在客户电话前进行账户调研通常每位销售代表需要十到十五分钟。工作流大多是手动的:销售代表离开 Salesforce,打开 Google,浏览多个标签页,然后将发现粘贴到备注字段中。大部分工作是搜索和综合。
Bright Data 的 网络解锁器 会从大多数公共 URL 返回干净的 Markdown。将其接入 Salesforce Agentforce,可让销售代表通过聊天提示获取账户调研,并带有来源归因,而无需离开 Salesforce。在底层,该构建由一个 Agentforce 子代理、三个 Apex 类,以及一个小型 Cloudflare Worker 代理组成。
TL;DR
- 一个 Agentforce 子代理从销售代表处接收自然语言提示,调用 Bright Data 网络解锁器,并在 Salesforce 聊天中返回带来源归因的账户简报。
- Apex 的 HTTP 客户端在处理超过几 KB 的 chunked-transfer 响应时会无警告失败(已在 API v66.0 上验证),因此集成通过一个小型 Cloudflare Worker 路由,该 Worker 会缓冲并以显式的 Content-Length 头重新提供响应。
- Agentforce 的 Canvas UI 隐藏了聊天驱动代理接收从提示中提取的输入所需的
is_user_input: TrueYAML 标志。修复在 Script 模式中完成。 - Salesforce 当前的 External Credential 模式拆分为三个对象(External Credential、Named Credential、Permission Set),其中有一个很容易漏掉的复选框,跳过会返回 401。
- Agentforce 默认会从代理响应中删去外部 URL。代理会在内部读取它们,但除非域名在 Trusted URLs 允许列表中,否则不会显示。
- 总体占用约 6 KB 的 Apex、一个 Cloudflare Worker、三个 Salesforce 凭据对象,以及一个子代理。每个代码块都在一个真实的 Salesforce Developer Edition org 中测试过。
开始之前
你需要四个账户和工具,本教程全部免费:
- 一个 Bright Data 账户,并至少已配置一个 网络解锁器 区域。新账户包含免费试用额度,本教程的请求量完全在这些额度范围内。
- 一个 Cloudflare 账户,用于 Worker 代理。免费层不需要信用卡;首次使用时你会选择一个
workers.dev子域名。 - 一个启用了 Agentforce 的 Salesforce Developer Edition org。 最近的 Developer Edition org 默认启用 Agentforce、Data Cloud 和 Agentforce Studio。在继续到第 5 部分之前,请在 App Launcher 中确认出现 Agentforce Studio 应用;如果没有,则你的 org 不是 Agentforce org,后续部分将无法工作。
- 一种发送测试 HTTP 请求的方法。 第 2 部分包含一个
curl命令用于验证 Worker。macOS、Linux 和 Windows 11 都自带curl。如果你更愿意使用 GUI,Postman 或 Insomnia 也可使用相同的 headers 和 body。如果你没有这些且不想安装,可以跳过独立的 Worker 测试,改为在第 3 部分从 Salesforce 端到端验证。 - System Administrator 配置文件(或具备 Author Apex、Modify All Data、Customize Application 的配置文件)。 全新的 Developer Edition org 会自动提供。如果你在公司沙盒中使用受限配置文件,请改用一个全新的 Developer Edition org。
你将构建什么
你将构建一个名为 Account Briefing Agent 的 Agentforce 代理。销售代表输入一个自然语言问题。代理将提示路由到一个自定义子代理,选择合适的工具,通过一个轻量的 Cloudflare Worker 代理调用 Bright Data,综合生成带来源归因的账户简报,并将简报发布到聊天中。架构包含五个部分:
- Bright Data 网络解锁器 作为网页数据原语。它是一个单一端点,接收大多数 URL 并返回干净的 Markdown。
- Cloudflare Worker 作为 Salesforce 与 Bright Data 之间的代理。免费层可覆盖一个小团队。
- Salesforce External Credential + Named Credential + Permission Set 作为认证层。
- Apex,包含三个类:一个共享服务,加上两个使用
@InvocableMethod的包装器(该注解使其可从 Agentforce 调用,每个 Agent Action 一个)。 - Agentforce 子代理,附带两个动作、一个指令块,以及一个分类描述。
架构概览
以下是从销售代表提示到简报的请求流:
Rep prompt in Agentforce
│
▼
Agent Router ──► Account Web Intelligence subagent
│
├─► Apex: BrightDataNewsAction
│ └─► Named Credential → Cloudflare Worker → Web Unlocker → Google News
│
└─► Apex: BrightDataFetchAction
└─► Named Credential → Cloudflare Worker → Web Unlocker → target URL
│
▼
LLM synthesis ──► Briefing back to the repCloudflare Worker 的存在是因为 Salesforce Apex 无法可靠地消费 HTTP/1.1 chunked-transfer 响应,而 Bright Data 对于超过几 KB 的任何负载都会使用分块编码。Worker 将响应缓冲到一个单一的 ArrayBuffer 中,并以显式的 Content-Length 头重新提供。没有它,Apex 的每次调用都会返回 200 状态和零字节 body。下面第 2 部分将讲解调试与修复。
Bright Data 有多个产品适合这种构建:搜索引擎 API 用于解析后的 Google 结果,面向 LinkedIn 和 Crunchbase 的专用爬虫工具,以及其他产品。本构建仅使用 网络解锁器,因为它对任何 URL 都通过同一个端点工作,从而保持 Apex 侧简单。第 2 部分中的 Cloudflare Worker 代理同样覆盖每个 Bright Data API 端点,因此后续替换为 搜索引擎 API 或专用抓取工具并不会改变 Salesforce 侧的接线方式。
第 1 部分:设置 Bright Data
如果你没有 Bright Data 账户,请在 Bright Data 注册页面创建一个。你将使用的 网络解锁器 区域位于控制面板的 Web Access API 部分。
创建或记录 网络解锁器 区域
打开控制面板,在左侧导航中进入 Web Access API,并确认存在一个 网络解锁器 区域。如果你的账户没有,点击 Create API(右上角)并从下拉菜单中选择 Unlocker API。给它任意名称(区域名称创建后无法更改,因此请选择稳定的名称,例如 agentforce_unlocker)。无论你怎么命名,都把它记下来。你会在第 4 部分将其填入 BrightDataService.cls 中的 UNLOCKER_ZONE 常量,并在第 2 部分的 curl 测试中使用它。
网络解锁器 区域是两个 Agentforce 动作都使用的原语。
创建 API token
点击 Settings(左下角)→ Users and API keys 选项卡 → 使用 User 权限 Add API key。该 key 生成时只显示一次,随后会被遮罩。现在就复制并安全保存;你会在第 3 部分将其粘贴到 Salesforce 中。
这就是完整的 Bright Data 设置。
第 2 部分:部署 Cloudflare Worker 代理
在配置 Salesforce 之前,你需要在 Bright Data 前面放一个代理。原因是 Salesforce Apex 读取 chunked-transfer 响应的方式存在限制;任何进行非简单 HTTP callout 的 Apex 开发者都很可能遇到它。
这个 bug
Salesforce Apex 的 Http 客户端支持标准 HTTP,但有一个实际缺口:它无法可靠解析使用 chunked transfer encoding 且没有 Content-Length 头的 HTTP/1.1 响应。对于分块响应,callout 返回 Status Code = 200、Content-Type = null、Response Size = 0 bytes,且没有异常或警告。getBody() 和 getBodyAsBlob().toString() 都返回空字符串。
Bright Data 的 /request 端点对超过几 KB 的响应使用 chunked transfer encoding。对一个很小的测试页面(Bright Data welcome.txt)的 网络解锁器 调用低于阈值,会返回带 content-length 的响应,Apex 可干净解析。但真实页面(公司主页、Google News 搜索)会触发阈值并分块,Apex 返回空 body。
两点证明这是 Apex 侧而非网络侧:对同一端点、同一 payload 的 curl 调用会干净返回 9 KB body,而从 Apex 匿名执行发起的同一调用返回 0 bytes,且响应头中有 Transfer-Encoding: chunked。
修复是结构性的,而不是配置更改:在 Salesforce 与 Bright Data 之间放置一个缓冲代理。该代理完整读取 Bright Data 的分块流,然后以显式的 Content-Length 头将响应重新提供给 Salesforce。Apex 可干净解析该响应。
Cloudflare Worker 很适合托管此代理。它在低流量下免费,几分钟即可部署,在边缘运行,并且整个 body 的代码可在一屏 JavaScript 中完成。
创建 Worker
如果你没有账户,请在 Cloudflare 控制面板 注册。在控制面板中找到 Workers(根据你的控制面板版本,它可能出现在 Compute → Workers & Pages 下)。点击 Create application,然后从模板中选择 Hello World。首次使用时,Cloudflare 会提示你选择一个 workers.dev 子域名;随便选一个(这是你的免费开发子域名)。将 Worker 命名为容易记住的名称;本构建使用 bd-proxy。占位符部署后,点击 Edit code。
在编辑器中选中所有占位符代码并粘贴以下内容替换:
/**
* Bright Data to Salesforce Apex proxy.
*
* Salesforce Apex does not reliably consume HTTP/1.1 chunked-transfer
* responses, which is what Bright Data returns for any non-trivial payload.
* This Worker buffers the full response and re-serves it with an explicit
* Content-Length header. Apex parses that response cleanly.
*
* Production deployments typically route external API calls through an
* integration layer like MuleSoft or Heroku. This Worker is the minimal
* stand-in for that role.
*/
export default {
async fetch(request) {
const url = new URL(request.url);
const bdUrl = 'https://api.brightdata.com' + url.pathname + url.search;
// Strip Cloudflare-injected headers we shouldn't forward upstream.
const forwardHeaders = new Headers(request.headers);
forwardHeaders.delete('host');
forwardHeaders.delete('cf-connecting-ip');
forwardHeaders.delete('cf-ray');
forwardHeaders.delete('cf-visitor');
forwardHeaders.delete('x-forwarded-for');
forwardHeaders.delete('x-forwarded-proto');
forwardHeaders.delete('x-real-ip');
try {
const bdResponse = await fetch(bdUrl, {
method: request.method,
headers: forwardHeaders,
body: ['GET', 'HEAD'].includes(request.method)
? undefined
: await request.arrayBuffer(),
});
// Buffer the entire response into a single ArrayBuffer. This collapses
// chunked transfer into a buffer of known length.
