
网页抓取是指使用脚本或自动化软件工具从网站提取内容和数据的过程。提取到的信息通常会导出为更有用的格式,比如原始文件或 CSV 文件,以便更轻松地使用。
如果您想简化网页抓取的工作流程,Google 表格可以满足您的需求。它是一个常用的数据管理工具,特别适合从网站抓取结构化或表格数据,以及对数据进行分析或可视化。例如,您可以用它来从电商网站获取商品详情和价格信息,或从商家名录中获取联系方式。同时,它也可用于追踪社交媒体参与度,或做公共舆情分析来衡量活动效果。
在本教程中,您将学习如何设置并使用 Google 表格来进行网页抓取。
设置您的 Google 表格
要使用 Google 表格进行网页抓取,您需要先创建一个新的 Google 表格。为此,请访问 https://sheets.google.com 并点击+按钮:
本教程将演示如何从 Books to Scrape 网站抓取书籍价格信息,但您可以通过更改以下 URL 和查询来使用其他网站。
了解 Google 表格公式
Google 表格支持大量单元格公式,可用于多种操作,包括网页抓取。让我们来看看其中一些公式的工作原理。
IMPORTXML
IMPORTXML 函数可以让您查询并将结构化数据导入 Google 表格。它支持 XML、HTML、CSV 和 TSV 文件格式。该函数的语法如下:
=IMPORTXML(url, xpath_query)该函数会从指定的网页 URL 获取数据,并使用 XPath 定位来查找网页上相关的元素。例如,您可以通过在 Google 表格单元格中添加以下公式,从 Books to Scrape 网站获取 H1 标题:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")初次使用时,Google 表格会提示您启用对第三方网站的数据访问权限:

点击允许访问(Allow access)后,Google 表格会将单元格的值解析成网页的 H1 标题,此处为 Default。
