

当网站更改其标记或开始屏蔽你时,网页爬虫工具就会失效。brightdata-scrape Kiro Power 会根据一条自然语言提示编写一个爬虫工具,并将其对接到 Bright Data 的 Web MCP 运行,由后者处理解锁与解析。本指南将一个可复用的 Power 模式应用到 4 个用例中,其中 2 个会一路带到真实 API 运行,包括一个用于检查 ChatGPT 是否提及你的品牌的用例。
TL;DR
到最后你将拥有一个 Power 模式,可以指向 4 个用例;每个用例都由一条自然语言提示驱动,其中 2 个会一路带到真实 API 运行:
- 零售价格追踪器,在 Amazon 和 Walmart 上跟踪同一款产品。
- 品牌可见性监控器,查看哪些 AI 助手提及你的品牌。
- LinkedIn 线索生成流水线,监控潜在客户列表的职位变动。
- Crunchbase 情报控制面板,为每家公司拉取数十个实时字段。
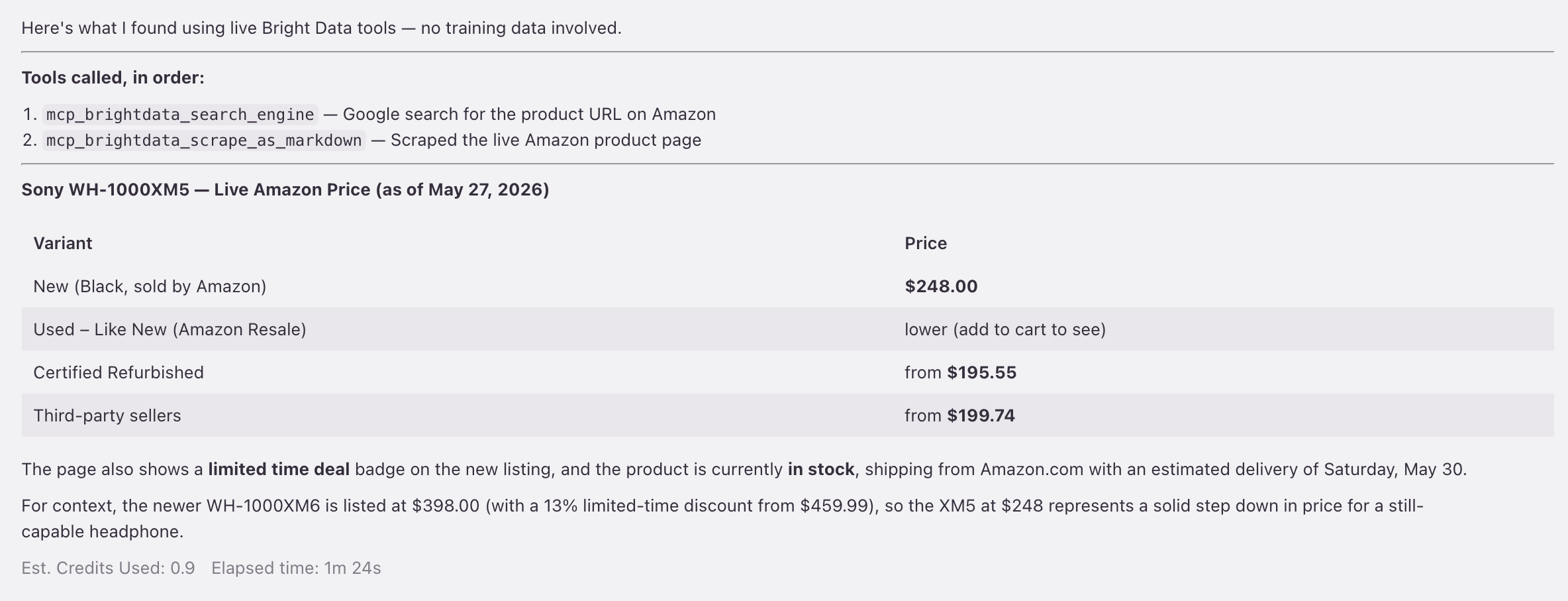
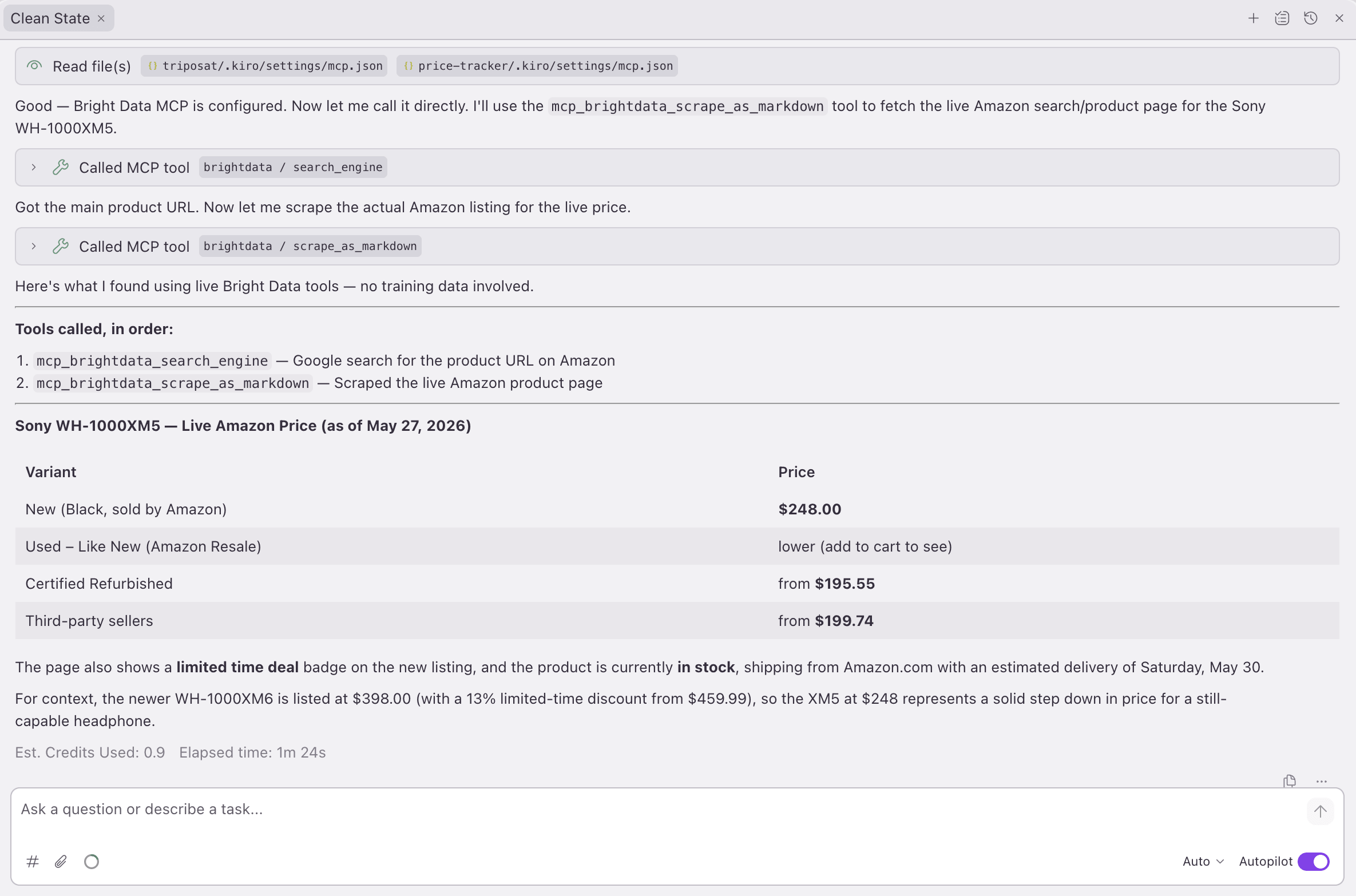
Kiro 代理发起 2 次实时工具调用,先 search_engine,再 scrape_as_markdown,并返回真实的 Amazon 价格 $248。
什么是 Kiro Power?
