

在本教程中,你将学习:
- Onyx AI 平台是什么,以及它作为搜索与 AI 助手提供了什么。
- 为什么通过 Web 发现、数据提取和集成能力扩展 Onyx 能将你的 AI 代理提升到新水平。
- 如何为此将 Bright Data 连接到 Onyx,可通过 MCP 或 OpenAPI 规范实现。
让我们开始吧!
Onyx:它是什么以及它提供哪些功能
Onyx 是一个企业搜索和 AI 助手平台,可连接到公司的内部文档、应用(如 Slack、Drive、GitHub 等)和人员,以提供即时、具备上下文的答案。它具有开源特性(拥有 18k+ GitHub stars),并且被构建为可自托管且完全透明。
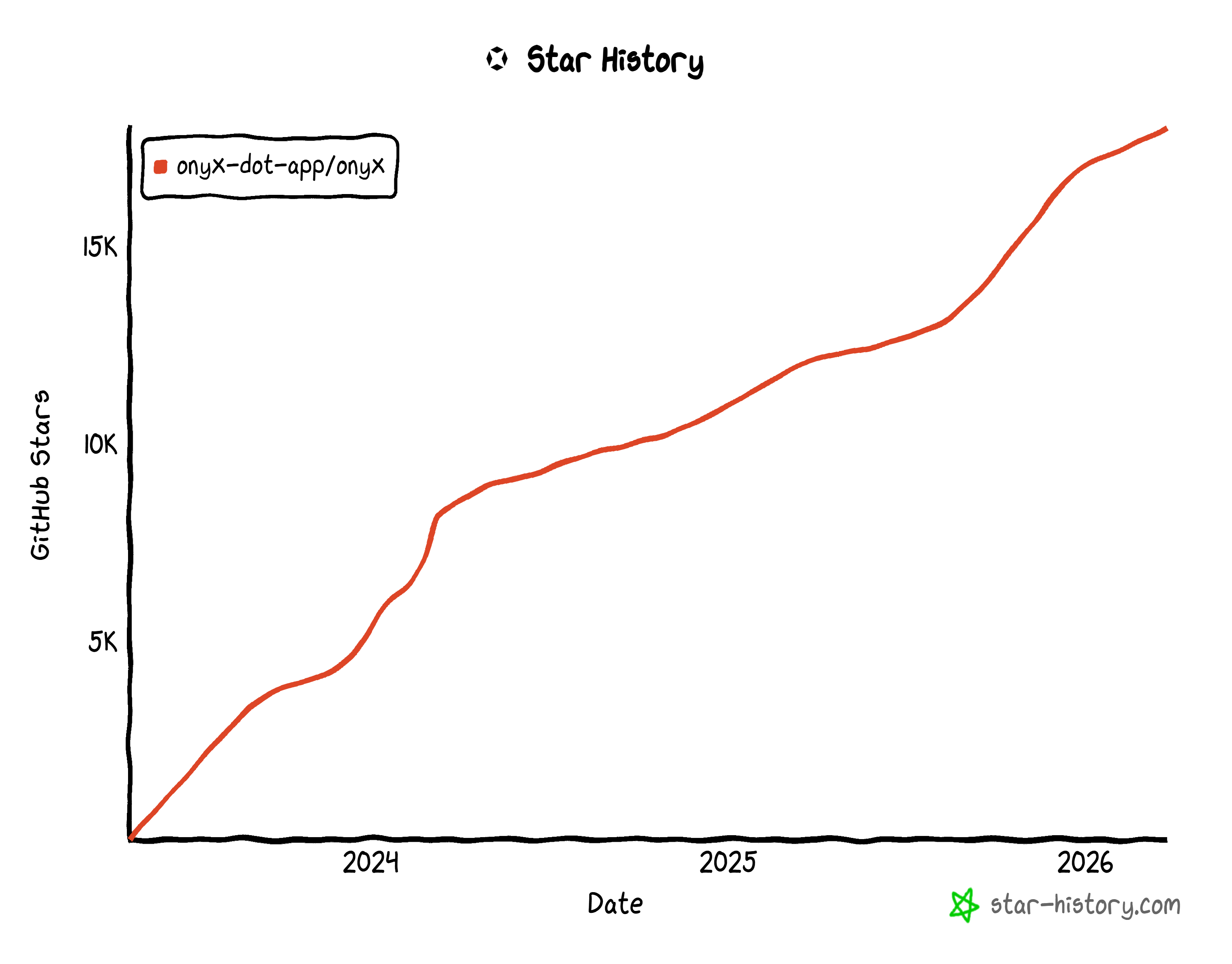
Onyx 与你的文档、应用和团队成员集成,同时让你对部署、数据隐私和自定义拥有完全控制权。它专注于可靠性、安全性和可扩展性,帮助你创建可进行深度研究、自动化任务并访问最新信息的定制 AI 代理。所有这些,都在一个基于 Web 的单一界面中完成。
该平台提供的主要功能包括:
- 自定义代理:构建具有独特指令、知识和动作、并针对你的工作流量身定制的 AI 代理。
- Web 与内部搜索:使用混合搜索、RAG 和 AI 生成的知识图谱,从 Web 或你组织的知识库中检索最新信息。
- 连接器:与 40+ 应用集成,以拉取文档、元数据和访问受控的信息。
- 深度研究:执行多步骤的代理式搜索,以提供深入的答案和洞察。
- 动作与 MCP 支持:使代理能够与外部系统交互并自动化工作流。
- 代码解释器:在聊天中直接运行脚本、分析数据、渲染图表并创建文件。
- 图像生成: 在平台内根据用户提示创建图像。
- 协作工具:共享聊天、收集反馈、跟踪使用情况并管理用户角色。
- 灵活的 LLM 支持:可与许多 LLM 配合使用,包括 OpenAI、Anthropic、Gemini,以及像 vLLM 或 Ollama 这样的自托管模型。
- 部署选项:在 Docker、Kubernetes、Terraform、云提供商上部署,或在完全隔离的环境中部署以满足企业安全需求。
在官方文档中了解更多。
通过 Web 数据检索、搜索与交互能力扩展 Onyx AI 平台
毫无疑问,Onyx 是一个强大的 AI 平台。同时,像所有基于 LLM 的系统一样,它的知识在模型训练时就已固定。当你的 AI 代理需要处理当前的真实世界任务时,这可能导致过时的响应、幻觉或缺口。
LLM 也无法原生浏览 Web 或与外部系统交互,这限制了它们在动态工作流中的有效性。为了解决这一点,Onyx 通过 MCP 服务器、动作和工具支持与外部服务的集成。
这就是 Bright Data 发挥作用的地方!通过将 Onyx 连接到 Bright Data,你的 AI 代理可以访问实时信息、搜索结果,以及来自几乎任何网站的结构化数据。
你可以为 Onyx 代理启用的主要 Bright Data 产品包括:
- 搜索引擎 API:从 Google、Bing 等收集搜索引擎结果,为更有依据的回答提供支持。
- 网络解锁器 API:从任何站点访问原始 HTML 或 Markdown 内容,绕过验证码破解和反机器人措施。
- 网页爬虫工具 API:从 Amazon、LinkedIn 和 Instagram 等平台提取结构化数据。
- Crawl API:将整个网站转换为结构化数据集,用于下游 AI 工作流。
- Browser API:以编程方式控制远程浏览器,在任何网站上进行自动化、解锁的交互。
这些服务的不同之处在于 Bright Data 的企业级基础设施。它建立在一个全球代理网络之上,覆盖 195 个国家/地区的 4 亿+ IP,在保持 99.99% 正常运行时间和 99.95% 成功率的同时,支持无限扩展。
通过这些集成,Onyx 代理不再受限于静态知识。它们可以探索、检索、基于实时 Web 数据进行推理,并与网站交互,以提供准确、具备上下文且可执行的响应。
如何将 Bright Data 集成到 Onyx 中
Onyx 支持多种与第三方提供商的集成方法。对于 Bright Data,选项是:
- MCP:将 Onyx 连接到 Bright Data Web MCP 服务器(远程连接,因为 Onyx 不支持本地 MCP 连接)。
- OpenAPI:在 Onyx 中使用 Bright Data API 产品的 OpenAPI 3.0 或 3.1 规范 创建自定义动作。
OpenAPI 方法需要更多配置,但可让你直接访问 Bright Data 的服务。另一方面,Web MCP 方法更容易上手,只需一次设置即可访问 60+ 工具。
在下面专门的分步章节中,你将看到如何实现这两种方法!但首先,让我们在本地机器上安装并设置 Onyx。
通用步骤:开始使用 Onyx
无论你是想通过 MCP 还是 OpenAPI 将 Bright Data 集成到 Onyx 中,你首先都需要在你的机器上安装并运行该解决方案。你还必须拥有一个管理员账户。
这些是我们将在本节中涵盖的前置步骤!
前提条件
在按照下面的说明操作之前,请确保你满足以下要求:
- Linux/macOS 操作系统,或安装了 Bash 的 Windows(甚至 Git Bash 也足够)。
- 本地已安装 Docker 和 Docker Compose,并且 Docker daemon 正在运行。
- 来自受支持的 LLM 提供商的 API key(这里我们将使用一个OpenAI API key)。
你的机器还需要满足硬件要求以获得流畅体验:
- CPU:至少 4 vCPUs(推荐:8+ vCPUs)。
- RAM:至少 10 GB(推荐:16+ GB)。
- Storage:至少 32 GB + ~2.5× 索引数据的可用空间(或对于少于 5,000 名用户的组织为 500 GB)。
步骤 #1:安装 Onyx
确保 Docker daemon 正在运行。然后,在 Bash 中运行以下命令以启动官方的 Onyx 安装脚本:
curl -fsSL https://raw.githubusercontent.com/onyx-dot-app/onyx/main/deployment/docker_compose/install.sh > install.sh && chmod +x install.sh && ./install.sh你应该会看到类似这样的消息:
按 Enter 继续。Onyx 安装脚本将检查你的机器是否满足前提条件,并在 10 个步骤中引导你完成安装过程。
在第 4 步,你将被询问要安装哪个版本的 Onyx:
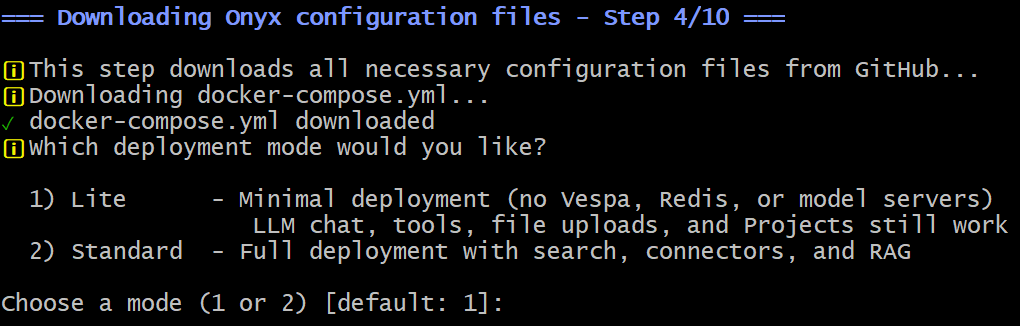
对于 Bright Data 集成,Lite 版本就足够了。因此,输入 1 或直接按 Enter(因为默认选项是 1)。继续使用默认选项,直到 Docker 镜像被下载、配置并启动。
如果一切按预期工作,你应该会看到:
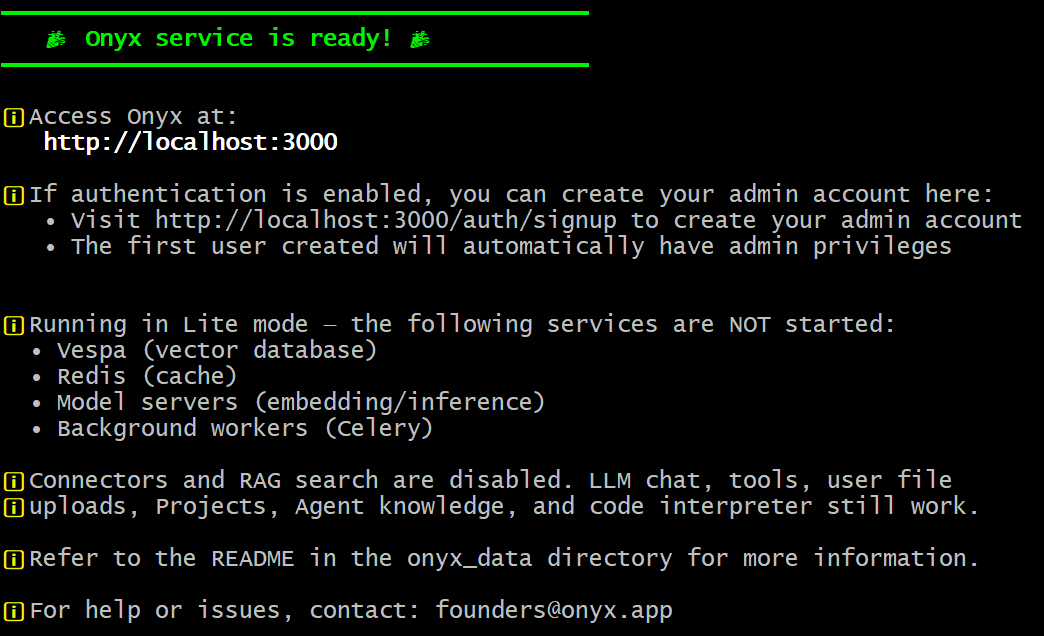
太棒了!Onyx 现在已在本地安装,并可在你的机器上通过 http://localhost 访问。
步骤 #2:创建管理员账户
要管理 Onyx,你必须创建一个管理员账户。为此,在浏览器中访问 http://localhost。你应该会看到以下表单:
创建账户并登录。然后你将进入 Onyx 控制面板:
在这里,你可以访问所有 Onyx 功能。特别是,通过 Admin Panel,你可以设置 Bright Data 集成,可通过 MCP 或 OpenAPI Tools 实现。
请记住,初始配置尚未完成,因为你仍需要将 Onyx 连接到你选择的 LLM。这就是你将在下一步中要做的事情!
