

在本指南中,您将了解到
- 什么是 Puppeteer Real Browser?
- 如何避免机器人检测并解决验证码问题
- 与香草 Puppeteer 的比较
- 如何使用它来对抗真实世界中的僵尸检测系统
- 其主要替代品
- 其主要局限性
- 更好的反僵尸浏览器自动化方法
让我们深入了解一下!
什么是 Puppeteer Real Browser?
Puppeteer Real Browser是一个 JavaScript 库,能让 Puppeteer 控制的浏览器表现得更像真实用户。这可减少 Cloudflare 等 WAF 服务的僵尸检测。它还支持自动验证码解码,包括Cloudflare Turnstile。
该库通过自定义配置扩展了 Puppeteer,同时支持代理和普通 Puppeteer 的所有其他功能。该库是开源的,在 GitHub 上有超过 1k颗星,在 npm 上以puppeteer-real-browser 的形式提供,并支持 Docker 部署。
注:2026 年 2 月,该库的作者mdervisaygan 宣布该项目将不再接受更新。这并不意味着 Puppeteer Real Browser 必定死亡,因为社区成员可以通过分叉继续开发。
Puppeteer Real 浏览器如何工作?
如果你使用过 Puppeteer、Playwright 或 Selenium 等浏览器自动化工具,就会知道这些工具控制的浏览器会被反僵尸系统检测到。在无头模式下运行时尤其如此,即使使用的是最好的无头浏览器。
阻塞之所以会发生,是因为自动化库以一种更容易控制的方式配置浏览器。反僵尸解决方案会查找这些配置和 “泄露”,以确定请求是来自使用普通浏览器的真人还是自动机器人。
Puppeteer Real Browser 使用Rebrowser 解决了这一问题,Rebrowser 是 Puppeteer 和 Playwright 的补丁集,旨在防止自动化检测。
Rebrowser 直接修改了puppeteer-core,修补了浏览器运行时,以消除 Puppeteer 留下的类似僵尸的痕迹。这些修改使浏览器看起来更像一个真实的用户会话,从而降低了被反僵尸系统拦截的几率。
不过,Cloudflare 等 WAF仍可能提供一键式验证码:
在这种情况下,Puppeteer Real Browser 依靠ghost-cursor与验证码进行交互,就像真实用户一样。这是一个 JavaScript 库,可以在 Puppeteer 或任何二维平面上生成类似人类的鼠标动作。
问题在于,由于光标行为不自然,Puppeteer 鼠标事件经常被检测为合成事件。Puppeteer Real Browser 通过改进 .screenX 和 .screenY 值的处理方式解决了这一问题,使鼠标移动看起来更自然。这有助于欺骗 Cloudflare Turnstile、reCAPTCHA 和其他一键式验证码,使其认为交互来自真实的人类用户。
图书馆还包括
- Puppeteer Extra:通过插件启用扩展
- Xvfb:用于处理虚拟浏览器显示,非常适合无头环境。
简而言之,Puppeteer Real Browser 结合了不同的增强功能,创造出一种隐秘的高保真自动化工具,既能模仿人类用户,又能避免被发现。
Puppeteer 真实浏览器 vs Puppeteer
下面是puppeteer与puppeteer-real-browser 的汇总表,用于比较这两种技术:
| 木偶师 | 傀儡廻真正的浏览器 | |
|---|---|---|
| GitHub 星级 | 1k 星级 | 89.7k 星级 |
| npm 库 | 木偶 |
木偶真实浏览器 |
| npm 下载 | ~360 万次每周下载 | 每周下载 ~10k 次 |
puppeteer-core版本 |
标准木偶核心 |
修补rebrowser-puppeteer-core以移除自动化痕迹 |
| 反僵尸检测 | 先进的僵尸防护功能可轻松检测到 | 旨在躲避僵尸检测系统(Cloudflare、Akamai 等) |
| 应用程序接口 | 默认值 | 与 Puppeteer API 相同,但有额外扩展 |
| 代理支持 | 支持代理服务器 | 支持代理服务器 |
| 验证码处理 | 无内置验证码解决方案 | 支持一键解决验证码问题(例如 Cloudflare Turnstile、reCAPTCHA) |
| 插件支持 | 不支持本地插件 | 与puppeteer-extra集成,提供插件支持 |
| 维护和更新 | 由 Google 积极维护 | 作者已停止出版(2026 年 2 月),但可通过社区继续出版 |
如何使用 Puppeteer Real 浏览器绕过 CATPCHAs
为了展示 Puppeteer Real Browser的功能,我们将针对Scraping Course 的反僵尸挑战页面进行测试:
这个受 Cloudflare 保护的页面具有 Turnstile 一键式验证码。在本节中,我们将逐步介绍如何使用 Puppeteer Real Browser 来解决这个问题。
如需另一种方法,请查看我们的Puppeteer 绕过验证码指南。必须知道的是,试图访问该页面的标准 Puppeteer 脚本总会遇到转门验证码并被阻止。
正如你即将看到的,Puppeteer Real Browser 是绕过 Cloudflare和类似反僵尸保护的有效解决方案!
