

在本指南中,我们将编写一个 Scrapy Spider 并将其部署到 AWS Lambda。就代码而言,这里比较直接。但在使用像 Lambda 这样的云服务时,会涉及许多环节。我们将向你展示如何处理这些环节,以及在出现问题时如何解决。
先决条件
要完成此任务,你需要以下内容:
- 对 Python 有基本的了解:我们将使用 Python 编写代码。你可以在 这里 了解更多关于使用 Python 进行网络爬虫的内容。
- AWS(亚马逊云服务)账号:由于我们使用 AWS Lambda,所以需要一个 AWS 账号。
- 一台安装了 WSL 2 的 Linux 或 Windows 机器:Amazon 使用 Amazon Linux 来运行代码。当我们上传代码时,需要保证二进制兼容。
- 对 Scrapy 有基本的了解:这并不是硬性要求,但 对 Scrapy 爬虫有基本了解 也会有所帮助。
什么是无服务器?
无服务器架构一直被誉为计算的未来。尽管无服务器应用的每小时运行费用可能更高,但如果你还没有付费去维持一台服务器,那么使用 Lambda 就很合理。
假设你的爬虫运行一次只需1分钟,并且你每天只运行一次。使用传统服务器,你需要按月为24小时不间断的运行付费,但实际只用了30分钟。而使用像 Lambda 这样的服务,你只需要为实际使用时长付费。
优点
- 计费:只需为你实际使用的部分付费。
- 可伸缩性:Lambda 可自动扩展,无需你手动操心。
- 服务器管理:无需花费时间来管理服务器,一切都由系统自动完成。
缺点
- 延迟:如果函数空闲时间较长,再次启动时会有更高的启动延迟。
- 执行时间:Lambda 函数默认超时时间为3秒,最长可运行15分钟。传统服务器在时间限制上更灵活。
- 可移植性:除了操作系统兼容性之外,你还依赖于特定厂商。你不能简单地把 Lambda 函数复制到 Azure 或 Google Cloud 运行。
