

在本教程中,你将学习:
- 为什么通过网页抓取从哔哩哔哩获取数据是合理的。
- 你可以从哔哩哔哩抓取哪些类型的数据。
- 如何构建一个哔哩哔哩抓取与下载流水线,用于采集 AI 训练(以及其他用例)的公开视频数据。
- 为什么在生产级、企业级应用中,专用的哔哩哔哩抓取器是更好的选择。
跳过复杂度:Bright Data 的哔哩哔哩抓取器可在企业级规模下交付开箱即用的视频数据,内置反爬绕过能力,并提供 99.99% 在线率。
让我们开始吧!
为什么要抓取哔哩哔哩:可能的用例
哔哩哔哩是一家总部位于上海的视频平台,常被称为“中国版 YouTube”。它于 2009 年上线,现已成长为面向 Z 世代的超级平台,拥有超过 2.94 亿月活用户,每日视频播放量超过 30 亿。
它最初以 ACG(动画、漫画与游戏)为核心,如今已覆盖科技、教育、生活方式、音乐、电竞与直播等内容。哔哩哔哩以实时“弹幕”评论与高参与度社区著称,并将用户生成内容、网红文化、游戏与广告整合在同一数字生态中。
鉴于哔哩哔哩增长迅速,获取平台数据可以支持多种用例,例如:
- 视频 AI 训练:大规模哔哩哔哩视频数据集可用于计算机视觉、语音识别、多模态大模型(multimodal LLM)、推荐系统与内容审核模型。这得益于丰富的元数据、转写文本、互动信号以及原始视听内容。
- 趋势与内容情报:分析分区、标签、播放量与互动指标,以识别 Z 世代与 ACG 社区中的新兴主题、快速增长的创作者与爆款内容形态。
- 创作者与达人分析:追踪 UP 主表现、粉丝增长、互动比率与发布频率,以评估 KOL(关键意见领袖)影响力,并优化中国市场的达人营销策略。
- 受众情绪分析:挖掘弹幕与普通评论,以规模化理解观众反应、情绪倾向、文化梗与实时反馈模式。
- 竞品对标:通过监测播放量、互动与内容策略,对比品牌账号、赞助活动与同类赛道头部玩家。
- 市场进入与本地化研究:评估内容偏好、语言使用与趋势主题,以便为中国数字原住民受众定制产品、活动与表达方式。
你可以从哔哩哔哩获取哪些数据
抓取哔哩哔哩时,你可以定位多个数据字段。具体可抓取的字段取决于你采集的页面类型与整体目标。因此,哔哩哔哩存在多个值得探索的数据类别。
视频元数据
当你针对某个具体的哔哩哔哩视频时,可以采集:
- 基础信息:标题、简介、封面图 URL、视频 ID、视频时长等。
- 投稿信息:发布时间戳与分区(例如“动画”“科技”“音乐”等)。
- 分类信息:标签、关键词,以及是否标记为原创或转载。
- 互动统计:播放量、点赞、投币、收藏与分享。
- 评论:视频中直接展示的弹幕评论,包括评论文本、时间戳、颜色、字号与显示模式。
- 字幕:AI 生成或 UP 主提供的转写文本。
用户与创作者主页
当你聚焦哔哩哔哩创作者主页时,可以抓取:
- 身份信息:用户名、用户 ID、性别、头像等。
- 社交指标:粉丝数、关注数,以及所有视频累计获得的总点赞数。
