

Exa 是语义搜索引擎。Bright Data 是网页数据基础设施。它们本质上是完全不同的产品,而该用哪一个,完全取决于你的 AI 智能体实际需要做什么。
本文将以生产级 AI 团队最关心的维度,对两者进行拆解对比:成本、速率限制、覆盖范围、访问能力与历史数据。不做含糊判断,只给数字与事实。
TL;DR – Bright Data vs. Exa 一览
- Exa 是语义搜索引擎;Bright Data 是网页数据基础设施。
- Bright Data SERP API 价格为 $1.50/1k 请求;Exa 为 $7/1k。
- Exa 默认
/search速率限制为 10 QPS。Bright Data 没有并发请求限制。 - Bright Data Web Unlocker 能抓取受反爬虫保护的页面;Exa 不能。
- Bright Data 拥有 50PB+ 的历史网页数据;Exa 仅支持实时数据。
- Exa 的 Find Similar 功能独特,Bright Data 没有直接等价能力。
- 用 Exa 做语义发现;用 Bright Data 做规模化的真实网页数据提取(ground-truth extraction)。
Bright Data vs. Exa:正面对比
| 维度 | Bright Data | Exa |
|---|---|---|
| 产品类别 | 网页数据基础设施(代理网络 + 抓取工具 + 数据集) | 语义搜索引擎 API |
| 搜索方式 | 通过 SERP API 抓取真实搜索引擎(Google、Bing、Yandex 等)+ 通过 Discover API 做实时发现 | 基于自研向量嵌入(embeddings)的神经索引(自有索引) |
| 每次查询结果数 | 最高 1,000(Discover API) | 标准版最高 100;企业版最高 1,000 |
| 完整页面内容 | 支持,通过 Web Unlocker 实时提取,以 Markdown 返回 | 支持,通过 /contents 接口(额外 $1/1k 页面) |
| 绕过反爬虫 & CAPTCHA | 支持,内置于 Web Unlocker;150M+ 代理 IP | 不支持,无法抓取登录墙或反爬虫保护后的内容 |
| 历史数据 | 支持,50PB+ Web Archive;预构建 Datasets | 不支持,仅实时索引 |
| 速率限制 | SERP API 无并发请求限制 | /search 默认 10 QPS;企业版可自定义 |
| 定价(按量付费) | 起价 $1.50/1,000 请求(SERP API) | $7/1,000 请求(标准搜索,1-10 个结果) |
| 支持的搜索引擎 | Google、Bing、DuckDuckGo、Yandex、Baidu、Naver、Yahoo | Exa 自有专有神经索引 |
| 合规 | GDPR、CCPA、SOC 2、SOC 3、ISO 27701 | SOC 2 Type II、可选 ZDR |
| MCP 集成 | 支持,Bright Data MCP Server(免费,每月 5,000 次免费请求) | 支持,Exa MCP Server |
| 框架集成 | LangChain、LlamaIndex、CrewAI、Agno、Dify、n8n、Zapier 等 70+ | LangChain、LlamaIndex、CrewAI、Vercel AI SDK 等 20+ |
| 免费层 | 支持,免费试用 | 支持,每月 1,000 次请求 |
| 企业级 SLA | 支持,99.9% SLA,专属客户经理 | 支持,自定义 SLA,1:1 上线辅导 |
什么是 Exa?
