

在本教程中,您将看到
- Qwen3 是什么?
- 为什么它非常适合网络搜索任务
- 如何在本地使用 Qwen3 和 Hugging Face 进行网络搜索
- 其主要局限性以及如何克服这些局限性
- Qwen3 以外的几种人工智能驱动的抓取工具
让我们深入了解一下!
什么是 Qwen3?
Qwen3是阿里巴巴云 Qwen 团队开发的最新一代 LLM。该模型是开源的,可在 GitHub 上自由探索–以 Apache 2.0 许可提供。这为研发工作提供了极大的便利。
Qwen3 的主要功能包括
- 混合推理:它可以在用于复杂逻辑推理(如数学或编码)的 “思考模式 “和用于快速通用响应的 “非思考模式 “之间切换。这样,您就可以控制推理的深度,以获得最佳性能和成本效益。
- 多样化的模型:Qwen3 提供一整套模型,包括密集模型(参数范围从 0.6B 到 32B)和专家混合模型(MoE)(如 30B 和 235B 变体)。
- 功能增强:它在推理、指令跟踪、代理能力和多语言支持(涵盖 100 多种语言和方言)方面取得了重大进展。
- 训练数据:Qwen3 是在一个包含约 36 万亿代币的海量数据集上进行训练的,几乎是其前身Qwen2.5 的两倍。
为什么使用 Qwen3 进行网络抓取?
Qwen3 可自动解释和结构化 HTML 页面中的非结构化内容,从而使网络刮削变得更容易。这消除了手动数据解析的需要。该模型无需编写复杂的逻辑来提取数据,而是为您理解页面结构。
依靠 Qwen3 进行网络数据解析,在处理常见的网络抓取难题时尤其有用,例如
- 频繁更改页面布局:亚马逊就是一个常见的例子,每个产品页面都可以显示不同的数据。
- 非结构化数据:Qwen3 可以从杂乱无章的自由格式文本中提取有价值的信息,而无需硬编码选择器或regex 逻辑。
- 难以解析的内容:对于结构不一致或复杂的页面,像 Qwen3 这样的 LLM 无需自定义解析逻辑。
如需更深入的了解,请阅读我们的使用人工智能进行网络搜索指南。
Qwen3 的另一大优势是开源。这意味着您可以在自己的机器上免费本地运行它,而无需依赖第三方 API 或支付 OpenAI 等高级 LLM。这样,您就可以完全控制您的搜索架构。
如何用 Python 中的 Qwen3 执行网络抓取
在本节中,目标页面将是 “学习网络抓取的电子商务测试网站“沙盒中的 “Affirm Water Bottle “产品页面:
这个页面就是一个很好的例子,因为电子商务产品页面的结构通常不一致,显示的数据类型也各不相同。这种多变性使得电子商务网页搜索特别具有挑战性,同时也是人工智能大显身手的地方。
在这里,我们将使用一个由 Qwen3 驱动的抓取器来智能地提取产品信息,而无需编写手动解析规则。
注:本教程将向您展示如何使用 “拥抱的脸 “在本地免费运行 Qwen3 模型。现在,还有其他可行的选择。其中包括连接到托管 Qwen3 模型的 LLM 提供商,或利用 Ollama 等解决方案。
请按照以下步骤开始使用 Qwen3 抓取网络数据!
