在本指南中,您将了解到
- Ferret 是什么?
- 如何将其配置为在 Go 环境中本地使用
- 如何使用它从静态网站收集数据
- 如何使用它搜索动态网站
- 雪貂的主要局限性及解决方法
让我们深入了解一下!
用于网络抓取的 Ferret 简介
在看到它的实际应用之前,请先了解一下 Ferret 是什么、它如何工作、它能提供什么以及何时使用。
什么是雪貂?
Ferret是一个用 Go 编写的开源网页抓取库。它的目标是使用声明式方法简化从网页中提取数据的过程。具体来说,它通过使用自己定制的声明式语言:Ferret 查询语言(FQL),抽象出解析和提取的复杂技术。
Ferret 在 GitHub 上拥有近 6千个 star,是最受欢迎的 Go 语言网页抓取库之一。它可嵌入式使用,并同时支持静态和动态网页抓取。
FQL:用于声明式网络抓取的雪貂查询语言
Ferret 查询语言(FQL)是一种通用查询语言,灵感主要来自 ArangoDB 的 AQL。虽然它的功能更多,但 FQL 主要用于从网页中提取数据。
FQL 采用声明式方法,这意味着它关注的是要检索哪些数据,而不是如何检索。与 AQL 类似,它与 SQL 也有相似之处。但与 AQL 不同的是,FQL 是严格只读的。请注意,任何形式的数据操作都必须使用特定的内置函数。
有关 FQL 语法、关键字、结构和支持的数据类型的更多信息,请参阅FQL 文档页面。
使用案例
如官方 GitHub 页面所强调的,Ferret 的主要使用场景包括:
- UI 测试:模拟浏览器的用户交互行为,自动化网页应用程序的测试,以验证网页元素在不同场景下的正确表现与渲染效果。
- 机器学习:通过从网页中提取结构化数据来创建高质量的数据集,随后可以用于机器学习模型的训练或验证,从而有效提升模型表现。查看如何使用网页抓取进行机器学习。
- 数据分析:抓取并整合网页数据(如价格、用户评价或用户活动),用于挖掘洞察、追踪趋势,或为数据仪表盘提供数据支持。
同时,请记住,网页抓取所能支持的应用场景远远不止上述示例。
开始接触雪貂
既然你已经知道了 Ferret 是什么,那么现在就可以看看它在静态和动态网页上的应用了。如果你还不熟悉这两者之间的区别,请阅读我们的指南:网页抓取中的静态与动态内容。
让我们建立一个使用 Ferret 进行网络搜索的环境!
先决条件
确保在本地计算机上安装了以下程序:
- 转到
- Docker
要验证 Golang 是否已安装就绪,请在终端运行以下命令:
go version您应该会看到类似下面的输出:
go version go1.24.3 windows/amd64如果出现错误,请安装 Golang 并根据操作系统进行配置。
同样,验证系统是否已安装并正确配置 Docker。
创建雪貂项目
现在,为你的 Ferret 网络扫描项目创建一个文件夹,并导航进入:
mkdir ferret-web-scraping
cd ferret-web-scraping为你的操作系统下载 Ferret CLI,直接解压到ferret-web-scraping/文件夹。运行
./ferret help输出结果应为
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.接下来,在你喜欢的集成开发环境(如 Visual Studio Code)中打开项目文件夹。在项目文件夹中创建一个名为scraper.fql 的文件:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fql将包含用于网络抓取的 FQL 声明逻辑。
配置 Ferret Docker 设置
要使用 Ferret 的所有功能,必须在本地安装或在 Docker 中运行 Chrome 或 Chromium。官方文档建议在 Docker 容器中运行 Chrome/Chromium。
你可以使用任何基于 Chromium 的无头镜像,但建议使用montferret/chromium镜像。通过以下方式获取
docker pull montferret/chromium然后,使用此命令启动 Docker 映像:
