

在本文中,您将了解到
- 为什么说 vanilla Puppeteer 不足以应对用户行为分析?
- 什么是
木偶人化,以及它如何帮助克服这些限制。 - 如何使用它进行网络抓取的分步教程部分。
- 这种抓取网络数据的方法还面临其他挑战。
让我们深入了解一下!
用户行为分析:标准 “傀儡廻 “的不足之处
用户行为分析(UBA)是收集和分析用户如何与网页交互的数据的过程。在网页抓取中,其主要目标是发现异常或可疑行为,以识别机器人。
这种复杂的反机器人技术越来越受欢迎。原因在于,现代人工智能驱动的机器人正在不断进化,变得更像人类。因此,传统的僵尸检测方法可能不再对它们有效。
为了对抗 UBA,一些自动化库试图更真实地模仿人类行为。例如,它们使用启发式方法甚至机器学习来模拟鼠标的移动。然而,在大多数情况下,打字仍倾向于显得像机器人,这是一个问题。
现在,假设你的 Puppeteer 脚本需要填写一个表单。即使你使用type()函数在按键之间添加一个小延迟,这种交互也不会显得自然。
以Quotes to Scrape的登录表单为例:
import puppeteer from "puppeteer";
(async () => {
// set up a new browser instance in headful mode
const browser = await puppeteer.launch({
headless: false, // set to false so you can watch the interaction
defaultViewport: null,
});
const page = await browser.newPage();
// connect to the target page
await page.goto("https://quotes.toscrape.com/login");
// simulate typing with a delay of 200ms between each character
await page.type("input[name="username"]", "username", { delay: 200 });
await page.type("input[name="password"]", "password", { delay: 200 });
// ...
// close the browser and release its resources
await browser.close();
})();这就是互动的样子:
尽管上述方法比直接设置输入字段的值更逼真,但看起来仍然不够人性化。问题在于,输入看起来过于流畅、一致和无误。扪心自问,哪个真正的用户会以完全相同的时间间隔输入每个字符,而不会犹豫不决或出现错别字?
可以想象,先进的 UBA 系统很容易发现这类脚本。这就是puppeteer-humanize等工具发挥作用的地方!
什么是木偶人化?
puppeteer-humanize是一个 Node.js 库,能让 Puppeteer 自动化更像人,特别是在与文本输入字段交互时。它有助于绕过分析用户行为的常见僵尸检测方法,这些方法通常会标记不切实际或过于精确的操作。
为此,Puppeteer-humanize通过以下方式为常规的 Puppeteer 交互注入了逼真的不完美:
- 模拟印刷错误。
- 模仿使用退格键来纠正这些错误。
- 以随机延迟的方式重新输入已删除的文本。
- 在按键之间引入随机延迟,以改变打字速度。
这使得自动键入显得更加自然,不那么机械。不过,需要注意的是,该库只专注于人性化输入行为和表单输入。因此,它并不是一个全面的反机器人绕过解决方案。
此外,请记住它的最后一次提交是在 2021 年,而且它还不支持基于 GAN 的鼠标移动模拟等高级功能。因此,它的功能范围仍然仅限于键入行为。
如何使用 puppeteer-humanize 进行网络抓取
请按照以下步骤学习如何使用puppeteer-humanize 构建一个更像人类的抓取机器人。这样可以降低被 UBA 系统检测到的几率,尤其是当你的脚本需要在表单中输入数据时。
目标将是Quotes to Scrape 的登录表单:
此示例纯粹用于演示如何模拟真实的表单填写。在现实世界的抓取场景中,除非获得明确许可,否则应避免抓取登录表单背后的内容,因为这可能会引起法律问题。
现在,让我们看看如何使用puppeteer-humanize进行网络抓取!