Kiro 是 AWS 构建的 AI IDE。Power 是 Kiro 自己的扩展格式:一个包含清单、MCP 服务器配置、引导文件和代码模板的文件夹。Kiro 只有在你的提示激活它时,才会将 Power 加载到上下文中。浏览 kiro.dev/powers 上的官方目录。Bright Data 在 GitHub 上单独发布 brightdata-scrape,因此你可以直接导入。
Power 与 Claude 技能 的一个重要区别是:每个 Power 都自带已配置好的 MCP(Model Context Protocol)服务器配置。因此代理获得的是可调用的新工具,而不仅仅是指令。对于 brightdata-scrape,该服务器就是 Bright Data 的 Web MCP。
该端点为你提供 网络解锁器、搜索引擎 API、Browser API,以及 Bright Data 预构建的数据集目录。Bright Data 的 MCP 让代理在一次工具调用中使用其中任意一个。这些工具(search_engine、scrape_as_markdown、50 个 web_data_* Pro 工具、scraping_browser_* 和 discover)用一套凭据和一种重试模式,替代了过去需要 3 个独立集成(代理、搜索引擎 API 和浏览器集群)的方案。
安装 brightdata-scrape Kiro Power
设置项目并确认连接共有 5 个步骤:
- 获取 Bright Data API token。 在 用户和 API 密钥 → API keys 下,添加一个具有 User 权限的 key,设置过期时间,并复制其值。免费层无需信用卡。
- 安装 Kiro,然后创建并打开项目。 下载并安装 Kiro。Power 需要在一个项目中工作,本指南使用 Next.js,因此创建一个项目并在 Kiro 中打开
price-tracker文件夹:
npx create-next-app@latest price-tracker \
–typescript, app, tailwind, src-dir, use-npm
cd price-tracker
你现在不需要安装任何其他东西。Kiro 会在第 3 阶段根据生成的爬虫工具需求再添加所需的包。
- 安装 Power。 在 Kiro 中打开 Powers 面板(左侧活动栏中的图标)。点击 Add Custom Power,然后点击 Import power from GitHub,再粘贴这个 URL:
https://github.com/brightdata/kiro-powers/tree/main/brightdata-scrape
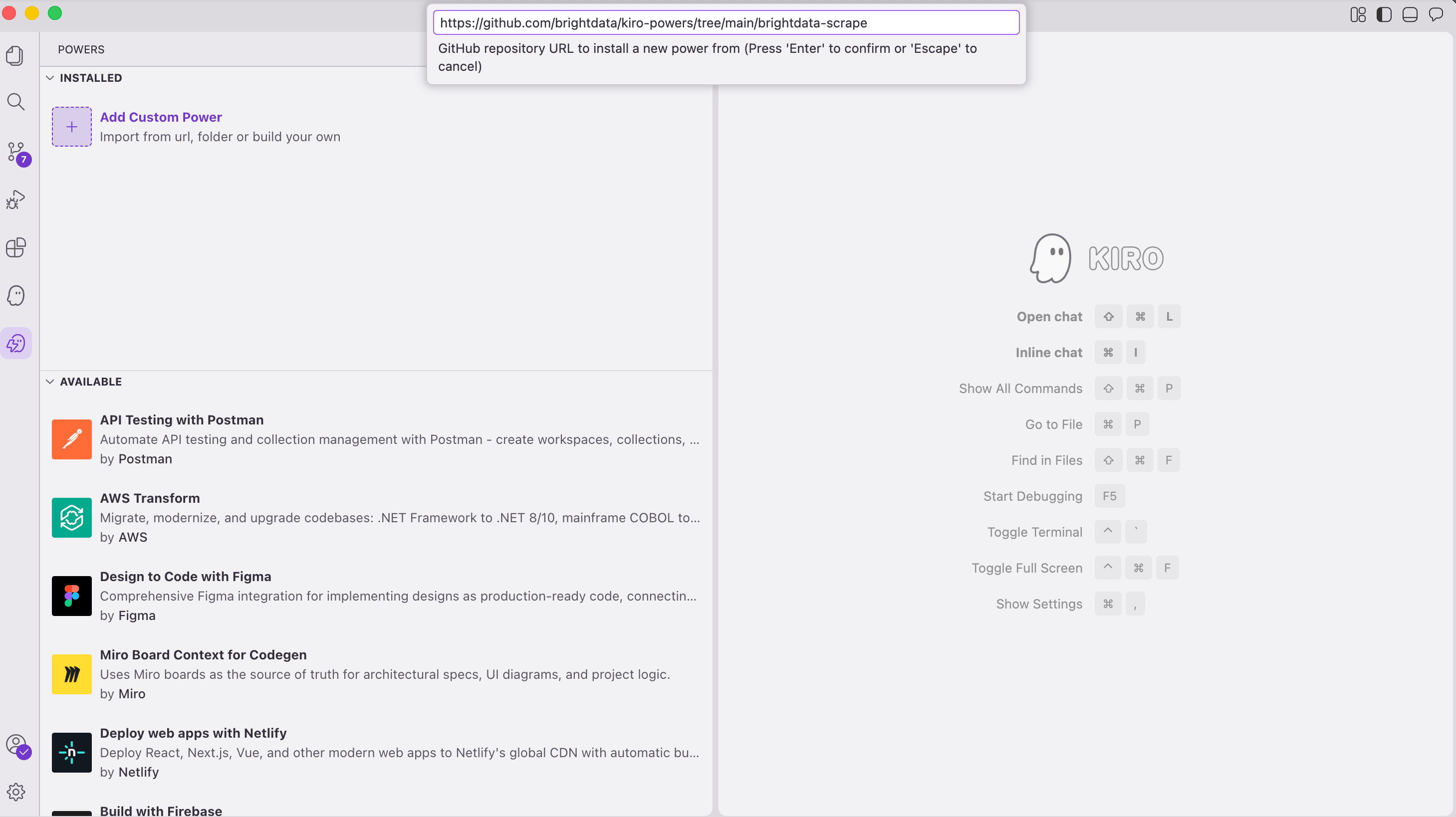
- 把 token 提供给 Kiro。 安装 Power 会在你项目的
.kiro/settings/mcp.json中添加一个名为brightdata的服务器,URL 为https://mcp.brightdata.com/mcp?token=${BRIGHTDATA_API_KEY}。打开该文件,将${BRIGHTDATA_API_KEY}替换为你在步骤 1 复制的字面 token,并保存。 然后把.kiro/settings/mcp.json加入.gitignore,确保 token 永远不会被提交。
为什么要用字面 token,而不是
${…}占位符? Kiro 目前不会在mcp.json中展开${VAR}(这是一个 已知的未解决问题),因此占位符会导致你看到Connection Failed/HTTP 404,而不是成功连接。
- 确认连接。 重新打开 MCP Servers 面板。几秒后,
brightdata会显示 Connected,其工具列表中包含search_engine和scrape_as_markdown,这就是你需要的信号。

