
在这篇博客文章中,你将学习:
- OpenAI Agent Builder 是什么,以及它提供了哪些能力。
- 为什么你应该考虑将 Bright Data 的 Web MCP 集成到其中。
- 如何在 OpenAI 的 Agent Builder 中构建一个可复用的多用途 AI 工作流,并利用 Web MCP 工具。
让我们开始吧!
什么是 OpenAI 的 Agent Builder?
Agent Builder 是一个用于可视化创建、测试并部署多步骤自治 AI Agent 与工作流的 Web 平台。它作为 OpenAI 的免费服务提供,并属于 AgentKit 的一部分——这是一个面向开发者与企业,用于构建、部署与优化 AI Agent 的完整工具套件。
具体来说,OpenAI 的 Agent Builder 提供了一个可视化画布,让你无需编写任何代码即可设计 Agentic AI 工作流。你可以从模板开始,通过拖拽节点来定义工作流的每个步骤,设置带类型的输入与输出,并直接在 Web 应用中预览运行结果。
在部署方面,你可以使用 ChatKit 将工作流嵌入到你的网站中,或下载 SDK 代码在自有基础设施上运行。
为什么要在 OpenAI 的 Agent Builder 中将你的 Agent 连接到 Bright Data 的 Web MCP
AI Agent 与工作流的能力取决于为其提供动力的 LLM,而 LLM 的能力又受限于它可访问的知识与工具。这构成了 AI Agent 最大的限制。原因在于 LLM 引擎受制于过时的知识,这反映了训练期间使用的 静态数据。
要克服这一限制,Agent 必须能够从 Web 获取与上下文相关、最新的信息——Web 是 地球上最大的数据来源。只有这样,AI Agent 或工作流才能真正突破其底层 LLM 的固有知识限制。
如果一个 Agent 还能与网页交互、在主流搜索引擎上执行搜索,并访问来自 Amazon、YouTube 等大型网站的结构化数据源,那么它将势不可挡。这正是 Bright Data Web MCP 为任何 LLM 提供的能力,也解释了它为何能被如此广泛地采用!
Bright Data 的 Web MCP 在 GitHub 上已获得 超过 1.5k 星标, 支撑了大量从实验性到生产可用的 AI Agent 与工作流。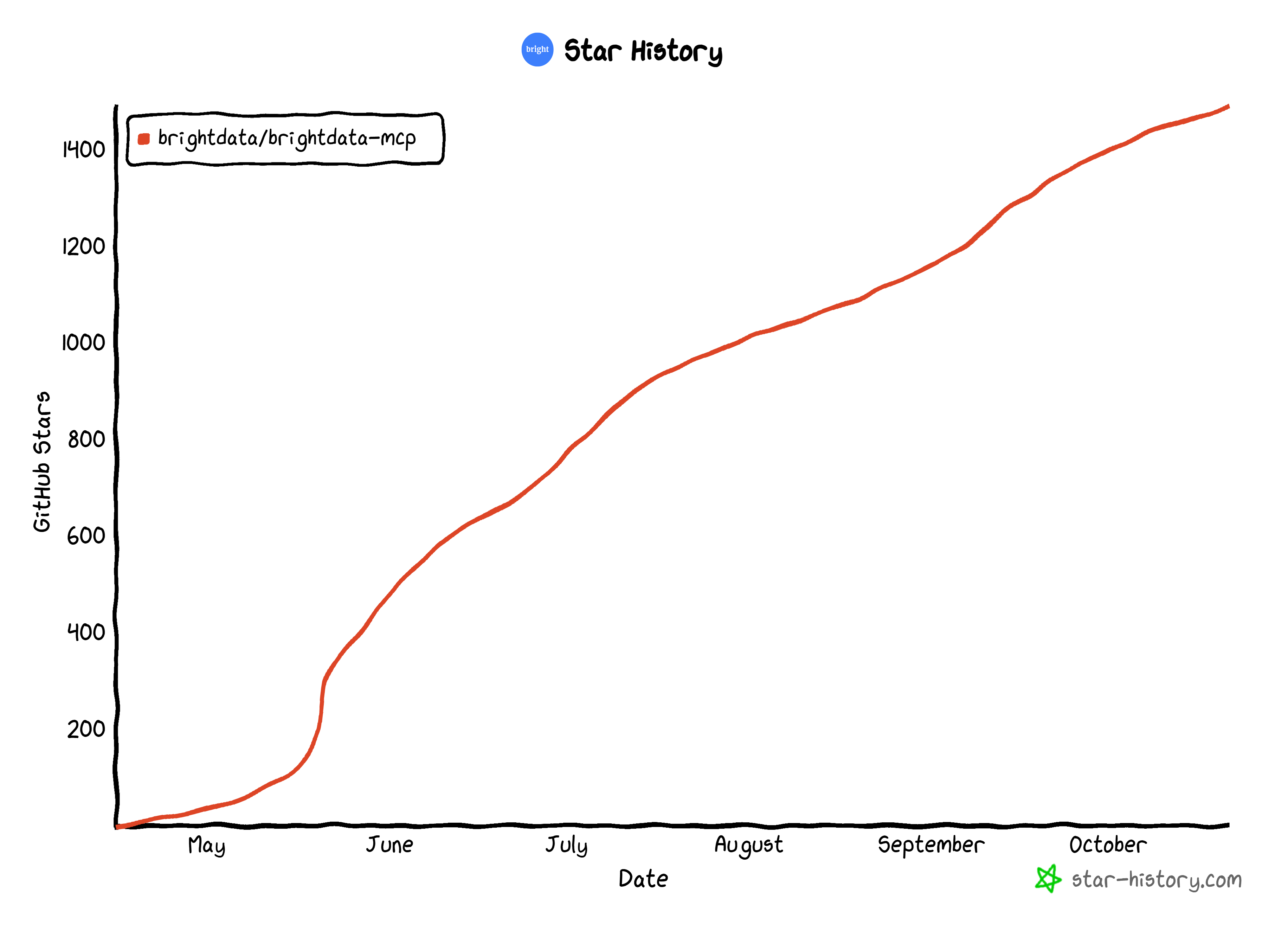
具体而言,Web MCP 暴露了 60+ 个工具, 用于网页搜索、网站导航、执行操作以及获取结构化数据,并且能够避免被反爬/反机器人措施阻断。
通过将其集成到支持自定义 MCP 集成的 OpenAI Agent Builder 中,你可以为 OpenAI 模型配备所需工具,从而克服 OpenAI(或任何其他提供商)AI 模型的固有限制!
Web MCP:Rapid 模式 vs Pro 模式
Bright Data 的 Web MCP 提供两种运行模式:
- Rapid 模式(默认):可使用核心工具,例如
scrape_as_markdown(将任意网页爬虫为 Markdown)和search_engine(执行搜索引擎查询)。该模式完全免费。详见 Web MCP 免费层公告。 - Pro 模式:解锁全部 60+ 工具,包括高级浏览器自动化与 Web 数据 API。该模式按用量计费。
更多细节请参考下方对比表:
| Rapid 模式(免费层) | Pro 模式 | |
|---|---|---|
| 价格 | $0/月(最多 5,000 次请求) | 按量计费 |
| 可用能力 | – 网页搜索 – 使用 Web Unlocker 进行爬虫 |
– 网页搜索 – 使用 Web Unlocker 进行爬虫 – 浏览器控制 – Web 数据 Scraper API |
| 启用方式 | 默认启用 | PRO_MODE=true 配置或在 URL 中添加 &pro=1 |
如何将 Web MCP 集成到使用 OpenAI Agent Builder 设计的 AI 工作流中
在本分步章节中,你将被引导完成在 OpenAI Agent Builder 中创建并集成 Bright Data Web MCP 工具的 AI 工作流。
示例工作流将演示如何获取并分析某条 Instagram 帖子的情感倾向,但 也支持许多其他用例。这只是这种配置可完成的众多任务之一。
请按照下面的说明操作!
