
在这篇博客文章中,你将看到:
- 什么是社交聆听,以及它为什么有价值。
- 为什么智能体 AI 是执行社交聆听的最佳方式。
- 使用 AI(尤其是通过智能体)进行社交媒体聆听的主要障碍。
- 如何用专为智能体准备的社交媒体抓取工具克服这些障碍。
- 一步步教程:在 LangChain 中构建一个智能体社交聆听工作流,并由 Bright Data 社交媒体抓取工具提供支持。
- 把该示例变成生产可用的智能体工作流还需要什么。
- 社交聆听的真实世界智能体工作流示例。
我们开始吧!
社交聆听:是什么、如何运作,以及示例
社交聆听(social listening)是监测并分析数字对话的过程,用于理解人们在谈论某个品牌、产品、公告、行业或特定话题时在说什么。
它不止是追踪提及(mentions)。社交聆听能帮助发现趋势、衡量情绪,并理解外部公众真正的感受。其最终目标是生成可指导营销、产品决策与客户支持的洞察。
从宏观上看,社交聆听通常遵循两步流程:
- 监测(Monitoring):在社交媒体平台上追踪与目标主题相关的提及、评论与对话(例如竞争对手、你的品牌、相关关键词等)。
- 分析(Analysis):解读这些数据以理解发生了什么、识别模式,并采取行动来改善结果或获得更深层情报。
例如,一家公司可以研究 Reddit 垂直社区中未经修饰的讨论,发现痛点或功能需求。同样,一个品牌也可以分析 Instagram 评论与话题标签(hashtags),来衡量互动与品牌认知。
为什么智能体 AI 工作流最适合社交聆听
传统的社交聆听工作流通常是静态的,由一系列组件组成,把数据在固定流水线中从输入传到输出。
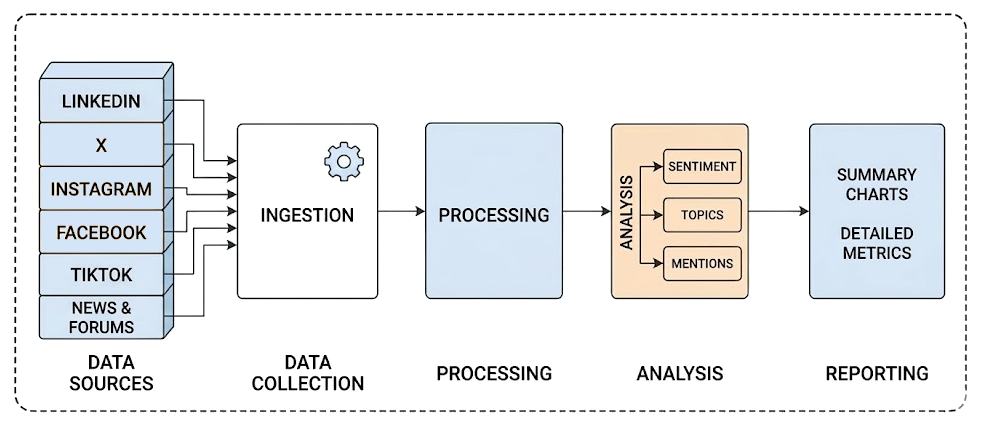
这种方式对很多数据分析流程都很有效,但面对社交媒体数据时会吃力。原因在于:解释语境并持续适应不断出现的新对话非常困难。这正是 AI 尤其是通过智能体工作流能够很好匹配的地方!
智能体社交聆听工作流,会把被动的数据流转化为主动的情报引擎。毕竟,与静态流水线不同,AI 智能体能够进行自主行为。
例如,当智能体在 Reddit 上检测到情绪异常飙升时,它可以主动去 X 或 Threads 上查找相关话题以定位根因;也可以在 Reddit 内部(甚至可能在 Google)做更深入的研究,理解到底发生了什么。
尤其是,智能体社交聆听工作流的主要优势包括:
- 更深层的情绪分析:不仅仅是打“正向/中性/负向”的标签,AI 还能理解讽刺与文化语境,从而在情绪与互动层面提供更高保真度的输入理解。
- 自主研究:智能体可以主动捕捉新兴趋势,或在不需要持续人工介入的情况下对持续对话进行深挖。
- 跨平台整合:智能体工作流可以同时监测多个网络,并把洞察聚合到一个可执行的统一视图中。
从固定流水线转向智能体推理,你才能真正开始“聆听”社交媒体。这种转变会带来一个动态系统:它能像对话本身一样快速演化,而无需频繁修改流水线中的元素。
用 AI 做社交媒体聆听的挑战
毫无疑问,AI 让社交聆听容易了很多,尤其是在理解“为什么”方面。先进的 AI/ML 模型可以分析情绪、预测潜在趋势,甚至解释细微差别。但仍有一个主要挑战存在:如何可靠、规模化地采集社交媒体数据?