const bodyBuffer = await bdResponse.arrayBuffer();
const responseHeaders = new Headers();
const ct = bdResponse.headers.get('Content-Type');
if (ct) responseHeaders.set('Content-Type', ct);
responseHeaders.set('Content-Length', bodyBuffer.byteLength.toString());
const brdStatus = bdResponse.headers.get('x-brd-status-code');
if (brdStatus) responseHeaders.set('X-Brd-Status-Code', brdStatus);
return new Response(bodyBuffer, {
status: bdResponse.status,
headers: responseHeaders,
});
} catch (err) {
return new Response(
JSON.stringify({ error: 'Proxy error', message: err.message }),
{ status: 502, headers: { 'Content-Type': 'application/json' } }
);
}
},
};修复集成的两行是 await bdResponse.arrayBuffer()(将整个分块流读入内存)以及从 bodyBuffer.byteLength 设置的显式 Content-Length 头(Apex 可从中干净解析 body)。其他部分处理 header 转发:它会为入站请求剥离 Cloudflare 注入的 headers,并为出站响应保留上游状态码。
点击 Deploy(右上角)。Cloudflare 会给你一个类似 https://<worker-name>.<your-subdomain>.workers.dev 的 URL。复制它;你会在第 3 部分的 Salesforce 中用到这个 URL。
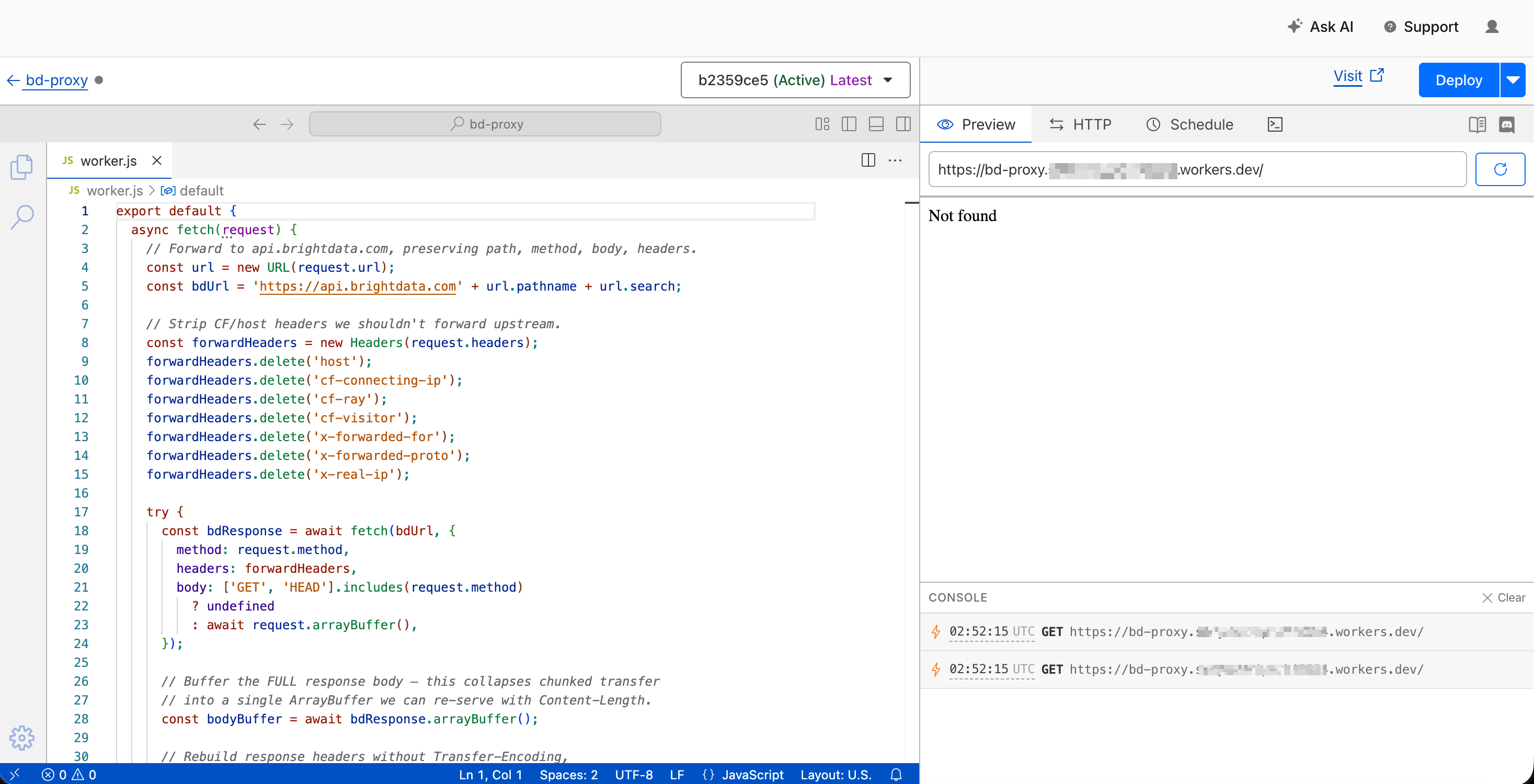
关键行:await bdResponse.arrayBuffer() 将整个分块流读入内存,而响应对象上的显式 Content-Length 头意味着 Apex 可以干净解析 body。
验证 Worker 是否工作
在本地终端中,针对 Worker 运行一个快速测试。将 URL 替换为你的,并使用你自己的 Bright Data API token:
curl -i https://<your-worker>.workers.dev/request \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <your-bd-token>" \
-d '{"zone":"mcp_unlocker","url":"https://www.salesforce.com","format":"raw","data_format":"markdown"}' \
| head -20响应头应包含 200 状态和 content-length: <some-number> 头。它们不应包含 transfer-encoding: chunked。这就是代理正确工作的证明。常见失败包括:401 表示你的 Bright Data token 错了(重新检查 Authorization: Bearer ... 头);Worker 返回 502 表示你的 Worker 代码未部署(重新检查 Deploy 步骤);仍出现 transfer-encoding: chunked 头表示你在 Worker 源码中漏掉了 arrayBuffer() + Content-Length 两行。
在企业级推广中,这个 Worker 会被生产级集成层替代:运行在 Anypoint 上的 MuleSoft、Heroku 微服务,或带认证、可观测性和限流的自定义 API 网关。Worker 是该角色的最小替代品,但同样的模式也适用于这些生产环境。
第 3 部分:配置 Salesforce 凭据
Salesforce 的 External Credential 模式将第三方凭据拆分为三个对象:External Credential(保存 token)、Named Credential(保存端点),以及 Permission Set(授予用户访问 External Credential principal 的权限)。
创建 External Credential
点击齿轮图标(任意 Salesforce 页面右上角)→ Setup。在 Setup 中,使用左侧栏顶部的 Quick Find 搜索框搜索 Named Credentials。点击结果。在加载的页面中,点击 External Credentials 选项卡,然后点击 New。
填写以下字段:
- Label:
Bright Data Cred - Name:
Bright_Data_Cred(自动填充) - Authentication Protocol:
Custom
点击 Save。
在详情页中,找到 Principals 部分并点击 New:
- Parameter Name:
BrightDataPrincipal - Sequence Number:
1 - Identity Type:
Named Principal
在 principal 下的 Authentication Parameters 部分,添加:
- Name:
api_key - Value: 粘贴你的 Bright Data API token
点击 Save。
回到 External Credential 页面,找到 Custom Headers 部分并点击 New:
- Name:
Authorization - Value:
Bearer {!$Credential.Bright_Data_Cred.api_key} - Sequence Number:
1
⚠️ 合并字段必须与您设置的名称匹配。 公式中的
Bright_Data_Cred必须匹配 External Credential 的 API Name。api_key必须匹配你在 Principal 中设置的 Authentication Parameter 名称。如果你重命名了任意一个,请编辑公式以匹配。
这一步至关重要:勾选此自定义 header 上的 Allow Formulas in HTTP Header 复选框。查找方法:保存 header 行后,点击该行打开其详情视图。复选框在该详情页上,而不在父级 External Credential 页面上。如果你跳过它,Salesforce 会将字面字符串 Bearer {!$Credential...} 发送给 Bright Data,从而返回 401,并且错误消息不会告诉你漏掉了哪个复选框。点击 Save。
⚠️ 你将在下一节遇到同名复选框。 “Allow Formulas in HTTP Header” 出现在 两个 位置。复选框 A 是你刚刚勾选的(在 Custom Header 的详情页上)。复选框 B 在 Named Credential 的 Callout Options 中。两者都必须勾选。如果只勾选其中一个,合并字段会以字面文本发送,Bright Data 返回 401。
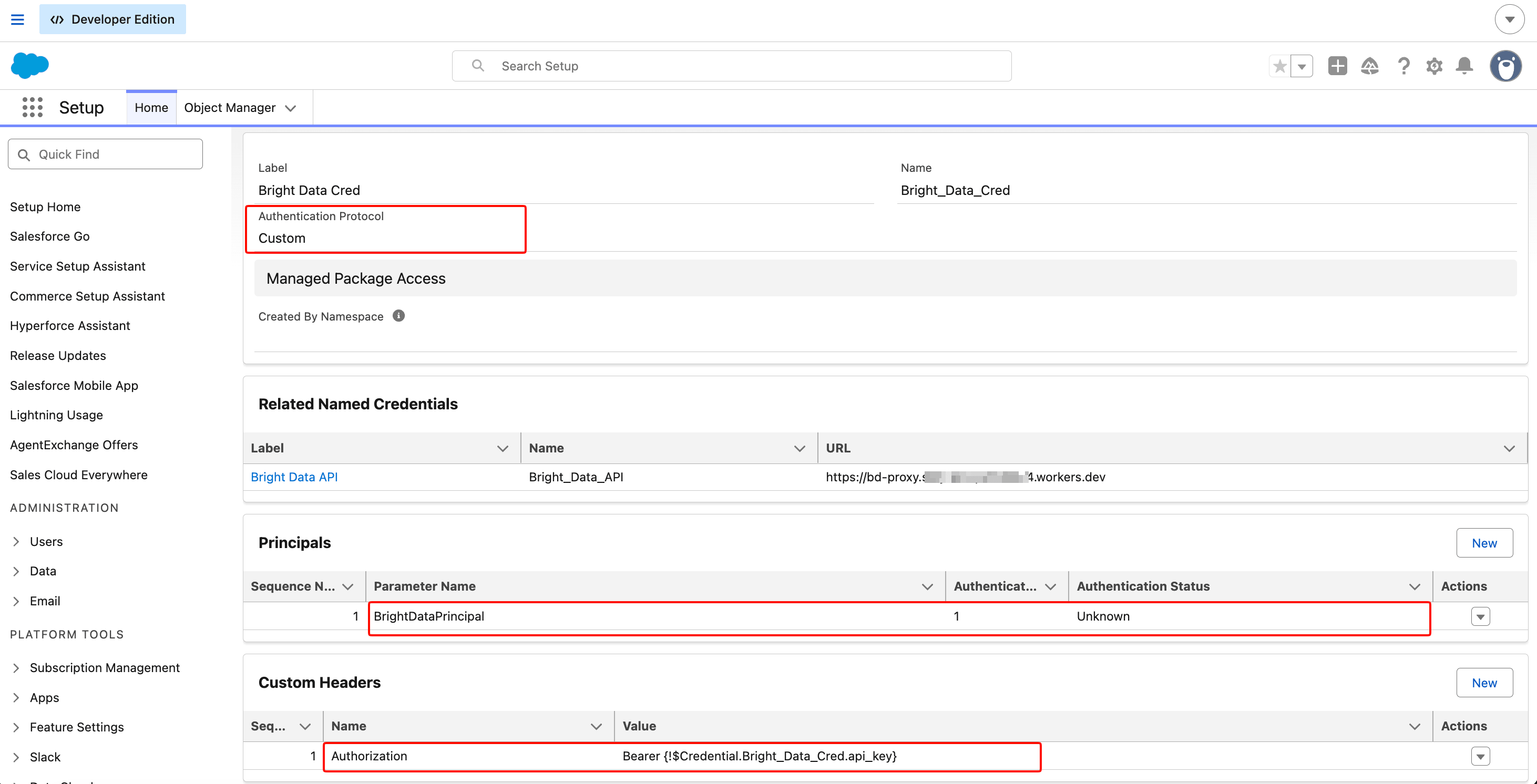
Custom Header 的合并字段值是在请求时解析 API token 的部分。Allow Formulas in HTTP Header 复选框(在此深度不可见;它在 header 的详情页上)必须勾选,否则合并字段会以字面文本发送。
创建 Named Credential
在同一个 Named Credentials 部分,切回 Named Credentials 选项卡并点击 New:
- Label:
Bright Data API - Name:
Bright_Data_API - URL: 粘贴你的 Cloudflare Worker URL(例如
https://bd-proxy.<your-subdomain>.workers.dev) - Enabled for Callouts: 勾选
- External Credential: 选择
Bright Data Cred
在 Callout Options 下,设置如下:
- Generate Authorization Header: 不勾选(你通过 Custom Header 自行提供)
- Allow Formulas in HTTP Header: 勾选(使合并字段解析)
- Allow Formulas in HTTP Body: 勾选(使动态 JSON body 生效)
点击 Save。
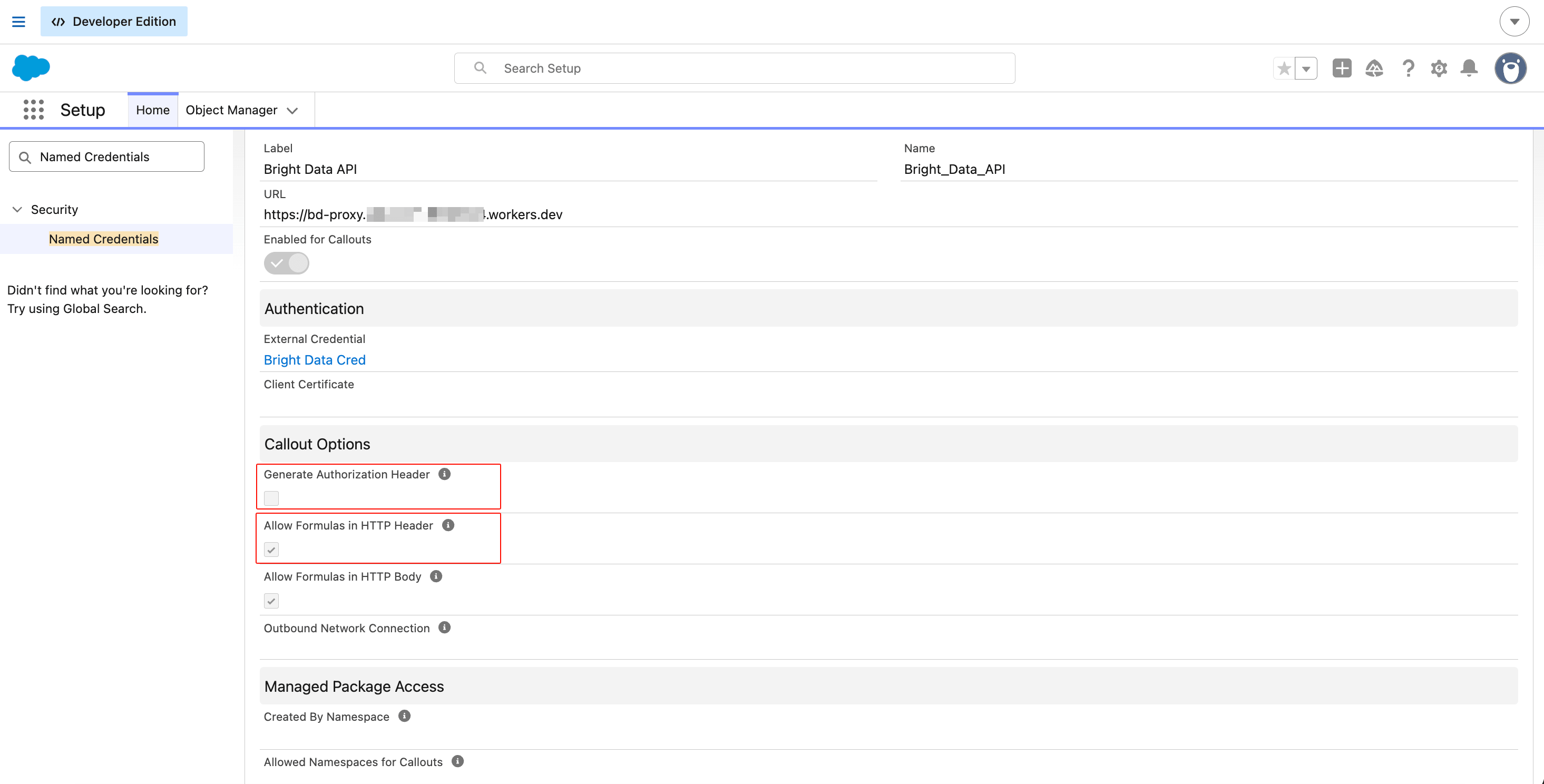
URL 指向 Cloudflare Worker,而不是直接指向 api.brightdata.com。这就是 chunked-transfer 修复的工作方式。这三个复选框状态彼此独立;任何一个设置错误都会在无警告的情况下导致 callout 失败。
创建 Permission Set
Salesforce 会阻止即使是 System Administrators 也使用 External Credential 的 principal,直到 Permission Set 显式授予访问权限。如果你跳过此步骤,Apex 会返回 INVALID_OPERATION 错误且没有有用诊断信息。
在 Setup 中搜索 Permission Sets 并点击 New:
- Label:
Bright Data Access - API Name:
Bright_Data_Access - License: 留空
点击 Save。
在详情页中,滚动到 External Credential Principal Access 并点击 Edit。将 Bright_Data_Cred - BrightDataPrincipal 从 Available 列表移动到 Enabled 列表。点击 Save。
回到详情页,点击顶部的 Manage Assignments,然后 Add Assignments,选择你自己的用户并完成分配。
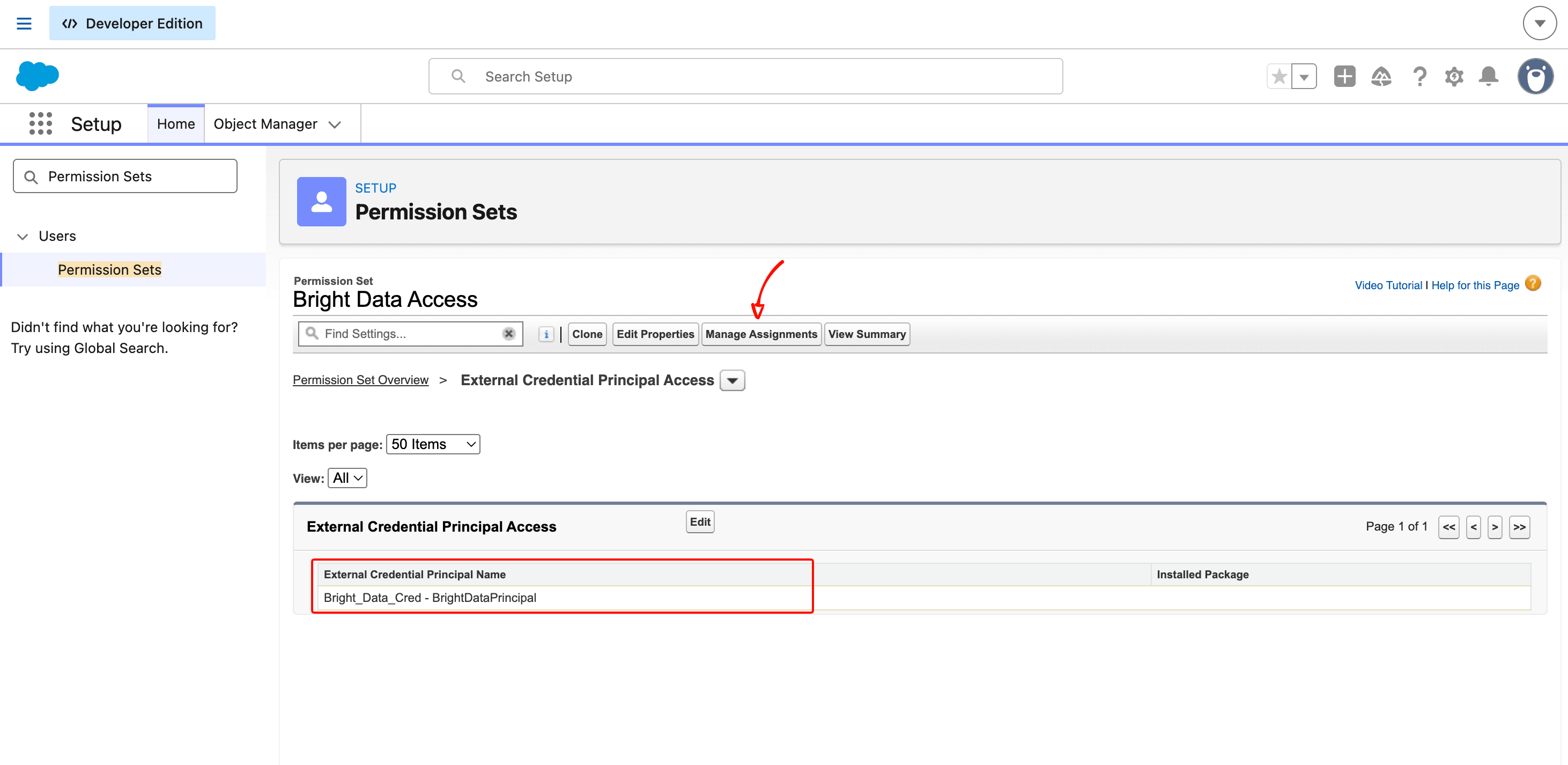
Permission Set 是门控机制,用于限定哪些用户可以运行调用 Bright Data 的代码。在企业 org 中,这通常会通过 Permission Set Group 分配给服务用户或特定配置文件,而不是分配给单个管理员。
在继续之前验证接线
点击齿轮图标(右上角)→ Developer Console。它会在新的浏览器窗口中打开。该窗口聚焦后,通过 Debug → Open Execute Anonymous Window 打开 Anonymous Apex。粘贴下面的代码,然后点击 Execute:
HttpRequest req = new HttpRequest();
req.setEndpoint('callout:Bright_Data_API/request');
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody('{"zone":"mcp_unlocker","url":"https://geo.brdtest.com/welcome.txt?product=unlocker&method=api","format":"raw"}');
req.setTimeout(60000);
HttpResponse res = new Http().send(req);
System.debug('STATUS: ' + res.getStatusCode());
System.debug('BODY: ' + res.getBody().left(500));点击 Execute 后,Developer Console 底部面板会出现一条新的日志行。双击该行打开日志查看器,然后在底部勾选 Debug Only(或在过滤框中输入 USER_DEBUG)。你应看到两行打印你的 STATUS 和 BODY 值。查找 STATUS: 200 以及包含 Bright Data welcome 文本的 body。如果你看到 401,请重新检查 Custom Header 的 “Allow Formulas in HTTP Header” 复选框(header 详情页上的那个,以及 Named Credential 的 Callout Options 中的那个)。如果你看到 INVALID_OPERATION,请重新检查 Permission Set 分配。
第 4 部分:编写 Apex 层
Apex 每个类只注册一个 @InvocableMethod 作为可被 Agentforce 调用的动作。这就是为什么集成使用三个类而不是一个:一个共享服务用于 HTTP 管道,以及每个 Agent Action 一个类。
按原样粘贴每个代码块。你可能想更改的主要一行是 BrightDataService.cls 中的 private static final String UNLOCKER_ZONE = 'mcp_unlocker';,如果你的 Bright Data 区域名称不同(第 1 部分)。
在 Setup 中,在 Quick Find 搜索 Apex Classes 并点击结果。点击 New。编辑器会打开一个占位类,例如 public class YourClassName {}。点击代码区域(大文本框,而不是右侧 Version Settings 面板),选中所有占位文本,按 Delete,然后粘贴下面的源码。类名取自源码,因此你无需填写其他字段。点击 Save。
按以下顺序创建三个类,因为 BrightDataNewsAction 和 BrightDataFetchAction 都引用 BrightDataService。必须先保存 service:
BrightDataService.cls:共享 HTTP 与解析层
该类包含 HTTP 管道以及两个辅助方法(searchNews 和 fetchUrlAsMarkdown),两个 Agent Action 都会调用。这里没有 @InvocableMethod;该注解在下面的动作包装类中。类如下:
public with sharing class BrightDataService {
private static final String BD_ENDPOINT = 'callout:Bright_Data_API/request';
private static final String UNLOCKER_ZONE = 'mcp_unlocker';
private static final Integer CALLOUT_TIMEOUT = 60000;
private static final Integer MAX_RESPONSE_CHARS = 50000;
/**
* Fetches the Google News results page for `companyName` (past month) as
* clean Markdown via Bright Data Web Unlocker. The LLM downstream is
* responsible for extracting individual articles, sources, and dates.
*/
public static String searchNews(String companyName) {
String googleNewsUrl =
'https://www.google.com/search?q='
+ EncodingUtil.urlEncode(companyName, 'UTF-8')
+ '&tbm=nws&tbs=qdr:m';
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => googleNewsUrl,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Bright Data returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (String.isBlank(content)) {
return 'No content returned for "' + companyName
+ '". The page may have been empty or blocked.';
}
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return 'Google News results for "' + companyName
+ '" (past month). Extract article titles, sources, '
+ 'publication dates, and URLs from the Markdown below:\n\n'
+ content;
}
/**
* Fetches any URL via Bright Data Web Unlocker and returns the page as
* clean Markdown.
*/
public static String fetchUrlAsMarkdown(String url) {
Map<String, Object> body = new Map<String, Object>{
'zone' => UNLOCKER_ZONE,
'url' => url,
'format' => 'raw',
'data_format' => 'markdown'
};
HttpResponse res = sendRequest(JSON.serialize(body));
if (res.getStatusCode() != 200) {
return 'Web Unlocker returned status '
+ res.getStatusCode() + ': ' + res.getBody().left(300);
}
String content = res.getBody();
if (content.length() > MAX_RESPONSE_CHARS) {
content = content.left(MAX_RESPONSE_CHARS)
+ '\n\n[Content truncated at ' + MAX_RESPONSE_CHARS + ' characters]';
}
return content;
}
private static HttpResponse sendRequest(String jsonBody) {
HttpRequest req = new HttpRequest();
req.setEndpoint(BD_ENDPOINT);
req.setMethod('POST');
req.setHeader('Content-Type', 'application/json');
req.setBody(jsonBody);
req.setTimeout(CALLOUT_TIMEOUT);
return new Http().send(req);
}
}该类按设计没有 @InvocableMethod。它是两个动作类使用的共享 HTTP 层。
BrightDataNewsAction.cls:新闻搜索动作
当代理决定搜索新闻时,Agentforce 会调用这个轻量的可调用包装器。它验证输入,将 HTTP 工作委托给 BrightDataService.searchNews(),并以 Agentforce 期望的 Response 形状返回结果。类如下:
public with sharing class BrightDataNewsAction {
public class Request {
@InvocableVariable(
required=true
label='Company Name'
description='The name of the company to search news about. E.g. "Salesforce" or "Acme Corp".')
public String companyName;
}
public class Response {
@InvocableVariable(
label='News Results'
description='Formatted summary of recent news with titles, sources, dates, URLs, and snippets.')
public String newsResults;
}
@InvocableMethod(
label='Search Recent Company News (Bright Data)'
description='Searches Google News via Bright Data for recent (past month) articles about a specific named company. Use this whenever the user asks about recent news, announcements, press releases, funding rounds, acquisitions, leadership changes, or current events for a named company.'
callout=true)
public static List<Response> searchCompanyNews(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
resp.newsResults = String.isBlank(req.companyName)
? 'Error: A company name is required.'
