

在本指南中,您将了解到
- Agno 是什么,为什么它是构建代理工作流程的绝佳选择?
- 为什么网络搜索能在人工智能代理中发挥如此重要的作用?
- 如何将 Agno 与其内置的 “亮数据 “工具集成,以创建网络搜索代理。
让我们深入了解一下!
什么是 Agno?
Agno是一个全栈 Python 框架,用于构建利用记忆、知识和高级推理的多代理系统。它能为各种用例创建复杂的人工智能代理。这些情况包括从使用简单工具的代理到具有状态和确定性的协作代理团队。
Agno 与模型无关,性能卓越,并将推理作为其设计的核心。它支持多模式输入和输出、复杂的多代理协调、带向量数据库的内置代理搜索以及完整的内存/会话处理。
截至本文撰写时,Agno 是最受欢迎的开源AI 智能体构建库之一,在 GitHub 上已收获超过 29,000 个 star:
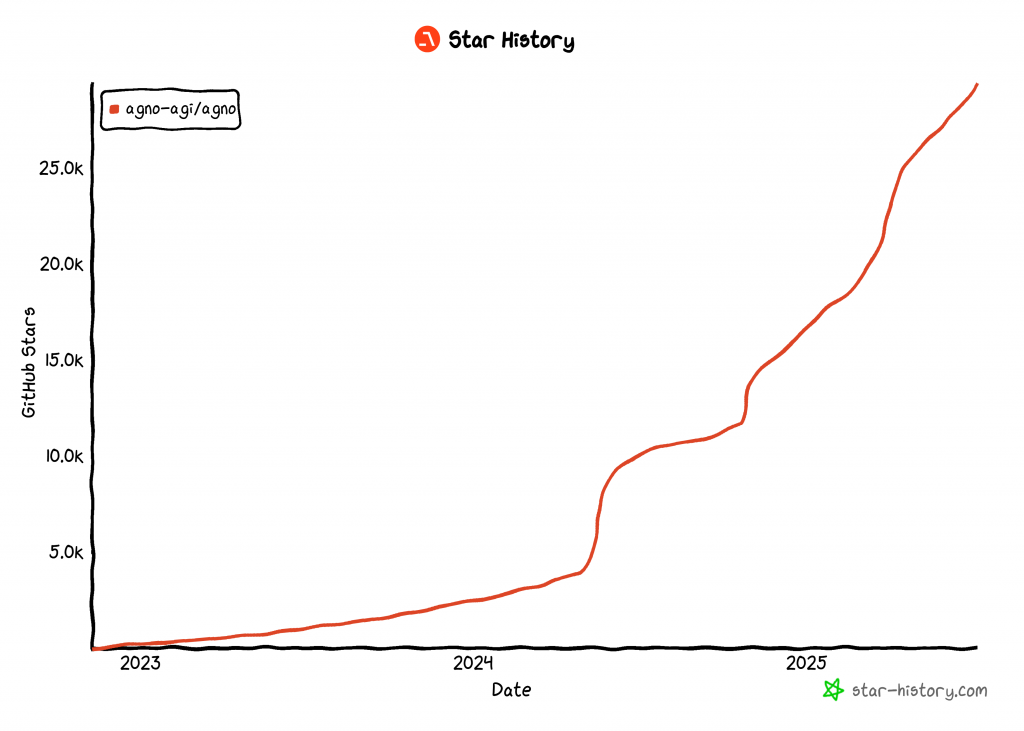
它的迅速崛起凸显了 Agno 在开发者和人工智能社区中获得关注的速度有多快。
为什么代理网络抓取如此有用?