步骤 1:安装puppeteer-real 浏览器
我们假设您已经建立了一个 Node.js 项目。如果没有,可以使用npm init 创建一个。
现在,导航到项目文件夹,用以下命令安装 puppeteer-real-browser:
npm install puppeteer-real-browser在 Linux 上,还需要将xvfb作为系统级依赖项进行安装。对于基于 Debian 的系统,请使用以下命令安装:
sudo apt-get install xvfb太好了!现在,您可以使用 Puppeteer Real Browser 绕过验证码了。
步骤 #2:初始设置
在 JavaScript 脚本中,从 Puppeteer Real Browser 导入 connect:
const { connect } = require("puppeteer-real-browser");通过connect()函数,您可以在异步函数中与修改后的浏览器引擎建立连接:
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// scraping logic...
await browser.close();
})();就像在普通 Puppeteer 中一样,你需要调用browser.close()来释放资源。
Puppeteer Real 浏览器中的connect()函数接受以下参数:
无头:默认为false。也可以使用其他值,如"new"、"true"和"shell",但false是最稳定的值。参数:附加 Chromium 标志可以字符串数组形式传递。查看支持的标志。自定义配置:Puppeteer Real 浏览器使用chrome-launcher初始化。你在这里传递的任何选项都将直接添加为初始化参数。