

Bright Data 是市场上最完整的网页抓取平台。它将最大的商业代理网络与结构化的爬虫 API 和现成的数据集相结合。它还增加了抓取浏览器、搜索引擎 API,以及 AI 代理集成。Zyte 是更早的、Scrapy 原生的替代方案,围绕单一的托管抓取 API 构建。
Zyte(前身为 Scrapinghub)创建了 Scrapy,这个开源的 Python 框架。它现在销售三款产品:Zyte API、Zyte Data 和 Scrapy Cloud。我们测试了两个平台并审查了独立的基准数据。我们从成功率、定价、产品深度和真实世界可用性方面进行了比较。Bright Data 在除一个狭窄的定价案例之外的每个维度都胜出。
TL;DR: Bright Data vs. Zyte
结论: Bright Data 对大多数团队来说是更好的选择。它在受保护站点上的得分更高,提供的产品多得多,并且定价可预测。Zyte 适合使用 Scrapy 原生的团队抓取简单、未受保护的站点。下面的基准数据来自 Scrape.do 的独立 2026 年测试。
| 功能 | Bright Data | Zyte |
|---|---|---|
| 成功率 | 98.87% | 91.43% |
| 产品范围 | 网页爬虫工具 API、网络解锁器、抓取浏览器、搜索引擎 API、代理、数据集、MCP | Zyte API、Zyte Data、Scrapy Cloud |
| 代理访问 | 直接:住宅代理、数据中心代理、ISP 代理,覆盖 195 个国家 | 无:由 Zyte API 在内部托管 |
| 预构建数据集 | 是,100+ 域名 | 否 |