Bright Data 提供了一种没有这些限制的解决方案。让我们一起来看看。
无服务器函数:最佳替代方案
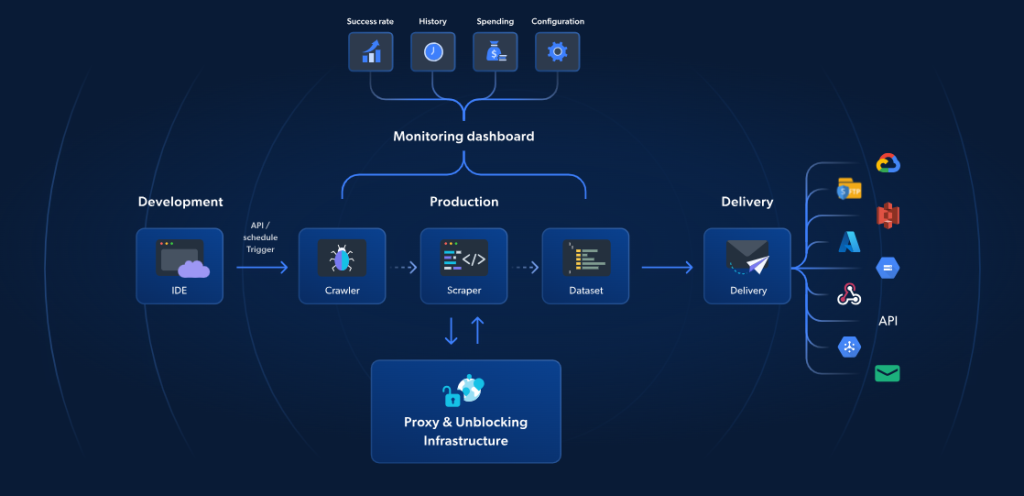
虽然使用 AWS Lambda 搭配 Scrapy 确实可以实现无服务器的网页爬取,但 Bright Data 的无服务器函数 是一款专门为更快、更可靠的爬取而构建的解决方案。它提供70多个预构建 JavaScript 模板、自带云端 IDE,以及基于 AI 的解封锁能力,可绕过验证码,实现无缝水平扩展,让你无需管理任何基础设施就能高效提取数据。
与 AWS + Scrapy 的方法不同,Bright Data 的解决方案还包括代理管理、自动扩展以及与存储平台(如 S3 或 Google Cloud)的直接集成。它的起价是每 1,000 次页面加载仅 2.7 美元。使用无服务器函数,你可以更简单、更快速、更具性价比地完成高阶的网页爬取。
现在,让我们继续本篇关于 Scrapy 与 AWS 的指南。
开始
服务配置
在你拥有了 AWS 账号之后,你需要一个 S3 存储桶(bucket)。打开 “All services” 页面并向下滚动。
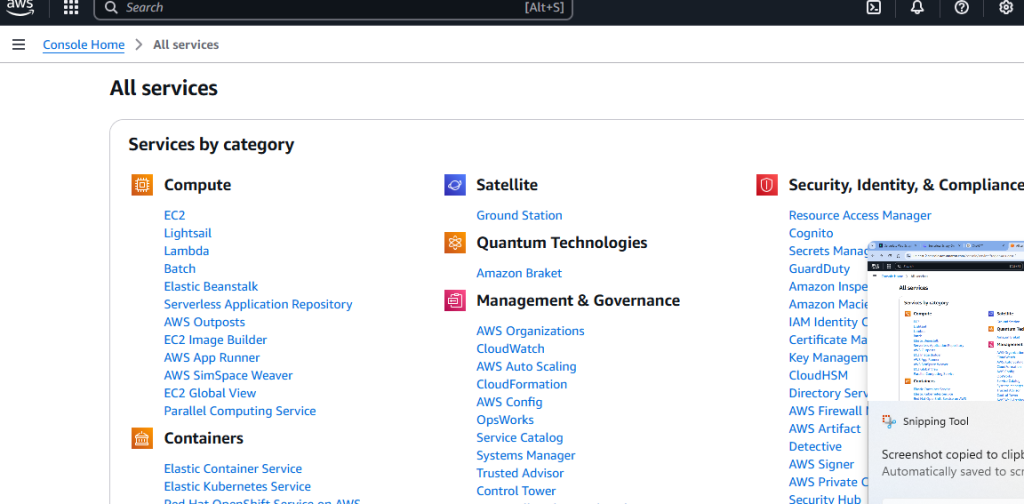
你会看到一个名为 Storage 的区域。这里的第一个选项就是 S3。点击它。
接着,点击 Create bucket 按钮。
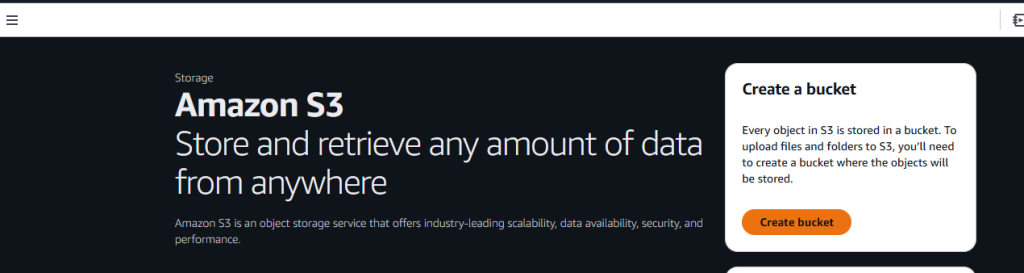
现在,你需要给这个存储桶命名并选择相应的设置。我们在这里使用默认设置。
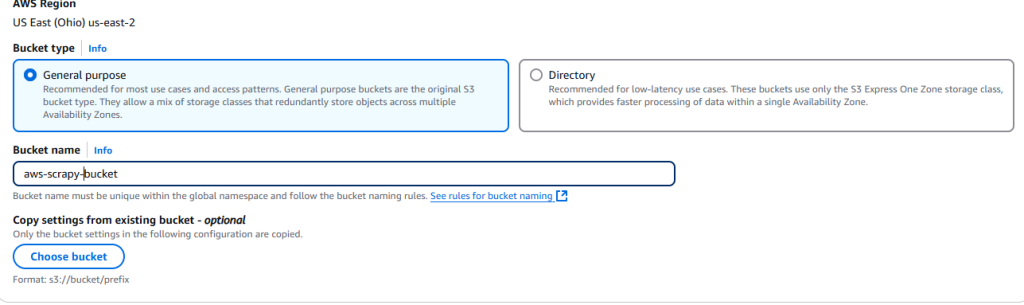
设置完成后,点击页面右下角的 Create bucket 按钮。

