

在本文中,你将了解:
- 什么是 Apache Spark Structured Streaming,以及它提供了什么。
- 为什么将 Bright Data 的搜索引擎 API 集成到 Spark Structured Streaming 管道中是一种制胜策略。
- 如何构建一个 PySpark 管道,使用 Bright Data 的搜索引擎 API 持续摄取实时网页搜索数据。
让我们开始吧!
什么是 Apache Spark Structured Streaming?
Apache Spark Structured Streaming 是一个构建在 Spark SQL 引擎之上的可扩展、容错的流处理引擎。与较旧的 Spark Streaming 库不同(它使用 DStreams 将数据划分为基于 RDD 的离散微批次),Structured Streaming 将实时数据流视为一个持续追加的无界表。你编写的 DataFrame 和 SQL API 代码与静态批处理作业中编写的代码相同,而 Spark 会在新数据到达时负责以增量方式运行它。
该引擎默认采用微批次执行模型。在每个触发间隔,Spark 从源读取最新数据,对其进行处理,并将结果写入接收端。它通过检查点跟踪进度,因此管道可以从故障中恢复,并准确地从中断处继续,从而提供端到端的容错保证。
Structured Streaming 支持多种内置源:Kafka 主题、Delta 表、通过 Auto Loader 的云对象存储、速率生成器(用于测试)等等。对于未被原生覆盖的源(例如 REST API),你可以使用 foreachBatch 扩展方法,它会将每个微批次交给一个 Python 函数,你可以在其中表达任意摄取逻辑。这就是我们将在这里使用的方法。
Spark Streaming 与 Spark Structured Streaming:有什么区别?
如果你熟悉传统的 Spark Streaming 库,你可能想知道它与 Structured Streaming 有什么关系。两者共享相同的底层 Spark 引擎,但在重要方面有所不同:
Spark Streaming 基于 DStreams,它是通过将传入流划分为有时间边界的批次而生成的一系列 RDD。所有转换都在 RDD 上运行,这意味着你使用的是更底层的 API。它对事件时间语义的支持有限(即按数据生成的时间而不是摄取的时间对数据排序),并且已不再积极开发。
Spark Structured Streaming 构建在 DataFrame 和 数据集 API 之上,使你能够访问完整的 Spark SQL 优化器。它提供原生事件时间窗口、水印以处理延迟数据、有状态聚合,以及通过检查点实现的更清晰的容错模型。由于它使用与批处理 DataFrame 相同的 API,你可以在同一个作业中混合流式和静态数据(例如,将流与静态查找表进行连接)。
简而言之,Spark Streaming 是一个为向后兼容而保留的传统项目,而 Structured Streaming 则是积极开发中、推荐用于所有新流式工作负载的引擎。
为什么要将 Bright Data 的搜索引擎 API 集成到 Spark Structured Streaming 中?
Spark Structured Streaming 为大规模转换和聚合数据提供了强大的引擎,但它需要一个可靠、结构化的实时网页数据源来发挥作用。这正是 Bright Data 的搜索引擎 API 发挥作用的地方。
搜索引擎 API 允许你以编程方式向主流搜索引擎(包括 Google、Bing、DuckDuckGo、Yandex 等)发出查询,并在不被阻止的情况下检索完整的搜索引擎结果页面(SERP)。结果以多种格式返回:解析后的 JSON、仅包含顶部自然结果的轻量级 parsed_light 变体、原始 HTML,或适合 AI 的干净 Markdown。由于直接抓取搜索引擎因反机器人措施、速率限制和动态渲染而出了名地困难,通过 Bright Data 的基础设施路由你的查询可以将所有这些复杂性从你的管道中移除。
将其与 Spark Structured Streaming 的微批次引擎结合起来,就创建了一个持续运行的管道,该管道会定期拉取最新的 SERP 数据,大规模应用转换和聚合,并将结构化结果写入你选择的任何接收端,而无需你管理代理、验证码破解或爬虫基础设施。
这种方法尤其适用于:
- 定期监控一组目标关键词在各搜索引擎中的排名,将结果写入 Delta 表,并计算随时间变化的排名变化。
- 持续获取竞争对手品牌名称或产品的 SERP,解析结构化结果,并将其流式传输到数据仓库以用于控制面板展示。
- 在并行微批次中轮询多个主题的 Google News 搜索结果,使用 Spark 的有状态聚合对文章去重,并将整理后的结果写入数据湖。
- 持续摄取 SERP 结果,以检测你的目标关键词何时出现付费广告,捕获广告文案和 URL,并向下游系统发出警报。
通过将 Spark Structured Streaming 的分布式、可扩展处理能力与 Bright Data 的面向 AI 和数据管道的网页访问基础设施相结合,你可以构建能够持续响应真实世界搜索数据的管道,而无需维护任何你自己的抓取基础设施。