- 个人信息:个人简介、生日与账号等级。
- 账号状态:认证标识(例如“官方音乐人”)与会员等级(例如大会员/VIP)。
- 作品列表:某个创作者公开发布的全部视频。
搜索与发现数据
你也可以利用哔哩哔哩的搜索系统来获取:
- 搜索结果:匹配特定关键词的视频、用户或直播列表。
- 热度数据:热搜关键词与日榜/周榜排名。
- 直播信息:房间 ID、直播标题、开播状态与同时在线人数(人气指数)。
用 Python 构建哔哩哔哩抓取器与视频下载流水线:分步指南
在本节的引导式步骤中,你将学习如何从 “科技”分区页面抓取哔哩哔哩视频元数据:
注意,这只是一个示例。同样的逻辑也适用于任何其他分区页面,包括主站首页。
接着,你将使用从该页面提取的视频 URL 构建第二个脚本,逐个下载视频。有了下载后的视频文件,你最终就能将它们直接输入到你的 AI/ML 训练流水线中。
按照下方说明操作即可!
前置条件
为了跟随本教程,请确保你具备:
- 本地已安装 Python 3.10。
- 本地已安装 FFmpeg。
- 熟悉浏览器自动化的工作原理。
- 对
yt-dlp的工作方式有基础理解。
使用以下命令验证你的机器上已安装 FFmpeg:
ffmpeg -version你应该会看到类似如下内容: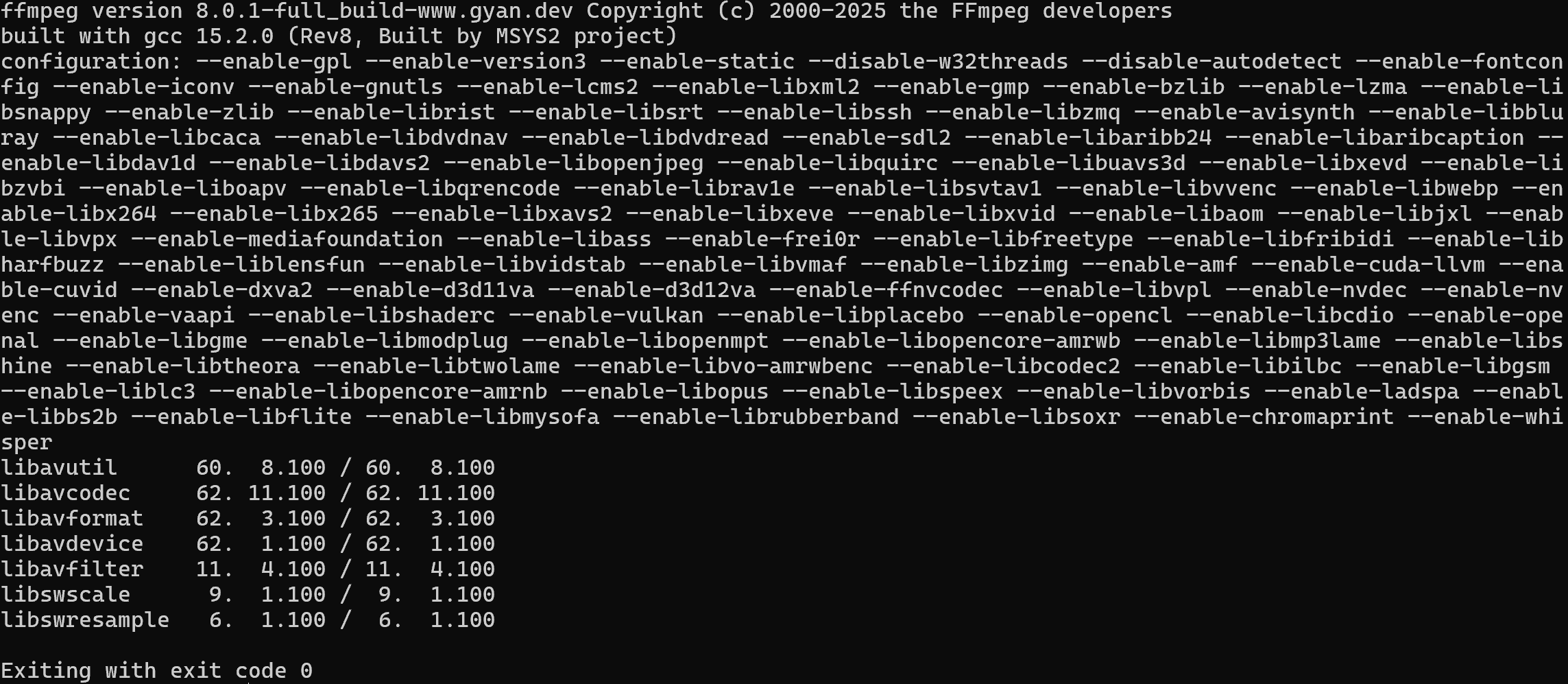
如果你看到的是报错,请按照 适用于你操作系统的官方安装指南安装 FFmpeg。
步骤 #0:先熟悉哔哩哔哩
在写任何代码之前,先花些时间探索目标网站。你需要判断它是静态还是动态的,因为你的网页抓取路线图取决于这一点。
如果网站是静态的,简单的 HTTP 客户端加 HTML 解析可能就足够。如果网站是动态的,你需要一个浏览器自动化工具。更多内容请参阅我们的指南:网页抓取中的静态与动态内容。
在浏览器中打开目标页面并开始与页面交互。注意该页面使用了无限滚动(infinite scrolling)的 UI 模式: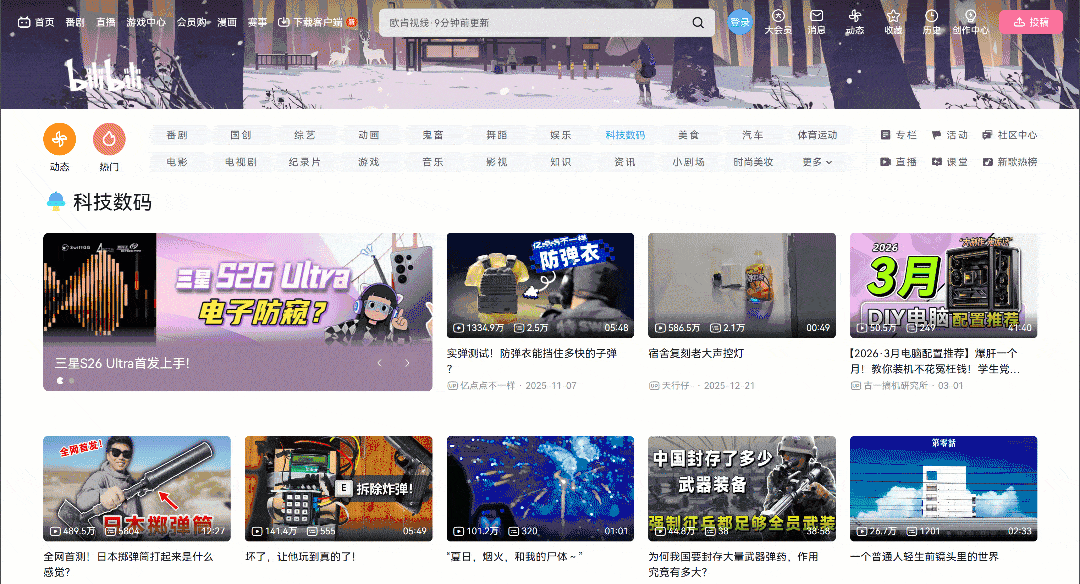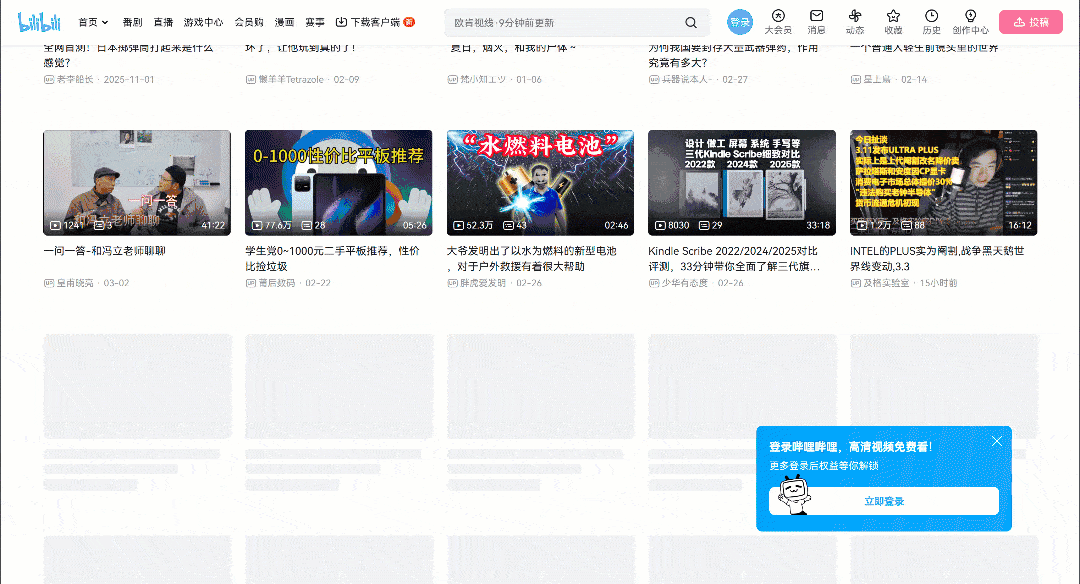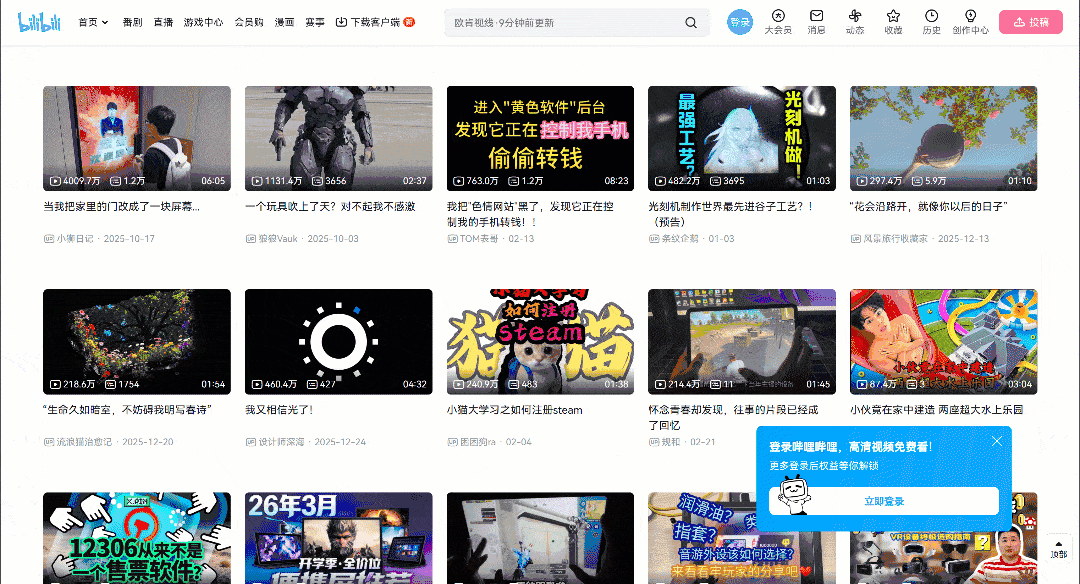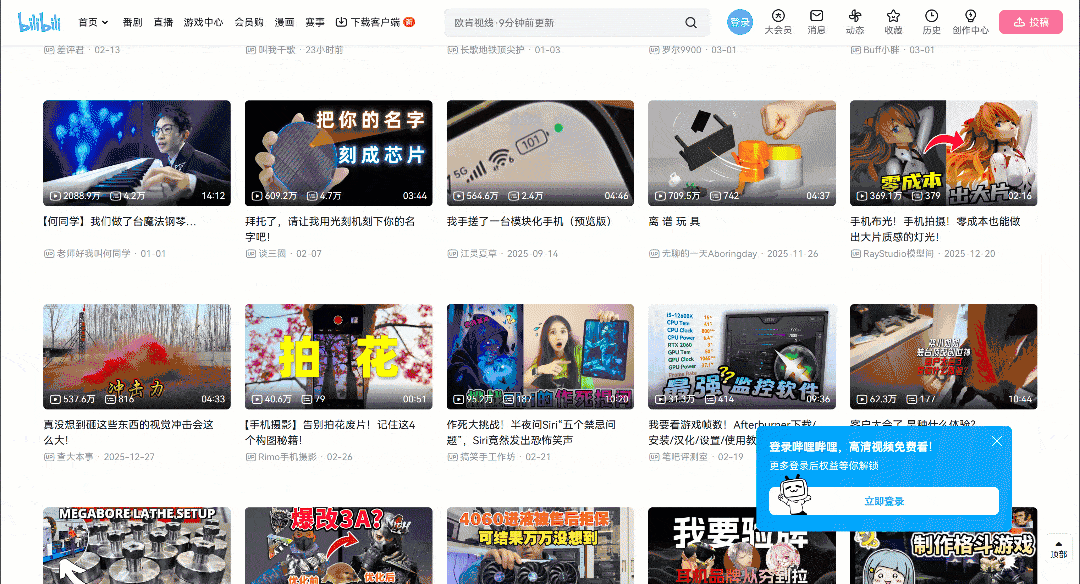
当你向下滚动时,新的视频卡片会自动加载。这种行为表明该网站是动态的:它依赖 JavaScript 基于用户交互去拉取并渲染新数据。
因此,仅靠简单的 HTTP 请求并不足够。你需要浏览器自动化工具来正确渲染并抓取内容。在本教程中,我们将使用 Playwright,但 Selenium、SeleniumBase 或 NODRIVER 等工具同样可行。
步骤 #1:搭建 Playwright 项目
首先打开终端,为你的哔哩哔哩抓取器创建一个新目录:
mkdir bilibili-scraper进入项目目录,并在其中创建一个 Python 虚拟环境:
cd bilibili-scraper
python -m venv .venv然后用你偏好的 Python IDE 打开项目文件夹。安装 Python 扩展的 Visual Studio Code 与 PyCharm Community Edition 都是不错的选择。
在项目根目录创建一个名为 scraper.py 的新文件,项目结构如下所示:
bilibili-scraper/
├── .venv/
└── scraper.py # <-----------在 IDE 集成终端中激活虚拟环境。在 Linux/macOS 上执行:
source .venv/bin/activate对应地,在 Windows 上运行:
.venv/Scripts/activate激活虚拟环境后,安装 playwright:
pip install playwright随后通过下载所需的浏览器二进制文件完成安装:
python -m playwright install现在,将以下基础 Playwright 初始化代码加入 scraper.py:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# Launch a controlled Chromium instance in headful mode
browser = await p.chromium.launch(headless=False) # Set to True in production
context = await browser.new_context()
page = await context.new_page()
# Scraping logic...
# Close the browser and release its resources
await browser.close()
if __name__ == "__main__":
asyncio.run(main())这段代码会初始化一个 Chromium 浏览器实例并让 Playwright 控制它。
在开发阶段,建议保持 headless=False,便于你可视化观察浏览器正在做什么。在生产环境中,建议设置 headless=True 以降低资源占用并通过无头模式加速执行。
做得很好!现在你已经拥有了一个可通过浏览器自动化来抓取哔哩哔哩的 Python 环境。
步骤 #2:连接到目标网站
使用 Playwright 打开目标网页,也就是哔哩哔哩“科技”分区页面:
# The target "Technology" Bilibili page
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navigate to the target page
