

在本教程中,您将学到
- 什么是 Botright 及其工作原理
- 如何将其用于网络搜索
- 使用 Botright 解决验证码问题的分步指南
- 在抓取工作流程中解决验证码问题的 Botright 替代方案
- 该图书馆的局限性以及如何克服这些局限性
让我们深入了解一下!
什么是 Botright?
Botright是一个开源 Python 网络抓取框架,用于自动进行浏览器交互并从网站中提取数据。它利用浏览器自动化和隐身技术来模仿真实用户行为。这使它能有效地搜索动态网站和受 Cloudflare 等反僵尸系统保护的网站。
它基于 Playwright,使用机器学习模型帮助你绕过验证码。为了达到阻止机器人的目的,验证码的设计对人类来说很容易解决,但对自动脚本来说却很困难。尽管如此,一些机器学习模型仍然强大到足以战胜它们。
👍优点:
- 反僵尸检测规避:Botright 专门用于绕过反僵尸系统。它通过改变浏览器指纹、使用真实或修改过的浏览器引擎以及模拟类似人类的交互等功能来实现这一目标。
- 内置验证码解决功能:它提供内置的机器学习功能,可解决常见的验证码问题。
- 处理动态内容:作为一款浏览器自动化工具,它能处理 JavaScript 繁重的网站和动态内容加载。
👎Cons:
- 依赖性强:为了显示其验证码解决功能,它依赖于一些数学、机器学习和高级交互库。这些都会使整个安装文件的大小达到几 GB。
- 不断变化的反僵尸环境:随着网站不断更新其僵尸检测技术和验证码,任何反检测库的有效性都会随时间推移而降低。
- 未维护:该库更新不频繁,需要较旧版本的 Python 以及一些手动调整才能运行。
如何使用 Botright 进行网络抓取
请记住,Botright 是在 Playwright 的基础上构建的。因此,在初始化之后,您就可以使用 Playwright 提供的 API 进行网络抓取了:
import asyncio
import botright
async def main():
# Create a Botright browser instance
botright_client = await botright.Botright()
browser = await botright_client.new_browser()
# Create a new page instance
page = await browser.new_page()
# Visit the target page
await page.goto("https://example.com")
# Scraping logic with the Playwright API...
# Close the botright browser instance
await botright_client.close()
# Execute the scraper function
if __name__ == "__main__":
asyncio.run(main())请注意,Botright 仅在异步模式下可用,因此您必须通过asyncio 使用它。
在 Botwright 中初始化浏览器后,您就可以使用Playwright API 进行网页抓取了。
如何使用 Botright 解决验证码问题:分步指南
Botright 真正的超能力是解决验证码的能力。根据官方 GitHub 页面的介绍,这些是它能解决的验证码:
| 验证码类型 | 已解决 | 成功率 |
|---|---|---|
| 验证码 | hcaptcha-challenger |
高达 90 |
| 重新验证 | 再识别器 |
从 50% 到 80 |
| v3 Intelligent Mode | Botright 的隐蔽性 | 100% |
| v3 Slider Captcha | cv2.matchTemplate |
100% |
| v3 Nine Captcha | CLIP 检测 | 50% |
| v3 Icon Captcha | cv2.matchTemplate/ SSIM / CLIP |
70% |
| v4 Intelligent Mode | Botright 的隐蔽性 | 100% |
| v4 Slider Captcha | cv2.matchTemplate |
100% |
| v4 GoBang Captcha | 数学计算 | 100% |
| v4 Icon Captcha | cv2.matchTemplate/ SSIM / CLIP |
60% |
| v4 IconCrush Captcha | 数学计算 | 100% |
在本指导章节中,您将了解如何使用 Botright 解决Google 重验证码问题。请按照以下步骤实现目标!