| AI 代理集成 | MCP 服务器 | 无 |
| 定价模型 | 固定:$1.5/1K 记录 | 按站点难度分层:$0.06 到 $16.08/1K |
| 免费层 | 5,000 记录/月,无需绑卡 | $5 额度,需要绑卡 |
| 最适合 | 大规模可靠性、数据集、代理控制、AI 代理 | Scrapy 原生团队在简单站点上 |
成功率:基准数据
可靠性是抓取中最重要的第一件事。Scrape.do 的 2026 年基准测试 针对七个高难目标对两者进行了测试。这些包括 Amazon、Indeed、Zillow、Google 和 X。Bright Data 得分 98.87%,是所有被测试提供商中最高的。Zyte 得分 91.43%。
这 7 个百分点的差距在规模化时会叠加。在 100,000 次请求中,这相当于 1,130 次失败与 8,570 次失败之间的差别。每一次失败都意味着浪费计算资源并需要重新爬取。在受保护站点上,Bright Data פשוט 更可靠。
测试中的响应时间很接近,每次大约 10 到 11 秒。速度不是这里的区分因素。在高难目标上的可靠性才是。
定价:固定费率 vs. 难度分层
这是两个平台在理念上差异最大的地方。Bright Data 收取一个固定费率。Zyte 按目标站点的难度收费。
Bright Data:固定费率定价
Bright Data 的 网页抓取 API 按量付费为每 1,000 条记录 $1.5。你只为成功结果付费。免费层包含每月 5,000 条记录且无需信用卡。Scale 计划为每月 $499,包含 384,000 条记录。