如何使用 Spark Structured Streaming 构建持续的 SERP 摄取管道
在本节指导中,你将构建一个 PySpark 管道,它将:
- 使用 Spark 内置的速率源作为时钟,按计划触发。
- 在每个微批次中,在
foreachBatch函数内部调用 Bright Data 的搜索引擎 API,以获取目标主题的实时 Google News 结果。 - 解析并转换结构化 JSON 响应为干净的 Spark DataFrame。
- 将结果写入接收端(本地 JSON 输出目录和控制台),以便你检查实时数据。
注意: 此示例演示了一个新闻监控用例,但相同的模式适用于任何持续 SERP 摄取场景:关键词排名跟踪、广告监控、通过网页搜索进行价格比较等等。
前提条件
要跟着操作,请确保你具备:
- 已安装 Python 3.8+。
- 已在本地安装 Apache Spark 3.3+,或可访问 Databricks / AWS EMR / Google Dataproc 集群。
- 已安装 PySpark:
pip install pyspark。 - 已安装
requests库:pip install requests。 - 一个拥有活动搜索引擎 API 区域和 API 密钥(具有 Admin 权限)的 Bright Data 账户。
按照Bright Data 官方文档设置你的搜索引擎 API 区域并获取你的 API 密钥。将你的 API 密钥和区域名称都安全地存储在某处;你很快就会用到它们。
第 1 步:设置你的项目
创建一个新的项目目录,并设置你需要的文件:
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpoint打开 config.py 并添加你的 Bright Data 凭据和搜索配置:
# config.py
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
SERP_API_ZONE = "YOUR_SERP_API_ZONE"
# The search query to monitor (customize this for your use case)
SEARCH_QUERY = "artificial intelligence news"
# How often to trigger a new micro-batch (in seconds)
TRIGGER_INTERVAL_SECONDS = 60
# Output directory for JSON results
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"安全提示: 在生产环境中,避免将凭据硬编码到源文件中。使用环境变量、密钥管理器(例如 AWS Secrets Manager、Azure Key Vault、HashiCorp Vault)或 Databricks Secrets 在运行时注入这些值。
第 2 步:初始化 SparkSession
打开 pipeline.py,首先创建你的 SparkSession。这是所有 Spark 功能的入口点:
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# Initialize SparkSession
spark = SparkSession.builder \
.appName("BrightDataSERPStream") \
.config("spark.sql.shuffle.partitions", "4") \
.getOrCreate()
# Reduce log verbosity for cleaner output
spark.sparkContext.setLogLevel("WARN")
print("SparkSession initialized.")将 spark.sql.shuffle.partitions 设置为像 4 这样的小数字适合本地开发环境。在集群上,你应根据数据大小和执行器核心数量来调整它。
第 3 步:定义搜索引擎 API 获取函数
接下来,定义将调用 Bright Data 搜索引擎 API 并返回解析结果的 Python 函数。此函数将从 Spark foreachBatch 回调内部在驱动程序上调用,因此它使用标准的 requests 库,而不是任何 Spark 分布式机制:
# pipeline.py (continued)
def fetch_serp_results(query: str) -> list[dict]:
"""
Calls Bright Data's SERP API and returns a list of parsed news results.
Uses the parsed_light data format for lightweight, structured JSON output.