Exa 是专为 AI 应用构建的搜索引擎。它不是使用传统关键词索引,而是构建了自己的神经索引:一个在网页上训练的大规模向量嵌入模型。你查询 Exa 时,它会在该索引上做语义向量搜索,并按概念相关性而不是关键词重合度来排序结果。
这套架构选择是 Exa 的核心差异点。它能够回答诸如“找与这个 arXiv URL 类似的论文”或“做半导体业务里类似 Nvidia 的公司有哪些”这类问题,这是基于关键词的 SERP 抓取工具无法做到的。根据其公开信息,截至 2026 年 3 月,Exa 的索引包括 10 亿+人物档案与 7000 万公司条目,并提供面向新闻、代码与财报的专门搜索模式。如果你正在评估 Exa 的替代方案,AI 网页搜索的 Exa 替代方案对包括 Bright Data、Tavily、Firecrawl 在内的工具做了更详细对比。
Exa 擅长什么
语义“Find Similar”搜索。没有其他搜索 API 能提供“找与这个 URL 在概念上相似的页面”。这是一个真实的能力差距,Bright Data 目前不覆盖。
低延迟检索。Exa Instant 可实现低于 200ms 的响应;标准搜索通常在 100–1,200ms。对交互式聊天界面与实时智能体来说,这个速度优势很明显。
开发者体验。提供 Python/TypeScript SDK,原生 LangChain、LlamaIndex、CrewAI 集成,支持 MCP Server,并提供每月 1,000 次免费请求。从零到接入一个可用智能体只需要几分钟。
专门的垂直索引。Exa 的人物索引(10 亿+档案,每周更新 5000 万+)与公司索引(7000 万+公司)面向招聘智能体、销售情报流水线与公司信息补全工作流做了专门优化。
基准测试准确率强。在 WebWalker 多跳检索中,Exa 在某 Fortune 100 企业评估(2025 年 1 月)里得分 81%,对比 Tavily 的 71%。在 AIMultiple 对 8 个 API 的 100-query 基准测试中,Exa 以 14.39 的 Agent Score 排名第 3。
Exa 在规模化场景下的核心限制
速率限制会限制生产负载。默认 /search 上限为 10 QPS(每分钟 600 次请求),这一点在 Exa 官方速率限制文档中有明确说明。对于运行成千上万并行研究任务的多智能体流水线,这个上限会迫使团队从第一天起就实现重试与队列。企业客户可谈更高额度,但需要单独走商务流程。
无法穿透反爬虫保护。Exa 按自身节奏抓取开放网页,无法获取 Cloudflare、防登录墙、CAPTCHA、或 JS 重型反机器人检测保护下的页面。对竞品情报、价格监控等“越有价值越受保护”的数据,这是硬限制。
没有历史数据层。Exa 只提供实时数据:没有归档产品、没有历史数据集、也没有对比今天与上季度结果的能力。对异常检测、趋势分析、或需要历史基线支撑的智能体输出,这是结构性缺口。
Exa 的索引不是 Google。Exa 返回来自其自有神经索引的结果,而不是 Google/Bing/Yandex 的真实 SERP。任何需要知道“用户此刻在 Google 上实际看到什么”的用例(SEO 监测、广告情报、排名追踪、品牌保护),Exa 的数据源都不适用。
高量时成本扩张不友好。若每月 100 万次请求,Exa 标准搜索成本 $7,000+;若再取全文内容,则 $8,000+。Exa 在 2026 年 3 月更新定价,把标准搜索从 $5/1k 提升到 $7/1k,并新增 Agentic 档位 $12/1k。
什么是 Bright Data?
Bright Data 是网页数据基础设施。它不维护自有搜索索引,而是通过针对不同数据获取模式设计的一套产品,在规模化条件下访问真实的实时网页数据。
SERP API 可实时抓取 Google、Bing、Yandex、Baidu、DuckDuckGo、Yahoo、Naver 等搜索结果,覆盖 195 个国家并支持城市级地理定位。它返回的是某个地点的真实用户“此刻”看到的内容,而不是任何索引“推断”你应该看到的内容。