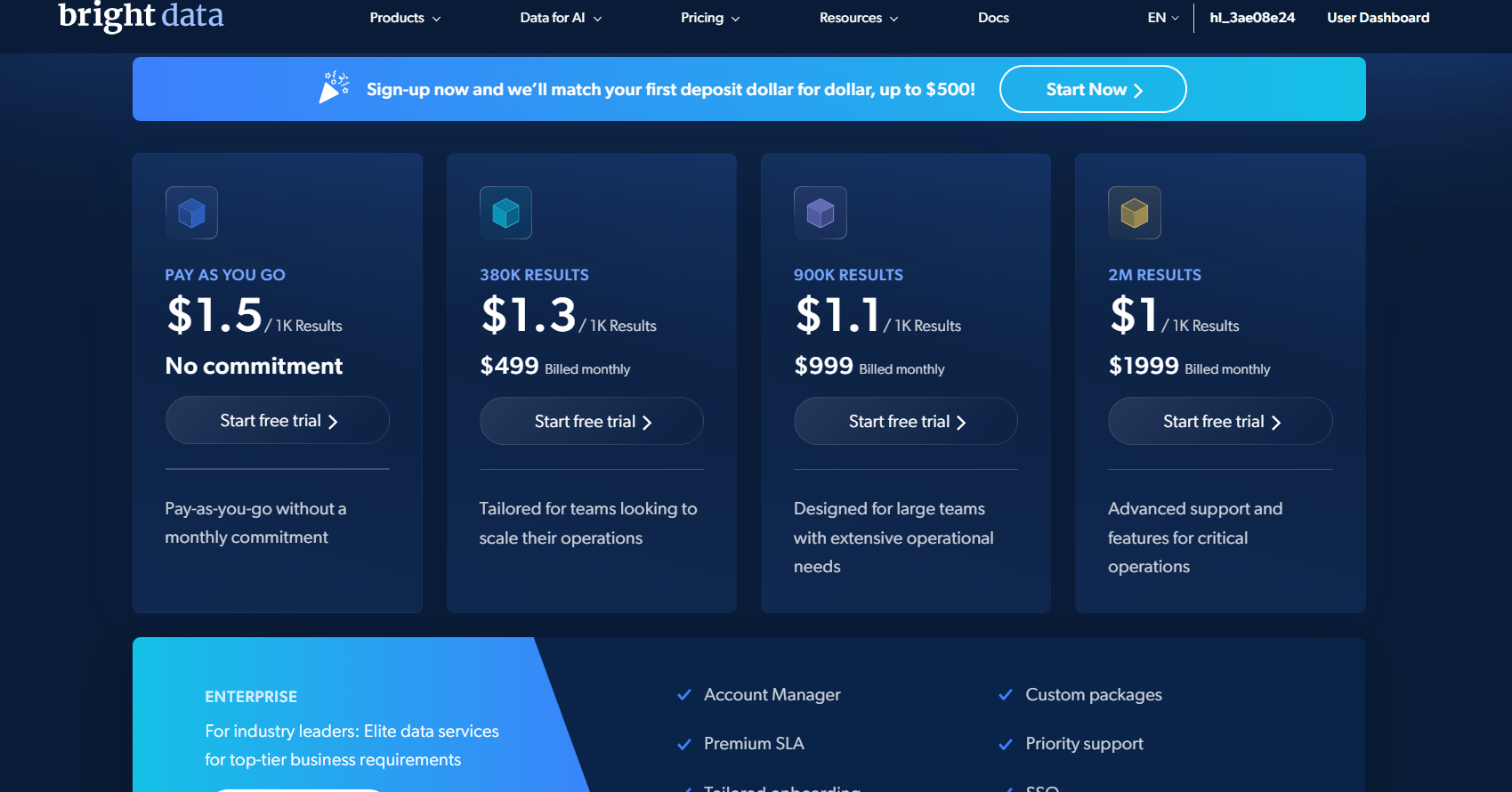
Zyte:五个难度层级
Zyte 将每个站点分为五个难度层级。HTTP 请求每 1,000 次从 $0.06 到 $1.27。浏览器渲染请求每 1,000 次从 $0.48 到 $16.08。确切费率取决于层级和你的月度承诺。
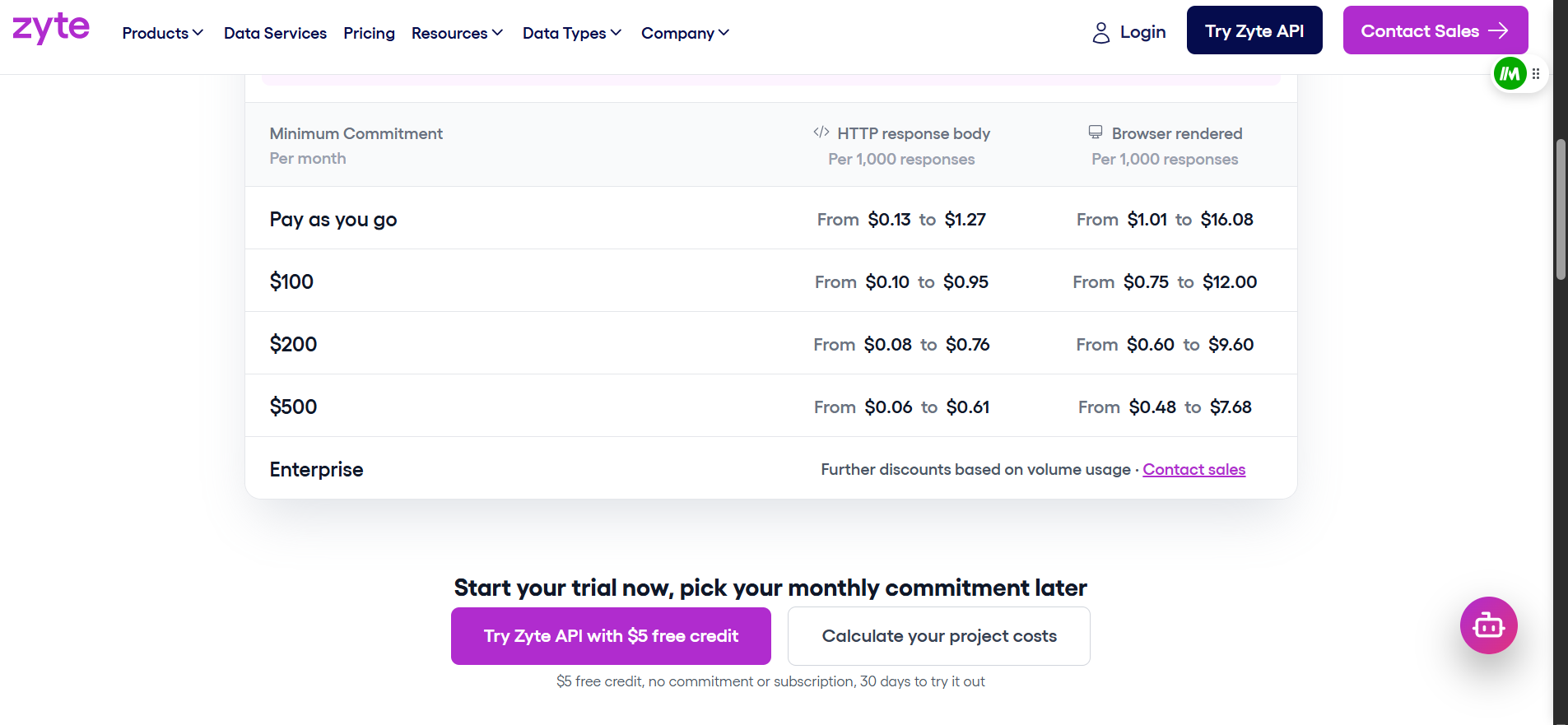
实际中的定价计算
以对一个高难站点进行带浏览器渲染的 100,000 次请求为例。Bright Data 按量付费成本为 $150。Zyte 在中等层级成本为 $402,在最高难度层级最高可达 $1,608。
再看对一个简单的仅 HTTP 站点进行 100,000 次请求。Zyte 成本低至 $13。Bright Data 仍为 $150。Zyte 在琐碎站点上胜出,但这些站点很少需要付费的爬虫 API。
更深层的问题是可预测性。你往往在抓取之前并不知道一个站点的层级。当目标跨越多个层级时,预算制定会变得困难。Bright Data 的固定费率完全消除了这个变量。
产品深度:全栈 vs. 单一 API
这是 Bright Data 最大的结构性优势。Zyte 提供三款产品。Bright Data 提供完整的数据基础设施栈。其网络覆盖 4 亿+ 住宅 IP、1,300,000+ 数据中心 IP,以及 195 个国家的 1,300,000+ ISP IP。
Bright Data 有而 Zyte 没有的
1. 预构建数据集。 Bright Data 为 100+ 域名维护可直接使用的 数据集。这些包括 LinkedIn、Amazon、Zillow 和 Google Maps。你用筛选条件查询一个数据集并获得结构化记录返回。无需爬虫工具、无需爬取、无需解析。
