该指南包括以下内容:
使用R进行网络抓取的第一步
你需要明白我们将会在该教程中使用什么工具。
相关工具:R和 rvest
R 是一个功能丰富且易于使用的库,用于统计分析和数据可视化,为数据整理和动态类型提供了有用的工具。
rvest来自“harvest意为丰收“,是最受欢迎的提供网络抓取功能的R包之一。Vanillarvest 允许您仅从一个网页中提取数据,这
非常适合批量采集以前的初步探索。之后
你可以使用polite扩展而抓取多个页面。
设置开发环境
如果您尚未在 RStudio 中使用 R,点击
这里安装 。
完成后,打开控制台并安装 rvest:
install.packages("rvest")
作为tidyverse集合的一部分,官方建议使用集合中的其他包进一步扩展 rvest 的内置功能,利用使用代码可读性的magrittr 或用于处理 HTML 和 XML 的 xml2。您可以通过直接安装 tidyverse 来做到这一点:
install.packages("tidyverse")了解网页
网络抓取是一种自动化流程中合规地从网
站检索数据的技术。
包括以下三个重要因素需要考虑:
- 数据有不同的格式;
- 不同的网页展示信息的方式是不同的;
- 抓取数据的时候必须合法合规。
要了解如何通过URL抓取数据,首先需要了解网页内容是如何通过 HTML 标记语言和及CSS 表单样式语言显示的。
HTML 提供网页的内容和结构——加载到 Web 浏览器以创建树状文档对象模型 (DOM)——通过使用“标签”组织内容。 标签具有层次结构,每个标签都具有应用于其开始 () 和结束 () 语句,并对应其中包含的所有内容的特定功能:
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html><html> 标签是网页的最小组件,其中嵌套了 <head>, 和 <body> 标签。 <head> 和 <body> 本身是其中其他标签的“父代parents”, <div>(用于文档部分)和 <p>(用于段落)是它们最常见的“子代children”。
在上面的代码片段中,您可以看到与每个 HTML“元素”关联的“属性”:lang, class和 style 是预先构建的; 以 data- 开头的属性是亚马逊自定义的。
class 和id 属性对于网络抓取特别有用,因为它们允许我们分别定位一组元素和一个特定元素。 这最初是为了在 CSS 中设置样式。
CSS 提供网页的样式:从着色到定位到大小,您可以选择任何 HTML 元素,并为其样式属性分配新值。 您还可以使用 style 属性在 HTML 元素中内联应用 CSS 样式,参见上面的代码片段:
<body .. style="padding-bottom: 0px;">在纯 CSS 中,这将被写为:
body {padding-bottom: 0px;}
在这里,body 是“selector选择器”, padding-bottom 是“property属性”, 0px 是“value值”。
任何tag、class或 id 都可以用作 CSS 选择器。
用户可以使用 script 标签通过JavaScript 编程语言提供的功能与网页上显示的内容进行动态交互。 用户交互后,显示的内容有可能会发生变化,出现新的内容; 高级网络抓取工具可以模仿用户交互,这一点,我们稍后会讨论。
了解开发工具
主流的浏览器提供内置的开发人员工具,允许收集和实时更新网页上的技术信息,用于日志记录、调试、测试和性能分析。 在本教程中,我们将使用Chrome’s DevTools.