Discover API 专为需要更广、更深实时证据的智能体工作负载而设计,而不是只拿一份浅层的、按 SEO 排序的链接列表。它能在每次请求中发现最多 1,000 个实时 URL,按智能体意图而非 SEO 排名进行排序,并可选返回清洗后的 Markdown 内容用于 RAG grounding 与验证。与搜索引擎或缓存索引不同,Discover 的每次请求都在查询时刻针对实时网页执行,因此特别适用于竞品情报、风险监控与尽调工作流。
Web Unlocker 可以获取任意网页,包括被 Cloudflare、CAPTCHA、登录墙或 JavaScript 渲染保护的页面,并返回干净的 Markdown 内容。它通过覆盖 195 个国家的 150M+ 住宅 IP 网络进行路由,自动处理绕过检测。
Datasets 提供覆盖 100+ 领域的预构建结构化数据。Web Archive API 提供 50PB+、可追溯多年历史的网页数据,是历史 grounding 的理想方案。
Bright Data 如何为 AI 获取网页数据
Bright Data 的架构基于一个核心前提:真实事实(ground truth)来自“实时网页本身”,而不是任何索引对网页的近似。对构建生产系统的企业 AI 团队,这在以下场景尤为关键:
- 你的智能体需要抓取竞争对手定价页,而该页面会拦截抓取工具
- 你的智能体需要知道 Google 对某个关键词此刻到底展示什么,而不是某个神经索引的估计
- 你的智能体需要并行跑 10,000 次查询且不被速率限制卡住
- 你的智能体需要判断今天的结果相对六个月前是否异常
Bright Data 服务 20,000+ 客户(含《财富》500 强),并被引用于 Gartner 的 Web 数据采集解决方案竞品格局报告。其拥有 GDPR、CCPA、SOC 2、SOC 3、ISO 27701 等认证。
核心产品:SERP API、Discover API、Web Unlocker、Datasets
| 产品 | 用途 | 价格 |
|---|---|---|
| SERP API | 实时抓取 7 大搜索引擎、覆盖 195 国、结构化 JSON/Markdown 输出 | 按量付费 $1.50/1k 起;月 200 万可低至 $1.00/1k |
| Discover API | 实时 URL 发现,单次最高 1,000 结果,意图排序,可选 Markdown 内容 | 免费(beta) |
| Web Unlocker | 获取受反爬虫保护的任意页面,返回干净 Markdown | $1/1k 请求起 |
| Datasets | 覆盖 100+ 领域的预构建结构化数据 | $250/100K 记录起 |
| Web Archive API | 50PB+ 历史网页数据 | $0.20/1k HTML 页面起 |
| MCP Server | 让 AI 智能体直接连接 Bright Data 全产品套件 | 免费,每月 5,000 次请求 |
价格对比:Bright Data vs. Exa
Exa 定价(2026 年 3 月)
| 产品 | 价格 |
|---|---|
| 标准搜索(1-10 结果) | $7 / 1,000 请求 |
| 超过 10 个结果的额外结果 | +$1 / 1,000 结果 |
| Agentic / 深度搜索 | $12 / 1,000 请求 |
| 带推理的深度搜索 | $15 / 1,000 请求 |
| Contents(全文) | $1 / 1,000 页面 |
| Answer API | $5 / 1,000 答案 |
| 免费层 | 每月 1,000 请求 |
| 企业版 | 自定义 |
关键细节:Exa 的定价是叠加的。如果你的智能体需要 10 个结果并同时需要全文内容,你需要为 search($7)+ contents($1)分别付费(每 1,000 次请求)。因此对需要内联全文的智能体来说,最低有效成本为 $8/1k。
Bright Data 定价
| 产品 | 价格 |
|---|---|
| SERP API(按量付费) | $1.50 / 1,000 结果 |
| SERP API(38 万结果/月) | $1.30 / 1,000 结果 |