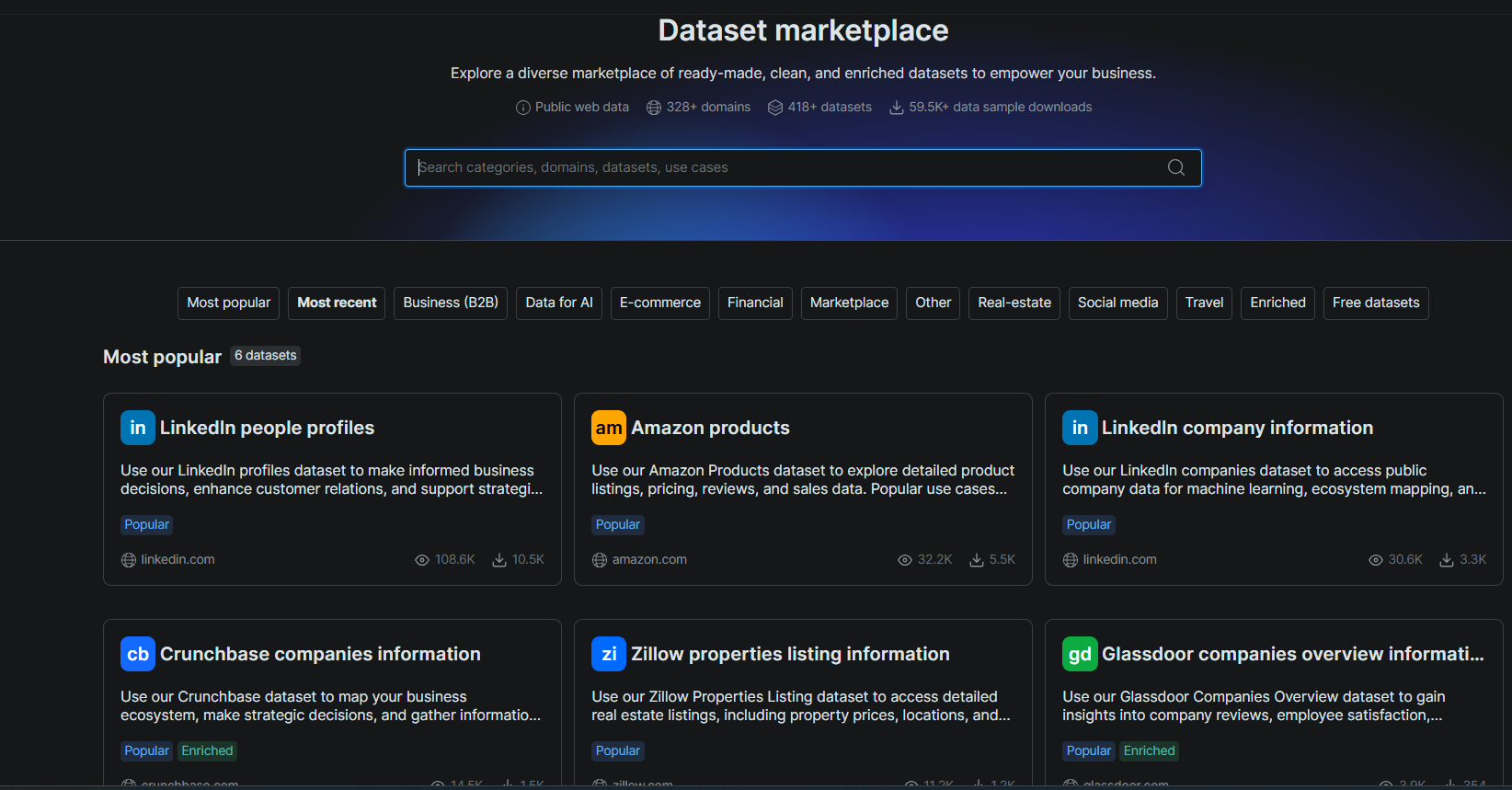
在我们的测试中,数据集 Filter API 在 46.5 秒内返回了 100 家 LinkedIn 公司。每条记录包含企业画像、融资历史以及 Crunchbase URL。Zyte 没有等价产品。在 Zyte 上完成同样任务意味着构建并维护一个自定义抓取工具。
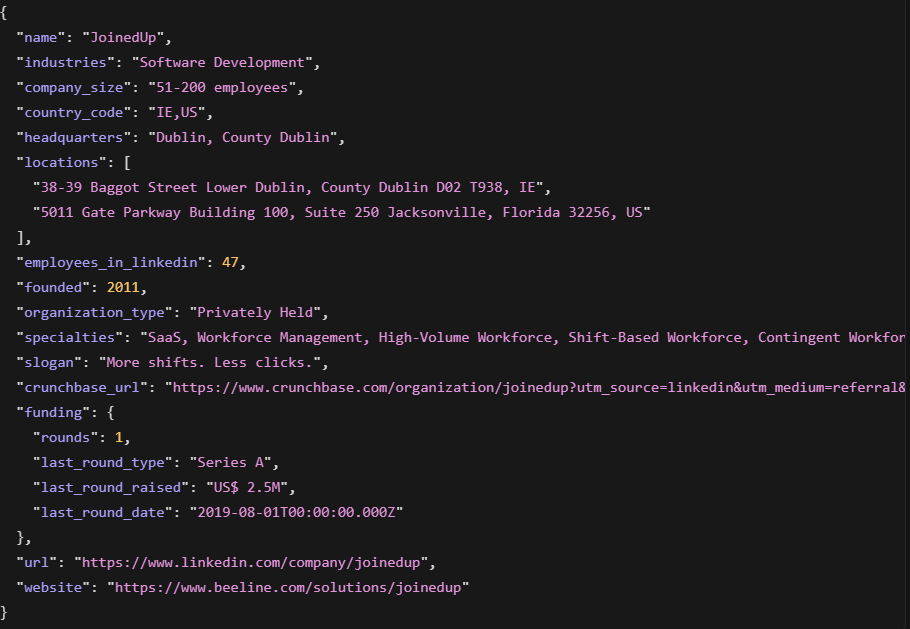
2. 直接代理访问。 Bright Data 允许你直接使用其 代理网络。你可以控制国家、城市和 ASN 定向。Zyte 在内部管理代理,因此你无法控制类型、位置或轮换。
3. 抓取浏览器。 抓取浏览器 将你现有的 Playwright、Puppeteer 或 Selenium 脚本连接到托管基础设施。它处理代理轮换、验证码破解和指纹。Zyte 需要你将该逻辑重写为 API 请求。
4. 搜索引擎 API。 搜索引擎 API 返回来自 Google、Bing 等的结构化搜索结果。Zyte 没有专门的搜索产品。
5. MCP 集成。 MCP 服务器 为 AI 代理提供原生的网页数据工具。用 LangChain、CrewAI 或 LlamaIndex 构建的代理可以直接调用它。Zyte 没有 MCP 集成。
Zyte 有而 Bright Data 没有的
1. Scrapy Cloud。 Zyte 创建了 Scrapy,并运行最好的 Scrapy 蜘蛛托管服务。它从每月每单位 $9 起处理部署、调度和监控。重度使用 Scrapy 的团队在这里有一个天然的归宿。