你可以用它来设置userDataDir或自定义 Chrome 浏览器路径(chromePath)。turnstile: 如果为 true,Puppeteer Real 浏览器会自动点击 Cloudflare Turnstile 验证码。connectOption:使用puppeteer.connect() 连接Chromium 时发送的选项。disableXvfb:在 Linux 上,当无头:false时,浏览器将使用虚拟显示器(xvfb) 运行。将其设置为true可禁用虚拟显示,查看实际的浏览器窗口。ignoreAllFlags:如果为 "true“,则覆盖所有默认初始化参数,包括首次加载时出现的 “让我们开始吧 “页面。插件:Puppeteer Extra 插件阵列。更多信息请参阅官方文档。
上述函数支持的所有其他选项均来自 Puppeteerconnect()方法。
由于我们要绕过 Cloudflare,本例中的关键设置是turnstile为true。
步骤 #3:连接到目标页面
使用 Puppeteer API 的goto()函数导航到目标页面:
await page.goto("https://www.scrapingcourse.com/antibot-challenge");由于turnstile设置为true,Puppeteer Real Browser 将自动等待 Cloudflare Turnstile 验证码加载并尝试解决。
步骤 #4:等待验证码解锁
如果在隐身模式下打开目标页面并手动解决验证码问题,会得到以下结果:

使用 DevTools 检查信息,您会看到:
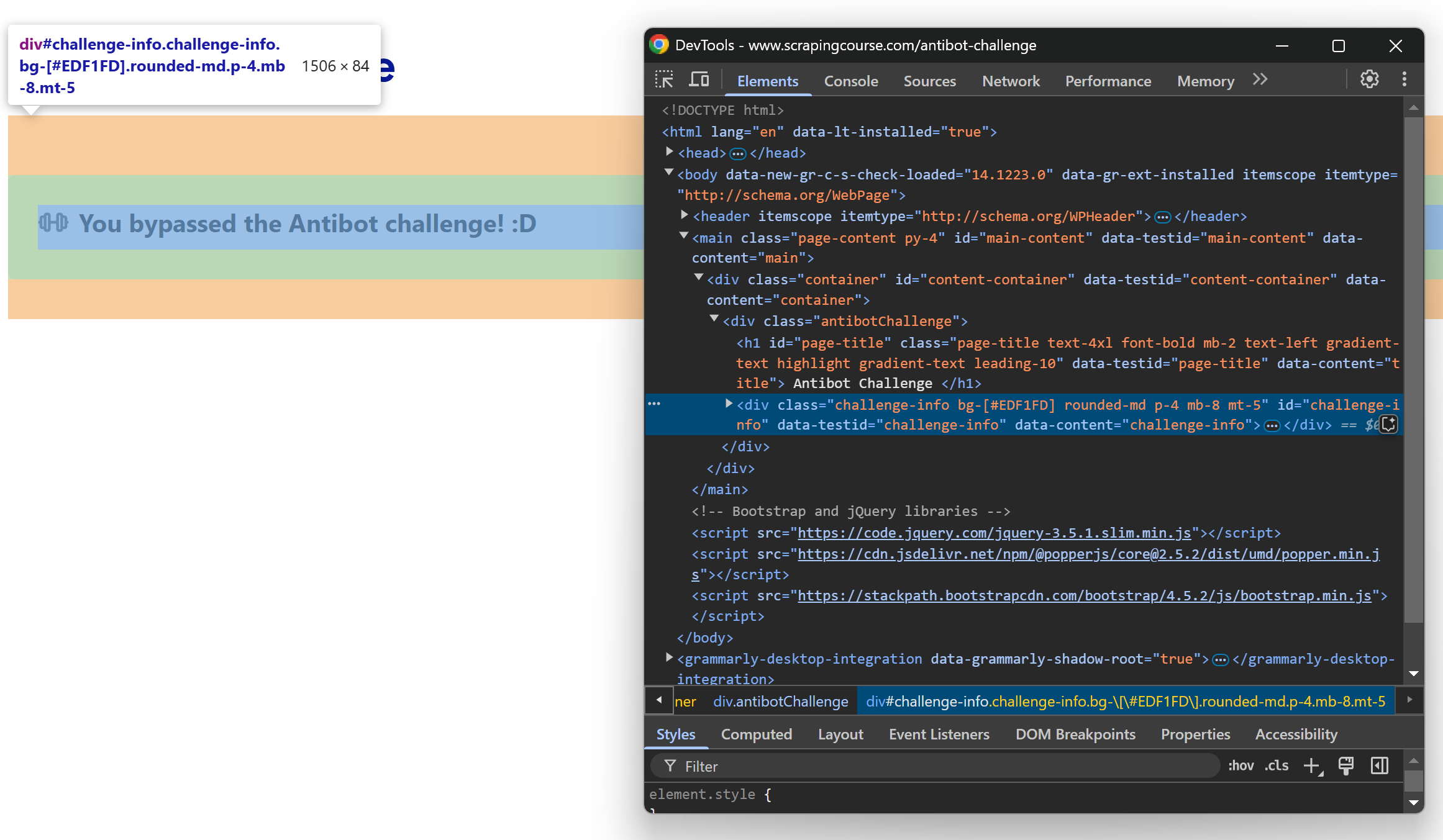
请注意,可以使用#challenge-infoCSS 选择器选择信息元素。