await page.goto(target_bilibili_page)goto() 会指示受控浏览器访问指定 URL,并等待页面加载完成。
就是这样!你现在已经连接到哔哩哔哩目标页面。
下一步是自动化滚动交互,让新的视频卡片动态加载。额外内容出现后,你就可以从这些 HTML 元素中提取数据了。
步骤 #3:加载更多视频卡片
如前所述,哔哩哔哩首页与分区页使用无限滚动 UI 模式。初始状态下只会显示少量视频卡片。随着你向下滚动,更多内容会通过 JavaScript 动态加载。
具体来说,页面初始会在一个 .head-cards HTML 元素中加载固定数量的视频卡片: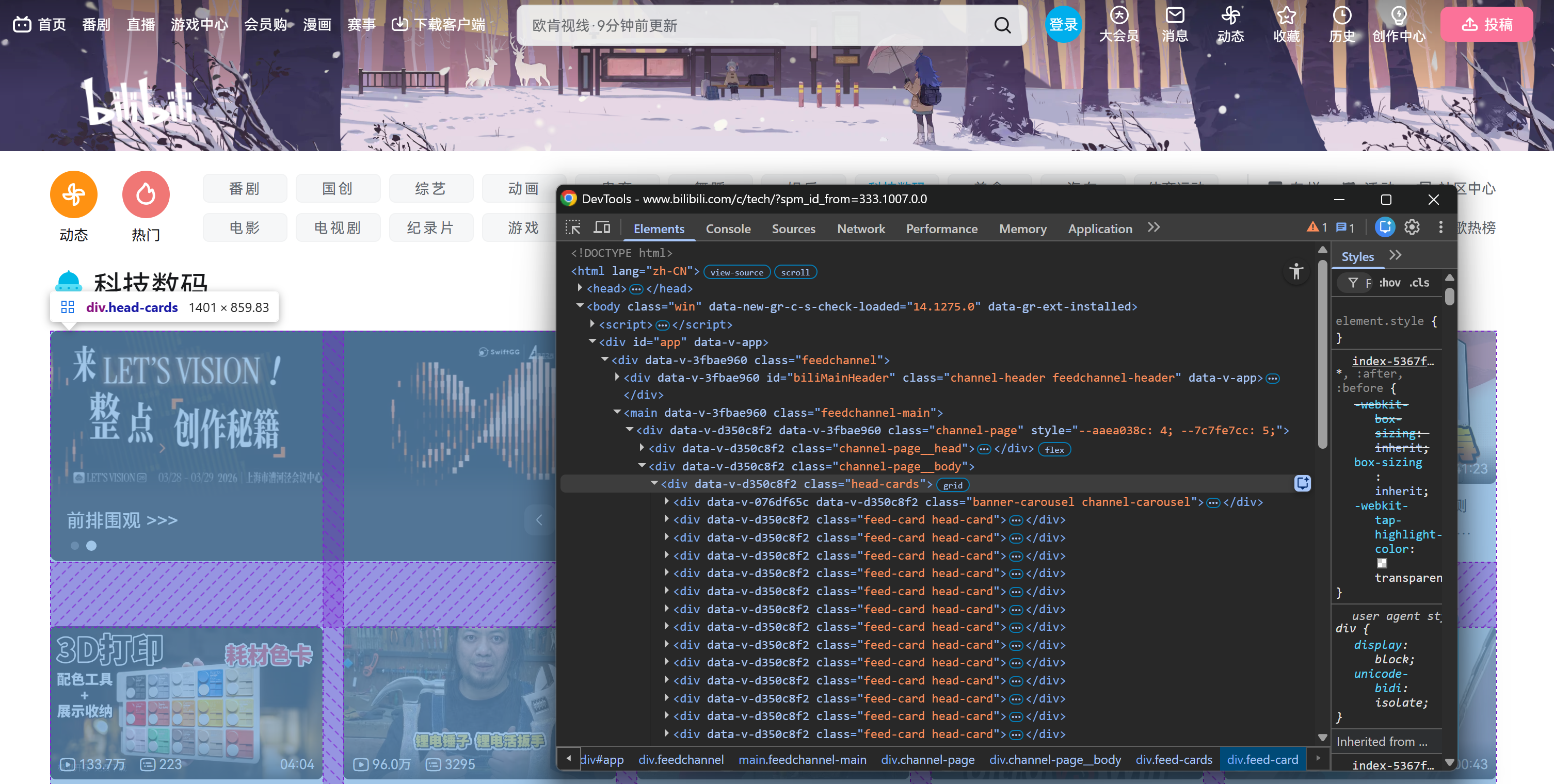
当你向下滚动后,页面会新增一个 .feed-cards 容器。该区域会在你持续滚动时动态填充更多视频卡片: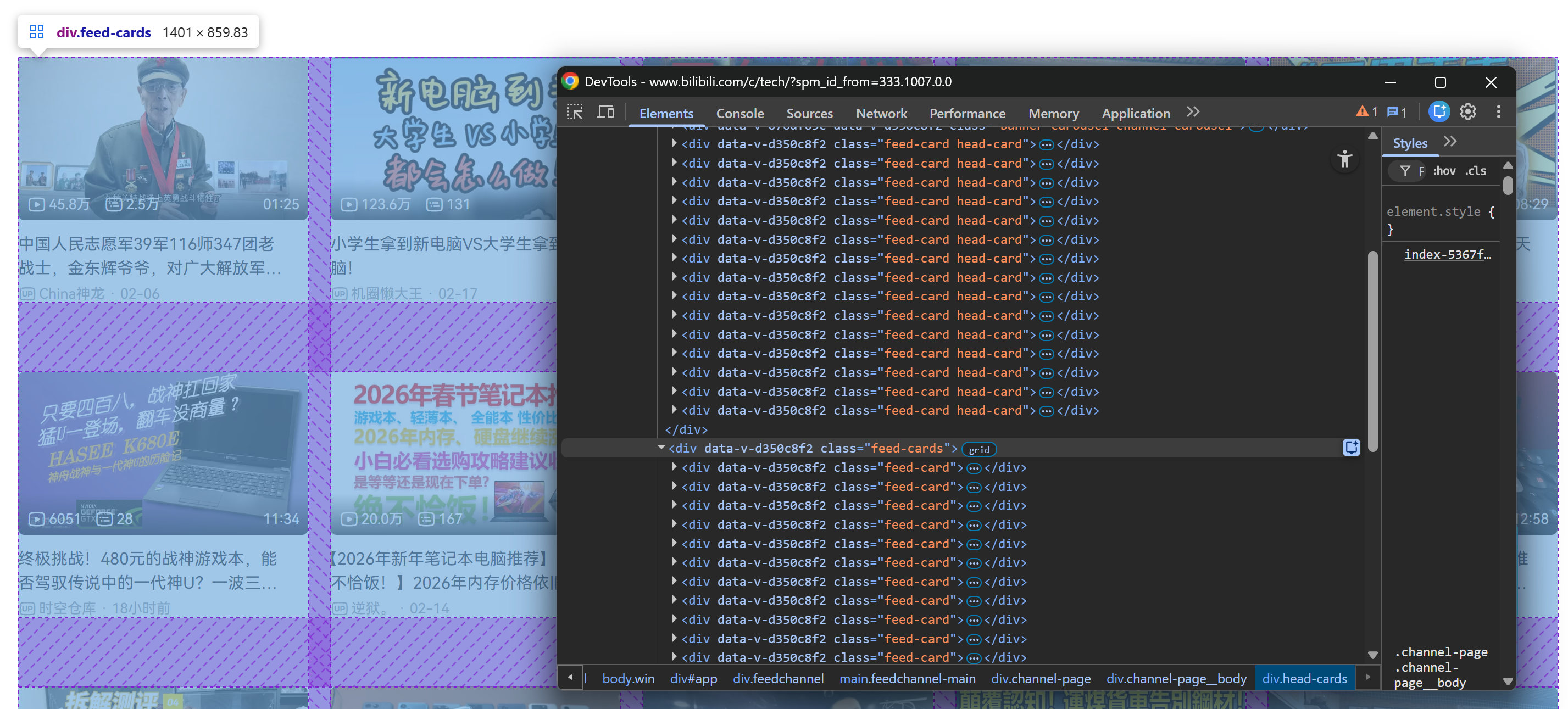
这里关键在于:所有视频卡片(无论是首屏静态加载还是滚动后动态加载)都可以通过下面这个 CSS 选择器选中:
.feed-card在本哔哩哔哩抓取教程中,假设你希望至少获取 50 条视频。为此,你需要模拟多次滚动交互。Playwright 没有提供专门的滚动 API,因此你将直接在页面上下文中执行一段简单的 JavaScript:
for _ in range(3):
# Allow lazy loading
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Allow lazy loading
await asyncio.sleep(2) 这个循环会执行 window.scrollTo() 三次,每次都从页面顶部滚动到页面底部。asyncio.sleep() 的调用很重要,因为:
- 它让滚动行为更像真实用户操作。
- 它降低触发反爬机制的风险。
- 它为懒加载内容提供充分渲染时间,再进行下一次滚动。
由于视频卡片是动态加载的,你不能假设滚动后它们会立刻出现。相反,你必须显式等待第 50 个卡片被挂载到 DOM。在 Playwright 中可以这样做:
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")这段代码为第 50 个 .feed-card 元素创建了一个 Playwright locator(之所以是 nth(49) 是因为索引从 0 开始)。然后通过 wait_for() 等待该元素被挂载到 DOM。
现在,如果你在有头模式(headless=False)下运行脚本,你会看到浏览器自动滚动三次:
如预期,每次滚动后都会加载新的视频卡片。
完成这一步后,你就可以确信页面上至少已经存在 50 个视频卡片。太棒了!