最直接的想法,是把智能体工作流直接接到各平台官方 API(如果有)。但官方 API 可能很贵、受速率限制,并且对你如何处理返回数据有限制。此外,API 响应可能随时间变化或不完整。基于这些原因,API 往往并不实际,很多团队会转而依赖网页抓取。
但社交媒体抓取天然困难,主要原因包括:
- 平台复杂且持续变化:社交媒体网站持续演进,交互与导航模式复杂且高度动态,使得数据解析变得困难。
- 反爬虫措施:CAPTCHA、人机验证与限速,需要复杂策略来做 IP 轮换、指纹管理等。
- 数据碎片化:数据分散在多个平台(X、Instagram、Threads、TikTok、Reddit、LinkedIn、YouTube、Facebook 等),难以构建统一的社交媒体数据集。
即使你已经可以使用可信的社交媒体抓取工具,仍然会遇到两个额外障碍:
- 工具兼容性:抓取工具必须与你计划使用的 AI 库或智能体工作流兼容。
- 数据可用性:抓取到的数据必须结构化、清洗,并以 AI 易于理解的格式交付。延迟、不一致格式或缺失字段会降低智能体工作流效果,并提升幻觉风险。可参考 智能体 AI 的最佳数据格式。
因此,尽管 AI 改变了社交聆听,但真正的瓶颈在数据获取。
面向 AI、可落地且可扩展的智能体社交聆听工具
你已经知道:让 AI 智能体访问可靠的社交媒体数据,是智能体社交聆听工作流的核心障碍。因此解决方案也很明确:智能体需要可被信任、且适用于企业级的社交媒体抓取工具。
当 AI 智能体自主调用这些工具时,它们会从指定社交平台获取对 AI 优化的数据;返回数据将成为 AI 分析、推理与归纳洞察的基础。困难在于找到足够好的工具——没有它们,你就会遇到典型的网页抓取的可靠性与可扩展性问题。
因此,面向智能体的社交媒体抓取工具必须:
- 足够稳定,成功率高、停机极少。
- 支持并发请求,以处理大体量数据。
- 以适合 LLM 摄取的格式返回内容,例如 JSON 或 Markdown。
- 能与所选 AI 智能体框架无缝集成——无论是 LangChain、LlamaIndex、CrawlAI、Agno、Dify 或类似框架。