现在,定义一个自定义函数来等待页面 DOM 更改:
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}该函数是必要的,因为 puppeteer-Real 浏览器没有为验证码解析提供内置回调。由于我们预计 Puppeteer Real 浏览器会成功绕过验证码,因此页面 DOM 会相应更新,你需要等待这些变化。
因此,可以使用delay()等待一段时间,让页面完全更新,如下所示:
await delay(10000);然后,等待目标信息元素出现在页面上:
await page.waitForSelector("#challenge-info", { timeout: 5000 });然后,检索并打印其内容:
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Page message: "${challengeInfo}"`);如果一切正常,脚本就会输出:
Page message: "You bypassed the Antibot challenge! :D"步骤 #5:将所有内容整合在一起
以下是 Puppeteer Real Browser 脚本的最终版本:
const { connect } = require("puppeteer-real-browser");
// custom function to implement a hard wait
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// connect to the controlled browser
const { browser, page } = await connect({
headless: false,
turnstile: true, // enable Turnstile CAPTCHA handling
connectOption: {
defaultViewport: null, // make the viewport as large as the browser window
},
args: ["--start-maximized"], // start the browser in a maximized window
});
// navigate to the challenge page
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // Wait for the page to be fully loaded and idle
});
// wait up to 10 seconds for the CAPTCHA to be solved
await delay(10000);
// wait up to 5 seconds for the challenge info element to appear
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// retrieve and print the challenge info text
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Page message: "${challengeInfo}"`);
// close the browser and release its resources