步骤 #3:通过连接到 LLM 完成设置
要完成配置,点击 “Let’s Go” 按钮:
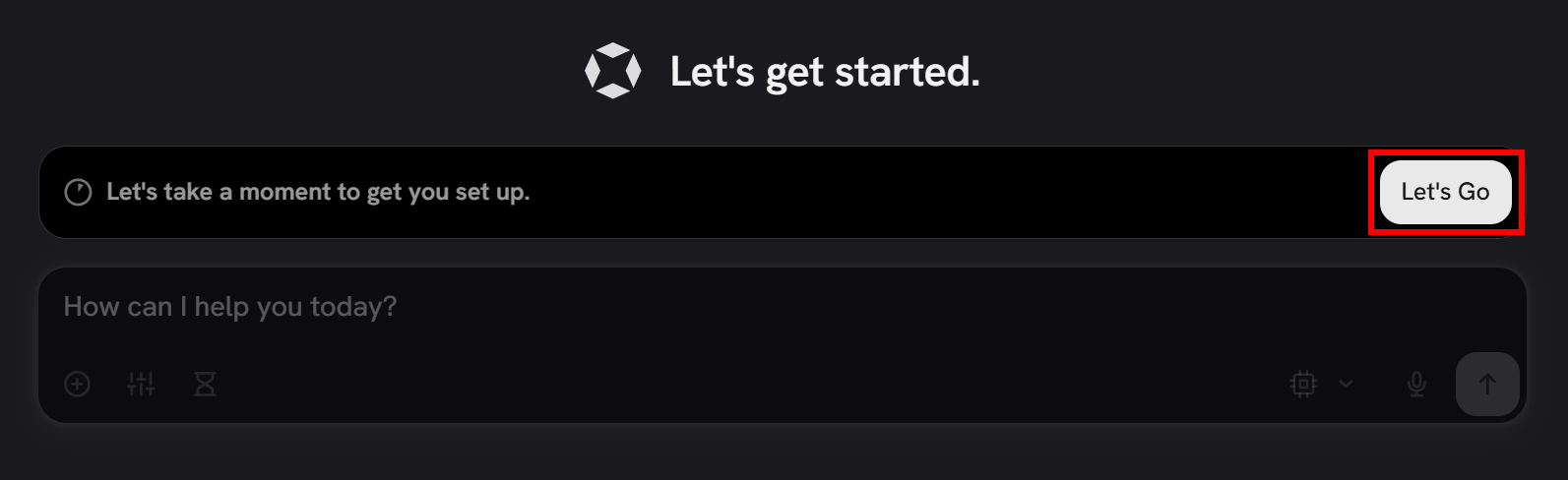
系统会提示你输入姓名。输入后点击 “Next”。然后,你将被要求配置 LLM 集成。
注意:下面将向你展示如何配置 OpenAI 模型。如果你计划使用任何其他受支持的 LLM,请点击提供商卡片并按照向导操作。
在这种情况下,从 OpenAI 卡片中选择 “GPT” 选项:
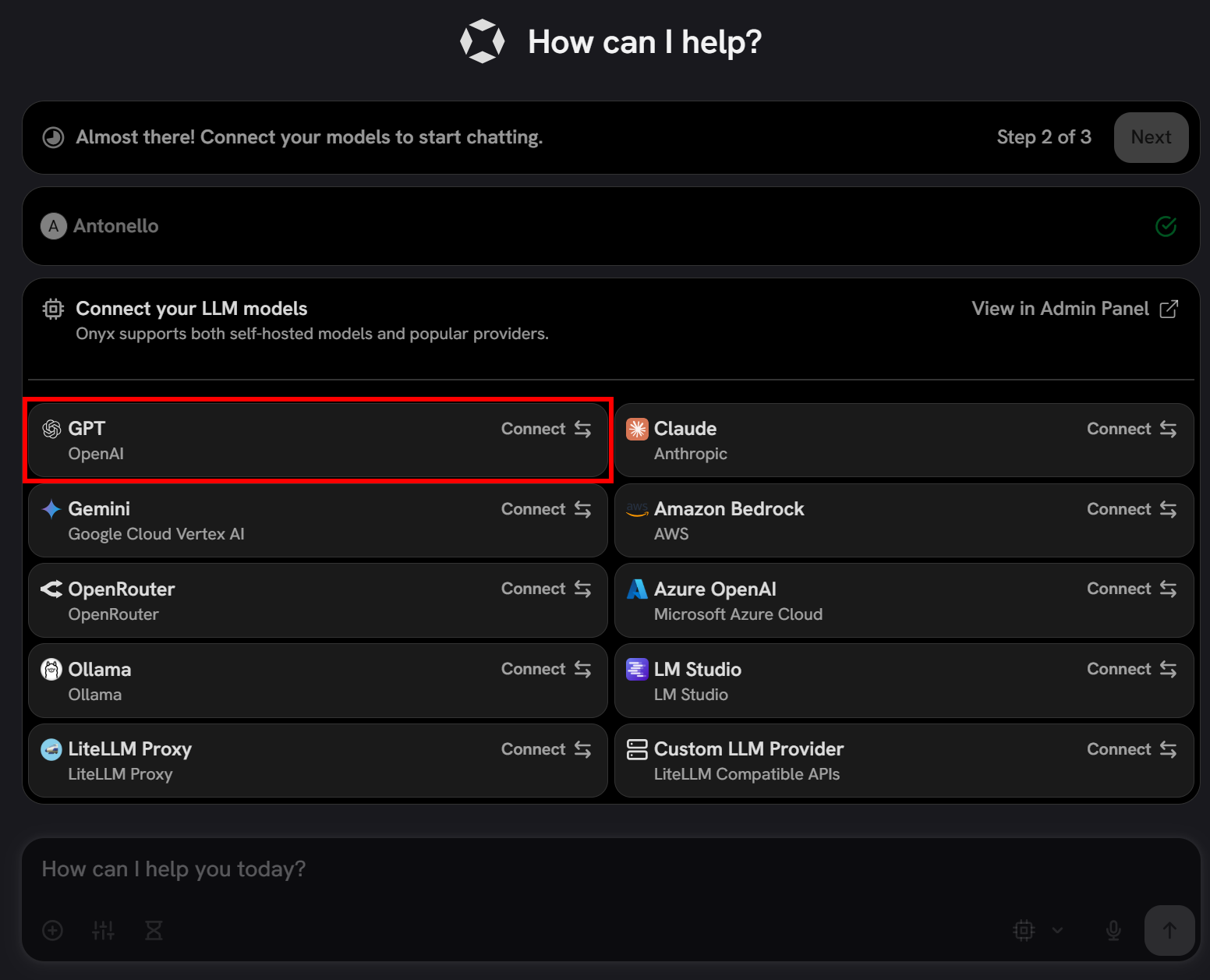
粘贴你的 OpenAI API key 并配置模型(例如,gpt-5-mini):
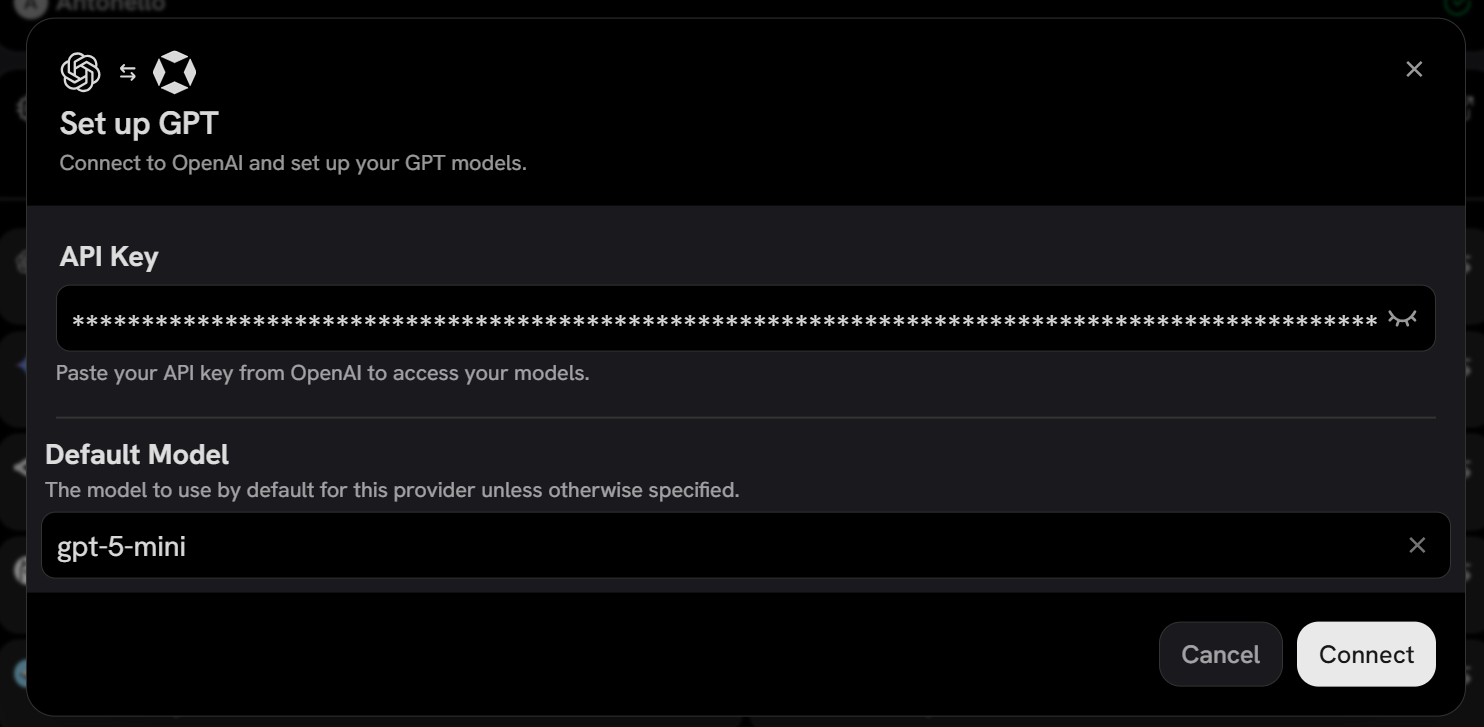
点击 “Connect”,你应该会看到 Onyx 已成功连接到所选的 LLM 提供商:
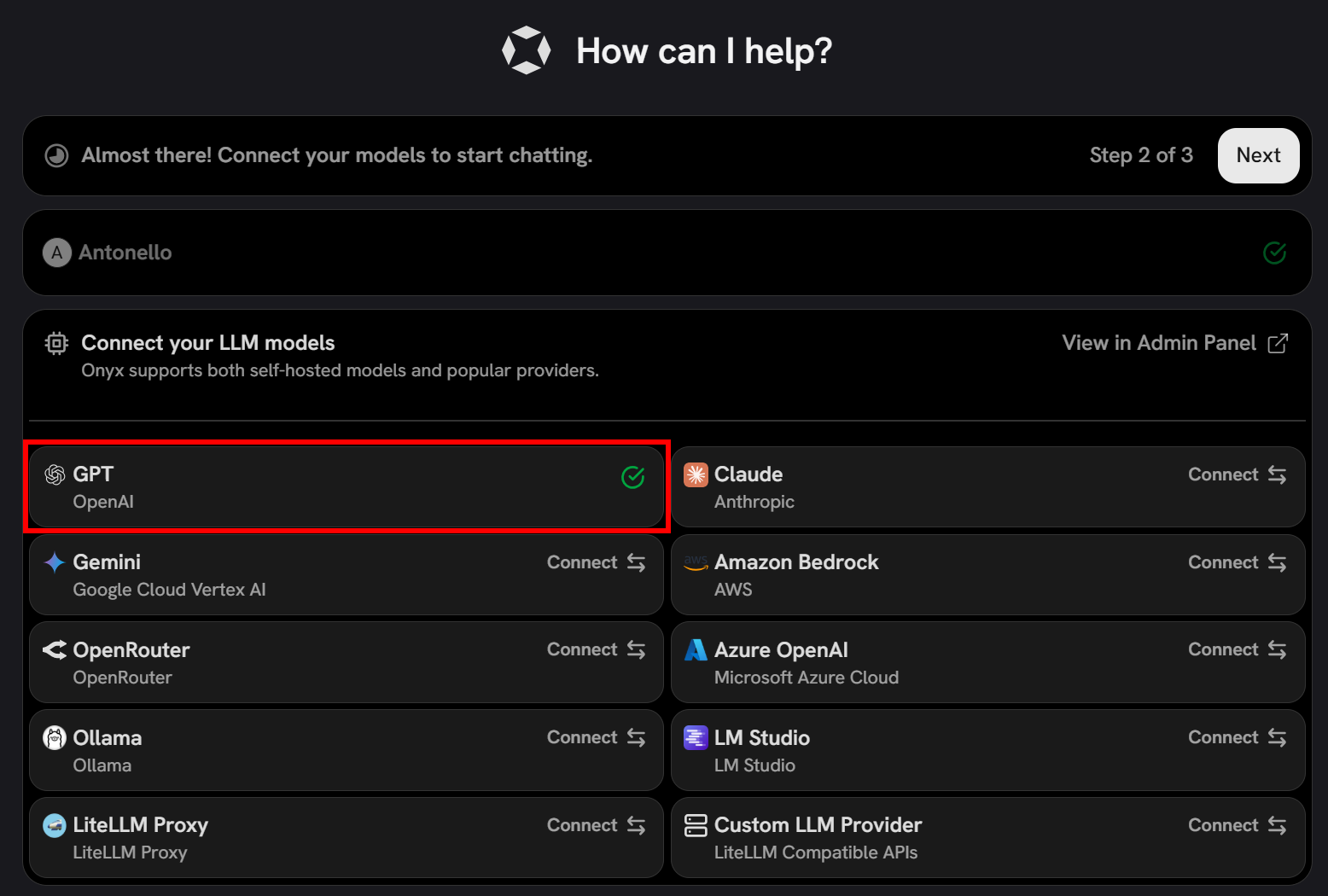
最后,继续进行配置的最后一步并点击 “Finish Setup”:
太棒了!你现在可以在 Onyx 中开始与已配置的 LLM 模型聊天并进行交互。在开始之前,继续设置 Bright Data 集成!