步骤 #4:熟悉视频卡片结构
为了提取正确的数据,你首先需要理解每个视频卡片在 DOM 中的结构。
先在 .head-cards 区域中右键点击某个视频卡片,并在浏览器开发者工具中检查: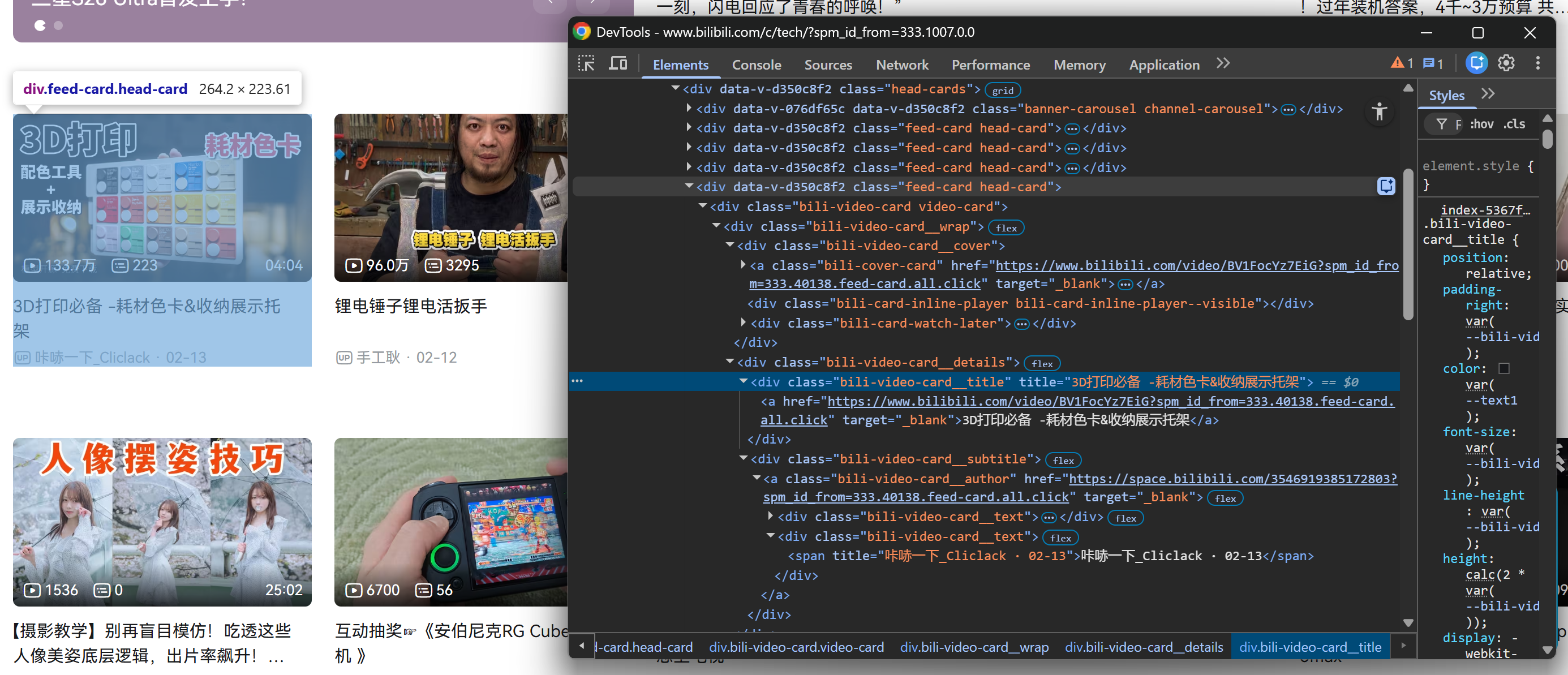
然后对滚动后加载出的 .feed-cards 区域中的视频卡片重复相同步骤: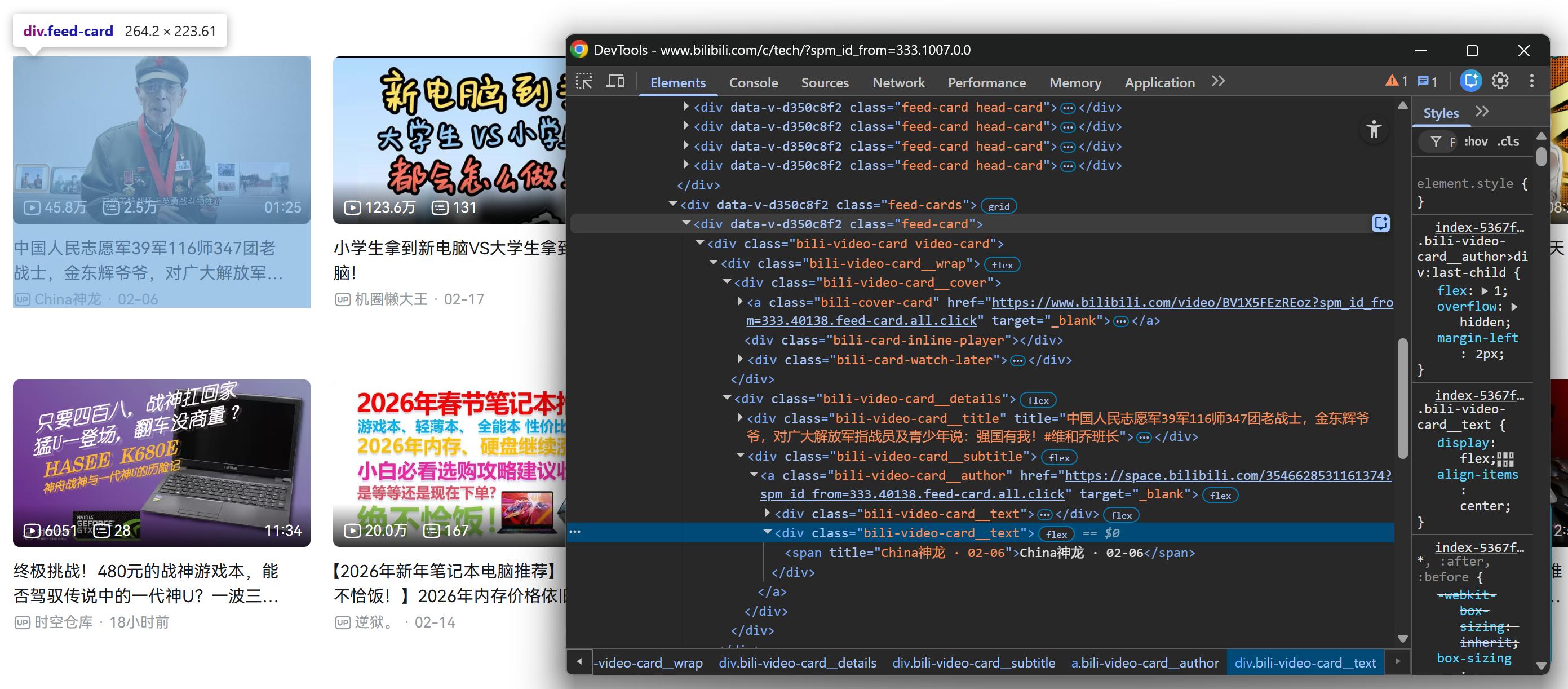
好消息是,所有 .feed-card 元素内部结构一致。这意味着你不必区分首屏加载的视频卡片与滚动后动态加载的视频卡片。你可以用同一套选择器抓取它们全部!