docker run -d -p 9222:9222 montferret/chromium注意:如果想查看 FQL 脚本执行过程中浏览器中发生的情况,请在主机上启动 Chrome 浏览器并启用远程调试功能:
chrome.exe --remote-debugging-port=9222用 Ferret 抓取静态网站
请按照以下步骤学习如何使用 Ferret 抓取静态网站。在本例中,目标页面将是沙盒网站 “Books to Scrape“:

我们的目标是使用 Ferret 的声明式方法,通过 FQL 从页面上的每本书中提取关键信息。
步骤 #1:连接到目标网站
在scraper.fql 中,使用DOCUMENT函数连接目标页面:
LET doc = DOCUMENT("https://books.toscrape.com/")LET允许您在 FQL 中定义变量。在该指令之后,doc将包含目标页面的 HTML。
步骤 #2:选择所有书籍元素
首先,通过浏览器访问并检查目标网页,熟悉其结构。具体来说,右键单击图书元素,选择 “检查 “选项,打开 DevTools:

请注意每个书籍元素都是位于父节点 <section> 之下的一个 <article> 节点。你可以使用 ELEMENTS() 函数选取所有书籍元素:
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS()将作为第二个参数传递的 CSS 选择器应用于文档。换句话说,它会在页面上选择所需的 HTML 元素。
遍历所选元素列表,并准备对其应用抓取逻辑:
FOR book_element IN book_elements
// book scraping logic...太棒了!是时候遍历每个图书元素并从中提取数据了。
步骤 #3:从每个报价单中提取数据
现在,检查一个 HTML 书本元素:

请注意,你可以抓取:
- 图片链接:来自
.image_container img元素的src属性。 - 书籍标题:来自
h3 a元素的title属性。 - 书籍详情页面的链接:来自
h3 a节点的href属性。 - 书籍价格:来自
.price_color元素的文本内容。 - 库存信息:来自
.instock元素的文本内容。
使用以下方法实现此数据解析逻辑:
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}其中,base_url是在for循环之外定义的变量:
LET base_url = "https://books.toscrape.com/"在上述代码中
- 使用
ELEMENT()可以使用 CSS 选择器选择页面上的单个元素。 attributes是ELEMENT()返回的所有对象都具有的特殊属性。它包含当前元素的 HTML 属性值。INNER_TEXT()返回当前元素中包含的文本。TRIM()删除前导和尾部空白。
太棒了静态抓取逻辑已完成。
步骤 #4:将所有内容整合在一起
您的scraper.fql文件应如下所示:
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}正如你所看到的,抓取逻辑更侧重于提取哪些数据,而不是如何提取。这就是使用 Ferret 进行声明式网络抓取的威力所在!
步骤 #5:执行 FQL 脚本
使用以下命令执行您的 Ferret 脚本:
./ferret exec scraper.fql在终端中,输出结果将是
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]这是一个 JSON 字符串,包含从网页中收集到的所有书籍数据。如需了解非声明式数据解析方法,请参阅我们的Go 网络刮削指南。
任务完成!
用 Ferret 抓取动态网站
Ferret 还支持抓取需要执行 JavaScript 的动态网站。在本节指南中,目标网站将是“Quotes to Scrape “网站的 JavaScript 延时版本:

该页面使用 JavaScript 在短暂延迟后将引用元素动态注入 DOM。这种情况需要执行 JavaScript,因此需要在浏览器中渲染页面。(这也是我们之前设置 Chromium Docker 容器的原因)。
