在本文中,你将学习:
- 什么是 Alteryx One 以及它提供的功能。
- 为什么将其连接到来自 Bright Data 的网页数据会让工作流更具洞察力。
- 如何在 Alteryx One 中使用来自 Bright Data 网页抓取的结构化新鲜网页数据来定义自动化工作流。
让我们开始吧!
什么是 Alteryx One?
Alteryx One 是一个统一的、由 AI 驱动的分析平台。它将数据准备、分析、自动化和 AI 集成在一个环境中。具体来说,它帮助组织连接多个数据源,构建可复用的工作流,并以规模化方式将洞察落地。
Alteryx One 提供的主要功能包括:
- 原生 AI 分析:将 AI 集成到分析工作流中,以检测模式、生成洞察并支持预测建模,而无需单独的工具。
- AI 就绪的数据准备:连接、清洗并转换来自多个来源的数据,在内置治理的支持下生成可信、可用于分析的数据集。
- 工作流自动化:自动化重复性的分析任务和端到端流程,减少手动工作并提升一致性。
- 统一的分析工作区:提供一个单一环境,团队可以协作构建、运行和管理分析工作流。
- 企业级治理与安全:确保合规、血缘追踪和受控访问,使分析能够在大型组织中安全扩展。
- 可扩展的集成:与企业系统和 LLM 连接,将分析直接嵌入现有数据生态系统。
Bright Data 如何支持 Alteryx One
Alteryx One 工作流的强大程度取决于其所消费的数据。当然,该平台为数据准备、分析和自动化提供了强大的能力。然而,输入数据的质量、新鲜度和可靠性 最终决定了输出的准确性。这正是 Bright Data 作为企业级网页数据提供商!发挥关键作用的地方。
Bright Data 通过覆盖 195 个国家/地区、超过 4 亿 IP 的全球代理基础设施 提供大规模、结构化的网页数据。凭借 99.99% 的正常运行时间和 99.95% 的成功率,它提供了生产级分析管道所需的可靠性。
要与 Alteryx One 直接集成,你可以先使用 Bright Data 的网页爬虫工具 API 获取最新网页数据,或通过 Bright Data 数据集 访问静态网页数据。这些数据可以以结构化格式自动交付到 Amazon S3(或任何其他常见交付目的地)。
然后,Alteryx One 可以直接从 S3 导入该数据集,并通过无代码工作流进行处理。最后,处理后的结果会写回到 S3(或任何首选目的地)以供下游使用。
结果是一个自动化的端到端分析管道。在这里,Bright Data 确保可靠的企业级数据摄取,而 Alteryx One 将这些数据转化为可执行的洞察。
使用来自 Bright Data 的网页数据在 Alteryx One 中构建自动化数据分析工作流
在本逐步章节中,你将被引导完成在 Alteryx One 中设置自动化工作流。
为了演示这种网页自动化工作流,你将依赖以下组件:
- Bright Data 的 Yahoo Finance 抓取工具 用于收集最新股票数据,并将其配置为交付到 Amazon S3。
- 一个 Alteryx One 工作流,用于导入数据、按成交量排序,并将其拆分为两个数据集:一个用于上涨股票,一个用于下跌股票。然后,它将处理后的输出写回到 Amazon S3。
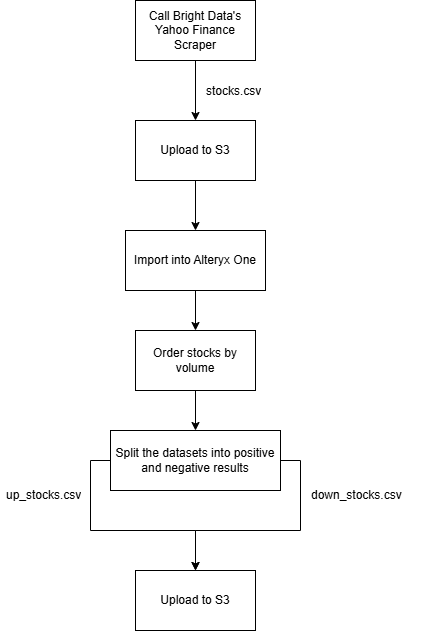
按照以下说明构建此工作流!
前提条件
要跟随本节内容,请确保你已具备:
- 一个 Alteryx One 账户(即使是 免费试用 账户也可以)。
- 在你的 AWS 账户中定义的一个 S3 bucket。
- 一个已配置 API key 的 Bright Data 账户。按照官方说明 生成你的 API key。
在本教程中,我们将假设你的 S3 bucket 名称为 bright-data-datasets。不过,任何其他 bucket 名称也同样适用。
第 #1 步:设置 Bright Data 爬虫 API
你的网页数据自动化管道的第一步是从网页检索源数据。为此,你将依赖 Bright Data 的 Yahoo Finance 爬虫工具来收集实时金融数据。让我们开始吧!
如果你还没有账户,请先创建一个 Bright Data 账户。否则,登录到你现有的账户。在控制面板中,导航到 “爬虫工具 > 抓取工具 Library” 页面:
搜索 “yahoo finance” 并选择 “finance.yahoo.com” 爬虫工具:
在 Yahoo Finance 抓取工具 页面,查看该爬虫工具的输入要求和输出 schema:
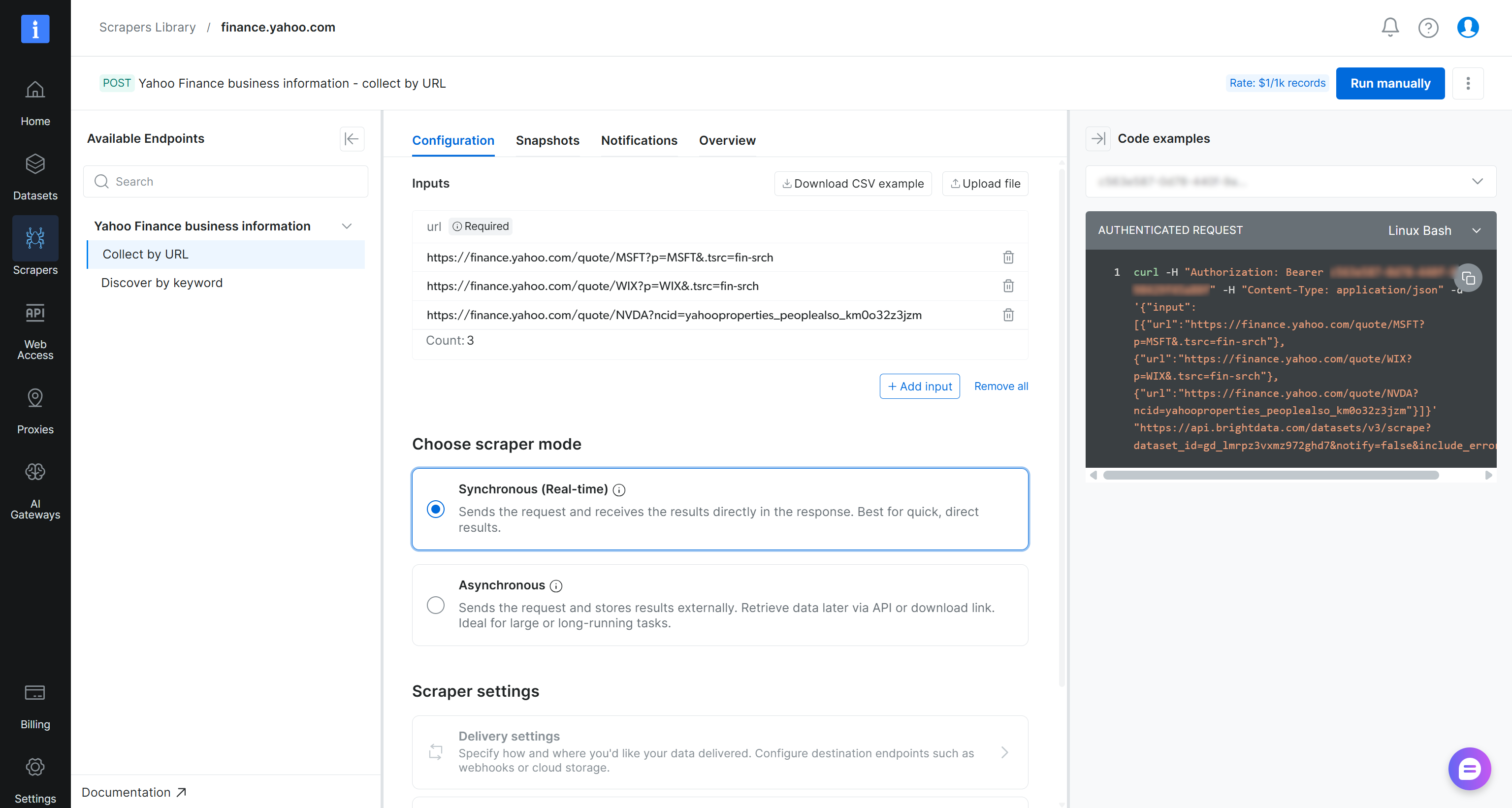
从高层来看,该爬虫工具接受一个或多个 Yahoo Finance 股票页面 URL 作为输入,并返回结构化的实时金融数据。正是我们需要的!
