


“社交聆听的成功关键在于使用合适的数据采集工具。没有准确、可靠的数据,你的洞察就会失真,你的决策也会偏离目标。从高质量数据开始,其他一切都会水到渠成。” – Vadim Savin,@notJust.dev 创始人
大家好!我是 Vadim,很高兴与大家分享这篇教程,介绍我如何构建一款 AI 驱动的社交聆听应用。这个项目旨在帮助你监控品牌、获取市场情报,并借助 Bright Data 工具与前沿 AI 技术在竞争中保持领先。
在开始之前,我想先分享一段小背景。几个月前,我在寻找一款能在整个互联网范围内监控我品牌的工具。市面上确实有很多针对特定平台(比如 Google 或社交媒体)的专用工具,但我找不到一款能让我对品牌在全网的健康状况获得 整体视角的产品。我想知道别人何时提到我的工作、何时提出投诉,或竞争对手在做什么新动作。既然找不到完美的工具,我就决定自己做一个。
今天,我会带你走完整个流程——从数据采集到 AI 驱动的洞察与自动化。无论你是开发者、企业主,还是对社交聆听感到好奇,这份指南都会给你可落地的步骤,把这些能力实现到你自己的项目中。让我们开始吧!
为什么社交聆听很重要
先从一个简单的问题开始:你多久会去看看网上都在怎么评价你的品牌?如果答案是“很少”,那你很可能错过了来自客户与竞争对手的宝贵洞察。
社交聆听的核心,是监控线上对话来理解 客户情绪、新兴趋势,甚至在 潜在公关危机升级前就提前发现。它也是一种强有力的方式:通过分析竞争对手的活动与策略来保持领先。不过难点在于 信息的分散性——它散落在社交媒体、论坛、博客与搜索引擎中。
这正是 Bright Data 与 大语言模型(LLMs)能发挥作用的地方。把这些技术结合起来,我们就能从全网采集数据、处理数据并提炼可执行洞察——全部集中在一个地方完成。
社交聆听应用的架构
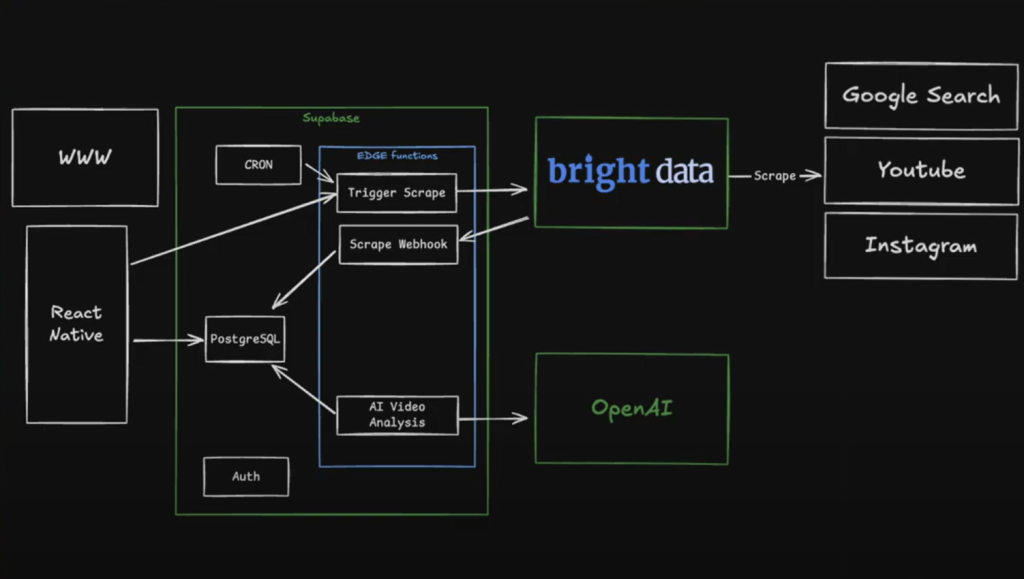
下面是我们将要构建系统的高层概览:
- 数据采集:使用 Bright Data 的 API 从搜索引擎、社交媒体平台及其他来源抓取数据。
- 数据存储:将结构化数据存入数据库,便于访问与分析。
- AI 驱动洞察:使用 OpenAI 的大语言模型提取关键洞察,例如情感分析、热门话题与客户痛点。