你可以点击浏览器右上角的“更多工具/More Tools”选项,找到开发人员工具:
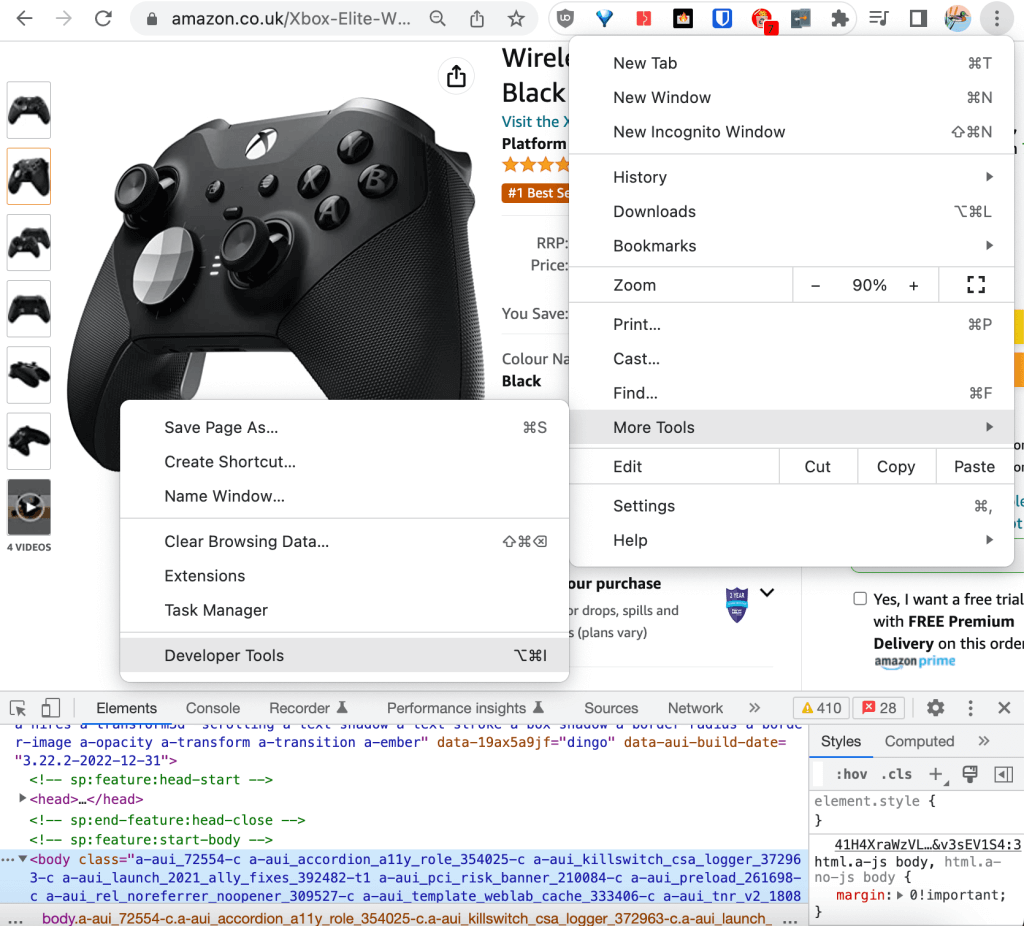
在 “DevTools/开发者工具” 中,您可以在“Elements 元素”选项中滚动浏览原始 HTML,滚动时,您会看到在网页中呈现的相应元素以蓝色突出显示:
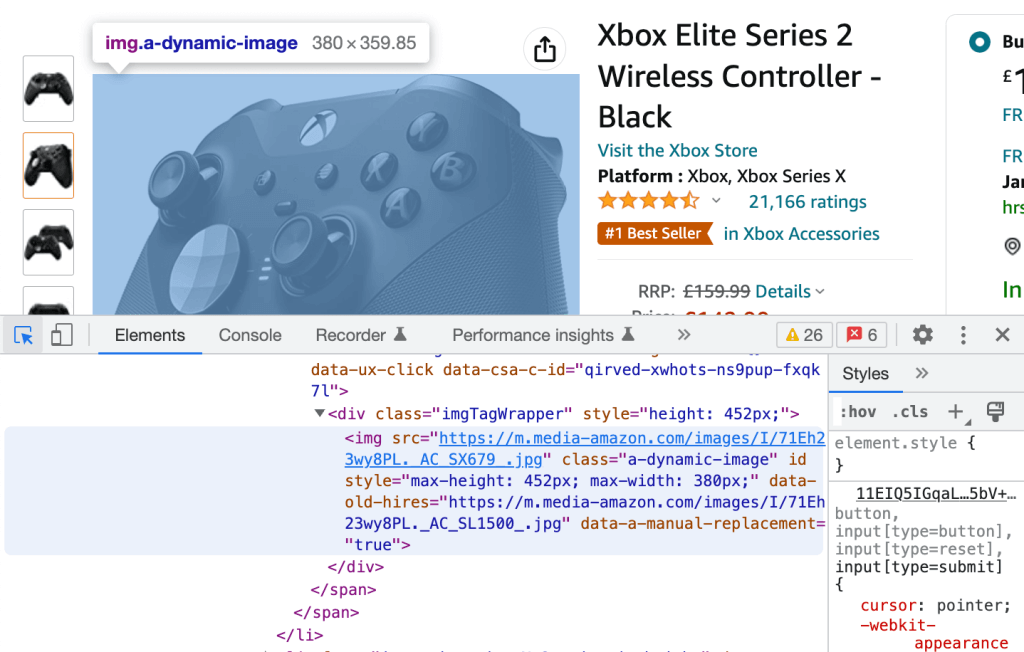
相反,您可以单击左上角的图标,并从网页中选择任何元素,以重定向到其原始 HTML 副本,再次以蓝色突出显示。
这两个过程是教程提取 “CSS Descriptors/CSS描述符”所需的全部过程。
教程:深入研究R中的网络数据抓取
在这一部分,我们将会探讨如何通过抓取 Amazon URL 的数据并 提取产品品论。
请求
开始前确保你在Rstudio环境中安装了以下内容:
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
交互式浏览网页
使用 Chrome 的 DevTools 浏览您的 URL 的 HTML,并创建包含我们目标信息的 HTML 元素的所有类和 ID 的列表,即产品评论:

每个客户评论都属于一个 div,其 id 格式如下:
customer_review_$INTERNAL_ID.