方法 #1:通过 Web MCP 将 Bright Data 连接到 Onyx
以下步骤将指导你通过其远程 Web MCP 服务器将 Bright Data 集成到 Onyx 中。
前提条件
要遵循本节内容,你需要:
- 一个 Bright Data 账户,并且已配置 API key。
- 熟悉MCP 的工作方式。
- 了解Bright Data Web MCP 服务器暴露的工具。
请通过上面的链接获取更多指导和说明。
步骤 #4:添加 Web MCP 服务器
要将 Bright Data 的 Web MCP 连接到 Onyx,请在 Admin Panel 中导航到 “MCP Actions” 页面:
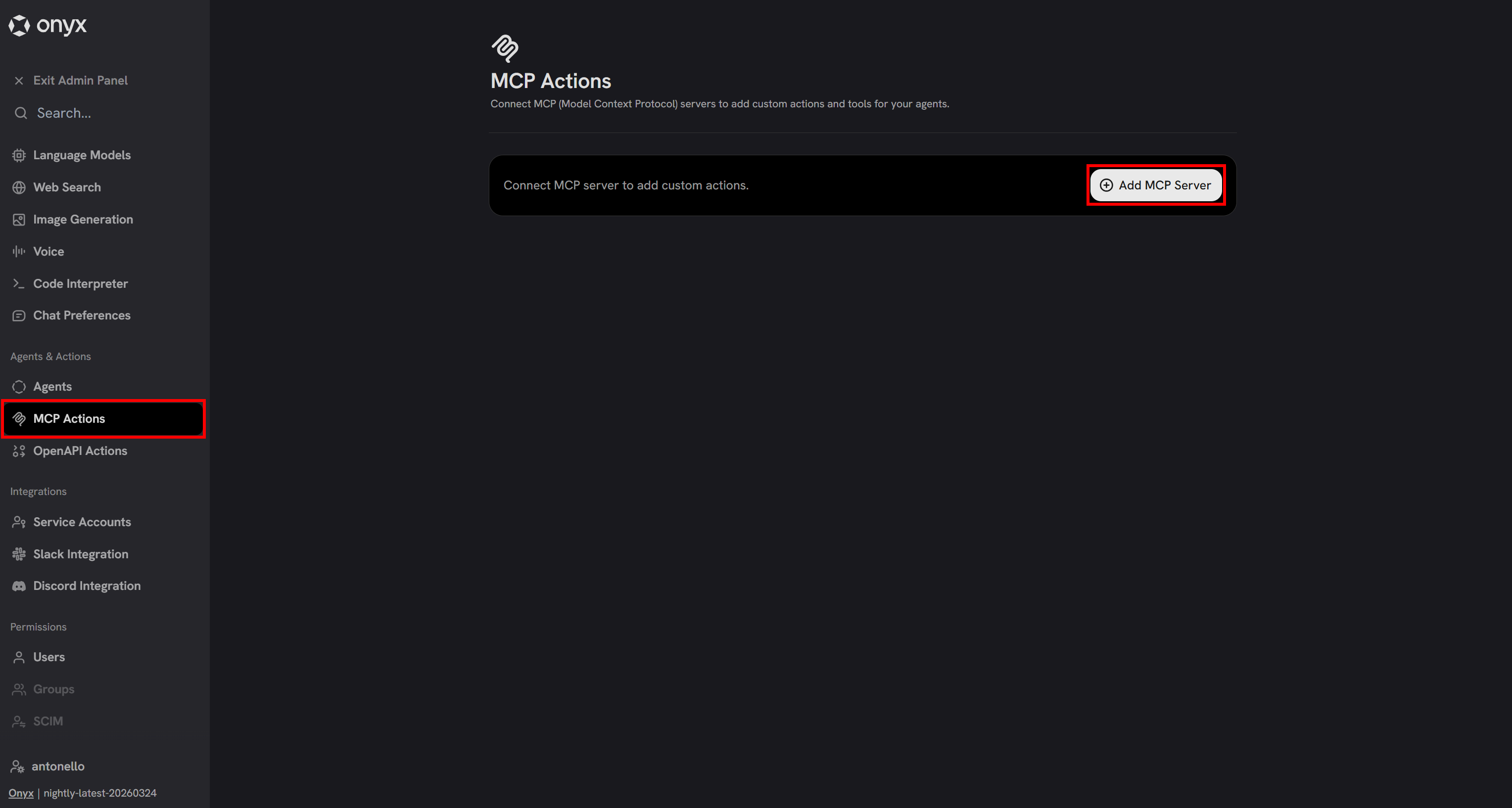
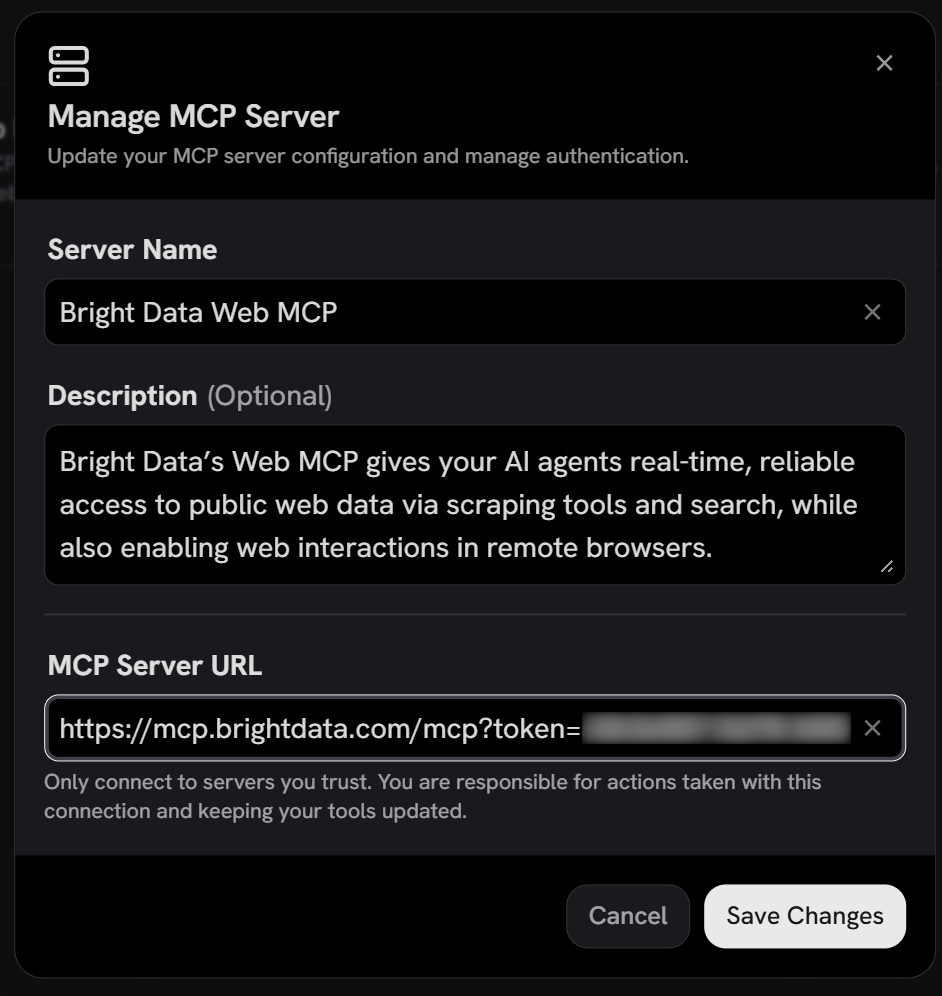
点击 “Add MCP 服务器” 创建新的集成。将出现一个配置模态框。按如下方式配置:
- Server Name:
Bright Data Web MCP - Description:
Bright Data's Web MCP gives your AI agents real-time, reliable access to public web data via scraping tools and search, while also enabling web interactions in remote browsers. - MCP 服务器 URL:
https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_TOKEN>&pro=1
请记住,Onyx 仅支持远程 MCP 服务器。在这种情况下,你正在通过 SSE 协议配置 Bright Data Web MCP。
要对你的 Bright Data 账户的请求进行身份验证,你必须在 URL 的 token 查询参数中包含你的 API key。&pro=1 参数是可选的,用于启用Pro 模式。这将提供对所有 Web MCP 工具的访问,包括用于 Web 交互的工具以及来自许多受支持域名的直接数据源。
如果你更愿意使用免费层级(Rapid 模式),其中仅包含 scrape_as_markdown 和 search_engine(以及它们的批处理版本),请改用此 URL:
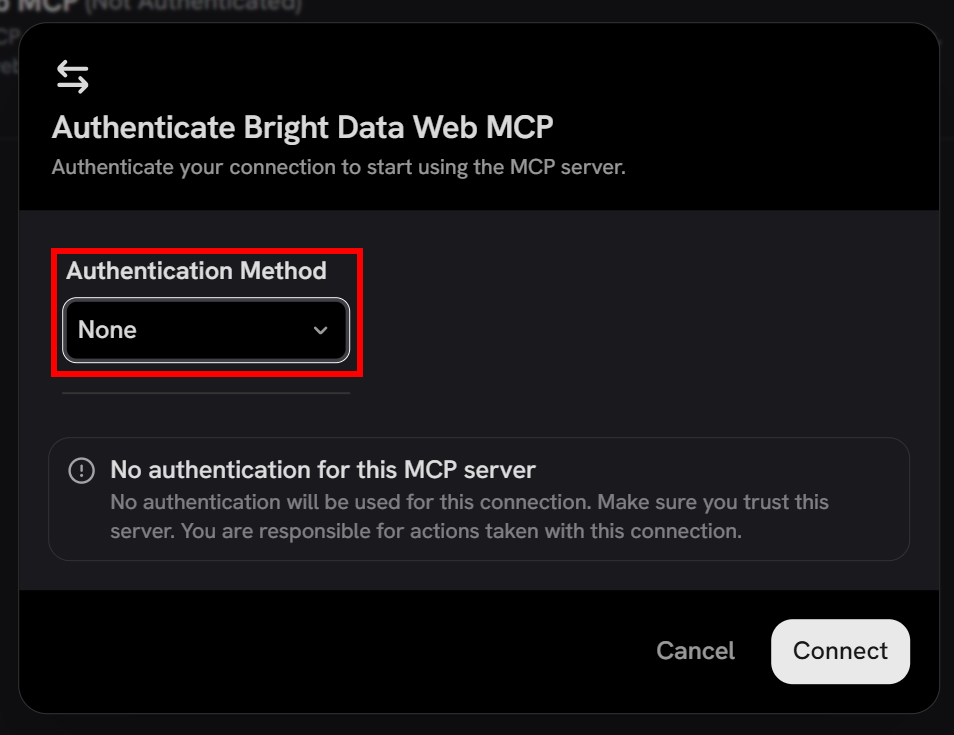
https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_TOKEN>现在点击 “Save Changes” 继续。然后你将看到身份验证设置模态框。
由于身份验证通过 URL 中的 API key 处理,将 “Authentication Method” 字段设置为 “None”,并点击 “Connect”:
在 “Bright Data Web MCP” 条目中,你会注意到 “Fetching tools…” 消息。不久之后,可用工具(在 Pro 模式下为 60+,或在 Rapid 模式下为 4 个)将出现:
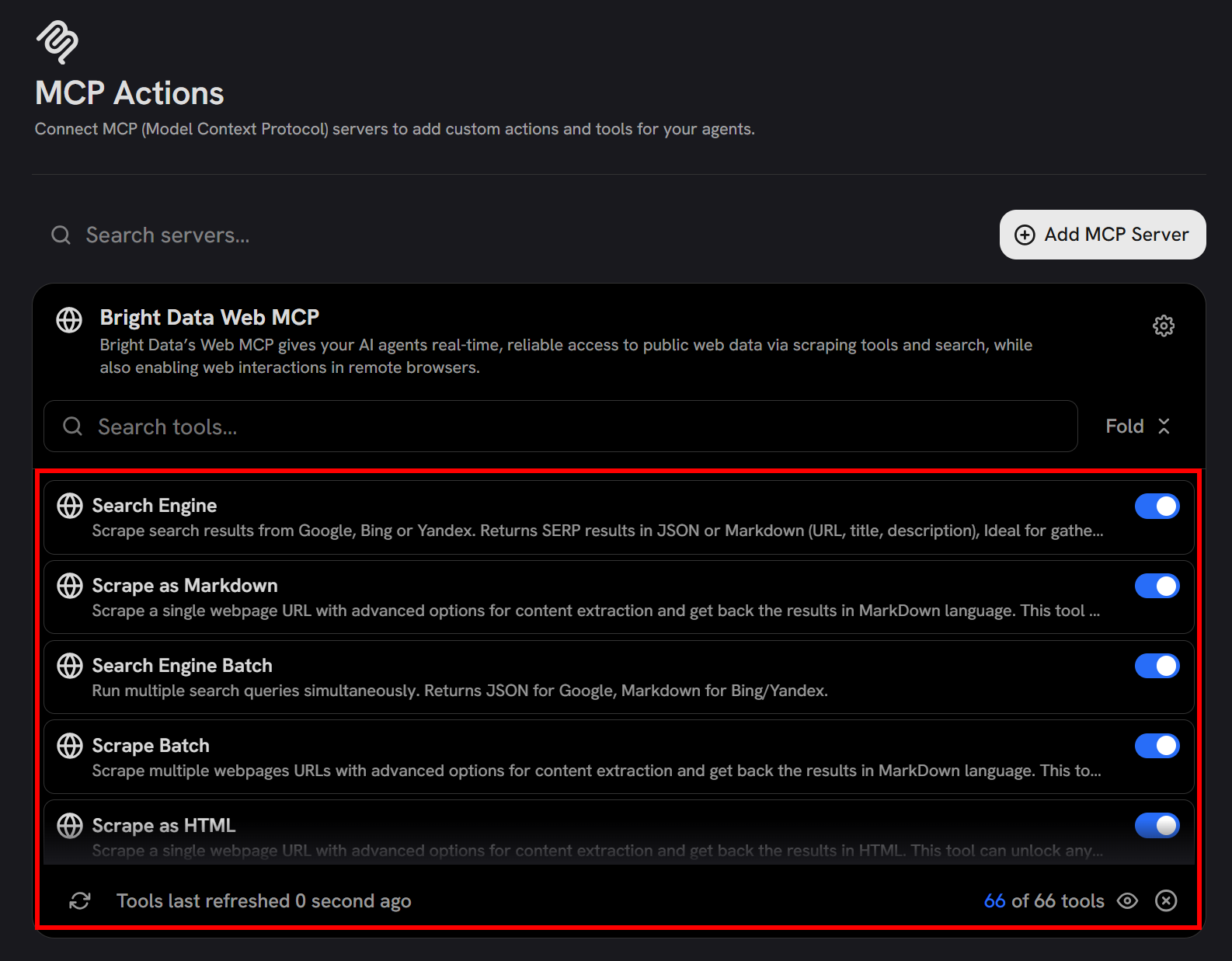
这确认 Onyx 已成功连接到远程 Web MCP 服务器并可访问其工具。在此界面中,你还可以选择启用或禁用哪些工具。
任务完成!Bright Data 现在通过 MCP 向你的 Onyx 实例暴露其 Web 搜索、数据检索和交互能力。
步骤 #5:启用 Web MCP 集成
默认情况下,已配置的 MCP 服务器在 Onyx 聊天中是禁用的。要启用它们并让底层 LLM 访问 Bright Data 工具,请在 Admin Panel 中前往 “Chat Preferences” 页面。
向下滚动到 “Actions & Tools” 部分,并确保切换并启用 “Bright Data Web MCP” 条目:
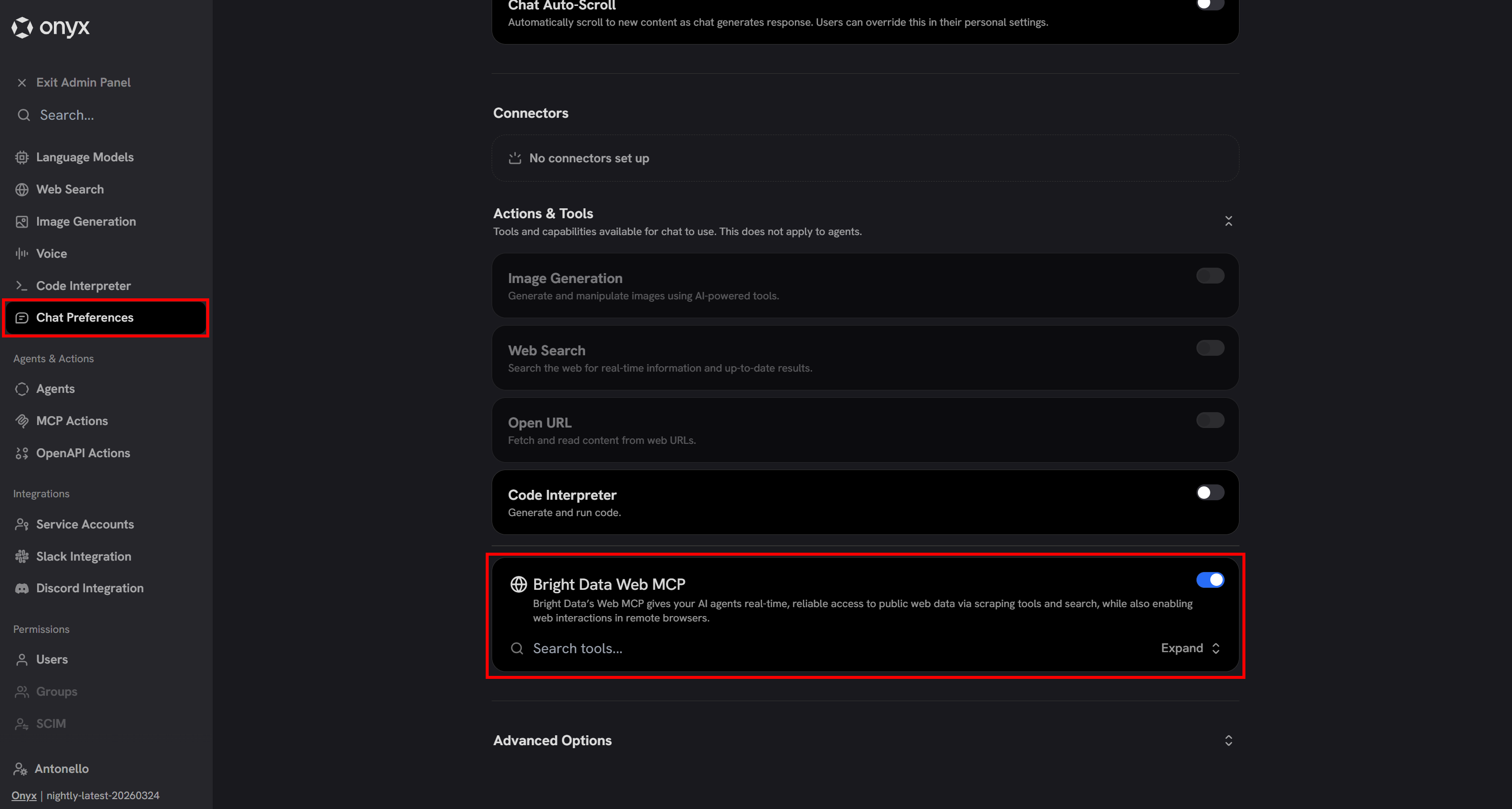
太好了!在 Onyx 中配置的 LLM(此处为 gpt-5-mini)现在可以使用通过 Web MCP 提供的 Bright Data 工具。
步骤 #6:测试集成
回到 Onyx 聊天界面,尝试运行如下提示:
Retrieve company information from the following Crunchbase page:
"https://www.crunchbase.com/organization/browser-use"
Next, search for recent news and opinions about the company. Select the 3–4 most relevant sources, including news articles and Reddit discussions, to capture both updates and public sentiment.
Generate a structured report including:
1. Company overview and key details (from Crunchbase)
2. Summary of recent news
3. Analysis of public sentiment and opinions from online sources这是普通 LLM 默认无法做到的,因为它需要访问 Web 抓取工具和搜索工具。特别是,预期行为是 LLM 将:
- 调用 Pro 模式下可用的 Crunchbase 抓取工具(或在 Rapid 模式下使用
scrape_as_markdown)。 - 使用
search_engine工具(或其批处理变体)检索 Google 搜索结果。 - 通过
scrape_as_markdown(或其批处理变体)抓取相关页面内容。 - 将所有收集的数据汇总为结构化报告。
发起提示后,你应该会得到:
上面的 GIF 经过加速,但它准确展示了前面描述的过程。这确认 Bright Data 在 Onyx 中的集成工作正常!