第 #2 步:配置 S3 交付
Bright Data 网页爬虫工具 API 支持 将抓取的数据自动交付到 Amazon S3(以及其他多个云存储提供商和交付方式)。要启用交付到 Amazon S3,你首先需要将爬虫工具切换为异步模式。
在 “Configuration” 选项卡中,选择 “Asynchronous” 选项。然后,点击 “Delivery settings”:
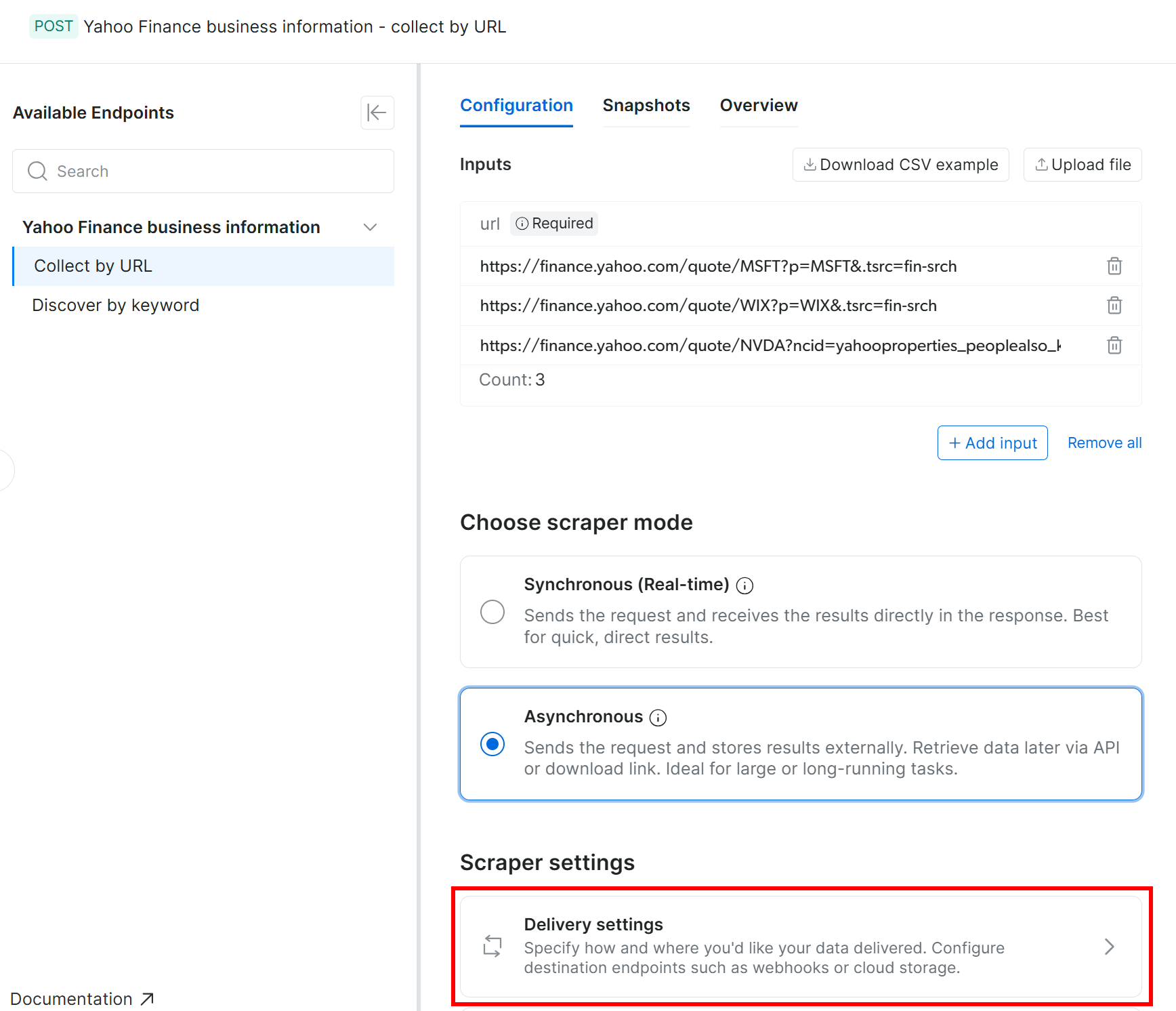
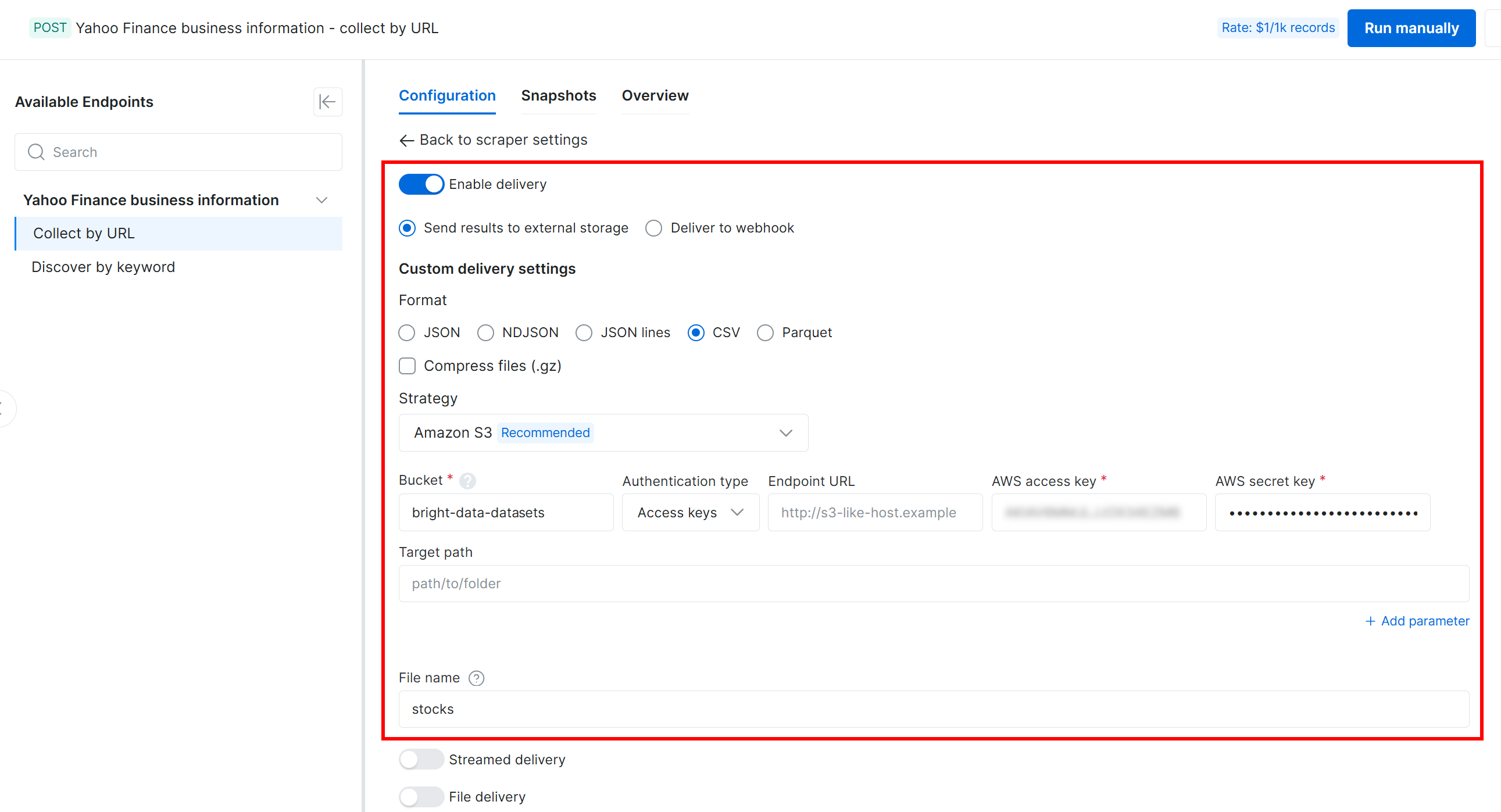
接下来,使用以下设置将交付配置到你的 Amazon S3 bucket:
- 启用 “Enable delivery” 开关。
- 将输出数据格式设置为 CSV。
- 选择 “Amazon S3” 作为存储目的地。
- 输入你的 S3 bucket 名称(在此示例中为
bright-data-datasets)。(你可以将 “Endpoint URL” 字段留空。) - 将 “Target path” 留空,以将文件上传到 bucket 的根文件夹。
- 将 “Authentication type” 选项设置为 “Access keys”。
- 粘贴你的 AWS Access Key ID 和 AWS Secret Access Key。
- 将文件名设置为
stocks。
通过此配置,网页爬虫工具 API 以异步模式运行。它不会立即返回数据,而是由 Bright Data 创建一个在其基础设施上执行的抓取任务。任务完成后,抓取的数据会自动上传到你的 Amazon S3 bucket。很好且无需人工干预!