创建完成后,你的存储桶会显示在 Amazon S3 的 Buckets 选项卡中。

项目设置
创建一个新项目文件夹:
mkdir scrapy_aws进入该新文件夹并创建一个虚拟环境:
cd scrapy_aws
python3 -m venv venv激活虚拟环境:
source venv/bin/activate安装 Scrapy:
pip install scrapy要爬取的目标
对于 动态网站、反爬虫机制或大规模爬取,你可以使用 Bright Data 的 Scraping Browser。它能自动化任务、绕过验证码并实现弹性扩展。
我们将在这里使用专门为网络爬虫教育而设的网站 books.toscrape。如下面的截图所示,每本书都在一个名为 product_pod 的 article 标签中。我们要从该页面中提取所有这些元素。
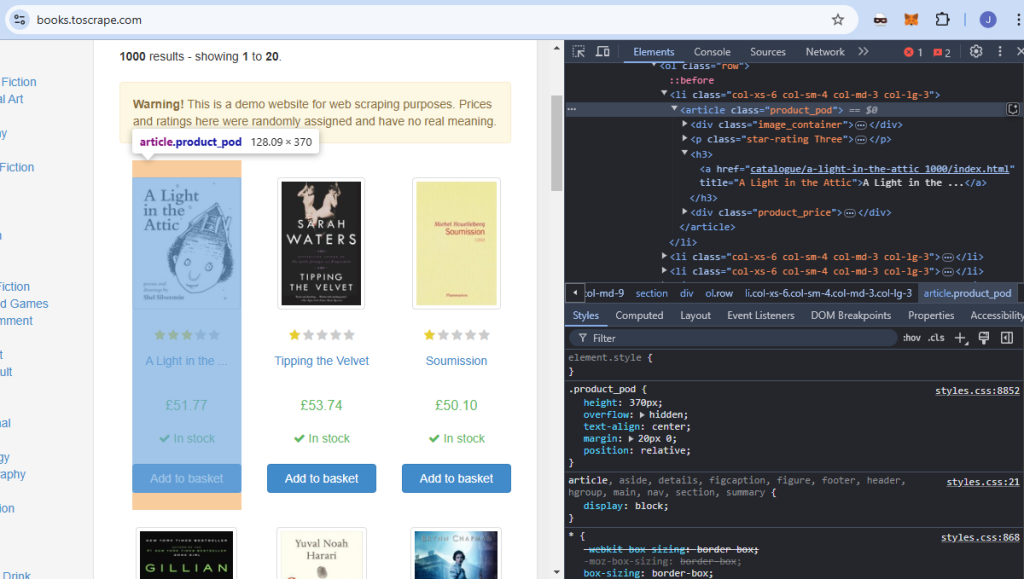
每本书的标题在 h3 元素中的 a 标签内。

