
在本教程中,我们将涵盖:
- 如何使用 Bright Data 的 SERP API 抓取 Naver 搜索结果
- 使用 Bright Data 代理构建自定义 Naver 爬虫
- 使用 Bright Data Scraper Studio(AI Scraper)以零代码工作流抓取 Naver
让我们开始吧!
为什么要抓取 Naver?
Naver 是韩国领先的平台,也是搜索、新闻、购物以及用户生成内容的主要来源。与全球搜索引擎不同,Naver 会在结果中直接呈现其自有服务,使其成为面向韩国市场的公司不可或缺的数据来源。
抓取 Naver 可以获取公共 API 不提供、且难以在大规模下手动收集的结构化与非结构化数据。
可以采集哪些数据?
- 搜索结果(SERP): 排名、标题、摘要与 URL
- 新闻: 发布方、标题与时间戳
- 购物: 商品列表、价格、卖家与评价
- 博客与 Cafe: 用户生成内容与趋势
关键使用场景
- 面向韩国市场的 SEO 与关键词追踪
- 跨新闻与用户内容的品牌与口碑监控
- 使用 Naver Shopping 进行电商与价格分析
- 从博客与论坛进行市场与趋势研究
在了解背景之后,让我们进入第一种方式:使用 Bright Data 的 SERP API 抓取 Naver 搜索结果。
使用 Bright Data 的 SERP API 抓取 Naver
当你希望获取 Naver SERP 数据、但不想管理代理、CAPTCHA 或浏览器环境时,这种方式非常理想。
前置条件
要跟随本教程,你需要:
- 一个 Bright Data 账号
- 在 Bright Data 控制台中可访问 SERP API、代理 或 Scraper Studio
- 安装 Python 3.9 或更高版本
- 对 Python 与 Web 抓取概念有基本了解
对于自定义爬虫示例,你还需要:
- 在本地安装并配置 Playwright
- 通过 Playwright 安装 Chromium
在 Bright Data 中创建 SERP API Zone
在 Bright Data 中,SERP API 需要一个专用 zone。设置步骤如下:
- 登录 Bright Data。