要进一步探索,展开计划下拉菜单以查看代理执行的所有步骤:
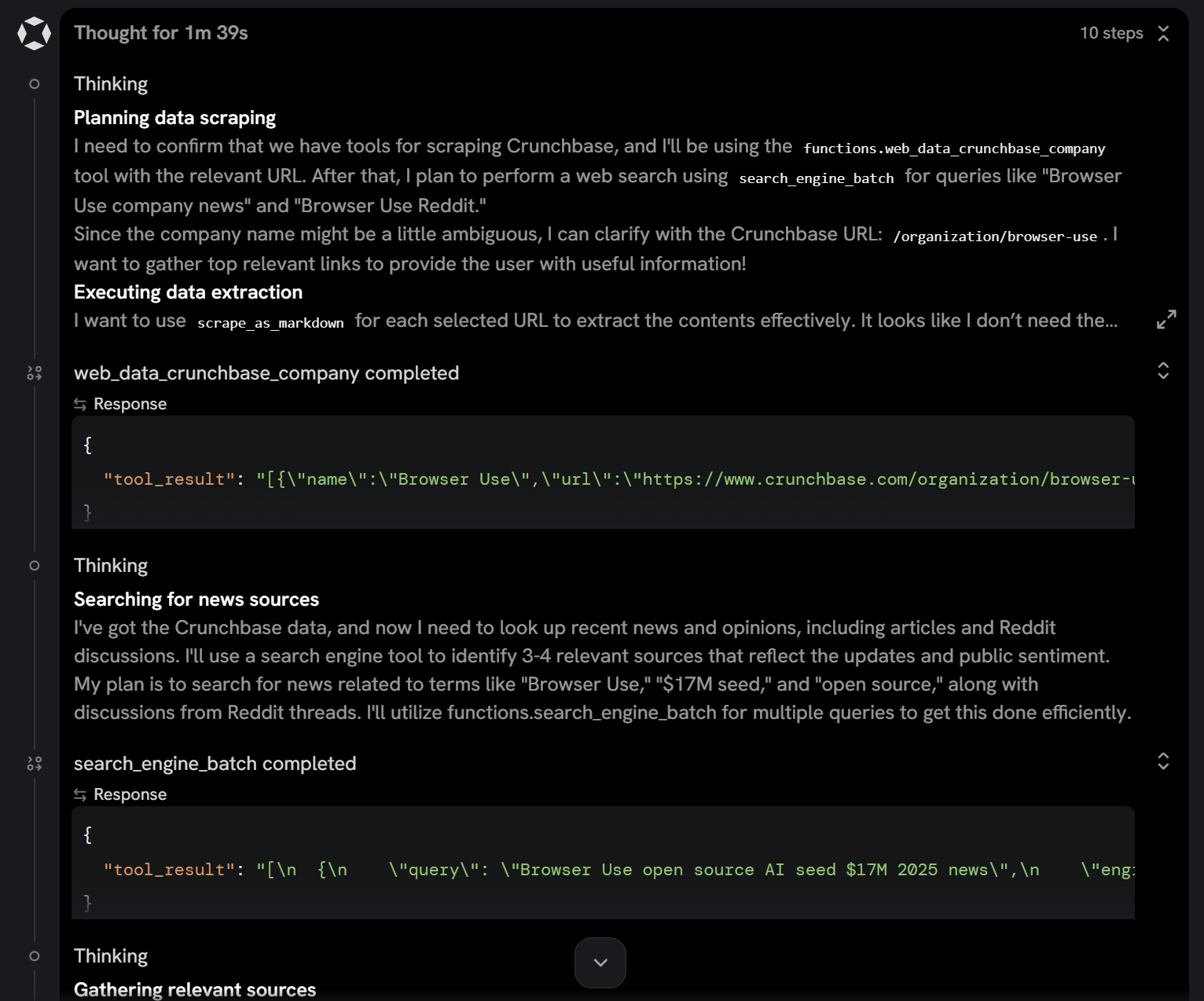
通过滚动查看,你可以观察到该代理:
- 调用了
web_data_crunchbase_company工具(在 Pro 模式下可用)以从 Crunchbase URL 检索结构化 JSON 数据。 - 使用
search_engine_batch工具(search_engine的批处理版本)并行执行相关搜索查询。 - 选择最相关的结果,并通过
scrape_batch(scrape_as_markdown的批处理版本)提取其内容。
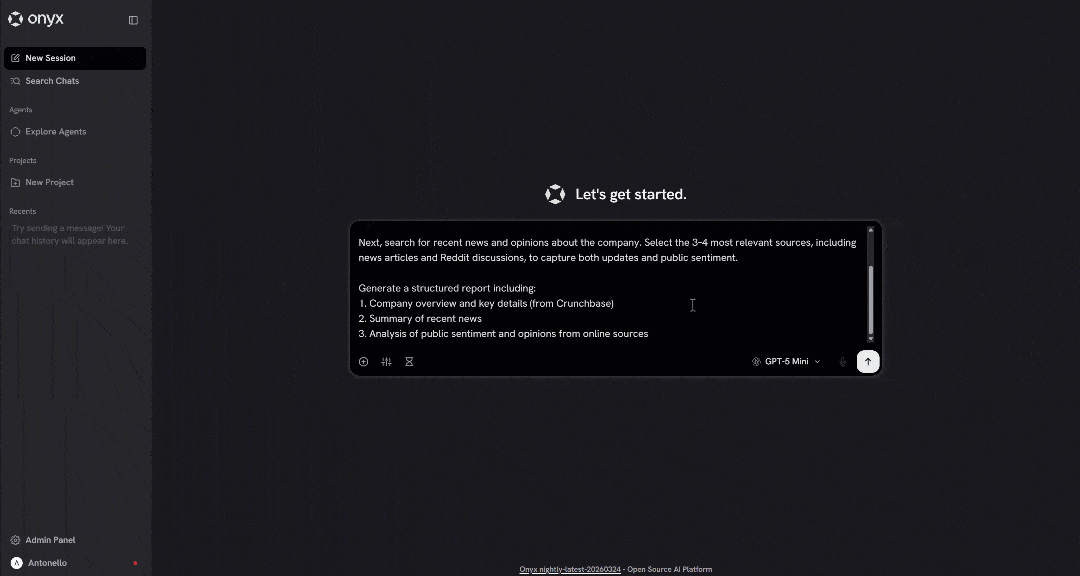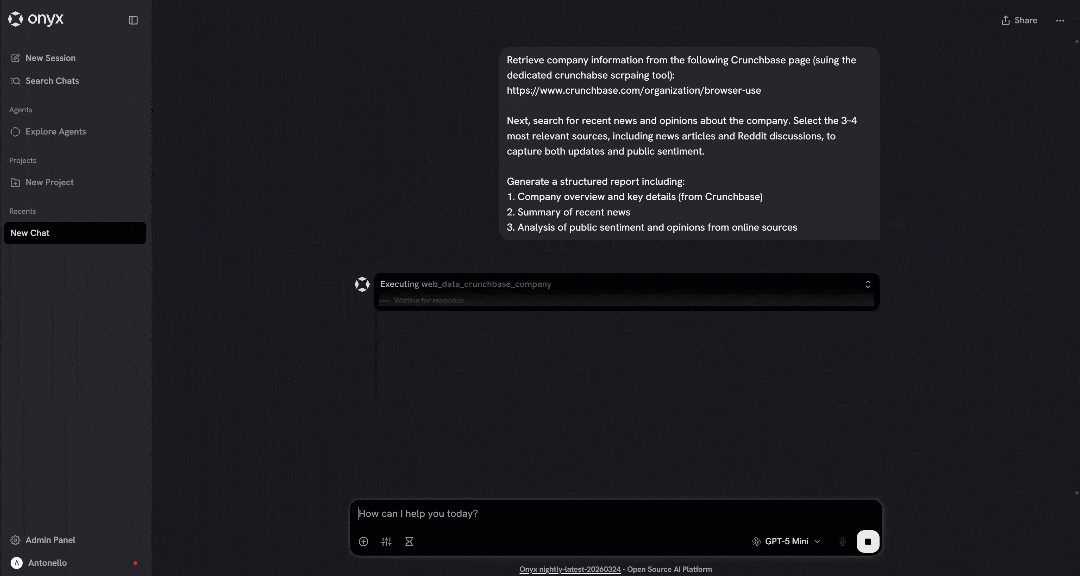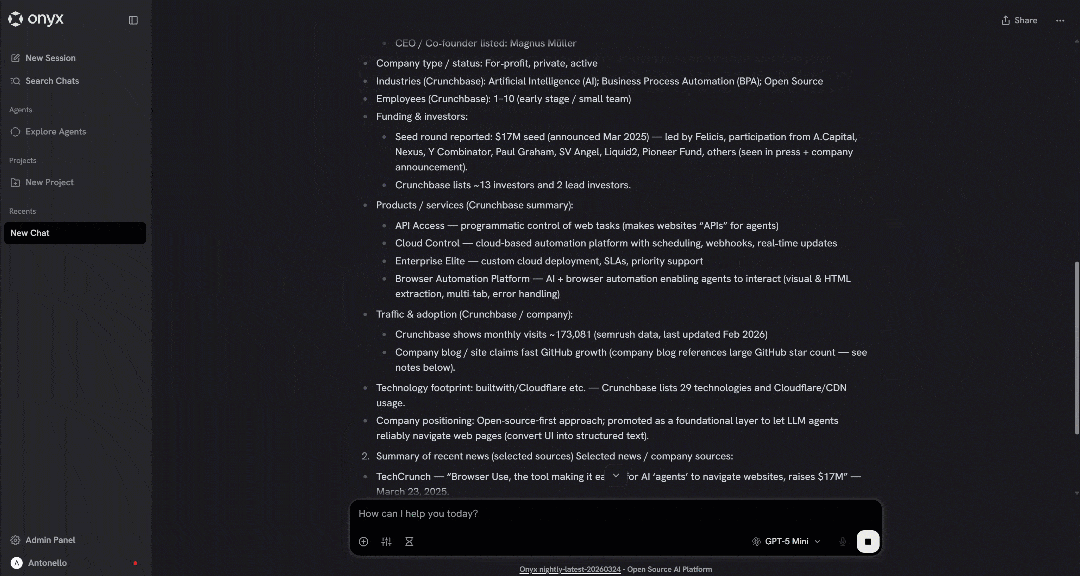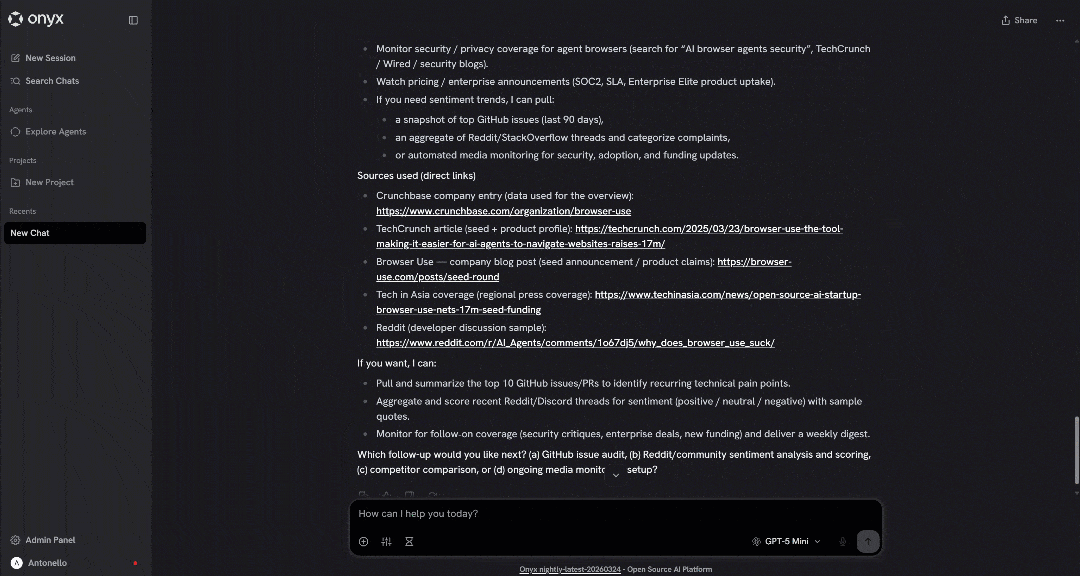
看看生成报告的一个片段:
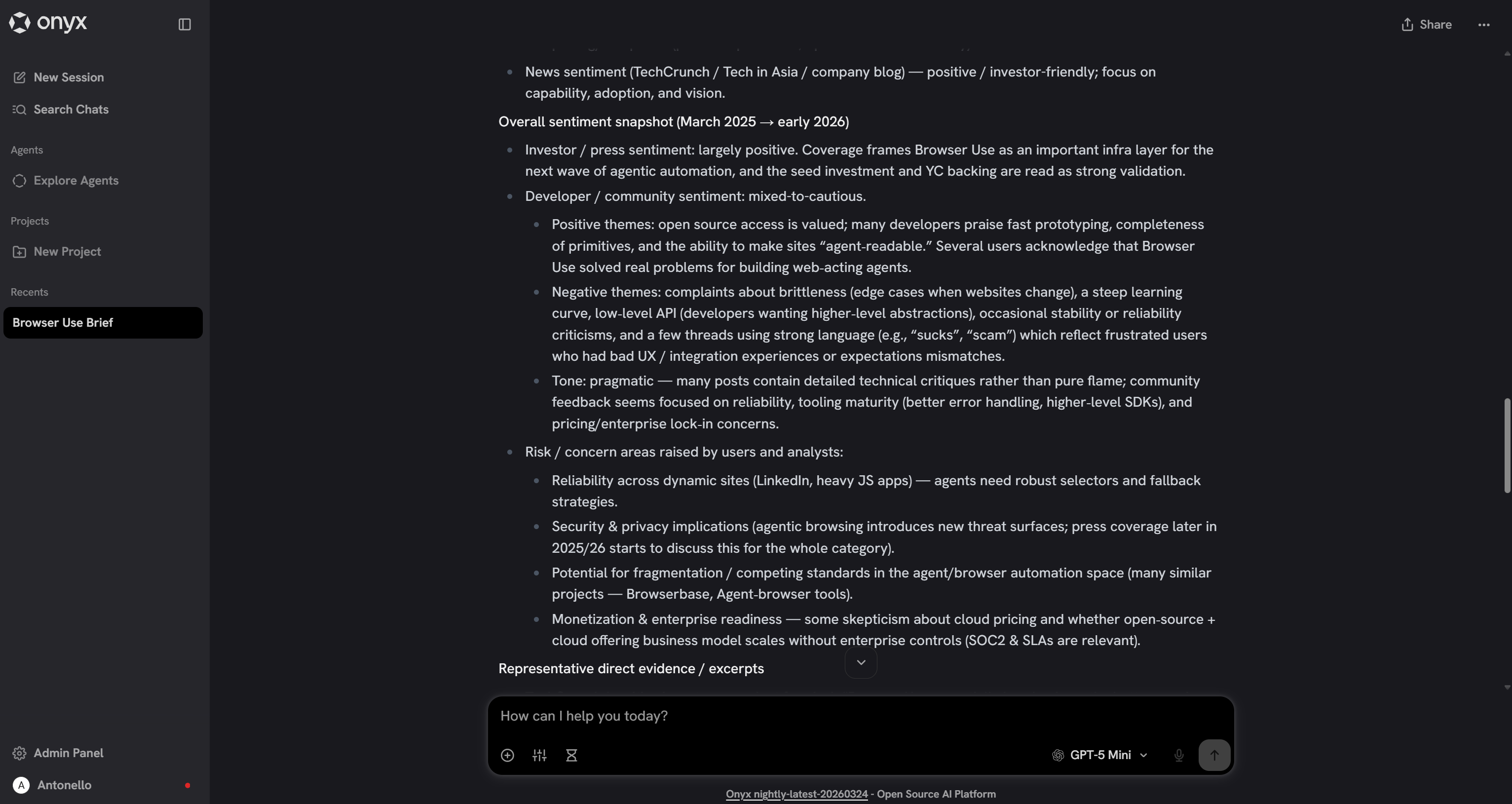
输出包含高质量、以数据为支撑的洞察,从而实现对公司的真正专业评估。
这只是一个示例。Bright Data 通过其 Web MCP 服务器支持许多其他用例!