步骤 #1:设置项目
在开始之前,请确保您的计算机已安装 Python 3.10+。否则,请下载并按照安装说明进行操作。
接下来,执行下面的命令为您的抓取项目创建一个文件夹:
mkdir qwen3-scraperqwen3-scraper目录将作为使用 Qwen3 进行网络抓取的项目文件夹。
在终端中导航到该文件夹,并在其中初始化 Python虚拟环境:
cd qwen3-scraper
python -m venv venv在你喜欢的 Python IDE 中加载项目文件夹。带有 Python 扩展的 Visual Studio Code或PyCharm Community Edition都是很好的选择。
在项目文件夹中创建一个scraper.py文件,其中应包含
现在,scraper.py只是一个空的 Python 脚本,但它很快就会包含 LLM 网络扫描的逻辑。
然后,激活虚拟环境。在 Linux 或 macOS 上,运行
source venv/bin/activate在 Windows 系统中,使用
venv/Scripts/activate注意:下面的步骤将指导你安装所有需要的库。如果您希望一次性安装所有库,可以使用下面的命令:
pip install transformers torch accelerate requests beautifulsoup4 markdownify太棒了您的 Python 环境已完全设置好,可以使用 Qwen3 进行网络搜索。
步骤 #2:在抱抱脸中配置 Qwen3
正如本节开头提到的,我们将使用 Hugging Face 在本地运行 Qwen3 模型。因为Hugging Face 最近添加了对 Qwen3 模型的支持,所以现在可以这样做了。
首先,确保您处于已激活的虚拟环境中。然后,运行以下命令安装必要的 Hugging Face 依赖项:
pip install transformers torch accelerate接下来,在你的scraper.py文件中,从Hugging Face 的转换器库中导入所需的类:
from transformers import AutoModelForCausalLM, AutoTokenizer现在,使用这些类加载标记符和 Qwen3 模型:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)在本例中,我们使用的是Qwen/Qwen3-0.6B型号,但您可以在 Hugging Face 上选择40 多种其他可用的 Qwen3 型号。
太棒了现在,您已经具备了在 Python 脚本中使用 Qwen3 的一切条件。
步骤 #3:获取目标页面的 HTML 代码
现在,是时候检索目标页面的 HTML 内容了。您可以使用强大的 Python HTTP 客户端(如 Requests)来实现。
在已激活的虚拟环境中,安装Requests 库:
pip install requests然后,在scraper.py文件中导入该库:
import requests使用get()方法向页面 URL 发送 HTTP GET 请求:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)服务器将响应页面的原始 HTML 内容。要查看完整的 HTML 内容,可以打印response.content:
print(response.content)结果应该是这个 HTML 字符串:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>现在,您可以在 Python 中获得目标页面的完整 HTML。让我们继续使用 Qwen3 解析它并提取我们需要的数据!
步骤 #4:将页面 HTML 转换为 Markdown(可选,但建议使用)
注意:此步骤并非严格要求。不过,它可以为您节省大量本地时间(如果使用付费 Qwen3 提供商,还可以节省资金)。因此,绝对值得考虑。
花点时间了解一下其他人工智能驱动的网络抓取工具(如Crawl4AI和ScrapeGraphAI)是如何处理原始 HTML 的。你会发现它们都提供了将 HTML 转换为 Markdown 的选项,然后再将内容传递给配置的 LLM。
他们为什么这样做?主要有两个原因:
- 成本效益:Markdown 转换可减少发送到人工智能的标记数量,帮助您节省成本。
- 处理速度更快:更少的输入数据意味着更低的计算成本和更快的响应速度。
如需了解更多信息,请阅读我们的指南:为什么新的人工智能代理选择 Markdown 而不是 HTML?
在这种情况下,由于 Qwen3 在本地运行,成本效益并不重要,因为您没有连接到第三方 LLM 提供商。真正重要的是更快的处理速度。为什么?因为要求所选的 Qwen3 型号(顺便说一下,这是现有的较小型号之一)处理整个 HTML 页面,可以轻松地将 i7 CPU 的使用率推至 100% 并持续数分钟。
这太大了,因为您不想让笔记本电脑或个人电脑过热或冻结。因此,通过转换为 Markdown 来减少输入大小是非常合理的。
是时候复制 HTML 到 Markdown 的转换逻辑并减少令牌的使用了!