步骤 #1:项目设置
如果尚未设置 Node.js 项目,可以使用npm init 在项目文件夹中创建一个:
npm init -y上述命令将在项目目录中生成package.json文件。在项目文件夹中,创建script.js文件,将JavaScript 搜索逻辑放在该文件中:
your-project-folder/
├── package.json
└── script.js然后,在您最喜欢的 JavaScript IDE 中打开该文件夹。Visual Studio Code可以完美运行。
在集成开发环境中,修改package.json文件,加入以下一行:
"type": "module"这会将您的项目设置为使用 ESM(ECMAScript 模块),现代 Node.js 项目通常推荐使用 ESM,而不是标准的 CommonJS 格式。
太好了!现在,您可以利用puppeteer-humanize在您的抓取脚本中模拟逼真的交互了。
步骤 #2:安装并开始使用 puppeteer-humanize
puppeteer-humanize最初是Puppeteer Extra 的一个插件,但现在已不再是了。因此,要使用它,只需安装即可:
@forad/puppeteer-humanize:模拟类人行为的库。puppeteer:核心浏览器自动化库
使用以下命令安装它们:
npm install @forad/puppeteer-humanize puppeteer接下来,打开script.js文件,像这样初始化一个基本的 Puppeteer 脚本:
import puppeteer from "puppeteer";
(async () => {
// set up a new browser instance in headful mode
const browser = await puppeteer.launch({
headless: false, // set to false so you can watch the interaction
defaultViewport: null,
});
const page = await browser.newPage();
// ...
// close the browser and release its resources
await browser.close();
})();太棒了现在你可以开始实施你的人形抓取交互了。
步骤 #3:连接到目标页面并选择输入元素
使用 Puppeteer 浏览目标页面:
await page.goto("https://quotes.toscrape.com/login");现在,在浏览器中打开同一页面,右键单击登录表单,然后选择 “检查 “来检查表单元素:
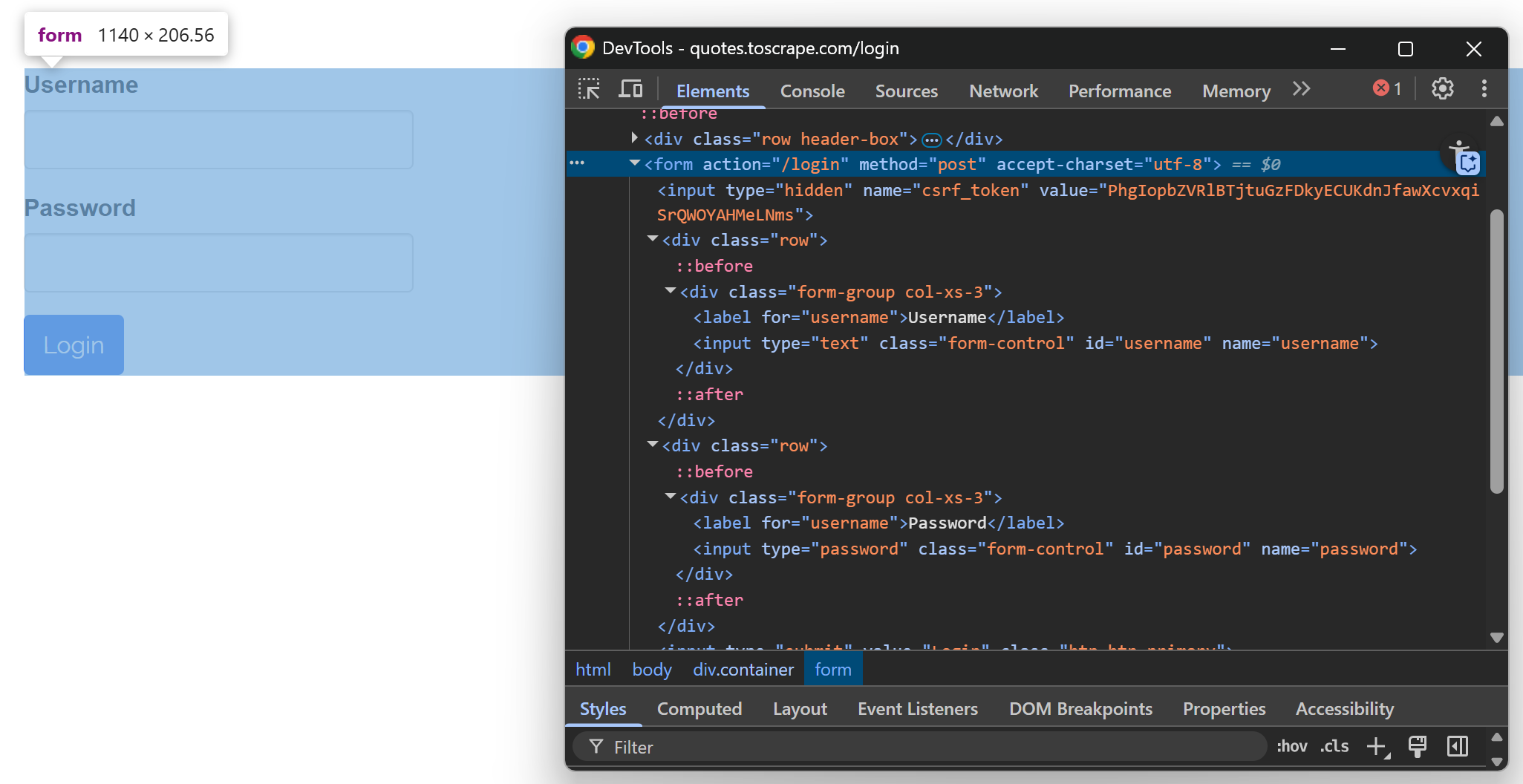
您会发现表格中包含
- 用户名输入字段,可使用
input[name="username"]进行选择 - 输入
[name="password"]可选择密码输入框
要在脚本中选择这些输入元素,请使用 Puppeteer 的$()方法:
const usernameInput = await page.$("input[name="username"]");
const passwordInput = await page.$("input[name="password"]");⚠️重要提示:puppeteer-humanize不支持定位器。这意味着您必须使用$()或$$() 直接检索元素句柄。
如果在页面上找到这两个输入,就准备像真实用户一样与它们进行交互:
if (usernameInput && passwordInput) {
// interaction...
}太棒了!是时候像真正的用户一样填写这些输入信息了。
步骤 #4:配置木偶人-人性化打字功能
首先,从puppeteer-humanize 中导入typeInto函数:
import { typeInto } from "@forad/puppeteer-humanize";然后,如下图所示,用它来配置类似人类的填表交互:
const typingConfig = {
mistakes: {
chance: 10, // 10% chance of introducing a typo that gets corrected
delay: {
min: 100, // minimum delay before correcting a mistake (in ms)
max: 500, // maximum delay before correcting a mistake (in ms)
},
},
delays: {
all: {
chance: 100, // 100% chance to add delay between each keystroke
min: 100, // minimum delay between characters (in ms)
max: 200, // maximum delay between characters (in ms)
},
},
};
// strings to fill into the input elements
const username = "username";
const password = "password";
// apply the human-like typing logic to both inputs
