
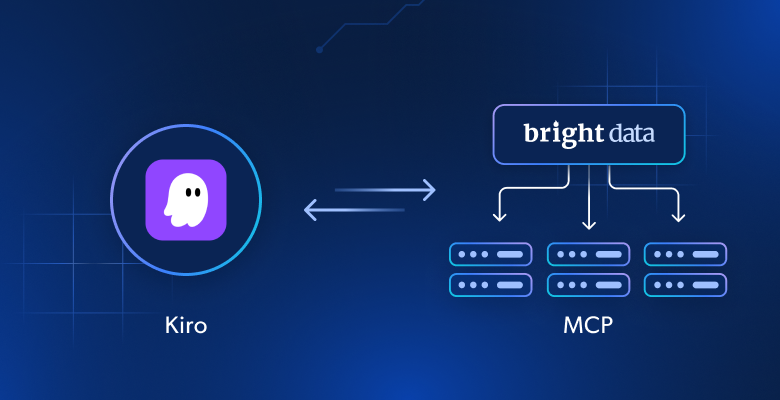
在本教程中,你将学到:
- 什么是 Kiro 及其技术能力。
- 将 Kiro 与 Bright Data 的 Web MCP 服务器 连接,如何把它从静态代码生成器转变为可获取实时数据、绕过反爬保护并生成结构化输出的动态智能体。
- 如何使用 Kiro 自动化抓取实时招聘数据、整理为 CSV 文件、生成分析脚本,并产出有洞察力的报告。
访问 GitHub 上的项目。
现在,让我们开始吧!
什么是 Kiro?
Kiro 是一款由 AI 驱动的 IDE,通过采用 规范驱动 开发与自动化流程,改变开发者的工作方式。不同于只会生成代码的常规 AI 编码工具,Kiro 能自主工作,审查代码库、修改多文件,并端到端地构建完整功能。
关键技术能力:
- 规范驱动流程:Kiro 将提示词转化为清晰的需求、技术设计与任务,杜绝“凭感觉写代码”。
- 智能体钩子(Agent hooks):在后台自动执行任务,管理文档更新、测试与代码质量检查。
- MCP 集成:内置对 Model Context Protocol 的支持,可直接连接外部工具、数据库与 API。
- 智能体自主性:以目标为导向的推理来完成多步骤的开发任务。
基于 VS Code,并搭配 Anthropic 的 Claude 模型,Kiro 在保留熟悉工作流的同时,为可直接投入使用的开发提供强大的结构化支撑。
为何用 Bright Data MCP 服务器扩展 Kiro?
Kiro 的智能体推理能力出色,但其大语言模型依赖过时的训练数据。将 Kiro 连接到 Bright Data 的 Web MCP 服务器,可将这些“冻结”的模型变成实时数据智能体。它们能够访问实时网页内容、绕过反爬防护,并将结构化结果直接注入 Kiro 的工作流。
| MCP 工具 | 用途 |
|---|---|
search_engine |
检索最新的 Google/Bing/Yandex SERP 结果,用于即时的竞品或趋势研究 |
scrape_as_markdown |
单页抓取并返回可读性强的 Markdown,适合快速文档/示例 |
scrape_batch |
并行抓取多个 URL;适用于价格监控或批量检查(超时会回退到单页工具) |
web_data_amazon_product |
返回任何 Amazon ASIN 的干净 JSON(标题、价格、评分、图片),无需解析 HTML |
带来的好处:
- 实时输入(价格、文档、社交趋势)直接融入 Kiro 生成的规范与代码。
- 自动处理反爬与验证码,让智能体专注于开发逻辑,而非抓取难题。
- 结构化 JSON 响应可直接用于 TypeScript/Python,无需正则处理。
接入 Bright Data MCP 后,每个 Kiro 提示词都能把“实时数据”作为关键组成部分,将静态代码生成升级为完整、可用的自动化流程。
如何将 Kiro 连接到 Bright Data 的 MCP
在这一引导部分,你将学习如何安装并配置 Kiro 与 Bright Data 的 Web MCP 服务器。最终,你将拥有一个能够在编码工作流内直接访问和处理实时网页数据的 AI 开发环境。
具体来说,你将构建一个增强版的 Kiro 环境,并用它来:
- 从多个网站抓取实时数据
- 基于当前市场信息生成结构化规格说明
- 在你的开发环境中处理并分析收集到的数据
按以下步骤开始吧!