方法 #2:通过 OpenAPI Specs 将 Bright Data 工具连接到 Onyx
作为前面所见方法的替代集成方式,通过使用 OpenAPI 规范定义的自定义动作,在 Onyx 中连接 Bright Data 工具。
注意:下面的步骤重点介绍集成 Bright Data 的 网络解锁器 和 搜索引擎 API,但它们可以很容易地适配到其他基于 API 的 Bright Data 解决方案。
前提条件
在按照下面的说明操作之前,你必须拥有一个 Bright Data 账户,并已设置好 网络解锁器 和 搜索引擎 API 区域,以及一个 API key。对 OpenAPI 规范的基本理解也会有所帮助。
要设置所需的 Bright Data 区域,请按照下面的说明操作。或者,如需更详细的指导,请参考这些文档页面:
如果你没有 Bright Data 账户,创建一个新的。如果你已经有了,只需登录。进入你的控制面板,导航到 “Proxies & Scraping” 页面,并查看 “My Zones” 表:
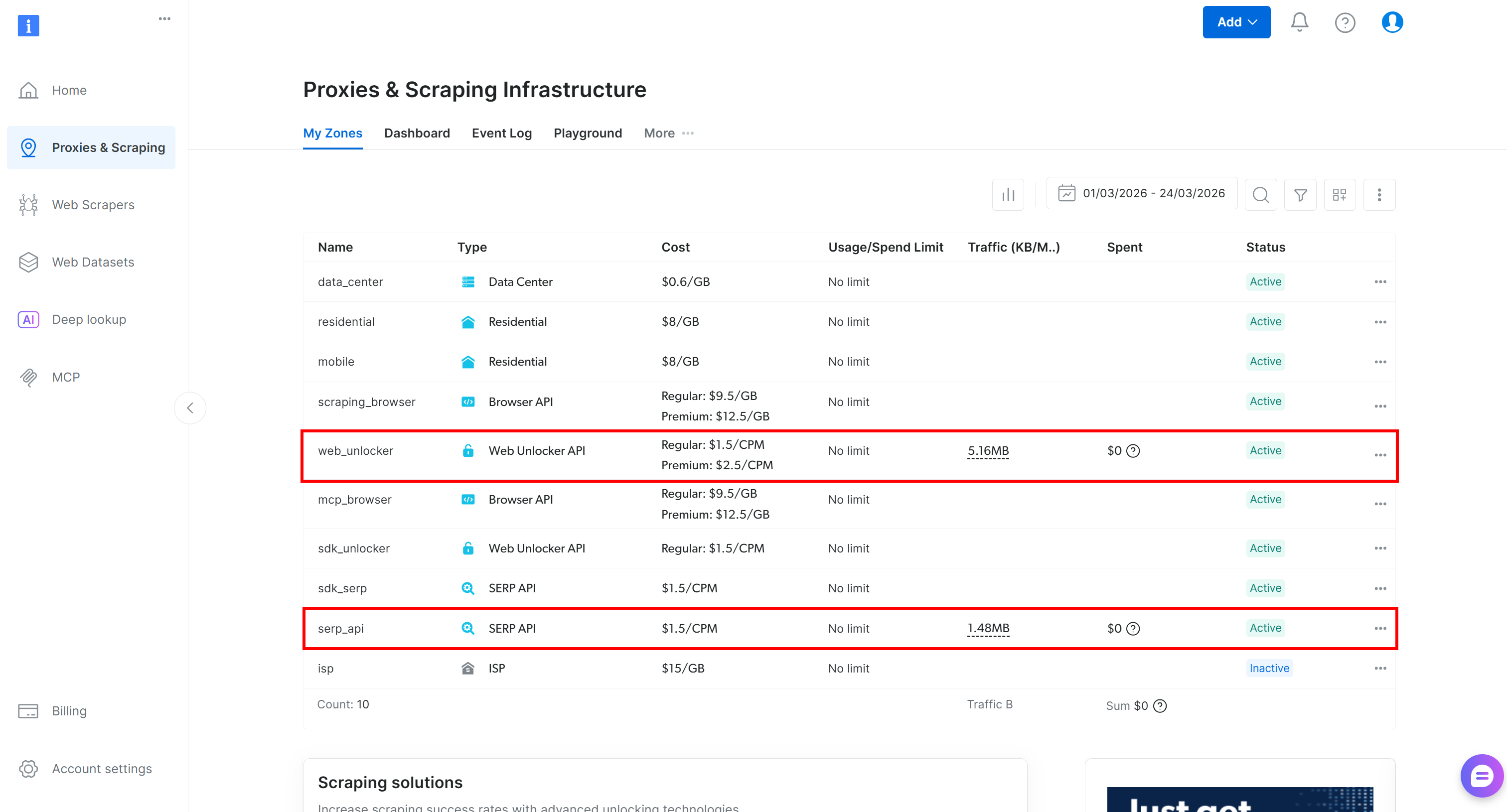
如果表中已经包含一个 网络解锁器 API 区域(例如 web_unlocker)和一个 搜索引擎 API 区域(例如 serp_api),那么你就可以开始了。这两个区域将用于通过自定义 OpenAPI 工具连接到 网络解锁器 和 搜索引擎 API 服务。
如果缺少任一区域,请创建它。滚动到 “Unblocker API” 和 “搜索引擎 API” 卡片,然后点击 “Create 区域”。按照向导添加区域:
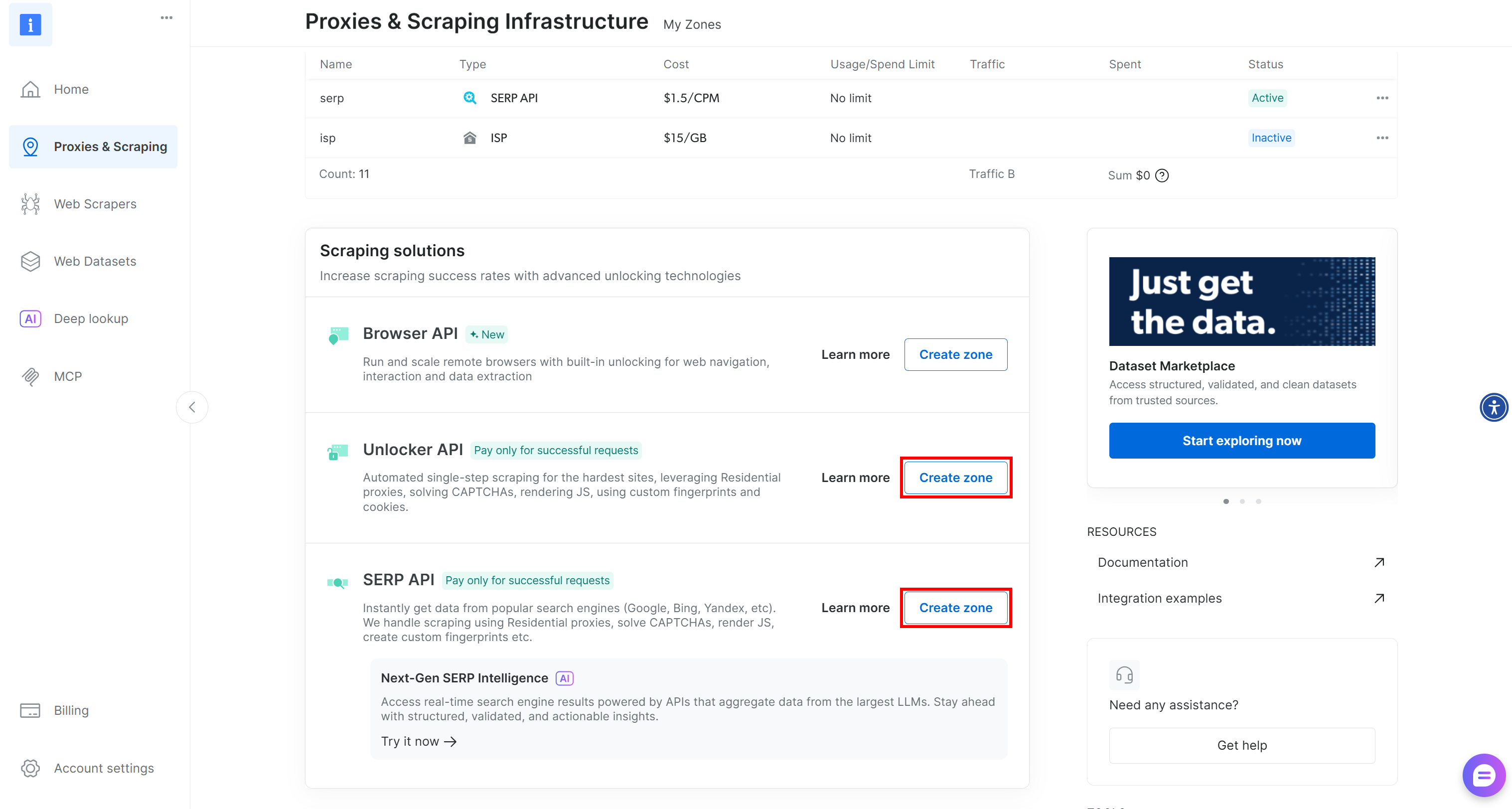
请务必记下你为两个区域分配的名称,因为你将在接下来的步骤中需要它们。最后,生成你的 Bright Data API key 并将其存放在安全的地方。
步骤 #4:添加 网络解锁器 OpenAPI Action
要添加新动作,打开 Admin Panel 并导航到 “OpenAPI Actions” 页面。然后点击 “Add OpenAPI Action” 按钮:
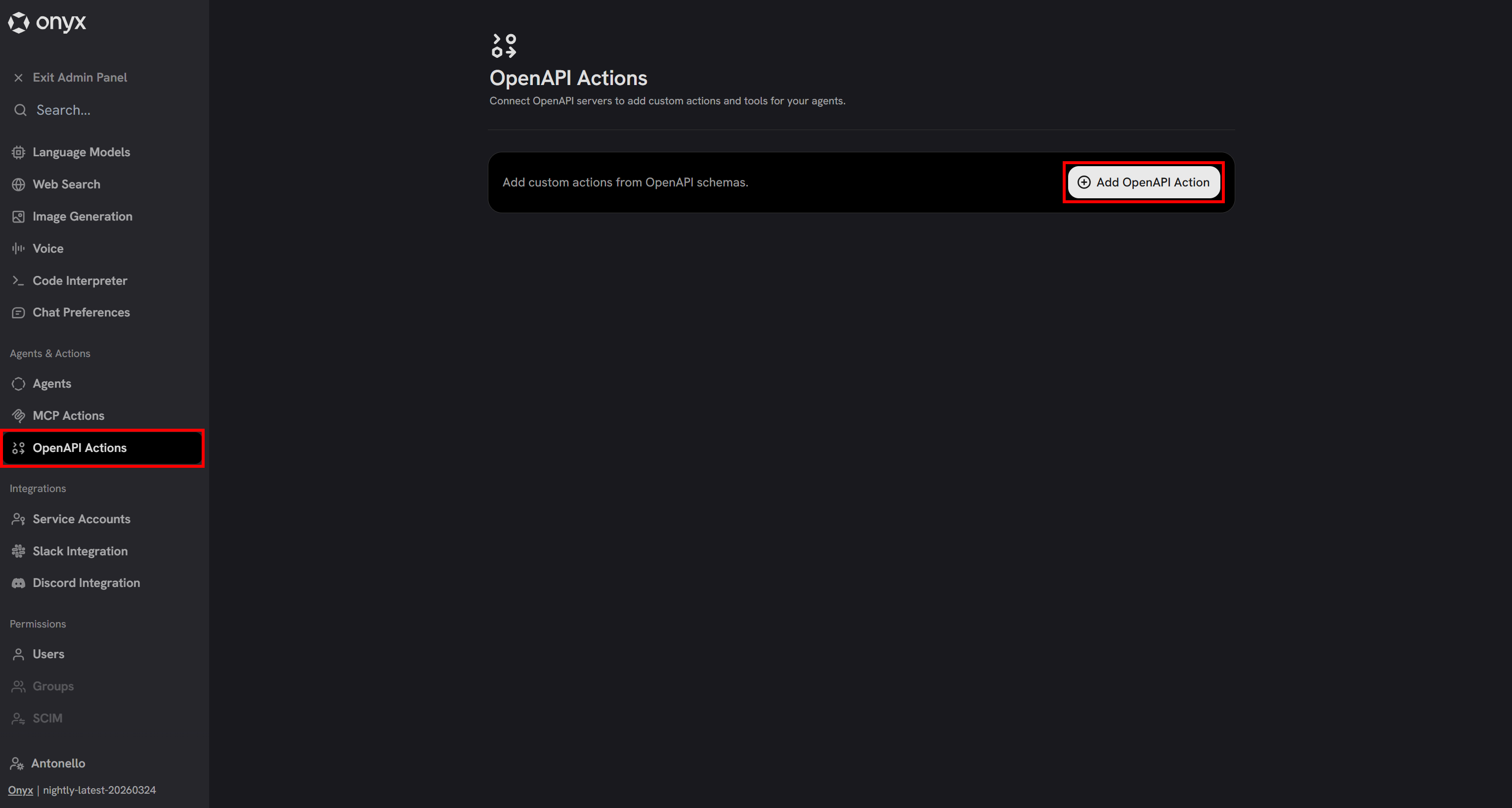
系统会要求你提供 OpenAPI schema 定义。你可以从 Bright Data OpenAPI specs 文章中的 网络解锁器 schema 的 JSON 版本 复制。
重要:你需要对 JSON spec 做的唯一更改是为 zone 字段设置一个默认值。该值应与你之前定义的 网络解锁器 API 区域名称匹配。具体来说,该部分应如下所示:
{
// ...