每个价格都存储在一个 p 标签里,它有一个名为 price_color 的类,并且嵌套在 div 中。

编写代码
接下来,我们来编写爬虫并在本地进行测试。新建一个 Python 文件并粘贴以下代码。我们将其命名为 aws_spider.py。
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))你可以使用以下命令测试该爬虫。它应该会输出一个包含书籍和价格信息的 JSON 文件:
python -m scrapy runspider aws_spider.py -o books.json现在,我们需要一个 handler(处理器),它的职责是运行爬虫。这里我们将创建两个几乎一样的 handler:一个用于本地运行,另一个用于 Lambda。
以下是我们本地使用的 handler,命名为 lambda_function_local.py:
import subprocess
def handler(event, context):
# Output file path for local testing
output_file = "books.json"
# Run the Scrapy spider with the -o flag to save output to books.json
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# Return success message
return {
'statusCode': '200',
'body': f"Scraping completed! Output saved to {output_file}",
}
# Add this block for local testing
if __name__ == "__main__":
# Simulate an AWS Lambda invocation event and context
fake_event = {}
fake_context = {}
# Call the handler and print the result
result = handler(fake_event, fake_context)
print(result)删除 books.json。然后你可以用以下命令测试这个本地 handler。如果一切正常,将会在项目文件夹中生成一个名为 books.json 的新文件。记得将 bucket_name 改为你自己的存储桶名称。
python lambda_function_local.py下面是我们在 Lambda 上使用的 handler。它和上面的例子很相似,但做了一些小调整来将数据存储到我们的 S3 存储桶中。
import subprocess
import boto3
def handler(event, context):
# Define the local and S3 output file paths
local_output_file = "/tmp/books.json" # Must be in /tmp for Lambda
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # Path in S3 bucket
# Run the Scrapy spider and save the output locally
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# Upload the file to S3
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"Scraping completed! Output uploaded to s3://{bucket_name}/{s3_key}"
}
- 我们先将数据保存到一个临时文件:
local_output_file = "/tmp/books.json",以避免丢失。 - 使用
s3.upload_file(local_output_file, bucket_name, s3_key)将文件上传到我们的 S3 存储桶中。
部署到 AWS Lambda
现在,我们需要将代码部署到 AWS Lambda。
先创建一个 package 文件夹:
mkdir package把我们的依赖项复制到 package 文件夹中:
cp -r venv/lib/python3.*/site-packages/* package/复制代码文件。请确保复制的是用于 Lambda 的 handler,而不是本地测试的那个:
cp lambda_function.py aws_spider.py package/将 package 文件夹压缩为一个 ZIP 包:
zip -r lambda_function.zip package/当我们创建好 ZIP 文件,就可以转到 AWS Lambda 并点击 Create function。输入基本信息,比如运行环境(Python)和架构等。
记得为它添加访问 S3 存储桶的权限。
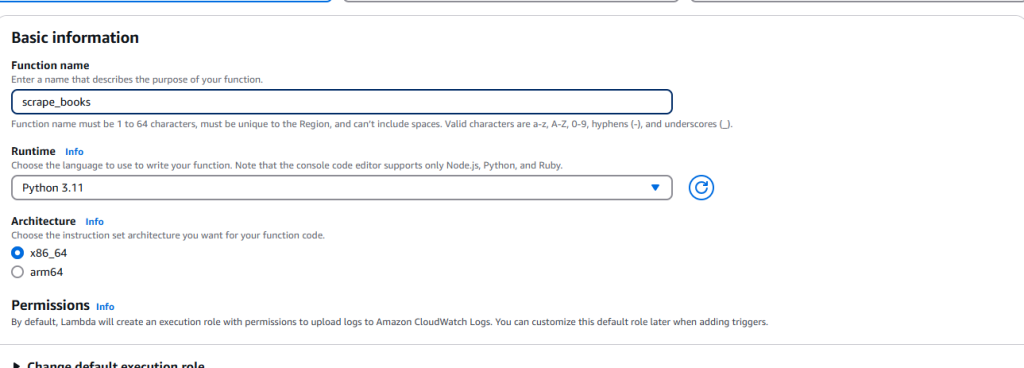
创建函数后,在源代码选项卡右上角可以找到 Upload from 下拉菜单。