| SERP API(90 万结果/月) | $1.10 / 1,000 结果 |
| SERP API(200 万结果/月) | $1.00 / 1,000 结果 |
| Web Unlocker | $1 / 1,000 请求起 |
| Datasets | $250 / 100K 记录起 |
| Web Archive | $0.20 / 1,000 HTML 页面起 |
| Discover API | 免费(beta) |
| MCP Server | 免费(每月 5,000 次请求) |
规模化成本:差距非常明显
| 用量 | Exa(仅标准搜索) | Exa(搜索 + 全文) | Bright Data SERP API |
|---|---|---|---|
| 10,000 次请求 | $70 | $80 | $15 |
| 100,000 次请求 | $700 | $800 | $130-150 |
| 1,000,000 次请求 | $7,000+ | $8,000+ | $1,000-1,500 |
当月请求量达到 100 万时,Bright Data 仅在搜索层面就比 Exa 便宜约 5–7 倍。若要在规模化场景下对 SERP 与网页搜索 API 提供商做更完整比较,可参考 2026 年最佳 SERP API 与网页搜索 API。对需要全文内容的智能体,差距会进一步扩大:Exa 需在基础搜索费上叠加 $1/1k;而 Bright Data Web Unlocker 起价 $1/1k(整体打包)。
Bright Data 没有并发请求限制
这不是细微差别。Exa 默认 /search 速率限制为 10 QPS,即每秒 10 次查询、每分钟 600 次——这一点可在 Exa 官方速率限制文档中确认。
Bright Data 的 SERP API 没有并发请求限制。其 FAQ 中写道:“并发请求数量没有限制。SERP API 为规模化而构建。”
对单智能体、一次只跑一个查询的工作负载,这差别不大。但对生产级 AI 流水线(并行跑几十/上百个研究任务)、竞品情报系统、多智能体研究框架、实时监控栈而言,这种差别是根本性的。使用 Exa,你从第一天起就得围绕“上限”做工程设计。
Bright Data 能访问 Exa 无法触达的页面
Exa 抓取开放网页,无法访问:
- 受 Cloudflare 保护的页面
- 有登录墙或认证要求的网站
- 强制 CAPTCHA 的页面
- 对原始 HTTP 请求不返回内容的 JS 重型网站
- 需要本地 IP 才能访问的地域限制内容
这不是批评,只是 Exa 的产品范围之外。
Bright Data 的 Web Unlocker 就是专门为这个问题而构建。它通过 150M+ 住宅 IP 路由请求,处理浏览器指纹,管理 CAPTCHA 处理,并将完整渲染后的页面内容以干净 Markdown 返回。若团队需要深入理解绕过反爬虫意味着什么,可参考绕过 Cloudflare 进行网页抓取的技术指南。对竞品价格情报这类场景(最有价值的数据往往在保护最严的页面上),这就是关键能力。
下面是同一任务下,生产级智能体使用 Bright Data SERP API 与 Exa 的最小示例:
# Bright Data SERP API - real Google results, no rate limit ceiling
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # LLM-ready output
}
)
results = response.json()
# Exa - semantic search, 10 QPS limit
from exa_py import Exa
exa = Exa(api_key="YOUR_EXA_KEY")
results = exa.search_and_contents(
"competitor pricing enterprise 2026",
num_results=10,
text=True
)