- 自动化:搭建一套系统,在自动驾驶模式下持续监控并更新数据。
下面我们一步一步拆解。
第 1 步:使用 Bright Data API 采集数据
抓取搜索引擎结果
为了监控品牌在 Google 等搜索引擎上的表现,我们将使用 Bright Data 的搜索引擎 API(搜索引擎 API)。这款工具可以轻松抓取搜索结果,并提取排名、链接、描述等数据。
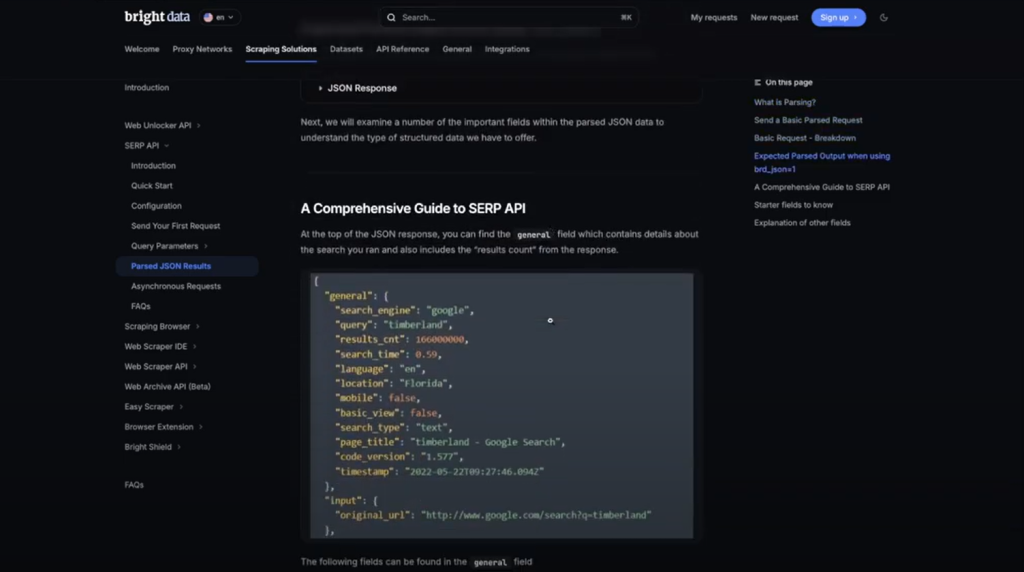
它的工作方式如下:
- 在 Bright Data 中配置一个 zone,并启用 CAPTCHA 解决能力,以处理反抓取机制。
- 使用 SERP API 针对指定查询(例如你的品牌名)发起请求。
- 解析返回的 JSON 响应,提取你需要的数据,如自然搜索结果链接、标题与描述。
采集到数据后,把它存入 PostgreSQL(托管在 Supabase)等数据库中,便于更快访问与后续分析。
抓取社交媒体数据
社交媒体平台是品牌提及与客户反馈的“金矿”。Bright Data 的 网页爬虫工具 API 提供了面向 YouTube、Instagram、LinkedIn 与 Reddit 等平台的预置爬虫工具。
例如,要抓取 YouTube 频道数据:
- 使用 YouTube Profiles Scraper 提取订阅数、视频链接与描述等信息。
- 设置 webhook,在任务完成后自动接收抓取结果。
- 将数据存入数据库以便进一步处理。
最棒的是:Bright Data 的爬虫工具会持续维护并定期更新,因此你不必担心网站改版导致代码失效。
第 2 步:用 AI 分析数据
采集到数据后,下一步就是用 AI 提取 可执行洞察。这正是 OpenAI 的大语言模型(LLMs)派上用场的地方。
用例 1:视频字幕分析
对 YouTube 视频,我们可以分析字幕来:
- 总结内容。
- 提取关键讨论话题。
- 识别品牌提及与对应时间戳。
通过 OpenAI 的 API,我们会把字幕与一个提示词一起发送,并指定期望的输出格式(例如 JSON)。AI 会返回结构化摘要与关键话题,我们再把它们存入数据库。
用例 2:评论情感分析
客户反馈对于理解公众舆论至关重要。通过分析 YouTube 评论(或其他平台的帖子),我们可以:
- 判断 情感倾向(正面、负面或中性)。
- 提取常见话题与痛点。
- 识别趋势或潜在公关危机。
流程包含:
- 将一批评论发送到 OpenAI 的 API,并在提示词中要求进行情感分析与话题提取。
- 解析返回的 JSON,并把结果存入数据库。
- 在易用的仪表盘中展示洞察。
第 3 步:自动化工作流
要让系统真正强大,我们需要自动化整个流程。这通常通过设置一个 cron job 定期执行以下任务:
- 触发对已追踪对象的数据抓取(例如指定频道、搜索查询或社交媒体账号)。
- 对新采集的数据运行 AI 分析。
- 更新数据库,并在发生重大变化时通知用户。
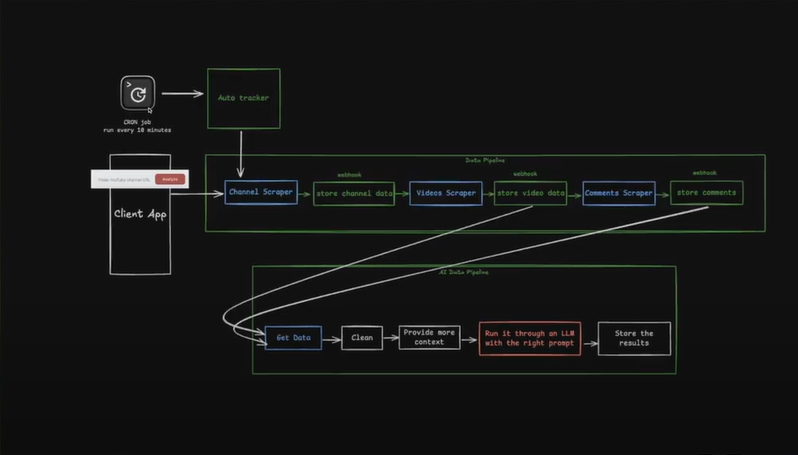
例如,你可以让系统每 24 小时抓取一次 Google 搜索结果,或每 10 分钟监控一次 Reddit 帖子。这样无需人工干预,也能始终保持洞察最新。
第 4 步:构建用户界面
在前端,你可以创建一个仪表盘,让用户能够:
- 追踪特定频道、搜索查询或账号。
- 查看实时洞察,如情感分析与热门话题。
- 在出现显著变化或潜在公关危机时接收提醒。
使用 React Native 与 Expo 等工具,你可以构建一个跨平台应用,在网页端与移动端都能顺畅运行。
下一步?如何增强你的社交聆听应用
以下是一些让你的应用更进一步的想法:
- 告警与通知:为特定指标或阈值设置邮件或 Slack 告警。
- 竞品分析:对比你的品牌与竞争对手的表现与情感倾向。
- 历史数据:长期追踪变化,用于识别趋势与增长。
- AI 建议:让 AI 基于洞察给出可执行行动建议。
- RAG 系统:实现检索增强生成(RAG),为你的数据构建聊天机器人或搜索引擎。
总结
通过将 Bright Data 的爬虫工具与 OpenAI 的大语言模型结合,我们构建了一套可扩展、AI 驱动的社交聆听应用,能够在全网监控你的品牌。从数据采集到洞察提取再到工作流自动化,这套系统能帮助你保持信息同步,并做出数据驱动的决策。
希望这份指南对你有所帮助并带来启发。如果你有任何问题或想分享你的用例,欢迎在社交媒体上联系我,或去我的 YouTube 频道查看更多教程。
也非常感谢 Bright Data 提供了让这个项目成为可能的工具。