await browser.close();
})();启动上述代码,就会打开一个浏览器,行为如下:
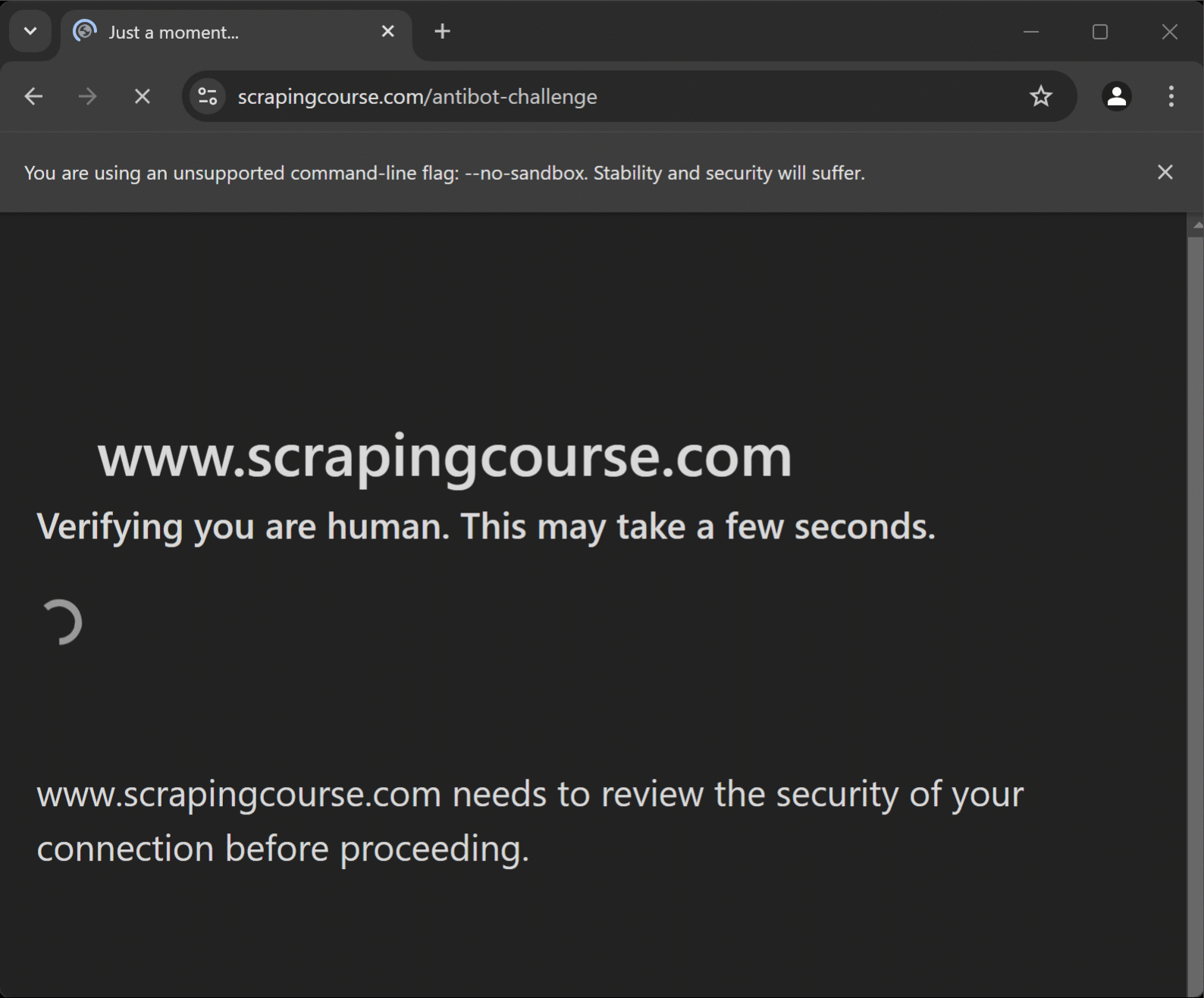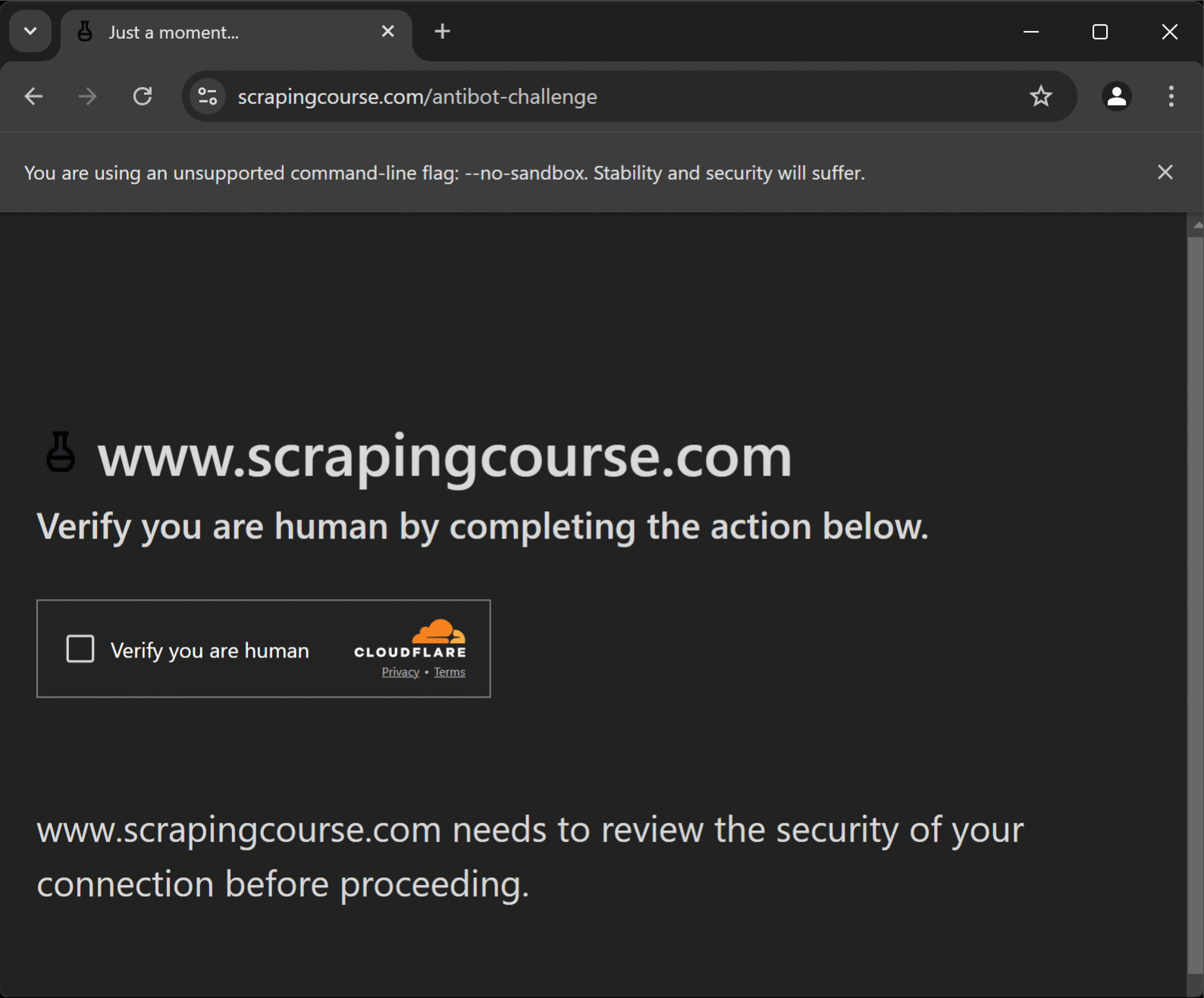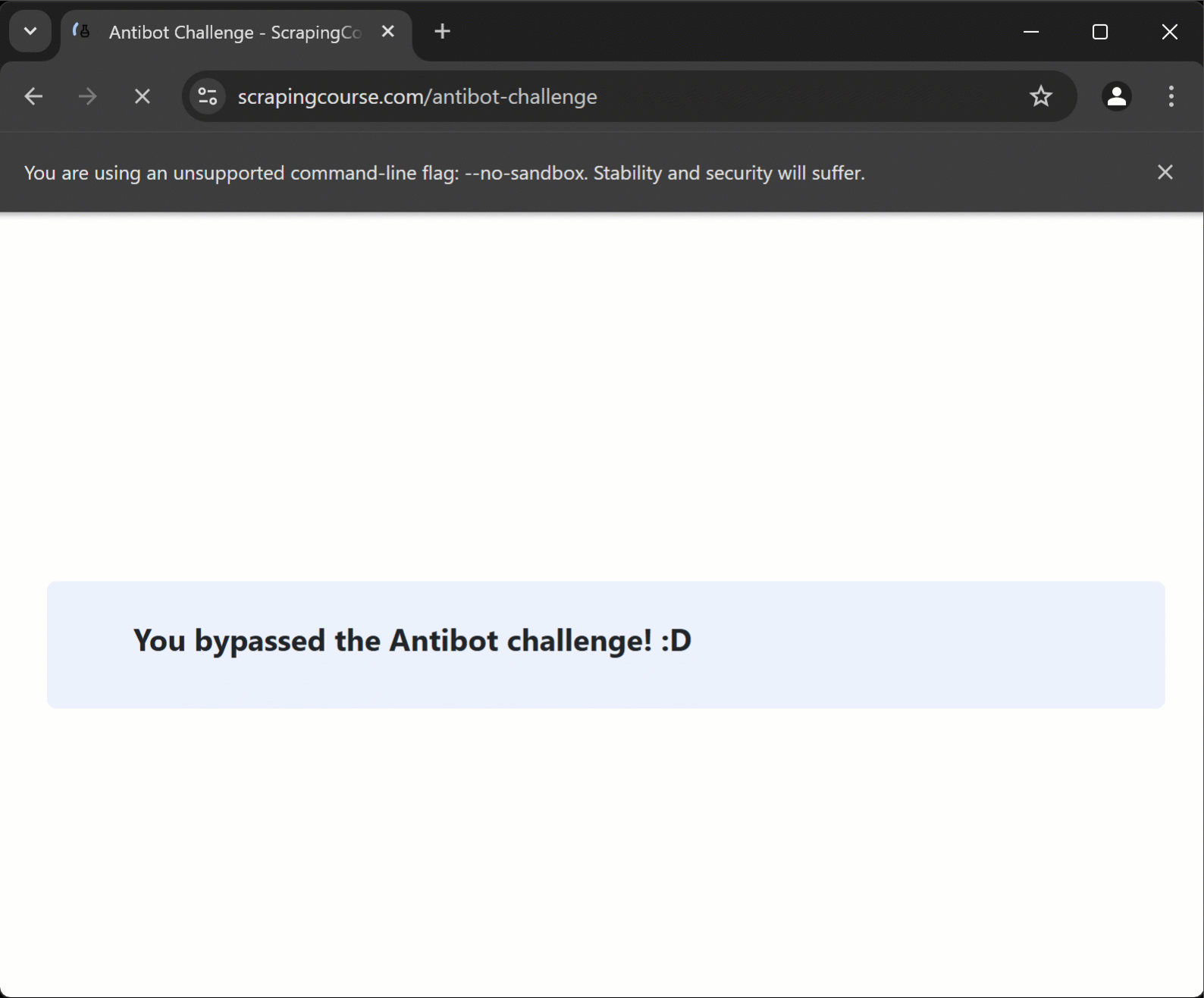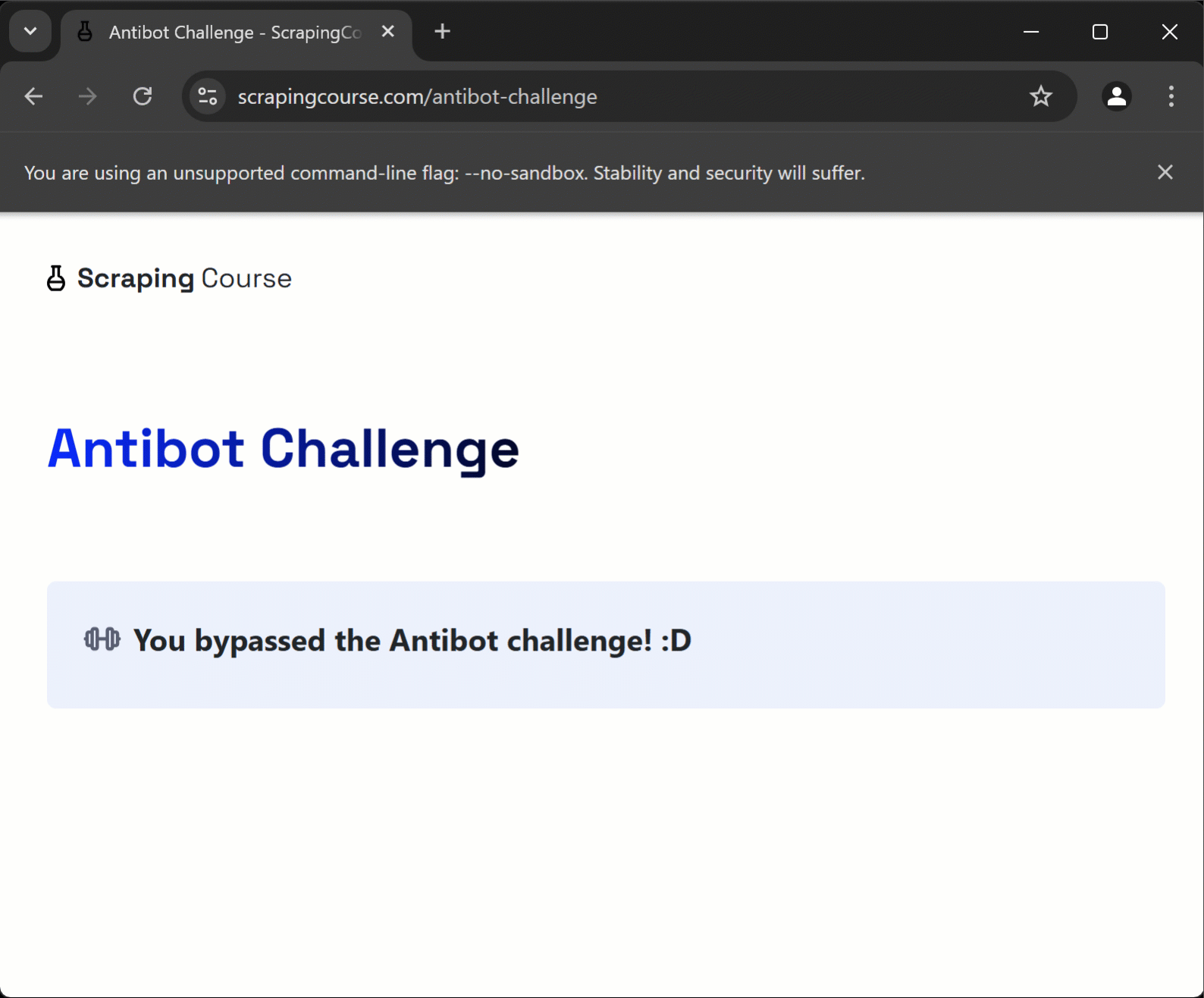
脚本访问 Cloudflare 保护的页面,自动解决验证码问题,然后到达目标页面,从中提取数据。
脚本会在终端中生成所需的结果:
Page message: "You bypassed the Antibot challenge! :D"太棒了Cloudflare 验证码已自动解决。
puppeteer-real-browser 的替代品
由于 puppeteer-real-browser 已不再维护,因此值得探索提供类似功能的替代方案,例如
- Puppeteer Stealth:Puppeteer Extra 的插件,可应用各种规避措施,使自动化更不易被发现。它能修改浏览器指纹、禁用 WebRTC 泄密,并模仿人类行为以绕过反僵尸措施。
- Playwright Stealth:Playwright Extra 插件,集成了与 Puppeteer Stealth 类似的隐身技术。它修补了浏览器 API,以防止指纹泄露。
- SeleniumBase基于 Selenium 的全功能自动化框架,内置反僵尸检测功能。它包括僵尸规避技术、用户代理欺骗、验证码处理和其他工具,可帮助 Selenium 脚本绕过僵尸保护。