传统的网络抓取依赖于编写死板的数据解析规则,从特定网页中提取数据。问题出在哪里?网站结构经常变化,这意味着你必须不断更新你的搜索逻辑。这将导致高昂的维护成本和脆弱的管道。
这就是为什么人工智能网页抓取技术越来越受到支持的原因。您可以使用人工智能模型,只需一个简单的提示,就能直接从网页的 HTML 中提取数据,而无需制作自定义解析脚本。这种方法非常流行,以至于最近出现了许多人工智能网页抓取工具。
不过,如果将人工智能网络抓取嵌入到人工智能代理架构中,它就会变得更加强大。特别是,你可以建立一个专门的网络抓取代理,让其他人工智能代理可以与之连接。这可以在多代理工作流中实现,也可以通过人工智能协议(如谷歌的 A2A)实现。
Agno 使上述一切成为可能。它可以让你构建独立的人工智能搜索代理或复杂的多代理生态系统。然而,普通的 LLM 并不是为熟练的网络抓取而设计的。它们经常无法连接到具有强大僵尸防御功能的网站,或者更糟糕的是,它们可能会产生 “幻觉”,返回虚假数据。
为了解决这些局限性,Agno 通过专用抓取工具与 Bright Data 进行了本机集成。利用这些工具,您的人工智能代理可以从任何网站上抓取新鲜的结构化数据。
为避免阻塞和中断,Bright Data 克服了 TLS 指纹、浏览器和设备指纹、验证码、Cloudflare 保护等挑战。数据检索完成后,将按照您最初的任务指示输入 LLM 进行解释和分析。
探索如何将 Bright Data 工具集成到 Agno 代理中,以实现更高级别的网络搜索!
如何在 Agno 中集成用于网络抓取的亮数据工具
在本节中,您将逐步了解如何使用 Agno 构建一个网页抓取人工智能代理。通过集成 Bright Data 工具,您的 Agno 代理将具备从任何网页中抓取数据的能力。
请按照以下说明在 Agno 中创建由 Bright Data 驱动的抓取代理!
先决条件
要学习本教程,请确保您具备以下条件:
- 本地已安装 Python 3.7 或更高版本(建议使用最新版本)。
- 一个 Bright Data API 密钥。
- 受支持的 LLM 提供商的 API 密钥(在此,我们将使用 Gemini,因为它可以通过 API 免费使用,但任何受支持的 LLM 提供商都可以)。
如果您还没有 Bright Data API 密钥或 Gemini API 密钥,请不要担心。我们将在接下来的步骤中指导您如何创建。
步骤 #1:项目设置
打开终端,为 Agno AI 代理项目创建一个新目录,该项目将使用 Bright Data 进行网络扫描:
mkdir agno-web-scraperagno-web-scraper文件夹将包含 Agno 代理抓取的所有 Python 代码。
接下来,导航进入项目目录,并在其中建立虚拟环境:
cd agno-web-scraper
python -m venv venv现在,在您最喜欢的 Python IDE 中加载该项目。我们推荐带有 Python 扩展的 Visual Studio Code或PyCharm Community Edition。
在项目文件夹中新建一个名为scraper.py 的文件。您的目录结构应如下所示:
agno-web-scraper/
├── venv/
└── scraper.py在终端中激活虚拟环境。在 Linux 或 macOS 中,执行
source venv/bin/activate同样,在 Windows 系统中,启动此命令:
venv/Scripts/activate在接下来的步骤中,将引导您安装所需的 Python 软件包。如果您希望现在就在激活的虚拟环境中安装所有软件包,请运行
pip install agno python-dotenv google-genai requests注意:我们安装google-genai,是因为本教程使用 Gemini 作为 LLM 提供程序。如果您打算使用其他 LLM,请务必为该提供程序安装相应的库。
一切就绪!现在,您已经有了一个 Python 开发环境,可以使用 Agno 和 Bright Data 构建抓取代理工作流程。
步骤 #2:配置环境变量 阅读
您的 Agno 抓取代理将通过 API 集成连接到第三方服务,如 Bright Data 和 Gemini。为确保安全,请避免将 API 密钥直接硬编码到 Python 代码中。相反,应将它们存储为环境变量。
为方便加载环境变量,请使用python-dotenv库。激活虚拟环境后,运行以下命令进行安装:
pip install python-dotenv接下来,在scraper.py文件中导入该库,并调用load_dotenv() 加载环境变量:
from dotenv import load_dotenv
load_dotenv()该函数允许脚本从本地.env文件读取变量。请在项目目录根目录下创建一个.env文件:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.py太棒了您现在可以使用环境变量安全地处理集成机密了。
步骤 #3:设置亮数据
Agno 中集成的 Bright Data 工具可让您访问多个数据收集解决方案。在本教程中,我们将重点介绍如何集成这两种特定的抓取产品:
- Web Unlocker API:高级数据抓取 API,能有效应对各种反爬机制,以 Markdown 格式稳定访问任意网页内容。
- Web Scraper APIs:专业的数据抓取端点,可合规地从包括 LinkedIn、亚马逊等热门网站中快速抓取最新的结构化数据。
要使用这些工具,您需要
- 在您的 Bright Data 账户中设置 Web Unlocker 解决方案。
- 获取您的 Bright Data API 令牌,以验证对 Web Unlocker 和 Web Scraper API 的请求。
请按照以下说明进行操作!