"properties": {
"zone": {
"type": "string",
"description": "Your Web Unlocker zone name.",
"default": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME> // e.g., "web_unlocker"
}
}
// ...
}这是必需的,因为 Onyx 不提供在运行时为请求体字段设置默认值的机制。因此,你必须为必填字段指定默认值。
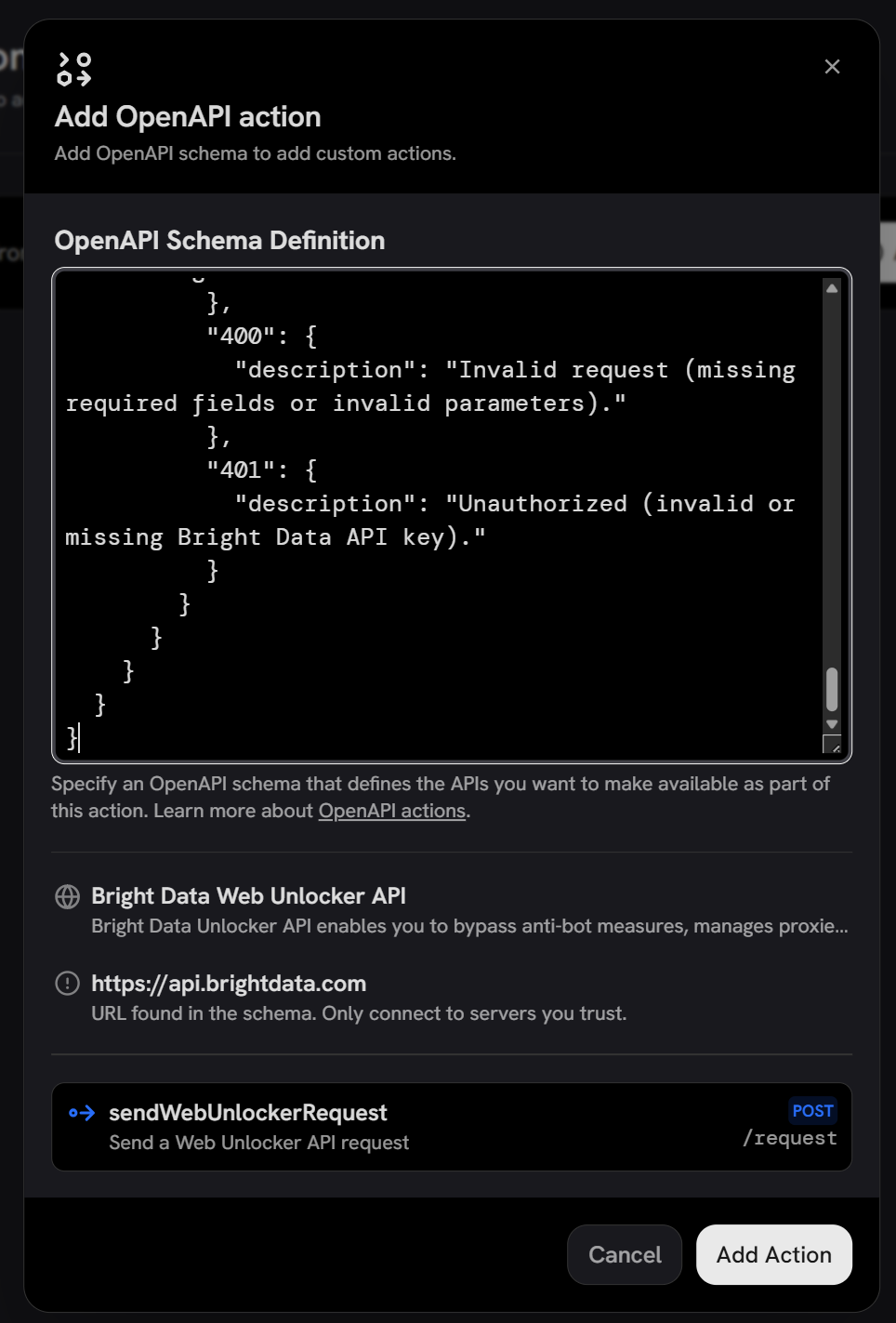
点击 “Add Action”,然后系统会提示你配置身份验证方法。选择 “Custom Authentication Header” 并按如下方式定义:
- Header:
Authorization - Value:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
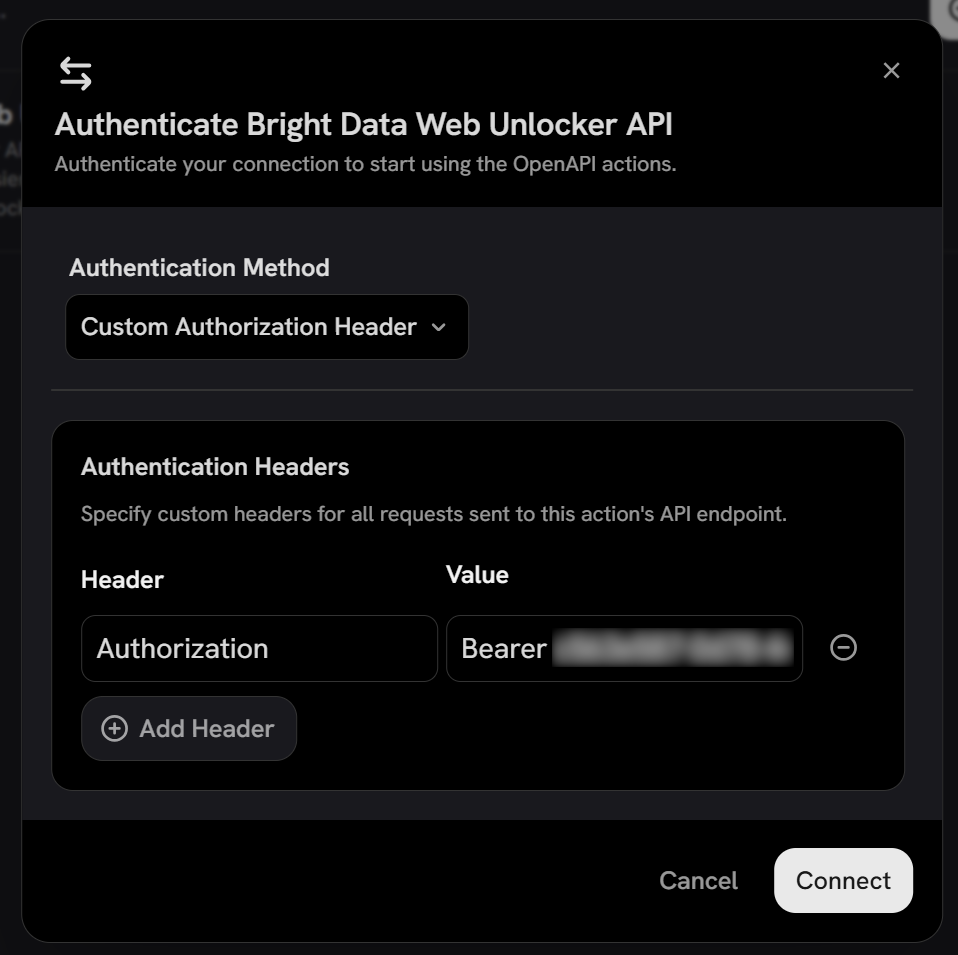
注意:Bearer <YOUR_BRIGHT_DATA_API_KEY> 是Bright Data API 用于通过 API key 进行身份验证的格式。
点击 “Connect” 确认。Bright Data 网络解锁器 API 现在将为你的账户完成身份验证,并作为 Onyx 中的一个工具可用。做得好!
步骤 #5:添加 搜索引擎 API OpenAPI Action
重复上一步,但将其适配到 搜索引擎 API 的 JSON 规范。确保将请求体中 zone 字段的默认值设置为你 Bright Data 账户中的 搜索引擎 API 区域名称。
添加后,OpenAPI Actions 部分现在应显示两个工具:
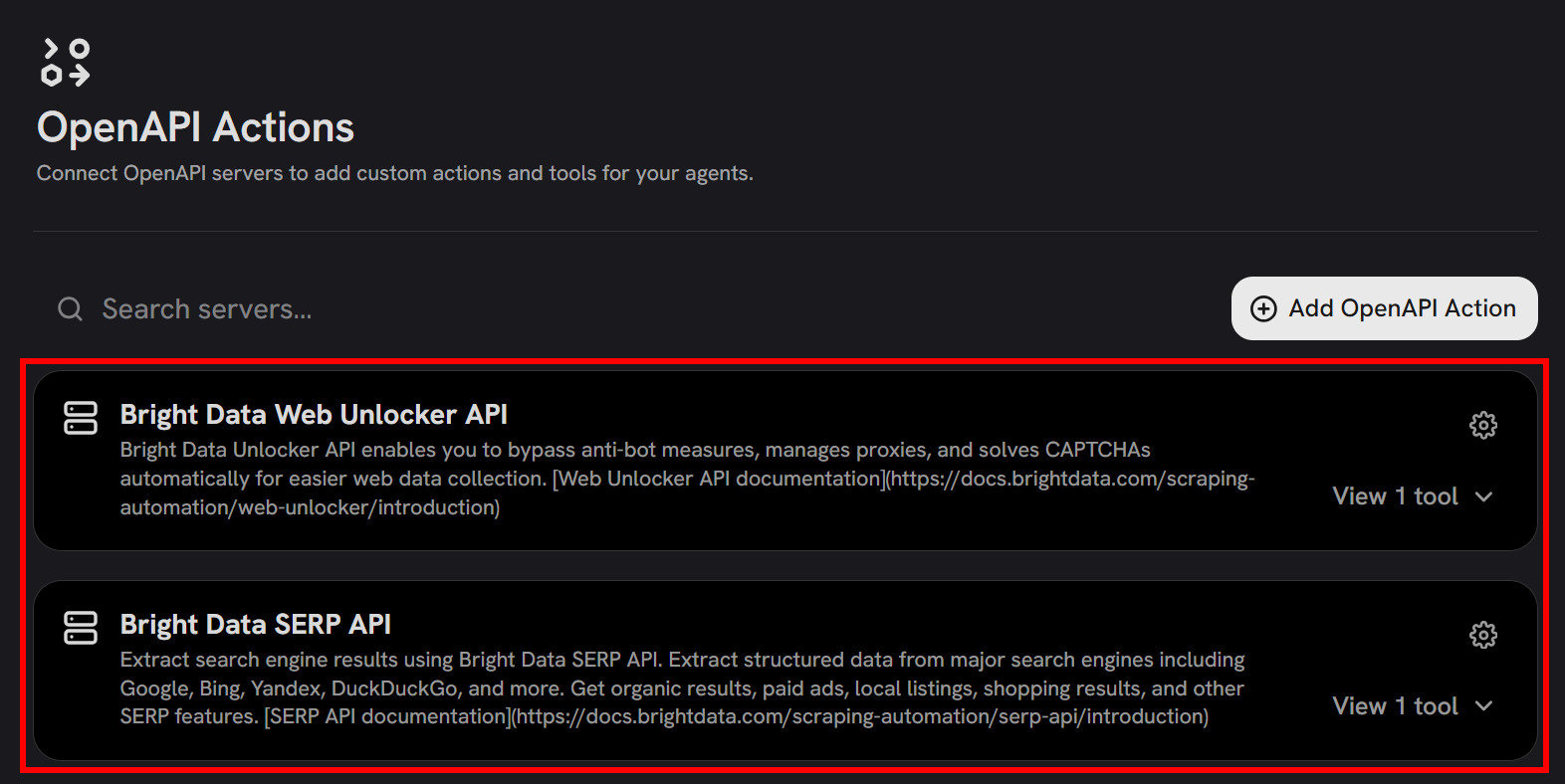
太棒了!Bright Data 网络解锁器 和 搜索引擎 API 工具现在已在 Onyx 中可用。
步骤 #6:启用 OpenAPI Tools
默认情况下,OpenAPI 工具在 Onyx 聊天中是禁用的。要启用它们,请在 Admin Panel 中前往 “Chat Preferences” 页面并将 OpenAPI 工具切换为开启:
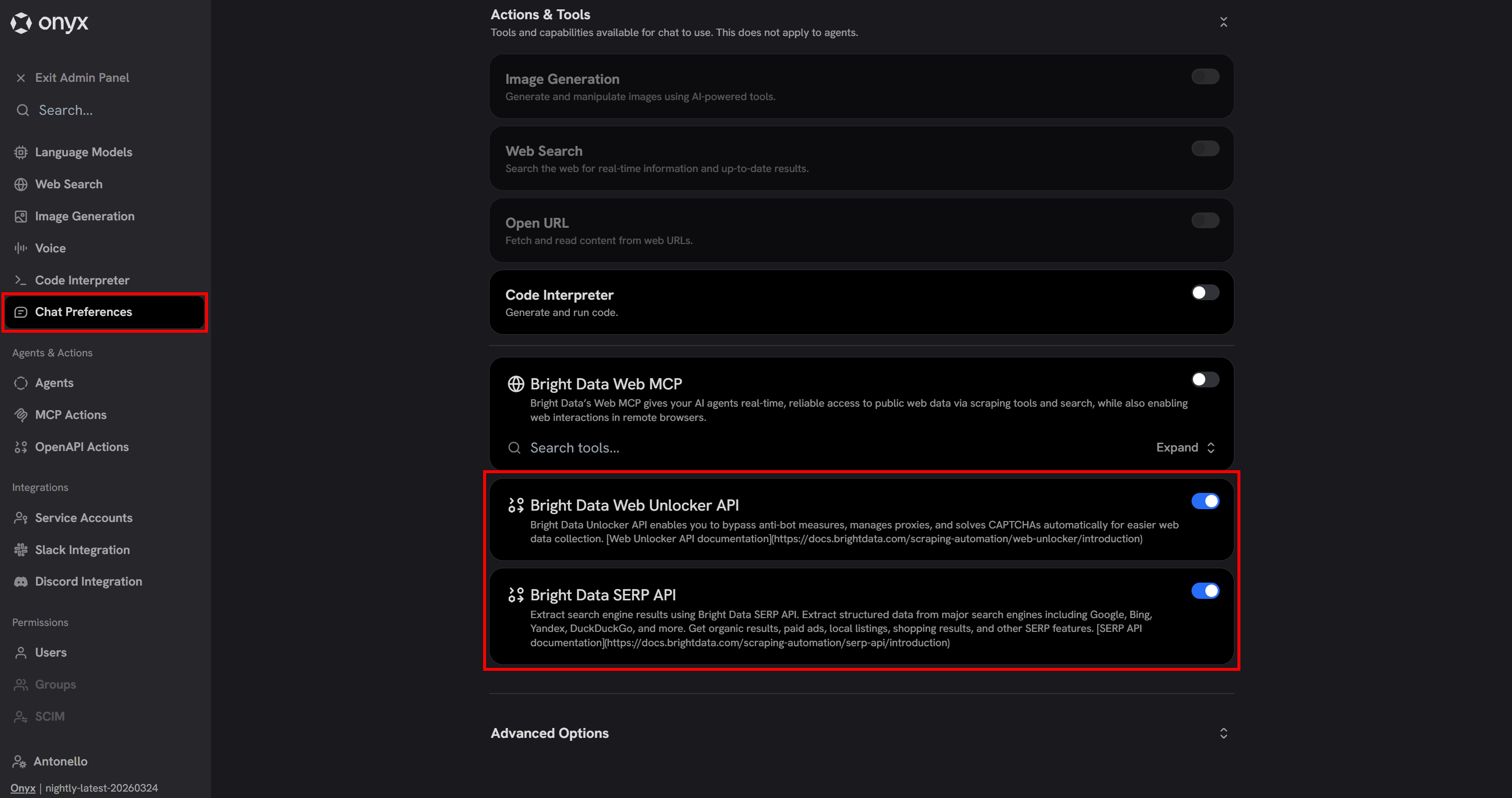
很好!由 Bright Data 驱动的 OpenAPI 工具现在可以被 Onyx 中的 LLM 调用。