- 在控制台中进入 SERP API 并创建一个新的 SERP API zone。
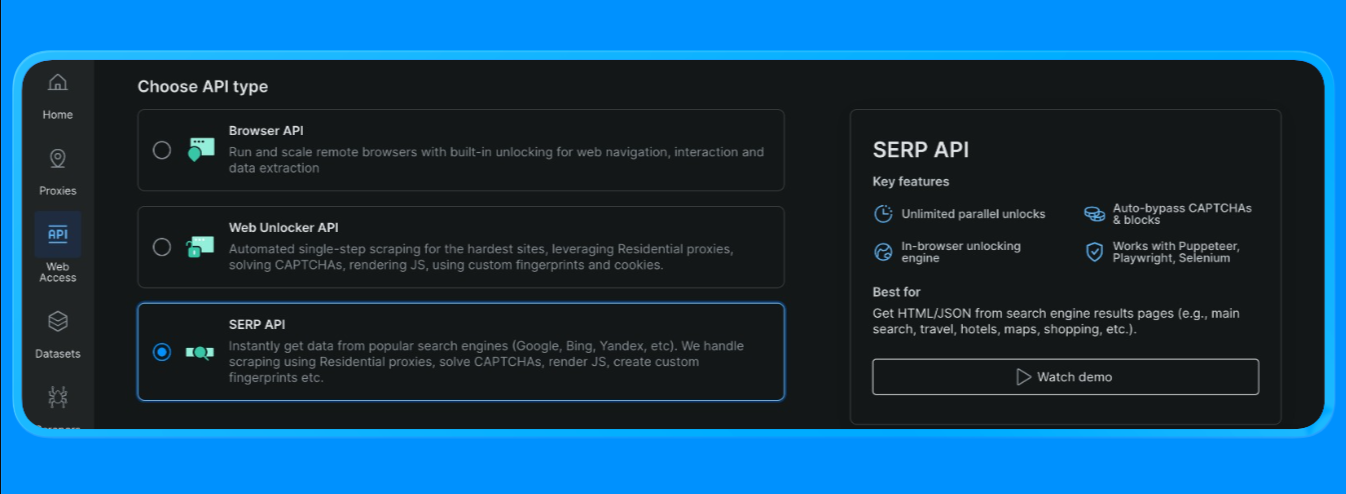
- 复制你的 API key。
构建 Naver 搜索 URL
Naver 的 SERP 可以通过标准搜索 URL 格式请求:
- 基础端点:
https://search.naver.com/search.naver - 查询参数:
query=<your keyword>
查询词使用 quote_plus() 进行 URL 编码,这样多词关键词(例如 “machine learning tutorials”)能被正确格式化。
发送 SERP API 请求(Bright Data Request Endpoint)
Bright Data 的快速开始流程使用一个统一端点 (https://api.brightdata.com/request),你需要传入:
zone:你的 SERP API zone 名称url:你希望 Bright Data 抓取的 Naver SERP URLformat:设置为 raw 以返回 HTML
Bright Data 也支持解析后的输出模式(例如通过 brd_json=1 返回 JSON 结构,或通过 data_format 选项返回更快的“顶部结果”),但本教程这一节我们将使用你的 HTML 解析流程。
你现在可以创建一个 Python 文件并加入以下代码:
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "your_brightdata_username"
BRIGHTDATA_PASSWORD = "your_brightdata password"
PROXY_SERVER = "your_proxy_host"
def clean_text(text: str) -> str:
return re.sub(r"\s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""Block ads/utility links; allow blog.naver.com since we want blog results."""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# block ad redirects + obvious non-content utilities
blocked_domains = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# In blog mode, you can either:
# (A) allow only Naver blog/post domains (more "Naver-ish")
allowed = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in allowed)
def pick_snippet(container) -> str:
"""
Heuristic: pick a sentence-like text block near the title.
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# avoid breadcrumb-ish lines
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# Blog SERP layouts change; use multiple fallbacks
selectors = [
"a.api_txt_lines", # common title link wrapper
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Naver blog vertical
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# Proxy-friendly timeouts
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# Block heavy resources to speed up + reduce hangs
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# Retry once (Navers can be slightly flaky)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("\nExtracted Naver Blog results:")
for i, r in enumerate(results, 1):
print(f"\n{i}. {r['title']}\n {r['link']}\n {r['snippet']}")通过 fetch_naver_html() 函数,我们将一个 Naver 搜索 URL 发送到 Bright Data 的 request 端点,并获取了完整渲染的 SERP 页面。Bright Data 自动处理了 IP 轮换与访问,使请求无需遭遇封锁或速率限制即可成功。
随后我们使用 BeautifulSoup 解析 HTML,并应用自定义过滤逻辑移除广告与 Naver 内部模块。extract_web_results() 函数会扫描页面以找到有效的结果标题、链接以及邻近文本块,对其去重后返回一个干净的搜索结果列表。
当你运行脚本时,将得到类似如下的输出: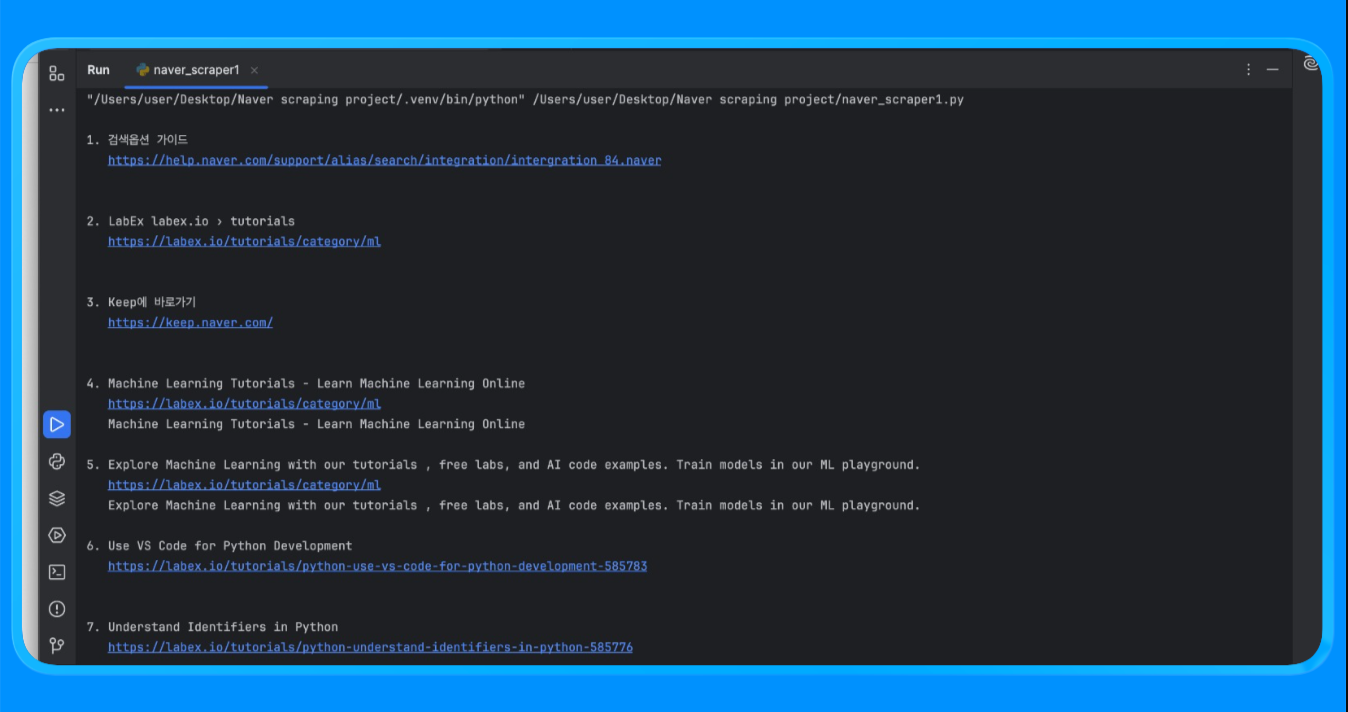
该方法用于在无需构建或维护自定义爬虫的情况下收集结构化的 Naver 搜索结果。
常见使用场景
- 在 Naver 上进行关键词排名与可见度追踪
- 韩国市场的 SEO 表现监控
- 分析 SERP 功能位,例如新闻、购物与博客展示位置
当你需要一致的输出结构、并以最小的搭建成本进行高请求量采集时,这种方式效果最佳。
在完成 SERP 级别抓取后,我们接下来将使用 Bright Data 代理构建自定义 Naver 爬虫,以支持更深度的抓取与更高的灵活性。
使用 Bright Data 代理构建自定义 Naver 爬虫
这种方式使用真实浏览器渲染 Naver 页面,同时通过 Bright Data 代理转发流量。当你需要完全控制请求、JavaScript 渲染,以及超出 SERP 范围的页面级数据提取时,它非常有用。