首先,如果您还没有 Bright Data 账户,请免费注册。如果已经注册,请登录并打开仪表板。在此,单击 “获取代理产品 “按钮:
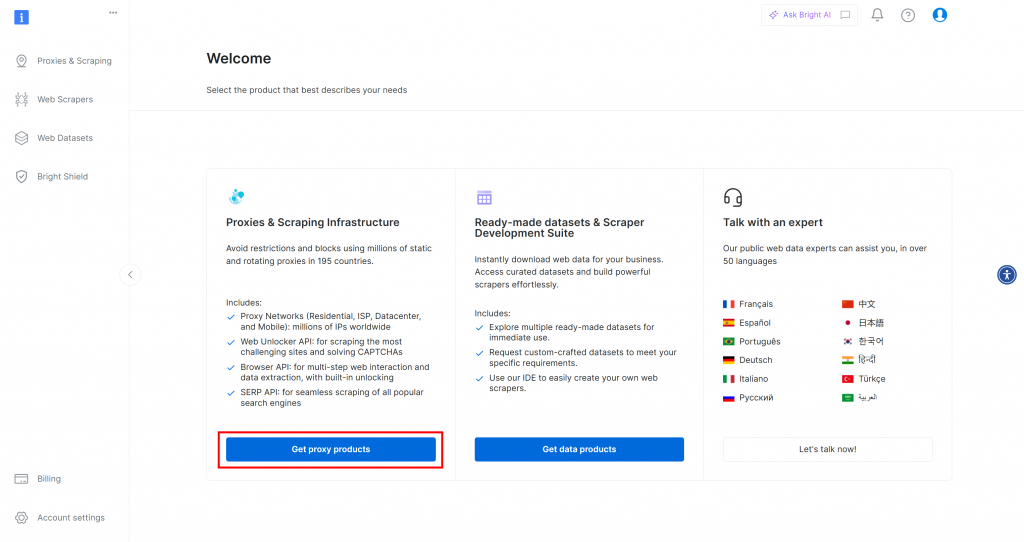
您将被重定向到 “代理和搜索基础设施 “页面:
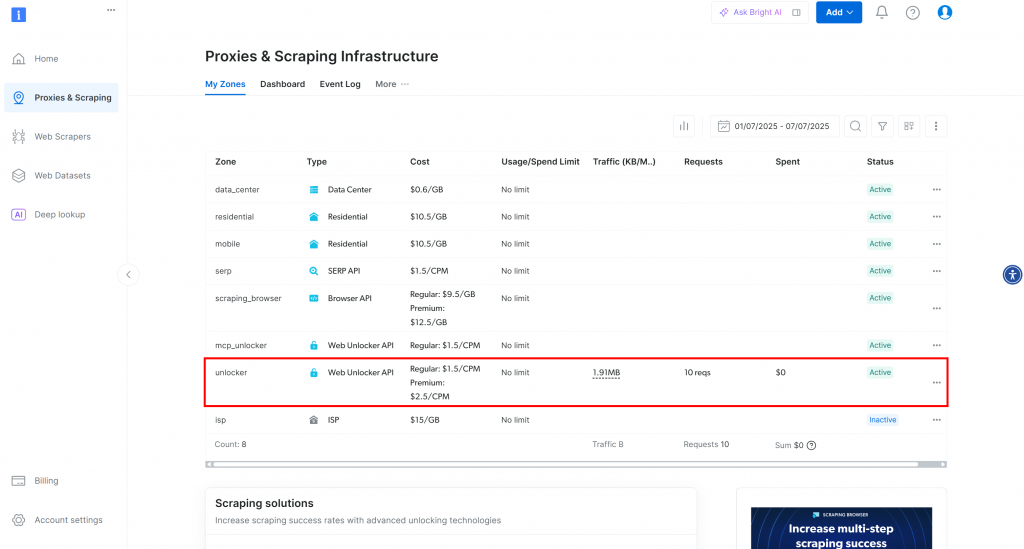
在此页面,您将看到已配置的 Bright Data 解决方案。在本例中,激活了 Web Unloker 区域。该区的名称是 “unblocker”(稍后将其集成到脚本中时需要用到)。
如果还没有 Web Unlocker 区域,请向下滚动到 “Web Unlocker API “卡,然后单击 “创建区域”:
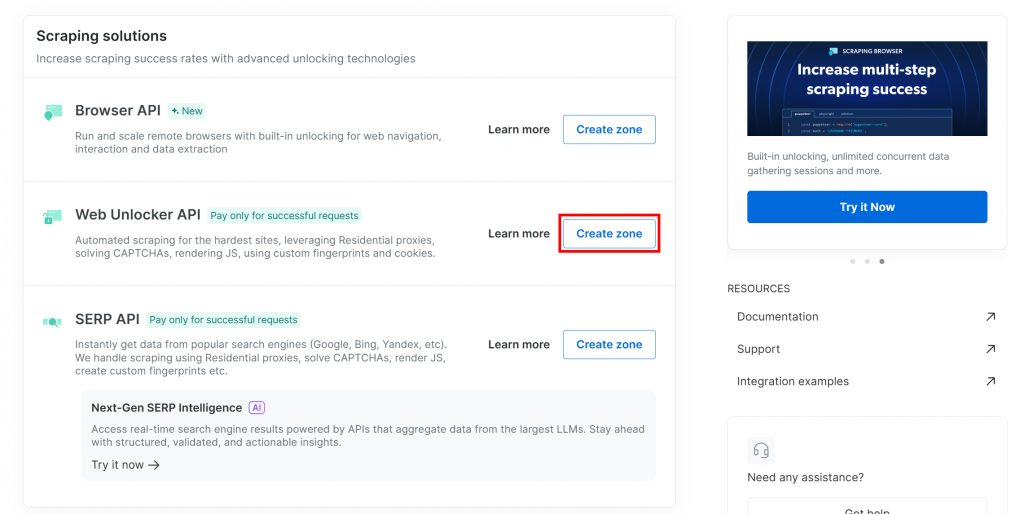
给你的区域起个名字(如 “解锁程序”),启用高级功能以获得最佳性能,然后按 “添加 “按钮:
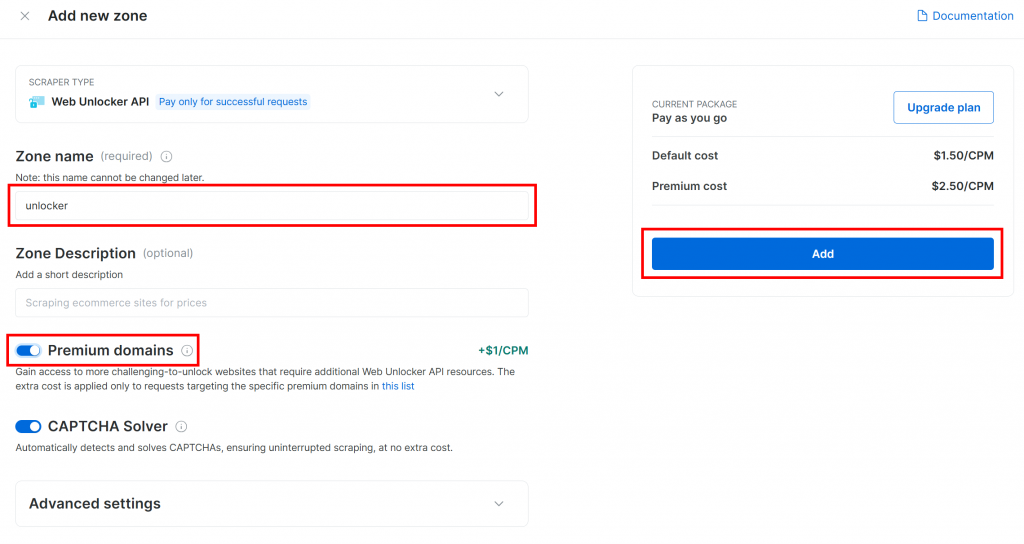
您将进入新区页面。确保切换按钮设置为 “激活 “状态,这表示产品已准备就绪可以使用:
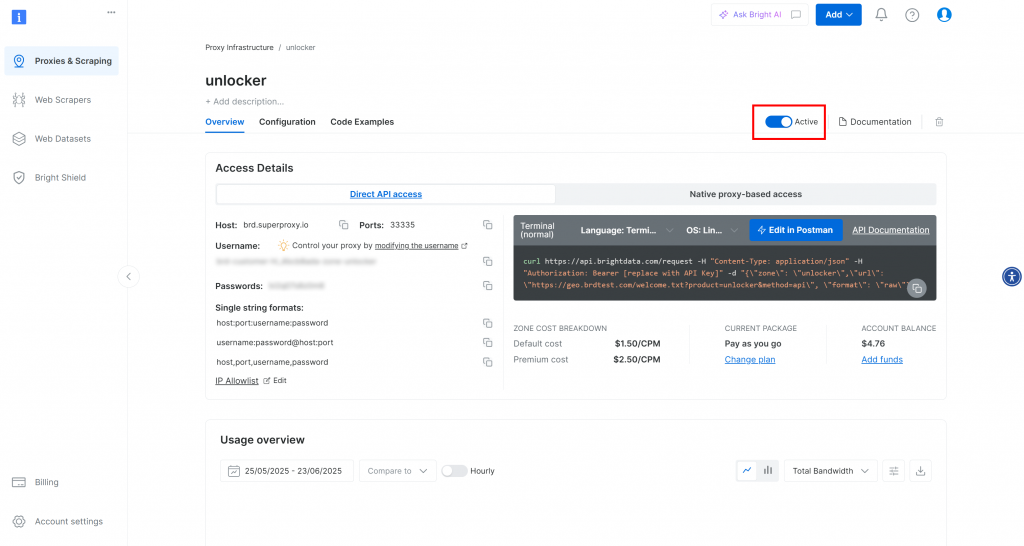
现在,按照Bright Data 官方文档生成 API 密钥。获得密钥后,像这样将其添加到.env文件中:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"将 占位符替换为实际的 API 密钥值。
完美!是时候将 Bright Data 工具集成到您的 Agno 代理脚本中,进行代理式网络搜索了。
步骤 #4:整合 Agno Bright 数据工具进行网络抓取
在激活虚拟环境的项目文件夹中,运行 Agno 安装程序:
pip install agno请记住,agno软件包已经内置了对 Bright Data 工具的支持。因此,您不需要任何额外的集成专用软件包。
唯一需要额外安装的软件包是 Python Requests 库,Bright Data 的工具使用它来调用您之前通过 API 配置的产品。请使用以下命令安装 requests:
pip install requests在scraper.py文件中,从agno 导入 Bright Data 抓取工具:
from agno.tools.brightdata import BrightDataTools然后,像这样初始化工具:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)将"unlocker "替换为 Bright Data Web Unlocker 区域的实际名称。
另外请注意,search_engine设置为 “假“,因为在本示例中我们不使用SERP API 工具,该工具只专注于网络抓取。
提示:可以从.env文件加载区域名称,而不是硬编码。为此,请在.env文件中添加此行:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"用真正的 Web 解锁器区域名称替换占位符。然后,就可以从BrightDataTools 中移除web_unlocker_zone参数。该类将自动从您的环境中获取区域名称。
注意:要连接到 Bright Data,BrightDataTools会在BRIGHT_DATA_API_KEY环境变量中查找您的 API 密钥。这就是我们在上一步中将其添加到.env文件的原因。
令人惊叹!整合 Gemini,为您的 Agno 网络搜索代理工作流程提供动力。
步骤 #5:从双子座配置 LLM 模型
是时候连接本教程中选择的 LLM 提供商 Gemini 了。首先安装google-genai软件包:
pip install google-genai然后,从 Agno 中导入双子座集成类:
from agno.models.google import Gemini现在,像这样初始化 LLM 模型:
llm_model = Gemini(id="gemini-2.5-flash")在上述代码段中,gemini-2.5-flash是您希望代理使用的 Gemini 模型名称。您也可以用任何其他受支持的 Gemini 模型来替换它(只需记住,其中有些模型不能通过 API 免费使用)。