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": config.SERP_API_ZONE,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# The parsed_light format returns a "news" array of result objects
results = data.get("news", [])
print(f"[SERP API] Fetched {len(results)} results for query: '{query}'")
return results
except requests.exceptions.RequestException as e:
print(f"[SERP API] Request failed: {e}")
return []让我们分解一下关键请求参数:
zone:你在 Bright Data 控制面板中的搜索引擎 API 区域名称。url:Google 搜索 URL。tbm=nws参数将结果限制为 Google News。hl=en将界面语言设置为英语,gl=us将美国设为地理定向结果的目标区域。format:设置为"raw"以直接接收响应正文。data_format:设置为"parsed_light"以接收一个干净的 JSON 数组,其中包含顶部自然/新闻结果的标题、URL、来源和日期——不包含广告或知识面板。对于包含广告和知识面板的完整 SERP 数据,使用"parsed"。对于适合 LLM 的输出,使用"markdown"。
第 4 步:使用速率生成器构建流式源
由于 Spark Structured Streaming 没有原生 HTTP 源,我们使用一种成熟的模式:内置的 rate 源充当时钟,每秒(或按配置的速率)生成一行。由 rate 源生成的每个微批次都会触发我们的 foreachBatch 回调,我们在其中调用搜索引擎 API。
将 rate 流定义添加到 pipeline.py:
# pipeline.py (continued)
rate_stream = spark.readStream \
.format("rate") \
.option("rowsPerSecond", 1) \
.load()
print("Rate stream created. Pipeline will trigger every micro-batch interval.")rate 源是专门为测试和像这样的时钟驱动场景设计的。由于现实世界中存在 API 速率限制,我们将在第 5 步中配置触发间隔,以便管道每分钟只调用一次搜索引擎 API,而不是每秒一次。
第 5 步:定义 foreachBatch 处理器
foreachBatch 处理器是该管道的核心。Spark 在每个微批次调用此函数,传入该批次行的 DataFrame 和唯一的批次 ID。在函数内部,我们调用搜索引擎 API,将结果转换为 Spark DataFrame,应用转换,并写入输出接收端:
# pipeline.py (continued)
# Define the schema for parsed SERP results
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
Called by Spark on each micro-batch trigger.
Fetches SERP data from Bright Data, converts results to a DataFrame,
and writes them to the output sink.
"""
print(f"\n--- Processing batch {batch_id} ---")
# Fetch live SERP results from Bright Data
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"Batch {batch_id}: No results returned. Skipping write.")
return
# Convert the results list to a Spark DataFrame
results_df = spark.createDataFrame(results, schema=serp_schema)
# Add metadata columns for tracking
enriched_df = results_df \
.withColumn("query", F.lit(config.SEARCH_QUERY)) \
.withColumn("batch_id", F.lit(batch_id)) \
.withColumn("ingested_at", F.current_timestamp())
# Print to console for visibility
enriched_df.show(truncate=False)
# Write to JSON output (append mode, partitioned by ingestion date)
enriched_df \
.withColumn("ingestion_date", F.to_date("ingested_at")) \
.write \
.mode("append") \
.partitionBy("ingestion_date") \
.json(config.OUTPUT_PATH)
print(f"Batch {batch_id}: Wrote {enriched_df.count()} records to {config.OUTPUT_PATH}")关于此设计,有几点需要注意:
spark.createDataFrame(results, schema=serp_schema) 将搜索引擎 API 返回的 Python 字典列表转换为带类型的 Spark DataFrame。提供显式 schema 优于 schema 推断——它使作业更快且更可预测。
F.lit(batch_id) 将当前微批次 ID 附加到每一行,如果管道重试失败的批次,这对于去重很有用(因为 foreachBatch 默认提供至少一次交付保证)。
F.current_timestamp() 使用驱动程序上的摄取时间为每一行添加时间戳,为每个结果何时进入管道提供可靠的审计跟踪。
第 6 步:启动流式查询
现在通过将 foreachBatch 处理器附加到 rate 流并启动查询,把所有内容连接起来:
# pipeline.py (continued)
# Attach the foreachBatch handler and configure the trigger interval
query = rate_stream.writeStream \
.foreachBatch(process_batch) \
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} seconds") \
.option("checkpointLocation", config.CHECKPOINT_PATH) \
.start()
print(f"Streaming query started. Triggering every {config.TRIGGER_INTERVAL_SECONDS} seconds.")
print("Press Ctrl+C to stop.")
