

多年来,Undetected Chromedriver一直是安全浏览和反僵尸绕过程序的主要工具。Undetected Chromedriver 背后的开发人员创建了NODRIVER。有了 NODRIVER,你就不再依赖 Selenium 或 Webdriver。只需进行简单的pip 安装,一切准备就绪。
在本指南中,您将了解到
- 什么是 NODRIVER?
- 它与其他无头浏览器有何不同?
- 如何使用 NODRIVER?
- NODRIVER 有哪些限制?
- 如何通过代理使用 NODRIVER?
- NODRIVER 的可靠替代品
什么是 NODRIVER,为什么要关注?
NODRIVER 究竟是什么?
NODRIVER 是 Undetected Chromedriver 的完全异步继承者。它将 “最佳实践 “作为所有 kwargs 的默认设置,只需少量代码即可直接运行。
NODRIVER 拥有以下功能:
- 性能
- 无外部依赖性(甚至连 Chromedriver 也没有)
- 反机器人旁路
- 持久会话 cookie
- 每次使用都有新的浏览器实例
是什么让 NODRIVER 与众不同?
NODRIVER 采用与 Undetected Chromedriver 甚至其他无头浏览器完全不同的架构。传统上,这些其他浏览器依赖于 Selenium 或Chrome DevTools Protocol(CDP)。
NODRIVER 使用自己定制的 DevTools 协议实现。在文档中,它实际上被称为 “chrome(类似)自动化库”。有了 NODRIVER,你就不需要依赖 Selenium,也不需要直接依赖 CDP。NODRIVER 使用 CDP 的自定义实现。要使用 NODRIVER,你只需要 pip 和基于 Chrome 浏览器。
使用 NODRIVER 搜索
1.开始
在开始之前,您需要确保已经安装了 Python 和浏览器。如果你正在阅读这篇文章,我假设你已经安装了这些设备。你可以用 pip 直接安装 NODRIVER。
pip install nodriver2.基本结构
我们的基本结构与 Playwright 或 Puppeteer 类似。如果你对在 Python 中使用 Playwright 感兴趣,可以点击此处查看完整的亚马逊列表搜索指南。NODRIVER 的感觉与 Playwright 非常相似,但目前仍在大力开发中。
这就是我们的基本结构。
import nodriver
async def main():
#start the browser
browser = await nodriver.start()
base_url = "https://quotes.toscrape.com"
#navigate to a page
page = await browser.get(base_url)
###logic goes here###
#close the browser
await page.close()
if __name__ == '__main__':
#in their docs, they advise directly against asyncio.run()
nodriver.loop().run_until_complete(main())3.获取页面
你可能已经注意到,在我们上面的基本骨架中,browser.get()返回的是一个页面对象。你甚至可以同时打开多个页面。如果你愿意发挥创造力,就能实现高度并发的操作。
下面的片段只是理论上的。
#navigate to a page
page_1 = await browser.get(base_url)
page_2 = await browser.get(a_different_url)
####do stuff with the different pages#####4.动态内容
要处理动态内容,您有两种选择。可以使用.sleep()方法等待任意时间,也可以使用.wait_for()等待页面上的特定选择器。
#wait an arbitrary amount of time
await tab.sleep(1)
#wait for a specific element
await tab.wait_for("div[data-testid='some-value']")注意:在上面的代码段中,我使用了tab而不是page作为变量名。它们可以互换。它们都是标签页对象。有关 NODRIVER 标签的更多信息,请点击此处。
5.寻找要素
NODRIVER 为我们提供了多种查找页面元素的方法。他们似乎正在处理一些传统方法。
有四种不同的基于文本的查找元素方法。其中两种可能会在未来消失。
#find an element using its text
my_element = page.find("some text here")
#find a list of elements by their text
my_elements = page.find_all("some text here")
#find an element using its text
my_element = page.find_element_by_text("some text here")
#find a list of elements using their text
my_elements = page.find_element_by_text("some text here")与上述方法一样,还有四种基于选择器的查找元素方法。其中两种可能会消失。如果 NODRIVER 的开发者希望与 CDP 明确保持一致,那么query_selector方法很可能会继续存在。