在引擎盖下,google-genai库希望你的双子座 API 密钥存储在名为GOOGLE_API_KEY 的环境变量中。要设置它,请在.env文件中添加以下一行:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"将 占位符替换为您的实际 API 密钥。如果您还没有,请按照官方指南生成 Gemini API 密钥。
注意:如果您想连接到不同的 LLM 提供商,请查看官方文档了解设置说明。
太棒了现在,您已经拥有了构建 Agno 搜索引擎所需的所有核心组件。
步骤 #6:定义扫描代理
在scraper.py文件中,像这样设置 Agno 搜索代理:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)这将创建一个 Agno Agent 对象,该对象使用配置的 LLM 来处理提示,并利用 Bright Data 工具进行网络搜索。
不要忘记在文件顶部添加此导入:
from agno.agent import Agent太好了!剩下的工作就是向你的代理商发送查询,并导出搜索到的数据。
步骤 #7:查询 Agno Scraping Agent
从 CLI 中读取提示,并将其传递给 Agno 搜索代理执行:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)第一行使用 Python 内置的input()函数读取用户输入的提示。提示应该描述你希望代理处理的抓取任务或问题。第二行 [调用代理的run()] 来处理提示并执行任务](https://docs.agno.com/agents/run#running-your-agent)。
要在终端中显示格式良好的响应,请使用
pprint_run_response(response)像这样从 Agno 导入这个辅助函数:
from agno.utils.pprint import pprint_run_responsepprint_run_response打印人工智能代理的响应。但您可能还想提取并保存 Bright Data 工具返回的原始数据。让我们在下一步中处理这个问题!