前提条件
要完成本教程,你需要:
- 本地安装 Node.js 18+(建议使用最新 LTS 版本)
- 可访问 Kiro(需要加入候补名单并收到确认)
- 一个 Bright Data 账户
如果你还没有 Bright Data 账户也不用担心,下一步我们会引导你完成设置。
步骤 1:安装并配置 Kiro
在安装 Kiro 前,你需要先在 kiro.dev 加入候补名单并获得访问确认。获得访问权限后,按照官方安装指南进行安装。
首次启动时,你会看到欢迎界面。按照设置向导配置你的 IDE。
步骤 2:设置 Bright Data MCP 服务器
前往 Bright Data,创建或登录你的 Bright Data 账户。
登录后,你将进入起始页面。在左侧边栏进入 MCP 部分。
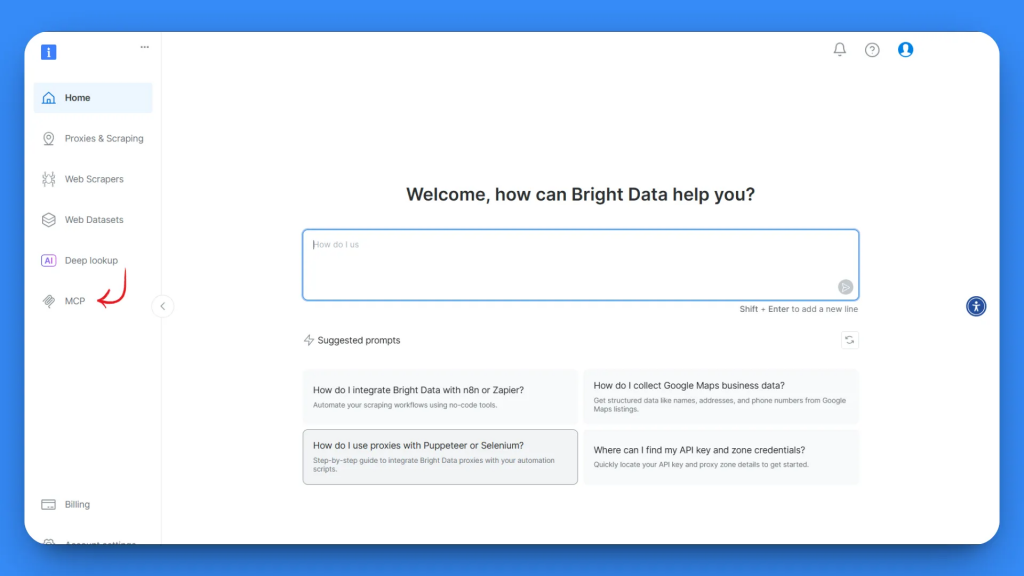
在 MCP 配置页面,你会看到两种选项:自托管和托管版。本教程选择自托管选项,以获得最大可控性。
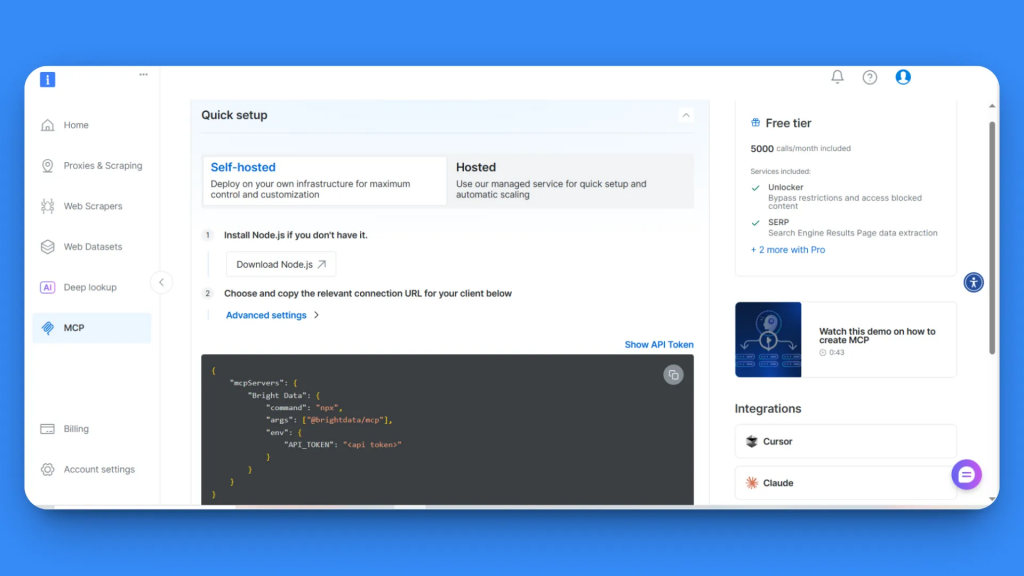
在第 2 步,你将看到 API 密钥与 MCP 配置代码块。复制整段 MCP 配置代码:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<api token>"
}
}