# $7/1k (search) + $1/1k (contents) = $8/1k effective cost在基础查询上,功能输出看起来相似。当你需要并行对 1,000 个竞争对手运行,或当目标页面拦截 Exa 的抓取时,差异就会显现。见示例:
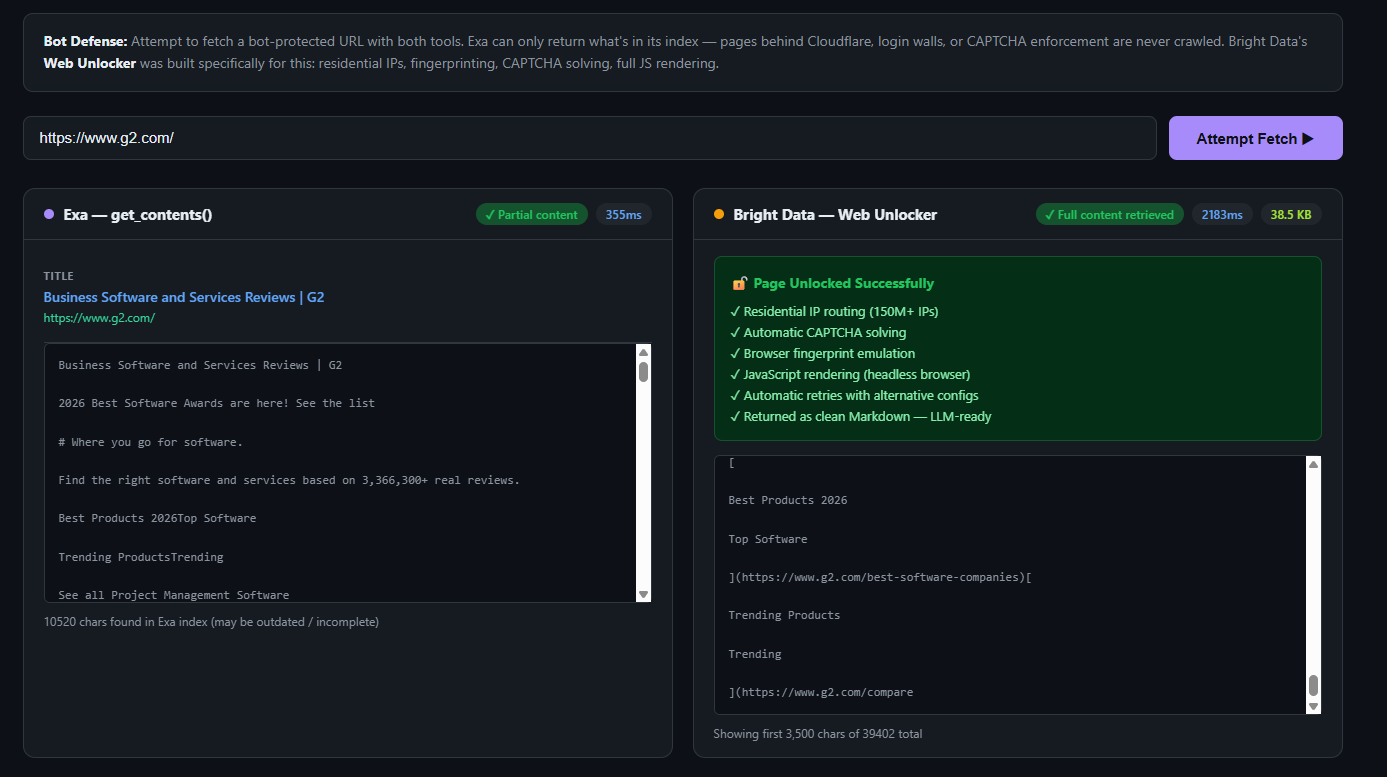
如果你想自己试试,可以查看这个 GitHub demo。
Exa 没有历史数据层
需要检测价格变化、政策变动或市场波动的 AI 智能体,必须有一个可对照的基线。没有“正常情况”,就无法标记“异常”。
Exa 仅支持实时数据:没有归档产品、没有历史数据集、没有时间序列能力。
Bright Data 的 Web Archive API 拥有 50PB+ 历史网页数据并每日增长。预构建的结构化 Datasets 覆盖 100+ 领域,为电商、社媒、房地产等场景提供历史基线。无论是做纵向情报(跟踪竞争对手定价页 12 个月变化)、长期跟踪监管披露文件,还是检测公众情绪变化,Bright Data 有基础设施而 Exa 没有。
用例选择指南
| 用例 | 最佳选择 | 原因 |
|---|---|---|
| RAG 原型 / 黑客松 | Exa | 快速、免费层、原生 LangChain、部署最省事 |
| 语义相似性搜索(“找和这个 URL 类似的页面”) | Exa | Find Similar 接口在 Bright Data 中无等价能力 |
| 人物 / 公司信息补全(招聘智能体、销售情报) | Exa | 10 亿+已索引档案、结构化公司索引 |
| 竞品价格情报(获取实时页面全文) | Bright Data | Web Unlocker 可绕过反爬虫;Exa 无法触达受保护页面 |
| 1,000+ 并发查询的生产智能体 | Bright Data | 无速率上限天花板;SERP API 为并行负载设计 |
| 真实 Google SERP 数据(SEO、广告监控、排名追踪) | Bright Data | SERP API 抓取真实 Google;Exa 使用自有索引 |
| 历史基线 / 异常检测 | Bright Data | 50PB+ Web Archive、Datasets、时间序列能力 |
| Cloudflare / 登录墙后的页面 | Bright Data | Web Unlocker;Exa 无法访问受保护内容 |
| 多引擎搜索(Google + Bing + Yandex) | Bright Data | SERP API 覆盖 7 大引擎、195 国 |
| 低延迟交互式聊天体验 | Exa | Exa Instant 可低于 200ms |
| 高量成本敏感(10 万+ 查询/月) | Bright Data | $1–1.50/1k vs. Exa 的 $7–15/1k |
何时选择 Exa
以下情况 Exa 更合适:
- 你在做原型或早期研究。每月 1,000 次免费请求、原生 LangChain/LlamaIndex 支持、SDK 上手简单,使 Exa 成为给 AI 智能体增加网页搜索的最低摩擦路径。
- 你的核心用例是语义相似性。“找与这个 URL 类似的页面”是 Exa 的独特能力;如果这是你的主要搜索模式,选 Exa。
- 你需要结构化的人物/公司数据。Exa 的 10 亿+档案索引与 7000 万公司索引,确实为销售与招聘情报智能体专门构建。
- 延迟是首要约束。Exa Instant 的亚 200ms 响应,在实时交互应用上优于任何实时抓取方案。
- 你的查询量低于每月 50,000–100,000 次,并且不需要真实 Google 数据或访问受保护页面。
何时选择 Bright Data
以下情况 Bright Data 更合适:
- 你在生产规模运行。无限并发请求与 99.9% uptime SLA 意味着无需为速率限制做工程绕路。
- 你需要真实 Google 结果。SERP API 实时抓取 Google(以及 Bing、Yandex、Baidu、Yahoo、Naver、DuckDuckGo),支持任意国家,返回真实用户所见,而不是神经索引估计。