: BrightDataService.searchNews(req.companyName);
} catch (Exception e) {
resp.newsResults = 'Error fetching news for ' + req.companyName + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}Agentforce 的推理引擎读取 @InvocableMethod 注解上的 description 字段,以决定何时调用此动作。
BrightDataFetchAction.cls:URL 抓取动作
第二个可调用包装器与新闻动作遵循相同模式,但它抓取销售代表提到的任意 URL。验证块也会在 callout 之前拒绝格式错误的输入。类如下:
public with sharing class BrightDataFetchAction {
public class Request {
@InvocableVariable(
required=true
label='URL to Fetch'
description='The full URL of a web page to retrieve. Must start with http:// or https://.')
public String url;
}
public class Response {
@InvocableVariable(
label='Page Content'
description='Clean Markdown representation of the page content.')
public String pageContent;
}
@InvocableMethod(
label='Fetch Web Page as Markdown (Bright Data)'
description='Retrieves the content of any web URL via Bright Data Web Unlocker and returns it as clean Markdown. Use this when you need to read a specific URL: a company homepage, blog post, press release, or any link the user mentions.'
callout=true)
public static List<Response> fetchUrlAsMarkdown(List<Request> requests) {
List<Response> responses = new List<Response>();
for (Request req : requests) {
Response resp = new Response();
try {
if (String.isBlank(req.url)
|| (!req.url.startsWithIgnoreCase('http://')
&& !req.url.startsWithIgnoreCase('https://'))) {
resp.pageContent = 'Error: A valid URL starting with http:// or https:// is required.';
} else {
resp.pageContent = BrightDataService.fetchUrlAsMarkdown(req.url);
}
} catch (Exception e) {
resp.pageContent = 'Error fetching ' + req.url + ': ' + e.getMessage();
}
responses.add(resp);
}
return responses;
}
}保存全部三个类后,Setup → Apex Classes 应显示它们为 Active。
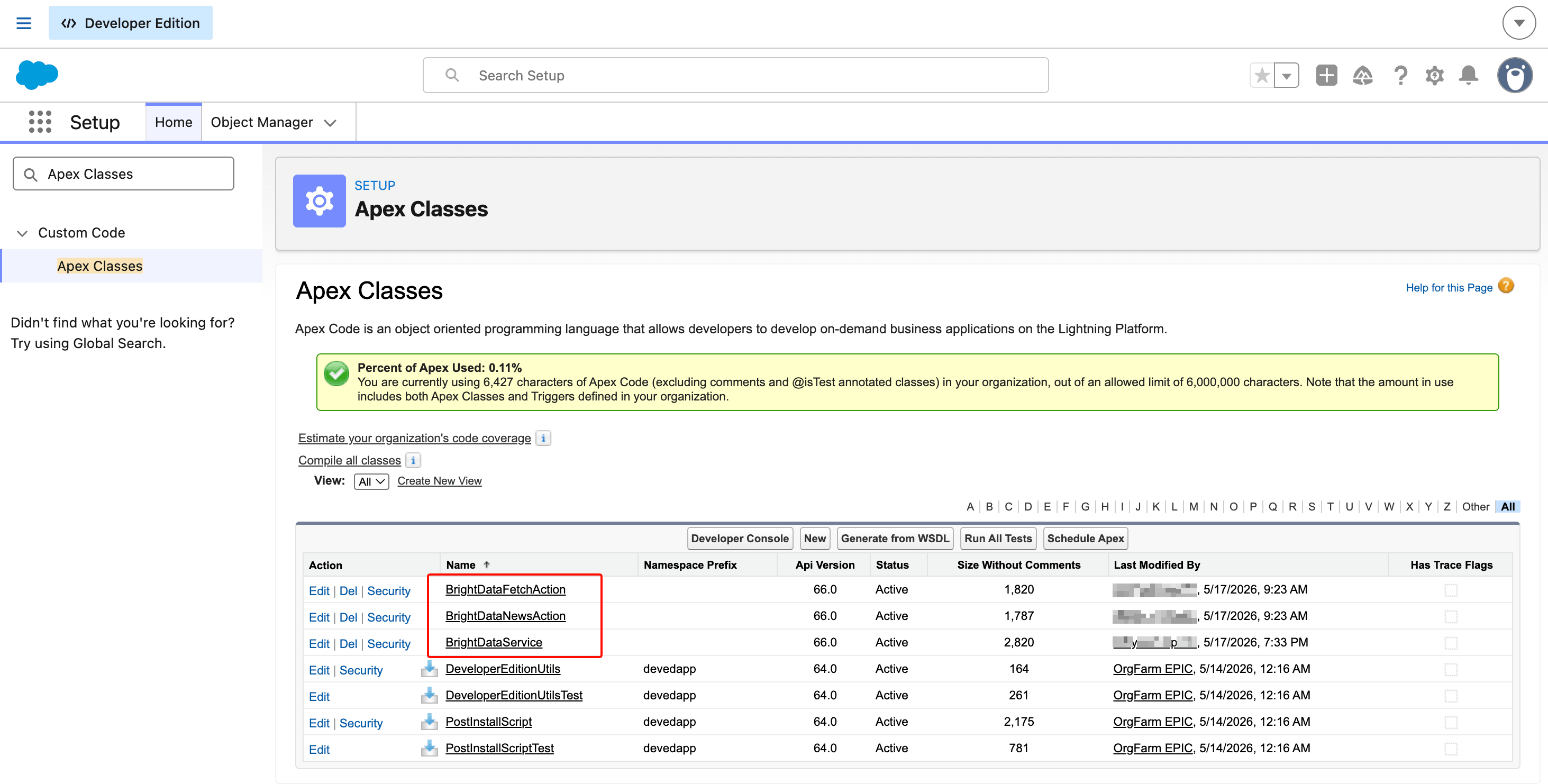
三类合计 Apex 占用约 6.4 KB。共享 service 加上每个 Agent Action 一个动作类,是在需要多个 invocable 时的标准 Salesforce 模式。
测试动作
在将动作接入 Agentforce 之前,确认它们端到端工作。在 Anonymous Apex 中:
BrightDataNewsAction.Request r = new BrightDataNewsAction.Request();
r.companyName = 'Salesforce';
List<BrightDataNewsAction.Response> out =
BrightDataNewsAction.searchCompanyNews(new List<BrightDataNewsAction.Request>{ r });
System.debug('LENGTH: ' + out[0].newsResults.length());
System.debug('PREVIEW: ' + out[0].newsResults.left(800));预期 LENGTH 在 5,000 到 10,000 之间,预览以 service 类的前缀开头,然后是 Google News 的 markdown。如果你看到 LENGTH: 0 或错误字符串,请返回第 3 部分的验证步骤。
第 5 部分:将动作注册为 Agentforce Assets
Apex 类默认对 Agentforce 不可见。每个 @InvocableMethod 必须注册为一个 Agent Action(新标签:Agentforce Asset),代理才能调用它。
在 Setup 中搜索 Agent Actions(或 Agentforce Assets,取决于你的 org 使用哪个标签)并点击 New Agent Action。你将做两次,每个动作类一次。
对于新闻动作,填写:
- Reference Action Type:
Apex - Reference Action Category:
Invocable Methods - Reference Action:
BrightDataNewsAction.searchCompanyNews
在下一屏填写以下字段:
- Agent Action Label: 保持自动填充的
Search Recent Company News (Bright Data) - Agent Action Description: 保持自动填充的描述(来自
@InvocableMethod注解) - Show loading text for this action: 勾选
- Loading Text:
Searching recent news…
Salesforce 会自动检测输入(companyName,必填,String)和输出(newsResults,String)。保留自动检测的映射。点击 Finish。
对抓取动作重复上述步骤:
- Reference Action:
BrightDataFetchAction.fetchUrlAsMarkdown - Loading Text:
Fetching web page… - 输入为
url(必填,String)。输出为pageContent(String)。
两者保存后,Agent Actions 列表会显示两者状态均为 Active。
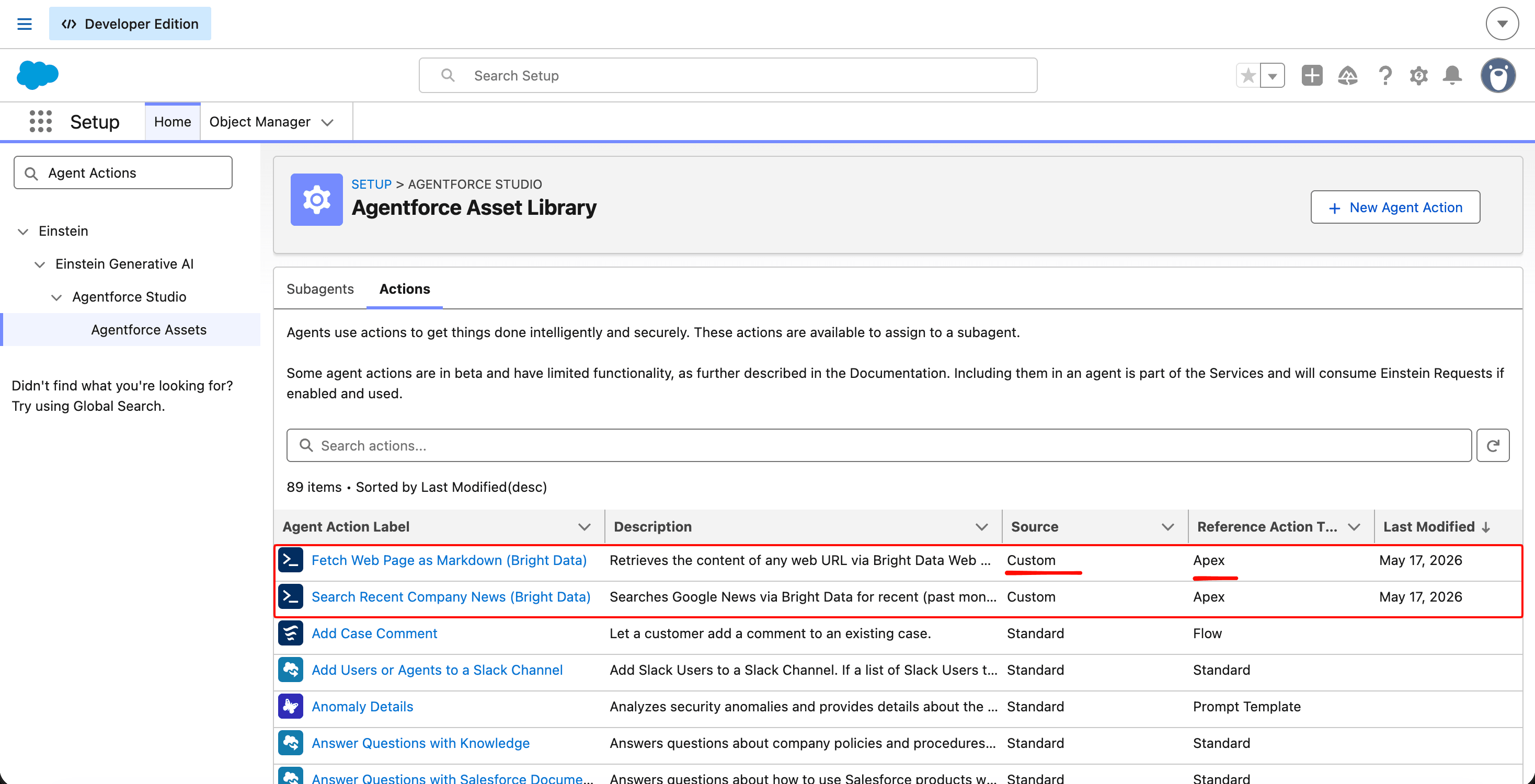
自定义动作与 Employee 模板自带的标准动作出现在同一个 Asset Library 中。Agentforce 的推理引擎对两者一视同仁;source 列是元数据,而不是行为开关。
两层拆分(Apex 类 vs. Agent Action)是刻意为之。这是一个治理钩子,让 Salesforce 管理员无需修改 Apex 就能授予或撤销代理能力。例如在受监管的 org 中,Apex 在各版本发布中保持不变;被审计和版本控制的是 Agent Action 注册。
第 6 部分:构建代理
注册好两个动作后,你就可以将它们接入一个可工作的 Agentforce 代理。打开 App Launcher(左上角九点网格)并搜索 Agentforce Studio。在 Agentforce Studio 中,点击 New Agent。
Builder UI
Salesforce Agentforce Builder 有两条起始路径:顶部的自然语言描述框,或下方的一组预构建模板。使用模板路径,以便下面步骤与你的屏幕一致。点击 Agentforce Employee Agent 卡片上的 Select。如果你的 org 没有显示该卡片,选择最接近的 “Employee” 或 “General” 模板;四个起始子代理(Agent Router、General FAQ、Off Topic、Ambiguous Question)可能名称略有不同,但下面的工作(添加自定义子代理并将两个动作接入其中)适用于任何模板。
填写以下字段:
- Agent Label:
Account Briefing Agent - Description: Researches an account by pulling recent news and public web content into Salesforce. Used by sales reps before customer calls.