2. AI 无代码提取。 Zyte 的 AI 可在无需选择器的情况下为支持的页面类型返回结构化数据。它对商品、文章和职位页面效果很好。Bright Data 的 爬虫工具 Studio 覆盖无代码构建,但 Zyte 的零配置方式对这些 schema 更顺滑。
3. Zyte Data。 Zyte Data 是一项完全托管的提取服务,起价每月 $500。他们的团队为你构建并维护管道。Bright Data 的数据集是自助式而非完全托管。
实操:Bright Data Web 爬虫工具 API
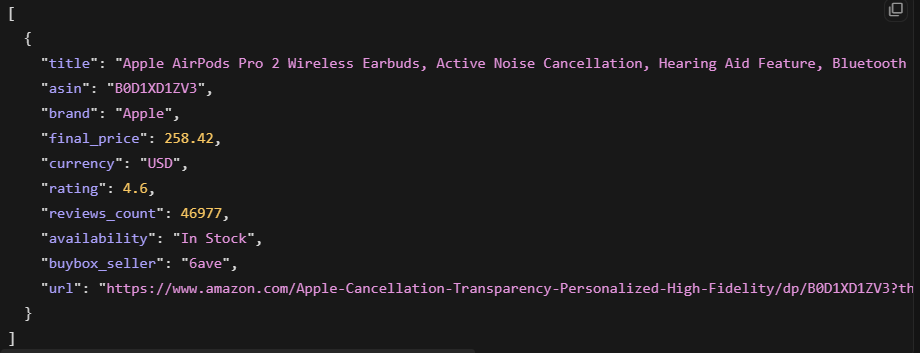
Bright Data 直接返回结构化 JSON。你发送一个 URL 并获得解析后的字段返回,无需处理 HTML:
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()这返回了商品标题、价格、评分、评论数和库存情况。输出是干净的结构化 JSON,可直接使用。
对于没有预构建抓取工具的站点,网络解锁器 会返回已解锁的 HTML,供你自行解析:
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")网络解锁器处理代理选择、CAPTCHA 破解和重试。你仍然可以控制代理类型和地理定向。
实操:Zyte API 如何工作
Zyte API 返回原始或浏览器渲染的 HTML,而你负责解析:
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")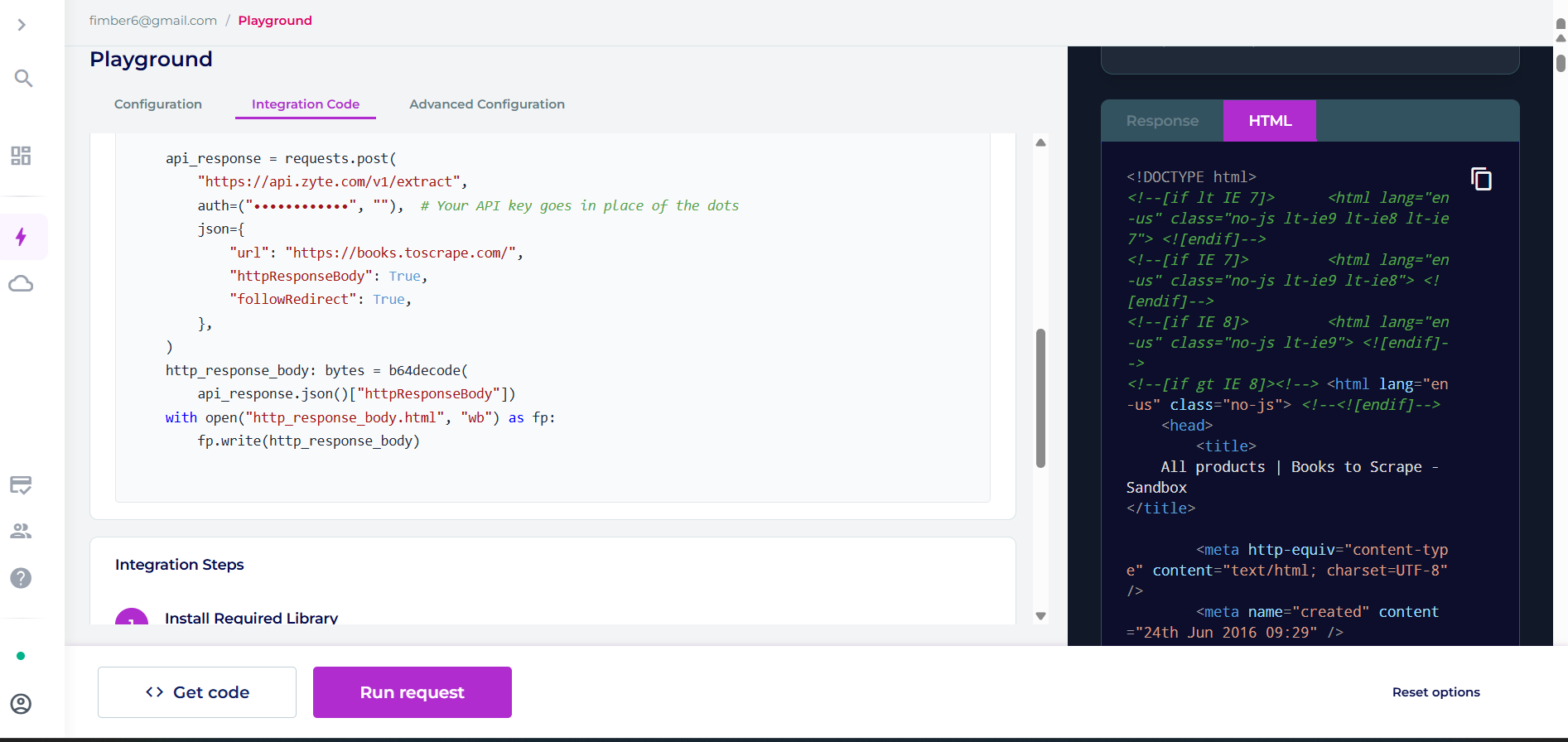
Zyte 的 AI 提取为支持的 schema 增加结构化输出。你设置一个标志并跳过选择器:
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")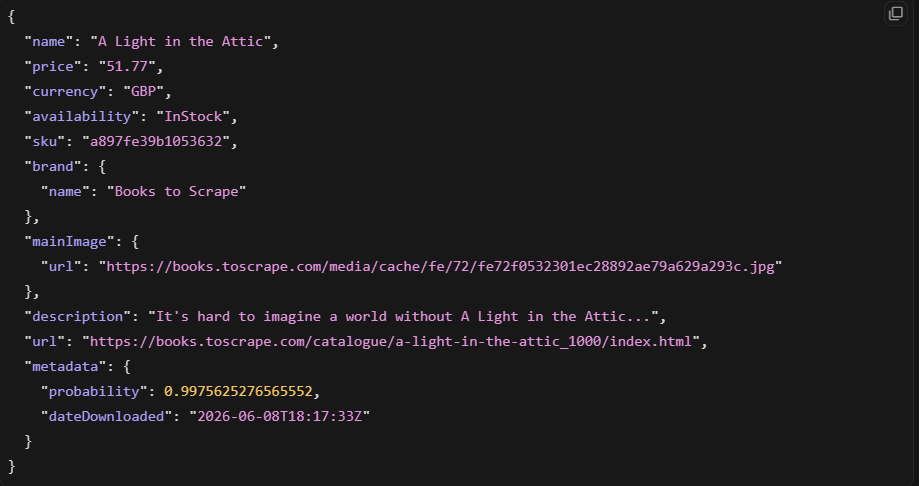
在我们的测试中,这返回了一个干净的商品对象。AI 提取对支持的页面类型确实有用。问题在于它只在 Zyte 已训练模型的地方有效。
何时选择哪个
- 选择 Bright Data:用于高成功率、预构建数据集、代理控制、AI 代理和可预测定价
- 选择 Zyte:如果你的团队基于 Scrapy 构建,并且主要抓取简单、未受保护的站点
- 两者都用:如果你在 Scrapy Cloud 上运行 Scrapy 蜘蛛,但在高难目标上需要 Bright Data
结论
Zyte 是一个适用于 Scrapy 原生团队在简单站点上的有能力的平台。当工作变得更难时差距就出现了。Bright Data 在受保护站点上得分更高,提供的产品多得多,并且定价无需猜测。
对于大规模的可靠数据,Bright Data 是更强、更广的基础。它通过了 ISO 27001 认证,并符合 GDPR 和 CCPA。详情请参阅 信任中心。你也可以阅读我们的 Bright Data vs. Apollo 对比。
今天开始免费试用并在你最难的目标上测试 Bright Data。
常见问题
Bright Data 或 Zyte 哪个更适合网页抓取?