现在在项目根目录创建 .env.local,并把同一个 token 放进去。你故意粘贴两次 token:.kiro/settings/mcp.json(步骤 4)中的那份用于在构建时将 Kiro 连接到 Bright Data,而这份会在运行时被 生成的应用 读取。
BRIGHTDATA_API_KEY=... # the token you generated above
BRIGHTDATA_UNLOCKER_ZONE=... # placeholder is fine for the retail build; set before a Web Unlocker use case在全新账户上,或者在你运行 网络解锁器 用例之前,先设置你的 区域 名称。请参阅下方 将全部 4 个用例扩展到生产环境 中的 Set your 网络解锁器 区域。
在全部 4 个用例中,只有提示会变化;4 阶段工作流保持不变。
Kiro 的 4 阶段工作流(适用于全部 4 个用例的一个模式)
Power 对每条提示都会运行相同的 4 个阶段。每个阶段在继续之前都会等待你的批准:
- 检测与规划。 Power 检查工作区清单(
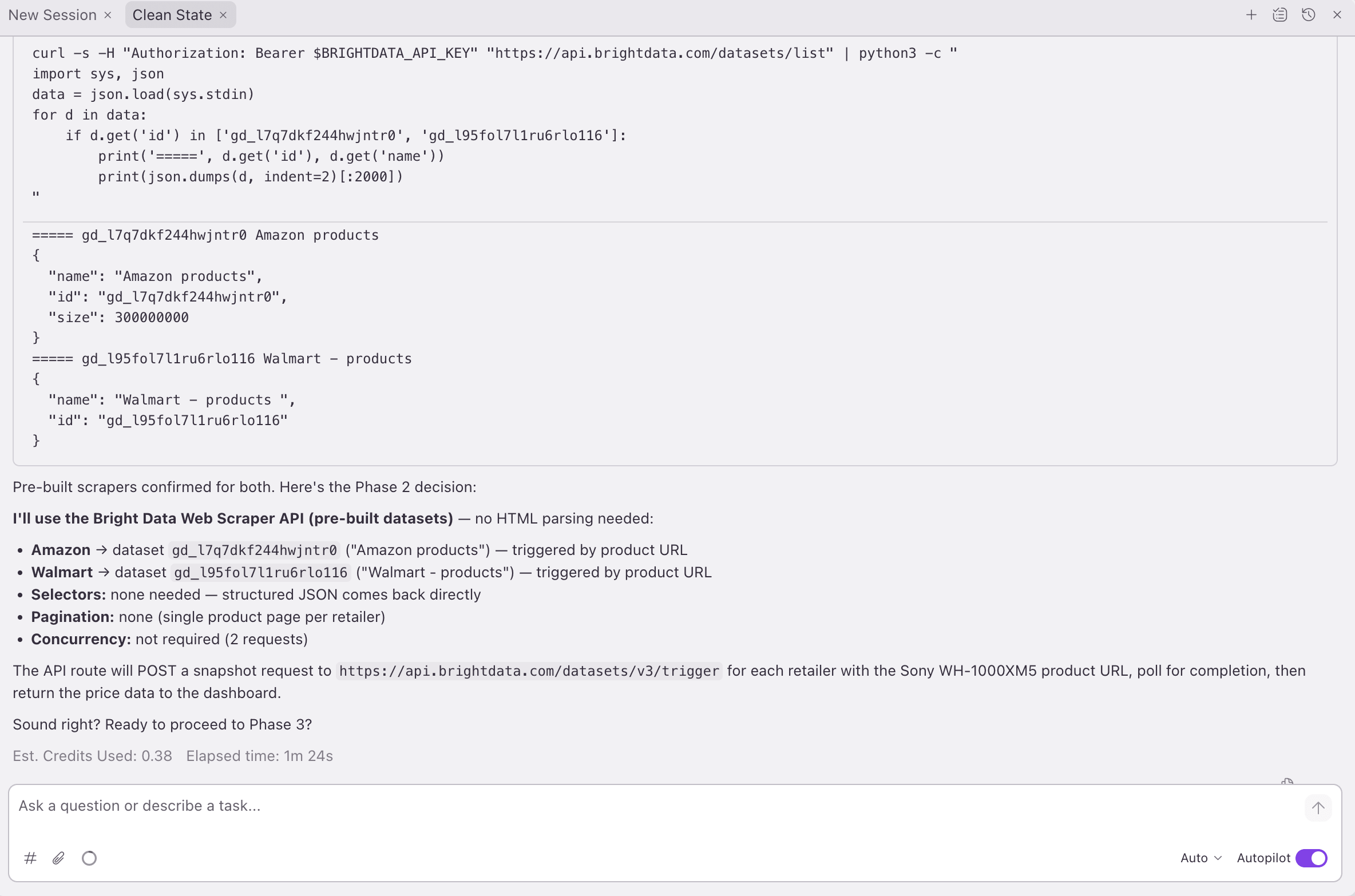
package.json、pyproject.toml、Cargo.toml、go.mod等)以及其中的依赖。然后它选择如何集成:如果发现 Web 框架,就生成一个 API 路由;如果发现 agent SDK,就生成一个 agent 工具;如果项目是一个库,就生成一个模块。它会问你要抓取什么以及要抓取多少条。 - 抓取 playbook。 Power 检查 Bright Data 的工具阶梯,并针对每个目标站点选择你当前套餐允许的最佳路径:Web Data Pro 工具(30+ 平台上的 50 个
web_data_*工具之一,字段有类型,需要&pro=1)→ 数据集触发器(相同数据,轮询,不需要&pro=1)→ 网络解锁器(用于长尾站点的代理 + 解析)→ Browser API(登录/点击流程)→ 搜索引擎 API(搜索结果)。
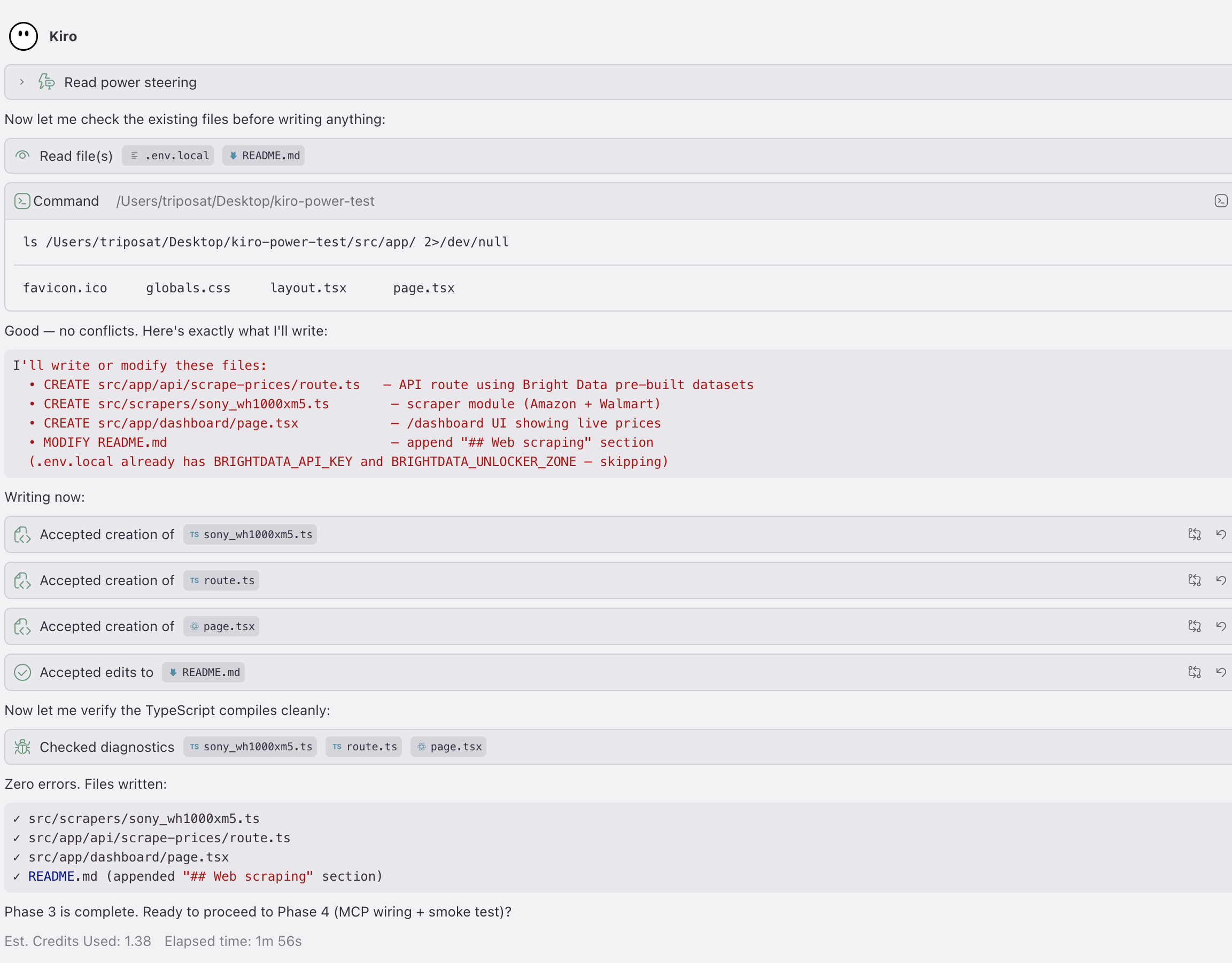
- 集成。 Power 生成文件。下面的零售运行生成了 4 个文件:一个爬虫工具模块、一个 API 路由、一个控制面板页面,以及在
README.md中新增的## Web scraping小节。(.env.local已经有 API token,所以第 3 阶段跳过了它。这就是文件安全规则:它不会覆盖已存在的文件。)
- MCP 与验证。 Power 将 Bright Data 的 MCP 服务器合并到
.kiro/settings/mcp.json,并对目标 URL 运行一次冒烟测试。本阶段会运行两项生产级防护:覆盖前先 diff,以及 FAIL → ITERATE 恢复。用例 1 的第 4 阶段完整展示了该恢复过程。
实时运行了什么,以及展示了什么
这里的一切都已针对真实 API 验证,而不是 mockup。 精确的价格、工具与耗时来自具体的捕获运行。由于这些爬虫工具读取的是实时数据,你自己的结果将反映当前价格、页面与模型回答,而不是这些捕获结果。
- 用例 1 和 4 完整对真实 API 运行: 零售(零 Pro 花费)与 Crunchbase(Pro 套餐)。下方每一张零售截图都来自该运行,用例 4 的完整代码也在其章节中。
- 用例 2 和 3 为展示而非重建: 提示、第 2 阶段会选择的工具,以及我们已针对每个工具实时验证过字段名的字段形状。它们复用用例 4 的
callMcpTool客户端,因此无需重复粘贴几乎相同的代码。 - 用例 2、3 和 4 在 Pro 模式(
&pro=1)下运行, 下方的“扩展到生产环境”会覆盖这一点。
用例 1:多零售商价格追踪
这是给 Kiro 的提示:
Prompt to Kiro: “Add a price-comparison agent that scrapes Sony WH-1000XM5 prices from Amazon and Walmart.”