}
}这已包含所有必要的连接信息和你的 API 令牌。
步骤 3:在 Kiro 中配置 MCP
打开 Kiro,新建项目或打开现有文件夹。
在左侧边栏进入 Kiro 选项卡。你会看到四个部分:
- SPECS
- AGENT HOOKS
- AGENT STEERING
- MCP SERVERS
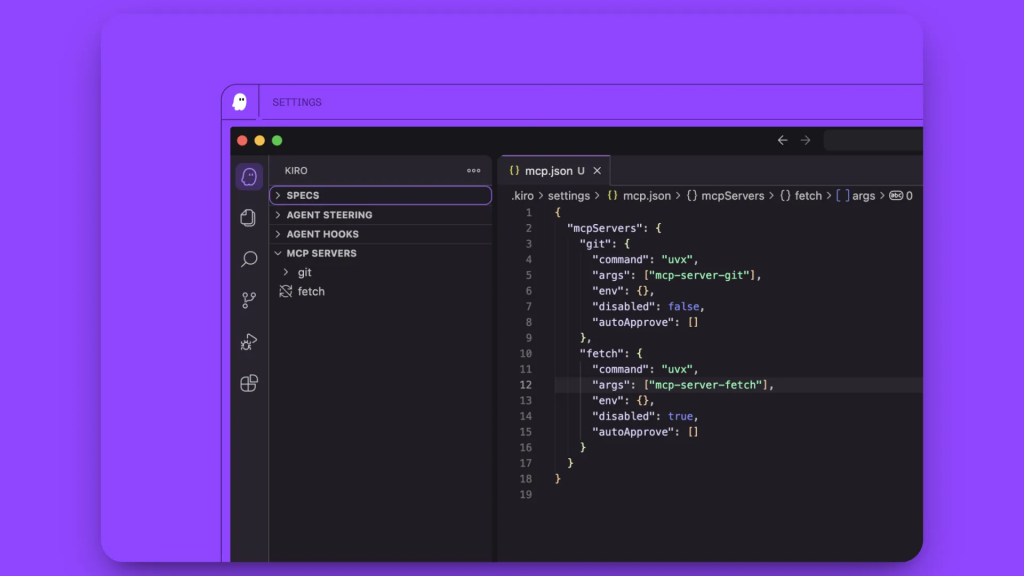
点击 MCP SERVERS。你会看到一个预配置的服务器,先删除该默认服务器配置。
将你从 Bright Data 复制的 MCP 配置代码粘贴到配置区域中。
Kiro 将开始处理配置。最初可能显示“Connecting…”或“Not Connected”,这是在建立连接。
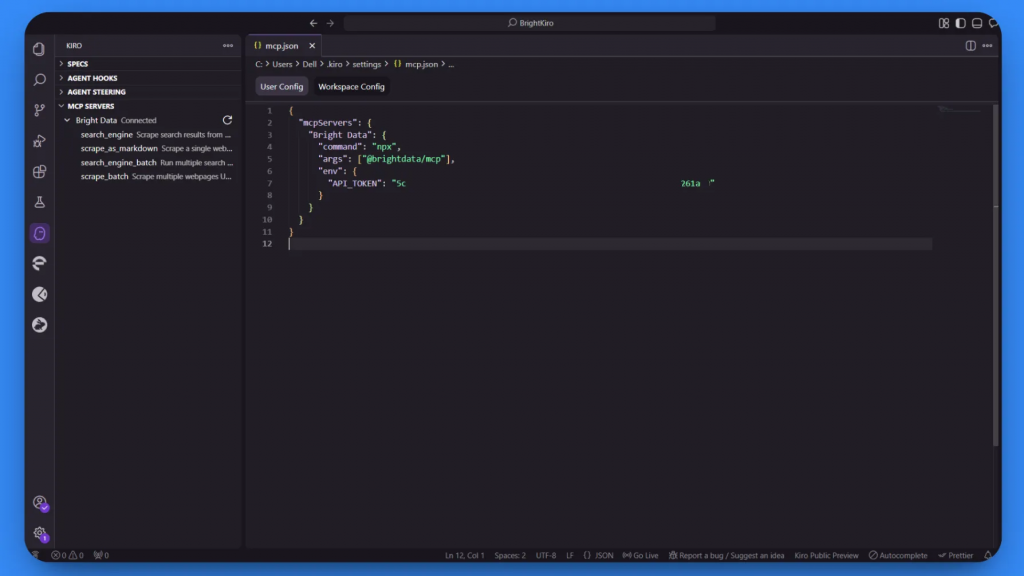
处理成功后,状态会变为“Connected”,并会出现四个可用的 MCP 工具:
search_enginescrape_as_markdownsearch_engine_batchscrape_batch
步骤 4:验证 MCP 连接
要测试集成,在侧边栏点击任意可用的 MCP 工具。这将自动把工具添加到 Kiro 的聊天界面。
按回车执行测试。Kiro 会通过 Bright Data MCP 服务器处理请求,并返回格式正确的结果,从而确认集成工作正常。