#find a single element using its css selector
my_element = page.select("div[class='your-classname']")
#find a list of elements using a css selector
my_elements = page.select_all("div[class='your-classname']")
#find a single element using its css selector
my_element = page.query_selector("div[class='your-classname']")
#find a list of elements using a css selector
my_elements = page.query_selector_all("div[class='your-classname']") 如上所示,无论你想如何查找页面上的元素,都可能有多种方法。假以时日,NODRIVER 背后的开发人员可能会对此进行改进。尽管如此,目前他们的解析方法就像瑞士军队的电锯。
6.提取数据
NODRIVER 提供了几种提取数据的方法。您可以使用.attributes特质直接提取属性,但这种方法对用户不太友好–它返回的是一个数组,而不是一个 JSON 对象。
这是我从链接对象中提取href的一个笨办法。虽然很难看,但还能用。我希望属性方法很快会被功能更强大的方法取代。
next_button = await page.select("li[class='next'] > a")
#this returns an array
attributes = next_button.attributes
#use array indexing to find the href object and its value
for i in range(len(attributes)):
if attributes[i] == "href":
next_url = attributes[i+1]注意:大多数其他无头浏览器都包含一个get_attribute()方法。不过,这种方法在 NODRIVER 中还无法使用。
下面是我们提取文本数据的方法。正如你可能注意到的,我们在这里没有使用await。我猜想这在将来会有所改变,以便与其他 CDP 风格的浏览器保持一致。在当前形式下,文本只是一个属性,而不是一个方法–当await与属性一起使用时,实际上会产生错误。这感觉与 Puppeteer 和 Playwright 都背道而驰,但这就是 NODRIVER 目前的状态–仍在紧锣密鼓地开发中。
#find the quote element
quote_element = await quote.query_selector("span[class='text']")
#extract its text
quote_text = quote_element.text7.存储数据
我们将把数据存储在一个小巧的 JSON 文件中。在提取引语时,每个引语都有一个标签列表,而 CSV 格式的列表效果并不好。
import json
with open("quotes.json", "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=4)8.把所有东西放在一起
现在,让我们将所有这些概念整合到一个工作脚本中。在下面的示例中,我们使用上述概念从Qutoes to Scrape(一个专为抓取教程而建的网站)中提取数据。复制并粘贴下面的代码,了解 NODRIVER 的实际工作原理。
import nodriver
import json
async def main():
#list to hold scraped data
scraped_data = []
browser = await nodriver.start()
next_url = "/"
base_url = "https://quotes.toscrape.com"
#while we still have urls to scrape
while next_url:
#go to the page
page = await browser.get(f"{base_url}{next_url}")
#find quote divs using a selector
quotes = await page.select_all("div[class='quote']")
#iterate through the quotes
for quote in quotes:
#find the quote element and extract its text
quote_element = await quote.query_selector("span[class='text']")
quote_text = quote_element.text
#find the author and extract the text
author_element = await quote.query_selector("small[class='author']")
author = author_element.text
#find the tag elements
tag_elements = await quote.query_selector_all("a[class='tag']")
tags = []