第 2 阶段的选择:在捕获的零 Pro 运行中,Power 选择了数据集触发器路径(相同数据,轮询)。如果使用 &pro=1,它会改为选择 Pro 工具 web_data_amazon_product 和 web_data_walmart_product。
扩展到更多零售商:同一模式可以通过用更广的零售商列表重新提示 Kiro 来添加 web_data_ebay_product、web_data_homedepot_products 和 web_data_bestbuy_products。某些零售商(Best Buy、Target)通常需要在 区域 上启用 Premium domains;在捕获运行中,Amazon 和 Walmart 不需要。
Kiro 生成的架构
控制面板在挂载时拉取 API。API 并行调用 Bright Data 的数据集触发器并返回结构化记录。
Browser opens /
│
▼ (auto-fetch on mount)
GET /api/scrape-prices
│
▼
src/scrapers/price-tracker.ts
fetchAllPrices()
│
▼ (Promise.allSettled, parallel)
┌────────────────────────────────────┐
│ Bright Data Datasets API │
│ gd_l7q7dkf244hwjntr0 → Amazon │
│ gd_l95fol7l1ru6rlo116 → Walmart │
└────────────────────────────────────┘*一条读取路径:控制面板 → API 路由 → 爬虫工具模块 → 2 个 Bright Data 数据集触发器。使用 &pro=1 时,爬虫工具模块变为直接的 web_data_ MCP 调用,而客户端轮询循环会移动到 MCP 服务器中。*
爬虫工具模块
src/scrapers/price-tracker.ts 保存数据集 ID、一个 triggerAndPoll 辅助函数,以及一个 normalise 步骤,用于将 Bright Data 的响应扁平化为一致的 PriceResult 形状。下面是该文件的核心部分,完整文件约 85 行:
// src/scrapers/price-tracker.ts (excerpt)
const BASE = "https://api.brightdata.com/datasets/v3";
const DATASETS = { Amazon: "gd_l7q7dkf244hwjntr0", Walmart: "gd_l95fol7l1ru6rlo116" } as const;
async function triggerAndPoll(datasetId: string, url: string) {
// 1. POST trigger with the target URL
const trigger = await fetch(`${BASE}/trigger?dataset_id=${datasetId}&include_errors=true`, {
method: "POST",
headers: { Authorization: `Bearer ${process.env.BRIGHTDATA_API_KEY}`,
"Content-Type": "application/json" },
body: JSON.stringify([{ url }]),
});
const { snapshot_id } = await trigger.json();
if (!snapshot_id) throw new Error("no snapshot_id returned from trigger");
// 2. Poll the snapshot endpoint (in-progress = HTTP 202; ~120 s cap)
for (let i = 0; i < 24; i++) {
await new Promise((r) => setTimeout(r, 5000));
const res = await fetch(`${BASE}/snapshot/${snapshot_id}?format=json`,
{ headers: { Authorization: `Bearer ${process.env.BRIGHTDATA_API_KEY}` } });
if (res.status === 202) continue;
return await res.json();
}
throw new Error("snapshot timed out after 120s");
}
// triggers both retailers in parallel; Promise.allSettled isolates errors per retailer,
// so one bad snapshot doesn't fail the other. The full file maps each settled result
// into a PriceResult (rejected ones carry an `error` field).
export async function fetchAllPrices() {
return Promise.allSettled(
Object.entries(DATASETS).map(([retailer, id]) =>
triggerAndPoll(id, PRODUCT_URLS[retailer]).then((r) => normalise(r[0], retailer, PRODUCT_URLS[retailer]))),
);
}Kiro 的聊天是一个实时 MCP 客户端,而不是记忆查找
在构建过程中,Kiro 的聊天面板会与代码调用的同一个 brightdata 服务器通信。当被问到 Sony 的价格时,聊天并不是从模型记忆中回答。它发起了实时的 search_engine 和 scrape_as_markdown 调用,并返回了一张表($195.55 翻新到 $248 全新,外加一个 $398 的 XM6 对比):
聊天是你在构建时探索的方式。下面的控制面板才是你的终端用户看到的内容。
控制面板
Kiro 生成的首页路由(/)将 API 返回的 JSON 渲染为 2 张彩色卡片(Amazon 橙色、Walmart 蓝色),并用一个绿色的“Best price”横幅选出两者中更便宜的那个:
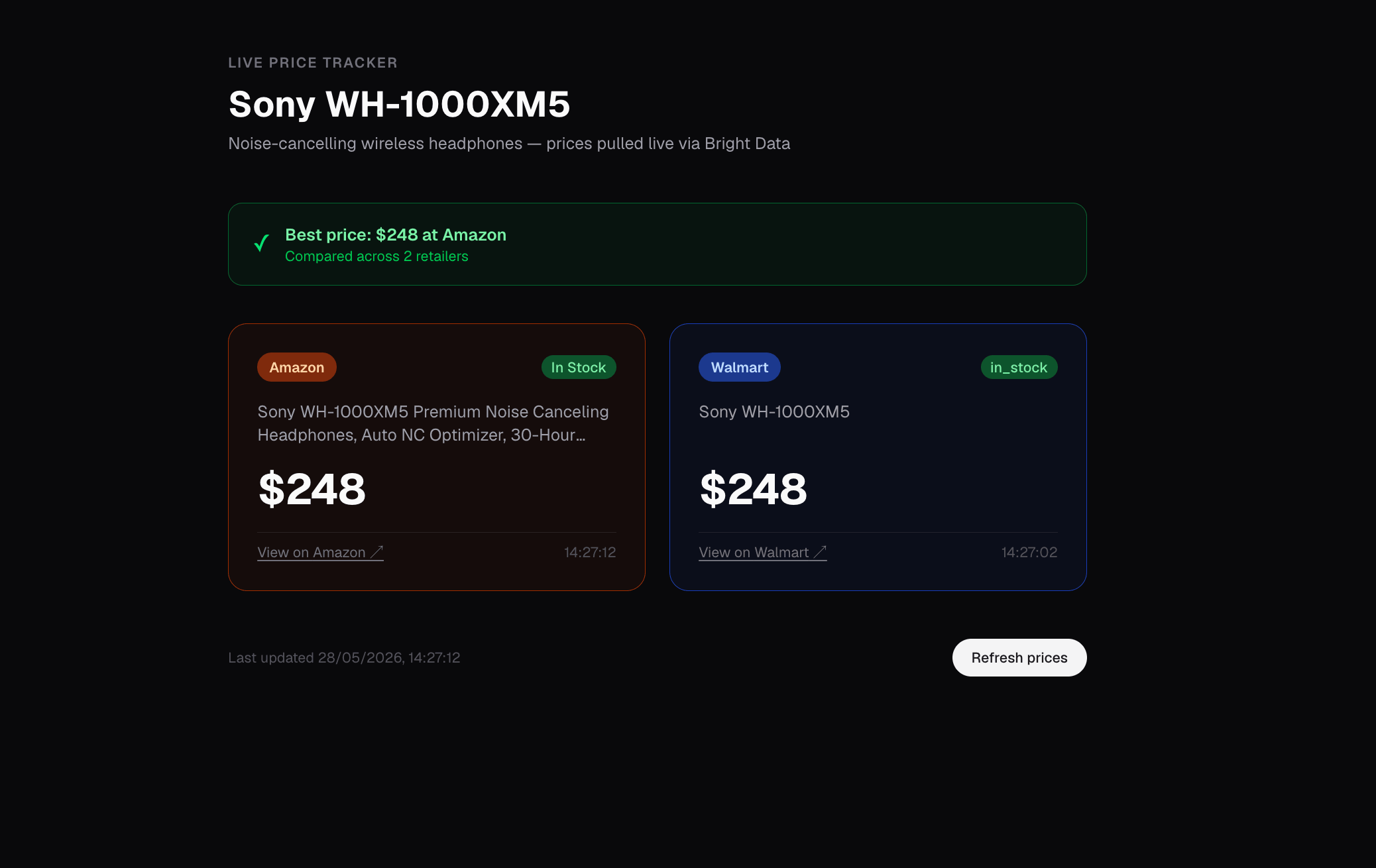
首页路由(/)视图。Sony WH-1000XM5 在 Amazon 和 Walmart 上均为 $248,并显示产品标题、库存状态以及每个零售商的时间戳,这些都直接从各自来源读取。Walmart 的原始 in_stock 与 Amazon 的 In Stock 会原样透传,因此你看到的就是每个来源返回的内容。构建告警时请归一化到你自己的 schema。
如果你自己检查原始页面,Amazon 的明显价格选择器(span.a-price-whole)通常返回空值,真正的选择器是 .a-price .a-offscreen。Walmart 根本不会把价格放在渲染后的 HTML 中;它位于 <script id="NEXT_DATA"> 的一个 JSON blob 里。上面的数据集触发器跳过了这两个问题,因为 Bright Data 在服务端解析页面并返回带类型的字段。
第 4 阶段:当 URL 漂移时的自愈
第 4 阶段是当冒烟测试失败时 Power 自动运行的恢复例程。在捕获运行中,Amazon 返回了干净的数据($248, In Stock),但 Walmart 返回的每个字段都为 null。Kiro 没有宣告成功。相反,它读取了原始记录的 error 键("dead page (404)"),调用 search_engine 找到当前的 Walmart URL,重新触发数据集,并在轮询卡住时切换到 scrape_as_markdown(返回 $248,与 Amazon 匹配)。然后它修补了生成的爬虫工具:

第 4 阶段检测到失效的 Walmart URL,找到可用的新 URL,并自行修补爬虫工具。18 分 54 秒包含了重新轮询的数据集任务,4.5 credits 是一次性的构建阶段成本,而不是运行时成本。
恢复循环能捕获抛错或返回 null 字段的失败(失效 404、页面重设计、快照错误)。但它无法捕获这样一种情况:URL 仍可解析,但指向了错误的产品。例如,一个 walmart.com/ip/... ID 悄然从 Sony 耳机变成了 PS5 列表,会为错误产品返回有效数据。要捕获这种情况,你需要基于搜索驱动的 URL,而不是硬编码 ID(下方的生产扩展章节会覆盖)。
跨第 2、4 阶段的捕获成本(截图中均可见):0.38 → 1.38 → 4.5 credits(累计总计)。这些是 Kiro IDE 的构建时 credits,是代理在编写代码时的用量,与 Bright Data 计费分开。因此这次捕获运行总计花费 4.5 credits,但其中大部分来自一次性的第 4 阶段自愈。没有恢复的干净构建大约是 2 credits(估算,因为我们没有捕获一次无自愈的运行)。
生产级防护:自愈、无静默覆盖、CI 验证的模板
在用例 1 中,第 4 阶段捕获了一个失效的 Walmart URL,并拒绝宣告成功。这种行为不是每次运行临时发挥出来的。它来自 Power 的 引导文件 中内置的生产规则。以下是这些规则的完整集合:
- 文件安全(第 3 阶段)。 Power 不会覆盖现有的爬虫工具(它会建议
_2.ts),会向README.md/.env.example追加而不是替换,并在写入前展示 CREATE/MODIFY 列表。 - MCP 配置合并(第 4 阶段)。 Power 会检测
.kiro/settings/mcp.json中是否已有brightdata条目;如果 URL 不同,会展示 diff 并在替换前询问,因此不会发生静默覆盖。 - 冒烟测试 FAIL → ITERATE。 连接 MCP 后,Power 会针对你的目标运行爬虫工具。若结果为空、为 null 或报错,引导文件逐字写明:“return to Phase 2… Do not declare success.”