- 能处理反爬虫措施,包括限速、IP 轮换、CAPTCHA 与其他防护。
- 支持多个社交媒体平台。
这正是 Bright Data 通过其 社交媒体抓取工具服务所提供的能力。下面我们详细看看!
Bright Data 的 AI 友好社交媒体抓取工具
Bright Data 是领先的网页数据采集平台,并在顶级社交媒体数据提供商中排名第一。在其面向 AI 的抓取解决方案中,社交媒体抓取工具特别适合智能体工作流:
- 实现 99.99% 可靠性与 99.95% 成功率,确保 AI 智能体持续数据流、停机最小化。
- 为规模化而构建,依托覆盖 195 个国家的 1.5 亿 IP代理网络支持高并发。
- 支持同时批量抓取最多 5,000 个社交媒体页面,让智能体能够处理大量数据。
- 返回 JSON、Markdown 等结构化、LLM 友好格式,优化快速摄取、推理与下游 AI 处理。
- 提供与70+ AI 框架与解决方案的官方集成,并提供原生 API 供自定义实现。
- 自动为你处理反爬虫与反抓取挑战。
- 支持主流平台,例如 Facebook、Instagram、LinkedIn、TikTok、X、Pinterest、Quora、YouTube、Threads、Reddit、Vimeo 等。
- 按成功计费(pay-per-success)模型确保成本效率,让大规模 AI 驱动的数据采集变得可预测且经济。
注意:该解决方案也可通过 Bright Data 的 Web MCP server 原生使用,从而更容易集成进智能体工作流。
如何构建一个由 Bright Data 支撑的社交聆听智能体
在这一节的指导中,你将看到如何从一个简单的社交聆听智能体开始。我们会用 LangChain 构建,并连接到 Gemini,但任何其他 AI 智能体框架与 LLM 提供商也都适用。
注意:如果你想要更实操的说明,了解如何使用 Bright Data 解决方案构建 AI 驱动的社交聆听应用,可参考网络研讨会“构建 AI 驱动的社交聆听应用”。
按下列步骤操作!
前置条件
为完成本教程,请确保你具备:
- 本地安装 Python 3.10。
- 一个Bright Data 账号并准备好 API key。