上面截图中客户评论对应div的HTML内容如下:
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
您感兴趣的每条客户评论内容都有其独特的类别:标题为 review-title-content,正文为 review-text-content,评级为 review-rating。
您可以检查该类在文档中是否是唯一的,并直接使用“simple selector简单选择器”。 一种更简单的方法是改用“CSS Descriptor/ CSS 描述符”,即使将来该类被分配给新元素,它也将保持唯一性。
只需右键单击“DevTools”里的“ element 元素”并选择“复制选择器Copy Selector”,就可简单地检索 “CSS Descriptor/ CSS 描述符”:
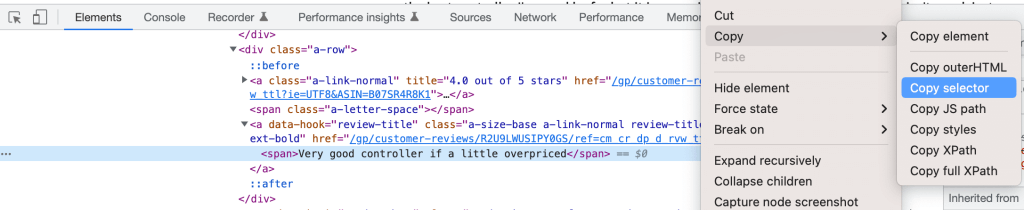
您可以将三个选择器定义为:
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > span标题customer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > span主体customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > span评级*
.review-rating被手动添加,以保证更好的一致性。
网页数据抓取中的CSS Selector vs. XPath
该部分,我们使用 “CSS 选择器/CSS selector ”来识别用于网络抓取的“元素/elements”。 另一种常见的方法是使用 XPath,即XML Path/ XML 路径,它通过在 DOM 中的完整路径来标识 element /元素
您可以按照与“CSS selector/CSS 选择器”相同的过程提取完整的 XPath。 例如,评论标题是:
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
“CSS selector/CSS 选择器”稍微快一些,而 XPath 具有更好的向后兼容性。 除了这些细小的差异之外,选择用哪个更多地取决于个人喜好而不是因为技术差别。
以编程方式从网页中提取信息
虽然我们可以直接使用“Console/控制台”开始探索如何通过网络抓取 URL,但我们将创建一个脚本以便追溯和再现,并使用 source() 命令通过“Console/控制台”运行它。
创建脚本后,第一步是加载已安装的库:
library(”rvest”)
library(”tidyverse”)然后,您可以如编程方式提取您感兴趣的内容。 首先,创建一个变量,您将在其中存储要搜索的 URL:
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
接下来,从 URL 中提取亚马逊标准标识号 (ASIN),将其作为唯一的产品 ID:
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
使用 RegEx 来清理通过网络抓取提取的文本很受欢迎,推荐使用它。
现在,下载网页的 HTML 内容:
HTMLContent <- read_html(HtmlLink)
read_html() 函数是 xml2 包的一部分。
如果你 print() 内容,我们会看到它与之前分析的原始 HTML 结构相匹配:
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
您现在可以为页面上的所有产品评论提取三个感兴趣的节点。 使用 Chrome 的 DevTools 提供的 CSS Descriptors,修改为从字符串中删除特定客户评论标识符 #customer_review-R2U9LWUSIPY0GS 和“>”连接符; 您还可以利用 rvest 的 html_nodes() 和 html_text() 功能将 HTML 内容保存在单独的对象中。
以下命令用语提取评论标题:
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
评论标题例子: review_title 是”Very good controller if a little overpriced.”.