# Wait for the query to terminate (runs indefinitely until interrupted)
query.awaitTermination().trigger(processingTime="60 seconds") 调用告诉 Spark 每 60 秒——即每分钟一次——触发一个新的微批次,而不管 rate 源生成了多少行。这就是控制你的搜索引擎 API 调用节奏的机制,使你在持续运行的同时保持在速率限制之内。
.option("checkpointLocation", ...) 对容错至关重要。Spark 将查询的进度元数据(偏移量、已提交批次)写入此目录。如果进程崩溃并重新启动,Spark 会读取检查点以确定哪些批次已经处理过,并从正确的位置干净地恢复。
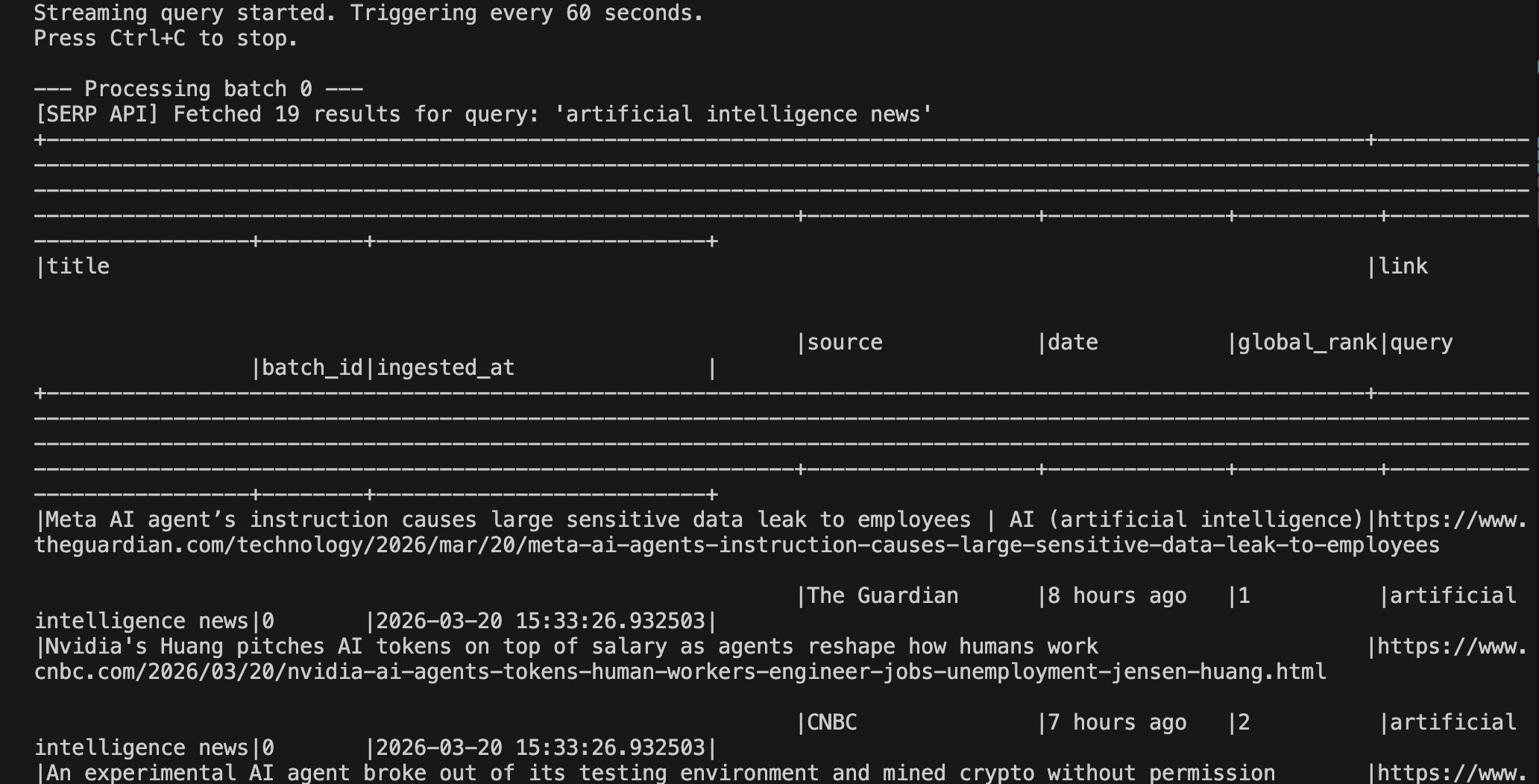
第 7 步:运行并检查结果
从你的终端运行该管道:
python pipeline.py在第一次触发后,你应该会看到类似如下的输出:
你可以在 localhost:4040 查看 Spark 上运行的输出:
运行几分钟后,检查输出目录:
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/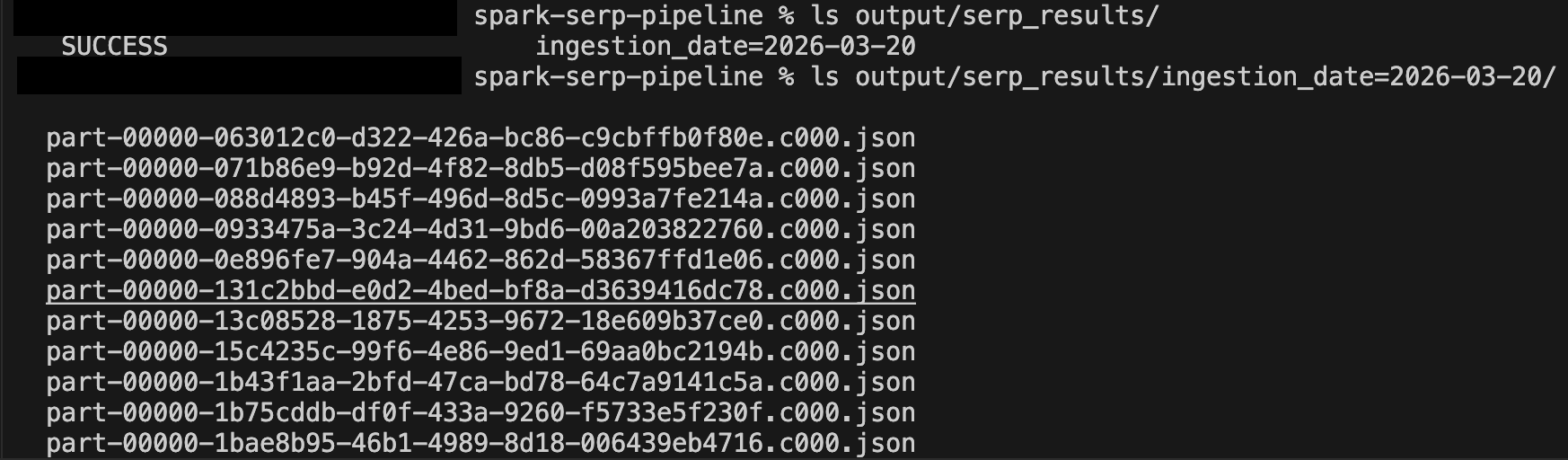
你可以随时将结果读回 Spark 进行临时分析:
# Read back the accumulated results
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)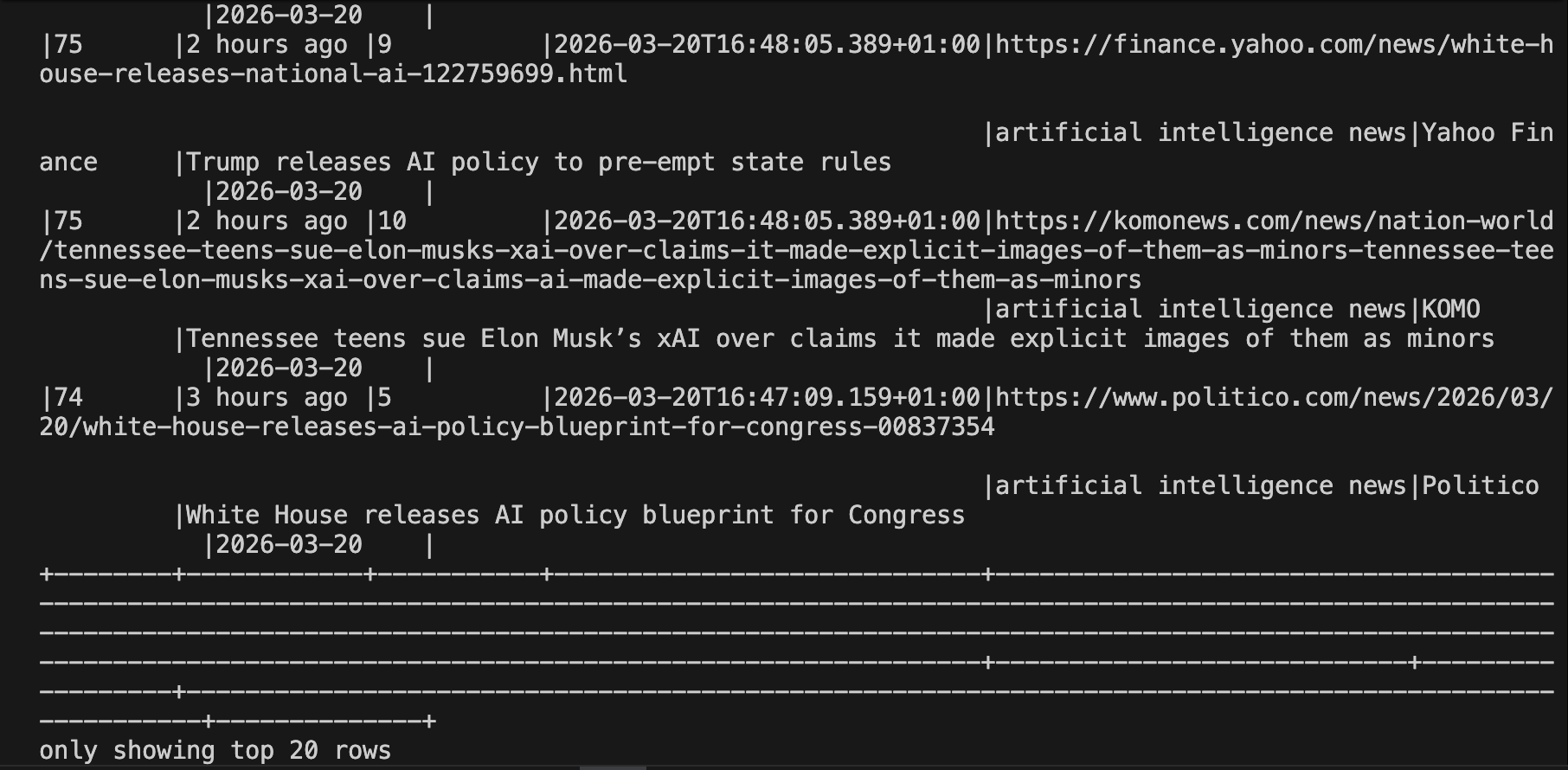
这里提供了完整的管道代码,集中在一个地方,便于参考。
进一步扩展
此示例演示了一种基础摄取模式,但你可以朝很多方向扩展它:
- 不只处理一个主题,而是在每次
foreachBatch调用中维护一个关键词列表并扇出到并行的搜索引擎 API 调用。使用 Python 的concurrent.futures.ThreadPoolExecutor在同一个微批次内同时为多个查询调用 API。 - 用 Delta 表替换 JSON 接收端,以实现符合 ACID 的增量写入并支持 schema 演化。这会让历史查询和去重变得简单得多。
- Bright Data 的搜索引擎 API 支持 Bing 搜索引擎查询,同时也支持 Google、DuckDuckGo、Yandex 等。在同一批次内并行轮询多个引擎并合并结果集。
- 使用 Bright Data 的 网络解锁器 跟进搜索引擎 API 返回的 URL,并检索每篇文章的完整 HTML 或 Markdown 内容。将该内容传输到同一个 Spark 管道中的下游 NLP 阶段。
- 将该管道部署在 Databricks、AWS EMR 或 Google Dataproc 上,以获得生产级可扩展性。在 Databricks 上,你还可以使用 Delta Live Tables 以声明方式管理该管道。