- Gemini API key(或任意其他LangChain 支持的 LLM 提供商的 API key)。
- 对LangChain 智能体如何工作有基础了解。
可参考官方指南:如何配置 Bright Data API key。请安全保存该 key,因为你将用它通过官方 LangChain–Bright Data 工具把 LangChain 智能体连接到 Bright Data。
关于 Bright Data 与 LangChain 的集成更多信息,可参考以下博客:
步骤 #1:搭建 LangChain 项目
为你的社交聆听智能体创建一个新的 Python 项目:
mkdir agentic-social-listening
cd agentic-social-listening在项目文件夹中,创建虚拟环境并激活:
python -m venv .venv
source .venv/bin/activate # or on Windows: .venv\Scripts\activate添加一个 agent.py 文件,用于存放社交聆听智能体逻辑。项目结构应如下:
agentic-social-listening/
├── .venv/
└── agent.py在已激活的虚拟环境中安装所需库:
pip install langchain langchain-google-genai langchain-brightdata分别是:
langchain:简化 AI 智能体构建。langchain-google-genai:通过ChatGoogleGenerativeAI集成将智能体连接到 Gemini。langchain-brightdata:通过官方集成把 LangChain 智能体连接到 Bright Data 的抓取工具解决方案,文档中有说明。
很好!现在用你喜欢的 Python IDE 打开项目文件夹,准备开发智能体社交聆听工作流。
步骤 #2:定义智能体工作流
假设你要构建一个社交聆听智能体,用于监测同一条公告在两个帖子上的情绪与提及情况(一个在 Instagram,一个在 TikTok)。尽管帖子不同,但底层公告相同。