第 #3 步:运行网页数据检索任务
为了验证网页数据提取工作流是否正常工作,请添加一些 Yahoo Finance 股票 URL 作为输入。在此示例中,我们将假设你想跟踪 纳斯达克前 10 只股票(即 NVDA、AAPL、GOOGL、MSFT、AMZN、TSLA、META、AVGO、WMT 和 AMD)。
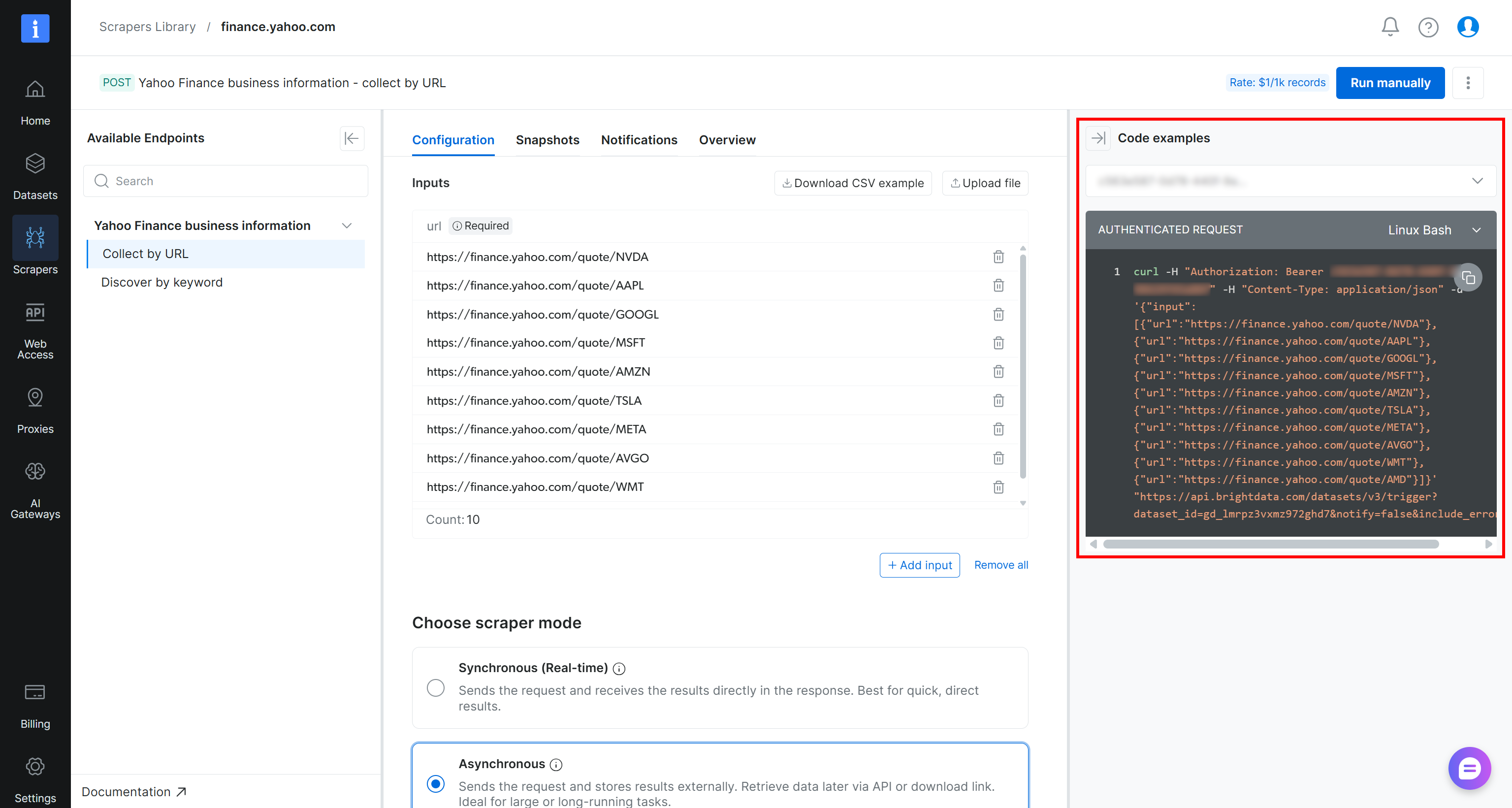
要以编程方式触发抓取任务,你可以使用爬虫工具页面上提供的 cURL 片段:
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"或者,你可以运行以下 Python 脚本:
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())在这两种情况下,请确保将 <YOUR_BRIGHT_DATA_API_KEY> 替换为你的 Bright Data API key。
注意:为了更简单的方法,可以直接从控制面板点击 “Run manually” 按钮来运行任务。
触发后,抓取请求将发送到 Bright Data 的云基础设施,提取任务将开始。你可以从 Bright Data 控制面板实时监控其状态:
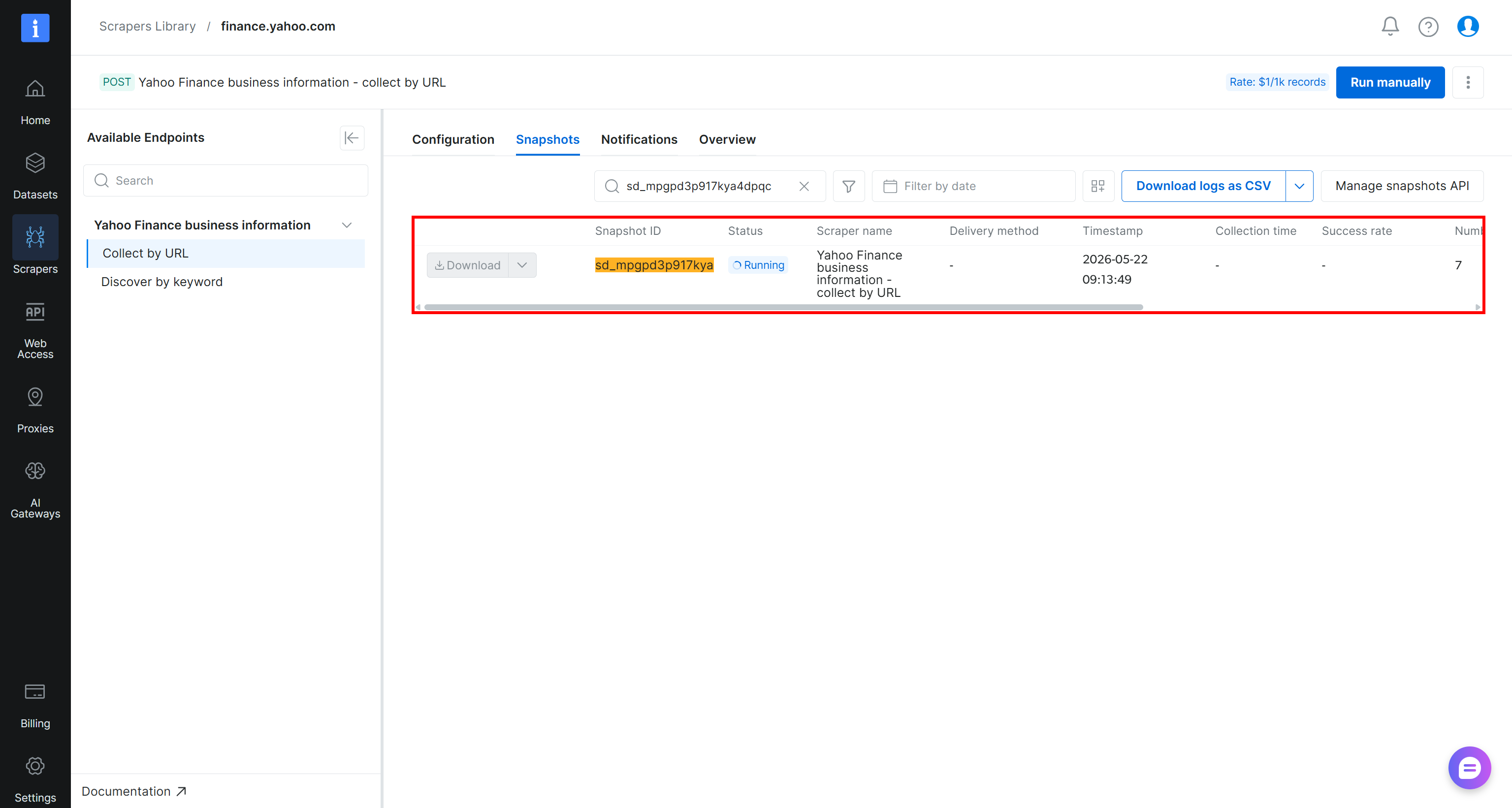
当任务状态变为 “Ready” 时,打开你的 Amazon S3 bucket。你应该会注意到一个名为 stocks.csv 的新文件:

下载 stocks.csv 文件并打开它。你将看到类似如下内容:
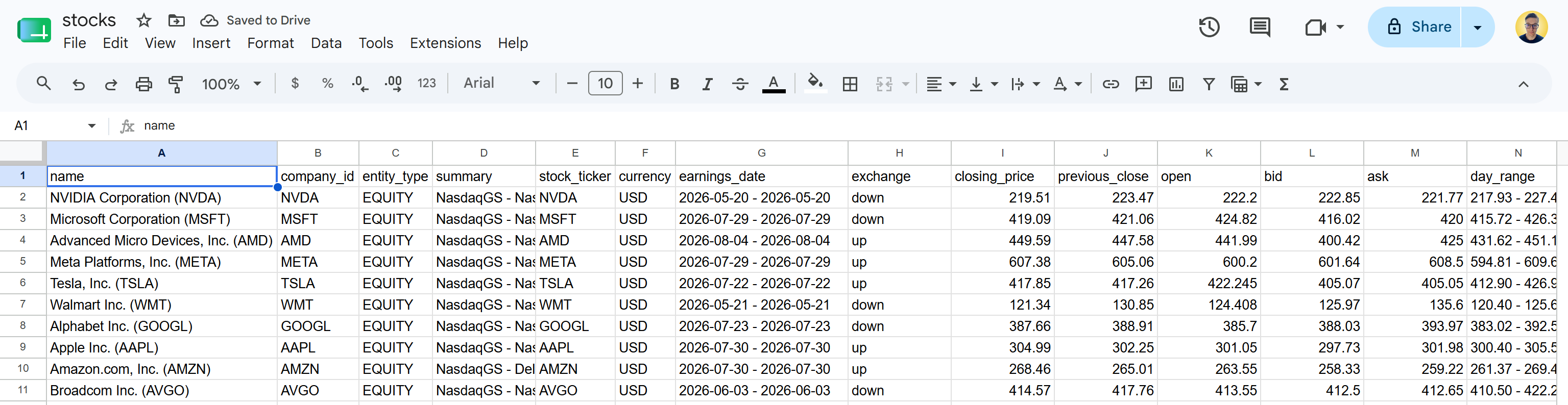
这与指定的 Yahoo Finance 页面上可用的股票数据相同。Bright Data 的 Yahoo Finance 爬虫工具 API 检索了股票数据并将其转换为结构化的 CSV 格式。
为了更好地理解抓取数据的结构以及可用的列,请查看 Yahoo Finance 爬虫工具页面 “Overview” 选项卡中的 “Dictionary” 部分:
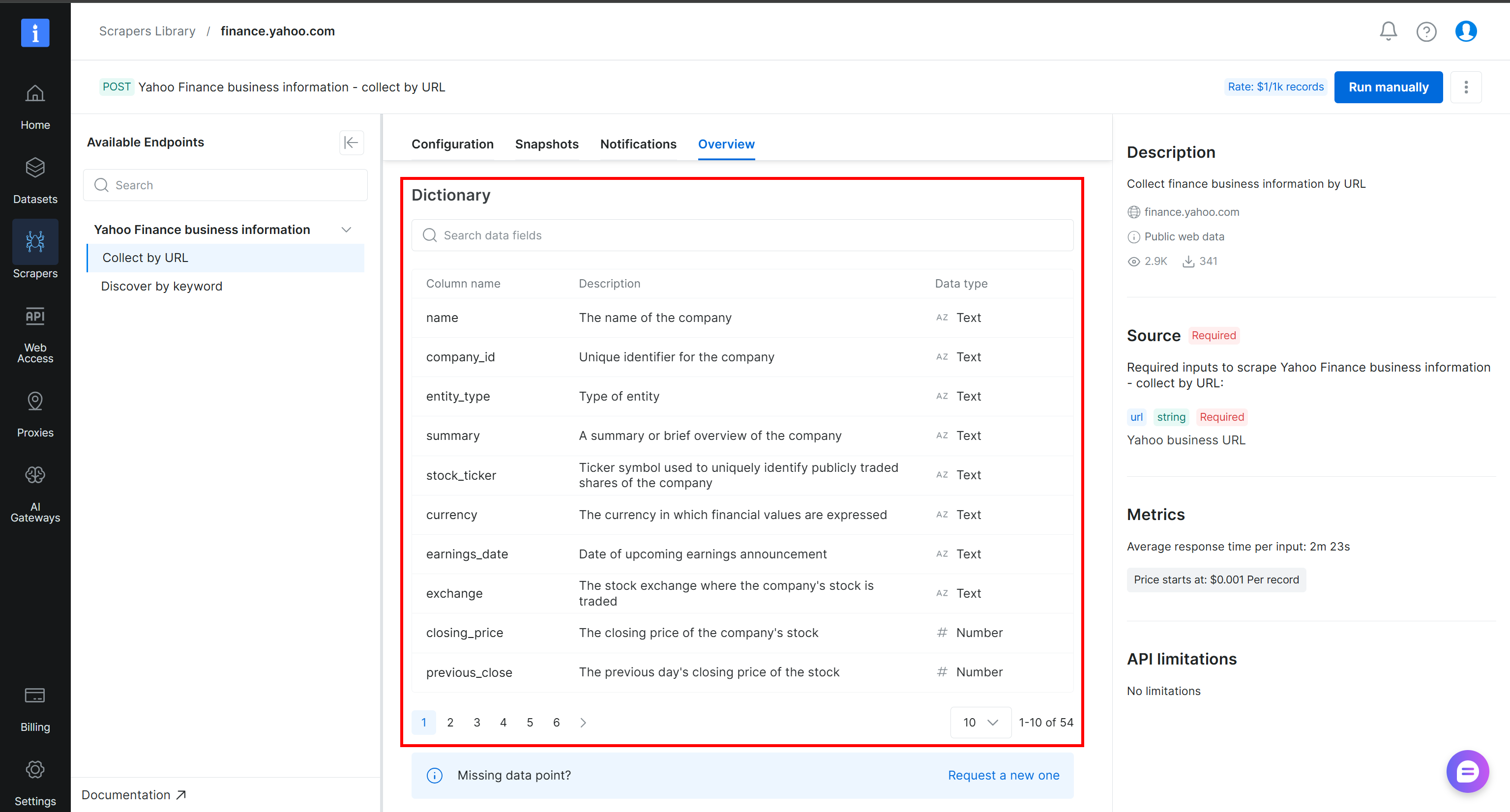
很酷!你现在已经拥有构建 Alteryx One 网页数据管道所需的数据。
第 #4 步:将 Alteryx One 连接到 S3 数据源
目前,抓取的源数据已交付到 Amazon S3。下一步是将你的 Alteryx One 账户连接到该 S3 bucket,以便工作流可以按需访问并分析数据。
要创建到你的 Amazon S3 bucket 的连接,请 登录 Alteryx One。导航到 “Data” 页面并打开 “Connections” 选项卡。然后点击 “New Connection”:
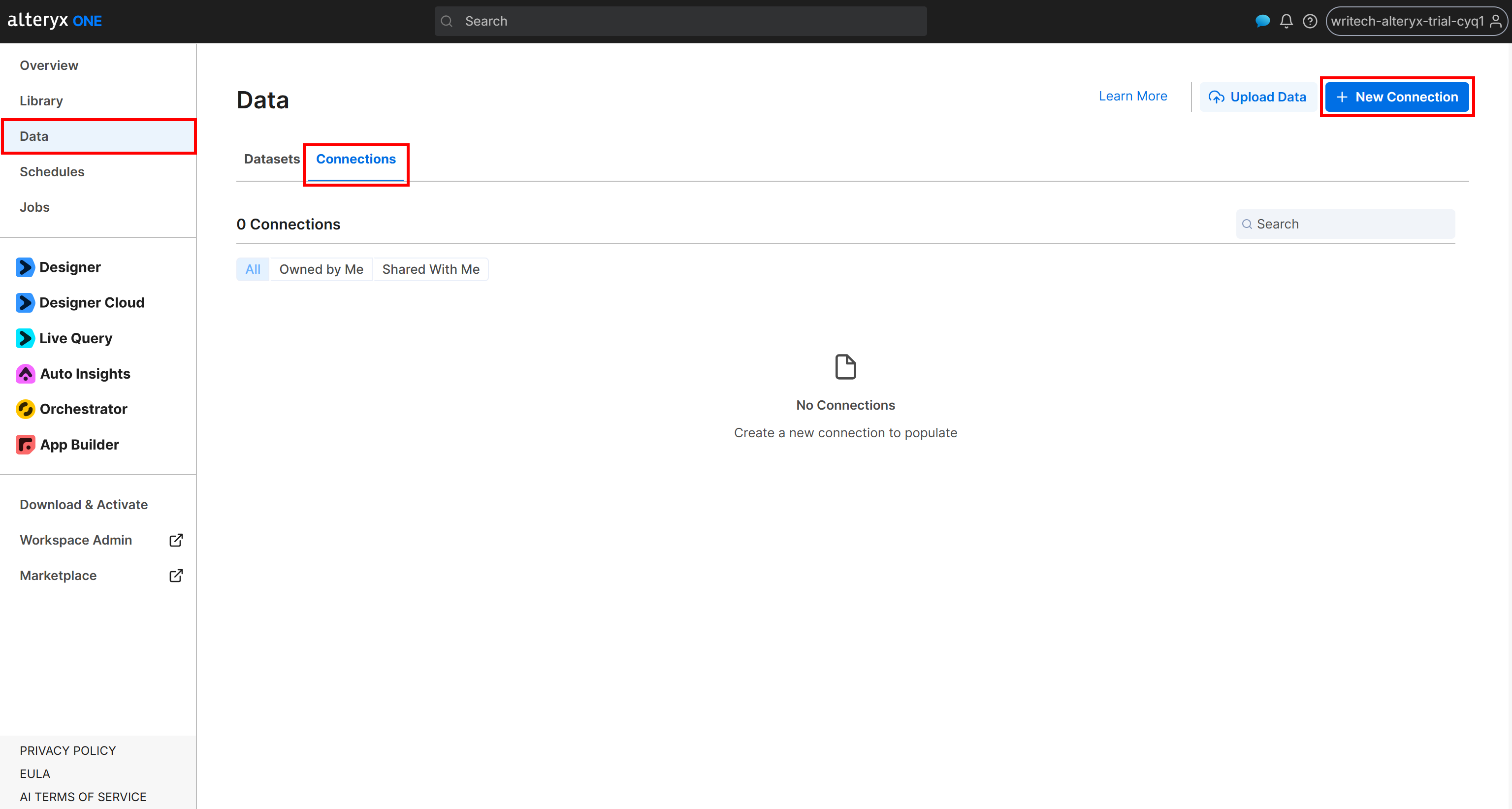
接下来,按如下方式配置 “External Amazon S3” 连接表单:
- Connection Name: Bright Data S3(或你喜欢的任何名称)。
- Default Bucket:
bright-data-datasets(或你的实际 bucket 名称)。 - Access Key ID 和 Secret Access Key: 你的 AWS Access Key ID 和 AWS Secret Access Key。
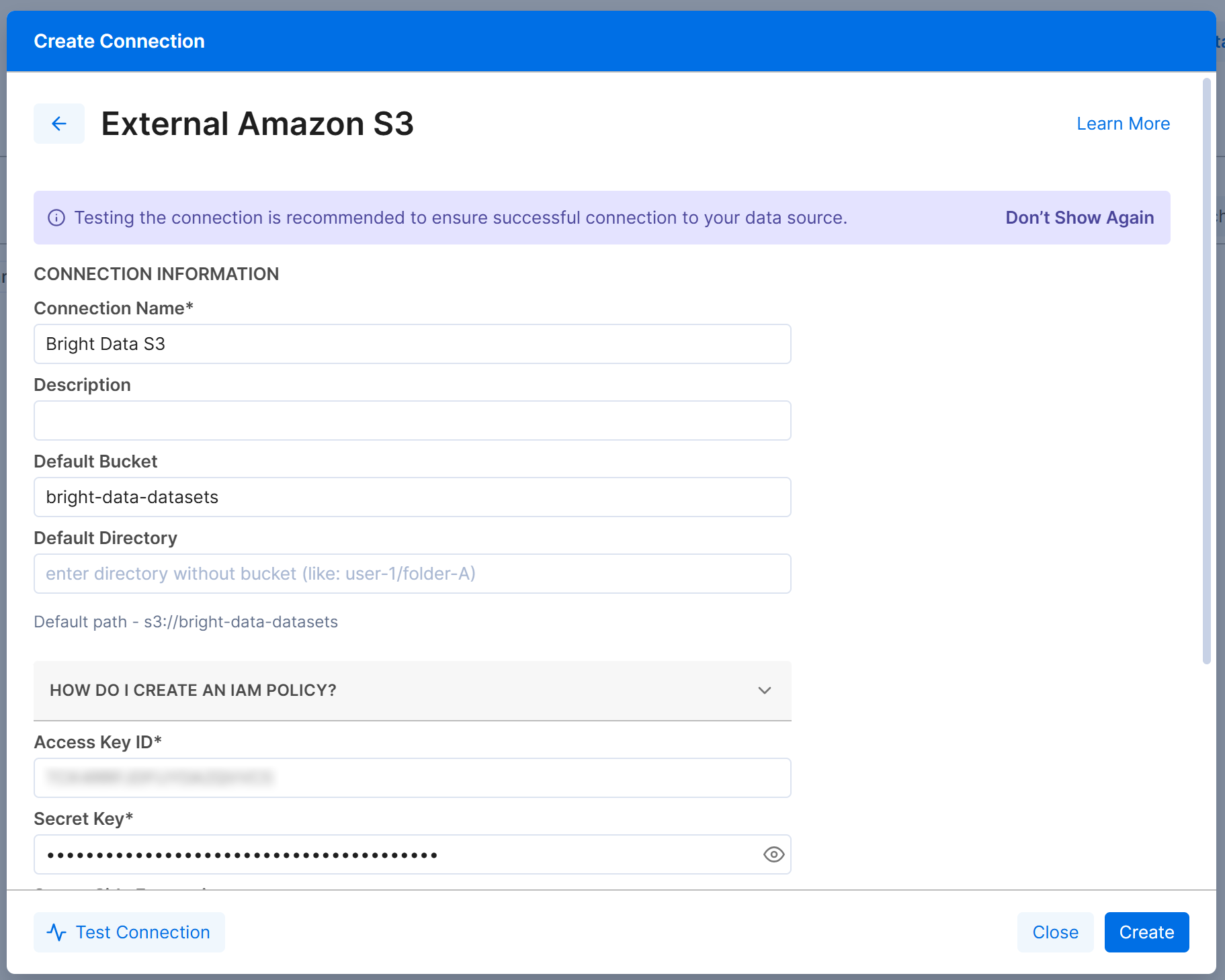
点击 “Create”,Amazon S3 连接将出现在 “Connections” 选项卡中:
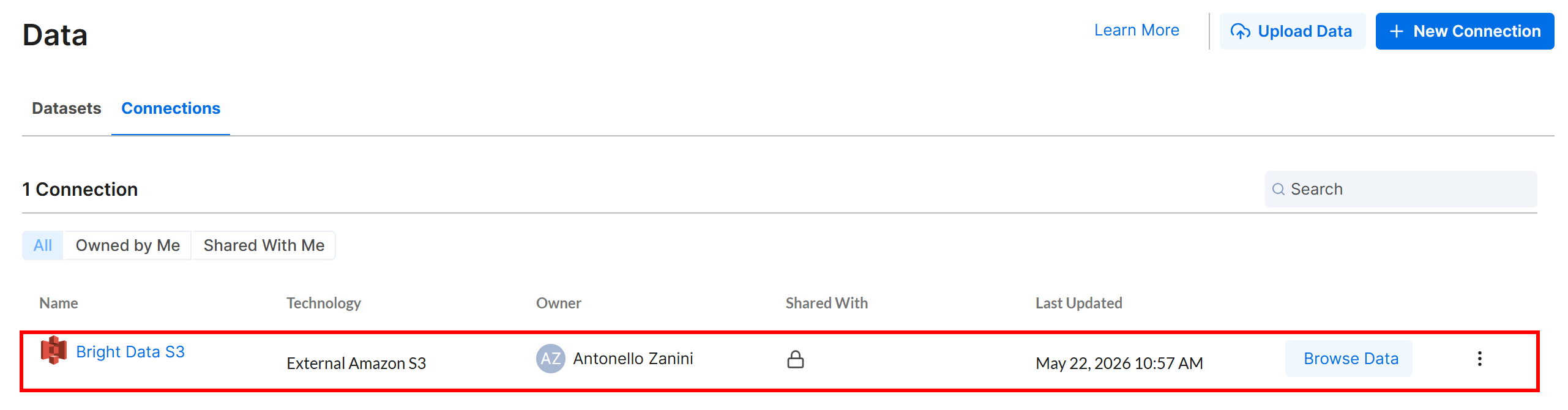
太棒了!现在是时候定义一个 Alteryx One 工作流,从你的 Amazon S3 bucket 读取输入数据了,Yahoo Finance 爬虫工具 API 会将其输出存储在那里。
第 #5 步:初始化 Alteryx One 工作流
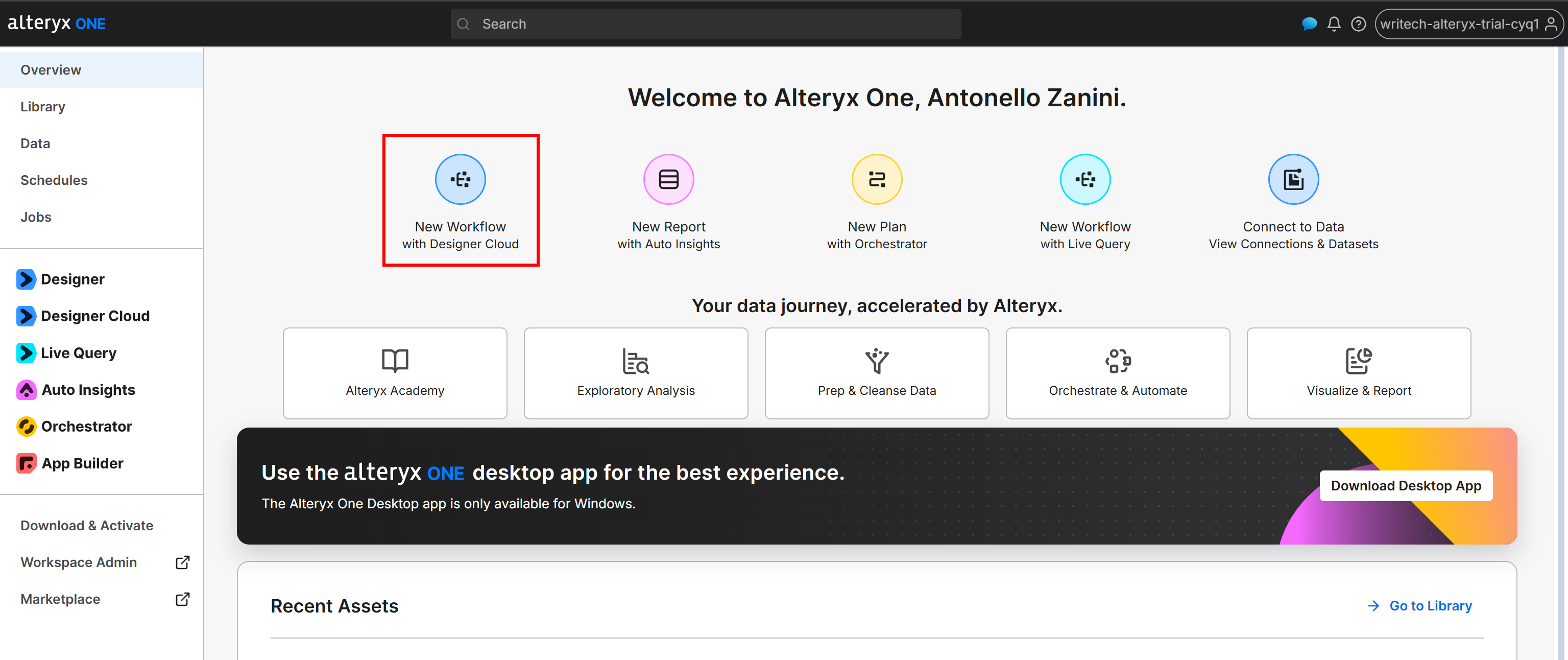
前往 “Overview” 页面并点击 “New Workflow with Designer Cloud” 按钮:
或者,你也可以从 Alteryx One 桌面应用创建工作流。
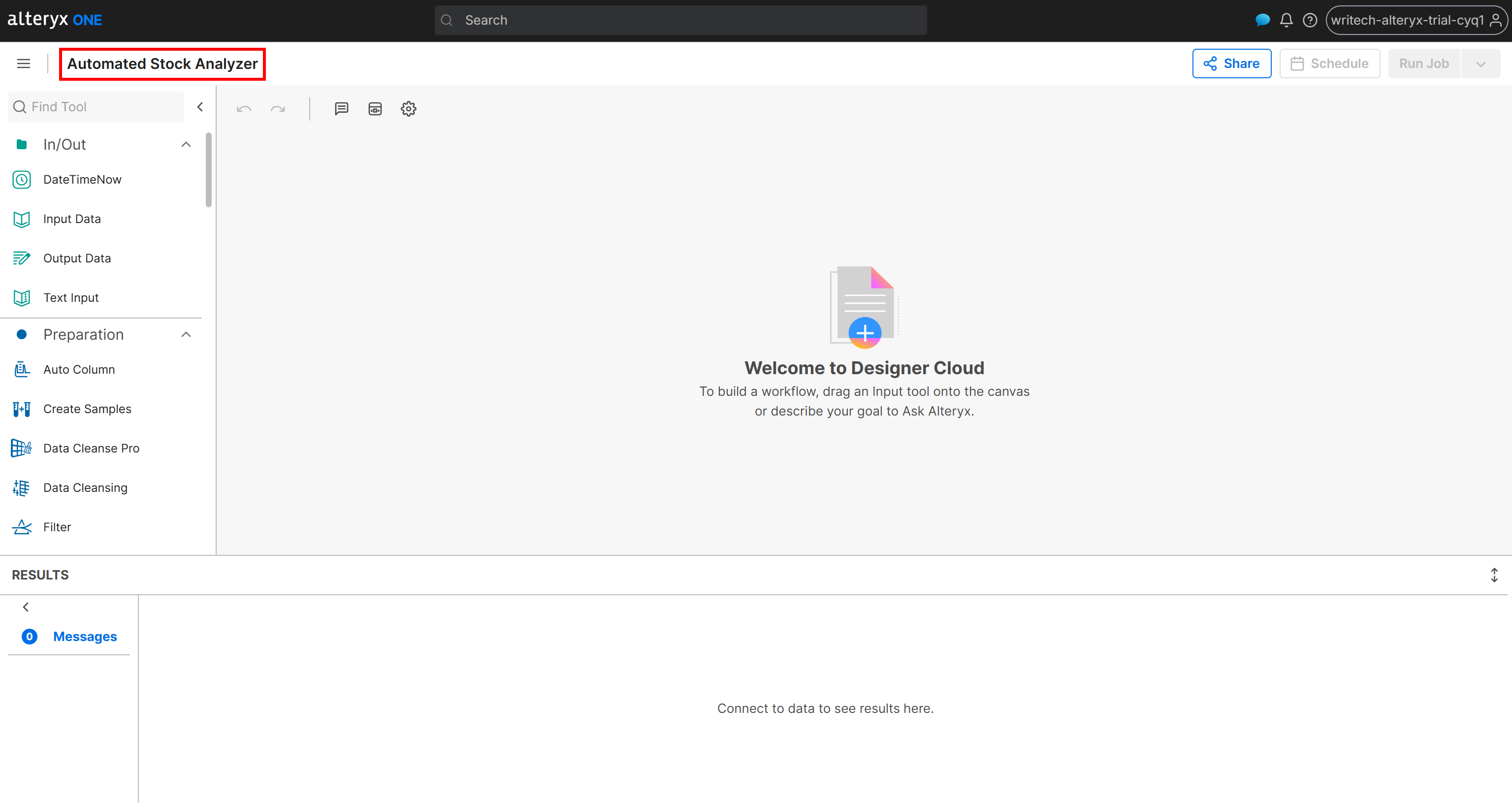
为你的工作流命名,例如 “Automated Stock Analyzer”:
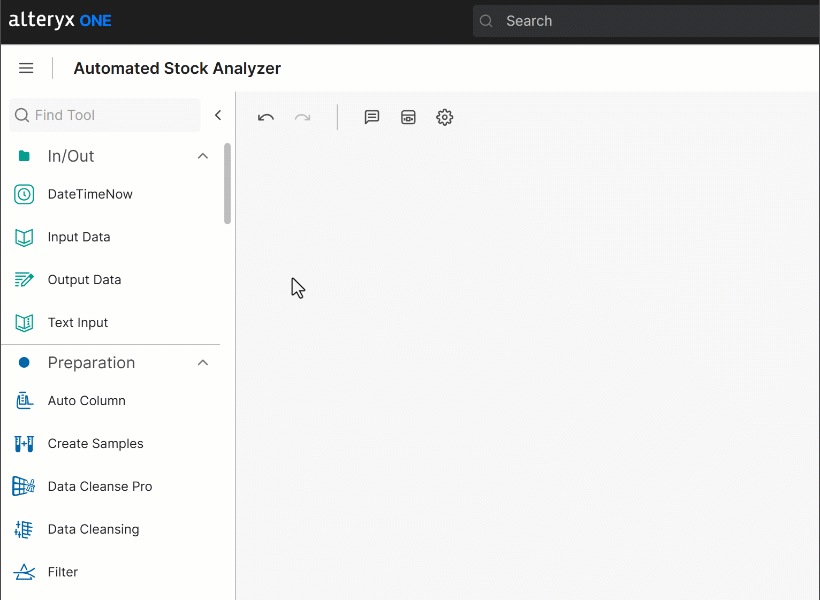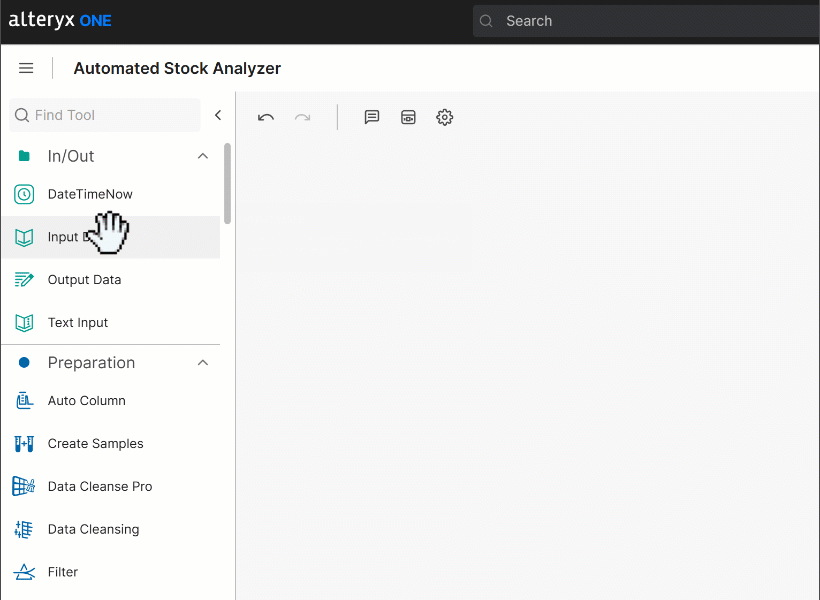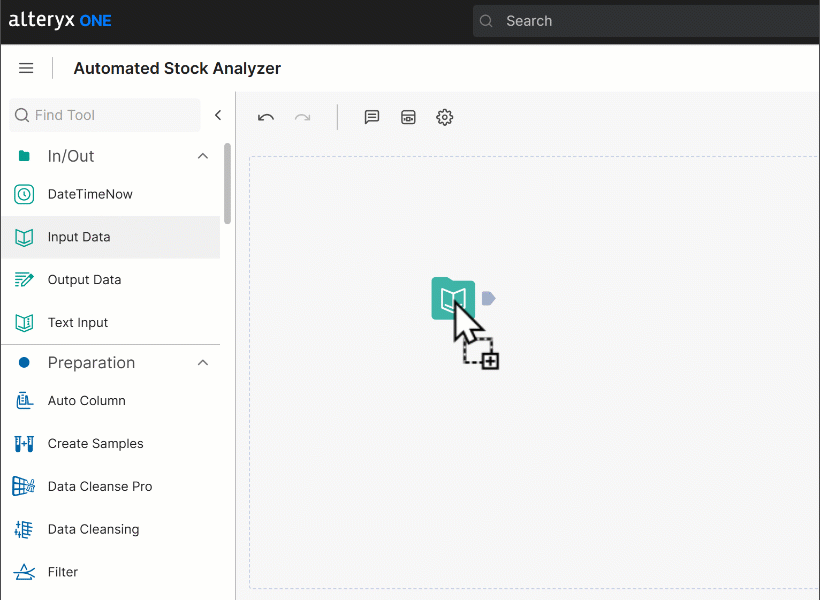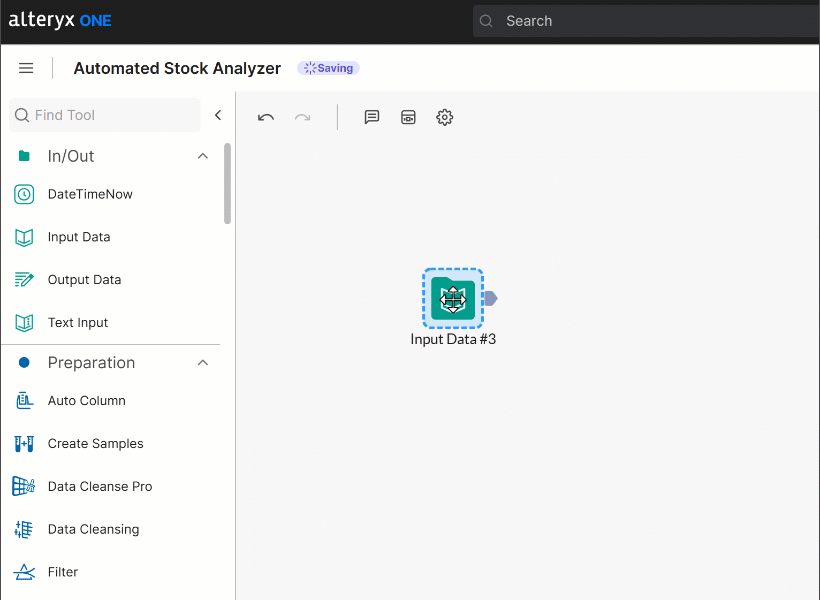