请注意:从每个视频卡片中,你可以采集:
- 从
.bili-video-card__title a元素中获取视频标题。 - 从同一个标题
<a>节点的href属性中获取视频 URL。 - 从
.bili-video-card__subtitle span[title]获取原始副标题(包含作者名 + 发布时间)。 - 从
.bili-video-card__author元素获取作者主页 URL。
很好!现在你已经理解了 DOM 结构,下一步就是把这些理解转化为可编程的哔哩哔哩数据抓取逻辑。
步骤 #5:抓取视频数据
请记住,目标页面包含多个视频卡片。因此,你需要一个数据结构来存储抓取结果。列表非常适合:
videos = []接着,遍历所有视频卡片,并应用前面描述的提取逻辑:
for i in range(feed_card_count):
# Get the current video card to extract data from
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Store the scraped data
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)上述代码片段会遍历每个视频卡片并:
- 提取标题、视频 URL、原始副标题与作者主页 URL。
- 解析副标题字符串(格式为
"<AUTHOR_NAME> · <DATE>"),将作者名与日期分别提取出来。 - 构建结构化的
video字典,并追加到videos列表中。
当 for 循环结束时,videos 列表将包含 50+ 个结构化的哔哩哔哩视频对象。太好了!
步骤 #6:导出抓取数据
为了更方便地处理抓取数据,将其导出到 videos.json 文件:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)如果你现在运行 scraper.py,它应当生成一个包含结构化哔哩哔哩视频数据的 videos.json 文件,如下所示: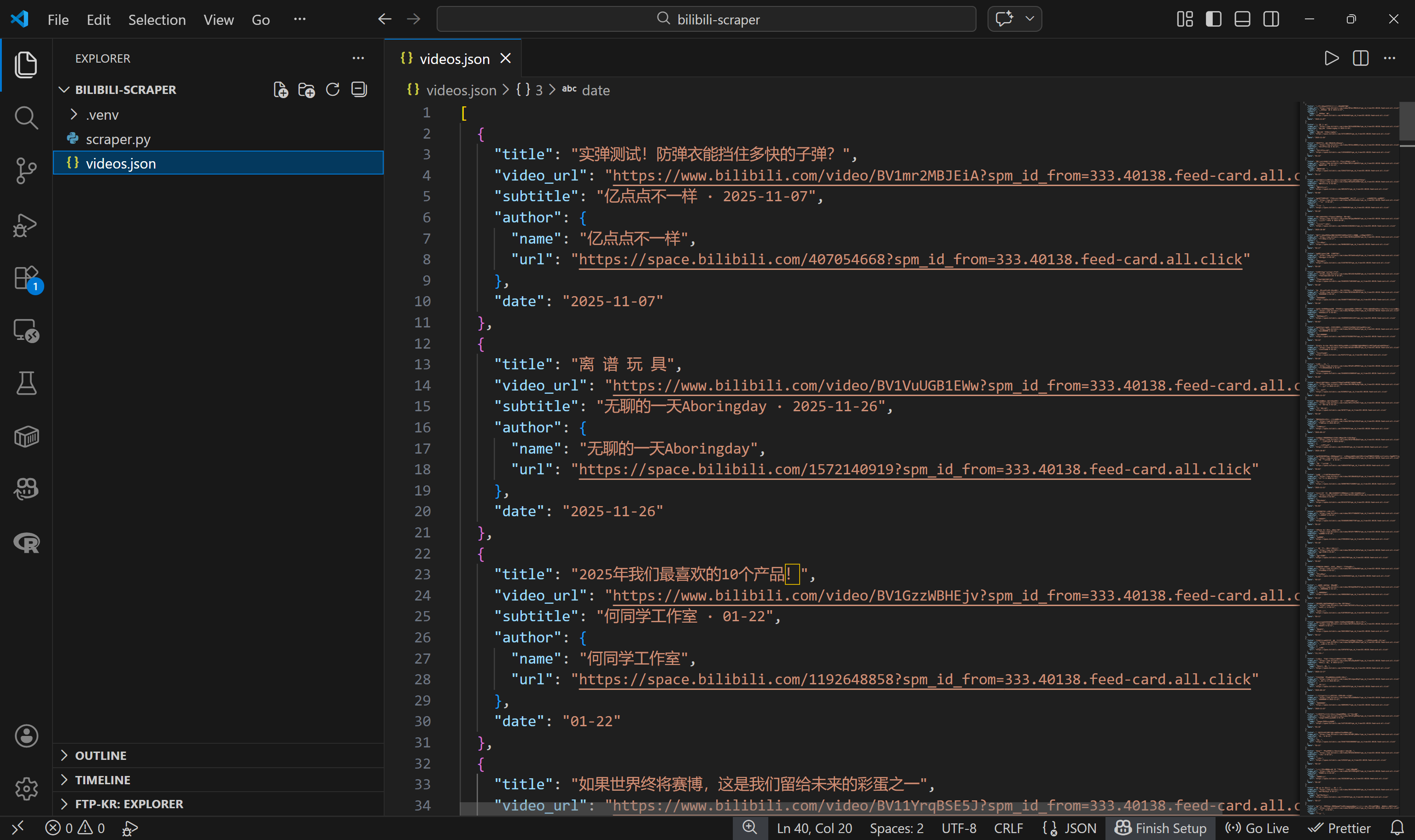
任务完成!你从一个包含大量视频卡片的页面出发,现在已经把它们的元数据以结构化 JSON 文件保存下来了。
如果你的目标只是抓取哔哩哔哩,教程到这里就可以结束(不过请务必查看最后一步获取完整脚本)。如果你还想更进一步,下载视频文件本身,请继续阅读……
步骤 #7:准备下载哔哩哔哩视频
从前面抓取到的 URL 下载哔哩哔哩视频,最简单的方法是使用 yt-dlp。
yt-dlp 是一个功能强大的音视频下载器,支持包括哔哩哔哩在内的数百个网站。它既可以在命令行使用,也可以通过 Python API 以编程方式使用。在这里,我们将通过其 Python API 以程序方式调用它。
在虚拟环境激活的情况下,安装 yt-dlp:
pip install yt-dlp然后在项目根目录新增一个名为 video-downloader.py 的文件:
bilibili-scraper/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------该文件将包含基于 yt-dlp 的哔哩哔哩视频下载逻辑。
video-downloader.py 脚本需要:
- 读取
videos.json文件。 - 提取每个视频的
video_url。 - 使用
yt_dlp中的YoutubeDL类下载视频文件。
实现如下:
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Load the video data from the input JSON file
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Loaded {len(videos)} videos from {INPUT_FILE}\n")
# Ensure that the output folder exists
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Downloading: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Video #{index} downloaded\n")
except Exception as e:
print(f"Video #{index} download failed: {e}\n")哇!不到 35 行代码就达成了目标。
步骤 #8:下载视频文件
确保本地安装了 ffmpeg,然后运行 video-downloader.py 脚本。在终端里你应该会看到类似输出: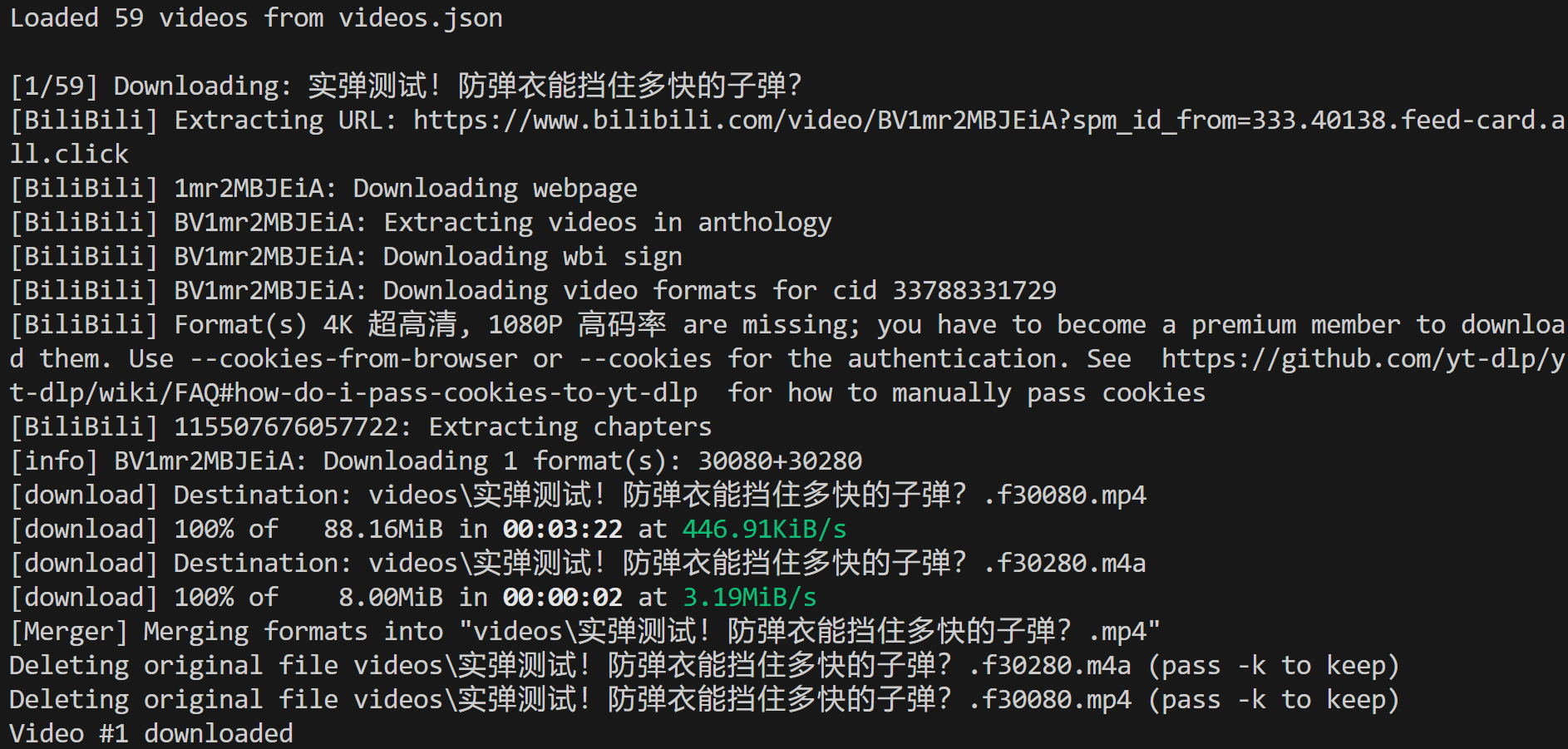
这表示从 videos.json 输入文件中加载了 59 个视频,并且第一个视频已成功下载到本地路径:
./videos/实弹测试!防弹衣能挡住多快的子弹?.mp4在 Visual Studio Code 中,你会看到该 MP4 视频文件出现在对应路径下: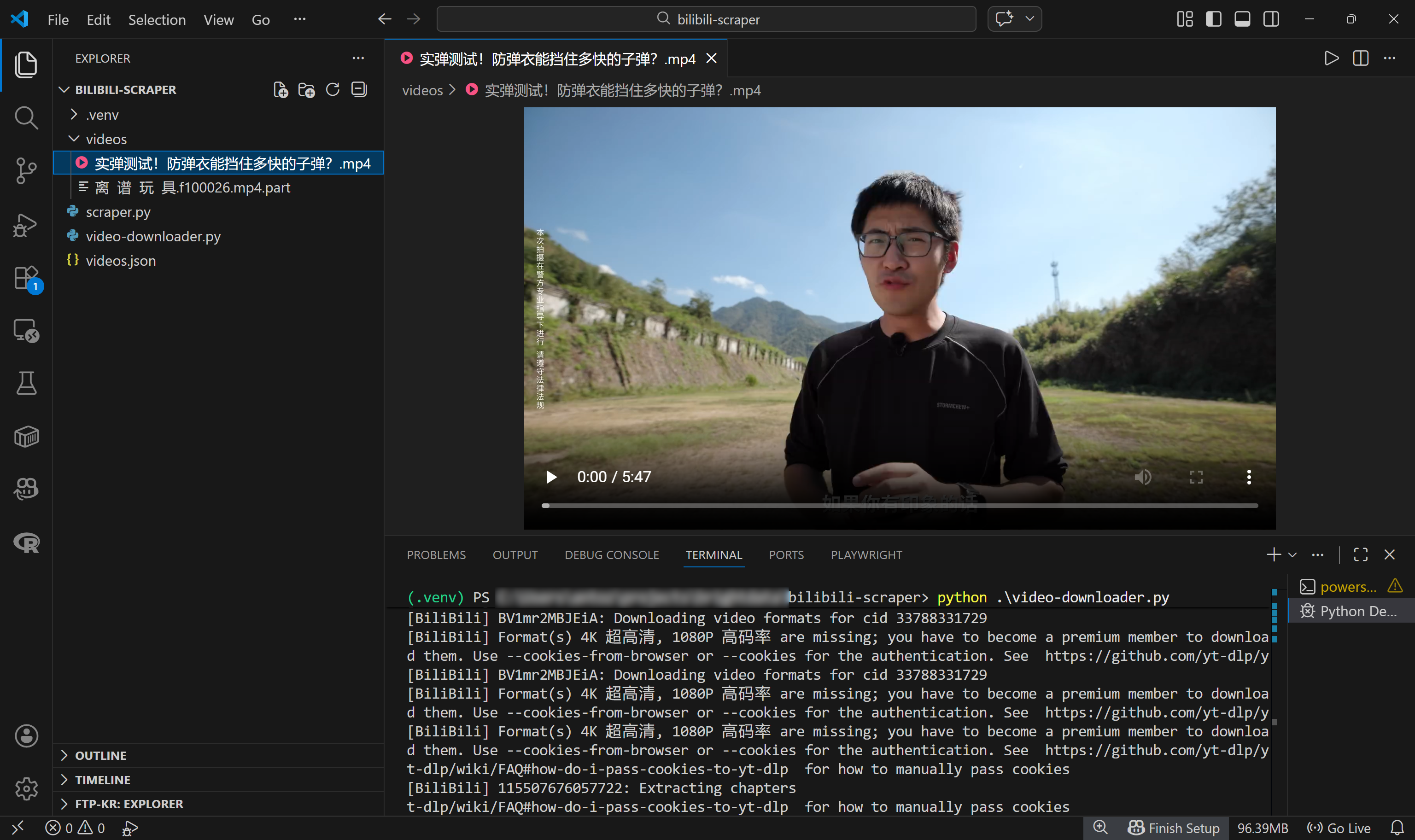
太棒了!你现在拥有一个全自动化的哔哩哔哩系统:不仅能发现新视频,还能下载它们。有了这些文件,你甚至可以通过多模态 ML 流水线来训练 AI 模型。
步骤 #9:最终代码
scraper.py 文件将包含如下代码:
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# Launch a controlled Chromium instance in headful mode
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# The target "Tech" Bilibili page
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navigate to the target page
await page.goto(target_bilibili_page)
# Scroll down the entire page 3 times
for _ in range(3):
# Allow lazy loading
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Allow lazy loading
await asyncio.sleep(2)
# Wait until the 50th video card element is attached to the DOM
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="visible")
# Select all feed cards via locator
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count} feed cards loaded.")
# Where to store the scraped data
videos = []
# Apply the Bilili data scraping logic on each video card
for i in range(feed_card_count):
# Get the current video card to extract data from
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Store the scraped data
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# Close the browser and release its resources
await browser.close()
# Export the scraped data to a JSON file
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
print(f"{len(videos)} scraped Bilibili videos exported to videos.json")
if __name__ == "__main__":
asyncio.run(main())用以下命令运行:
python scraper.py这将生成一个包含抓取到的哔哩哔哩视频数据的 videos.json 文件。然后你可以使用下面的 video-downloader.py 脚本下载这些视频:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Load the video data from the input JSON file