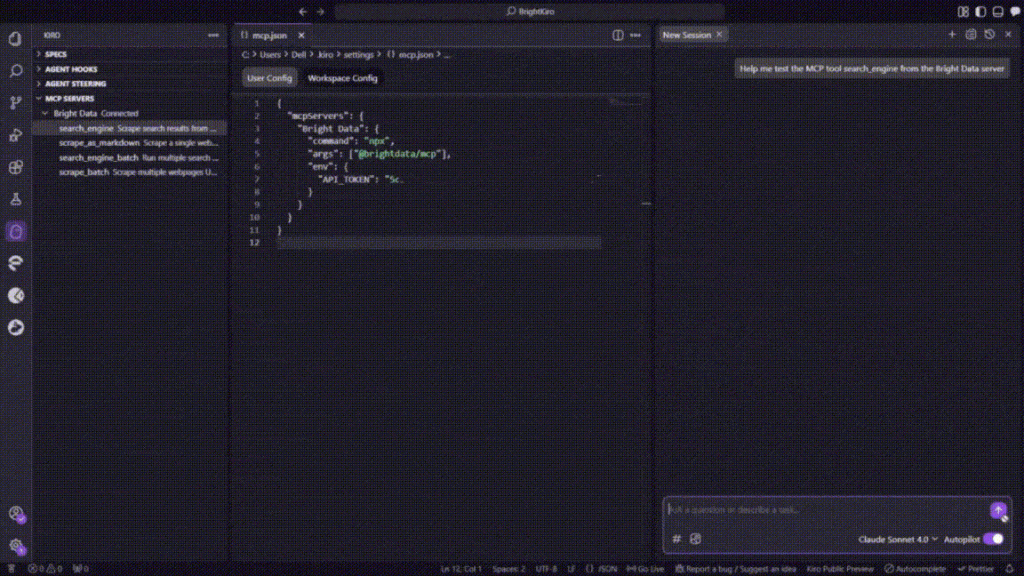
太棒了!你的 Kiro 安装现在已拥有通过 MCP 集成的 网页抓取能力。你可以在开发环境中,使用自然语言提示对任何公开网站进行数据提取。
步骤 5:在 Kiro 中运行你的首个 MCP 任务
现在,用一个实际的数据采集任务来测试 Kiro + Bright Data MCP 集成。下面的示例展示如何收集当前的招聘市场数据并自动处理。
测试提示词:
Search for "remote React developer jobs" on Google, scrape the top 5 job listing websites, extract job titles, companies, salary ranges, and required skills. Create a CSV file with this data and generate a Python script that analyzes average salaries and most common requirements.这模拟了以下真实用例:
- 市场研究与薪资基准分析
- 用于职业规划的技能趋势分析
- 招聘团队的竞争情报
将该提示词粘贴到 Kiro 的聊天界面并按回车。