- undetected-chromedriver:修改后的 ChromeDriver 版本,可帮助 Selenium 脚本绕过僵尸检测。它移除了自动化标记,混淆了 WebDriver 属性,并确保浏览器的行为更像人类操作的会话。
Puppeteer Real 浏览器限制
Puppeteer Real Browser 是一款功能强大的反僵尸浏览器自动化工具,但它也有一些缺点。作者对这些制约因素的认识是透明的,并对其局限性提供了清晰的见解。
主要限制因素有
- 不再维护:自 2026 年 2 月起,原作者宣布不再更新该库。未来的改进将取决于社区贡献而非主动开发。
- 并非 100% 检测不到:虽然可以减少僵尸检测,但先进的反僵尸系统仍可能标记自动流量。
- 需要额外配置:用户可能需要对代理、标头和其他设置进行微调,以获得最佳的隐蔽性和功能。
- 无法访问 窗口 对象中的函数:出现这种情况是因为 Rebrowser 关闭了浏览器运行时。解决方法是使用puppeteer-intercept-and-modify-requests 或 Chrome 浏览器插件将 JavaScript 注入页面。
- 依赖外部库:该库依赖于 Rebrowser、Puppeteer Extra 和 ghost-cursor 等第三方项目,这些项目可能会变更或终止。
- 与 reCAPTCHA 有关的问题:reCAPTCHA v3 要求通过活动的 Google 会话。即使使用无法检测的浏览器,在没有有效会话的情况下尝试自动验证也可能会被标记。
无缝反僵尸浏览器自动化
上述缺点可能会让你放弃使用 Puppeteer Real Browser。虽然你可以试试它的替代品,但很可能会遇到类似的难题。
重要的是,大多数反僵尸浏览器自动化库的重点是修补浏览器,而不是浏览器自动化库本身。虽然可能需要对这些库的核心部分稍作修改,但大部分工作都是为浏览器引擎打补丁,以避免检测泄漏。