首先,在隐身模式下打开目标网页,以确保是一个全新的会话。然后,右键单击页面上的任意位置,选择 “检查”,打开 DevTools。现在,检查页面结构。你会发现所有相关数据都包含在 CSS 选择器#main 标识的 HTML 元素中:
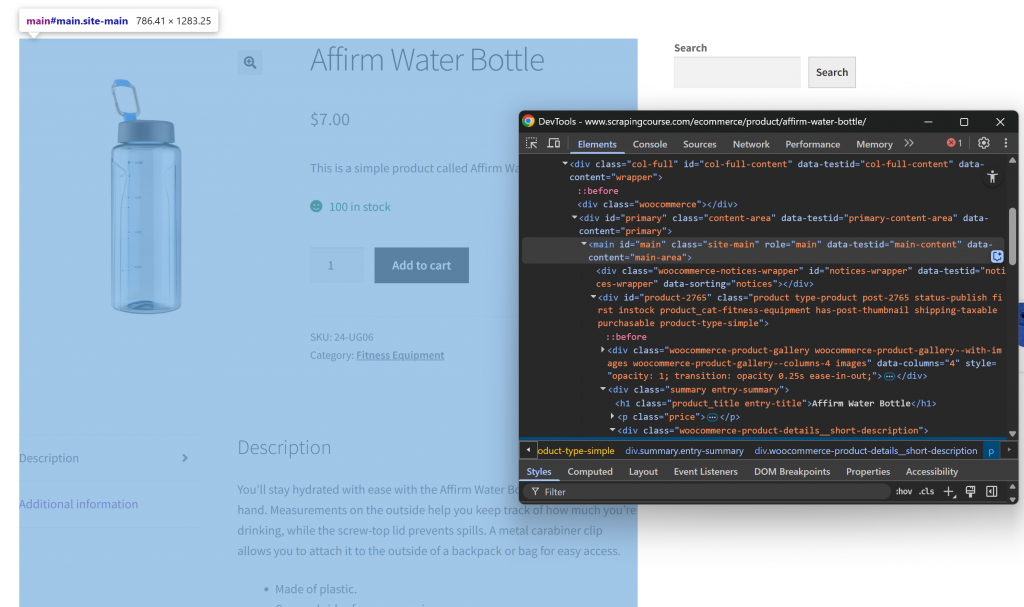
在 HTML 到 MARKDOWN 的转换过程中,只需关注#main内的内容,就可以只提取页面中包含相关数据的部分。这就避免了包含页眉、页脚和其他你不感兴趣的部分。这样,最终的 Markdown 输出就会短得多。
要只选择#main元素中的 HTML,您需要一个Python HTML 解析库,如 Beautiful Soup。在激活的虚拟环境中,使用此命令安装它:
pip install beautifulsoup4如果您不熟悉其 API,请参阅我们的美丽汤网络抓取指南。
然后,在scraper.py 中导入它:
from bs4 import BeautifulSoup现在,用 “美丽汤 “来
- 解析通过请求获取的原始 HTML 代码
- 选择
#main元素 - 提取其 HTML 内容
通过此片段实现上述三个微型步骤:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)如果打印main_html,会看到类似下面的内容:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>该字符串比完整的 HTML 页面小得多,但仍包含约 13 402 个字符。
要在不丢失重要数据的情况下进一步缩小文件大小,可将提取的 HTML 转换为 Markdown。首先,安装markdownify库:
pip install markdownify在scraper.py 中导入markdownify:
from markdownify import markdownify然后,使用它将#main中的 HTML 转换为 Markdown:
main_markdown = markdownify(main_html)数据转换过程应产生如下输出结果:
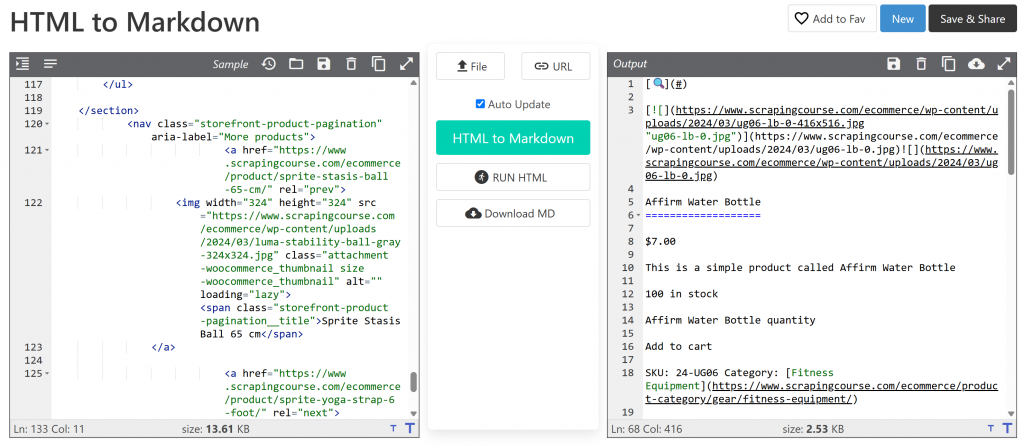
Markdown 版本约为 2.53 KB,而原始#mainHTML 版本为 13.61 KB。大小减少了 81%!除此之外,重要的是 Markdown 版本保留了您需要抓取的所有关键数据。
有了这个简单的技巧,你就可以将庞大的 HTML 代码段缩减为紧凑的 Markdown 字符串。这将大大加快通过 Qwen3 进行本地 LLM 数据解析的速度!