- CI 测试过的模板(49 个测试通过)。
validate_power.py和test_validate_power.py检查 frontmatter、MCP 配置、引导文件与模板是否存在。它们不会针对真实站点测试生成代码;那是第 4 阶段冒烟测试在每个项目中的职责。 - 自动 区域 预配置。 MCP 服务器会调用
/zone/get_active_zones并在首次运行时创建缺失的 区域,因此新账户无需先手动创建 网络解锁器 区域。
用例 2:GEO 品牌可见性监控器
可见性问题。 买家在联系销售之前,越来越多地会在 LLM 答案页(ChatGPT、Grok、Perplexity)上形成候选清单,因此不在前 3 意味着很多买家可能永远看不到你。问题在于传统的品牌监测工具(PR、社媒聆听、SEO)并不是为监控 LLM 答案而构建的,因此你无法可靠地看到自己的排名位置。
Prompt to Kiro: “Add a brand-visibility monitor that scrapes how ChatGPT, Grok, and Perplexity answer my 5 priority buyer queries, and alerts me when my brand stops being mentioned.”
GEO 工具及其返回内容
该用例的 Pro 工具:第 2 阶段会选择 geo 组:web_data_chatgpt_ai_insights、web_data_grok_ai_insights 和 web_data_perplexity_ai_insights。每个工具就是其引擎(没有引擎选择器),接收一个 prompt 参数,并将渲染后的 LLM 答案以 markdown 返回。每个引擎一个工具,你就覆盖了买家今天使用的 3 个主要答案页,而不仅仅是 ChatGPT 的。
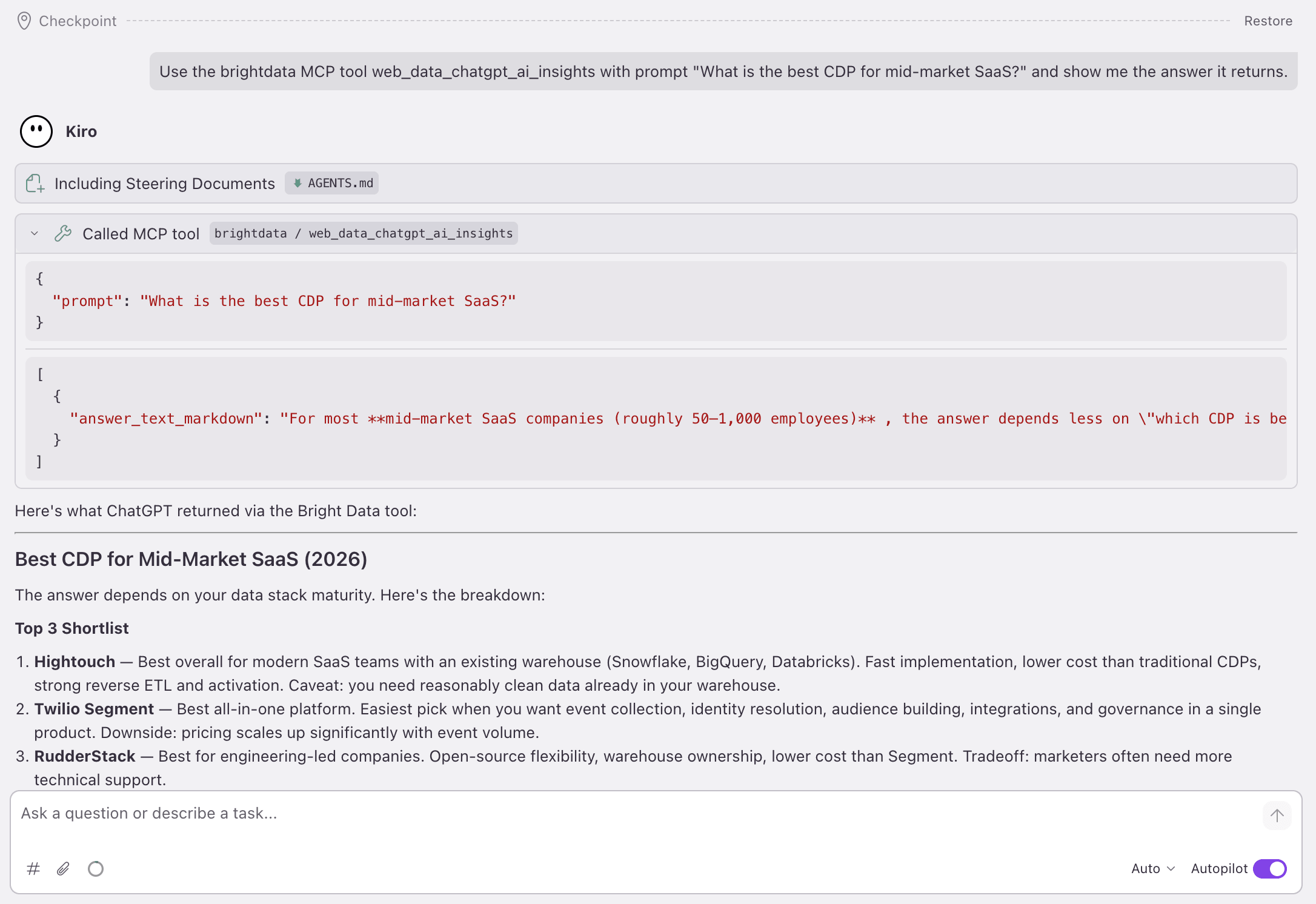
第 3 阶段生成 一个 src/scrapers/brand_visibility.ts 模块,它用单个 { prompt } 调用每个 web_data_* 工具,并收集其 answer_text_markdown。ChatGPT 与 Perplexity 会以内联方式返回,并在 Promise.all 下并行运行。Grok 通常会超过 MCP 轮询窗口并异步返回,因此它保持在单独的非阻塞路径上;将其视为最终一致,而不是阻塞调用。
这是实时响应形状, 直接从 web_data_chatgpt_ai_insights 与 web_data_perplexity_ai_insights 捕获,提示为 “What is the best CDP for mid-market SaaS?”,两者都返回了相同的单字段形状(Grok 的异步调用超过了 9 分钟轮询):
{
"answer_text_markdown": "For most **mid-market SaaS companies (roughly 50,1,000 employees)**, the answer depends less on \"which CDP is best\" than on your data-stack maturity. My ranking: 1) [Hightouch](https://hightouch.com?utm_source=chatgpt.com) , warehouse-native; 2) [Twilio Segment](https://segment.com?utm_source=chatgpt.com) , all-in-one; 3) [RudderStack](https://www.rudderstack.com?utm_source=chatgpt.com) , engineering-led..."