现在,想象一下利用 Playwright、Puppeteer 和 Selenium 等虚构的浏览器自动化库(依靠其更新和稳定的 API)来控制专门为网络抓取设计的基于云的可扩展浏览器。这正是Bright Data 的 Scraping Browser 所提供的体验!
Scraping Browser 内置网站解锁功能,可为你自动处理拦截。它能与由 7200 多万个 IP 组成的代理网络无缝集成,在云端高效运行,还包括一个集成的验证码解码器。
针对抓取优化的浏览器是实现反僵尸浏览器自动化的真正解决方案!
结论
在本文中,你将了解如何使用 Puppeteer Real Browser 处理 Puppeteer 中的僵尸检测。该库提供了一个打了补丁的 puppeteer-core 版本,可用于网络抓取而不会被阻止。
问题在于,puppeteer-real-browser已不再维护。因此,虽然它今天可能有效,但随着反僵尸解决方案的不断发展,它明天可能就失效了。
问题不在于 Puppeteer 控制浏览器的 API,而在于浏览器本身。解决办法是使用基于云、随时更新、可扩展、内置反僵尸绕过功能的浏览器,如Scraping Browser!
Bright Data’s Scraping Browser 是一款高度可扩展的云浏览器,可与Puppeteer、Selenium、Playwright 和其他浏览器配合使用。它能为您处理浏览器指纹、验证码解析和自动重试。
此外,得益于包括全球代理网络在内的全球代理网络,每次请求时它都会自动轮换出口 IP:
立即创建免费的 Bright Data 帐户,试用我们的抓取浏览器或测试我们的代理服务器。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