await typeInto(usernameInput, username, typingConfig);
await typeInto(passwordInput, password, typingConfig);上述键入配置:
- 偶尔介绍错别字,然后进行现实的更正–就像真正的用户会做的那样。
- 在每个按键之间添加随机延迟,模仿自然打字速度变化。
这种行为使您的自动化看起来更人性化,从而限制了被 UBA 技术检测到的机会。
太棒了!现在,你的 “傀儡廻 “脚本应该更像真人了。
步骤 #5:填写表格,准备网络抓取
现在您可以使用下面的代码填写表格:
const submitButton = page.locator("input[type="submit"]");
await submitButton.click();请记住,Quotes to Scrape 上的登录表单只是一个测试页面。具体而言,您可以使用用户名和密码凭据访问该页面。提交表单后,您将被重定向到一个包含您可能想要抓取的数据的页面:

这时,你可以使用常规的 Puppeteer API 来实现实际的抓取逻辑:
// wait for the page to load
await page.waitForNavigation();
// scraping logic...现在,本文的重点是木偶人化。因此,我们将不在这里介绍抓取部分。
如果你对从 Quotes to Scrape 抓取数据并导出为 CSV 感兴趣,请阅读我们关于使用 Puppeteer 进行网络抓取的完整教程。
第 6 步:将所有内容整合在一起
现在,您的script.js应包含
import puppeteer from "puppeteer";
import { typeInto } from "@forad/puppeteer-humanize";
(async () => {
// set up a new browser instance in headful mode
const browser = await puppeteer.launch({
headless: false, // set to false so you can watch the interaction
defaultViewport: null,
});
const page = await browser.newPage();
// visit the target page
await page.goto("https://quotes.toscrape.com/login");
// select the login form inputs
const usernameInput = await page.$("input[name="username"]");