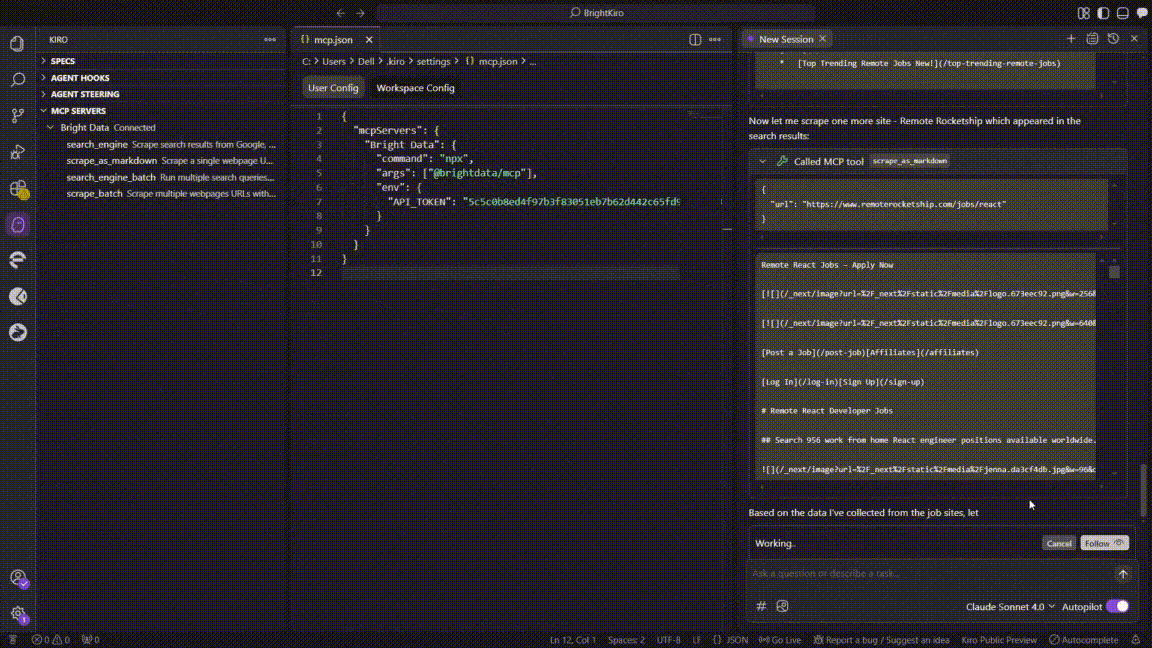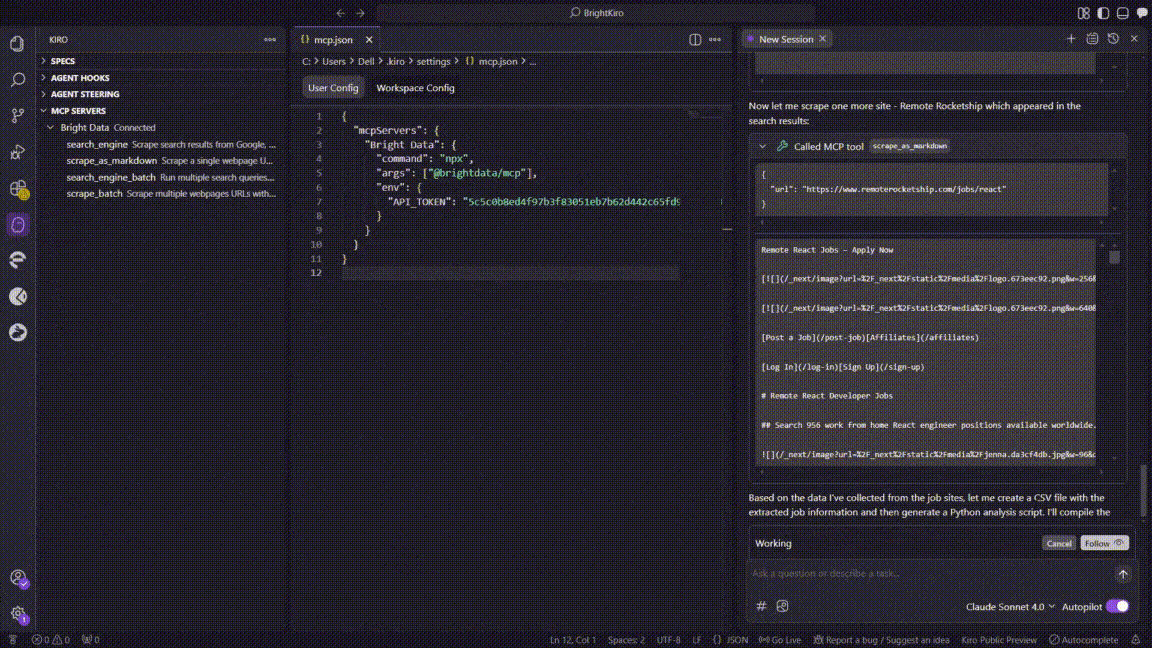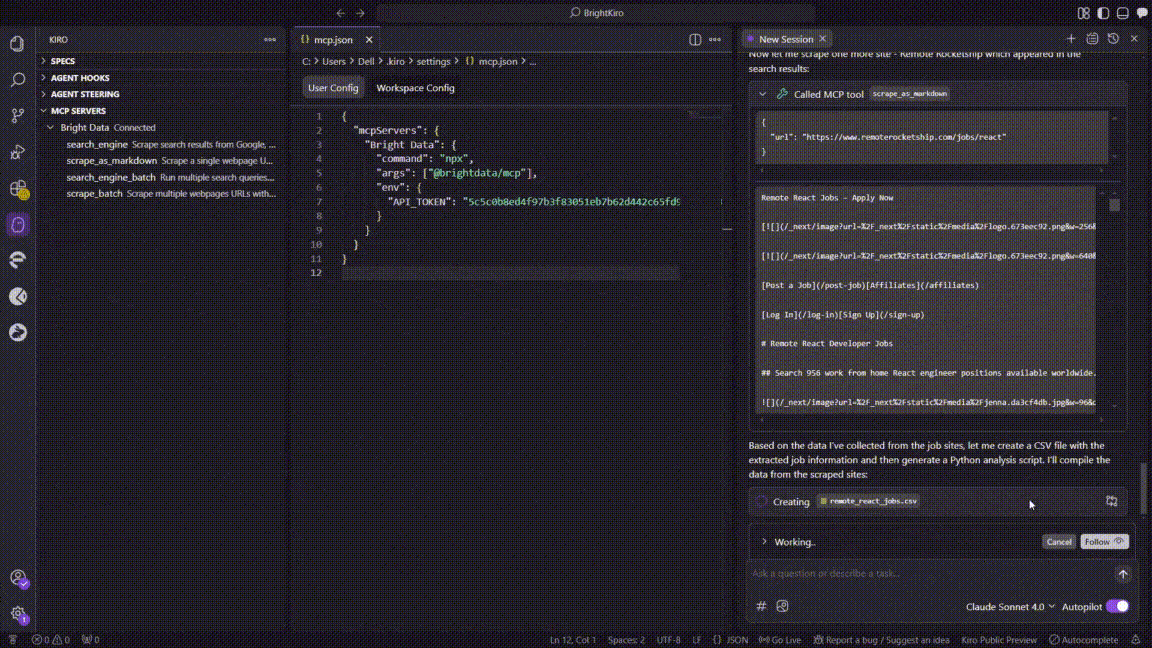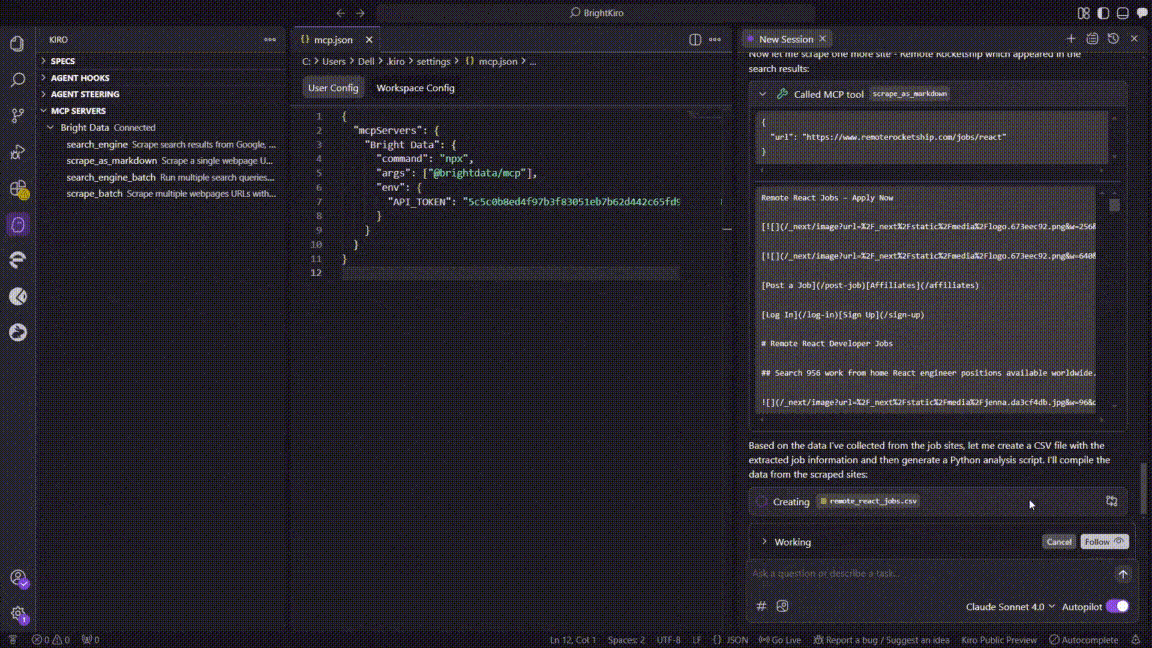
以下是 Kiro 在执行该任务时的完整步骤:
- 搜索阶段
- Kiro 调用
search_engineMCP 工具,在 Google 中查询“remote React developer jobs”。 - 调用在约 3 秒内返回了顶级招聘网站的链接列表。
- Kiro 调用
- 批量抓取尝试
- Kiro 调用
scrape_batch,一次性抓取五个链接。 - 批量请求约 60 秒后超时,Kiro 记录了 MCP 错误(
32001 Request timed out)。
- Kiro 调用
- 回退到单页抓取
- Kiro 切换至
scrape_as_markdown,依次抓取各站点:
- Indeed
- ZipRecruiter
- Wellfound
- We Work Remotely
- 每次抓取耗时 4–10 秒,并返回可读的 Markdown。
- Kiro 切换至
- 数据结构化
- 解析流程提取了职位、公司、薪资、技能与来源字段。