- 将增强后的 SERP 结果写入 Kafka 主题,并由下游微服务、控制面板或告警系统实时消费。
结论
在本教程中,你学习了如何使用 Bright Data 的搜索引擎 API 持续摄取实时搜索引擎结果,并使用 Apache Spark Structured Streaming 对其进行处理。通过使用 rate 源作为调度时钟、使用 foreachBatch 作为集成桥梁,你构建了一个持续运行的管道,它在每次触发时获取最新的 SERP 数据,将其转换为带类型的 Spark DataFrame,并将结果写入分区的 JSON 接收端,同时内置了容错检查点。
这种模式非常适合任何需要大规模处理实时网页搜索信号的团队:关键词排名跟踪、竞争监控、新闻聚合、广告情报等等。与临时的基于脚本的轮询不同,Spark Structured Streaming 管道为你提供了一个分布式、可恢复且易于扩展的基础,它会随着你的数据量增长而成长。
要构建更高级的管道,请探索 Bright Data 的完整网页数据产品套件,其中包括用于绕过任意 URL 上机器人保护的网络解锁器、用于 JavaScript 密集型网站的抓取浏览器,以及适用于最热门平台的现成数据集。
立即注册一个免费的 Bright Data 账户 ,并立即开始使用可靠的实时网页数据为你的数据管道提供支持。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。