步骤 #8:导出抓取的数据
在运行搜索任务时,您的 Agno 网络搜索代理会在幕后调用已配置的 Bright Data 工具。确保您的脚本也能导出这些工具返回的原始数据,这将为您的工作流程增添很多价值。因为您可以在其他场景(如数据分析)或其他代理用例中重复使用这些数据。
目前,您的抓取代理可以访问BrightDataTools 的这两种工具方法:
scrape_as_markdown():抓取任何网页并以 Markdown 格式返回内容。web_data_feed():从 LinkedIn、亚马逊、Instagram 等热门网站读取结构化 JSON 数据。
因此,根据任务的不同,抓取数据的输出可以是 Markdown 格式,也可以是 JSON 格式。要处理这两种情况,可以通过response.tools[0].result 从工具结果中读取原始输出。然后,尝试将其解析为 JSON 格式。如果失败,则将抓取数据视为 Markdown 格式。
用这几行代码实现上述逻辑:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) 不要忘记从 Python 标准库中导入json:
import json太好了!您的 Agno 网络抓取代理工作流程现已完成。
步骤 #9:将所有内容整合在一起
这是您的scraper.py文件的最终代码:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)只需不到 50 行代码,您就可以构建一个人工智能驱动的抓取工作流程,从任何网页中提取数据。这就是将 Bright Data 与 Agno 结合起来进行代理开发的威力!
步骤 #10:运行 Agno 搜索代理
在终端运行 Agno 网络扫描代理:
python scraper.py系统会提示您输入一个请求。试着输入
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"您应该会看到类似下面的输出:
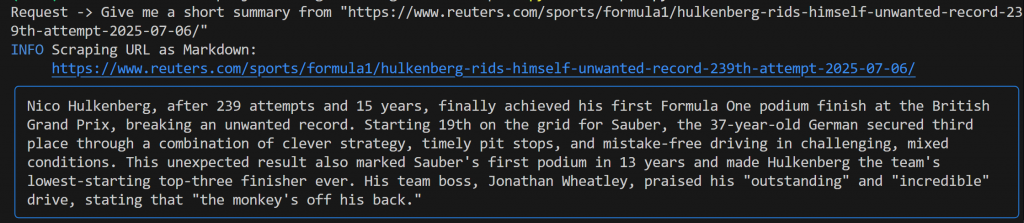
该输出包括
- 您提交的原始提示。
- 显示使用哪种 Bright Data 工具进行抓取的日志。在本例中,它确认调用了
scrape_as_markdown()。 - 双子座生成的 Markdown 格式摘要,以蓝色矩形突出显示。
如果你查看项目根文件夹,就会看到一个名为output.md 的新文件。在任何 Markdown 查看器中打开它,你就会得到一个 Markdown 版本的抓取页面内容:

可以看出,Bright Data 的 Markdown 输出准确地捕捉到了原始网页的内容:
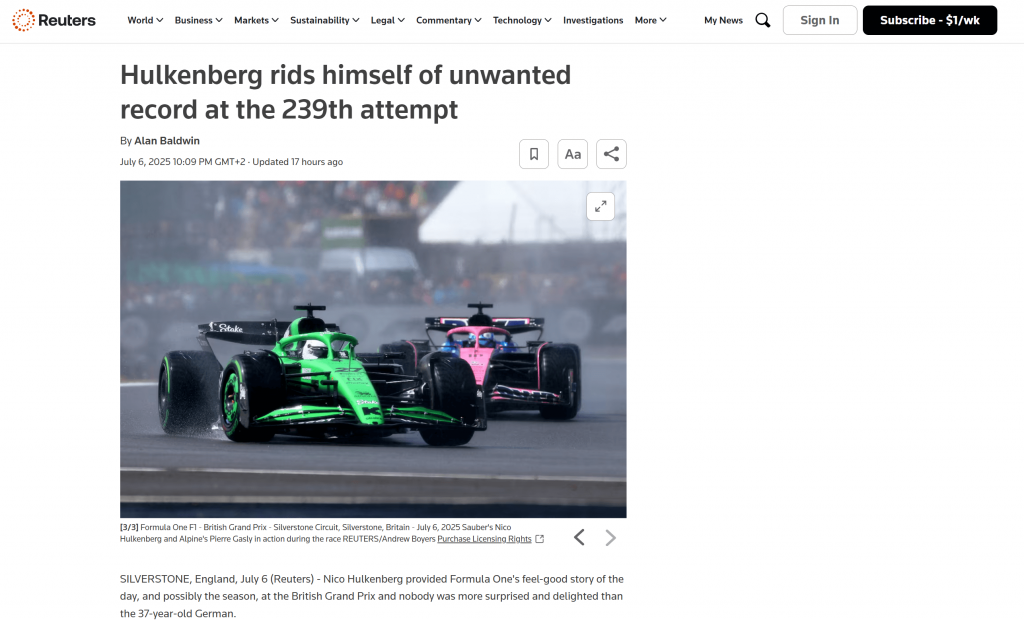
现在,尝试用一个不同的、更具体的请求再次启动抓取代理:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" 这次的输出结果可能是这样的
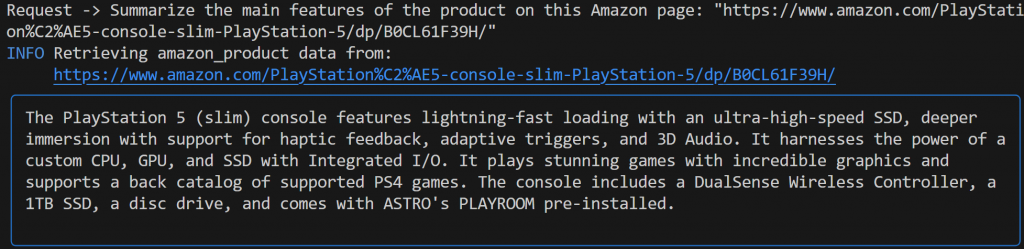
请注意由 Gemini 驱动的 Agno 代理如何自动选择web_data_feed工具,该工具已为亚马逊产品页面的结构化搜索进行了正确配置。
这样,您就可以在项目文件夹中找到output.json文件。打开该文件并将其内容粘贴到任何 JSON 查看器中:
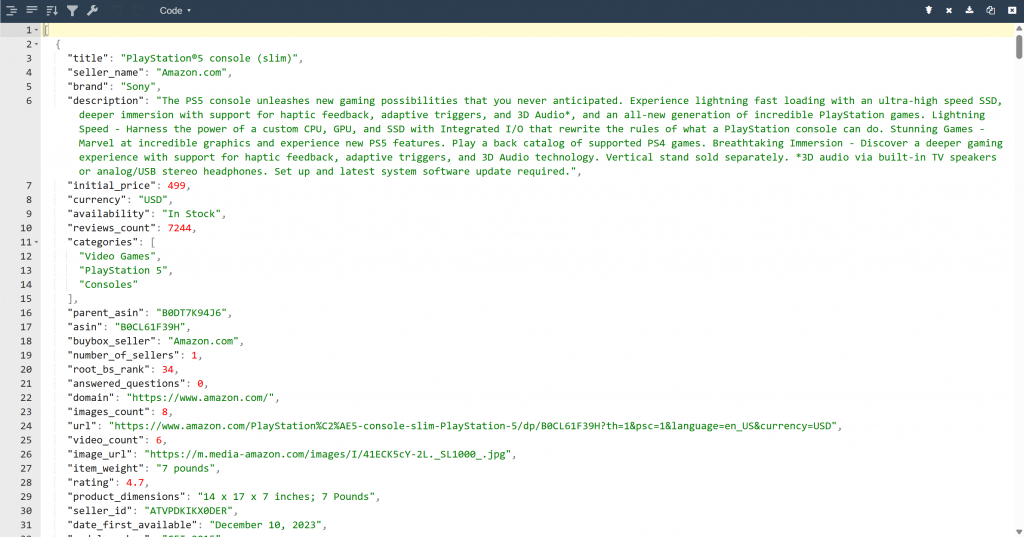
看看 “亮数据 “工具从亚马逊网页中提取的结构化 JSON 数据是多么整洁:
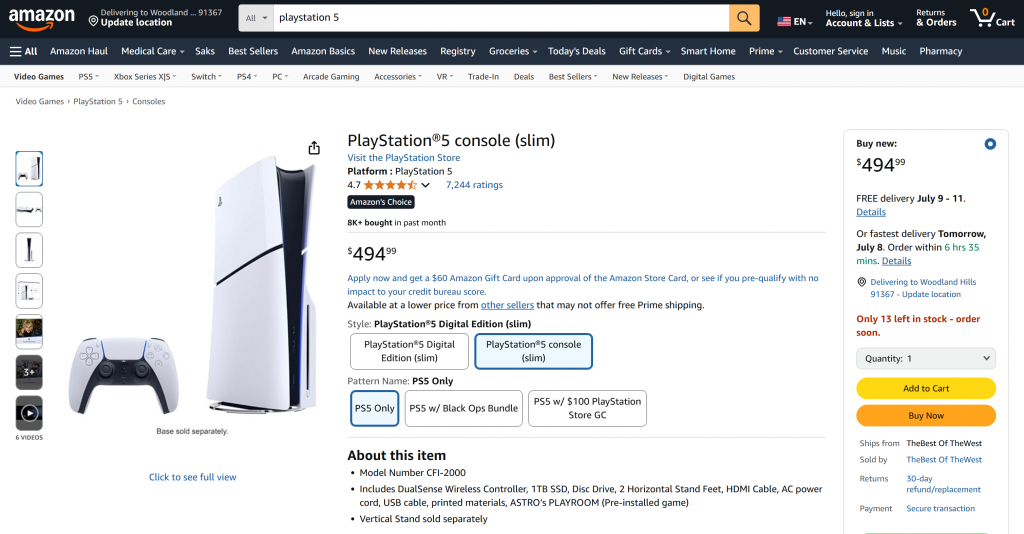
这两个例子都说明了你的代理现在可以从几乎任何网页上获取数据。即使是像亚马逊这样的复杂网站也是如此,这些网站以其严密的反抓取防御(如臭名昭著的亚马逊验证码)而闻名。
就是这样!在 Bright Data 工具和 Agno 的支持下,您刚刚在人工智能代理中体验了无缝网络搜索。
下一步工作
您刚刚使用 Agno 创建的网络抓取代理只是一个开始。从这里开始,您可以探索多种方法来扩展和增强您的项目:
- 加入存储层:使用 Agno 的本地矢量数据库来存储您的代理通过 Bright Data 收集的数据。这将为您的代理提供长期记忆,为代理 RAG 等高级用例铺平道路。
- 创建用户友好界面:创建一个简单的网络或桌面用户界面,这样用户就能以自然、对话的方式与您的代理聊天(类似于与 ChatGPT 或 Gemini 的交互)。这将使您的抓取工具更易于使用。
- 探索更丰富的集成:Agno 提供各种工具和功能,可将您的代理技能扩展到抓取之外。深入Agno 文档,了解如何连接更多数据源、使用不同的 LLM 或协调多步骤代理工作流程。
结论
在本文中,您将了解到如何使用 Agno 构建用于网络搜索的人工智能代理。这得益于 Agno 与 Bright Data 工具的内置集成。这些工具使所选择的 LLM 具备了从任何网站提取数据的能力。
请记住,这只是一个简单的例子。如果您想开发更高级的代理,您将需要用于获取、验证和转换实时网络数据的解决方案。这正是您可以在Bright Data AI 基础架构中找到的。
创建一个免费的 Bright Data 帐户,开始尝试使用我们的 AI 就绪抓取工具!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