这是个很有意思的例子,因为它展示了智能体如何对同一活动在多平台上的互动进行追踪,识别共性与平台特有的情绪,并检测产品提及或促销请求。
这里我们用 Nike 的一则公告作为示例。它在Instagram 上长这样: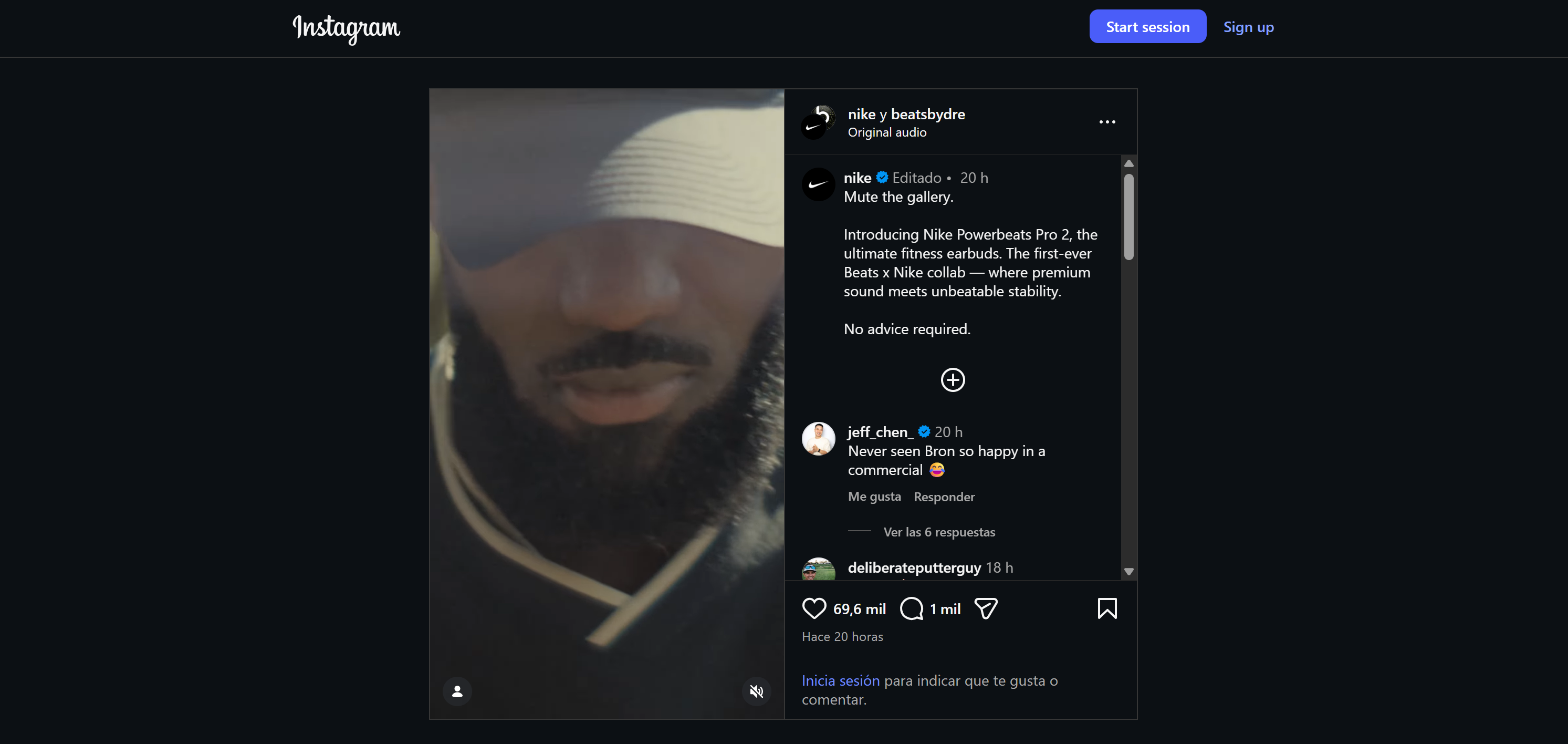
在TikTok 上长这样: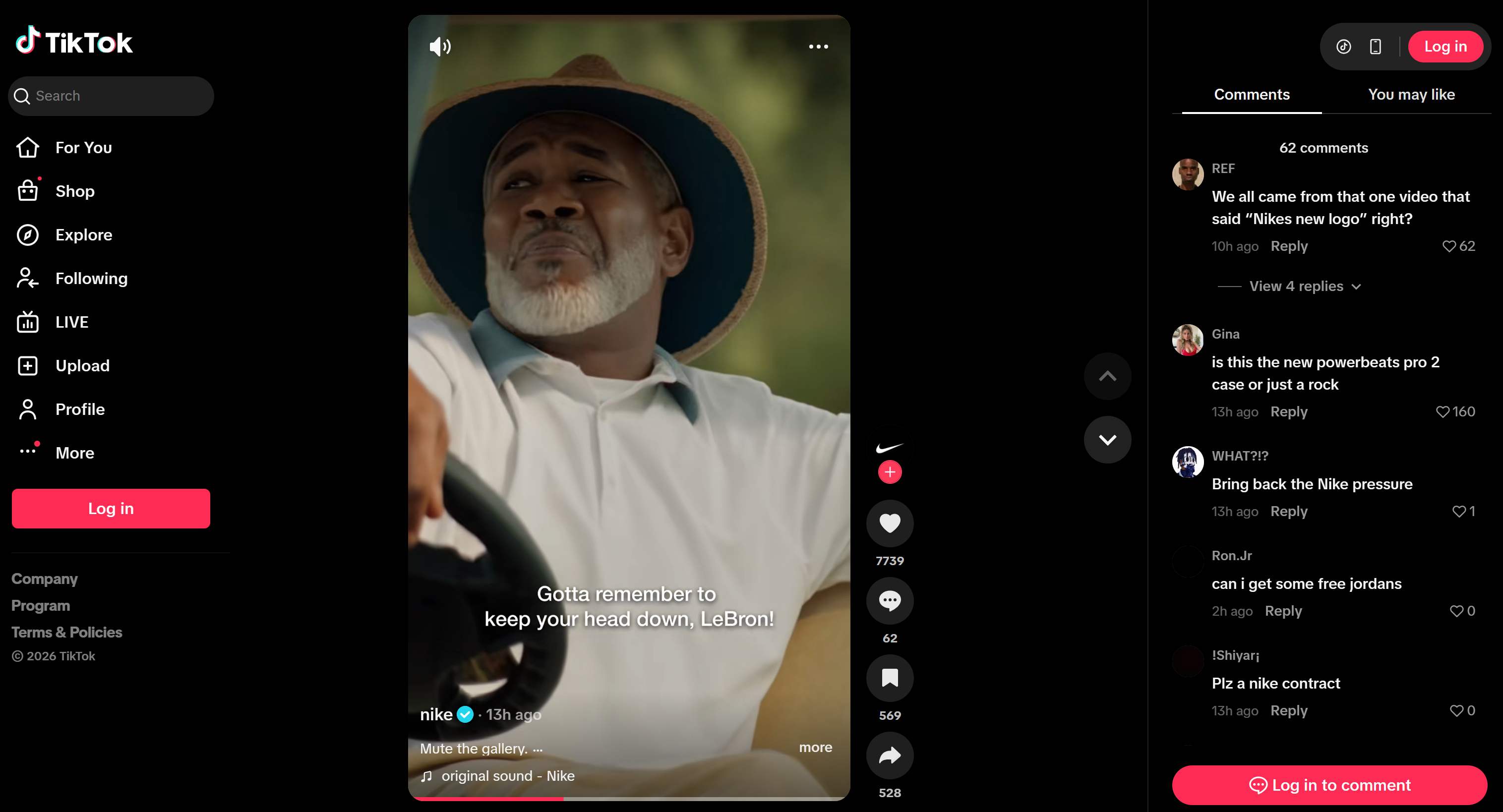
思路是让 AI 智能体使用 Bright Data 的社交媒体抓取工具 API抓取两个帖子里的评论,然后由 Gemini 驱动的 LLM“大脑”对数据进行分析与处理。这样就完成了一个基础的智能体社交聆听工作流。
注意:这只是一个示例,假设你已经有目标社交帖子。在生产可用的场景中,Bright Data 工具还可用于网页搜索、追踪整个社交账号,并以规模化方式处理多平台社交聆听。
都清楚了!开始开发智能体吧。
步骤 #3:实现智能体
要构建前面介绍的社交聆听智能体,请在 agent.py 中加入以下代码:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# Replace with your actual API keys
GOOGLE_API_KEY = "<YOUR_GOOGLE_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
# Initialize the LLM engine
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Initialize the Bright Data Web Scraper API tool
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Create a ReAct agent with access to the Bright Data Web Scraping APIs
agent = create_agent(llm, [web_scraper_api_tool])