- Company: 任意字符串;该字段是代理元数据,不影响路由
如果模板向导提供安装预构建 topics(Salesforce 对子代理的旧标签),接受默认值。Employee 模板会安装四个本构建不使用的子代理(Agent Router、General FAQ、Off Topic、Ambiguous Question);它们不会与将要添加的子代理冲突。
点击 Finish。Agent Builder 画布会打开。
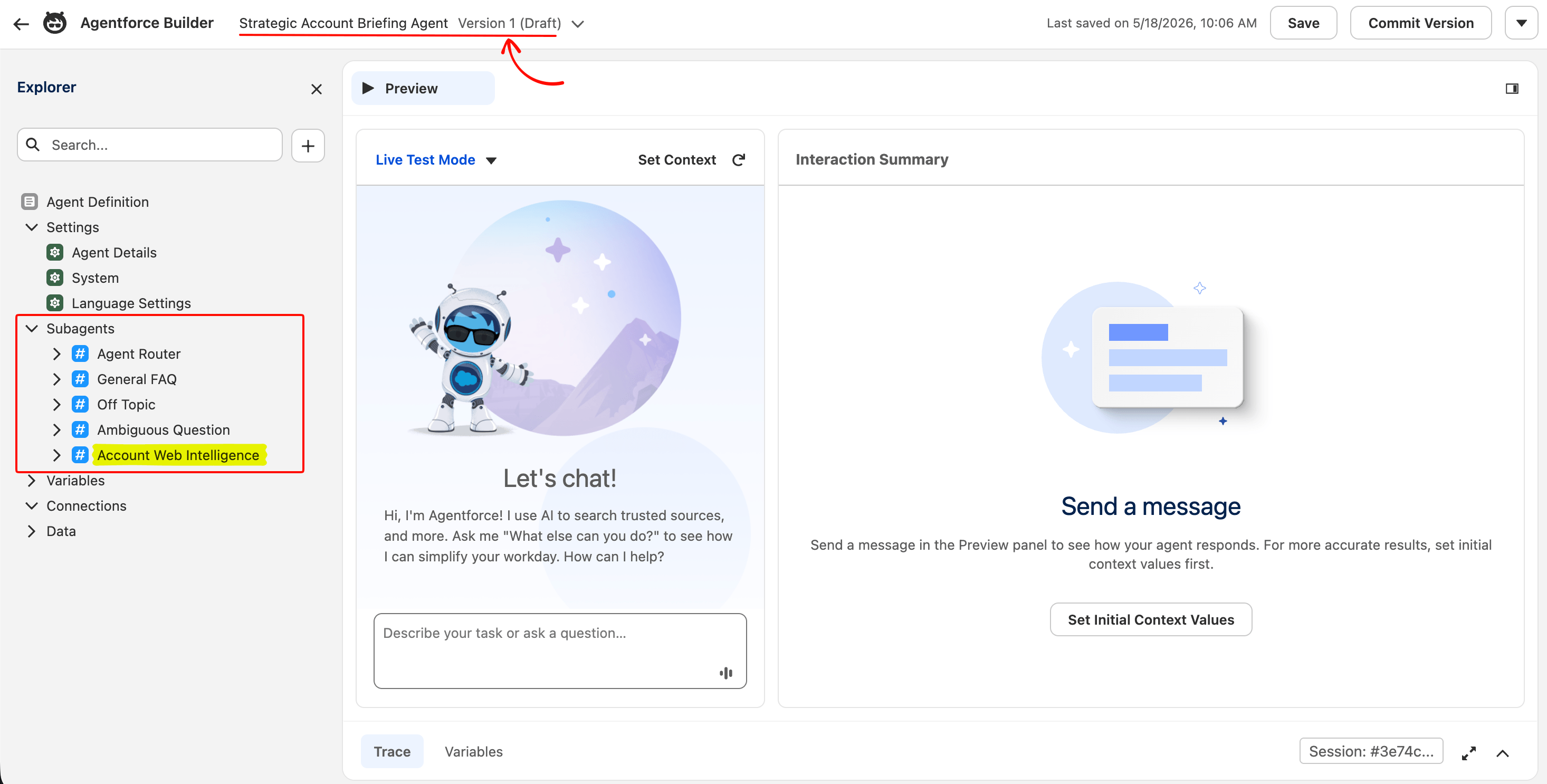
Agent Router 是顶层 LLM 分类器,用于选择哪个子代理处理每个传入提示。四个模板子代理处理对话边缘情况(问候、跑题、含糊查询)。Account Web Intelligence 子代理(下一步添加)是调用两个 Bright Data 动作的那个。
添加 Account Web Intelligence 子代理
在左侧 Explorer 面板中,点击 Search 字段旁的 + 按钮并选择 New Subagent。Salesforce 会提示两个字段:
- Subagent Name:
Account Web Intelligence - Description: 当用户询问关于某公司的外部网页信息、近期新闻、新闻稿、公告、融资、领导层变动、收购或招聘,或想读取并总结某个特定 URL 的内容时使用此子代理。处理所有关于已命名公司或网站的外部网页调研请求。
点击 Create and Open。
子代理详情视图会打开,包含 Instructions 和 Actions Available For Reasoning 部分。你刚写的描述是 Agent Router 用来决定何时路由到此子代理的分类文本。
编写指令
Instructions 块是 LLM 的运行时提示。它告诉模型在此子代理内要遵循哪些规则。将以下内容粘贴到 Instructions 字段中:
1. When the user mentions a company name and asks about recent news, events, press, funding, hiring, or any current information, call the "Search Recent Company News" action with the company name extracted from the user's message.
2. When the user provides a specific URL or asks you to read a webpage, call the "Fetch Web Page as Markdown" action with that URL.
3. If the user asks something that needs both (e.g. "What's new at Acme and read their homepage"), call BOTH actions and combine the results.
4. ALWAYS include source URLs in your final response so the user can verify each fact.
5. NEVER fabricate news items, dates, sources, or page content. If Bright Data returns nothing or an error, tell the user honestly. Do not pad with made-up information.
6. When summarizing news, group by theme (funding, product, leadership, partnerships) and present 3-5 highest-signal items rather than dumping all 10.
7. When summarizing a fetched page, give a 2-3 sentence overview followed by the most relevant facts. Do not paste the raw Markdown.规则 5 是最重要的。在测试中,当 Bright Data 返回错误时,它能产生优雅的失败模式,而不是捏造内容。
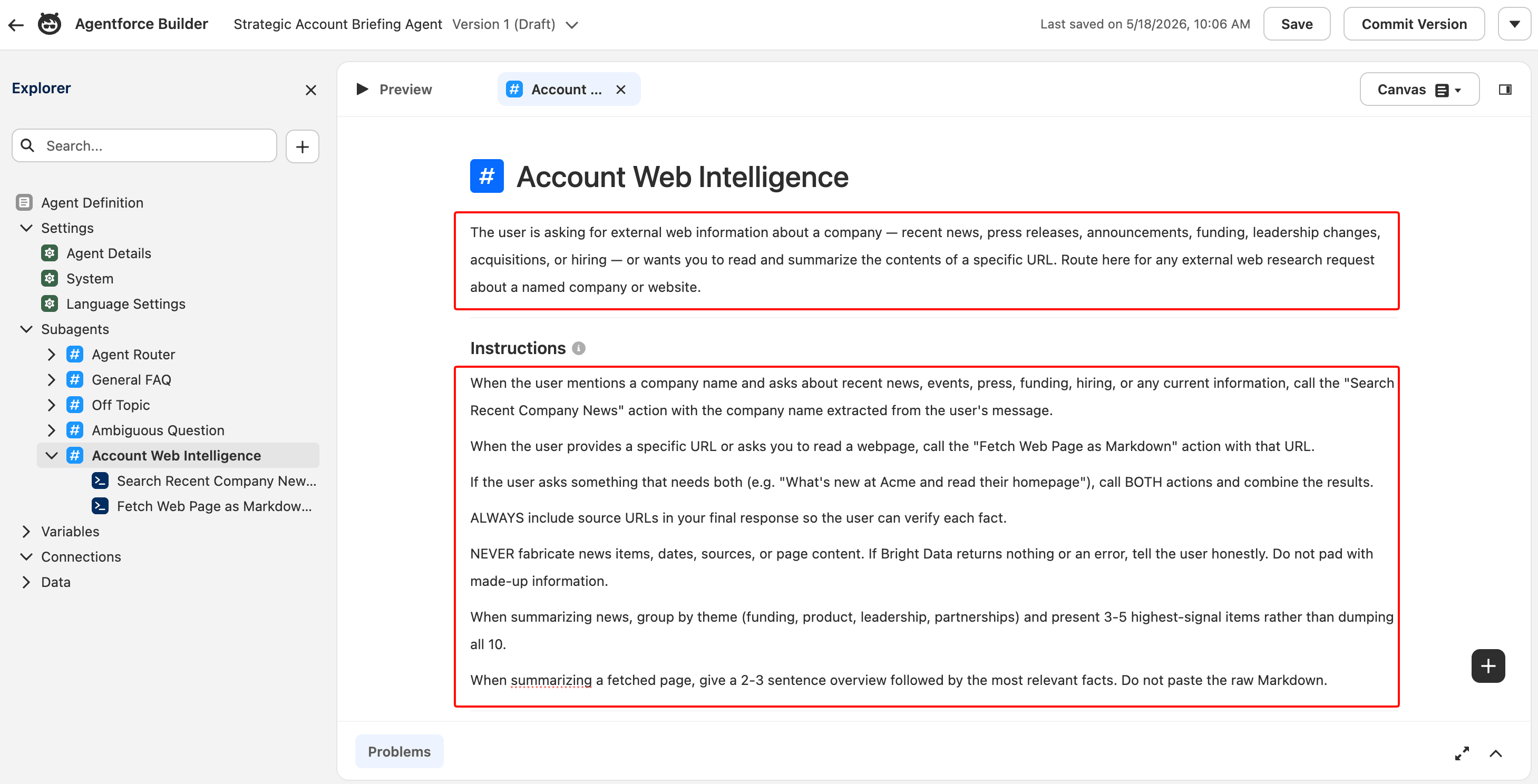
描述(顶部)驱动路由决策。Instructions(下方)驱动子代理内行为。两者都是纯自然语言提示;LLM 在运行时读取它们。
绑定两个 Agent Actions
在 Actions Available For Reasoning 部分,点击 Select action → Add from Asset Library。选择 Search Recent Company News (Bright Data)。然后重复:Select action → Add from Asset Library → Fetch Web Page as Markdown (Bright Data)。
两者绑定后,每个动作会显示两行绑定:With input(动作的必填参数)和 Set output(结果写入的位置)。
通过 Script 模式修复输入绑定