构建工作流的第一步是加载源数据。为此,将 “Input Data” 节点拖到工作流画布上:
然后双击该节点进行配置,并将其连接到你的 Amazon S3 bucket,选择 stocks.csv 文件。按照设置向导导入数据集。完成后,你应该会看到数据成功加载:
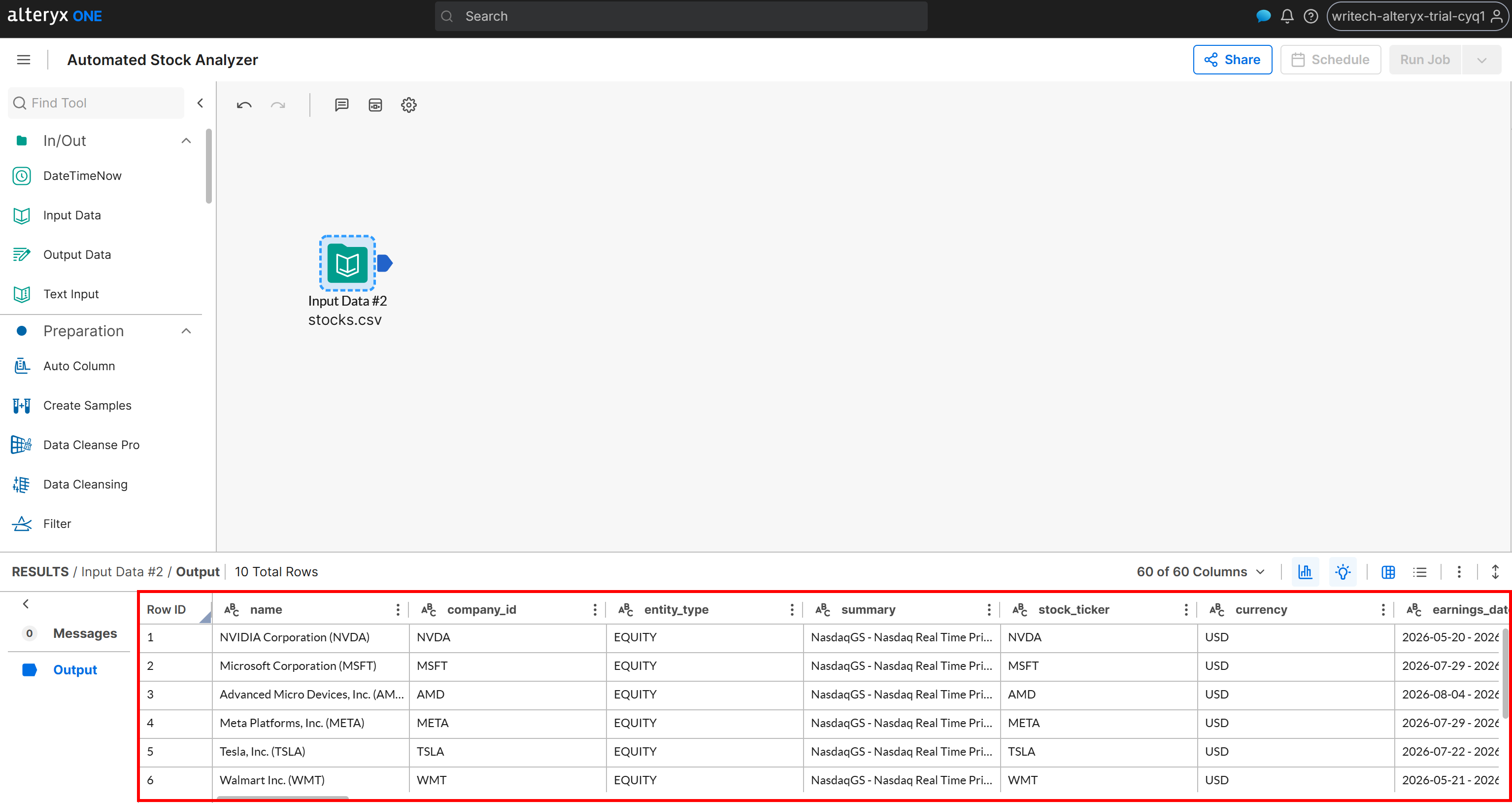
此时,工作流已可访问抓取的网页数据。很好!现在,你可以开始添加数据分析逻辑。
第 #6 步:定义数据分析逻辑
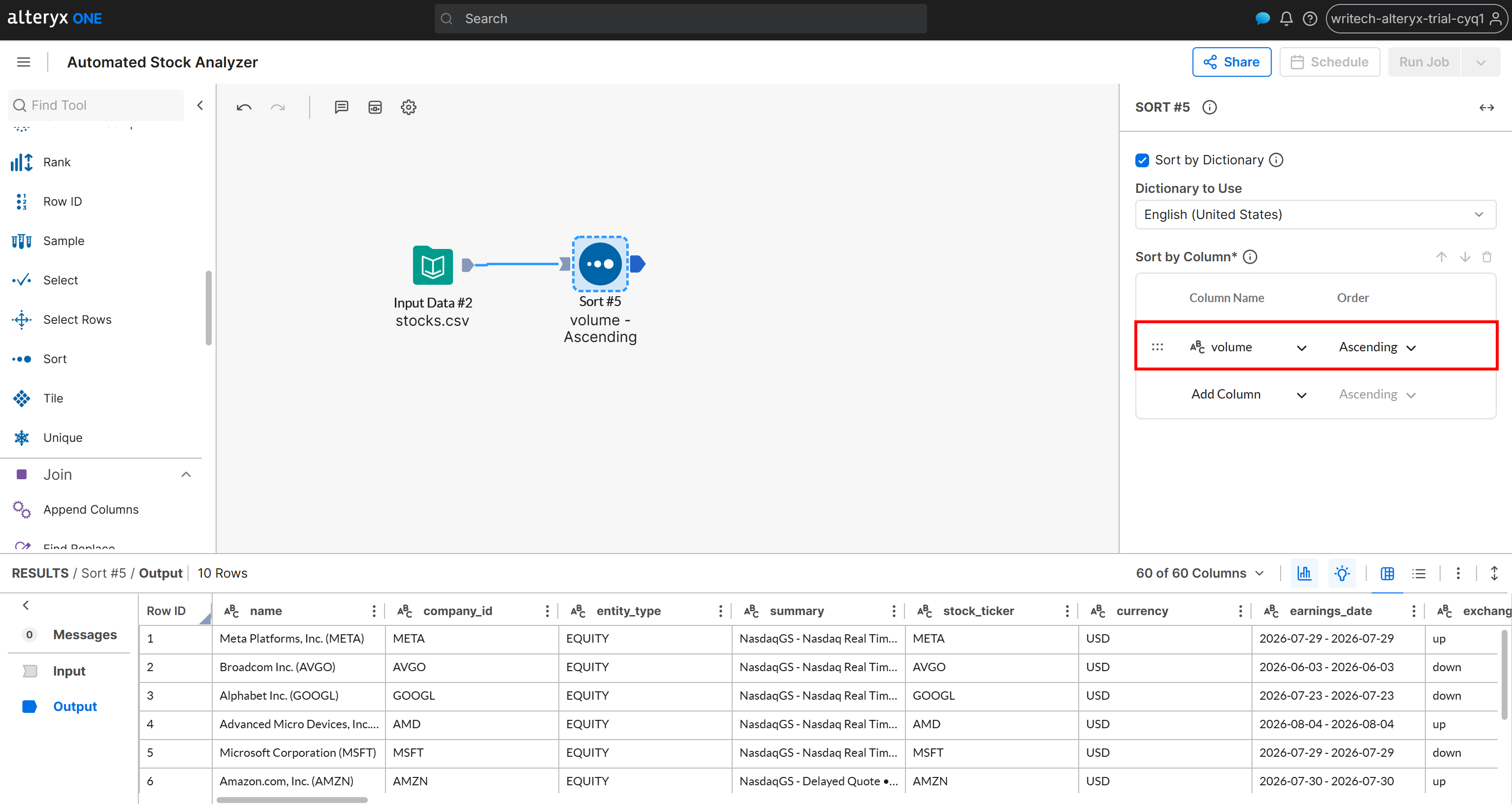
假设你希望结果按特定标准排序,例如每日交易量。添加一个 “Sort” 节点,并在排序配置中选择 volume 列并将顺序设置为 Ascending:
现在,假设你想将数据集拆分为两组:
- 当日收盘上涨的股票。
- 当日收盘下跌的股票。
为此,根据其 exchange 字段是否包含 “up” 或 “down” 来分类股票。添加一个 “Filter” 节点并将其连接到 “Sort” 节点的输出。然后定义如下过滤条件:
- Column Name:
exchange - Operator: Equals
- Value:
up
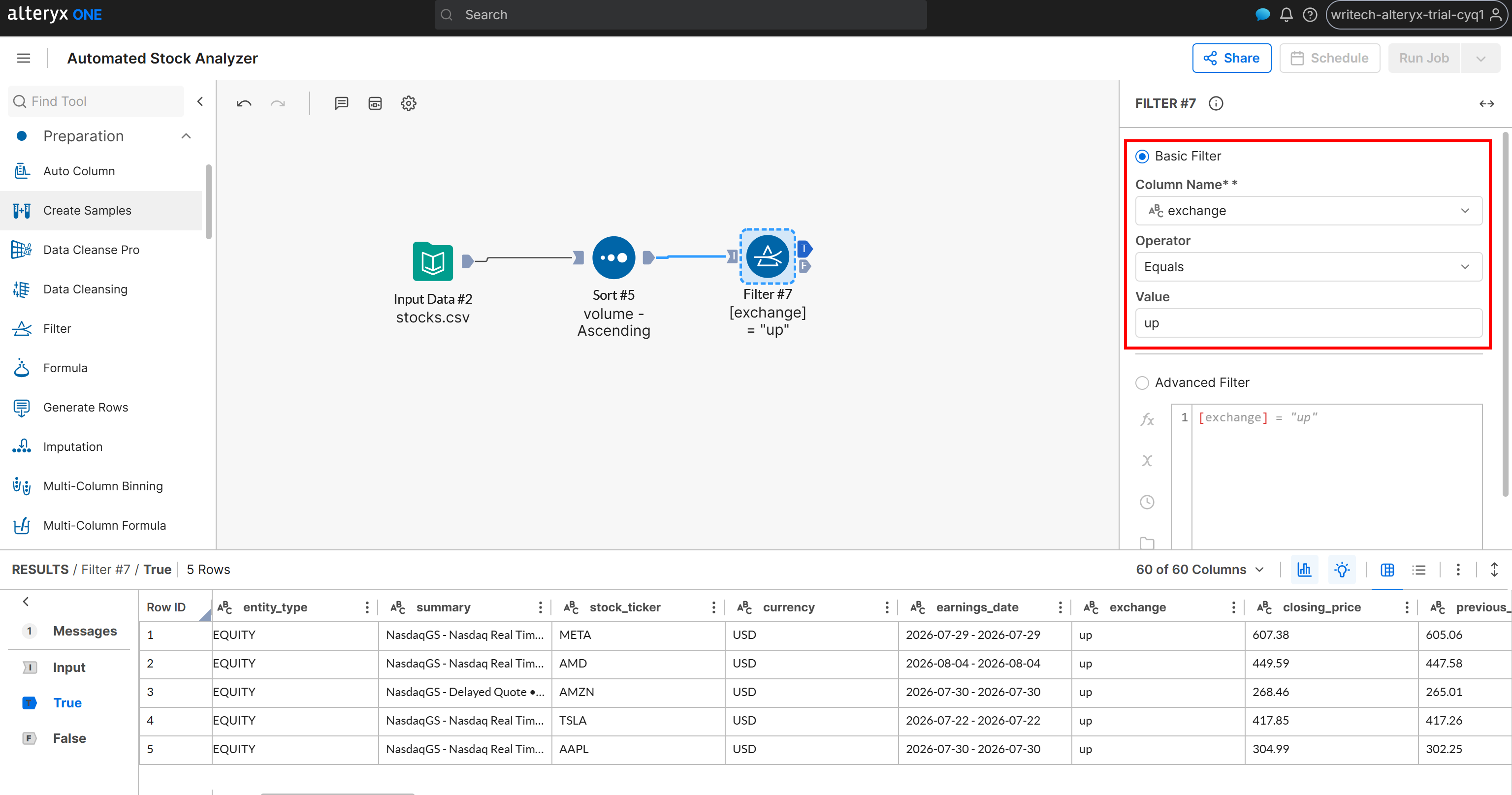
Filter 节点会产生两个输出:
T(True):包含exchange字段为 “up” 的股票。F(False):包含exchange字段不是 “up” 的股票(即为 “down”)。
这个简单网页自动化工作流的最后一步是定义输出目的地。来处理它吧!