Bright Data 对大多数团队更好。在 Scrape.do 的 2026 年基准测试中,它得分 98.87%,而 Zyte 为 91.43%。它还提供多得多的产品。Zyte 适合使用 Scrapy 原生的团队抓取简单站点。
Bright Data 和 Zyte 的定价如何对比?
Bright Data 对每 1,000 条记录收取固定 $1.5,并且每月有 5,000 条免费。Zyte 按站点难度收费,每 1,000 次请求从 $0.06 到 $16.08。Bright Data 的定价更可预测。
Zyte 是否像 Bright Data 一样有预构建数据集?
没有。Bright Data 为 100+ 域名提供现成数据集,包括 LinkedIn 和 Amazon。Zyte 没有等价产品。你需要自己构建并维护这些爬虫工具。
我可以使用现有的 Scrapy 或 Playwright 代码吗?
Zyte 运行 Scrapy Cloud,这是 Scrapy 蜘蛛的最佳托管服务。Bright Data 的抓取浏览器将现有的 Playwright、Puppeteer 和 Selenium 脚本连接到其基础设施。
我应该选择 Bright Data 还是 Zyte?
选择 Bright Data 以获得大规模可靠性、数据集、代理控制和 AI 代理。如果你的团队是 Scrapy 原生并且主要抓取简单、未受保护的站点,则选择 Zyte。



技术写作者
Amitesh Anand 是一位开发者倡导者和技术写作者,分享有关 AI、软件和开发工具的内容,拥有 1 万粉丝和超过 40 万次观看。