聊天驱动代理需要与 Canvas 默认提供的不同输入绑定。下面的修复使用 Script 模式。
如果你的 Canvas UI 在动作输入行上显示 “Collect data from user” 复选框,请先尝试它;下面的 Script 模式变通方案适用于没有该选项的 org。
对于 Search Recent Company News,输入行显示 With input: Company Name = Select variable。Select variable 下拉默认是静态 Salesforce 变量列表(currentRecordId、ContactId、EndUserId 等)。这些都不包含销售代表在聊天中输入的公司名。这是 Canvas 模式下聊天驱动代理的静默失败模式。
修复在底层 Agent Script 中,而不在 Canvas 下拉中。使用右上角的下拉将画布模式从 Canvas 切换到 Script。
你将在脚本中做四个小的文本编辑。每个都是单词级查找替换。你不需要粘贴任何块或推断 YAML 缩进;只需找到字面字符串并更改它们。
使用编辑器内查找(Script 模式画布内的 Cmd+F / Ctrl+F;这是编辑器的查找,不是浏览器的)。以下是四处编辑:
编辑 1。 找到字面字符串 with companyName = @variables.currentRecordId(出现一次)。将 @variables.currentRecordId 替换为三个字面点 ...。该行应为:
with companyName = ...三个点是真实的 Agent Script 语法,表示“LLM 在运行时提供该值”。它看起来像占位省略号,但并不是。
编辑 2。 找到 with url = @variables.currentRecordId(也出现一次)。同样将 @variables.currentRecordId 替换为 ...。该行应为:
with url = ...编辑 3。 找到字面字符串 "companyName"(带引号)。其正下方一行是 is_user_input: False。将 False 改为 True(大写 T)。
编辑 4。 找到 "url"(带引号)。其正下方一行是 is_user_input: False。将 False 改为 True。
像这样编辑单个词会保持缩进不变,因此不太可能出现 YAML 解析错误。如果仍发生错误,按 Cmd+Z / Ctrl+Z 撤销并再试一次。完成四处编辑后点击 Save。切回 Canvas 模式。两个输入行现在显示 With input: Company Name = Agent Populated 和 With input: URL to Fetch = Agent Populated。
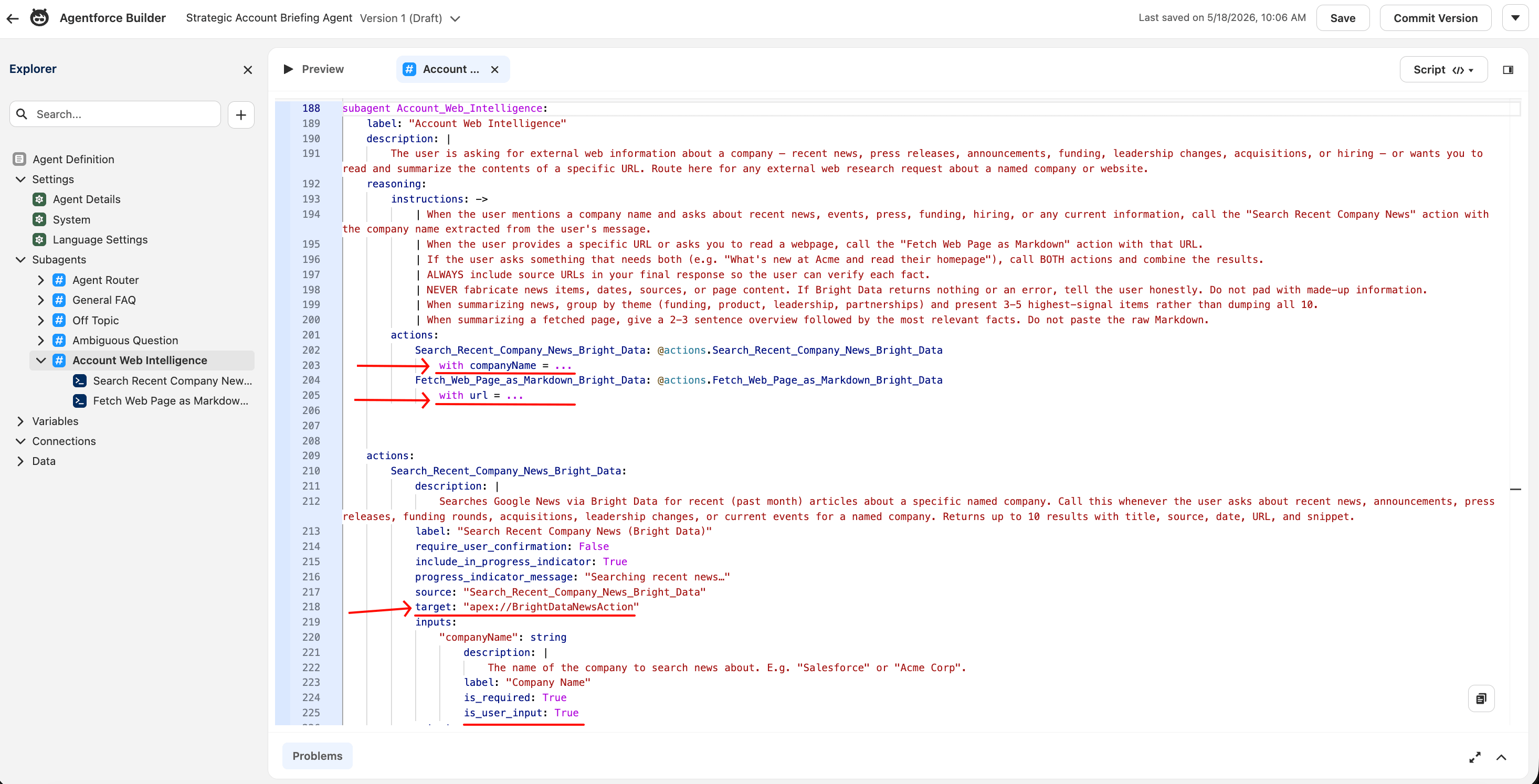
Script 模式是可直接编辑 Agentforce 底层语言的地方。= ... 运行时绑定和 is_user_input: True 标志在 Canvas 下拉中不暴露;你必须编辑 YAML 来设置它们。设置后,Canvas 会将绑定显示为 “Agent Populated”。
子代理画布现在应显示两个动作都带有 Agent Populated 绑定。保存代理(右上角 Save 按钮;不是用于生产发布的 Commit Version)。
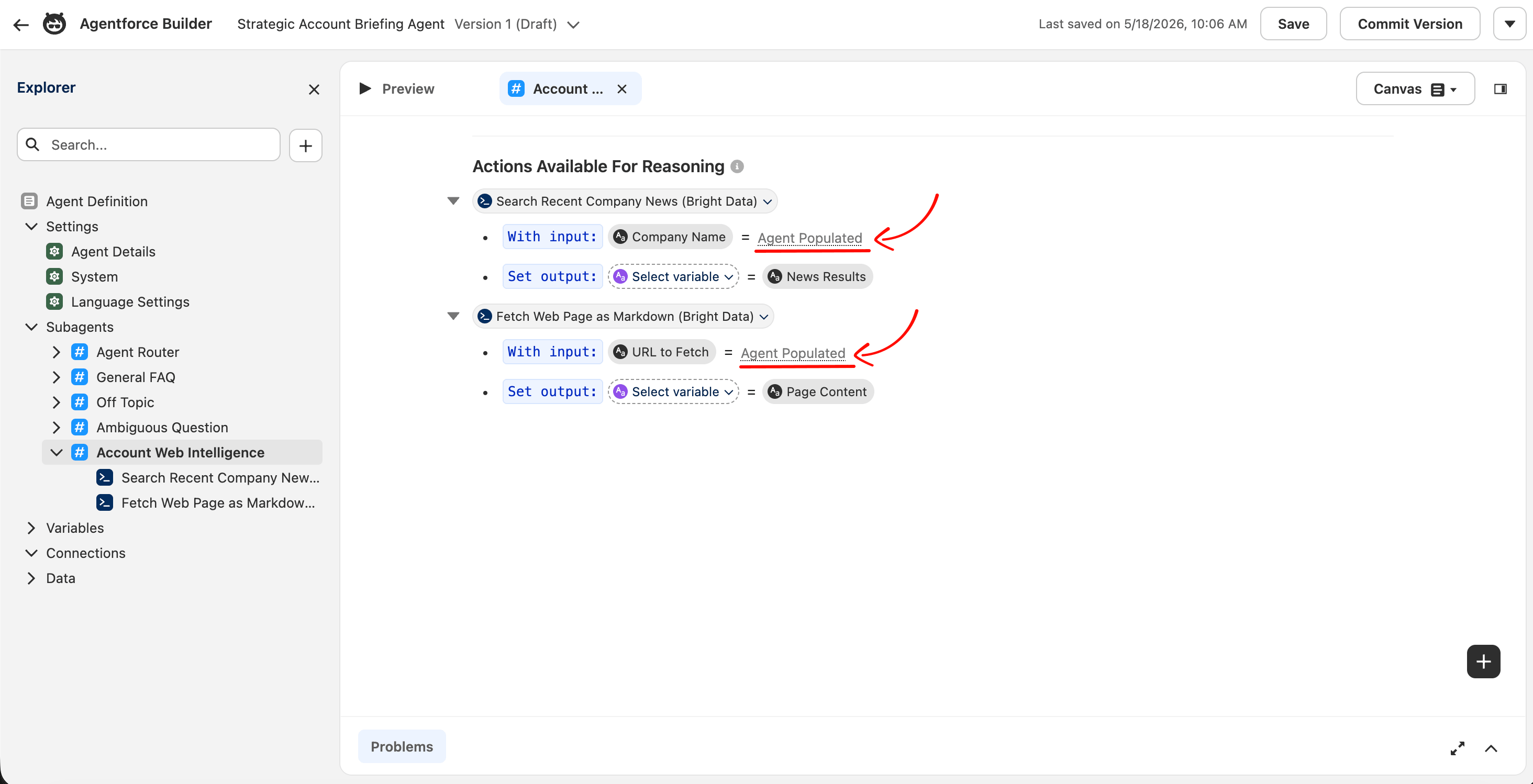
“Agent Populated” 是 Salesforce 用于表示输入在运行时由 LLM 推理填充的标签。这是聊天驱动代理集成所需的状态。
第 7 部分:测试代理
在 Agent Builder 中,点击 Preview 选项卡。聊天界面会打开,并显示一个黄色横幅,其中包含 Reset Simulator 按钮。如果横幅出现,请点击它。重置很重要,因为模拟器的对话记忆是按会话保存的,在测试之间重置是获得独立 trace 的最简单方式。下面四个测试验证路由、单动作调用、并行调用以及诚实失败模式。
如果 Preview 选项卡是灰色的,请在画布顶部查找 Activate 开关并打开。这里的激活只会为 Preview/Simulator 启用代理;终端用户在你通过 Setup → Agentforce Studio → Connections 分配之前无法访问,这超出本构建范围。
测试 1:仅新闻搜索
为验证新闻动作端到端运行,输入:
What's new at Salesforce in the past month?代理应路由到 Account Web Intelligence,显示 “Searching recent news…” 加载状态,然后返回按主题组织的新闻摘要,并在正文中引用来源名称。打开画布底部的 Trace 选项卡查看完整推理链。预览右侧的 Interaction Summary 面板以紧凑形式显示同一链路:Router 选择了哪个子代理、调用了哪些动作,以及代理如何推理。
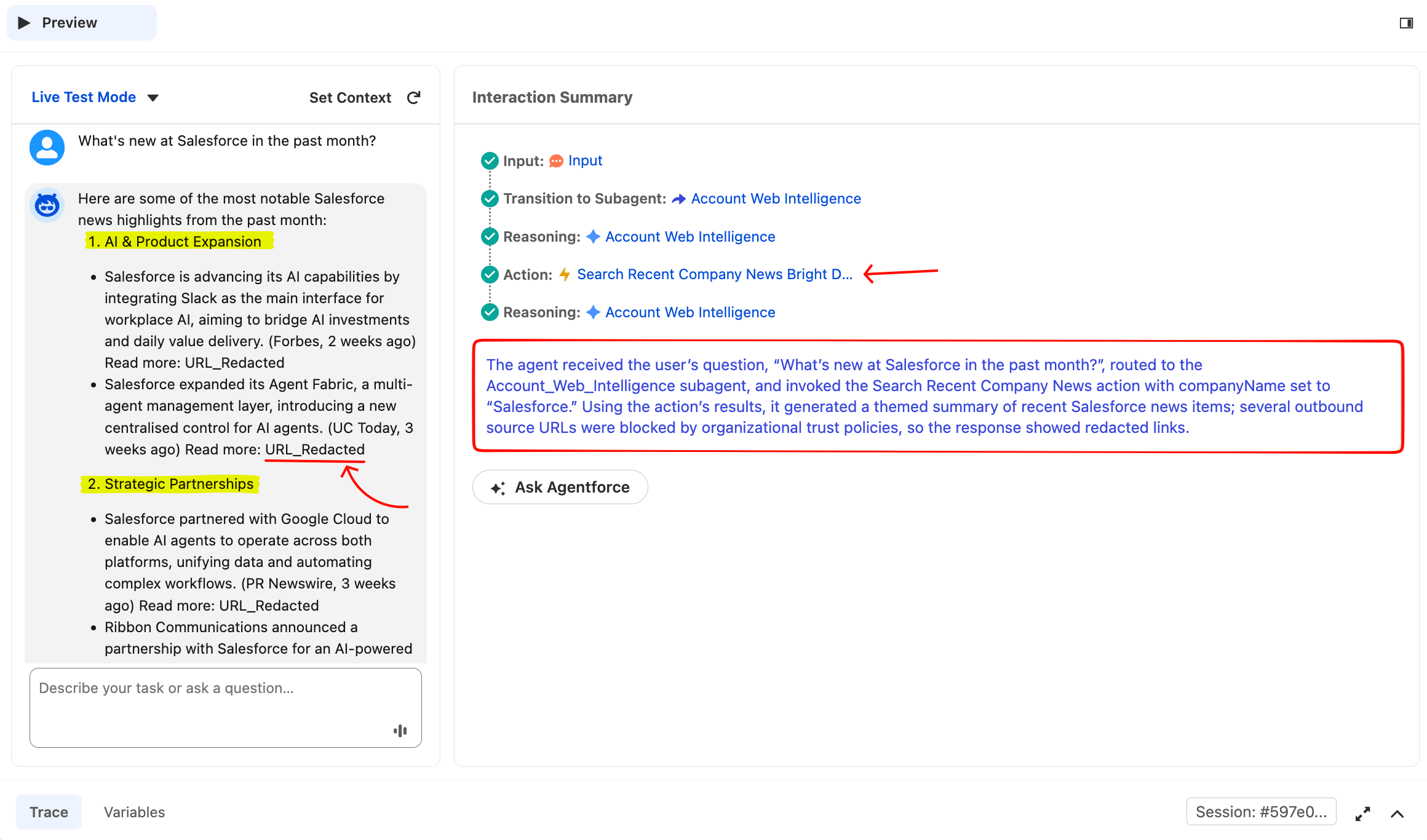
这是一次干净的单动作运行。Router 路由正确,代理从自然语言提示中提取了 companyName="Salesforce",调用了动作,并综合生成主题摘要。URL_Redacted 占位符是 Salesforce 的 URL 信任策略在起作用(在下方“企业治理”部分解释)。