请按照以下步骤学习如何使用 Ferret 处理动态网页!
步骤 #1:在浏览器中连接到目标网页
使用以下行文通过无头浏览器连接目标页面:
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})请注意DOCUMENT()函数中驱动程序字段的使用。它告诉 Ferret 在通过 Docker 配置的无头 Chroumium 实例中呈现页面。
步骤 #2:等待目标元素出现在页面上
在浏览器中访问目标页面,等待加载引用元素,然后检查其中一个:
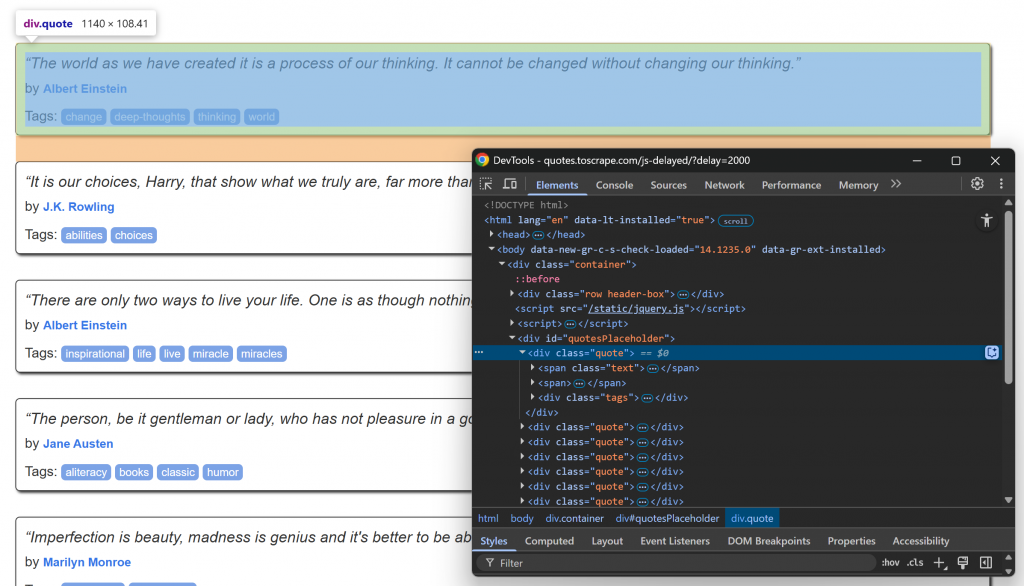
请注意如何使用.quoteCSS 选择器选择引用元素。这些引用元素将在短暂延迟后通过 JavaScript 呈现,因此您必须等待。
使用 Ferret 中的WAIT_ELEMENT()函数等待引用元素出现在页面上:
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)这是对依赖 JavaScript 渲染内容的动态网页进行抓取时必须使用的结构。
步骤 #3:应用抓取逻辑
现在,请关注.quote节点内 info 元素的 HTML 结构:
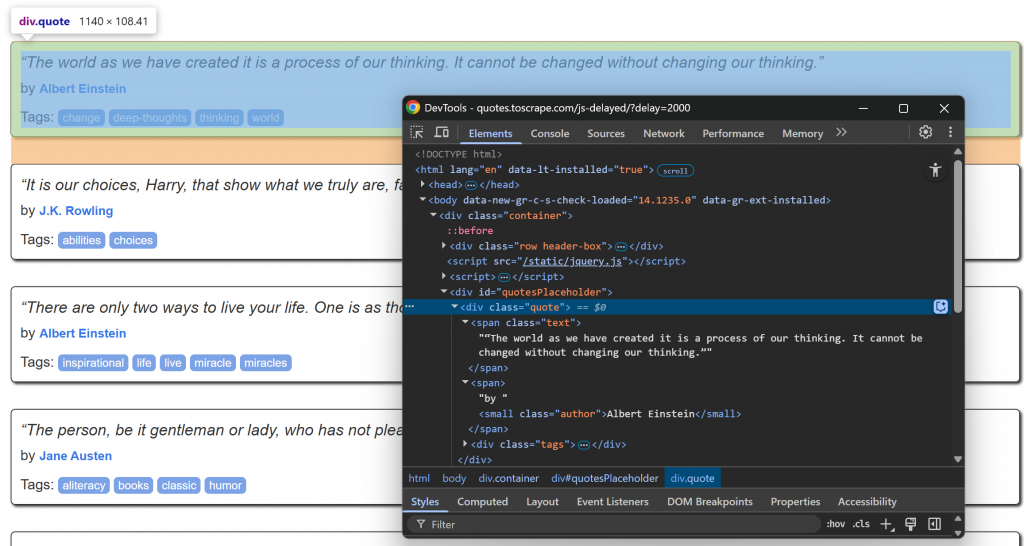
请注意,您可以进行刮削:
.quote中的引用文本- 作者来自
.author
使用以下工具执行 Ferret 网络扫描逻辑
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}真棒!解析逻辑已完成。
步骤 #4:组装一切
scraper.fql文件应包含
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}如你所见,这与静态网站的脚本并无太大区别。原因还是因为 Ferret 采用了声明式的网络抓取方法。
步骤 #5:运行 FQL 代码
通过以下命令运行您的 Ferret 数据抓取脚本:
./ferret exec scraper.fql这一次,结果将是
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]就是这样!这正是从 JavaScript 渲染的页面中获取的结构化内容。
雪貂声明式网络抓取方法的局限性
毋庸置疑,Ferret 是一款功能强大的工具,也是为数不多的采用声明式方法进行网络抓取的工具之一。然而,它至少有三大缺点:
- 文档不完善,更新不频繁:虽然官方文档包含有用的文本,但缺乏全面的 API 参考资料。这使得构建复杂脚本变得十分困难。此外,该项目没有定期更新,这意味着它可能会落后于现代抓取技术。
- 不支持反窃取旁路:Ferret 不提供处理验证码、速率限制或其他高级反抓取防御的内置机制。因此,它不适合对受保护较强的网站进行抓取。
- 表达能力有限:FQ(Ferret 查询语言)仍在开发中,其灵活性和控制能力不如 Playwright 或 Puppeteer 等更先进的抓取工具。
这些限制无法通过简单的集成轻松解决。此外,不要忘记 Ferret 的核心重点是检索网络数据。因此,解决办法是考虑采用更强大的替代方案。
Bright Data 的人工智能基础架构包括一套为可靠的智能网络数据提取量身定制的高级服务。这些服务使您能够从任何网站大规模检索数据。
结论
在本教程中,您学习了如何使用 Ferret 在 Go 中进行声明式的网页数据抓取。如演示所示,这个库支持抓取静态和动态网页数据,让您只需关注要提取的数据,而无需关注如何抓取的细节。
然而,Ferret 存在一些功能限制,可能不是最佳的数据抓取解决方案。如果您正在寻找一种更简单、高效且易于扩展的方式来获取网页数据,可考虑使用网页抓取 API(Web Scraper APIs),该 API 提供专用终端,从超过120个热门网站获取最新鲜、结构化且完全合规的网页数据。
立即注册Bright Data账号,试用我们强大的网页数据抓取基础设施!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。