在编写代码之前,你需要先创建一个代理 zone,并从 Bright Data 控制台获取代理凭证。
获取本脚本所用代理凭证的步骤:
- 登录你的 Bright Data 账号
- 在控制台进入 Proxies 并点击 “Create Proxy”
- 选择 数据中心代理(Datacenter Proxies)(我们在该项目选择此选项;具体选择取决于范围与项目用例)
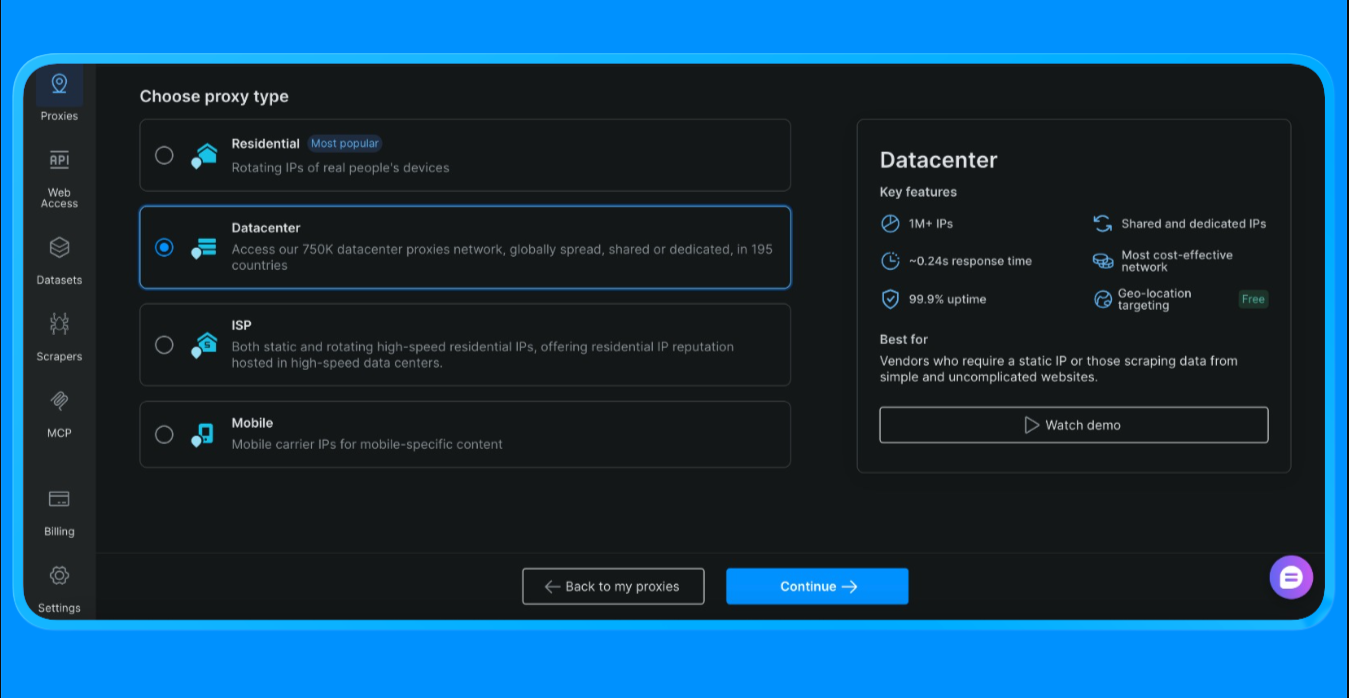
- 创建一个新的代理 zone
- 打开该 zone 的设置并复制以下值:
- 代理用户名
- 代理密码
- 代理端点与端口
这些值用于对通过 Bright Data 代理网络转发的请求进行身份验证。
将 Bright Data 代理凭证添加到脚本中
创建代理 zone 后,将脚本更新为你从控制台复制的凭证。
BRIGHTDATA_USERNAME包含你的客户 ID 与代理 zone 名称BRIGHTDATA_PASSWORD包含该代理 zone 的密码PROXY_SERVER指向 Bright Data 的超级代理(super proxy)端点
设置完成后,Playwright 发起的所有浏览器流量都会自动通过 Bright Data 转发。
现在我们可以继续使用以下代码进行抓取:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "your_username"
BRIGHTDATA_PASSWORD = "your_password"
PROXY_SERVER = "your_proxy_host"
def clean_text(s: str) -> str:
return re.sub(r"\s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continue
if href in seen:
continue
seen.add(href)