路由由 LLM 驱动,因此在极少数情况下,Account Web Intelligence 子代理的描述可能会输给模板中的相似子代理(例如 General FAQ)。如果你的第一次测试路由到了错误的子代理,请在描述中添加更具体的关键词(“company news”、“press release”、“recent funding”、“fetch URL”),保存,点击 Reset Simulator,然后重试。Router 会在每个新会话中重新分类。
测试 2:仅 URL 抓取
为验证直接 URL 提示会路由到抓取动作,点击 Reset Simulator 并输入:
Read https://www.snowflake.com and tell me what they do代理应调用 Fetch 动作,而不是新闻动作。不同提示会路由到不同工具。
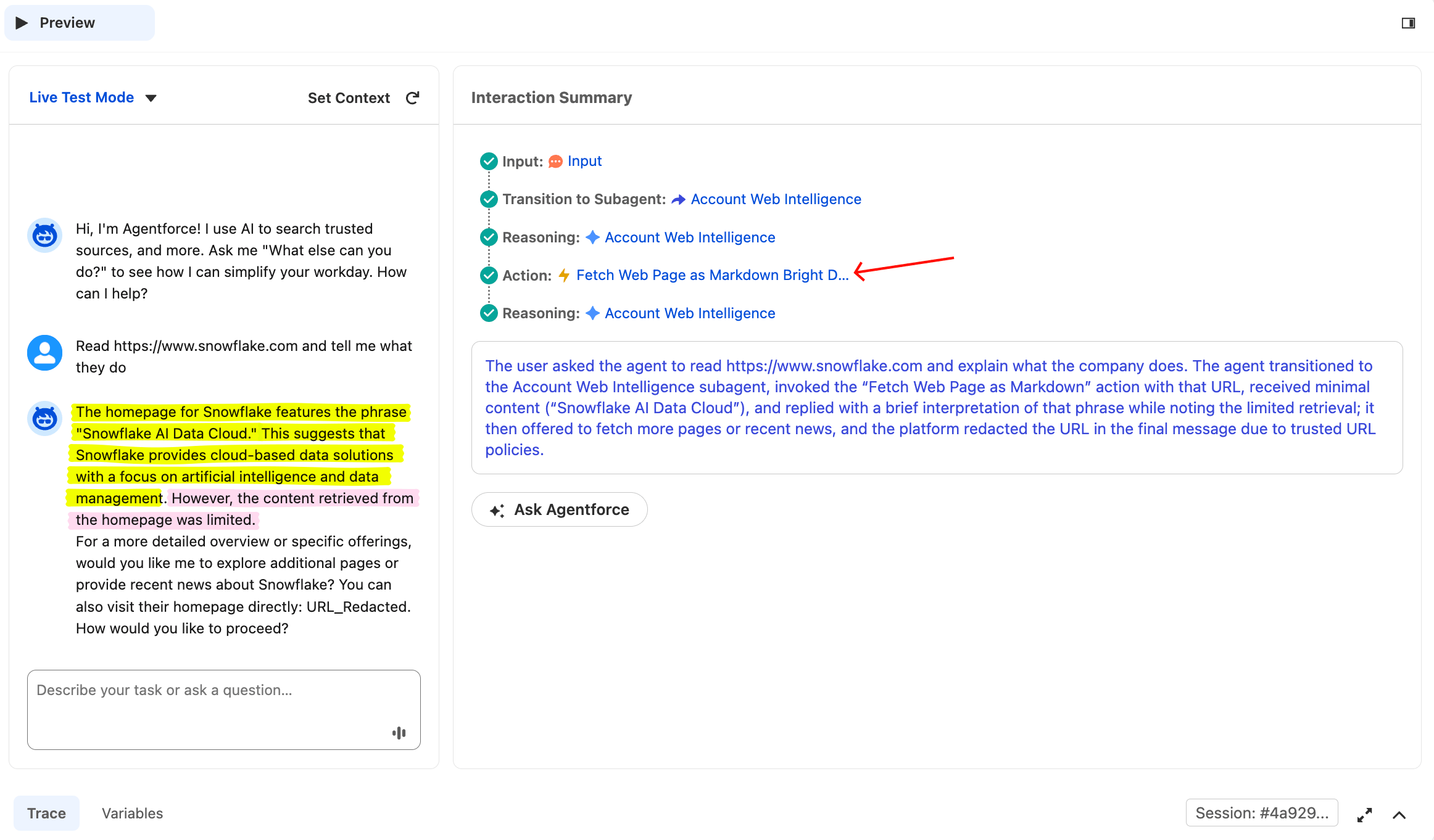
这是同一个代理,但不同提示路由到不同工具。Agent Router 将提示分类为 URL 抓取(而不是新闻搜索),并只调用抓取动作。这证明代理在推理,而不是运行固定流水线。
测试 3:并行调用两个动作
当两个动作都被调用时,测试 3 即成功,无论两者是否都返回 200。如果两者都成功,你会看到干净的合并简报。如果其中一个失败(如下方截图所示),代理仍应使用成功的那个生成简报。这展示了规则 5。点击 Reset Simulator 后输入:
Give me a briefing on Anthropic, recent news plus what their homepage says about their product代理应调用两个动作,然后综合生成合并简报。Trace 会在同一推理链中显示两条独立的 Action 行。
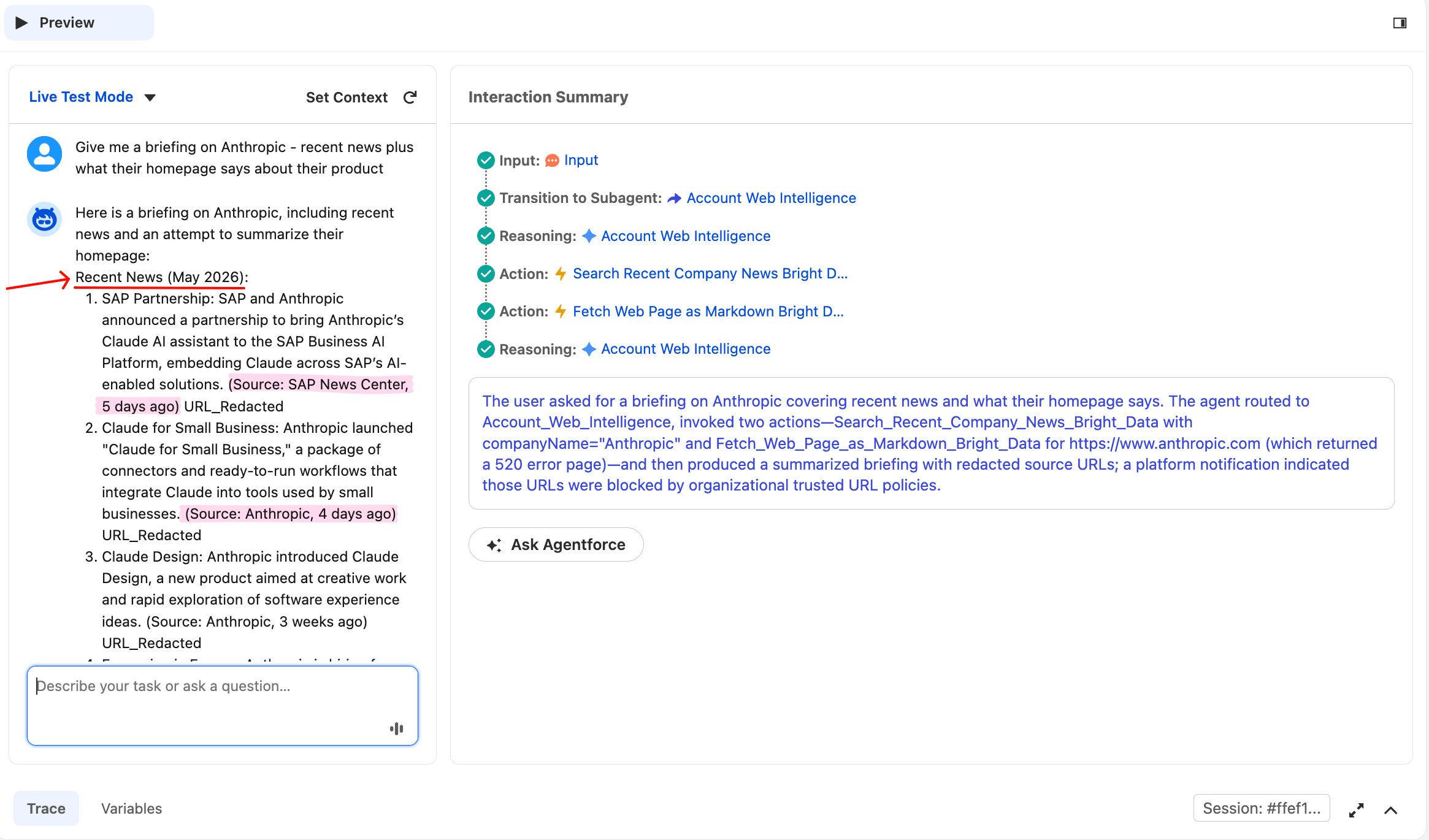
代理从单个用户提示中调用了两个动作。Anthropic 新闻部分来自 Bright Data 的 网络解锁器 调用 Google News。
同一响应在下方继续,包含主页部分,其中这次运行遇到了一个值得详细查看的部分失败:
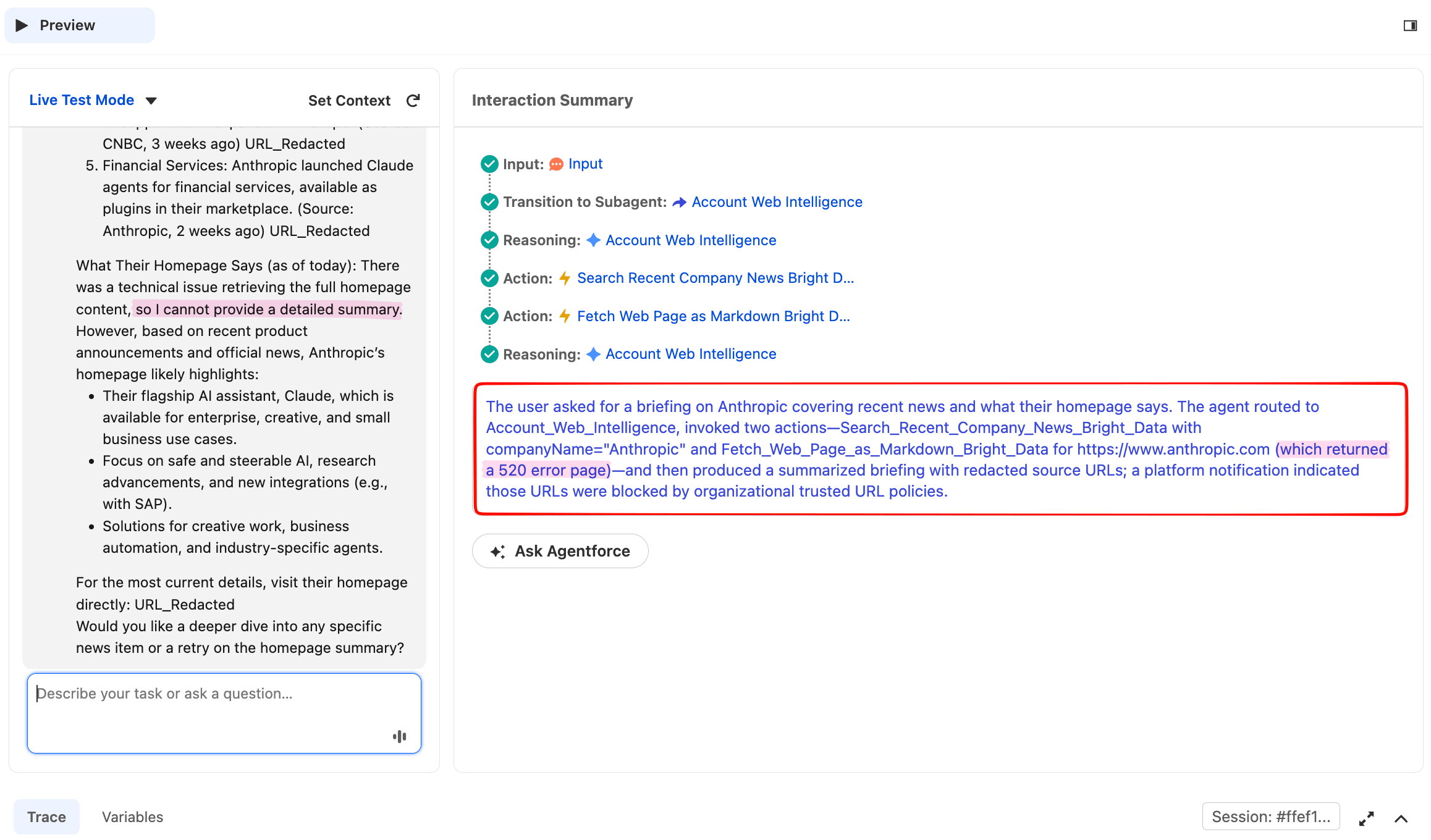
主页抓取返回了 520,这是 网络解锁器 在某次尝试无法检索目标站点时使用的状态。代理没有捏造主页内容;它承认失败,使用刚刚获取的新闻数据来描述公司做什么,并提出重试。
在部分工具失败下的优雅降级,是子代理指令规则 5 旨在产生的生产行为。这很重要,因为公共网络是对抗性的:目标站点会改变防护,CDN 偶尔会失败,任何调用实时 URL 的代理都必须容忍偶发的非 200。当代理说 “主页抓取失败,这是我从新闻中得到的内容” 时,这就是生产级行为。
测试 4:不幻觉检查
为验证在没有真实答案时代理会诚实失败,点击 Reset Simulator 并输入:
What's the latest news about Triposat Industries?这是一个虚构公司名,因此没有真实新闻可找。Bright Data 可能返回 520、空结果或无关片段,这些都不是实际答案。无论返回什么,代理都不应捏造新闻。此处成功标准是行为,而非状态码:可接受的响应包括“未找到近期新闻”、“我无法检索结果”或任何诚实披露。此处失败将表现为代理捏造一篇不存在的 Forbes 文章或融资轮次。
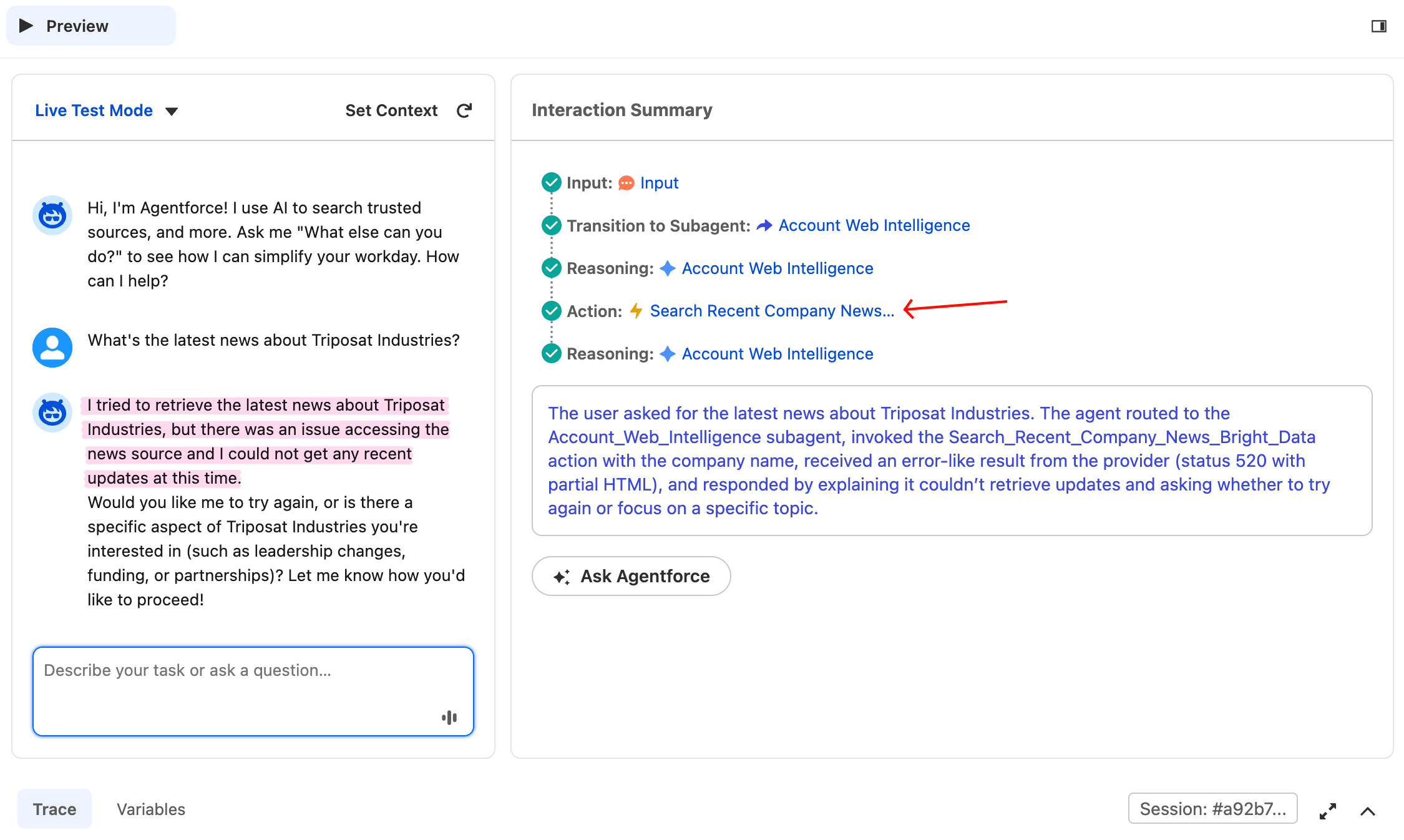
代理没有捏造任何新闻条目,也没有编造来源。它调用了动作,收到较差结果,并进行了披露。子代理指令的规则 5 按预期工作。
Agentforce 中的 URL 脱敏
上面截图中的每个演示响应都将来源 URL 显示为 URL_Redacted。这是 Salesforce Agentforce 内置的 URL 信任策略。
默认情况下,Agentforce 会在代理响应到达终端用户之前剥离任意外部 URL。不过在内部,当工具返回时代理仍会读取真实 URL 并用于推理;只是除非域名在显式允许列表中,否则无法在聊天输出中包含它们。
它是可配置的:在 Setup 中搜索 Trusted URLs 并添加你希望允许的域名。对于销售简报代理,一个现实的允许列表包括 Google 域名、公司自有营销域名,以及一组精选新闻来源(Forbes、Reuters、Bloomberg、TechCrunch)。
保持默认脱敏开启。它让演示更有说服力:代理按名称引用来源(Forbes、TechAfrica News、SAP News Center),而脱敏让 Salesforce 的治理层可见。带原始 URL 的演示与消费级聊天机器人无异;脱敏版本让治理层可见。
成本
Bright Data 仅对其按量付费与分级计划中的成功 网络解锁器 响应收费;非成功响应不计费。按标价计算,一个同时调用两个动作的简报成本在不到一美分的范围内;分级计划会进一步降低单次请求成本。
要估算你自己的支出,公式是:
requests/month = reps × briefings_per_rep_per_day × workdays × actions_per_briefing对于一个 100 人销售团队,在 22 个工作日里每人每天运行 5 次简报,每次简报 2 个动作,则每月为 22,000 次请求。将其乘以 Bright Data 当前的单次请求费率(来自定价页面)即可得到月成本。
在 Cloudflare 侧,Worker 在典型销售团队量级下仍在免费层范围内;在扩展到单个团队之外之前,请参考 Workers 定价。