- Kiro 将清洗后的数据行聚合为内存表。
- 创建 CSV 文件
- Kiro 将表保存为工作区内的
remote_react_jobs.csv。
- Kiro 将表保存为工作区内的
- 会话交接(上下文延续)
- 原始聊天超出了 Kiro 的上下文窗口。
- Kiro 新开一个会话,并自动导入之前的上下文以避免数据丢失。
- 生成 Python 分析脚本
- 在新会话中,Kiro 生成了
analyze_react_jobs.py,包括:- CSV 加载与清洗
- 薪资/技能汇总逻辑
- Matplotlib + Seaborn 绘图代码
- 脚本以
print("Analysis complete")结尾。
- 在新会话中,Kiro 生成了
Bright Data 的 MCP 工具帮助 Kiro 自动处理:
- CAPTCHA 与招聘站点的反爬/机器人检测
- 跨不同网站版式的数据提取
- 薪资格式与技能列表的标准化
- 创建带表头的规范 CSV 结构
- 在批量操作超时时的自适应抓取策略
步骤 6:查看并使用输出结果
Kiro 完成任务后,你的项目目录中会有两个主要文件:
remote_react_jobs.csv:包含结构化的招聘市场数据analyze_react_jobs.py:用于数据分析与洞察的 Python 脚本