results.append({"title": title, "link": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}\n {r['link']}\n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))scrape_naver_blog() 函数会打开 Naver 博客垂直频道,屏蔽图片、媒体与字体等重资源以减少加载时间,并在发生超时时重试导航。页面完全加载后,它会获取渲染后的 HTML。
extract_blog_results() 函数随后使用 BeautifulSoup 解析 HTML,应用针对博客的过滤规则:排除广告与工具页、允许 Naver 博客域名,并提取一份干净的博客标题、链接与附近的文本摘要。
运行脚本后,你会得到如下输出:
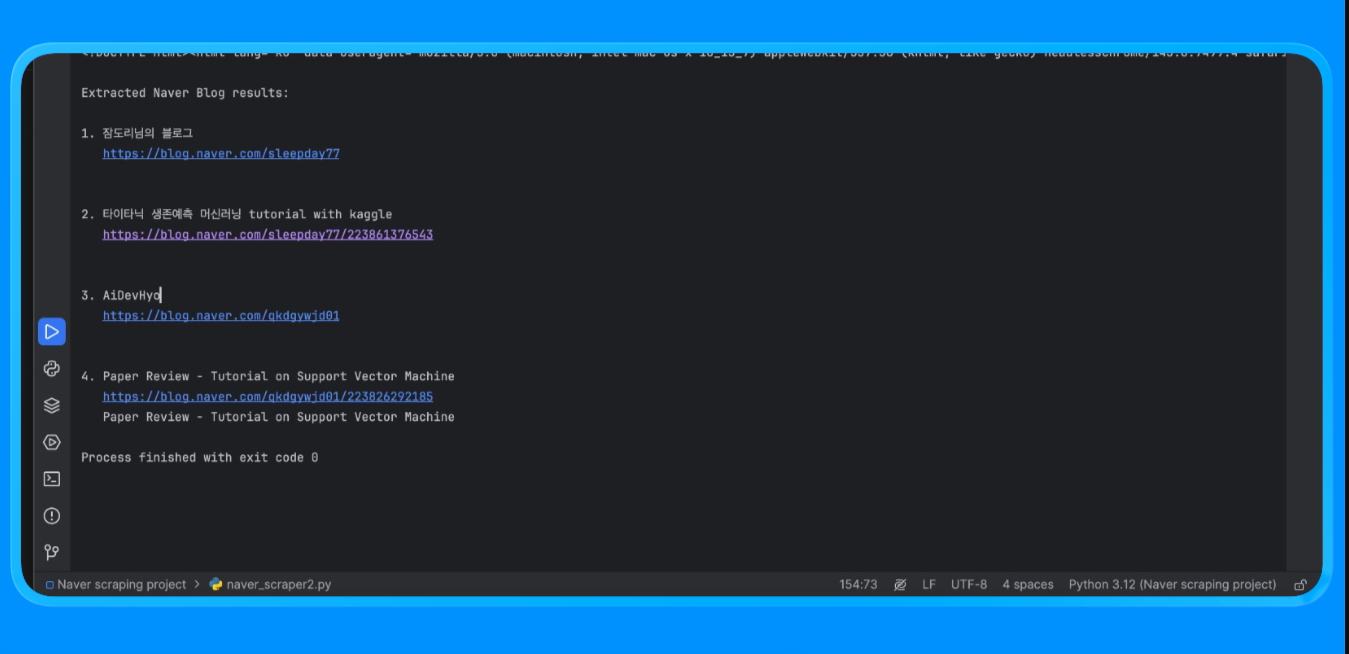
该方法用于从 需要浏览器渲染且需要自定义解析逻辑的 Naver 页面中提取内容。
常见使用场景
- 抓取 Naver Blog 与 Cafe 内容
- 采集长文、评论与用户内容
- 从 JavaScript 密集型页面提取数据
当需要页面渲染、重试与细粒度过滤时,这种方式最理想。
现在我们已经通过 Bright Data 代理跑通了自定义爬虫,接下来进入最快的方案:无需编写代码即可提取数据。在下一节中,我们将使用 Bright Data Scraper Studio(基于同一基础设施的零代码 AI 工作流)抓取 Naver。
使用 Bright Data Scraper Studio 抓取 Naver(零代码 AI 爬虫)
如果你不想编写或维护抓取代码,Bright Data Scraper Studio 提供了一种零代码方式,可使用与 SERP API 和代理网络相同的底层基础设施来提取 Naver 数据。
开始步骤:
- 登录你的 Bright Data 账号
- 在控制台左侧菜单打开 “Scrapers”,然后点击 “Scraper studio”。你会看到类似如下的控制台界面:
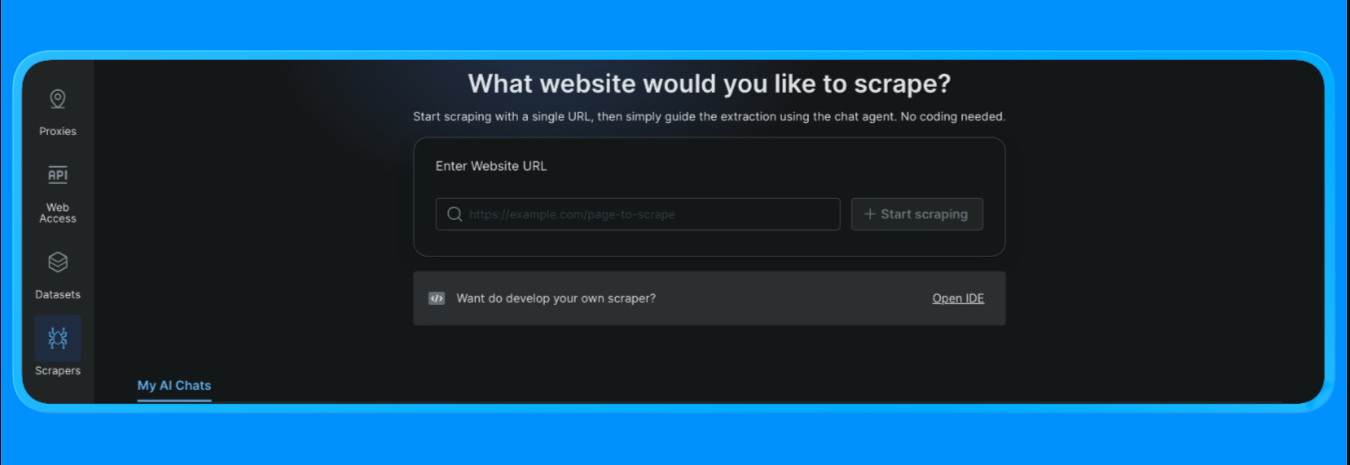
输入你要抓取的目标 URL,然后点击 “Start Scraping” 按钮。