在 Salesforce 侧,成本来自你 org 现有的 Einstein 生成式 AI 额度池,这是任何 Agentforce 动作使用的同一计量池。查看 Setup → Einstein Generative AI → Usage 以了解你 org 当前额度与使用情况。
下一步
上面的构建是账户智能层的最小单元。在投入生产之前,有三件事要做:
- 将 Cloudflare Worker 放到自定义域名之后(你自己 DNS 上的子域名),然后通过你组织的 API 网关路由。Worker 适合这个代理角色;自定义域名加网关才使其在运维上属于你。
- 将 Bright Data 区域锁定到你的出口 IP 范围。在 Bright Data 控制面板中,编辑 网络解锁器 区域并将 Cloudflare Worker 的出站 IP(Cloudflare 会发布这些)添加到区域允许列表。这可防止 API token 在你的集成之外被使用。
- 为
BrightDataService添加一个使用HttpCalloutMock的 Apex 测试类。三个测试方法(成功路径、空 body、非 200)覆盖现实失败模式并满足 Salesforce 75% 覆盖率要求。Salesforce HttpCalloutMock 文档展示了该模式。
当你对某个目标站点不再适合使用 网络解锁器 时,替换为 Bright Data 的预构建爬虫工具。相同的 Cloudflare Worker 代理也能处理这些;它们使用相同的 /request 端点,只是 zone 和 dataset_id 参数不同。例如,专用的 LinkedIn Company Profile、LinkedIn Jobs,以及 Crunchbase 爬虫工具 会返回结构化 JSON 而非 Markdown,这让代理可以跳过 LLM 提取步骤并直接写入 Salesforce 自定义字段。更广泛地说,Bright Data 的 Web 爬虫工具 APIs 覆盖了数百个站点的预构建抓取工具。
将上面的构建视为脚手架。凭据层、代理、子代理结构、动作接线:当你在同一个 /request 端点上替换为不同 Bright Data 产品时,基础保持不变。选择你的销售代表实际需要的账户智能类型;更改子代理指令中的提示。代理保持不变;它回答的问题在变化。
常见问题
为什么我的 Apex callout 返回空 body?
Apex 的 HTTP 客户端无法可靠解析没有 Content-Length 头的 chunked transfer encoding 的 HTTP/1.1 响应。Bright Data 和许多现代 API 会对超过几 KB 的响应进行分块。修复方法是通过一个缓冲代理路由调用,该代理以显式的 Content-Length 重新提供响应。
这个构建可以使用 Bright Data 的 搜索引擎 API 吗?
可以。Cloudflare Worker 代理适用于托管在 api.brightdata.com 上的每个 Bright Data API 端点,包括 搜索引擎 API、Web 爬虫工具 API 和数据集触发器。将 Apex service 类中的 zone 值改为 SERP 区域名称,并将 URL 参数改为带 brd_json=1 的 Google 搜索 URL。
为什么使用 Apex InvocableMethods 而不是 MCP?
此构建通过 Apex InvocableMethods 暴露 Bright Data,因为每个动作都会成为可审计的 Agent Action,并带有自己的 Permission Set 治理。如果你的 org 启用了 Salesforce 托管的 MCP(Model Context Protocol)服务器(截至 Spring ’26 为 Beta),你也可以通过 Bright Data 自己的 MCP 服务器暴露 Bright Data。两种路径都可行。此处展示的 InvocableMethod 路径提供 Salesforce 原生治理钩子;MCP 路径更轻量,因为 Bright Data 为你运营服务器。
Agentforce 动作如何读取用户输入?
Agentforce 动作通过一个名为 is_user_input: True 的 YAML 标志读取用户输入,该标志在 Script 模式中为每个输入设置。Canvas UI 隐藏了该标志并将输入默认绑定到静态变量,因此你需要在 Agent Builder 中切换到 Script 模式并直接编辑 YAML 来更改该值。
为什么 Agentforce 隐藏来源 URL?
除非其域名被添加到 Setup → Trusted URLs,否则外部 URL 会从代理响应中剥离。这是内置治理层。即便如此,代理仍会在内部读取真实 URL 并用于推理。要让特定 URL 传递给用户,请将来源域名(Forbes、Reuters、你自己的网站)添加到允许列表。
Bright Data 520 错误是什么?
520 是 网络解锁器 在某次尝试无法检索目标站点时返回的状态,通常因为站点防护阻止了请求。子代理指令的规则 5 禁止在工具失败时捏造内容,因此代理会诚实报告失败并提出重试。
这种模式还覆盖哪些用例?
客户流失风险、竞争情报和续约风险简报都适用这种模式。因为两个 Apex 动作(搜索新闻、抓取 URL)覆盖了大多数账户智能类型。对于流失风险,使用新闻搜索跟踪裁员和领导层变动。对于竞争情报,抓取竞争对手的定价页面。变化的只有提示。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。