步骤 #5:使用 Qwen3 进行数据解析
要让 Qwen3 正确刮取数据,需要编写有效的提示。首先要分析目标页面的结构:
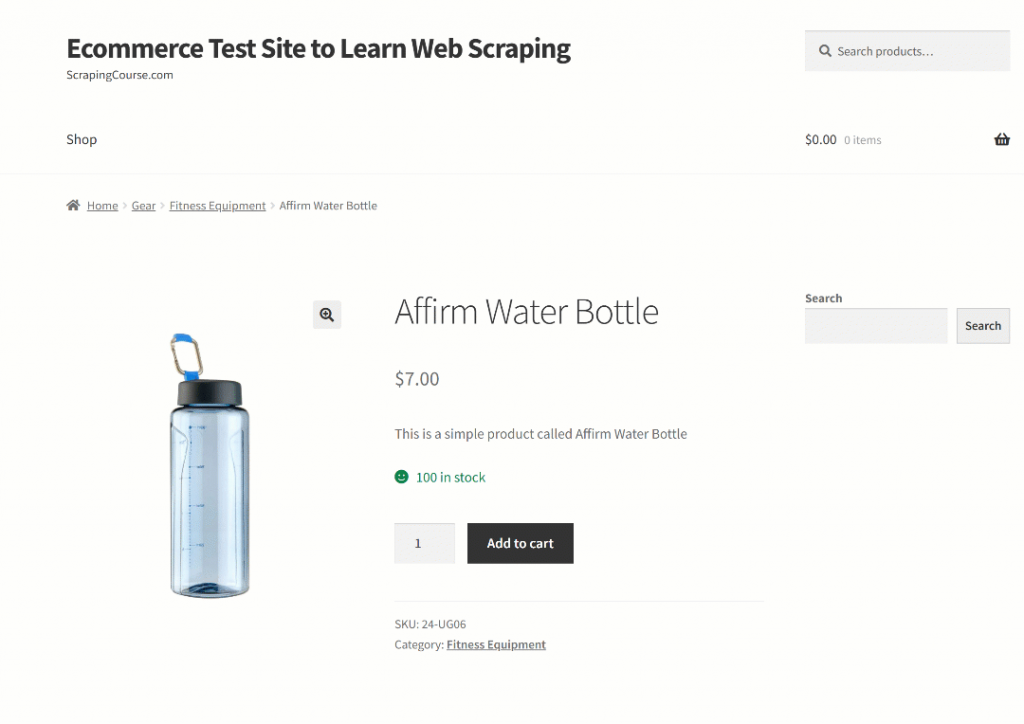
所有产品的页面顶部都是一致的。另一方面,”附加信息 “表会根据产品的不同而变化。由于您可能希望您的提示在平台上的所有产品页面上都有效,因此您可以这样概括地描述您的任务:
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>该提示指示 Qwen3 从main_markdown内容中提取结构化数据。要获得可靠的结果,最好让提示尽可能清晰和具体。这有助于模型准确理解您的期望。
现在,按照官方文档的说明,使用 “拥抱脸 “运行提示:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")上述代码使用apply_chat_template()对输入信息进行格式化,并从配置的 Qwen3 模型生成响应。
注意:一个关键细节是在apply_chat_template() 中设置enable_thinking=False。默认情况下,该选项设置为True,这将激活模型的内部 “推理 “模式。该任务对于复杂问题的解决非常有用,但对于像网络抓取这样的简单任务来说,则没有必要,而且可能适得其反。禁用它可以确保模型只专注于提取,而不添加解释或假设。
太棒了您刚刚指示 Qwen3 在目标页面上执行网络抓取。
现在,只需调整输出并将其导出为 JSON 即可。
步骤 #6:转换 Qwen3 输出结果
Qwen3-0.6B 模型的输出结果在不同的运行过程中会略有不同。这是 LLM 的典型表现,尤其是像这里使用的这种较小的模型。
因此,有时product_raw_string变量会以纯 JSON 字符串的形式包含所需的数据。有时,它可能会将 JSON 包在一个 Markdown 代码块中,就像这样:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```要处理这两种情况,可以使用正则表达式提取出现在 Markdown 块内的 JSON 内容。否则,将字符串视为原始 JSON。然后,将得到的 JSON 数据解析为 Python 字典json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)开始了!至此,你已将抓取数据解析为可用的 Python 对象。最后一步是将抓取数据导出为更方便用户使用的格式。
步骤 #7:导出抓取的数据
现在,您已经在 Python 字典中获得了产品数据,可以像这样将其保存到 JSON 文件中:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)这将创建一个名为product.json的文件,其中包含结构化产品数据。
干得好您的 Qwen3 网络抓取器现已完成。
步骤 #8:将所有内容整合在一起
以下是您的scraper.pyQwen3 抓取脚本的最终代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)运行脚本:
python scraper.py首次运行脚本时,”拥抱脸庞 “会自动下载所选的 Qwen3 模型。该模型约为 1.5GB,因此下载可能需要一些时间,具体取决于你的网速。在终端中,你会看到如下输出:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]该脚本可能需要一些时间才能完成,因为 PyTorch 在加载和运行模型时会对 CPU 造成压力。