要求
要重现本教程,您需要满足以下前提条件:
注意:最新版本的 Python 无法使用 Botright。因此,您的计算机必须安装 3.10.11 或更低版本。
步骤 #1:项目设置和 Botright 安装
本节结束时,代表项目文件夹的botright_project/将包含以下内容:
botright_project/
├── scaper.py
└── venv/在哪里?
scraper.py是包含 Botright 验证码解决逻辑的 Python 文件。venv/是 Python 3.10 虚拟环境。
在 Windows 中,可以像这样创建 Python 3.10虚拟环境目录venv/:
py -3.10 -m venv venv要激活它,请运行
venvScriptsactivate在 Linux 上,执行
python3.10 -m venv venv然后,用
source venv/bin/activate在已激活的虚拟环境中,将pip升级到最新版本:
python -m pip install --upgrade pip然后,用以下命令安装 Botright:
pip install botright --use-pep517
pip install hcaptcha_challenger==="0.10.1.post2"备注
--use-pep517是强制性的,以确保所有依赖于pyproject.toml文件的遗留依赖项都能正确安装。- 自 Botright 最新版本发布以来,
hcaptcha_challenger已经发生了很大的变化。具体来说,最新版本的hcaptcha_challenger不再公开 Botright 在幕后调用的方法。因此,您必须安装特定版本才能使用该库。
太好了!您的环境已经设置好,可以使用 Botright 解决验证码问题。
步骤 #2:定义验证码解析逻辑
要使用 Botright 解决验证码问题,请在scraper.py文件中编写以下代码:
import asyncio
import botright
async def scraper():
# Start the Botright instance
botright_client = await botright.Botright(headless=True)
browser = await botright_client.new_browser()
# Create a new page instance
page = await browser.new_page()
# Open the target web page with the reCAPTCHA demo
await page.goto("https://www.google.com/recaptcha/api2/demo")
# Solve the CAPTCHA
await page.solve_recaptcha()
