理来自云或数据中心服务器,与 ISP 无关,成本低廉且速度快,适合大批量爬取。不过,它们模拟真实用户行为的能力较弱,更容易触发风控与访问限制。
您可以通过在请求负载中指定代理,为您的 FlareSolverr 请求添加代理支持。虽然免费公共代理在网上很容易找到,但对于需要稳定性的生产环境而言,使用托管代理服务通常更好。
下面的示例脚本展示了如何为 FlareSolverr 请求集成来自 BrightData 的轮换代理:
import requests
import random
proxy_list = [
'185.150.85.170',
'45.154.194.148',
'104.244.83.140',
'58.97.241.46',
'103.250.82.245',
'83.229.13.167',
]
proxy_ip = random.choice(proxy_list)
proxies = {
'http': f'http://{proxy_ip}',
'https': f'https://{proxy_ip}',
}
payload = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
response = requests.post(url, headers=headers, json=data, proxies=proxies)
print("Status Code:", response.status_code)在生产环境中,您可以维护一个更大的代理列表,并在每次请求前进行轮换,以确保在进行网络爬取时具有更多变换的代理选择。
管理会话与处理 Cookies
Cookie 是 Cloudflare 用来管理用户流量并防范重复恶意请求的手段,它能够在不消耗大量资源的情况下,为每个请求提供安全验证。FlareSolverr 会在其返回的 JSON 中收集并传递这些 Cookie 数据,从而在后续请求中帮助您免于再次重复挑战。

FlareSolverr 提供了会话管理功能,以便在多个请求间保持一致性。一旦创建了会话,浏览器实例会一直保留所有的 Cookie,直到您销毁会话为止。这能在您爬取时带来更好的扩展性与更快的响应速度。
以下示例展示了如何在代码脚本中创建会话:
import requests
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "sessions.create",
}
response = requests.post(url, headers=headers, json=data)
print(response.text)
在请求负载中将命令改为 sessions.create(而不是 request.get)即可创建会话,而 url 值并不是此命令所必需,但您可以为该会话配置代理。查看 FlareSolverr 的命令结构,了解 sessions.destroy、sessions.list 以及 post 请求等其他可用命令:

随后,您可以将会话 ID 值添加到请求中来使用已创建的会话:
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":"<SESSION_ID>"
}
response = requests.post(url, headers=headers, json=data)
print(response.text)其中的 maxTimeout 值决定了请求的最长执行时间(毫秒)。若在规定时间内无响应,就会报错。下面是一个结合创建会话与使用会话 ID 的完整示例脚本:
import requests
import time
# creating the session
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
first_request = {
"cmd": "sessions.create",
}
first_response = requests.post(url, headers=headers, json=first_request)
session_id = first_response.json().get('session', {})
# using the session id
second_request = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":f"{session_id}"
}
second_response = requests.post(url, headers=headers, json=second_request)
print("Status:", second_response.json().get('status', {}))您可以在此 GitHub 仓库中查看所有示例 Python 脚本。
至此,您已经了解了如何使用 FlareSolverr 发送请求并解析响应,但同样重要的是要知道如何在出现错误时进行处理。
FlareSolverr 请求的故障排查
Cloudflare 会频繁更新其安全协议,而不同的网站及用例也可能导致意料之外的行为。本节将介绍一些常见错误、FlareSolverr 的处理方式以及您可采用的应对方法。
在排查爬取请求时,建议首先执行以下步骤:
- 确认您的 FlareSolverr 服务是否已启动并可访问:检查本地或自定义主机上的 Docker 容器是否出现超时或连接故障。
- 检查日志:FlareSolverr 日志包含详细的运行信息,可用于调试和优化,也可协助您在社区进行求助。
以下是一些常见错误与解决思路:
- Repeated challenge/CAPTCHA failures(重复出现挑战/CAPTCHA 失败):这可能表示目标网站将您的请求标记为可疑。您可尝试调整请求方式并切换代理,以更好地模拟真实用户行为。同时注意 Cookie 可能会过期,因此需要定期刷新,并确保保留会话信息。
Challenge not detected错误:这可能是由于未触发挑战、不兼容特定的安全措施、FlareSolverr 版本过旧,或者是挑战被刻意隐藏。如果未检测到挑战也能成功获取内容,则暂时不必处理。但若不行,请尝试更新 FlareSolverr 版本并重新测试以定位问题。Cookies Provided by FlareSolverr Are Not Valid错误:当 FlareSolverr 返回的 Cookie 失效时就会出现此问题,通常由 Docker 与 FlareSolverr 间的 IP 或网络不匹配引起。
如果遇到上述未涵盖的其他问题,您可以在网上寻求更多信息。FlareSolverr 拥有庞大的开源社区,大多数常见难题往往都已有人讨论并给出了可行的解决方案。
FlareSolverr 替代方案
FlareSolverr 是一个开源工具,比较适合具备一定技术能力的用户。由于 Cloudflare 不断更新其安全机制,这可能导致 FlareSolverr 无法即时适配,对时间敏感型的操作会造成影响。此外,截至 2026 年 1 月,FlareSolverr 的CAPTCHA 解题功能尚未恢复,对部分网站的Cloudflare 挑战也还无法绕过。
如果您需要更大规模的爬取,或需要更强大的 Cloudflare 绕过功能,下列替代方案可提供更多特性与更高的可靠性:
- 爬取浏览器: 这是一种专门为网络爬取设计的图形界面浏览器,带有自动代理轮换和内置 CAPTCHA 解题等功能。Bright Data 抓取浏览器 还能方便地与 Playwright、Puppeteer、Selenium 等框架集成,可在可视化浏览器环境中大规模进行自动化数据采集。
- 网络抓取 APIs: 这类 API 已经对特定目标站点进行了适配,能够按需获取数据,而无需手动维护爬虫流程,使用简单且能进行批量数据调用。Bright Data 网络抓取 API 可连接多个热门网站,如 LinkedIn、Zillow、Yelp、Instagram 等,实现 100% 合规的数据收集。
- 按需数据集: 这是一种托管服务方式,可直接提供所需数据集,免去自行维护的麻烦。Bright Data 提供众多热门数据集,如 LinkedIn、Instagram、Walmart、Shein 产品及 Booking.com 列表等,并会定期更新,您可以基于订阅进行访问。
- 托管爬取方案: 最后,完整的托管解决方案可帮助您在多数网站安全机制下轻松爬取,包括 JavaScript 渲染、浏览器指纹、验证码处理和地理位置切换等功能。例如,Bright Data 的网络解锁器 就能解锁几乎任何域名。
总结
在本文中,您了解了 FlareSolverr 及其如何绕过 Cloudflare 验证,并学习了如何在多代理环境中配置 FlareSolverr,保持对多次请求的数据访问。我们还探讨了常见错误的排查及相应的解决思路。
如果您想使用更稳定且合规的数据采集工具,我们的 Scraping Browser 和 Web Scrapers 能为您的爬取流程提供具有高成功率的优化服务,包括可靠的代理、直观的界面以及接近 100% 的网络爬取成功率。
立即注册并开启免费试用吧!