IMPORTHTML
IMPORTHTML 函数可以让您从 HTML 页面上的表格或列表中导入数据。该函数的语法如下:
=IMPORTHTML(url, query, index)此函数会根据指定的 query 属性,从 url 中导入数据。query 属性可以设为 list 或 table,取决于您要导入的数据类型。index 从 1 开始,决定要导入哪一个表或列表。例如,您可以使用以下公式从 Books to Scrape 获取书籍列表:
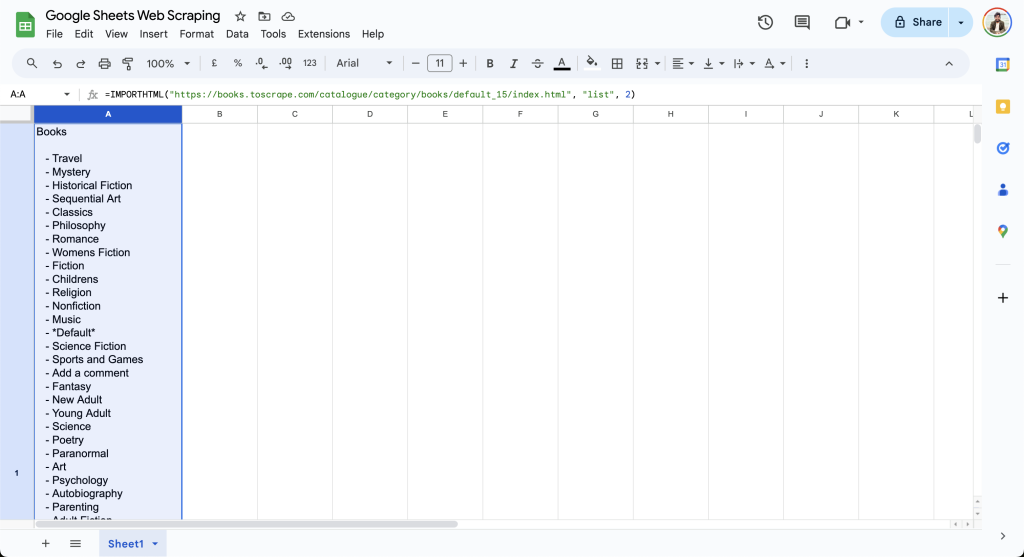
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)此公式会在当前单元格输出书籍列表,如下所示:
可以看到,IMPORTXML 和 IMPORTHTML 这两个公式的用法非常简单,可通过少量查询即可开始从网页抓取数据。对于更复杂的使用场景,您可以参阅这篇指南,了解如何在 Excel 中使用 VBA 和 Selenium 进行网页抓取。
使用 IMPORTXML 提取数据
在上一节中,您了解了 IMPORTXML 的基本用法,通过指定相关的 XPath 属性来获取网页标题。XPath 非常强大,允许您在不考虑页面层级结构的情况下定位到任何网页元素。本节中,您将使用 IMPORTXML 抓取 Books to Scrape 网页上所有书籍的标题、价格和评分。
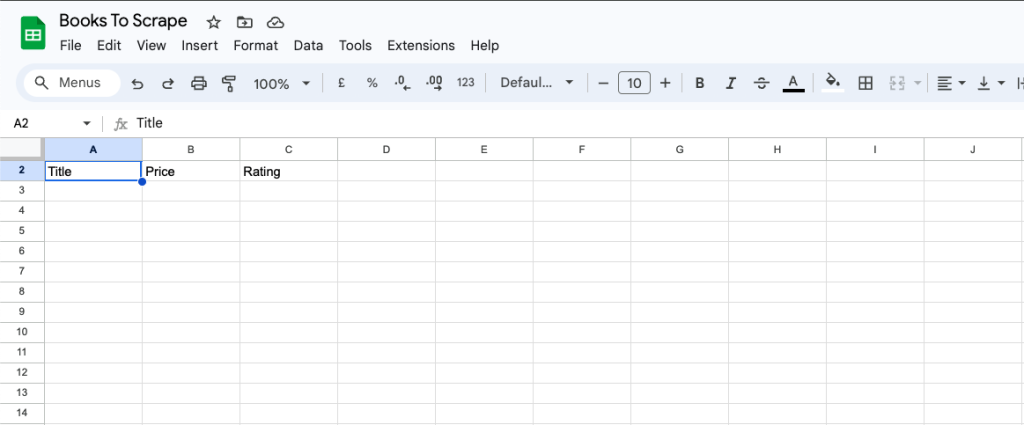
首先,在 Google 表格中添加 Title、Price 和 Rating 列:
要从 Books to Scrape 获取书籍标题,您需要其在网页中的 XPath 定位,可使用浏览器的检查(Inspect)工具来找到。右键单击第一个书名并选择 Inspect,然后在出现的元素上点击 Copy > XPath 来复制该元素的 XPath:
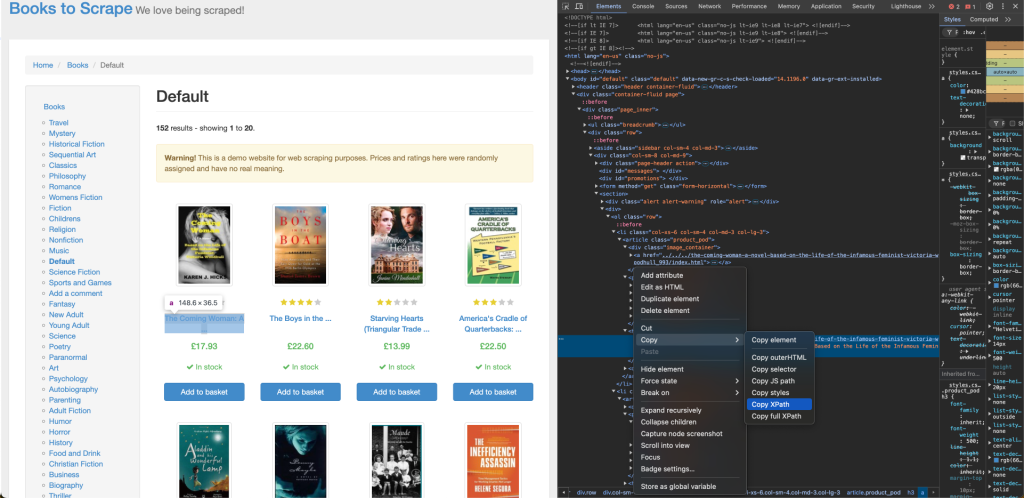
第一个书名的 XPath 对应到一个 a 标签,类似如下所示:
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a您需要对 XPath 做一些调整,以确保能够正确导入列表中的所有书名:
- XPath 中包含
li[1],表示只定位到第一个书籍。将其改为li,即可定位到所有相关元素。 a标签内的文本是截断的书名,而a标签包含一个title属性,其中有完整的书名。将a改为a/@title即可使用该属性。- 将 XPath 中的双引号替换为单引号,以避免在公式中转义出现问题。
完成调整后,您可以在 Google 表格的 A2 单元格中添加以下公式:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")随后,表格会从网页导入数据并更新行,如下所示:
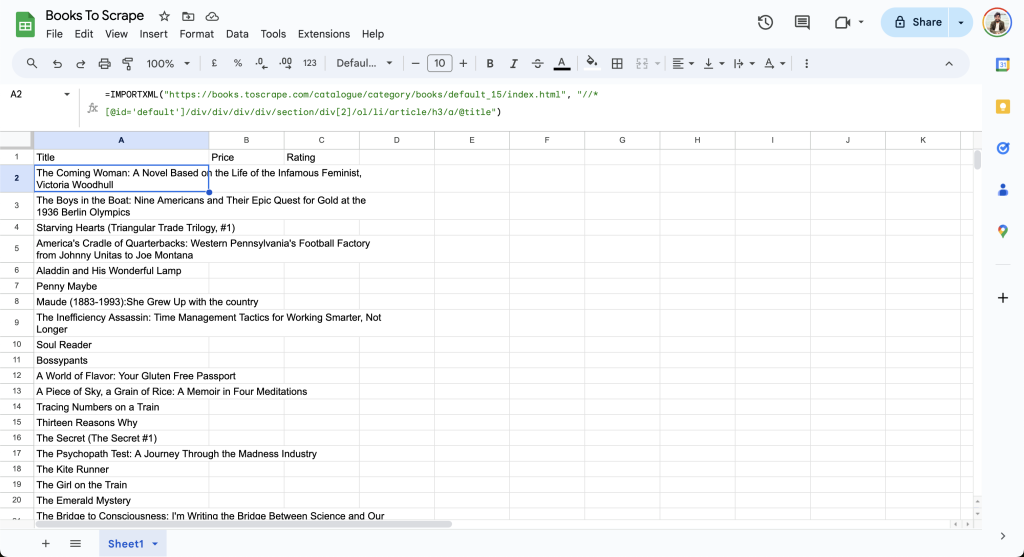
接下来,构造价格的 XPath 并在表格的 B2 单元格中添加:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")最后,找到评分的 XPath,并添加到表格的 C2 单元格:
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")最终表格中的数据如下所示:
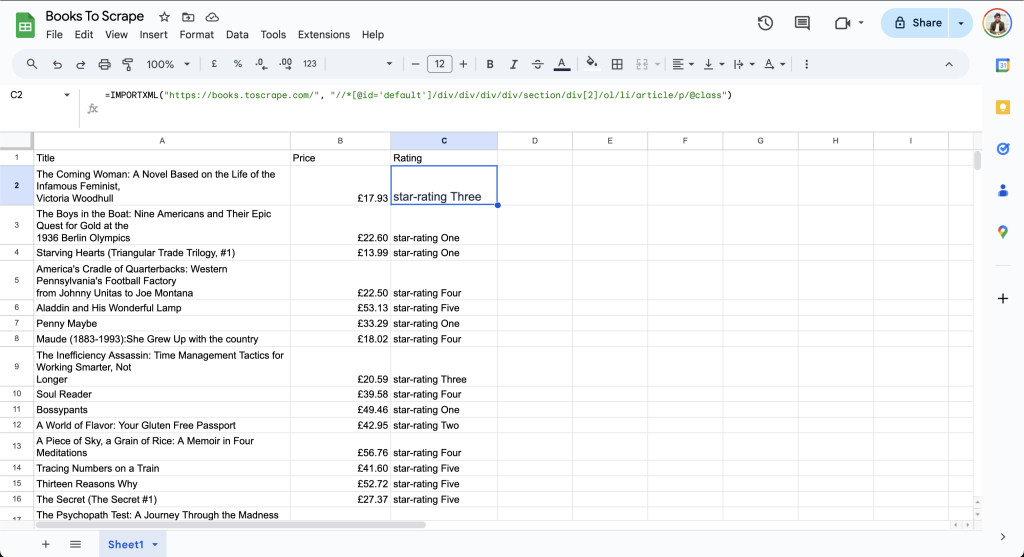
可以看出,Rating 列显示的是 star-rating Three 或 star-rating Four。由于 Google 表格还不支持 XPath 2.0,因此无法在导入时对数据进行进一步简化。
应对复杂网页