前置条件
要在 OpenAI Agent Builder 中构建 AI 工作流,你需要:
- 一个 OpenAI 账号, 并已设置账单信息。(理想情况下,你的组织也应完成验证,以访问所有模型与功能。)
- 一个 Bright Data 账号,并已配置 API Key(应具备 Admin 权限)。
若要设置账号并获取 API Key,请 参考官方指南。 请将 Bright Data API Key 保存在安全的位置,因为很快就会用到。更多细节请参阅 Web MCP 文档。
由于 OpenAI Agent Builder 仅与远程 Web MCP 服务器集成,因此无需在本地安装任何东西(如 Python 或 Node.js)。 此外,本教程不需要编码技能。
了解 MCP 的工作原理, 熟悉 Bright Data Web MCP 暴露的工具, 以及 其远程运行方式,会很有帮助。
步骤 #1:创建一个新的工作流
在浏览器中访问 Agent Builder 平台, 使用你的 OpenAI 账号登录。首次登录时,你应会看到如下界面:
要创建新工作流,点击“Create”按钮:
默认会出现一个“New workflow”页面,包含如下设置:
OpenAI Agent Builder 会自动创建一个基础 AI 工作流,包含两个默认节点:
在画布上,你可以添加并连接节点来定义单 Agent 或多 Agent 的 AI 工作流——完全无需编写代码。
很棒!这已经是一个非常好的起点。
步骤 #2:集成 Web MCP
默认情况下,Agent 节点由某个 OpenAI 模型驱动,并可访问受支持的 OpenAI 工具。 但若要集成 MCP,你需要进行额外配置。