# Define a simple social listening query
prompt = """
You are a social listening expert.
Targets:
- Instagram Reel: "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- TikTok Video: "https://www.tiktok.com/@nike/video/7618336096694406414"
Task:
1. Use Bright Data's Social Media Scraper API to collect all comments from the target posts.
2. Generate a Markdown report summarizing engagement and sentiment.
3. Highlight comments mentioning other Nike products, promotions, or interesting user requests for follow-up analysis.
"""
# Stream the agent's step-by-step output
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()这段代码做了什么:
- 读取 Gemini 与 Bright Data API 访问凭证(生产环境中应从环境变量读取)。
- 创建一个由 Gemini 驱动的 AI 引擎,用于处理与分析社交媒体数据。
- 通过 LangChain 工具
BrightDataWebScraperAPI将智能体连接到 Bright Data 的抓取工具 API(包括社交媒体抓取工具 API)。 - 使用
create_agent()定义一个可动态调用 Bright Data 抓取工具的 ReAct 智能体。 - 告诉智能体目标(Instagram 与 TikTok 帖子)与任务(收集评论、情绪分析、生成报告、标记关键提及)。
- 启动智能体并将结果流式输出到终端。
任务完成!你已经实现了一个用于社交聆听的基础智能体工作流。
步骤 #4:测试智能体
运行:
python agent.py你会看到智能体按预期调用 bright_data_web_scraper 工具: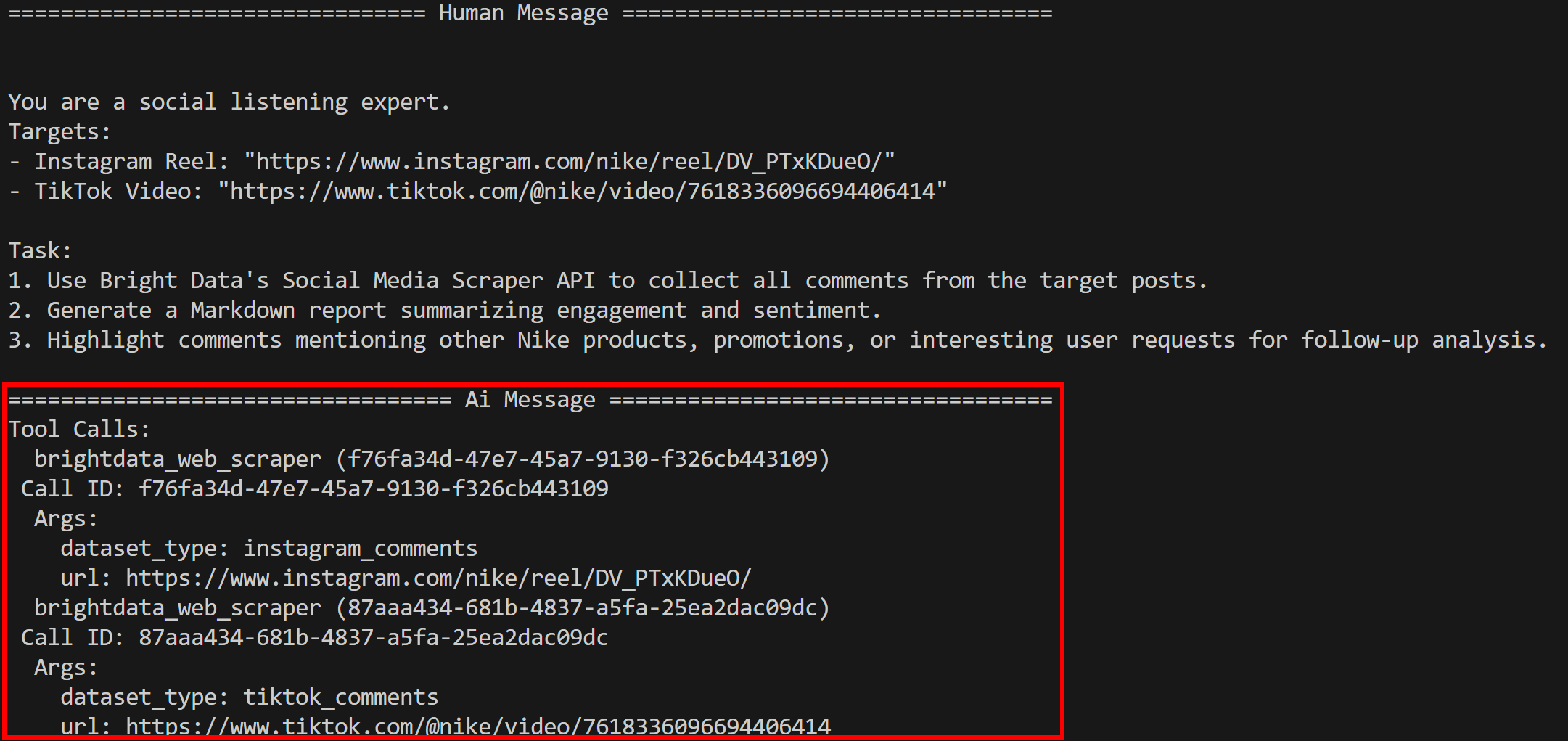
具体而言,它会调用底层的 instagram_comments 与 tiktok_comments 工具。底层实际依赖的是 Bright Data 的 Instagram 评论抓取工具 与 TikTok 评论抓取工具。
工具返回 JSON 结构化数据,包含从两个帖子抓取到的全部评论: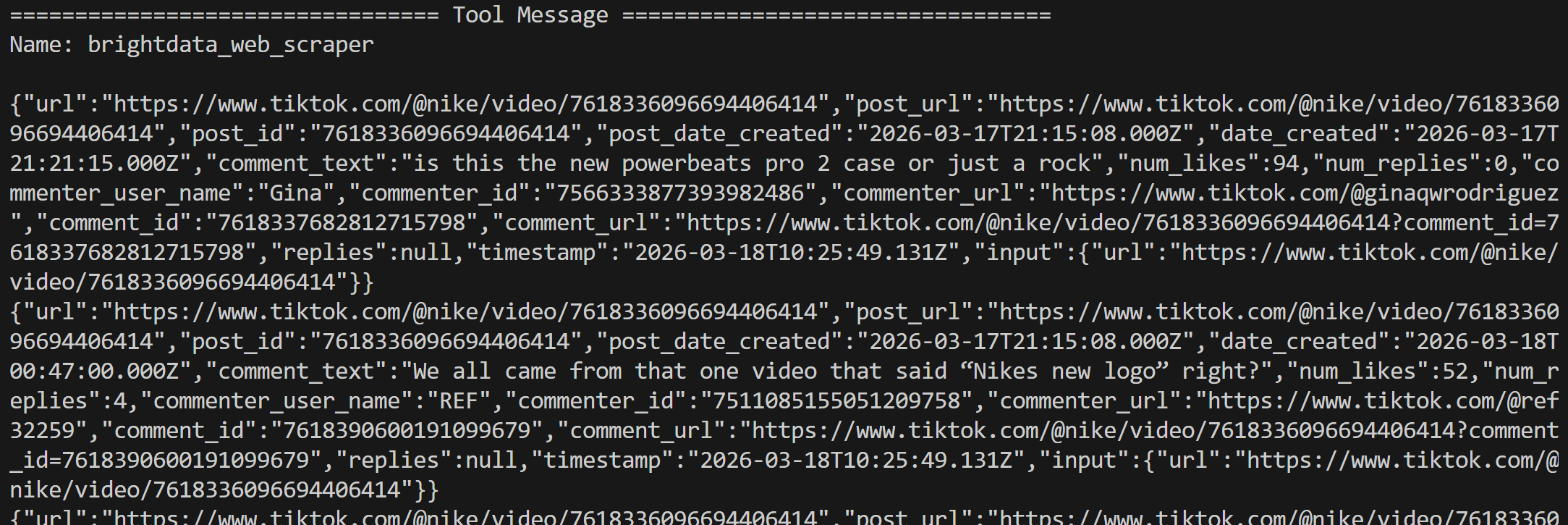
随后,智能体会按指令对评论进行社交聆听处理,并生成一份 Markdown 报告: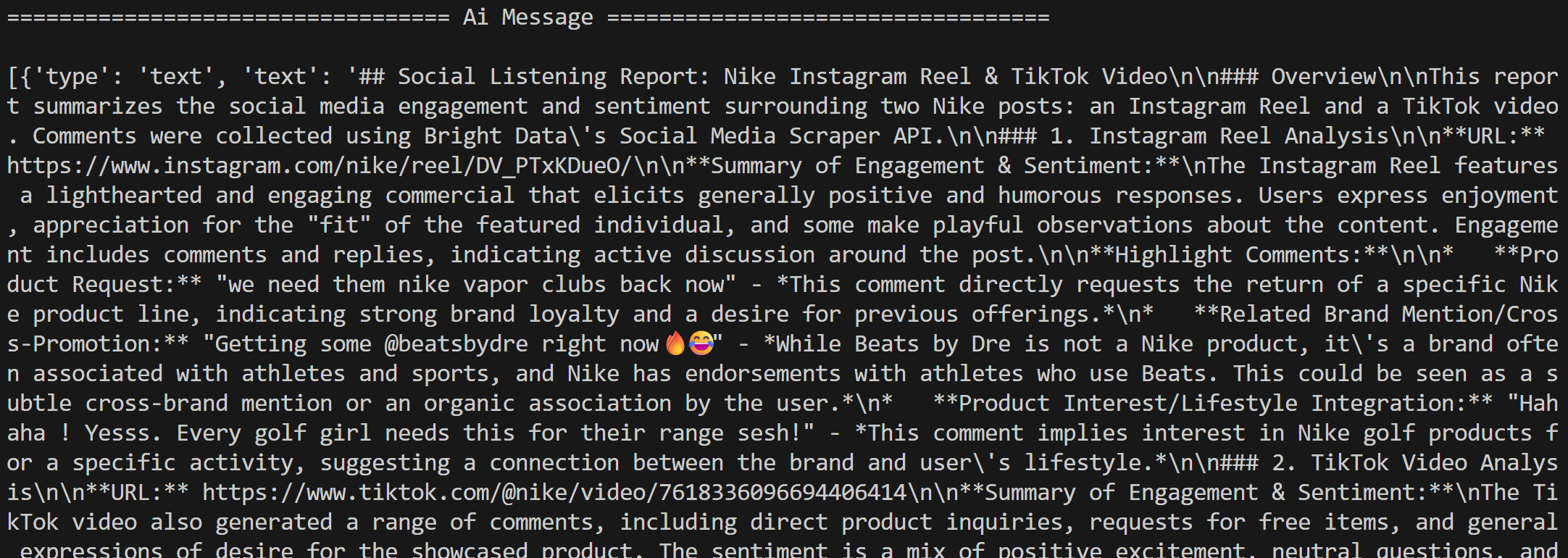
在 Markdown 渲染器中查看,报告会像这样: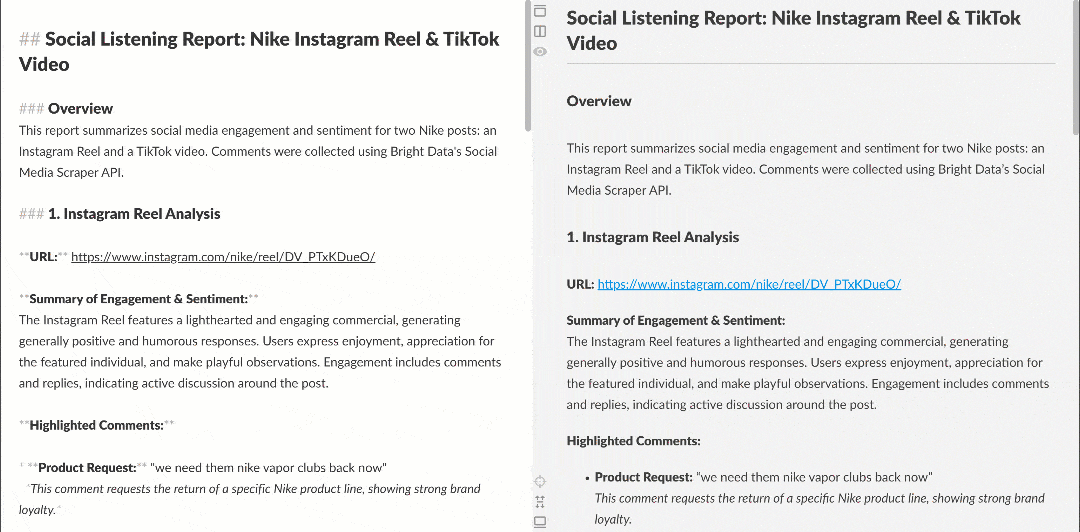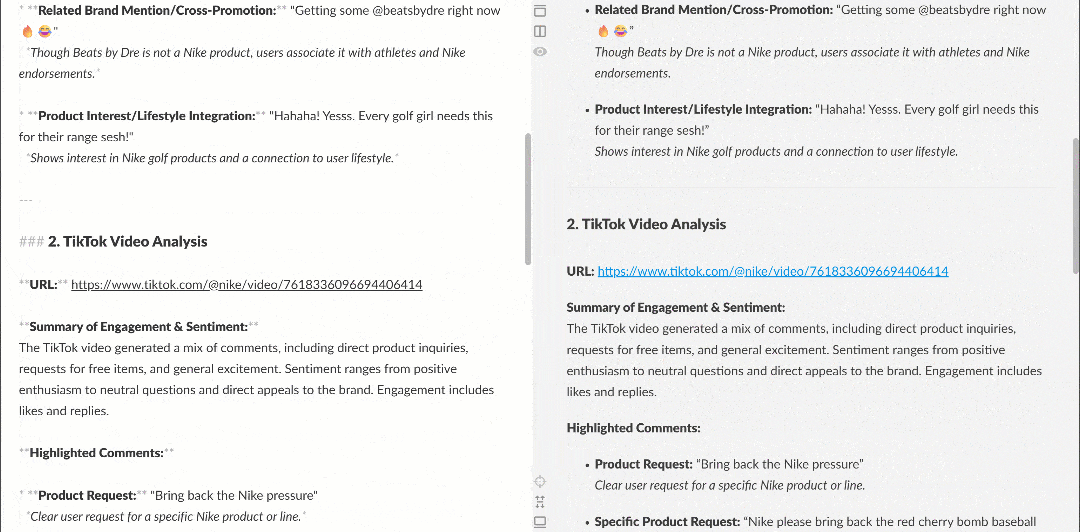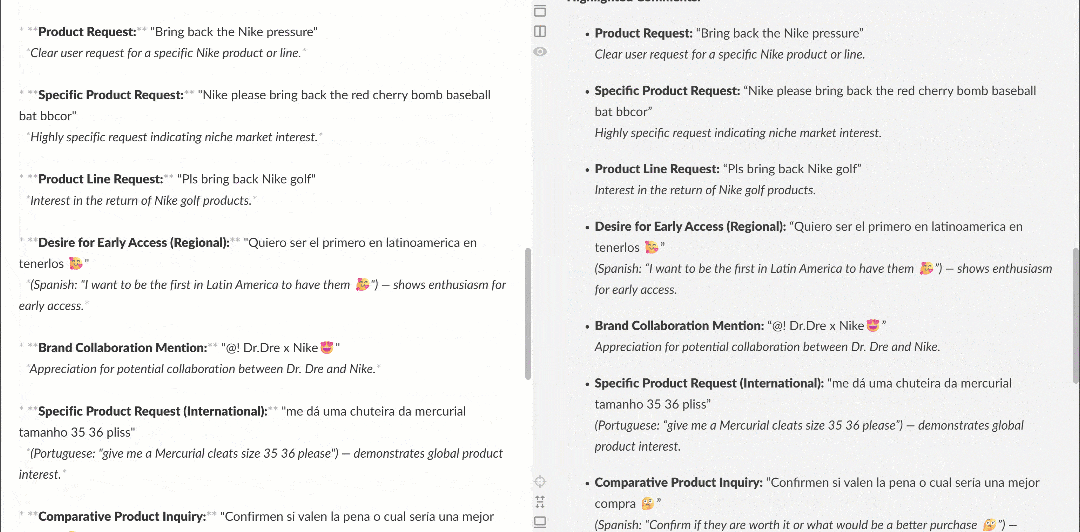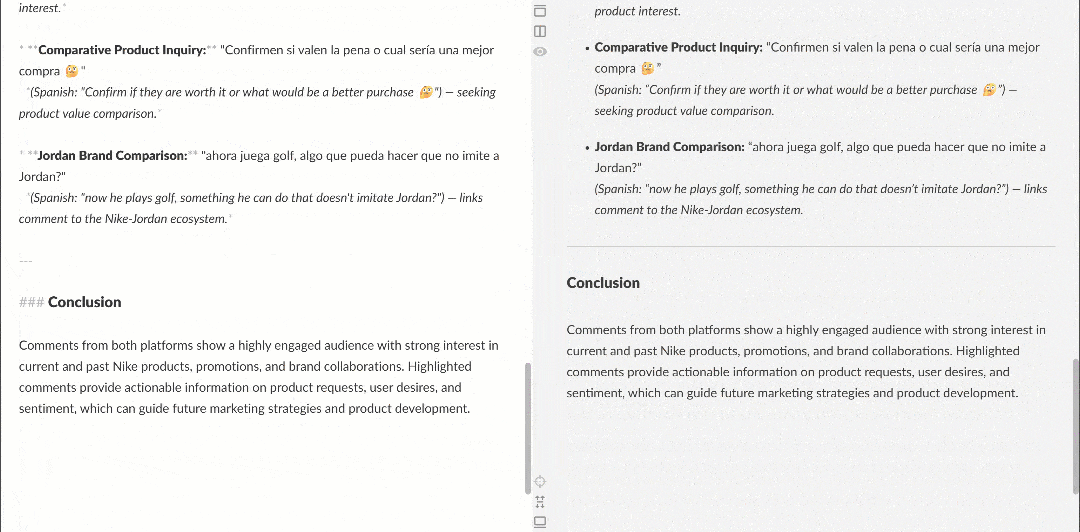
注意其中包含有趣洞察,例如有多位用户要求 Nike 重新推出 Nike Golf 或更多关注高尔夫产品。这些细节可能会被基础情绪分析流程忽略。
另外,如果发生错误,或智能体判断抓取到的数据不足以达成目标,它会自动继续抓取更多评论或重复调用 Bright Data 工具。这让智能体具备真正的自主性。
就是这样!你已经学会了如何在 LangChain 中构建一个由 Bright Data 驱动的智能体社交媒体聆听工作流。
生产可用的社交聆听智能体工作流
上一章展示了如何构建一个简单的社交聆听智能体。但生产可用的智能体工作流要复杂得多。下面我们看看该如何设计,以及落地实现的步骤!