}该工具将模型答案作为单个 answer_text_markdown 字符串返回,而不是预解析的品牌排名。品牌提取步骤由你完成。一个天真的第一种方法是对 markdown 做一次 includes() 检查,但它会漏掉大小写、名称变体以及你的品牌出现在另一个词内部的情况。任何真实使用场景下,都应将 markdown 传给一次便宜的 LLM 调用,并让它输出排序后的列表。
告警循环以及由谁安装
告警循环如下:它每天为每个引擎存储 1 行 answer_text_markdown,然后提取你的品牌是否出现(以及出现位置),接着在你的品牌从曾经出现过的答案中消失时告警,最后渲染一个包含 3 个引擎的今日答案网格,并带有品牌出现标记。
在你接入告警之前有一个注意事项:LLM 答案是非确定性的,因此同一提示在不同运行中可能会对品牌给出不同排序。每天一次抓取只是一个样本,而不是稳定信号,因此品牌某一天掉出榜单往往是噪声,而不是真实变化。对每个提示多采样几次,或在数天内做平滑处理,再将掉出视为真实。
由谁安装:这适用于 B2B SaaS 市场与 DevRel 团队、增加 LLM 覆盖的品牌监测机构,以及跟踪模型输出漂移的 AI/ML 研究人员。用量约为 5 个提示 × 3 个引擎每日轮询,即约 450 次调用/月,按按量计费约 $0.68/月。
用例 3:LinkedIn 线索生成流水线
B2B 的问题是:你必须跟踪 50 个销售潜在客户(或候选人、或合作伙伴项目联系人)的职位变动、公司变动或晋升。常见方案是 LinkedIn Sales Navigator 加上手动审查工作流。结构化数据方案是:每个潜在客户每天轮询 1 次 MCP 调用。
Prompt to Kiro: “Watch these 50 LinkedIn prospects for job changes, company moves, or promotions. Notify my CRM when anything changes.”
LinkedIn 工具及其返回内容
该用例的 Pro 工具。 第 2 阶段会选择 social 组中的 LinkedIn 集群:web_data_linkedin_person_profile、web_data_linkedin_company_profile、web_data_linkedin_job_listings 和 web_data_linkedin_people_search。
以下是第 3 阶段生成的内容(字段名已针对工具实时验证):
// src/scrapers/linkedin_prospects.ts (excerpt)
import { callMcpTool } from "@/lib/mcp-client"; // Kiro generates this MCP-client call in Phase 3 , not an installable package
interface ProspectSnapshot {
url: string;
current_company_name: string; // current_company is a nested object; *_name is the string
position: string; // job-title field , there is no "current_title"
location: string;
followers: number;
}
type Change = { field: string; from: string; to: string };
export const snapshotProspect = (url: string) =>
callMcpTool("web_data_linkedin_person_profile", { url }) as Promise<ProspectSnapshot>;
// Diff today vs. yesterday; emit a Change for any field that moved.
export function diffProspect(prev: ProspectSnapshot, now: ProspectSnapshot): Change[] {
return (["current_company_name", "position"] as const)
.filter((f) => prev[f] !== now[f])
.map((f) => ({ field: f, from: prev[f], to: now[f] }));
}完整记录会返回 30+ 个带类型的字段,包括 current_company(对象)、experience[]、education[]、about、followers、connections、city、country_code 等。
CRM 通知循环以及由谁安装
CRM 通知循环如下:它为每个潜在客户存储昨天的快照,然后由后台 worker 每天运行一次今天的抓取与 diff,接着将变更 POST 到你的 CRM webhook(Salesforce、HubSpot、Attio,而不是 Bright Data 的 MCP)。
由谁安装:这适用于 B2B 销售、招聘、RevOps 以及合作伙伴项目经理。用量约为 50 个潜在客户每日轮询,即约 1,500 次调用/月,按按量计费约 $2.25/月。
用例 4:竞争情报控制面板
企业并购与战略的问题是:团队必须跟踪一份竞争对手与收购目标的观察列表,关注融资轮次、员工人数变化与动量变化。常见基线是手动刷新 Crunchbase 并维护表格的工作流。结构化数据方案是:每家公司每周轮询 1 次 MCP 调用。
Prompt to Kiro: “Track these 30 competitors on Crunchbase. Alert me when any raises a round, crosses an employee-count band, or jumps in growth ranking.”
Crunchbase 工具及其返回内容
第 2 阶段选择的 Pro 工具:Power 选择 web_data_crunchbase_company(business 组)。经实时验证,它每家公司返回 93 个带类型的字段,包括 funds_raised、num_funding_rounds、acquisitions、exits、num_employees、cb_rank、growth_score、heat_score、founders、built_with_tech、ipo_status 和 region。
以下是第 3 阶段生成的内容:
// src/scrapers/competitor_intel.ts
import { callMcpTool } from "@/lib/mcp-client"; // Kiro generates this MCP-client call in Phase 3 , not an installable package
interface CompanySnapshot {
name: string;
num_employees: string; // band, e.g. "5001-10000"
cb_rank: number; // Crunchbase rank (lower = more prominent)
growth_score: number; // 0-100
heat_score: number; // 0-100 momentum signal
funds_raised: unknown[]; // array of funding/investment events
ipo_status: string; // "private" | "public" | ...
region: string;
url: string;
}
type Alert =
| { kind: "headcount_band"; from: string; to: string }
| { kind: "new_funding_event"; count: number }
| { kind: "growth_surge"; from: number; to: number };
// the MCP row arrives untyped, so you map just the fields you track into a typed CompanySnapshot
export async function snapshotCompany(url: string): Promise<CompanySnapshot> {
const row = await callMcpTool<Record<string, unknown>>("web_data_crunchbase_company", { url });
return {
name: String(row.name ?? ""),
num_employees: String(row.num_employees ?? ""),
cb_rank: Number(row.cb_rank ?? 0),
growth_score: Number(row.growth_score ?? 0),
heat_score: Number(row.heat_score ?? 0),
funds_raised: Array.isArray(row.funds_raised) ? row.funds_raised : [],
ipo_status: String(row.ipo_status ?? ""),
region: String(row.region ?? ""),
url,
};
}
export function detectMoves(
prev: CompanySnapshot, now: CompanySnapshot,