脚本完成后,会在项目文件夹中创建一个名为product.json的文件。打开该文件,你会看到结构化的产品数据,如下所示:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}注:由于 LLM 的性质不同,可能会以不同的方式构建抓取内容,因此确切的输出结果可能会略有不同。
就是这样!您的脚本刚刚将原始 HTML 内容转化为干净、结构化的 JSON。这一切都要归功于 Qwen3 Web scraping。
克服这种网络抓取方法的主要局限性
当然,在我们的例子中,一切工作都很顺利。但这只是因为我们使用的是一个专门为此而建的演示网站。
在现实世界中,大多数网站都非常清楚其面向公众的数据的价值。因此,它们通常会实施反抓取技术,以快速阻止使用请求等工具自动发起的 HTTP 请求。
此外,这种方法不适用于 JavaScript 繁重的网站。这是因为请求和 BeautifulSoup 的组合可以很好地处理静态页面,但无法处理动态内容。如果您不熟悉两者的区别,请参阅我们关于静态内容与动态内容的文章。
其他潜在拦截器包括 IP 禁止、速率限制器、TLS 指纹识别、验证码等。总之,网络抓取并不容易,尤其是现在大多数网站都配备了检测和阻止人工智能爬虫和机器人的功能。
解决方法是利用专为现代网络搜索请求而构建的网络解锁 API。这种服务会为你处理所有棘手的问题,包括旋转 IP、解决验证码问题、渲染 JavaScript 和绕过僵尸保护。
您只需将目标页面的 URL 传递给 Web Unlocker API 端点即可。API 将返回完全解锁的 HTML,即使页面依赖于 JavaScript 或受到高级反僵尸系统的保护。
要将其集成到脚本中,只需用以下代码替换步骤 #3 中的requests.get()行即可:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.text有关详细信息,请参阅Web Unlocker 官方文档。
有了 Web Unlocker,您就可以放心地使用 Qwen3 从任何网站中提取结构化数据,再也不会出现数据块、渲染问题或内容缺失。
用于网络抓取的 Qwen3 的替代产品
Qwen3 并非唯一可用于自动网络数据解析的 LLM。请在以下指南中探索一些替代方法:
- 使用双子座进行网络抓取:完整教程
- 使用 Perplexity 进行网络抓取:逐步指南
- 使用 ScrapeGraphAI 进行 LLM 网络抓取
- 如何使用 Crawl4AI 和 DeepSeek 构建人工智能搜索器
- 使用 LLaMA 3 进行网络抓取:将任何网站转化为结构化 JSON
结论
在本教程中,您将学习如何使用 Hugging Face 在本地运行 Qwen3,从而构建一个人工智能驱动的网络抓取器。网络抓取的最大障碍之一是被拦截,但使用 Bright Data 的Web Unlocker API 可以解决这个问题。
如前所述,将 Qwen3 与 Web Unlocker API 相结合,您几乎可以从任何网站提取数据。所有这些都无需自定义解析逻辑。这一设置展示的只是 Bright Data 基础架构实现的众多强大用例之一,它可以帮助您构建可扩展的、人工智能驱动的网络数据管道。
那么,为什么要止步于此?考虑探索Web Scraper API–专用端点,从 120 多个流行网站中提取新鲜、结构化和完全合规的网络数据。
立即注册免费的 Bright Data 帐户,开始使用 AI 就绪的抓取解决方案进行构建!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