第 #7 步:指定输出文件
在画布上添加一个 “Output Data” 节点,并将其连接到 “Filter” 节点的 T 输出。配置 “Output Data” 节点,将数据写入你的 Amazon S3 bucket(或任何其他已连接的数据源)。例如,创建一个名为 up_stocks.csv 的文件:
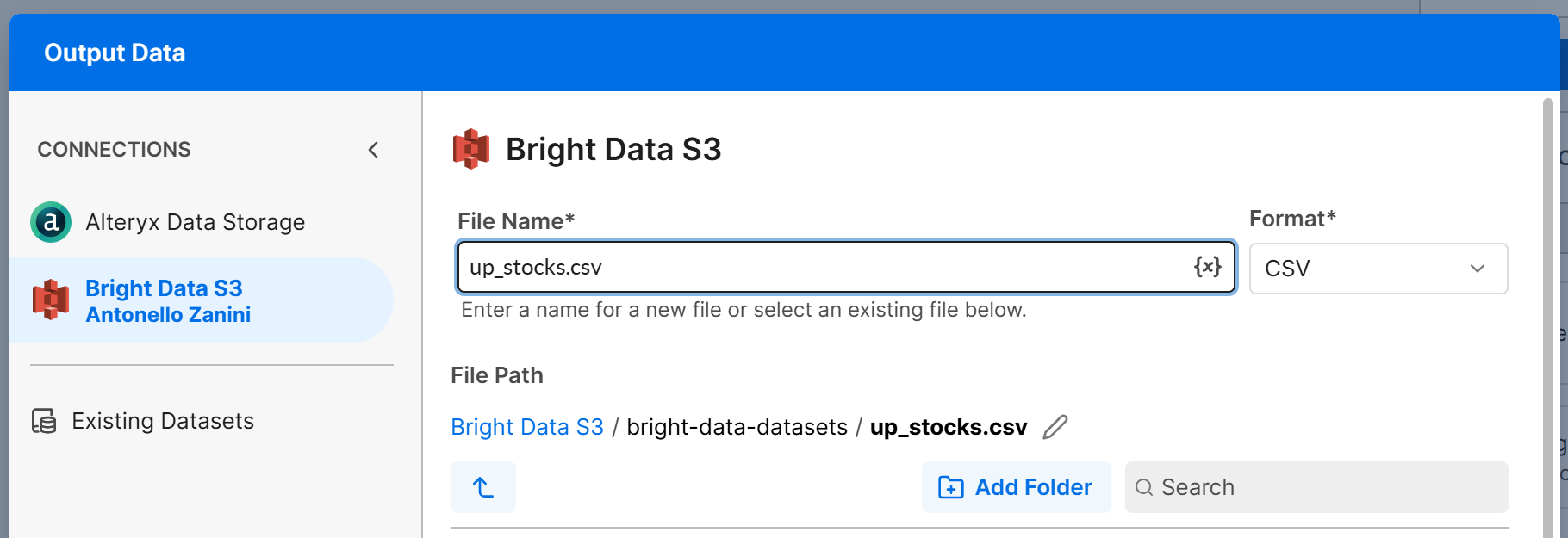
点击 “Next”,然后点击 “Confirm” 以保存 T 分支的输出配置。对 F 分支重复相同过程,并将其配置为写入 down_stocks.csv 文件。
最终工作流将如下所示:
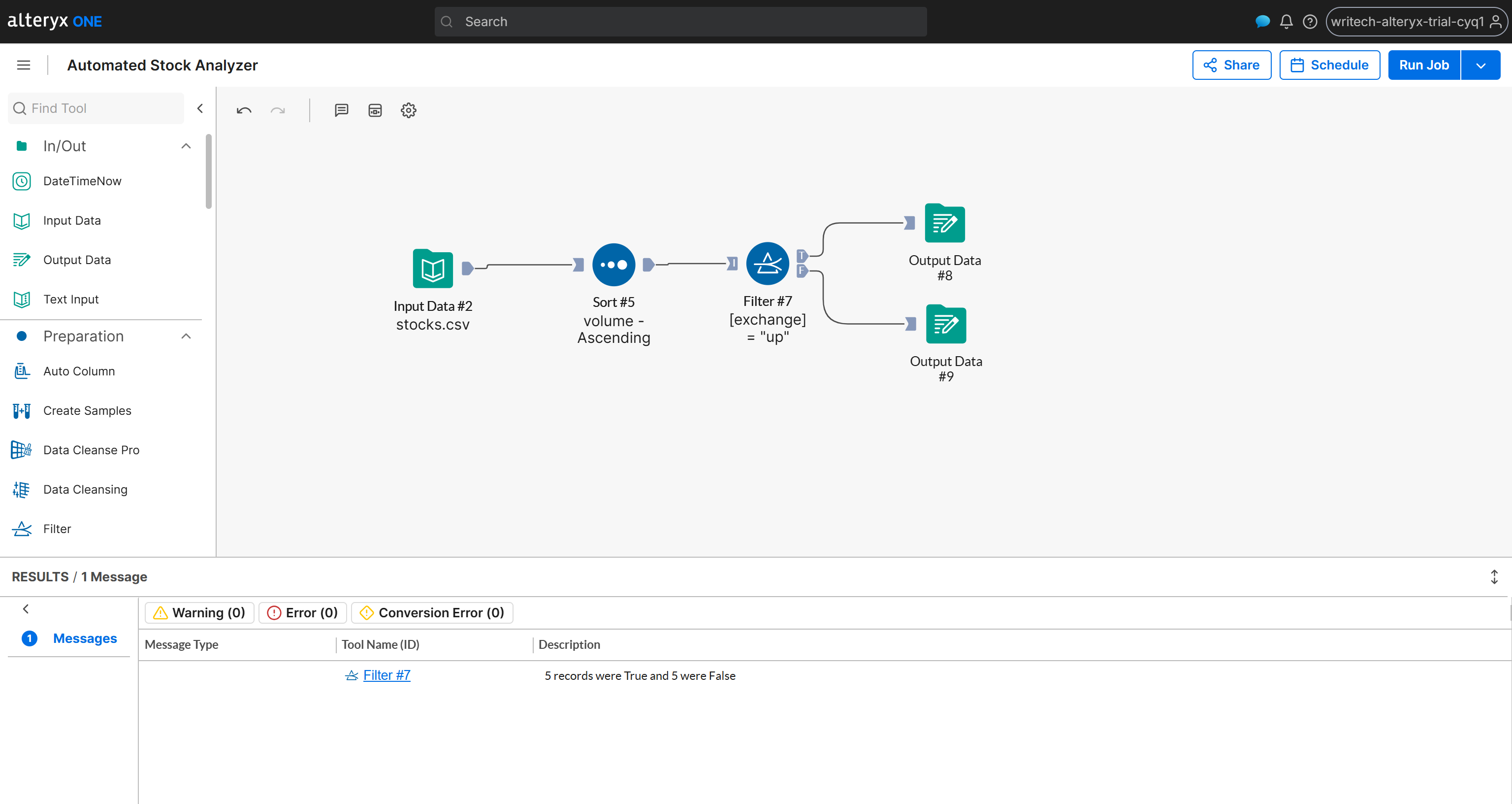
任务完成!现在你只需要运行工作流来测试一切是否按预期工作。
第 #8 步:启动工作流
点击 “Run Job” 按钮,并等待由 Bright Data 驱动的自动化网页数据分析工作流完成:

执行完成后,你将在 Alteryx One 中收到成功通知,以及一封确认邮件。
现在,检查为 T 场景生成的输出:
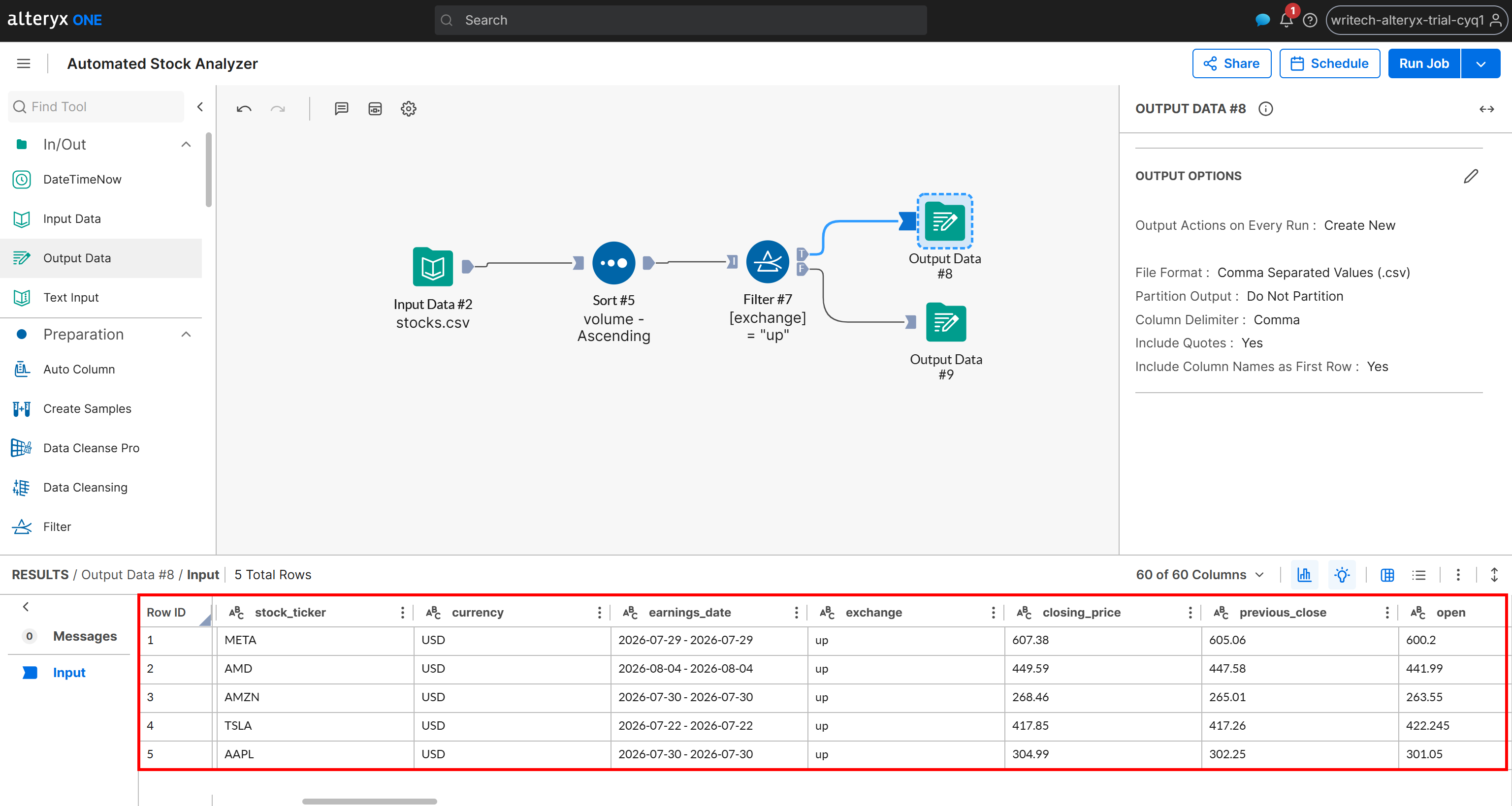
注意,该输出仅包含变动状态为 “up” 的股票,并按成交量升序排序。相同的数据也可在由管道生成并存储在你的 Amazon S3 bucket 中的 up_stocks.csv 文件中找到。
接下来,检查为 F 场景生成的输出:
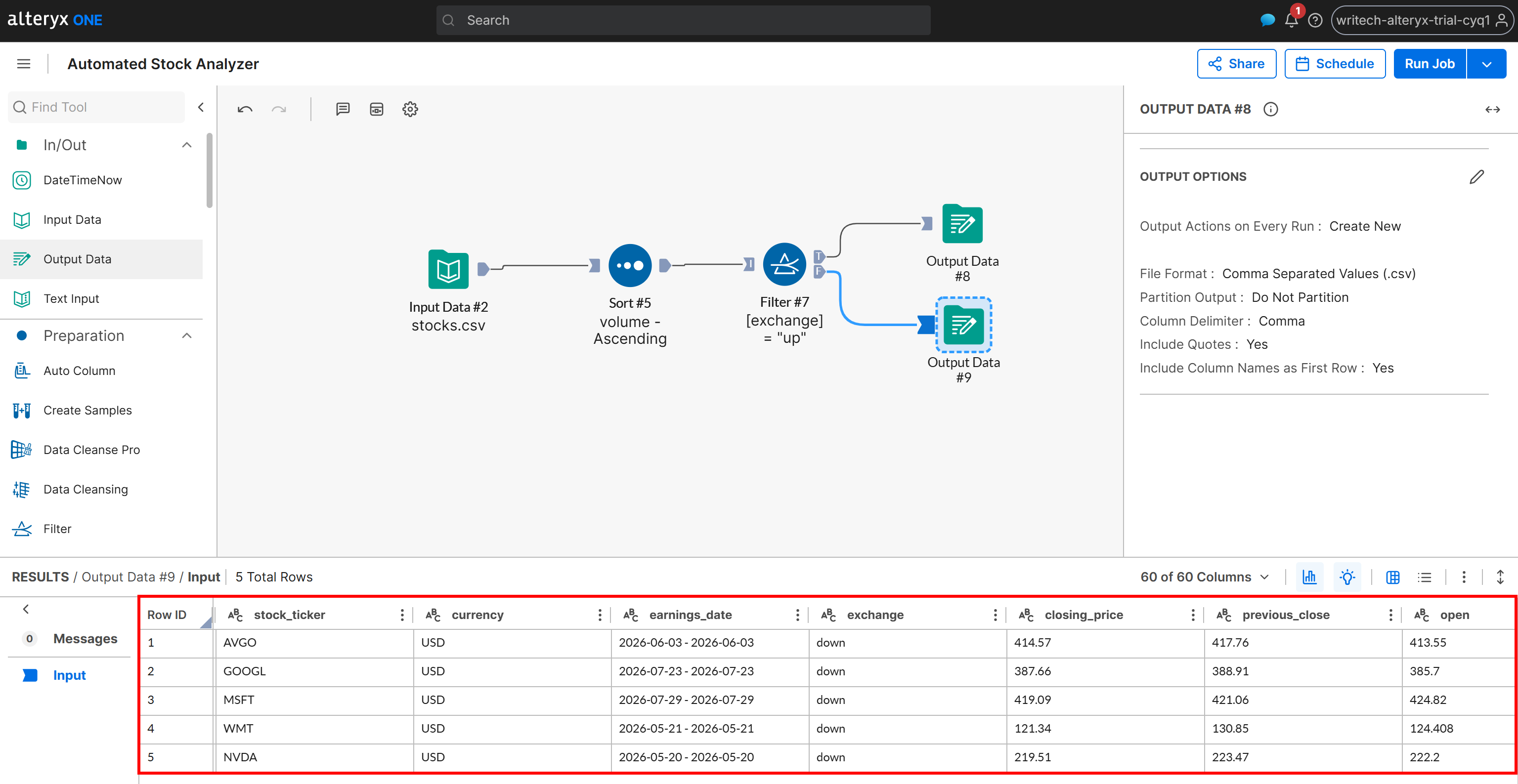