# Screenshot the page to capture the solved CAPTCHA
await page.screenshot(path="screenshot.png")
# Close the botright browser instance
await botright_client.close()
# Execute the scraper function
if __name__ == "_main_":
asyncio.run(scraper())上述代码
- 使用方法
new_browser(),在无头模式下启动 Botright 浏览器实例。 - 创建一个新的页面实例,并在其中打开 reCAPTCHA 演示页面。
- 使用
solve_recaptcha()方法解决验证码问题。 - 将已解决的验证码截图并关闭浏览器实例。
注意:请阅读文档中的“验证码解决 “部分,了解解决其他类型验证码所需的支持方法。
完美!您已经编写了使用 Botright 解决重新验证码的逻辑。
步骤 #3:运行代码
使用以下命令运行代码bash python scraper.py
这是在标题模式(headless=False)下运行脚本时看到的内容:
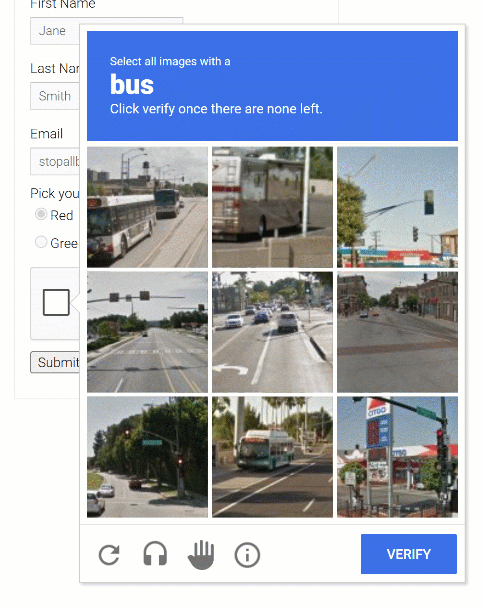
Botright 脚本生成的screenshot.png将包含以下内容
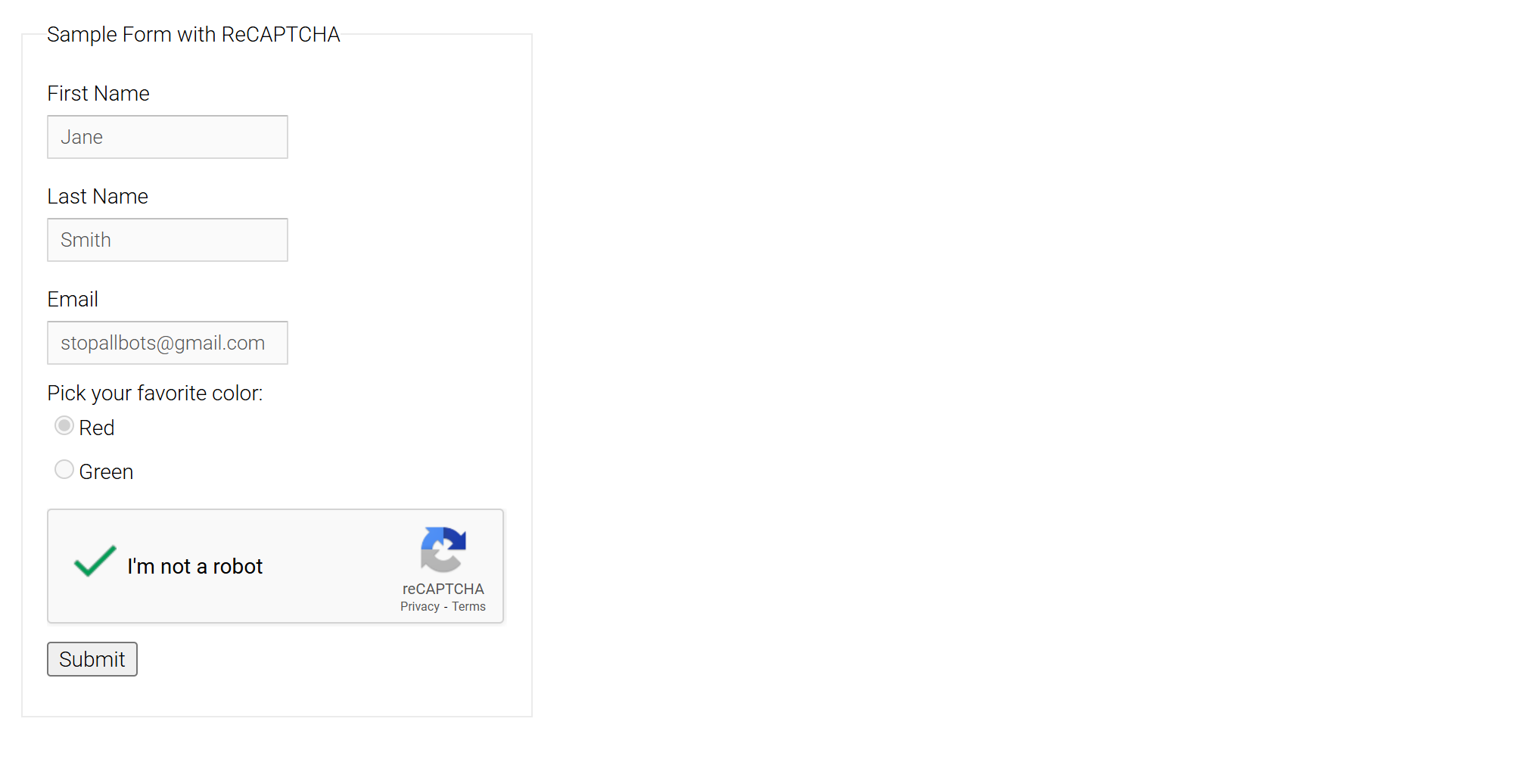
最终,脚本应能检测到所有图像并自动解决验证码问题。不过,由于不能保证 100% 的准确率,所以偶尔也会出现失败。在这种情况下,只需继续运行脚本,直到成功为止。在生产过程中,您必须执行自动重试逻辑。
正如您所看到的,Botright 将机器学习模型与自动化人工集成工具相结合,从而实现了以下功能:
- 了解验证码的含义
- 检测符合所需标准的图像
- 像人一样点击这些图片
任务完成
替代 Botright 的验证码解决方案
验证码对大多数机器人都很有效。虽然验证码会破坏普通用户的体验,但现代验证码仍然是抵御人工智能抓取程序和爬虫的主要手段之一。这就是为什么验证码越来越受欢迎的原因,因为大多数网站都希望保护自己的网页和数据不受人工智能机器人日益增长的趋势的影响。
现在,Botright 并不是唯一能够解决验证码问题的工具。如果您需要在抓取过程中绕过验证码,可以考虑使用以下替代库和方法:
- 如何使用 Puppeteer 绕过验证码
- 如何使用 Python 中的 Selenium 绕过验证码
- 如何使用 Playwright 绕过验证码
- 2026 年使用 SeleniumBase 进行网络抓取指南
- 如何使用未检测到的 ChromeDriver 进行网络抓取
- 2026 年 5 个最佳验证码代理
在网络搜索中使用 Botright 的局限性
Botright 是一款相当有效的在网络抓取中解决验证码问题的工具,但它远非完美。该库使用基于机器学习的方法,但并不总能产生一致的结果。此外,它还有些过时,而且不经常维护。
这是一个大问题,尤其是考虑到现代验证码正变得越来越复杂。因此,Botright 背后的机器学习模型需要定期更新才能跟上。