步骤 #7:测试集成
要检查 Onyx 中的 LLM 是否可以自动调用 Bright Data 工具,尝试如下提示:
Search for the latest stock market news on Google. Select the top 3 most relevant articles, extract their content in Markdown, and generate a concise summary report highlighting the key insights for today.这代表了一个代理可能使用的典型搜索并提取模式,用于从 Web 获取具备上下文、最新且可验证的信息。普通 LLM 默认无法执行此操作,因为它需要同时具备 Web 搜索和抓取能力。
预期行为是 LLM 将:
- 调用 搜索引擎 API 搜索股市新闻。
- 使用 网络解锁器 API 提取顶部结果。
发起提示后,你应该会看到类似这样的内容:
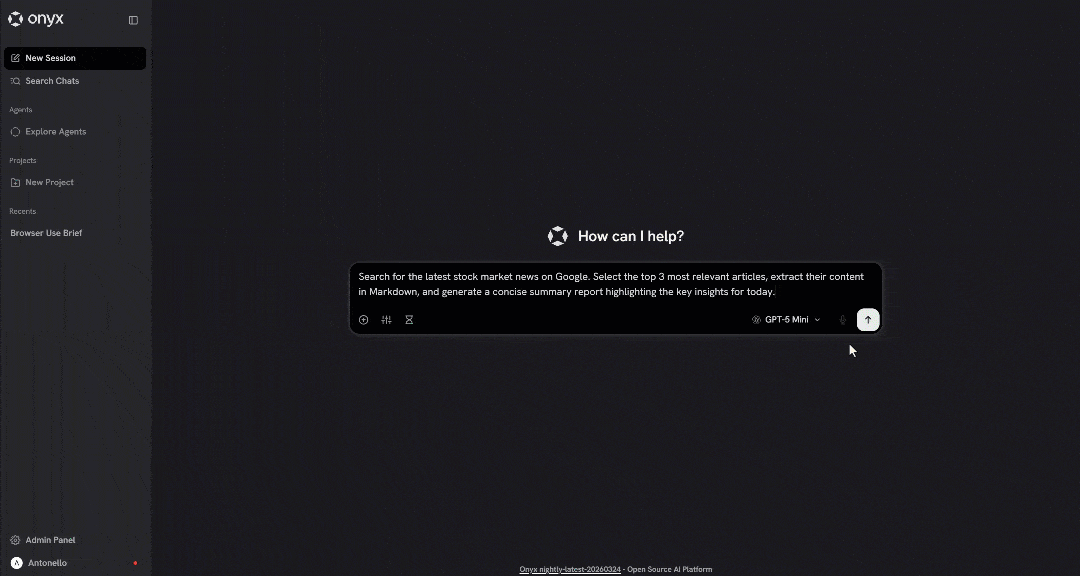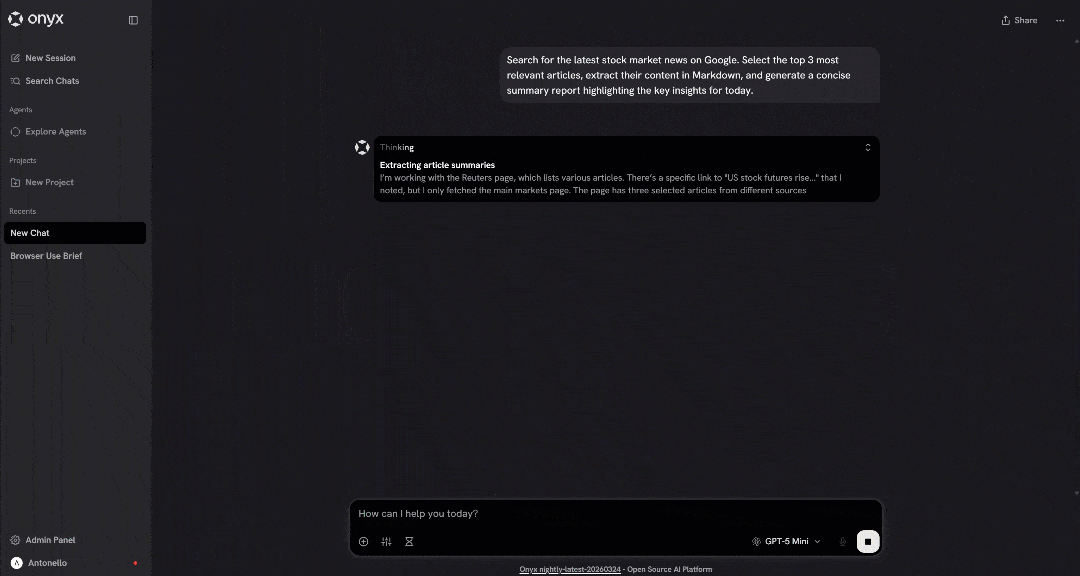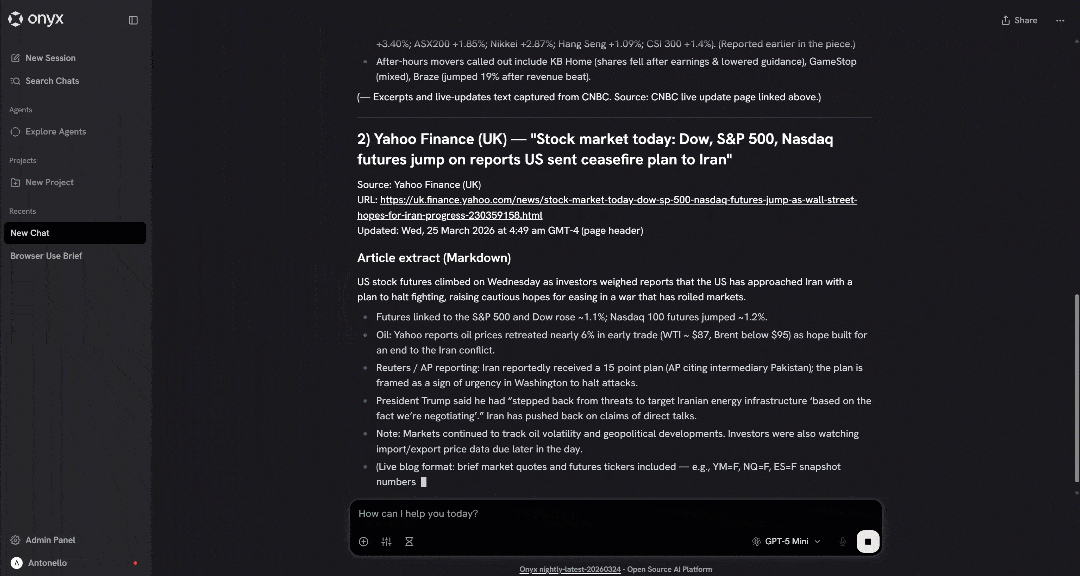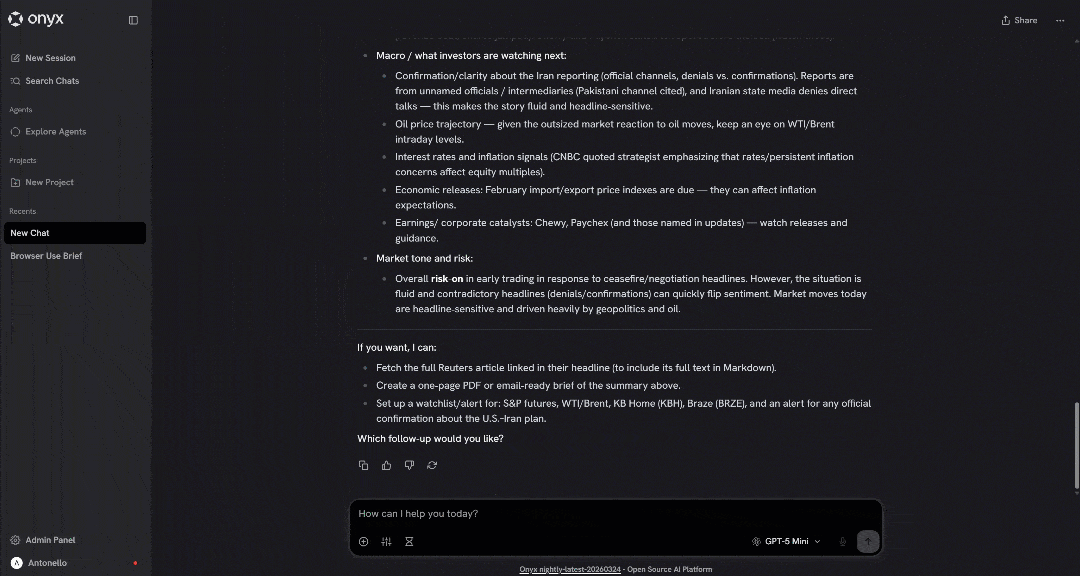
如果一切正常,你会注意到 LLM 调用了 搜索引擎 API 工具,选择了顶部新闻文章,并按预期使用 网络解锁器 API 抓取了它们的内容。
Et voilà!这确认集成正在工作。Bright Data 现在已在 Onyx 中完全可用,从而带来超强的聊天体验。
结论
在本文中,你了解了 Onyx 是什么,以及它作为 AI 搜索与助手平台带来了什么。你还看到了它由于 LLM 驱动的特性而存在的限制,以及如何使用 Bright Data 集成来解决这些限制。
如上所述,Bright Data 使代理能够访问实时 Web 数据,以获得更准确且具备上下文的响应。在 Onyx 中,这可以通过 Web MCP 实现,或通过 OpenAPI 规范直接集成 Bright Data 产品。
要进一步扩展功能,请将 Onyx 代理连接到面向 AI 的 Bright Data 全套服务。
立即免费创建 Bright Data 账户,并开始集成我们的 Web 数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