Scraper Studio 随后会抓取该站点并返回你需要的信息。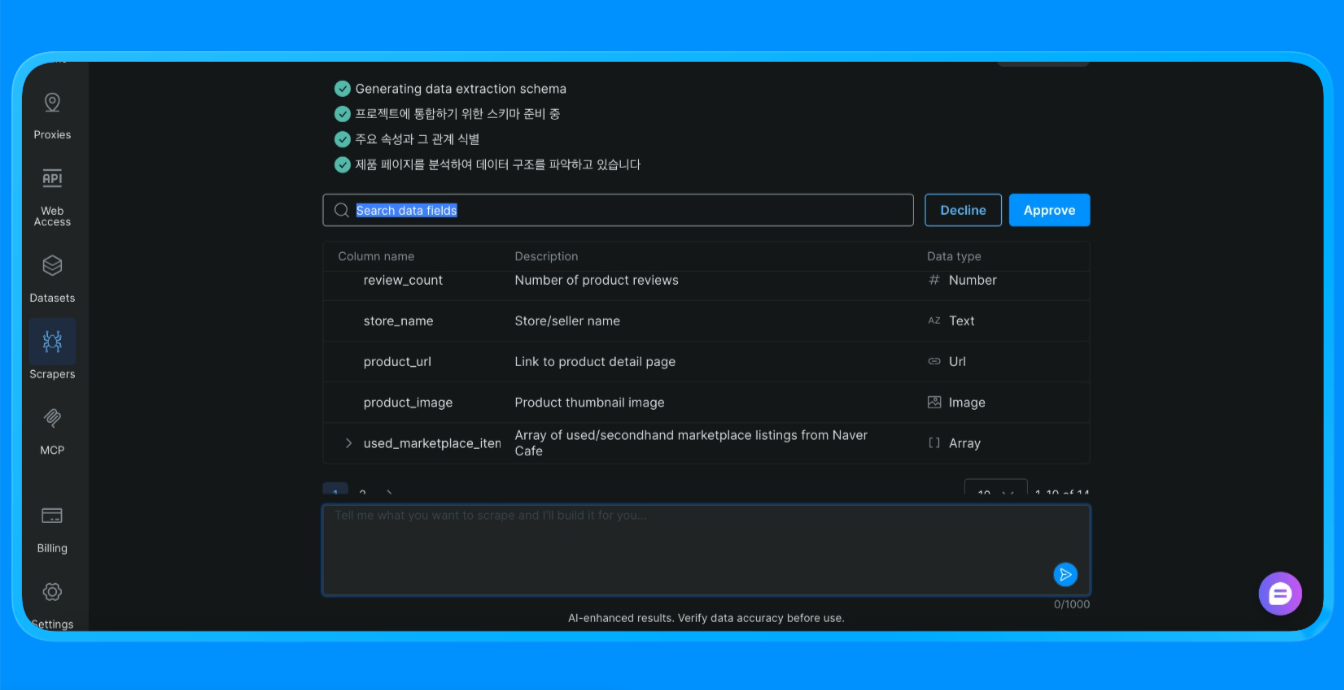
Scraper Studio 通过 Bright Data 的基础设施加载 Naver 页面,应用可视化提取规则,并返回结构化数据——否则这通常需要自定义爬虫或浏览器自动化才能实现。
常见使用场景
- 一次性数据采集
- 概念验证(PoC)项目
- 非技术团队采集网页数据
当速度与易用性比定制化更重要时,Scraper Studio 是不错的选择。
对比三种 Naver 抓取方式
| 方式 | 搭建成本 | 控制程度 | 可扩展性 | 适用场景 |
|---|---|---|---|---|
| Bright Data SERP API | 低 | 中 | 高 | SEO 追踪、关键词监控、结构化 SERP 数据 |
| 使用 Bright Data 代理的自定义爬虫 | 高 | 非常高 | 非常高 | 博客抓取、动态页面、自定义工作流 |
| Bright Data Scraper Studio | 非常低 | 低到中 | 中 | 快速提取、零代码团队、原型开发 |
如何选择:
- 当你需要大规模、可靠且结构化的搜索结果时,使用 SERP API。
- 当你需要完全掌控渲染、重试与提取逻辑时,使用代理 + 自定义爬虫。
- 当速度与简化流程比定制化更重要时,使用 Scraper Studio。
总结
在本教程中,我们介绍了三种使用 Bright Data 抓取 Naver 的生产级方法:
- 用于结构化搜索数据的托管式 SERP API
- 通过代理实现完全灵活与可控的自定义爬虫
- 用于快速数据提取的零代码 Scraper Studio 工作流
每种方案都构建在同一套 Bright Data 基础设施之上。正确的选择取决于你需要的控制程度、抓取频率,以及你是否希望编写代码。
你可以访问 Bright Data 以获取 SERP API、代理基础设施与零代码 Scraper Studio,并选择最适合你工作流的方式。
更多 Web 抓取指南与教程:



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