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Loaded {len(videos)} videos from {INPUT_FILE}\n")
# Ensure that the output folder exists
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Downloading: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Video #{index} downloaded\n")
except Exception as e:
print(f"Video #{index} download failed: {e}\n")用以下命令执行:
python video-downloader.py运行结果会生成一个 ./videos 文件夹,其中包含为每个发现的哔哩哔哩视频下载的 MP4 文件。
大功告成!你刚刚学会了如何构建一个哔哩哔哩抓取器,并用它将抓取到的视频数据输入到下载器中。该流程能帮助你获取用于 AI 训练或其他用例的实际视频文件。
下一步
现在你已经同时拥有结构化元数据与实际视频文件,可以将这些数据传入AI 训练流水线。例如,你可以为计算机视觉任务抽取帧、为 NLP 模型微调生成转写文本、分析音频信号,或基于视频内容与元数据构建推荐系统。标题、作者、日期与原始视频文件的组合,为你提供了一个适合实验的丰富多模态数据集。
此外,为加速下载阶段,可以考虑将流程并行化,让多个视频同时下载。这样能更充分利用现有带宽,从而缩短下载耗时。
面向生产的哔哩哔哩抓取方案:获取用于 AI 的视频数据
如果你对大量视频运行下载脚本,最终可能会看到类似如下错误:
Unable to download webpage: HTTP Error 412: Precondition Failed (caused by <HTTPError 412: Precondition Failed>)这是因为哔哩哔哩部署了反爬防护。当平台检测到可疑流量(例如来自同一 IP 的自动化请求过多)时,会开始返回 412 Precondition Failed 响应。
错误页面大致如下:
这只是抓取哔哩哔哩时需要面对的挑战之一。其他常见问题还包括目标页面结构变化、基于指纹的检测等。虽然自建的 Playwright + yt-dlp 方案很适合小规模项目,但长期维护会变得复杂且脆弱。
要在规模化场景下稳定抓取哔哩哔哩,你需要更健壮的基础设施来处理 IP 轮换、浏览器指纹、CAPTCHA 处理与自动重试。这正是 Bright Data 的哔哩哔哩抓取器所提供的能力。
该网页抓取 API 同样支持无代码方式,可获取视频标题、上传日期、播放量、点赞、评论、收藏、时长、UP 主名称、简介、URL 等更多信息,并为你自动绕过反爬机制。
哔哩哔哩抓取器的独特之处在于它运行在覆盖 195 个国家/地区、拥有 1.5 亿+ IP 的代理基础设施之上,可实现 99.99% 在线率、99.95% 成功率,并支持无限并发。这使其能够支撑大规模、企业级抓取场景——而这对于多模态 AI 训练尤为关键,因为训练往往需要海量视频数据。
在获取视频 URL 之后,将 Bright Data 的 Web Unlocker API 集成到自动化的 yt-dlp 工作流中,即可避免 412 错误,实现无封锁的视频下载。借助 Bright Data,你可以不再担心限流、封禁或 yt-dlp 失败,从而获取更多视频用于训练你的 AI/ML 模型。
结论
在这篇博客文章中,你了解了可以从哔哩哔哩抓取哪些数据,以及它支持的主要用例。其中一个最有意思的场景就是基于视频数据进行 AI 训练。由于平台上拥有数以亿计的视频内容,哔哩哔哩是一个巨大的、可公开获取的多媒体内容来源。
整个流程从一个你已逐步学会构建的哔哩哔哩抓取器开始。它会采集结构化的视频元数据(包括视频 URL)。然后你可以将这些 URL 输入到基于 yt-dlp 的工作流中,下载实际视频文件——正如本指南所演示的那样。
Bright Data 通过专用抓取器与直接的 yt-dlp 集成选项来支持哔哩哔哩抓取,从而实现可靠、不中断的下载。更多信息请查看我们关于大规模访问视频数据以进行 LLM 训练的解决方案。
立即注册 Bright Data,探索我们的视频数据采集解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