#iterate through the tags and extract their text
for tag_element in tag_elements:
text = tag_element.text
tags.append(text)
#add our extracted data to the list of scraped data
scraped_data.append({
"quote": quote_text,
"author": author,
"tags": tags
})
#check the page for a "next" button
next_button = await page.select("li[class='next'] > a")
#if it doesn't exist, close the browser and break the loop
if next_button == None:
await page.close()
next_url = None
#if it does, follow this block instead
else:
attributes = next_button.attributes
#loop through the attributes to find your desired attribute, its value is the next index
for i in range(len(attributes)):
if attributes[i] == "href":
next_url = attributes[i+1]
#write the data to a json file
with open("quotes.json", "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
nodriver.loop().run_until_complete(main())如果运行上述脚本,就会得到一个 JSON 文件,其中包含如下所示的对象。
[
{
"quote": "“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
{
"quote": "“It is our choices, Harry, that show what we truly are, far more than our abilities.”",
"author": "J.K. Rowling",
"tags": [
"abilities",
"choices"
]
},NODRIVER 目前的局限性
目前,NODRIVER 有一些值得注意的严重局限性。让我们来看看这些限制。
无头模式
每当我们在无头模式下运行 NODRIVER 时,它都会出错。我们不确定这是有意为之(作为一种反机器人绕过),还是一个合理的问题。
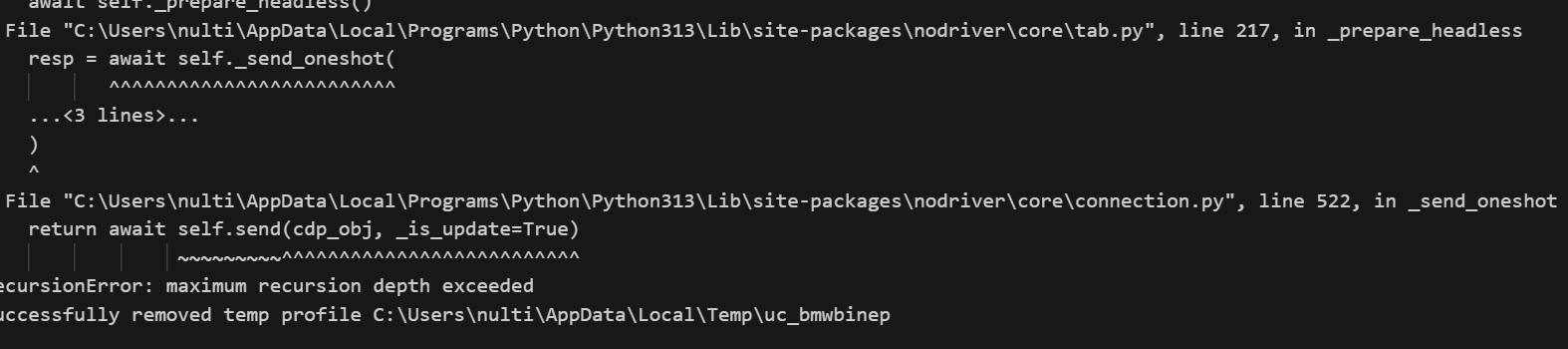
页面互动
虽然 NODRIVER 在其文档中列出了许多页面交互,但其中大多数要么部分有效,要么根本无效。正如你所看到的,下面的截图记录了click_mouse()和mouse_click ()。
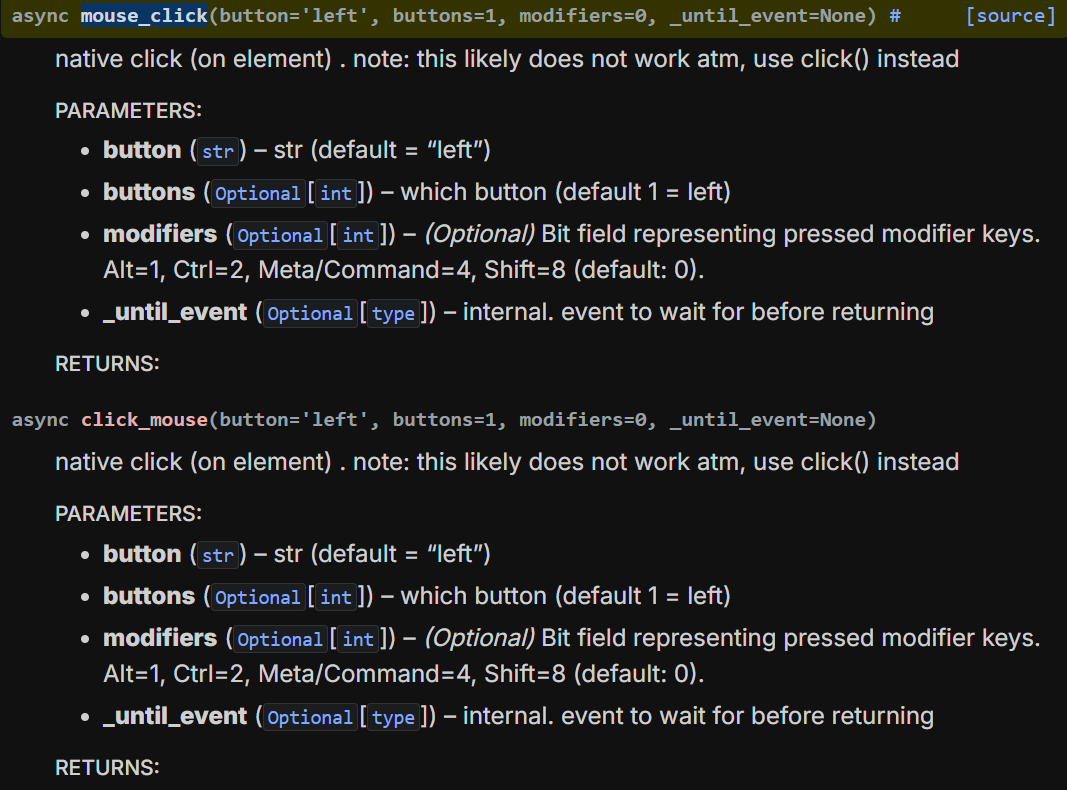
属性提取
NODRIVER 最大的痛点在于属性提取。如前所述,这将输出一个数组,而且正如你在我们的href解决方法中看到的那样,它非常过时。下面是属性的字面输出。对于生产级抓取,这一点需要解决。

使用 NODRIVER 的代理功能
目前,NODRIVER 对代理的支持有限。它们确实为代理连接提供了一个create_context()方法。
下面的片段直接来自他们的问题页面。然而,在尝试了几个小时的这个方法和其他各种方法后,我仍然无法连接。
tab = await browser.create_context("https://www.google.nl", proxy_server='socks5://myuser:mypass@somehost')
# or add new_window=True if you would like a new window如果你查看他们的文档,就会发现有一个关于代理的部分[1]。尽管有官方的代理部分,但没有实际的文档。我们认为这将在不久的将来得到修复。
可行的替代方案
虽然它目前还不能用于生产,但我对 NODRIVER 的未来充满期待。如果你正在寻找更重型的产品,请看看下面的浏览器。
- 硒:自 2004 年以来一直保持强劲势头。Selenium 依赖于 Chromedriver,但它已经过实战测试并可投入生产。了解有关Selenium 网络抓取的更多信息。
- Playwright:Playwright 给人的感觉就像你在本教程中看到的 NODRIVER 的精良即用版。了解如何使用Playwright 进行网络抓取。
结论
NODRIVER 是一款令人兴奋的浏览器自动化新工具,但快速的开发意味着某些功能仍在不断成熟。如果要进行大规模、可靠的网络抓取,可以考虑使用像 NODRIVER 这样强大的解决方案:
- 住宅代理:绕过地理限制的真实设备连接。
- 网络解锁器:带内置验证码解码器的托管代理。
- 扫描浏览器:远程浏览器自动化,支持代理和验证码。多步骤搜索项目的完美解决方案。
- 自定义搜索器:无需代码即可运行自定义搜索任务,并由专家协助提取数据。
注册免费试用,立即开始使用!



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。