下面的代码将提取评论正文:
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
评论征文例子: review_body写到”In all honesty, I’m not sure why the price…”.
您可以使用以下命令提取评论评分:
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
一个条目的例子:review_rating 是 “4.0 out of 5 stars”.
为了提高这个变量的质量,只提取评级“4.0”并将其转换为 int:
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
管道功能 %>% 由 magrittr 工具包提供。
现在你可以将抓取的内容导出到tibble 中进行数据分析了,tibble是一个 R 包,属于 tidyverse 集合,用于操作和打印数据框。
df <- tibble(review_title, review_body, review_rating)
输出数据帧如下:

最后,最好将代码重构到函数 scrape_amazon <- function(HtmlLink) 中,这样实际操作中就可以用代码扩展到多个 URL了。
扩大到多个URL
创建网络抓取模板后,您可以通过网络爬取和抓取为亚马逊上所有重要竞争对手的产品创建一个 URL 列表。
当扩充到多个 URL 批量解决方案时,您需要概述应用程序的技术要求。
拥有定义明确的技术需求,能确保有效的支持业务需求以及与现有系统的无缝集成。
根据具体的技术要求,需要更新抓取功能以支持以下组合:
- 实时或批量抓取
- 输出格式:JSON、NDJSON、CSV 或 XLSX
- 输出目的地:email, API, webhook, 或云储存
早前提到,您可以使用 polite 扩展 rvest 来抓取多个网页的数据。 polite 通过使用三个主要功能来创建和管理网络收集会话,完全符合网络主机的 robots.txt 文件以及内置速率限制和响应缓存:
- bow()为特定 URL 创建抓取会话,即它将您介绍给网络主机并请求抓取权限。
- scrape()访问 URL 的 HTML; 您可以将函数通过管道传递给 rvest 中的 html_nodes() 和 html_text() 以检索特定内容。
- nod()将会话的 URL 更新到下一页,而无需重新创建会话。
引用polite网站上的原话:“ 每个polite 会话都有三大支柱:寻求许可,慢慢来,不发送两次。
下一步:预建还是自建?
为了开发可以为企业提取优质数据的先进网络抓取工具,需要具备一些功能:
- 具有专业的网络数据提取知识的专家团队
- 一个 DevOps 工程师团队,在代理管理和反机器人规避方面具有专业知识,可以通过验证码并解锁防范严密的网站;
- 一个数据工程师团队,在创建用于实时和批量数据提取的基础设施方面具有专业知识;
- 了解隐私数据保护法律要求(如 GDPR 和 CCPA)的法律专家团队。
网络内容格式很多,找到结构完全相同的两个网站几乎不可能的。 网站越复杂,要抓取的功能和数据越多,所需的编程知识就越高级,更不用说解决方案所需的额外时间和资源了。
通常情况下,您至少希望实现以下高级功能:
- 最大限度地减少验证码和机器人检测的机会:一种简单方法是添加随机 sleep() 以避免网络服务器和常规请求模式过载。 还有一种更有效的方法是使用 user_agent 或代理服务器在不断轮换IP发送请求。
- 抓取 Javascript 支持的网站:在我们举的的亚马逊例子中,选择特定产品变体时 URL 不会更改。 这对于抓取评论是可以接受的,因为它们是共享的,但对于抓取产品规格而言就不行。 要模拟动态网页中的用户交互,您可以使用RSelenium 等工具来自动化网页浏览器的导航。
当想要访问资源有限的网络数据、确保数据质量或解锁更高级的用例时,预构建网络抓取工具可能是正确的选择。
亮数据Bright Data的网页爬虫 提供许多技术领先的网站的数据抓取模板,包括前文演示的Amazon爬虫!