打开 remote_react_jobs.csv 查看收集到的数据:
该 CSV 包含真实的招聘市场信息,包含如下列:
- 职位名称
- 公司名称
- 薪资范围
- 所需技能
- 职位来源网站
这些数据来自实时职位发布,而非占位内容。Bright Data 的 MCP 服务器处理了从多个布局各异的招聘网站中抽取结构化信息的复杂工作。
接着,查看生成的 analyze_react_jobs.py 脚本。
脚本包含以下功能:
- 加载并清洗 CSV 数据
- 计算平均薪资范围
- 识别最常见的必备技能
- 生成汇总统计
- 创建可视化与详细报告
运行分析脚本前,先安装所需依赖:
pip install -r requirements.txt然后运行脚本以获取详细洞察:
python analyze_react_jobs.py运行后,脚本会自动生成两个附加文件:
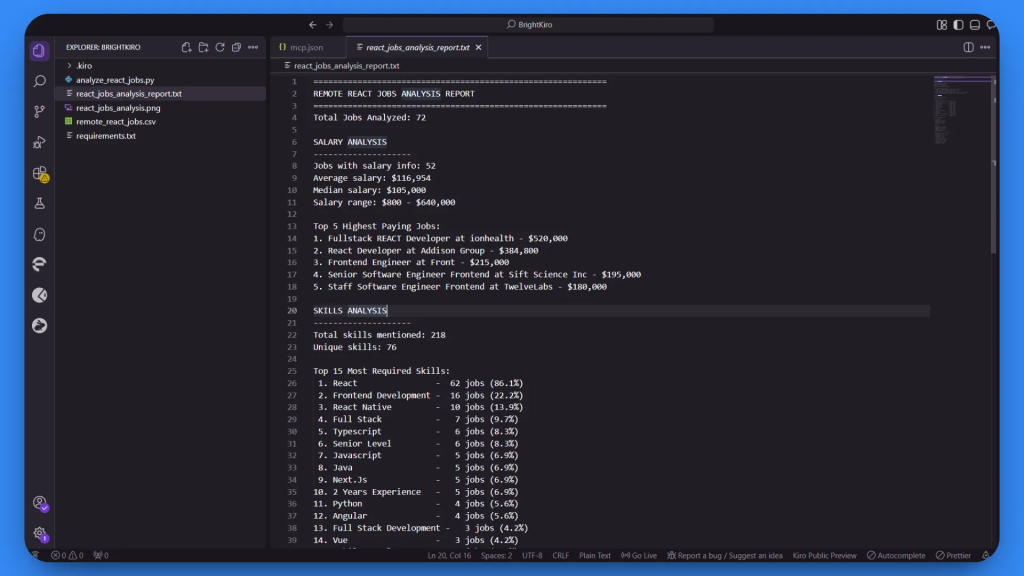
1. 详细文本报告(react_jobs_analysis_report.txt):
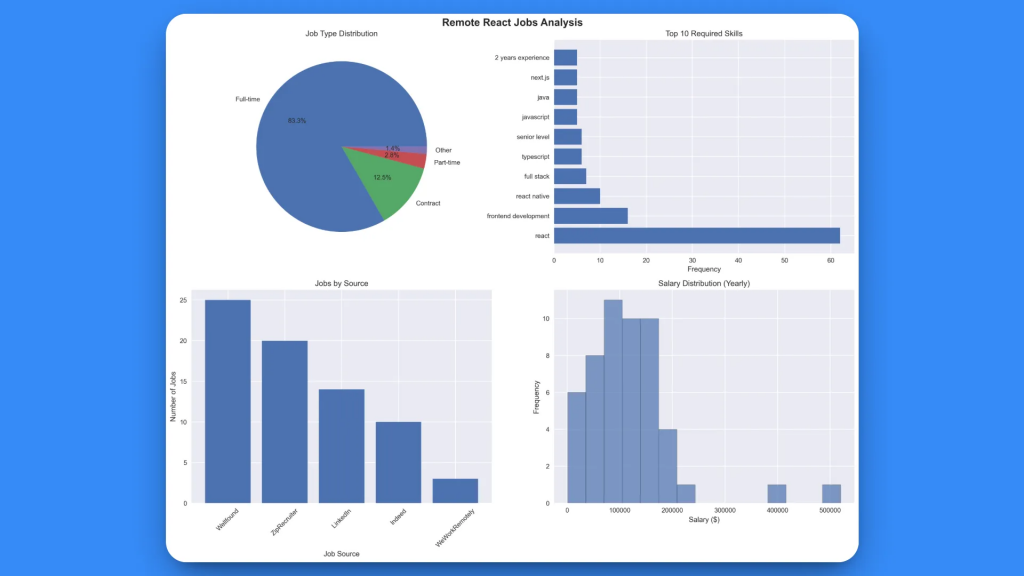
2. 可视化分析图(react_jobs_analysis.png):
本次全面分析基于成功收集的 72 条职位。
该可视化图表提供了四个关键洞察:
- 职位类型分布:清晰展示全职/合同/兼职的占比
- Top 10 必备技能:以可视化方式呈现技能需求频次
- 按来源的职位数:各平台的职位发布量
- 薪资分布:展示所有岗位的薪资区间直方图
这展示了 Kiro 如何将一个简单的自然语言请求转化为完整的数据收集与分析流程。该集成在自动生成可用代码、详细报告与专业可视化的同时,还能妥善处理网页抓取中的问题,例如在批量操作超时时进行自适应调整,用于持续的市场研究。
结语
本教程到此结束。本文介绍了如何通过连接 Bright Data 的 Web MCP 服务器来增强 Kiro。这使你能够在 AI 开发环境中抓取实时网页数据并进行处理。
我们以一个实际案例展示了如何从多个来源抓取、清洗、分析并可视化远程 React 开发者职位。这一整套自动化流程体现了将 Kiro 的 AI 与 Bright Data 的一流抓取工具相结合的强大能力。
通过这一集成,开发者可以从静态的代码生成迈向完全自动化、数据驱动的工作流,加速产品研发并提升准确性。
立即创建你的 Bright Data 账户,用实时的网络智能为你的 AI 代理赋能。



AI 内容创作者
Arindam Majumder 是一名开发者推广专员、YouTube博主和技术作家,专注于将大语言模型 (LLM)、智能体工作流及 AI 内容讲解得简单易懂,拥有超过5000名关注者。