虽然 Google 表格非常适合简单的抓取任务,但如果目标网站包含动态内容和分页,或需要点击等交互,那么抓取就会变得更具挑战性。例如,如果网页使用 JavaScript 异步加载内容,Google 表格里的 IMPORTXML 和 IMPORTHTML 无法抓取这些数据,因为它们只能处理静态网页。同样,如果内容需要用户点击、输入或滚动才能呈现,这些公式也无法实现抓取。如果您需要抓取动态内容,可以编写一个使用 Selenium 这类无头浏览器(headless browser)的脚本。
另外,Google 表格也无法自动处理分页抓取。虽然您可以手动在最后一行后添加 IMPORTXML 公式并更新 URL,但这种方法不具备可扩展性,需要对每个页面重复此过程。
如果您需要处理更高级的应用场景,例如动态内容或大规模的数据抓取,建议使用 Bright Data 的产品来高效完成数据提取。Bright Data 提供统一的 Web Scraping API,可针对各种数据提取任务,并在底层处理代理、CAPTCHA 和用户代理(user agent)等问题。其 API 能够处理大批量请求、解析和验证,让您可以更快地部署并扩展。此外,Bright Data 还提供大量现成的数据集,涵盖热门网站如LinkedIn、Zillow 等,可轻松与您现有的工作流程集成,大大减少维护抓取脚本的难度。
在 Google 表格中自动刷新数据
对于一些抓取任务,比如价格监测或社交媒体参与度追踪,需要定期自动刷新抓取的数据,以确保您获取的都是最新信息,用于分析和决策。
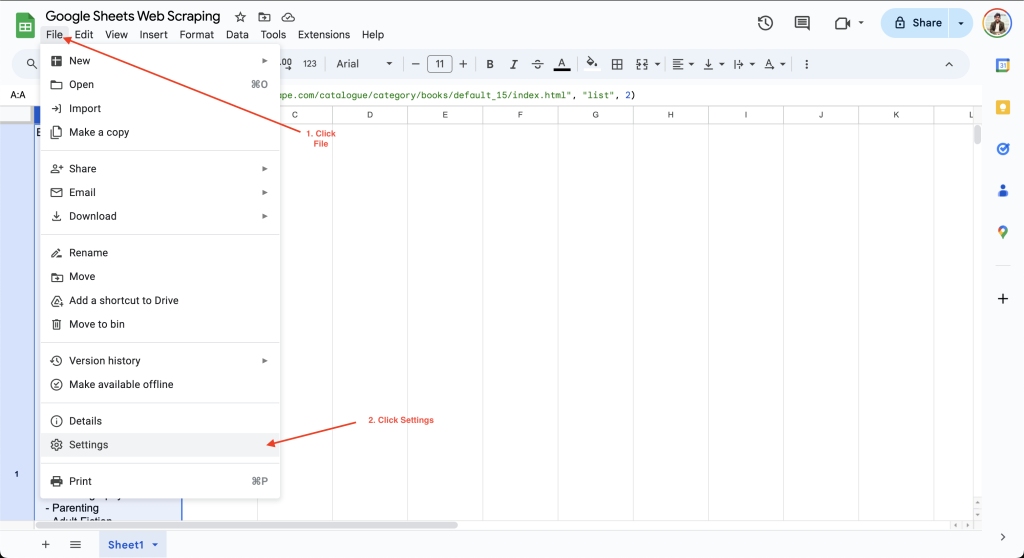
要在 Google 表格中设置计算间隔,只需点击 文件(File) > 设置(Settings),并在计算(Calculation)标签下进行配置:
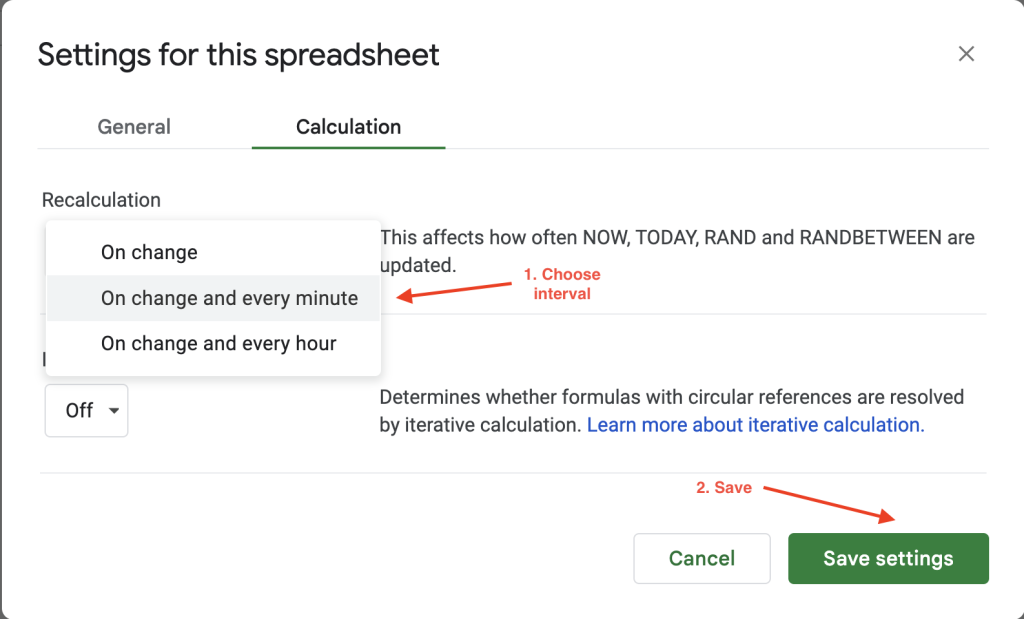
然后您可以将计算间隔设置为每分钟或每小时。例如,这里将重新计算(Recalculation)设置改为有变动时及每分钟,以便每分钟自动刷新数据:
需要注意的是,Google 表格自动刷新功能的灵活性有限,只能在每分钟或每小时之间选择。如果您需要更灵活的刷新频率,Bright Data 提供清洗、验证并保持实时更新的数据集,支持多种文件格式(JSON、CSV、Parquet 等),非常适合大规模抓取需求,避免自行维护庞大的抓取基础设施。
实施最佳实践与故障排查
如果您想提高抓取效率,请务必只提取所需的数据。尝试抓取不必要的数据会减慢抓取速度,并增加目标网站的负载。
如果想要抓取大量数据,可以在请求之间添加人工延时,并考虑在非高峰时段运行任务,以免给目标网站带来过大流量压力。过大的流量可能导致 IP 被封禁或速率限制,从而阻止您继续抓取。可参阅如何在抓取时避免被封禁。
除了 IP 封禁之外,显示 CAPTCHA 验证也是网站常用的一种反爬虫技术,在用户验证为真人之前禁止访问内容。若要针对更高级的抓取场景,您可以使用Bright Data 的住宅代理(Residential Proxies)来进行 IP 轮换并自动处理 CAPTCHA。
在抓取任何数据之前,您同样需要查看目标网站的服务条款,以确保合规。您的脚本应该遵守该网站的 robot.txt 设置,了解更多可参阅这篇文章来学习如何使用 robot.txt 规则进行网页抓取。
总结
对于不涉及动态内容、隐藏元素或分页的静态网站,Google 表格是非常理想的数据抓取解决方案。本文中,您学习了如何使用 IMPORTXML 和 IMPORTHTML 这类简单的公式来轻松自动化数据提取,而无需具备任何编程背景。
对于涉及动态内容或海量数据等复杂抓取任务,Bright Data 提供易用、灵活、可扩展并且高性能的 API,可将数据以 JSON、CSV 或 NDJSON 等多种格式输出。在底层,它替您处理代理和用户代理轮换,以及 CAPTCHA 和动态内容,让您无需操心抓取的诸多复杂细节。如果您想让网页抓取更进一步,可考虑尝试 高效的 Web Scraper API。
现在就注册免费试用,开始优化您的数据工作流程吧!