const passwordInput = await page.$("input[name="password"]");
// if they are not both null, interact with them
if (usernameInput && passwordInput) {
// configure the typing behavior
const typingConfig = {
mistakes: {
chance: 10, // 10% chance of introducing a typo that gets corrected
delay: {
min: 100, // minimum delay before correcting a mistake (in ms)
max: 500, // maximum delay before correcting a mistake (in ms)
},
},
delays: {
all: {
chance: 100, // 100% chance to add delay between each keystroke
min: 100, // minimum delay between characters (in ms)
max: 200, // maximum delay between characters (in ms)
},
},
};
// test strings to fill into the input elements
const username = "username";
const password = "password";
// apply the human-like typing logic to both inputs
await typeInto(usernameInput, username, typingConfig);
await typeInto(passwordInput, password, typingConfig);
// submit the form
const submitButton = page.locator("input[type="submit"]");
await submitButton.click();
// wait for the page to load
await page.waitForNavigation();
// scraping logic...
}
// close the browser and release its resources
await browser.close();
})();用以下命令启动上述puppeteer-humanize搜索脚本:
node script.js结果将是
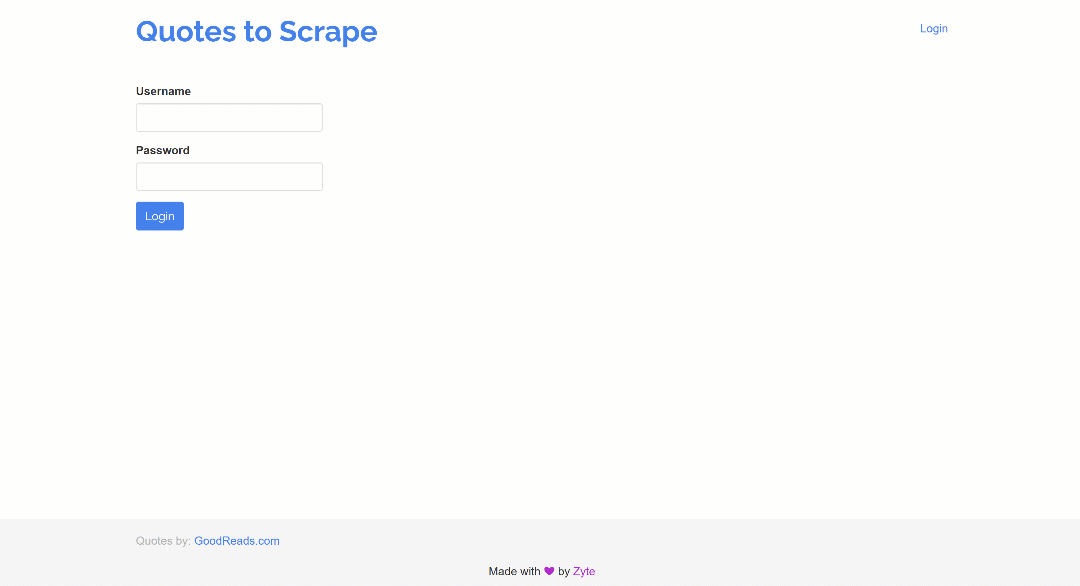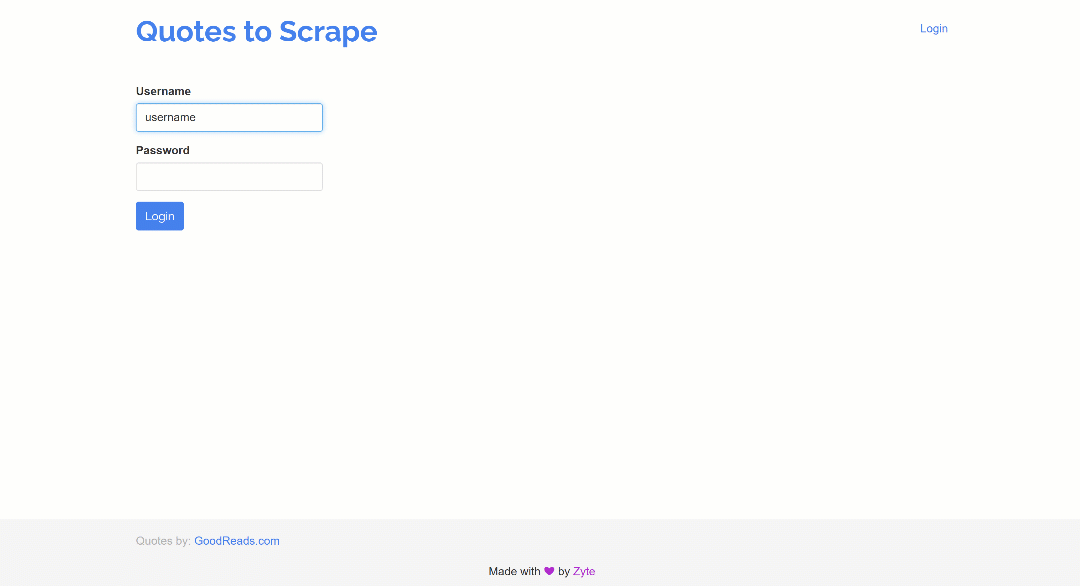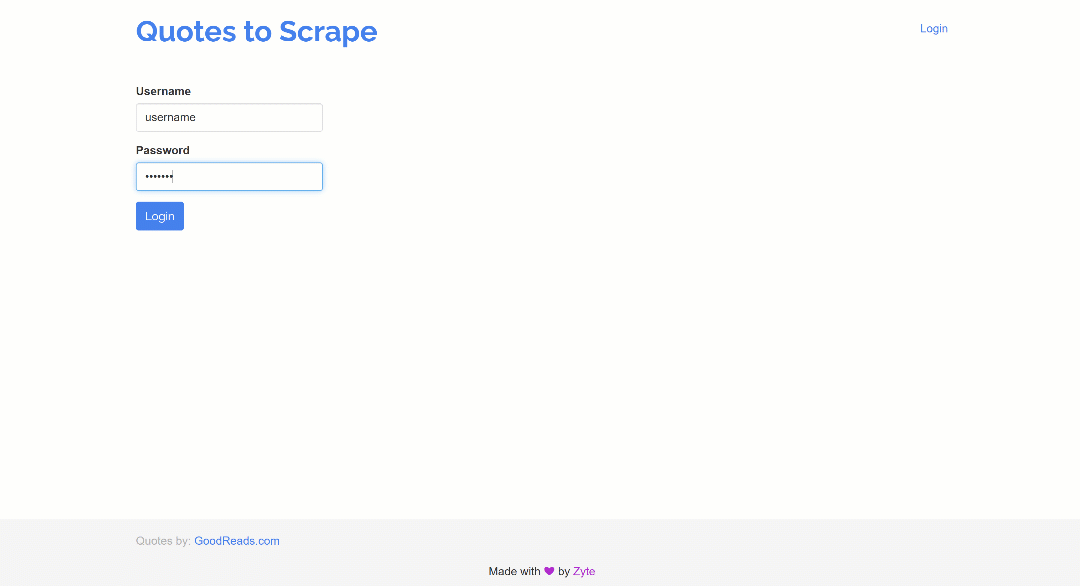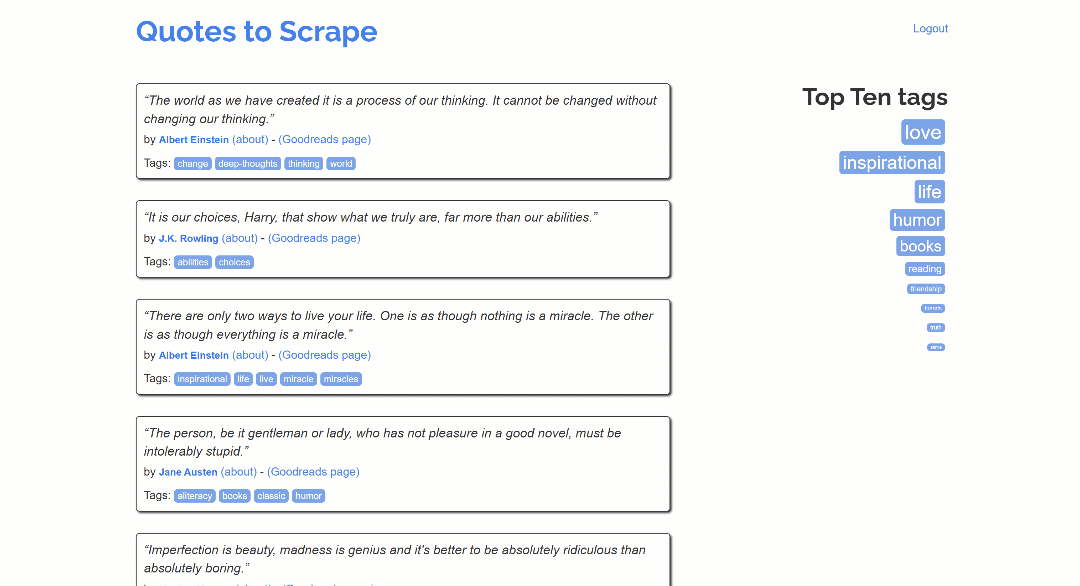
正如你所看到的,Puppeteer 机器人现在与登录表单的交互方式更加自然,就像真正的人类用户一样。它以逼真的速度打字,偶尔会打错字,然后纠正过来。这就是Puppeteer 人性化的力量!
这种网络抓取方法面临的挑战
puppeteer-humanize绝对是减少被分析用户交互方式的技术检测到的机会的好帮手。不过,反捕获、反捕获和反机器人技术远不止用户行为这么简单!
首先,请记住 Puppeteer 必须对浏览器进行编程控制。这就引入了微妙的变化和迹象,可能会暴露浏览器是自动化的。为了减少这些泄露,你还应该考虑使用 Puppeteer Stealth。
即使同时使用了puppeteer-humanize和 Puppeteer Stealth,您仍可能在交互过程中遇到验证码。在这种情况下,请参阅我们关于使用 Playwright 绕过验证码的文章。
虽然这些工具和指南可以帮助你建立一个更有弹性的抓取设置,但它们所依赖的许多变通方法并不能持久。如果你面对的是使用高度复杂的反僵尸解决方案的网站,你成功的几率就会大大降低。此外,添加多个插件可能会增加你的设置对内存和磁盘的占用,并且难以扩展。
在这一点上,问题不只是 Puppeteer 本身,而是它所控制的浏览器的局限性。真正的突破来自于将 Puppeteer 与专为网络抓取而设计的云浏览器 Headful 集成。该解决方案内置支持旋转代理、高级验证码解码、逼真的浏览器指纹等功能。这正是Bright Data 浏览器 API 的意义所在!
结论
在本教程中,您将了解到 vanilla Puppeteer 在用户行为分析方面的不足,以及如何使用puppeteer-humanize 解决这一问题。特别是,您将通过分步教程了解如何将这种方法集成到网络抓取工作流程中。
虽然这种方法可以帮助你绕过简单的反僵尸系统,但并不能保证高成功率。尤其是当您搜索依赖验证码、IP 禁止或现代人工智能反僵尸技术的网站时,情况更是如此。此外,扩展这种设置也很复杂。
如果您的目标是让您的抓取脚本甚至人工智能代理表现得更像真实用户,那么您应该考虑使用专门为此用例设计的浏览器:Bright Data 的代理浏览器。
创建一个免费的 Bright Data 帐户,访问我们的整个 AI 就绪抓取基础设施!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