选择 .zip file 并上传你创建的 ZIP 文件。
点击 test 按钮等待函数运行完成。运行完毕后,检查你的 S3 存储桶,你应该能看到一个名为 books.json 的新文件。
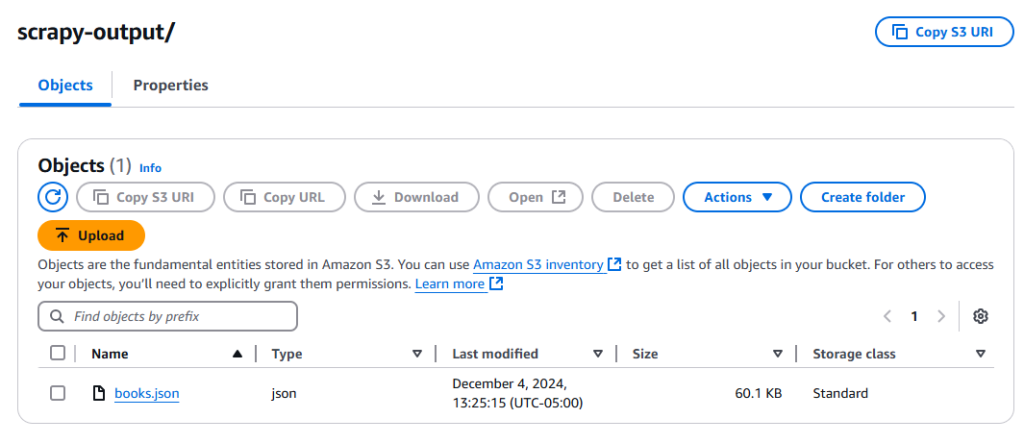
故障排查技巧
Scrapy 找不到
你可能会遇到找不到 Scrapy 的错误。这种情况下,你需要在 subprocess.run() 的命令数组中加入以下参数:

依赖问题
你需要确保本地 Python 版本和 Lambda 的 Python 版本一致。可以先检查本地的 Python 版本:
python --version如果这个命令输出的版本与 Lambda 不一致,请将 Lambda 的配置改为相同的版本。
Handler 问题

你的 handler 配置应与 lambda_function.py 中的函数一致。正如上图所示,我们用了 lambda_function.handler。其中,lambda_function 是 Python 文件名,handler 是函数名。
无法写入 S3
如果你在保存输出时遇到权限问题,则需要为你的 Lambda 实例添加权限。
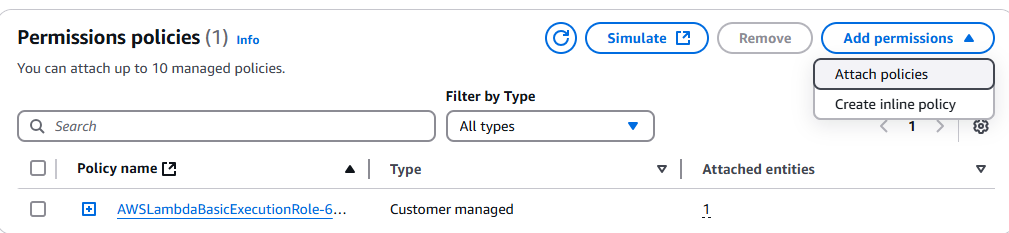
前往 IAM 控制台 并搜索你的 Lambda 函数。点击并选择 Add permissions 下拉框。
点击 Attach policies。
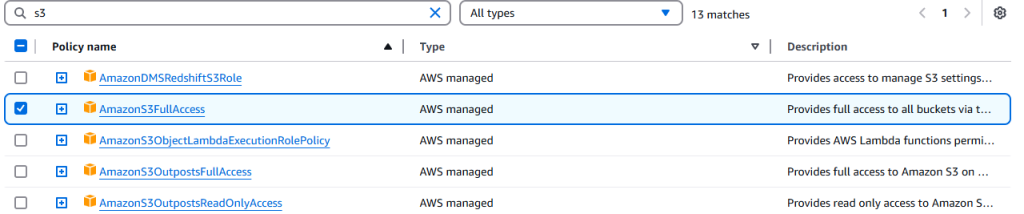
选择 AmazonS3FullAccess。
结论
恭喜你!到这里,你已经能够在 AWS 控制台的复杂界面中游刃有余,也可以使用 Scrapy 编写爬虫,并通过 Linux 或 WSL 来确保与 Amazon Linux 的二进制兼容。
如果你并不想手动编写爬虫,可以了解一下我们的 Web Scraper APIs 以及 现成数据集。立即注册,开始你的免费试用吧!



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。