架构
在智能体社交聆听工作流中,相比使用单个“巨型智能体”,使用多个专门化 AI 智能体通常会得到更好的结果。每个智能体专注于不同职责,一个可能的智能体配置是:
- 数据获取智能体:通过 Bright Data 的社交媒体抓取工具等工具,从多个平台收集帖子、评论、账号资料或互动指标。
- 分析智能体:处理采集到的数据,提取趋势、情绪与其他可执行洞察,把原始社交内容转化为有意义的情报。
- 报告/输出智能体:把分析后的数据格式化为看板、摘要或文件(JSON、CSV),便于人或其他 AI 系统消费。
- 协调智能体:统筹整个工作流,确保交接顺畅,评估结果质量,并在需要改进或补采数据时自动迭代流程。
路线图
给定以上四个智能体,可按如下方式实现社交聆听的智能体工作流:
- 选择AI 智能体技术栈:根据所需智能体类型、工具集成与工作流编排便利性选择。
- 添加智能体:在所选框架内创建四个占位智能体。
- 集成社交媒体抓取工具:让数据获取智能体可以访问 Bright Data 的社交媒体抓取工具或单个平台的专用抓取工具。
- 配置数据获取任务:指示数据获取智能体抓取所需社交媒体数据。
- 分析采集到的数据:指示分析智能体处理文本、情绪、趋势与互动指标。
- 生成结构化报告:指示报告智能体输出所需格式。
- 协调与迭代:实现协调智能体以监控结果、触发重复循环等。
- 设计智能体闭环:连接四个智能体(数据获取 → 分析 → 报告 → 协调)。
- 自动化调度:设置周期性运行,实现持续社交聆听。
智能体社交聆听工作流示例
基于前面展示的AI 智能体路线图,你可以构建多种社交聆听智能体工作流。以下是一些示例!
品牌情绪监测
AI 智能体持续追踪各社交平台上对你品牌的提及。借助 Bright Data 的社交媒体抓取工具,智能体收集帖子、评论与互动,然后分析情绪、发现新兴趋势并标记负面峰值,从而实现主动式口碑管理。
竞品分析
AI 智能体监测 TikTok、X、Reddit 与 YouTube 评论中的话题标签、关键词与讨论;AI 进一步识别内容策略、活动表现与受众互动模式,帮助你实时调整策略。
趋势发现与预测
AI 智能体监测 TikTok、X 与 Reddit 上的话题标签、关键词与讨论。Bright Data 的抓取工具 API 提供结构化、LLM 友好数据,让智能体识别上升趋势、预测热度,并指导营销或产品决策。
危机检测与响应
智能体监测多个网络中突发的负面情绪激增或病毒式传播内容。借助 Bright Data 的社交媒体抓取工具,AI 可立即告警、起草符合语境的回复,或触发自动升级(escalation)流程。
活动反馈分析
AI 智能体从 Facebook、Instagram、YouTube 等平台收集用户反应、评论与帖子指标。通过 Bright Data 的抓取工具,智能体能获取所需数据来追踪活动效果并优化信息传递策略。
结论
本文中,你了解了什么是社交媒体聆听、它包含哪些内容,以及为什么智能体工作流是实现社交聆听的最佳方式。你也清晰理解了其中挑战,并知道如何使用面向 AI 的社交媒体抓取工具克服它们。
Bright Data 通过专门的、企业级且易于集成的 社交媒体抓取工具支持社交聆听。这让你可以在不牺牲可靠性或性能的前提下,构建可扩展的社交聆听智能体工作流(以及其他社交媒体营销用例)。
立即免费创建 Bright Data 账号,探索我们面向 AI 的网页数据采集解决方案!
FAQ
社交聆听与社交监测有什么区别?
社交监测(social monitoring)通过收集通知、点赞与指标来追踪“发生了什么”。社交聆听则通过分析对话背后的情绪与趋势来理解“为什么”,以指导长期策略。
情绪分析与社交聆听有什么区别?
情绪分析评估文本中的情感或观点,如正向、负向或中性。社交聆听更广:它跨平台监测对话以追踪趋势、品牌认知与客户反馈,并常把情绪分析作为其中一个工具。
AI 智能体能用于社交聆听吗?
能。AI 智能体非常适合社交聆听,因为它们能够适应变化或意外场景,这正是不断演化的社交媒体环境的典型特征。
AI 需要哪些工具才能做社交聆听?
用于社交聆听的 AI 智能体需要采集社交媒体数据的工具。通过集成 Bright Data 的社交媒体抓取工具等抓取工具,智能体可以规模化监测多个平台,并输出实时、可执行的情报。
哪些社交媒体平台适合做社交聆听?
最适合用于智能体社交聆听进行抓取的平台包括:X、Reddit、Threads、Facebook、Instagram、LinkedIn、TikTok、Quora、Pinterest、YouTube 与 Vimeo。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