要让 Agent 节点访问远程 MCP 服务器,点击画布中的该节点,这将打开右侧的配置面板。 在面板中,点击 “Tools” 区域的 “+” 按钮,然后选择 “MCP server” 选项: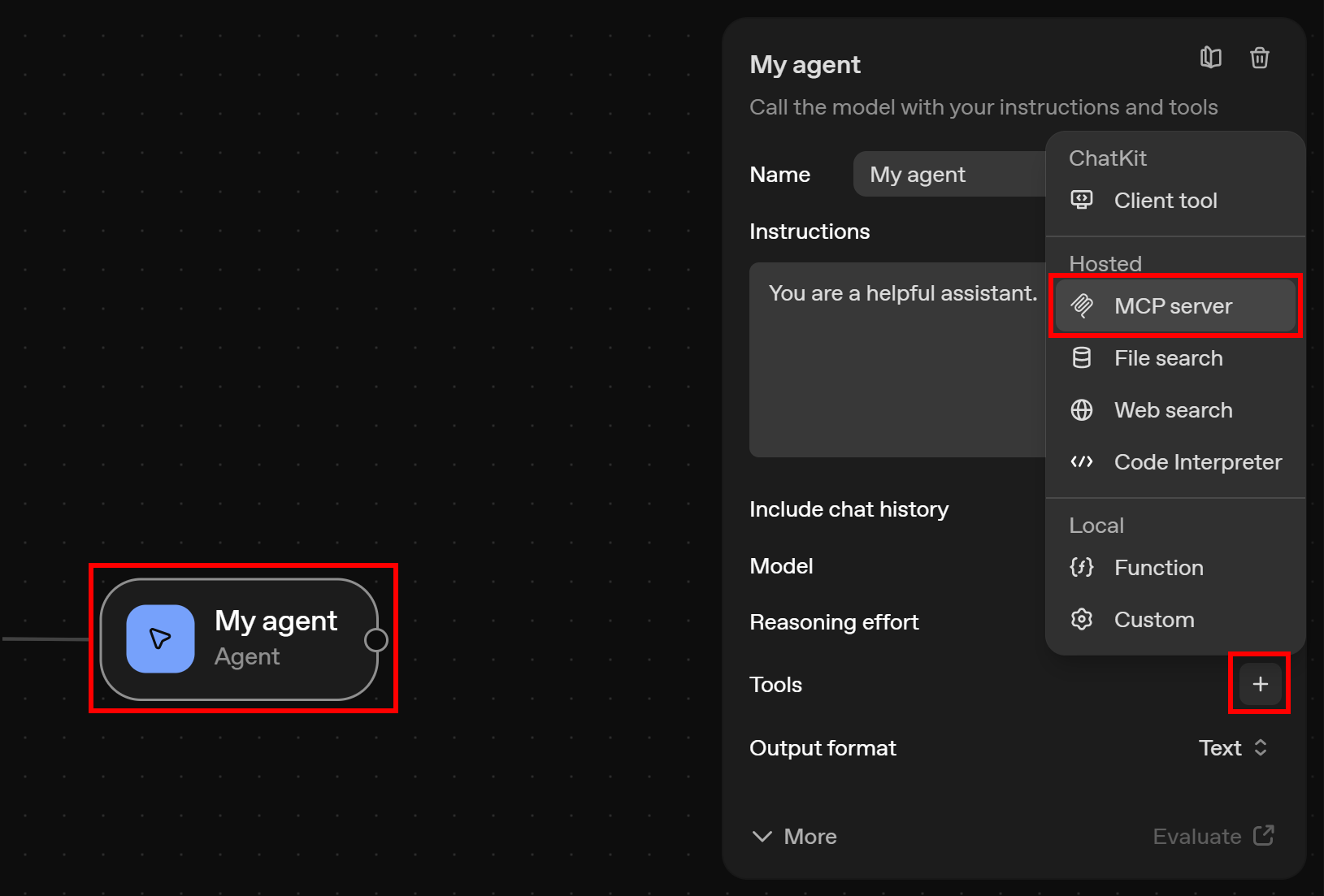
接下来会出现如下 “Add MCP Server” 弹窗: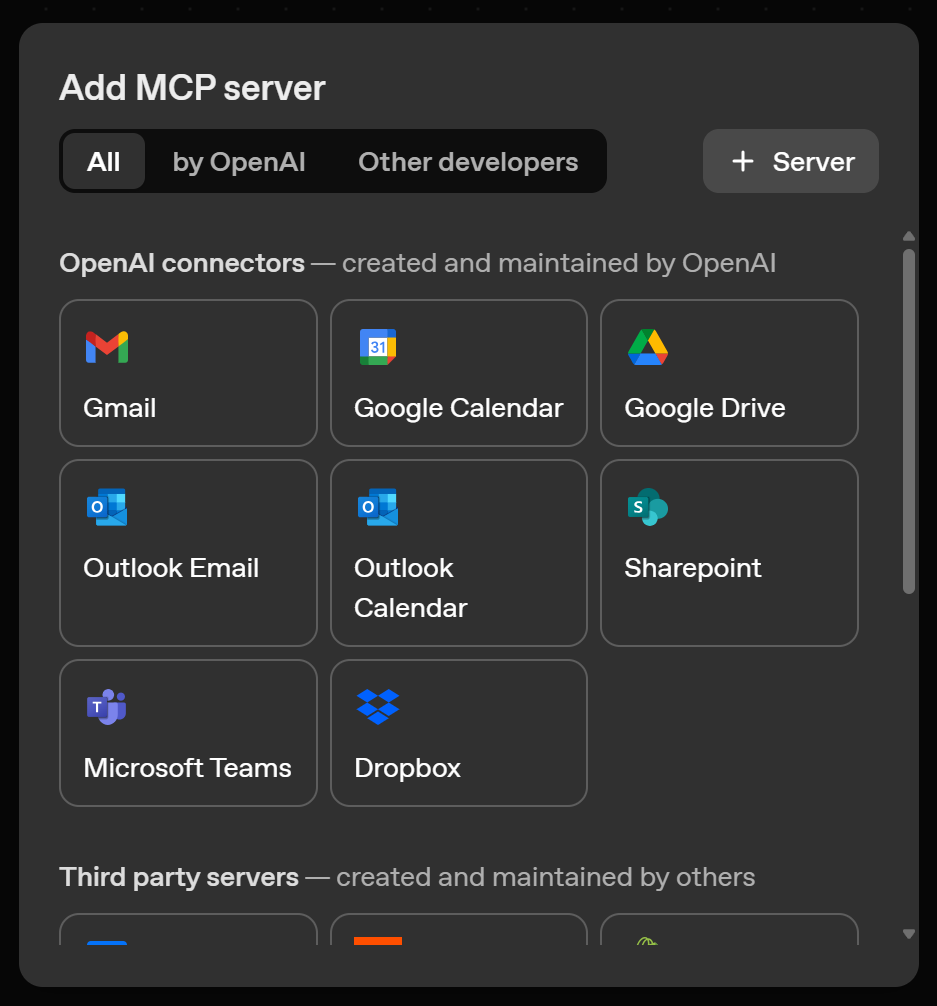
在这里,你可以选择预配置的 MCP 服务器,或自定义连接。要自定义连接,点击 “+ Server” 按钮: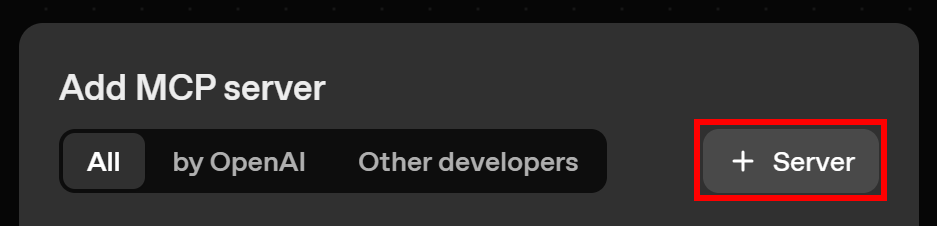
然后按如下方式填写连接 Bright Data Web MCP 的表单:
- URL:
- 用于 免费层集成:
https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_TOKEN> - 用于 Pro 模式:
https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_TOKEN>&pro=1请记得将<YOUR_BRIGHT_DATA_API_TOKEN>替换为你实际的 Bright Data API Key。 注意:以上 URL 连接的是远程 Web MCP 服务器的 Streamable HTTP 版本。若要连接 SSE 版本,请将 URL 中的 “mcp” 替换为 “sse”。 更多信息请 参考官方文档。 同时建议阅读我们关于 SSE vs Streamable HTTP 的对比文章。
- 用于 免费层集成:
- Label:例如 “bright_data_web_mcp”(必须使用 snake_case 格式)。