): Alert[] {
const alerts: Alert[] = [];
if (now.num_employees !== prev.num_employees) {
alerts.push({ kind: "headcount_band", from: prev.num_employees, to: now.num_employees });
}
if (now.funds_raised.length !== prev.funds_raised.length) {
alerts.push({ kind: "new_funding_event", count: now.funds_raised.length - prev.funds_raised.length });
}
if (now.growth_score - prev.growth_score >= 5) {
alerts.push({ kind: "growth_surge", from: prev.growth_score, to: now.growth_score });
}
return alerts;
}实时样本。 对 Stripe 调用 web_data_crunchbase_company 的真实结果返回了 num_employees: "5001-10000"、cb_rank: 300、growth_score: 98、heat_score: 60、ipo_status: "private"、region: "California",以及一个已填充的 funds_raised 投资事件数组。
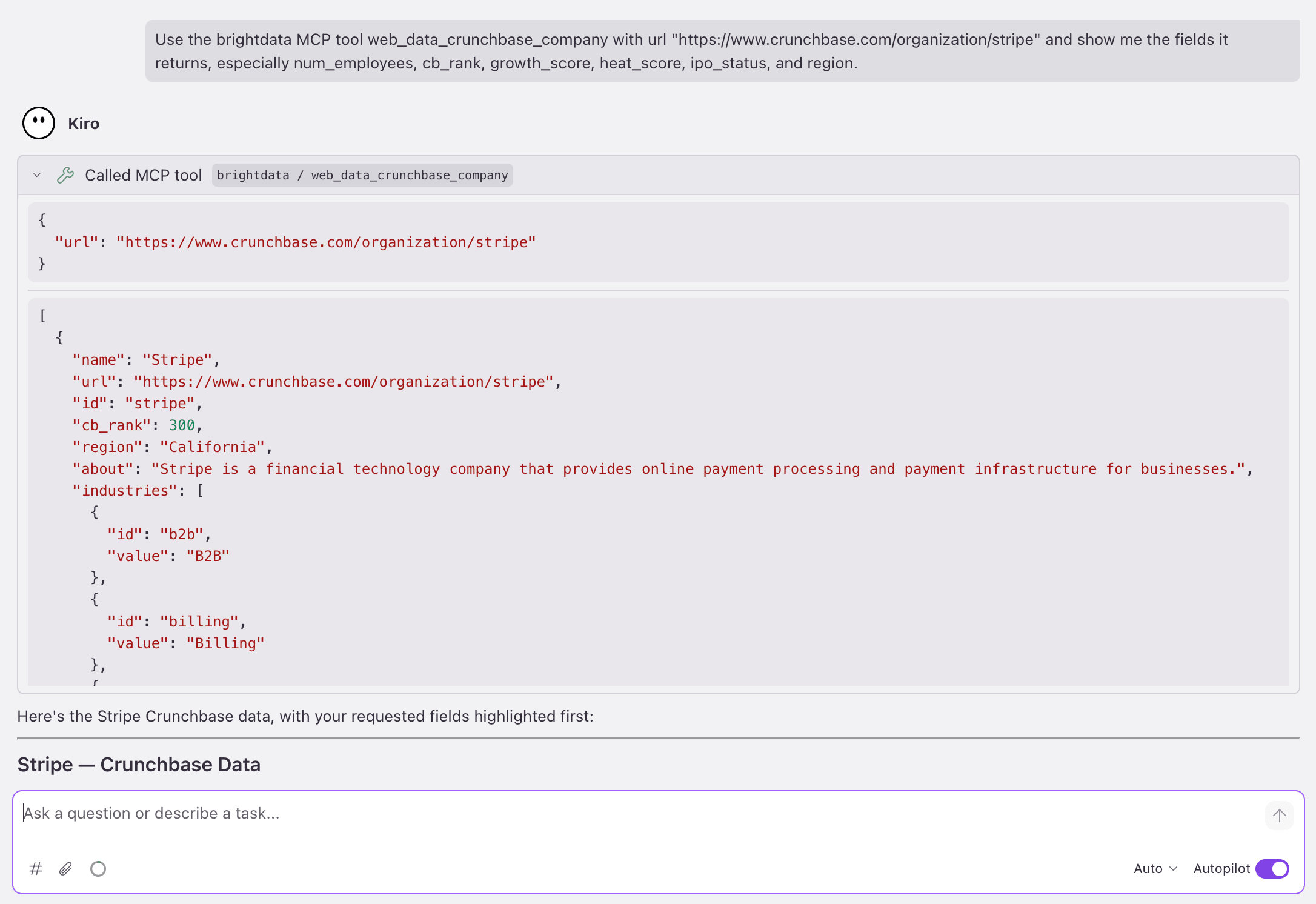
Power 生成了 4 个文件(上面的爬虫工具、下面的客户端、一个 API 路由、一个控制面板页面),且生成的代码以零 TypeScript 错误编译。设置好 BRIGHTDATA_API_KEY 后,将其对接到实时 MCP 运行(实时抓取约 58 秒)会返回上面的 Stripe 记录并渲染如下内容:
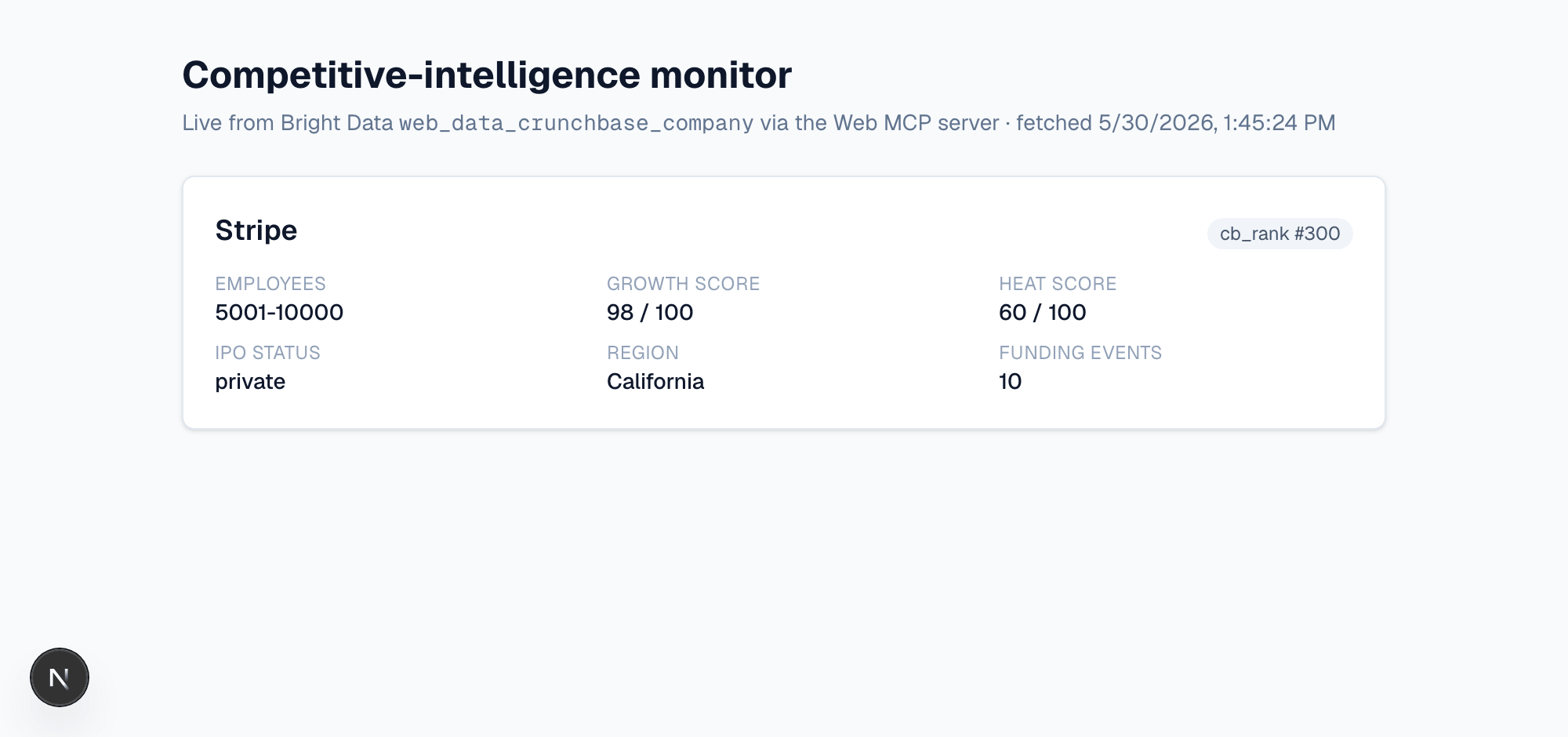
首页路由(/),由返回上述 Stripe 记录的同一次 web_data_crunchbase_company 调用实时渲染。
要自己运行它,克隆示例仓库:git clone https://github.com/triposat/crunchbase-intel-demo && cd crunchbase-intel-demo && npm install && cp .env.example .env.local,粘贴一个启用 Pro 的 token,然后运行 npm run dev。(&pro=1 已经在仓库的 mcp-client.ts 中;你只需要一个启用了 Pro 模式的账户。)
共享的 MCP 客户端
爬虫工具导入的 callMcpTool 是 Power 在第 3 阶段生成的一个轻量 MCP 客户端,GEO 与 LinkedIn 模块也被编写为复用它。完整如下:
// src/lib/mcp-client.ts , the client callMcpTool resolves to
const MCP_URL = `https://mcp.brightdata.com/mcp?token=${process.env.BRIGHTDATA_API_KEY}&pro=1`;
async function post(body: unknown, sessionId?: string) {
const headers: Record<string, string> = {
"Content-Type": "application/json",
Accept: "application/json, text/event-stream",
};
if (sessionId) headers["mcp-session-id"] = sessionId;
return fetch(MCP_URL, { method: "POST", headers, body: JSON.stringify(body) });
}
// the server replies as SSE: one JSON object per `data:` line
function parseSse(text: string) {
if (!text.includes("data:")) {
try { return [JSON.parse(text)]; }
catch { throw new Error(`MCP returned a non-JSON response: ${text.slice(0, 120)}`); }
}
return text.split("\n").filter((l) => l.startsWith("data:"))
.map((l) => { try { return JSON.parse(l.slice(5).trim()); } catch { return null; } })
.filter(Boolean);
}
export async function callMcpTool<T = unknown>(name: string, args: Record<string, unknown>): Promise<T> {
// 1. initialize , the session id comes back as a response header
const init = await post({ jsonrpc: "2.0", id: 1, method: "initialize",
params: { protocolVersion: "2024-11-05", capabilities: {}, clientInfo: { name: "intel", version: "1.0" } } });
if (!init.ok) throw new Error(`MCP connection failed: HTTP ${init.status} ${init.statusText}. Check BRIGHTDATA_API_KEY.`);
const sessionId = init.headers.get("mcp-session-id") ?? undefined;
await init.text();
// 2. confirm initialized, then 3. call the tool
await post({ jsonrpc: "2.0", method: "notifications/initialized", params: {} }, sessionId);
const res = await post({ jsonrpc: "2.0", id: 2, method: "tools/call", params: { name, arguments: args } }, sessionId);
if (!res.ok) throw new Error(`MCP tool call failed: HTTP ${res.status} ${res.statusText}.`);
const reply = parseSse(await res.text()).find((m: { id?: number }) => m?.id === 2);
if (reply?.error) throw new Error(`MCP error: ${reply.error.message}`);
const text = reply?.result?.content?.find((c: { type: string }) => c.type === "text")?.text;
const payload = text ? JSON.parse(text) : reply?.result;
return (Array.isArray(payload) ? payload[0] : payload) as T;
}把该文件放到 src/lib/ 中,上面的 Crunchbase 爬虫工具就可以运行了。
监控循环以及由谁安装
监控循环如下:它为每家公司存储上周的快照,然后将本周快照与上周快照做 diff,接着把任何融资事件、员工人数区间跨越或增长分数飙升发布到你的战略 Slack 频道。用量约为 30 家公司每周轮询,即约 120 次调用/月,按按量计费约 $0.18/月。
由谁安装:这适用于企业发展、竞争情报、战略、VC/PE 交易团队,以及构建账户情报的销售代表。这些团队需要的是数据深度而非零售规模,因为他们希望每家公司获得 93 个结构化字段,否则就得手动收集。
将全部 4 个用例扩展到生产环境
生成的爬虫工具以零 TypeScript 错误编译,并对接真实 API 运行(上面的零售与 Crunchbase 运行),且具备上述防护。以下变更将它们扩展到生产规模,加入真实工作负载所需的后台任务、快照表与吞吐设置:
- 切换到 Pro 工具。 在
.kiro/settings/mcp.json中将&pro=1追加到 MCP URL,使其变为https://mcp.brightdata.com/mcp?token=<your-token>&pro=1,并重启服务器。(注意前导&,因为token=已经开启了 query string。)第 2 阶段会选择web_data_*工具而不是数据集触发器。轮询通常会降到秒级,解析变为读取带类型字段。该标志需要放在 2 个位置:.kiro/settings/mcp.json,让 Kiro 的代理看到 Pro 工具;以及生成应用的src/lib/mcp-client.ts,让运行中的应用调用它们。 - 设置你的 网络解锁器 区域。 网络解锁器 路径读取