该输出仅包含变动状态为 “down” 的股票,同样按成交量升序排序。相同结果会写入你的 Amazon S3 bucket 中的 down_stocks.csv 文件。
瞧!你刚刚在 Alteryx One 中构建了一个由 Bright Data 驱动的网页数据分析管道。请注意,这只是一个示例,并且还有许多其他网页数据自动化场景是可能的。
后续步骤
请记住,这只是一个包含少量示例步骤的简单数据分析管道。在实践中,你可以通过添加额外的处理节点(包括 AI 节点)甚至引入多个数据源,使其变得更加复杂。
例如,你可以配置其他 Bright Data 网页爬虫工具 API 写入同一个 Amazon S3 bucket。然后,可以将生成的数据集进行合并以用于丰富和更高级的分析,使用 join 操作。
此外,要构建一个完全自动化、始终保持最新的数据管道:
- 触发 Bright Data 网页爬虫工具 API 更新 Amazon S3 中的源数据。
- 在 Bright Data 中,配置一个 webhook 来调用 Alteryx One 工作流运行 API。
结论
在本教程中,你了解了 Alteryx One 为自动化数据分析带来了什么。具体来说,你看到了如何将通过 Bright Data 的网页爬虫工具 API 检索的数据通过 Amazon S3 集成到 Alteryx One 中。高质量的网页数据能显著提升洞察的准确性和价值,从而带来更好的分析结果。
立即创建一个免费的 Bright Data 账户,开始探索我们面向企业的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。