- Description:例如 “Bright Data Web MCP”。
- Authentication:选择 “None”(因为 URL 中的
token查询参数已完成认证)。
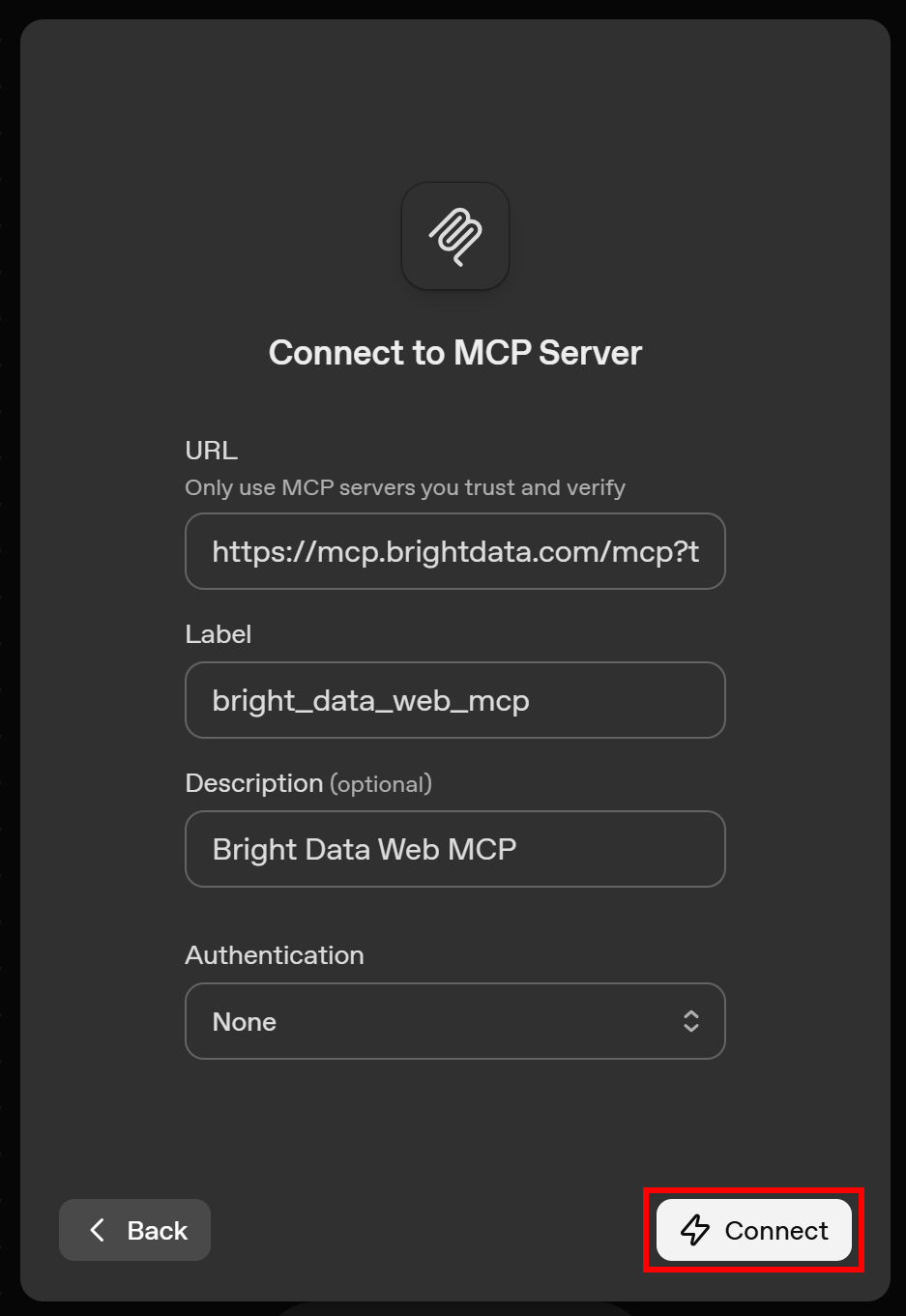
填写完成后,点击 “Connect” 按钮。OpenAI Agent Builder 会在连接 Bright Data Web MCP 远程服务器并验证配置时显示短暂的 “Establishing connection…” 提示。
如果一切正常,你将看到可用工具的摘要。在 Pro 模式(&pro=1)下,应该如下所示: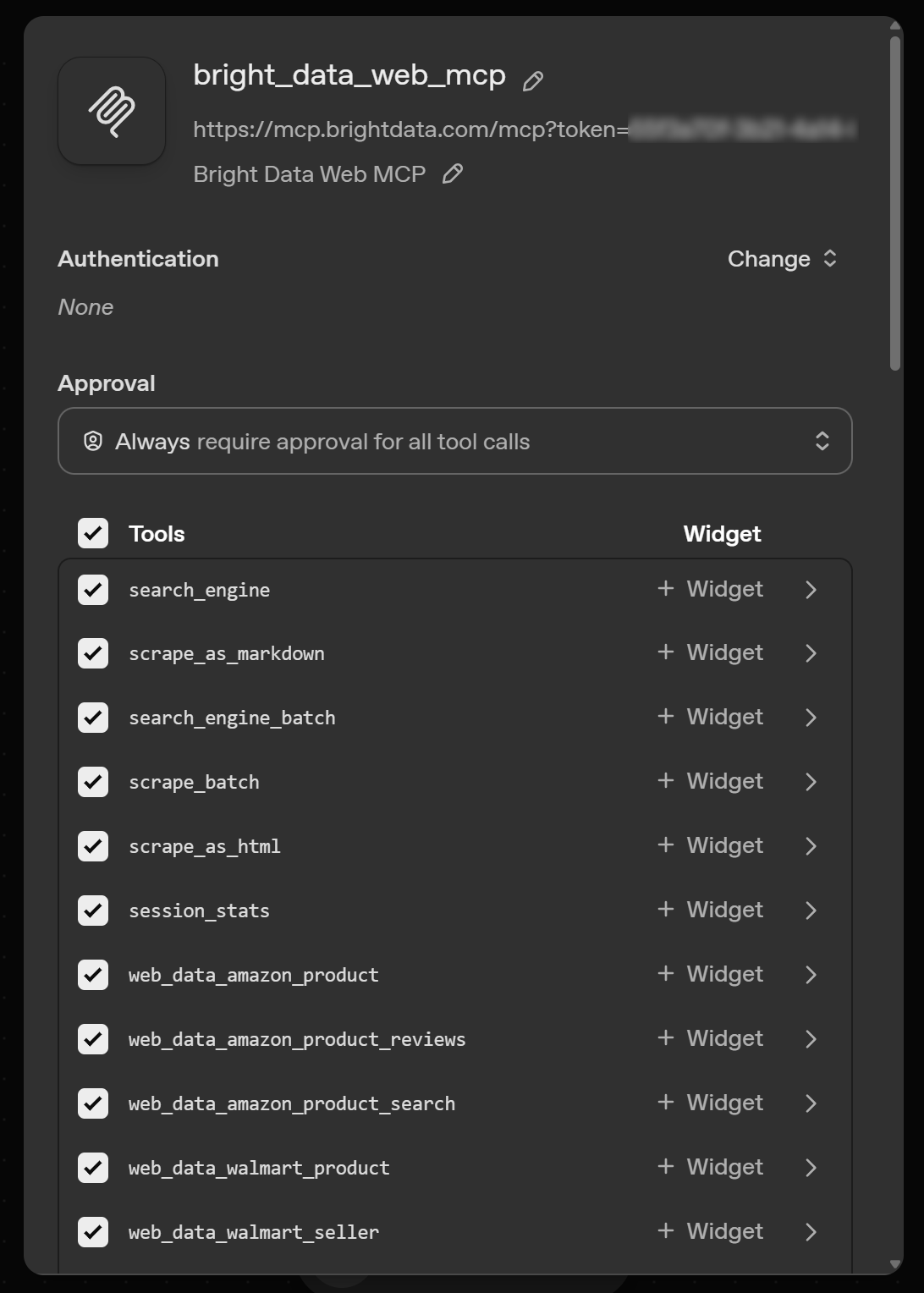
如果你使用的是免费层(Rapid 模式),列表中只会显示可用的 4/5 个工具(即 scrape_as_markdown、search_engine 以及它们的批量版本)。
在该页面中,你可以启用或禁用单个工具,让 Agent 节点只访问你需要的工具。保持全部启用,向下滚动并点击 “Add” 完成集成。
太棒了!你的 Agent 节点现在可以访问 Bright Data Web MCP 服务器的所有工具了。
步骤 #3:配置 Agent 节点
Agent 节点现已连接到 Web MCP 服务器: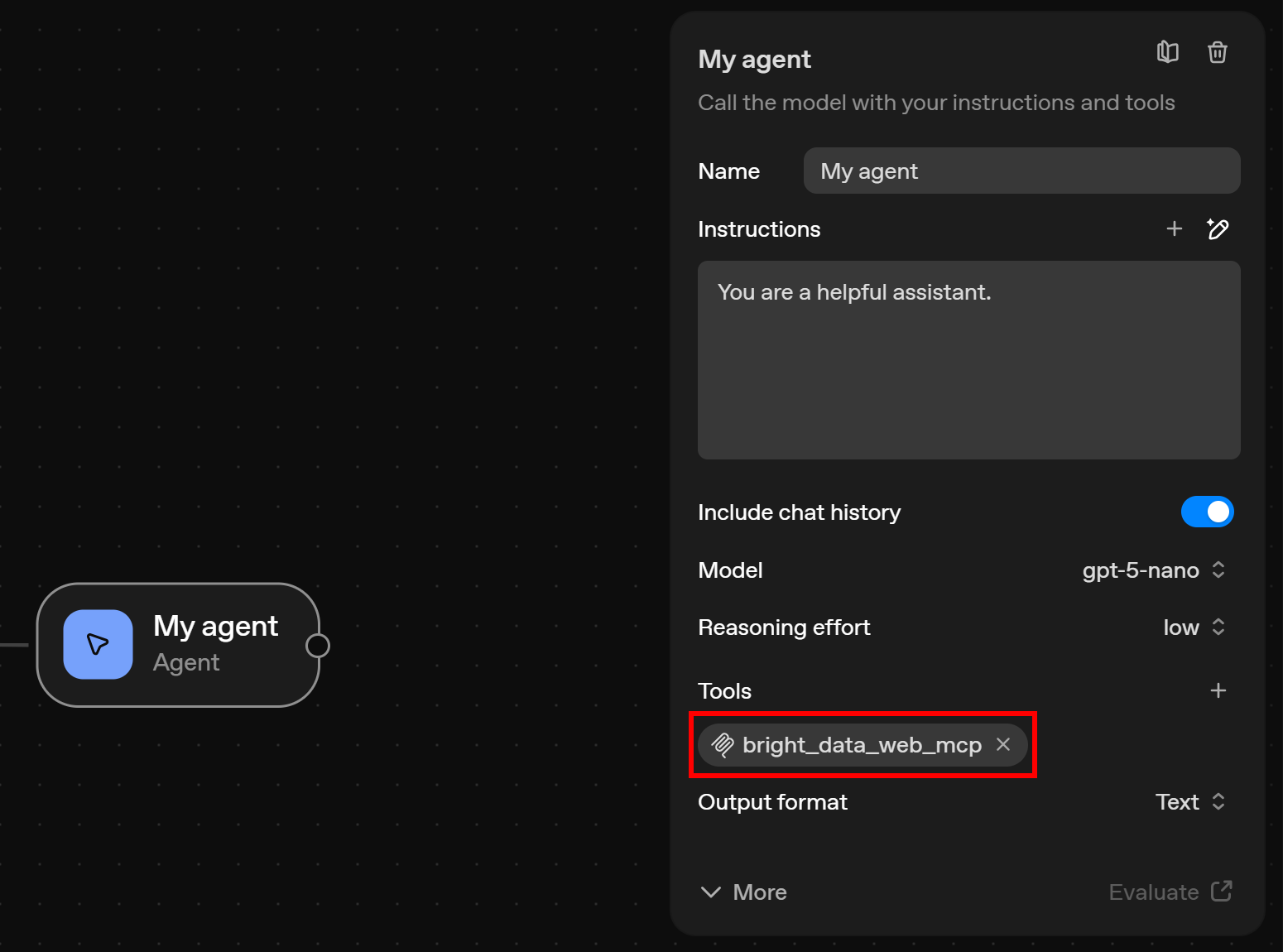
现在也该配置它的其他选项了。在 “My agent” 配置标签页中,将其命名为类似 “Web data agent”,并将描述更新为:
You are an assistant that can search the web, access web data feeds, and scrape or interact with web pages online这很重要,因为它告诉 Agent:它不再是默认的 AI 助手,而是拥有 由 Web MCP 服务器提供的网页数据检索与交互能力。
接下来,选择一个支持工具调用的 GPT 模型。本示例使用 gpt-5-nano, 当然 gpt-5 或 gpt-5-mini 也同样适用。你还可以查看我们基准测试中 GPT-5 模型的对比结果。
你的 Agent 节点最终配置应如下所示: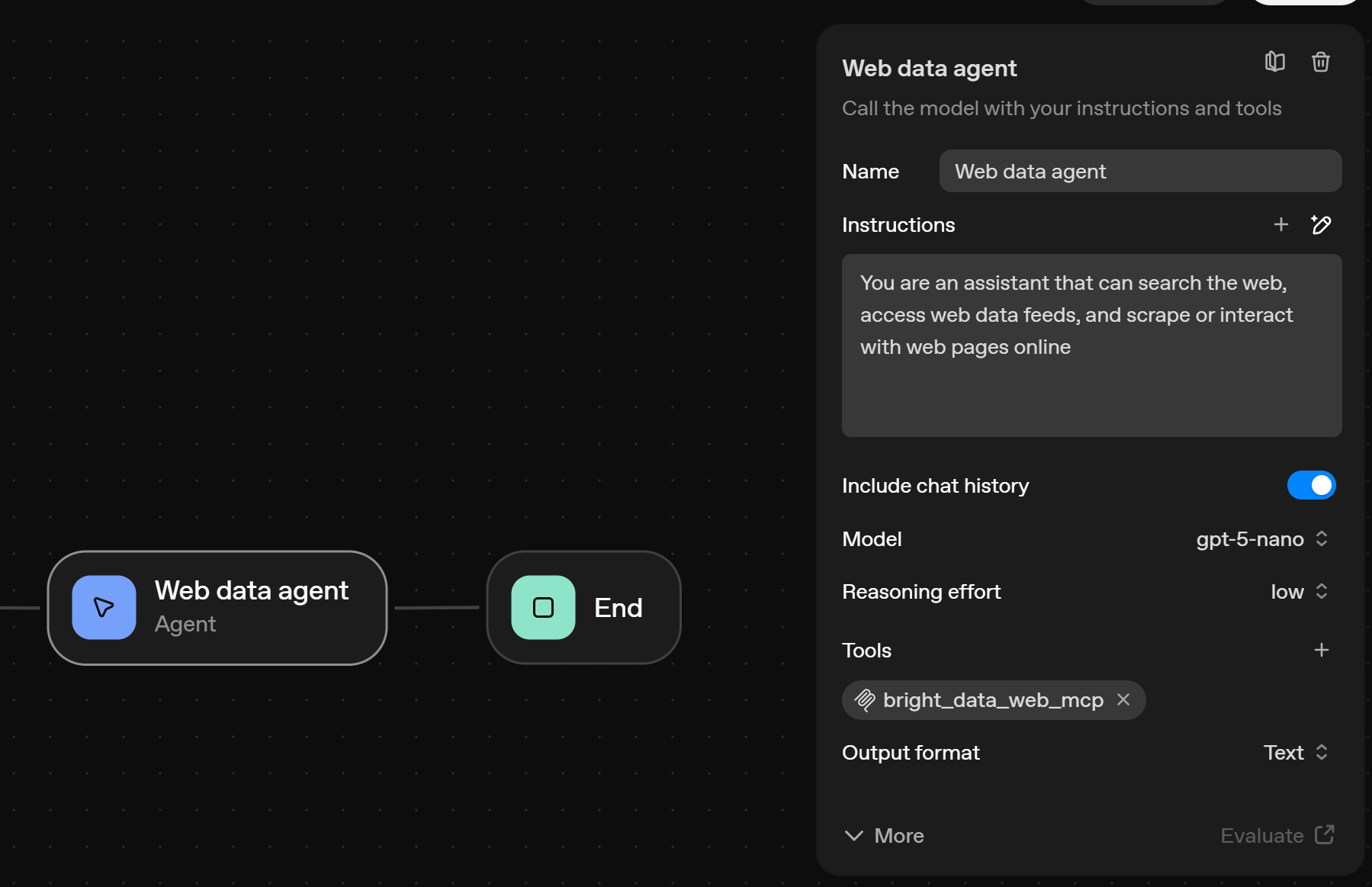
完美!作为该 AI 工作流核心引擎的 Agent 节点,现在已完成所有配置并可直接使用。
步骤 #4:完成工作流
要完成你的 AI 工作流,你必须添加一个 “End” 节点,并将其连接到 Agent 节点(现命名为 “Web Data Agent”)的输出。
最终,你的 AI 工作流应如下所示:
请记住,这只是一个用于演示如何在 OpenAI Agent Builder 中使用 Bright Data Web MCP 的简单示例。但借助 Web MCP 工具,这个基础的 3 节点工作流已经可以 处理多种用例。
同时,真实世界的生产级工作流通常更复杂,往往涉及多个 Agent、多步流程甚至循环。想看一些示例,可以访问我们的 AI Agent Showcase 页面。
关键在于,OpenAI Agent Builder 提供了构建这些高级 AI 工作流所需的一切。因此,请 参考文档以探索所有可用功能。
步骤 #5:测试 AI 工作流
现在只剩下验证所设计的 AI 工作流是否能正常运行。要测试它,点击右上角的 “Preview” 按钮:
这会在右侧打开一个聊天组件,你可以通过它与 AI 工作流交互: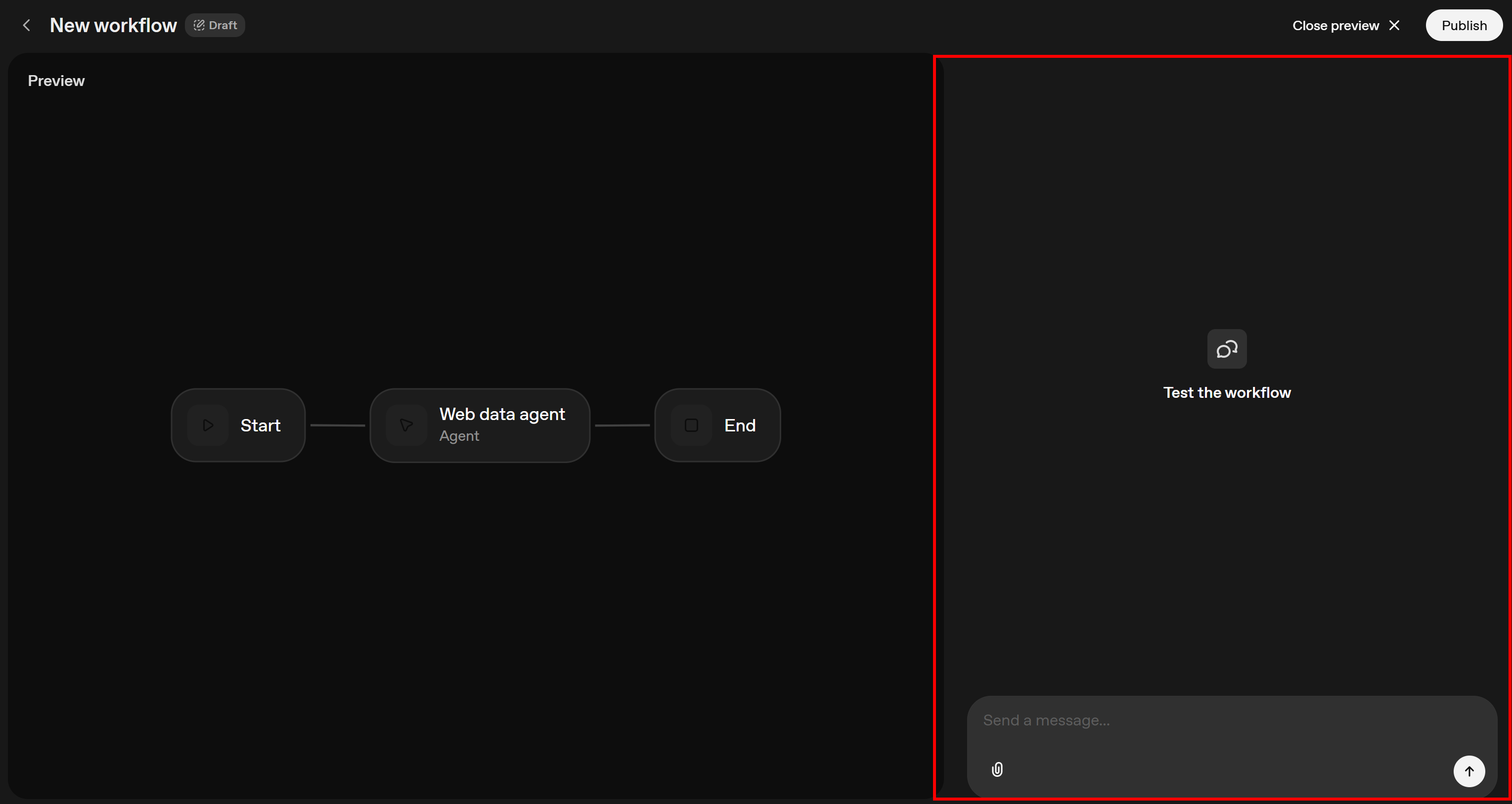
要验证已配置的 Agent 节点能够访问 Bright Data Web MCP 提供的强大工具,你需要提供合适的提示词。例如,若你想测试 Instagram 帖子情感分析工作流,可以输入如下提示:
Retrieve the main data and comments from the following Instagram post:
"https://www.instagram.com/sportscenter/p/DQDjScTDEmQ/"
Then return a Markdown report with the post’s main information and a sentiment analysis of the most relevant comments.假设你已将 Web MCP 远程服务器配置为 Pro 模式。在这种情况下,在 Agent Builder 中执行该提示词将产生类似如下的结果: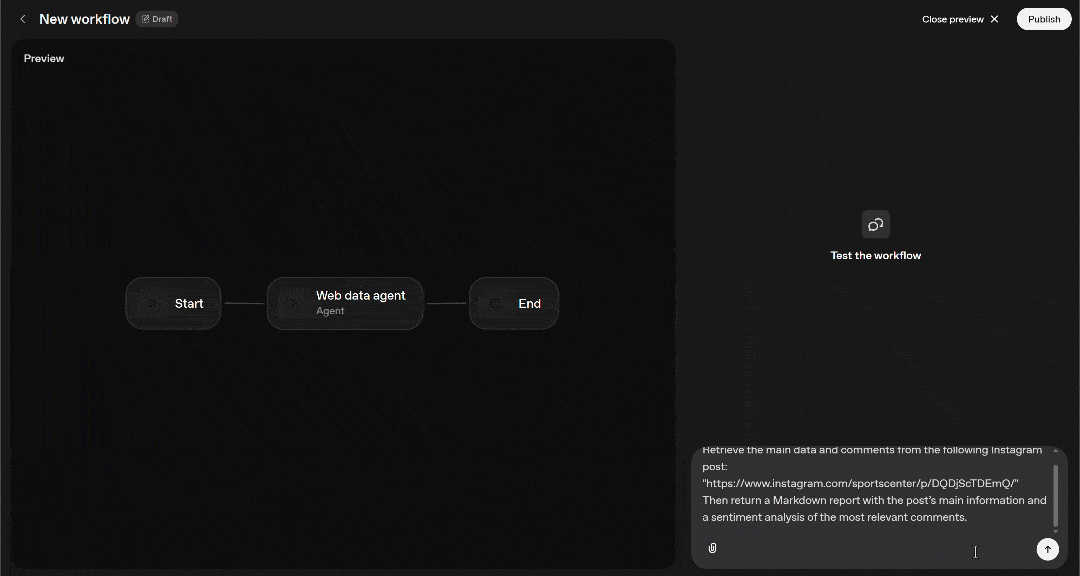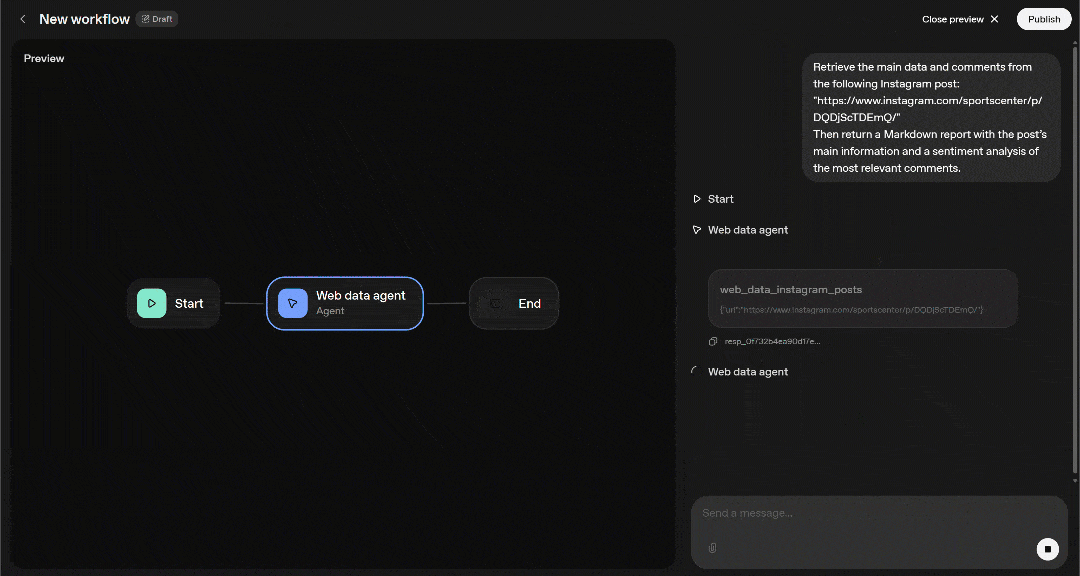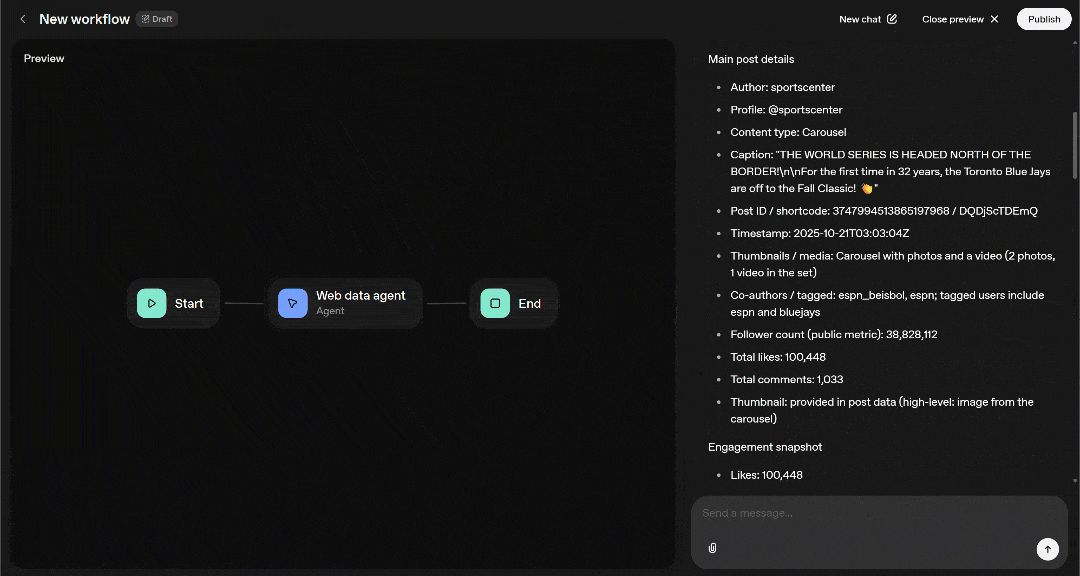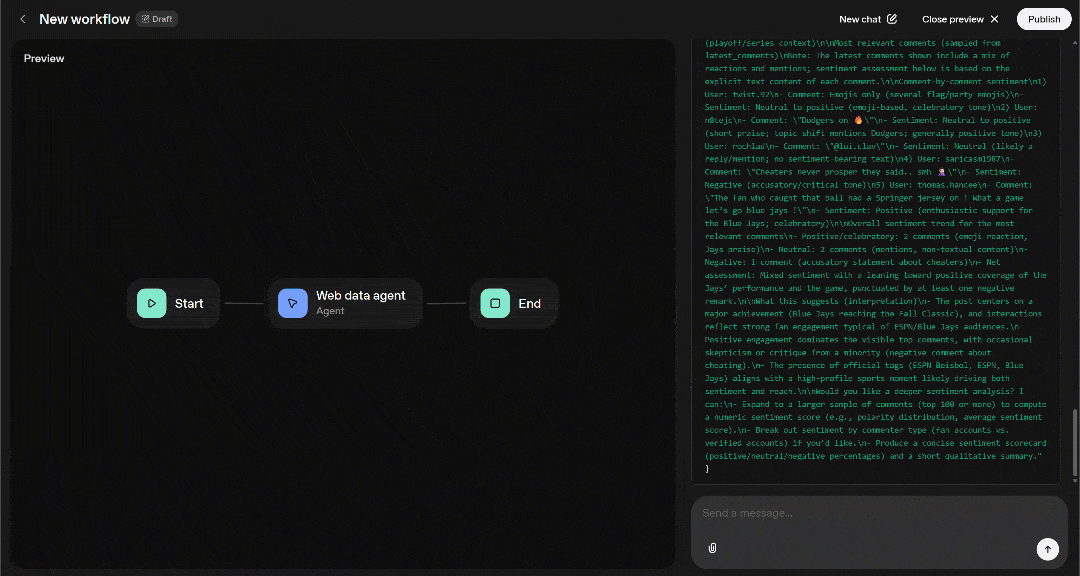
该 GIF 做了加速处理,因此可能不易看清发生了什么。以下编号列表给出完整总结:
- 提示词从 “Start” 节点传递到 “Web Data Agent” 节点。