BRIGHTDATA_UNLOCKER_ZONE,而你的 区域 具有账户特定名称(web_unlocker、mcp_unlocker、web_unlocker1等)。在你的 Web Access 控制面板 中找到确切名称,并在.env.local中设置。名称不匹配会返回带zone not found的 HTTP 400。在全新账户上,在 MCP 服务器首次调用自动预配置 区域 之前,该表可能为空。如果出现 2 个 区域,选择标记为 Free tier 的那个。 - 将轮询移出请求路径。 在我们的运行中,单记录
web_data_*触发器大约在 10,90 秒返回,多记录则需要数分钟。延迟会变化,而像 Grok 这样的 LLM 答案工具可能会远超轮询窗口。MCP 服务器会在超时前持续轮询数分钟(POLLING_TIMEOUT环境变量设置上限)。在生产环境中,应从后台 worker(Vercel Cron、Inngest、Trigger.dev)运行触发器并写入快照表。控制面板从表中读取,而不是实时抓取。(MCP 之外的直接 数据集 API 支持 webhook 投递,如果你需要 push 而不是 poll,可用notify与endpoint参数设置。参见 Bright Data 的 trigger-a-collection 文档。) - 批处理 + 范围。
scrape_batch和search_engine_batch每次调用可运行多个 URL,从而降低每个 URL 的 token 开销。将&groups=ecommerce,social,geo,business追加到 MCP URL 只加载你的用例所需的工具组,从而缩小代理必须读取的工具列表握手。11 个组分别是ecommerce、social、finance、business、research、app_stores、travel、geo、code、browser和advanced_scraping。 - 跨技术栈模板。 Power 包含 22 个生产模板:TS(Next、Express、Fastify、Hono、Koa)与 Python(FastAPI、Flask、Django)的 Web 框架路由,agent-SDK 工具(Anthropic、OpenAI、LangChain、Vercel AI SDK、Mastra),以及通用模块(TS fetch + Cheerio、Python stdlib + BeautifulSoup,以及通用
curl.sh)。Kiro 通过清单检测 7 种语言并选择匹配项,但一等代码生成仅支持 TS 与 Python。Go、Rust、Ruby、Java 和 PHP 会被检测到并路由到curl.sh回退方案。 - 使用搜索驱动的 URL,而不是硬编码。 硬编码 URL 可能会在列表 ID 轮换时失效:过期 ID 仍可解析但指向错误产品(用例 1 中 PS5 与耳机的失败案例,恢复循环无法捕获)。内置修复是以 discovery 模式触发数据集,而不是按 URL 触发。将数据集触发器 body 从
[{ url }]替换为 discovery 查询(discover_by=keyword、category_url或best_sellers_url),让 Bright Data 找到当前产品。参见 Bright Data 的 trigger-a-collection 文档 了解 discover 请求形状。 - 登录流程 + 引导。 Browser API 通过一个为代理使用而设计的 ARIA 快照接口(Playwright-MCP 风格 refs)处理需要认证的站点。向你的工作区添加
.kiro/steering/<your-domain>.md,即可在不 fork 的情况下覆盖 Power 内置的引导。若来源提供官方 API,请使用官方 API。
设置 &pro=1 后,重新打开 MCP 面板会显示完整工具目录:
下一步
一个 Power 通过单个 MCP 端点驱动全部 4 个用例,因此你可以把时间花在集成与告警逻辑上,而不是爬虫工具的底层管道。
自己构建零售追踪器。 将 https://github.com/bright-cn/kiro-powers/tree/main/brightdata-scrape 粘贴到 Kiro 的 Add Custom Power → Import power from GitHub,然后运行用例 1 的提示。在我们的运行中,这花了 20,30 分钟,零 Pro 花费,并确认了安装与 4 阶段工作流。赶时间?也可以直接克隆完成的应用:git clone https://github.com/triposat/retail-price-tracker && cd retail-price-tracker && npm install && cp .env.example .env.local,添加一个免费的 Bright Data token,然后运行 npm run dev。
然后通过重新提示来扩展,而不是重写。 在 .kiro/settings/mcp.json 中添加 &pro=1,并以按量计费价格运行上面 3 个 Pro 套餐提示中的任意一个(GEO、LinkedIn 或 Crunchbase 情报)。无需新代码,只需对同一个 Power 输入新的提示。
延伸阅读:Web MCP 页面(完整工具列表),以及 Bright Data 的 Kiro 聊天工作流文章(同样的工具如何用于交互式使用)。
常见问题
哪些是免费的,哪些是付费的?
免费: 你在 Web MCP 中获得 5 个基础工具(search_engine、search_engine_batch、scrape_as_markdown、scrape_batch 和 discover),每月 5,000 次请求免费(根据 Bright Data 的 MCP README)。付费: Pro web_data* 工具需要付费,零售构建使用的数据集触发器路径也需要付费,因为它会直接调用 Bright Data 的 数据集 API。该路径单独计费,先有约 ~1,000 条记录的免费试用,之后约 ~$1.50/1,000 条记录,因此每次运行抓取几件产品通常只需不到一美分。
Pro 工具的费用是多少?
Pro web_data_* 工具的费用为 $1.00,$1.50 每 1,000 条结果,取决于你的套餐(Bright Data 的定价页面):
| Plan | Price per 1,000 results |
|---|---|
| Pay-As-You-Go | $1.50 |
| Starter | $1.30 |
| Professional | $1.10 |
| Business | $1.00 |
对于单实体 Pro 调用(每次调用抓取 1 条 LLM 答案、1 个 LinkedIn 资料或 1 个 Crunchbase 公司),月度估算假设 1 次调用 = 1 条计费结果,这与 Bright Data 对单记录 web_data_* 工具的按用量计费一致。对于像 web_data_amazon_product_search 这样的批量搜索工具,每条结果的计数会随返回条目数扩展。原型阶段请使用 limit 参数,并在预算前根据你的账户核对当前费率。
Browser API 单独计费,为 $5,8/GB 带宽。如果你添加 AI-agent 层,那么 Anthropic、OpenAI 或 Google 的定价也会按每次 LLM 调用适用。
这能与 GPT 或 Gemini 一起使用吗?
可以,brightdata-scrape Power 支持 OpenAI(GPT)与 Google(Gemini),不只支持 Anthropic。当你提示 Kiro 添加 agent 层(“add an /api/agent route that uses these 爬虫工具 as tools”)时,它会根据你项目的依赖选择匹配的工具模板(Anthropic SDK、OpenAI SDK、LangChain、Mastra 或 Vercel AI SDK)。在生成的路由中将 anthropic(...) 替换为 openai(...) 或 google(...),然后调整该提供方的客户端设置与模型 ID 以匹配。
它能抓取需要登录的网站吗?
brightdata-scrape Power 可以抓取需要登录的网站,但不能使用数据集触发器默认路径。切换到 Browser API 以获得有状态会话,并添加你自己的凭据存储。Power 的第 2 阶段阶梯会在需要登录与点击流程时升级到 Browser API。
我能在一个项目中运行全部 4 个用例吗?
可以。每个用例都是一个自包含模块(各自的 src/scrapers/ 文件、API 路由与视图),并复用同一个 MCP 服务器,因此 4 个用例可以共存于一个 Next.js 项目中。本指南没有把它们合并成一个应用(2 个实时构建:零售与 Crunchbase,是两个独立的 demo 仓库;GEO 与 LinkedIn 以提示形式展示),但没有任何东西阻止你这么做。
我能从 Claude Code 或 Cursor 使用它吗?
对于 Claude Code 或 Cursor,请使用 Bright Data 的 Claude 技能,而不是 brightdata-scrape Kiro Power。Bright Data 在 github.com/bright-cn/skills 提供抓取 skills(例如 scraper-builder 与 scrape),可在 Claude Code、Cursor 或任何支持 技能 的 agent host 中运行。它们在同一 Bright Data 基础设施上覆盖了大致相同的抓取工作,但它们以 skills + bdata CLI 的形式打包,而不是这个 Power 的 MCP + Next.js 代码生成,因此安装与生成代码会有所不同。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。