- 你的智能体需要访问受保护页面。Web Unlocker 处理 Cloudflare、CAPTCHA、登录页与 JS 渲染;Exa 做不到。
- 你需要历史数据。Web Archive API 提供 50PB+ 历史数据,用于基线 grounding 与纵向分析。
- 规模化成本很关键。当每月 10 万+请求时,Bright Data 比 Exa 便宜约 5–7 倍。
- 你在构建企业级系统。20,000+ 客户、《财富》500 强采用、Gartner 认可与70+ AI 框架集成,意味着 Bright Data 能融入既有企业数据栈。
结论:两种不同工具,分别适配两类不同任务
Exa 与 Bright Data 并不是在竞争同一类任务。
Exa 在其设计目标上非常出色:语义神经搜索、快速开发者接入、以及针对人物与公司的专用索引。如果你需要寻找概念相似页面、探索语义邻域,或搜索 10 亿+ LinkedIn 档案,Exa 的架构非常适合。
Bright Data 面向的是另一组问题:在生产规模下访问实时网页的真实事实,包括那些会拦截爬虫工具的网页部分。SERP API 以 $1.50/1k 的价格提供真实 Google 结果且无并发上限;Web Unlocker 能访问 Exa 的抓取无法触达的页面;Web Archive 提供实时 API 无法提供的历史基线。
决策框架如下:
- 如果你的智能体需要语义相似页面、搜索 10 亿+档案、或在 200ms 内返回答案,Exa 就是为此设计的。
- 如果你的智能体需要生产规模、真实 Google 数据、反爬虫访问能力、历史基线,或在每月 10 万+查询时的成本效率,Bright Data 是正确的基础设施。
很多生产级 AI 团队会两者并用:在流水线早期用 Exa 做语义发现,在规模化阶段用 Bright Data 做实时验证、整页内容提取与 SERP 情报。它们并不互斥,只是天花板不同——在企业规模下,Exa 的天花板会很快显现。对于正在评估AI 工作流的顶级 MCP Servers的团队,Bright Data 的 MCP Server 通常被评为将智能体落地到实时网页数据中的领先选择。
常见问题
Bright Data 和 Exa 有什么区别?
Exa 是语义搜索引擎 API,返回来自其自有神经索引的结果。Bright Data 是网页数据基础设施:抓取真实搜索引擎、提取受反爬虫保护的页面,并提供历史数据集。两者解决的问题不同、适配规模也不同。
Bright Data 比 Exa 更便宜吗?
是的。Bright Data 的 SERP API 按量付费起价为 $1.50/1,000 请求。Exa 标准搜索为 $7/1,000 请求。在每月 100 万次请求规模下,Bright Data 大约便宜 5–7 倍。
Exa 能抓取 Cloudflare 保护的网站吗?
不能。Exa 无法抓取受 Cloudflare、登录墙或 CAPTCHA 系统保护的页面。Bright Data 的 Web Unlocker 专为绕过反爬虫保护而构建,依托 150M+ 住宅 IP 网络。
Exa 有速率限制吗?
有。Exa 默认 /search 速率限制为 10 QPS(每分钟 600 次请求)。企业客户可谈更高额度。Bright Data 的 SERP API 没有并发请求限制。
对企业 AI 智能体来说,最好的 Exa 替代方案是什么?
Bright Data 是领先的企业级 Exa 替代方案:提供无限并发请求、实时抓取 Google/Bing/Yandex、通过 Web Unlocker 绕过反爬虫保护、历史数据归档,并支持基于 MCP 的 AI 智能体工作流,同时采用按成功计费模式。
Exa 有历史数据吗?
没有。Exa 只提供实时数据,没有归档或数据集产品。Bright Data 的 Web Archive API 拥有 50PB+ 历史网页数据并持续每日增长。



高级 SEO 专家
 6 years experience
6 years experience
Daniel Shashko 是 Bright Data 的高级 SEO/GEO 专家,专注于 B2B 营销、国际 SEO,以及开发 AI 驱动的代理、应用与网页工具。