- “Web Data Agent” 执行提示词,并将其交给已配置的 GPT 模型。
- 模型识别出 Web MCP 中的
web_data_instagram_posts高级工具是完成任务的合适工具。该工具描述为: “快速读取结构化的 Instagram 帖子数据。需要有效的 Instagram URL。这可能是缓存查询,因此比爬虫更可靠。” 因此非常符合目标。(该工具通过连接 Bright Data 的 Instagram Scraper 来工作。) - 该工具以 JSON 格式返回 Instagram 帖子数据,模型对其进行分析。
- 模型生成所需的 Markdown 报告,并在聊天中展示。
由于 Agent 节点被配置为输出文本结果,因此到达 “End” 节点的最终输出应类似如下: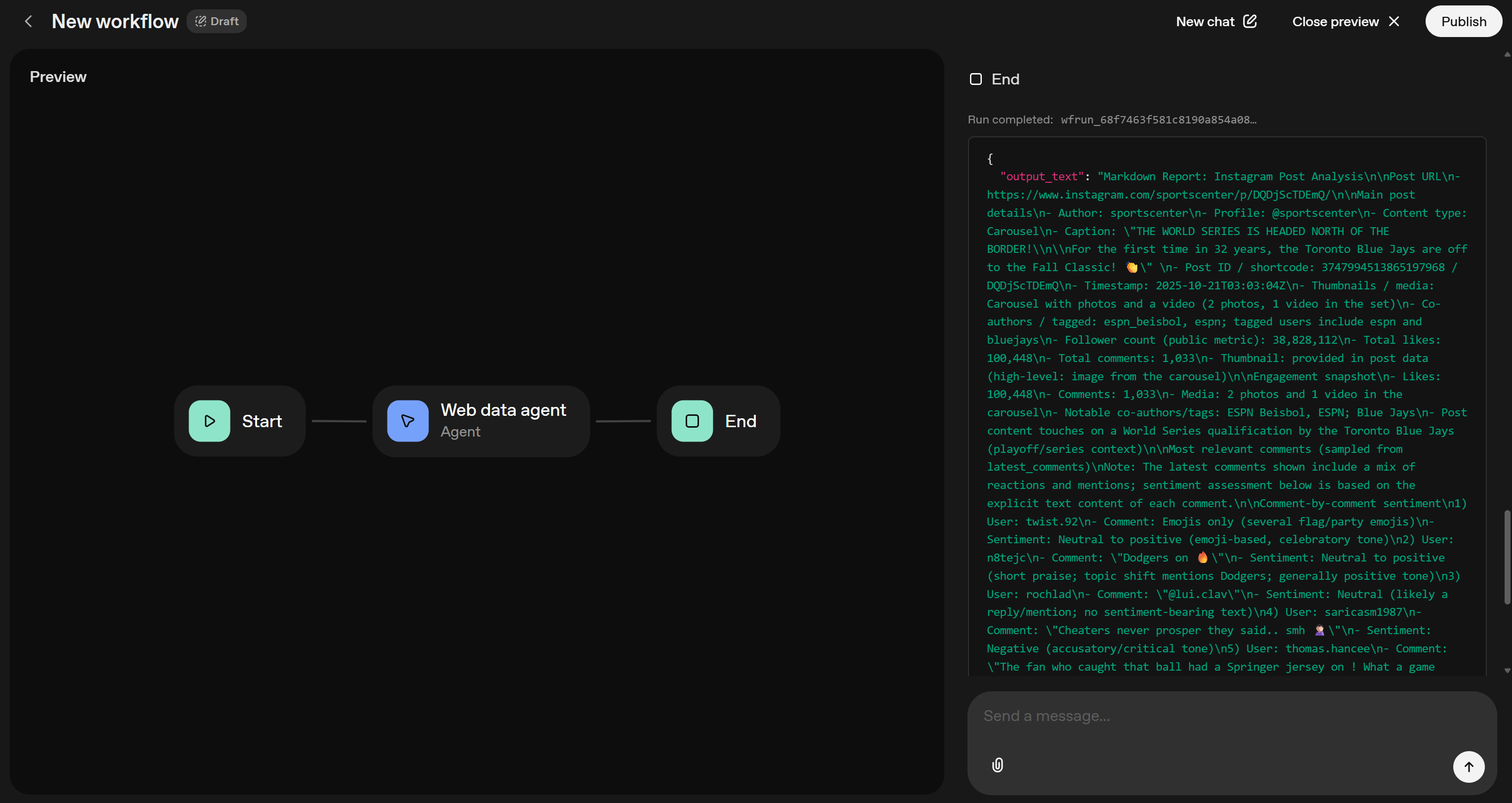
注意 output_text 字段包含 Markdown 字符串形式的输出。将其复制到本地的 report.md 文件中,并用 Visual Studio Code(或任意 Markdown 查看器)查看: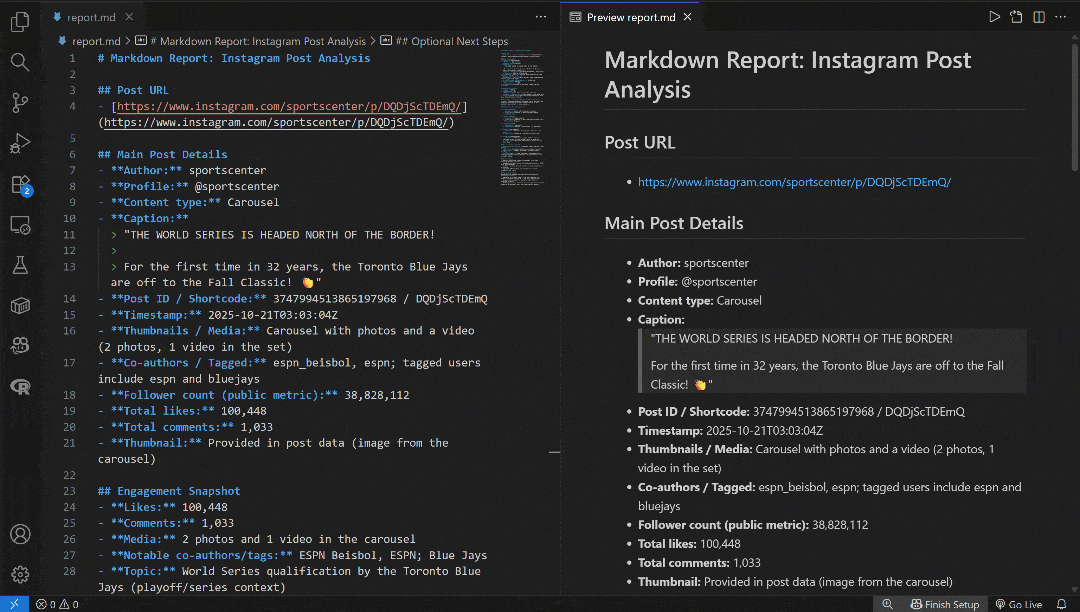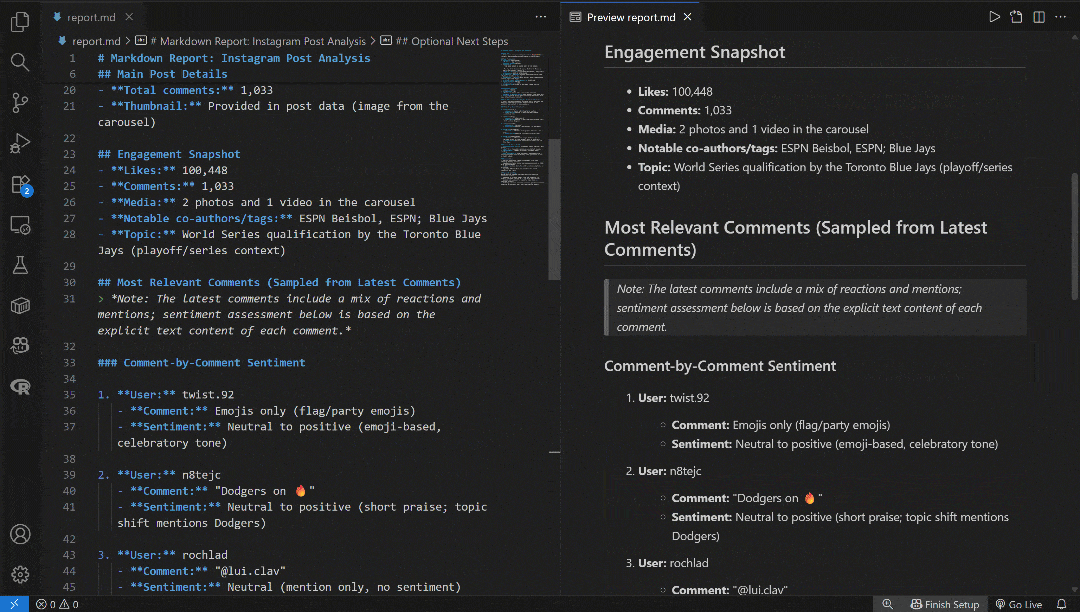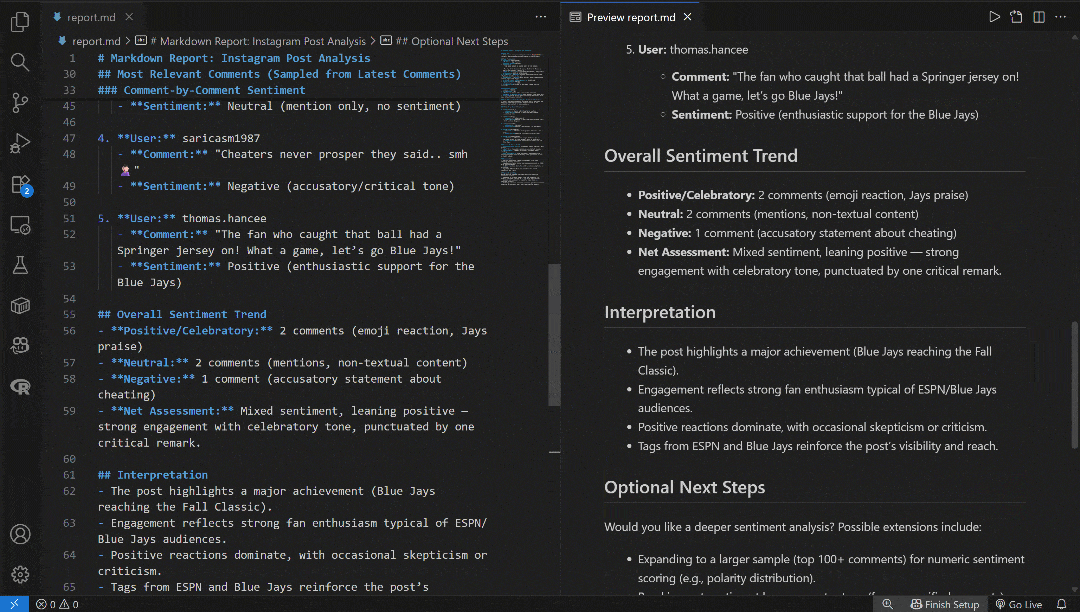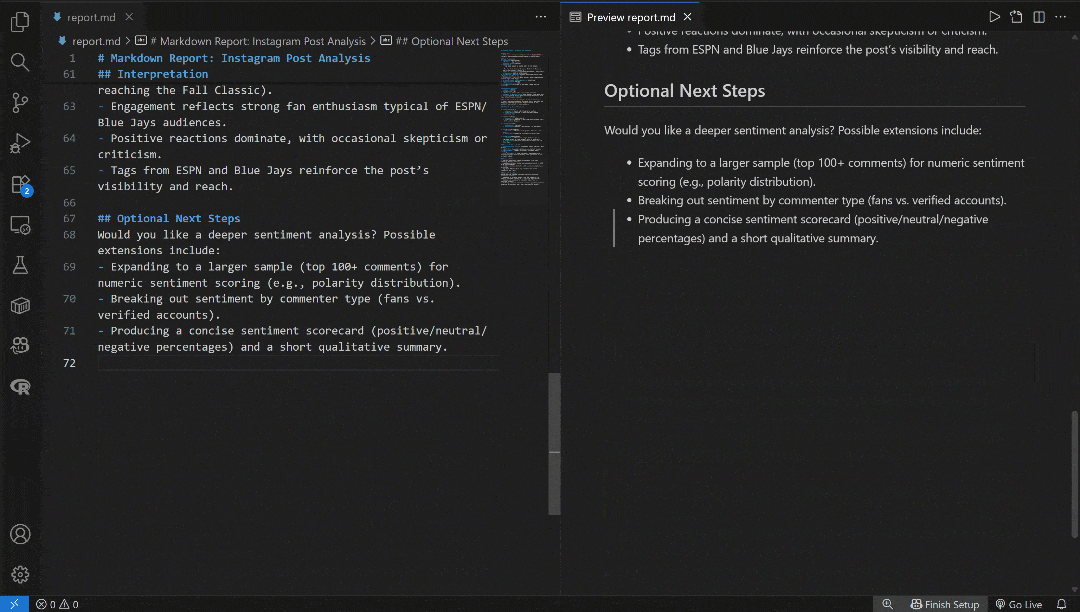
将其与 源 Instagram 帖子 对比,你会发现它包含了所有正确的帖子数据——包括浏览量与评论等指标——以及对最重要评论的情感分析: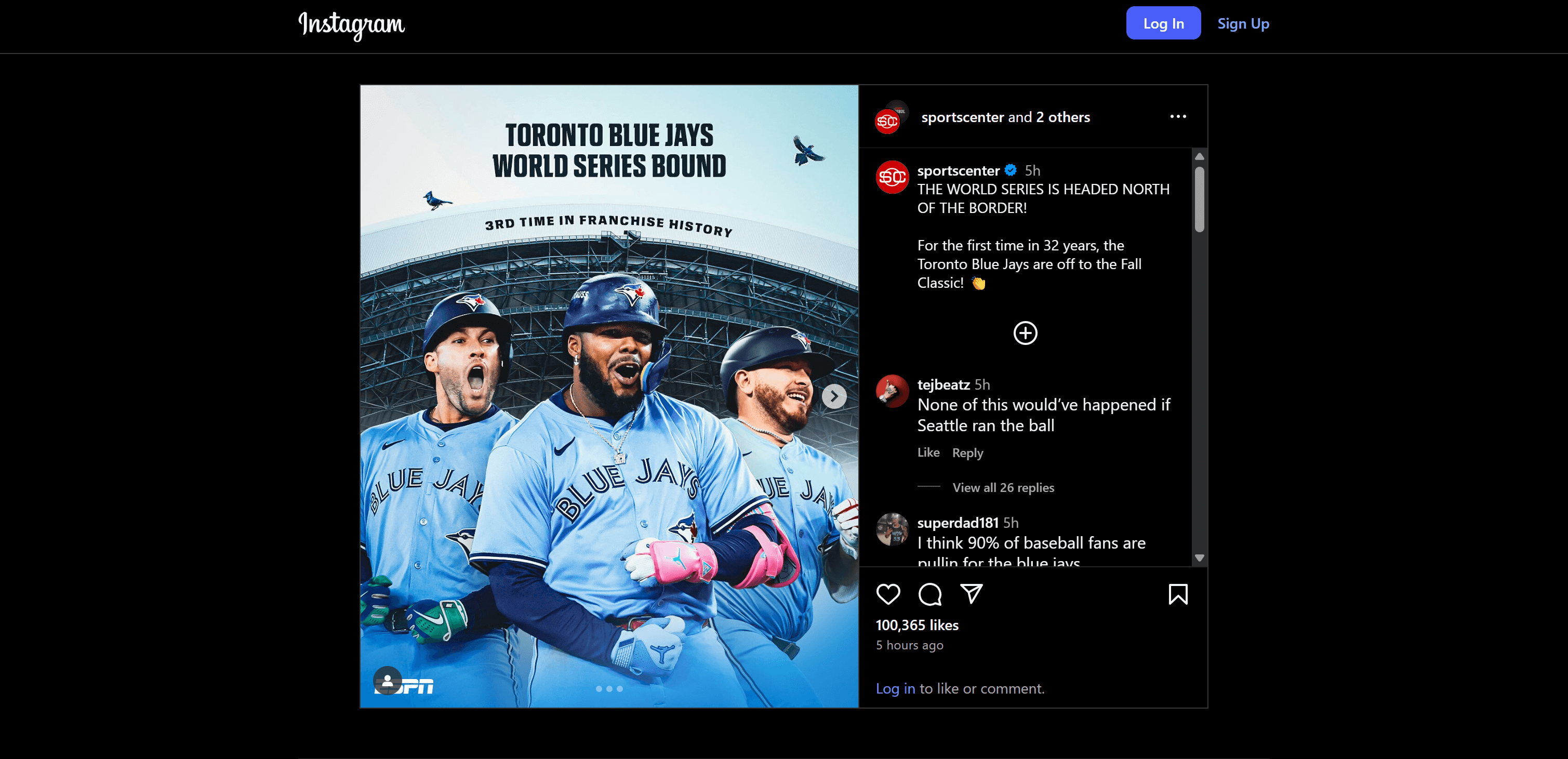
任务完成!