简而言之,不要指望 Botright 可以解决现代验证码问题。尤其是面对新的基于谜题的验证码(如hCaptcha 提供的验证码)时,更是如此:
正如前面的视频结果(以 3 倍速度录制)所示,Botright 的速度并不是特别快。原因在于,它需要消耗大量计算资源来分析 reCAPTCHA 呈现的每张新图片,并确定要点击的正确图片。在现实世界中,Botright 解决一个 reCAPTCHA 可能需要 15 秒。这对于大规模抓取操作来说时间太长了。
此外,Botright 还基于 Playwright,这带来了浏览器自动化工具的所有典型限制。这些限制包括无头模式下的浏览器指纹识别问题和高资源消耗。
要在基于浏览器自动化的抓取工作流程中更快、更一致地解决验证码问题,更好的选择是使用专为网络抓取优化的基于云的浏览器。该解决方案就是抓取浏览器。
Scraping Browser 是一款云搜索浏览器,提供内置的反机器人绕过功能、自动 IP 轮换、浏览器指纹保护、重试机制,当然还有验证码解决功能。
特别是,该解决方案可以处理各种验证码,包括reCAPTCHA、hCaptcha、px_captcha、SimpleCaptcha、GeeTest CAPTCHA、FunCaptcha、Cloudflare Turnstile、AWS WAF Captcha、KeyCAPTCHA 等。
结论
在本文中,您将了解到 Botright 如何利用浏览器自动化和机器学习来解决用于网络抓取的验证码问题。虽然 Botright 提供了一些灵活的反僵尸功能,但也存在性能缓慢、资源消耗大、依赖性过时和结果不一致等问题。
对于需要更快、更轻松地大规模克服验证码的企业和团队,Bright Data 提供了几种先进的产品,远远超出了 Botright 的开源方法:
- 验证码解码器:企业级解算器,支持多种验证码类型(包括 reCAPTCHA、hCaptcha、Cloudflare 等),成功率高,无需大量本地依赖。
- 搜索浏览器:基于云的浏览器,专为抓取而设计,具有自动 IP 轮换、内置反僵尸保护和无缝验证码解决功能,所有功能均在云中管理,高效可靠。
- 网络解锁器:新一代解锁引擎,专为应对最严峻的反机器人和反验证码挑战而设计,可自动为每个网站请求选择最佳方法,无需人工干预。
- 代理服务:访问全球最大的代理服务器池(住宅、数据中心和移动),绕过地理限制,提高匿名性–这对于大批量或分布式抓取项目至关重要。
- Scraper API:大规模提取结构化网络数据的工具,每个请求都包含防拦截和验证码解决方案,以及直观的管理仪表板。
有了 Bright Data,您可以对任何复杂的网站进行抓取,节省工程资源,并确保符合行业最佳实践。立即开始免费试用!



技术写作者
 3 years experience
3 years experience
Federico Trotta 是一名技术写作者、编辑和数据科学家。擅长技术内容管理、数据分析、机器学习和 Python 开发。