如果你曾尝试爬虫 Instagram,你就会知道这有多么困难。仅凭原生的 GPT-5 模型显然无法完成这些工作,这恰好突显了 Bright Data Web MCP 的强大之处。 该集成让你能够在几秒钟内获取公开 Instagram 帖子以及其他众多平台的 AI-ready 数据。
注意:通过串联提示词,你可以利用全部 60+ 工具测试更多场景。这里仅是一个简单示例!
Voilà!Bright Data Web MCP 在 OpenAI Agent Builder 中的集成表现非常出色,帮助你创建更“有资源”的 AI 工作流。
下一步
要创建工作流的新主版本,点击右上角的 “Publish” 按钮。这会生成一个快照,你可以部署或回滚到该版本。
要进行部署,点击顶部导航中的 “Code”:
你有两种方式 将工作流部署到生产环境:
- ChatKit:提供一个 ID,你可以使用它将该工作流嵌入到你的 ChatKit 应用 中。这是推荐的部署方式。
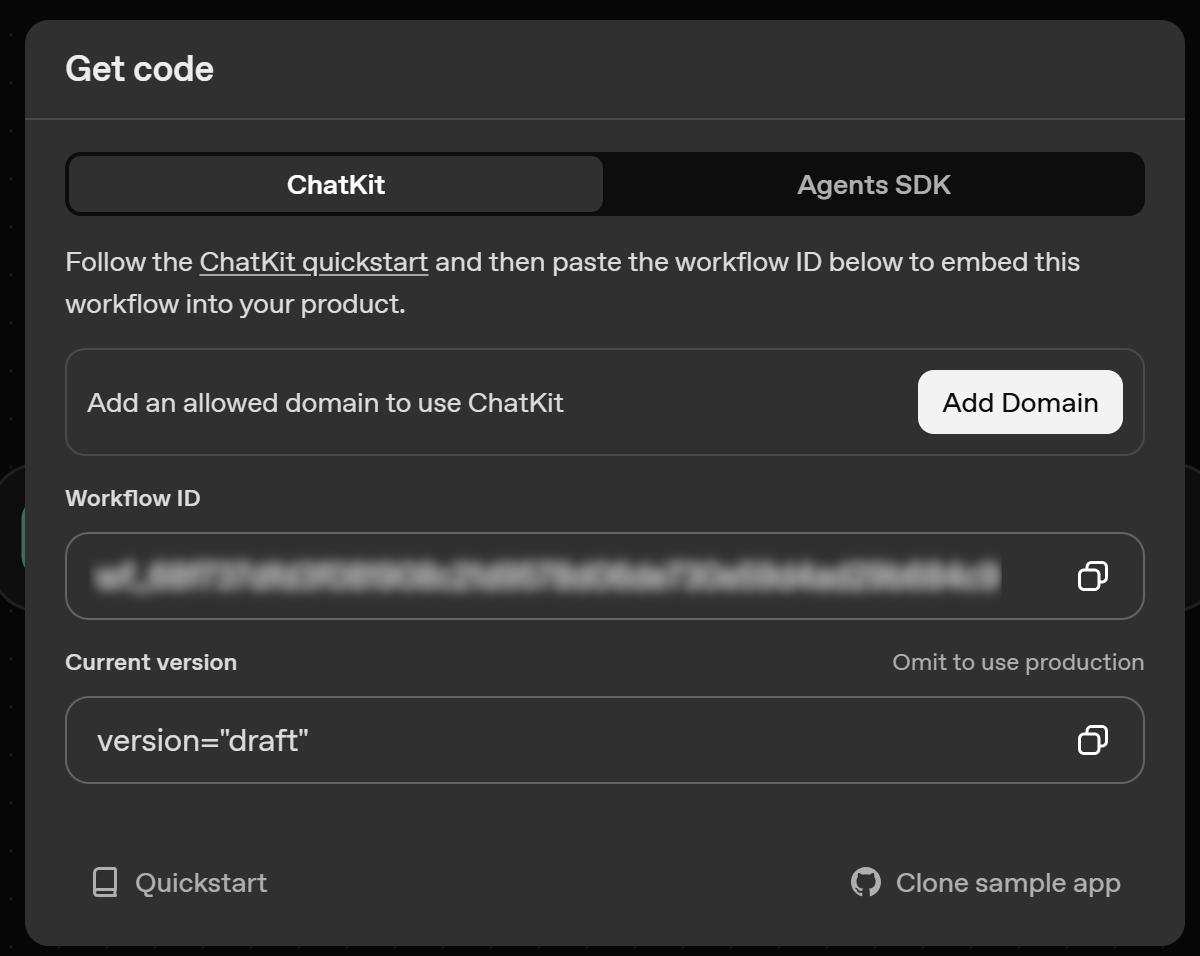
- 高级集成:获取通过 Agents SDK 库生成的工作流代码,用于构建并自定义 Agent 聊天体验。
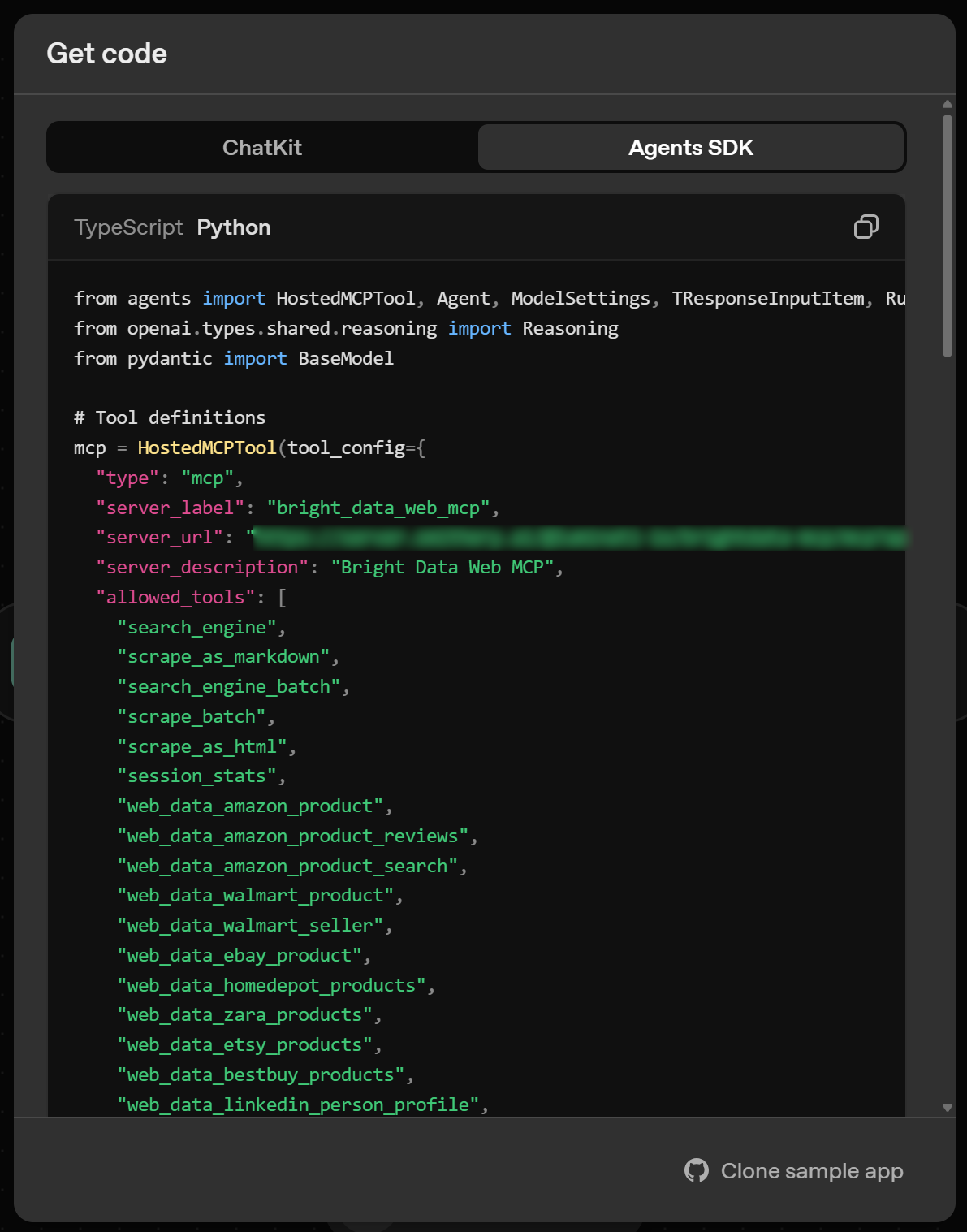
关于 SDK 的更多指导,请参阅我们的教程:“将 OpenAI Agents SDK 与 Web Unlocker 集成以获得高性能。”
结论
在本文中,你学习了如何在 OpenAI Agent Builder 中利用 MCP 集成。具体而言,你看到了如何仅通过在画布上拖拽节点,就能创建一个由 Bright Data Web MCP 工具增强的 AI 工作流。
该集成让 Agent 节点中选定的 GPT 模型能够访问强大的工具,用于网页搜索、结构化数据提取、实时 Web 数据源、自动化 Web 交互等。
要构建更高级的 AI Agent,欢迎探索 Bright Data 生态系统 中完整的 AI-ready 产品与服务。
立即免费注册 Bright Data,并开始试用我们的 Web 数据工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




