

在本文中,你将了解:
- Ruflo 是什么、它的主要功能和能力,以及它最大的局限性。
- 如何使用像 Bright Data 这样面向 AI 的网页数据基础设施解决方案来解决这些局限性。
- 将 Bright Data 和 Ruflo 集成到 Claude Code 或 OpenAI Codex 设置中的两种主要方式。
- 如何通过在本地 Claude Code 驱动的项目中设置 Ruflo 来开始使用它。
- 如何通过 MCP 向该设置添加 Bright Data 企业级网页搜索、数据检索和网站交互能力。
- 如何使用 Bright Data Claude 技能 实现相同的集成。
- 这种 Ruflo + Bright Data 设置能为 agentic 编码助手带来什么。
让我们深入了解!
Ruflo 简介:面向 Claude 的智能体编排平台
你很快就会看到如何以及为什么要将 Ruflo 与 Bright Data 的网页数据检索和搜索能力结合起来。但首先,花一点时间了解一下 Ruflo 是什么,以及它能带来什么!
什么是 Ruflo?
Ruflo(前身为 Claude Flow)是一个 AI 编排框架,旨在将 Claude Code(以及 OpenAI Codex)转变为一个功能丰富的多智能体编排框架。
具体来说,它为 agentic 编码助手配备了一组协调工作的、约 100 个并行运行的专业 AI 智能体。这使 Claude Code 和 OpenAI Codex 能够通过智能路由、共享内存和自学习工作流来处理复杂的软件任务。
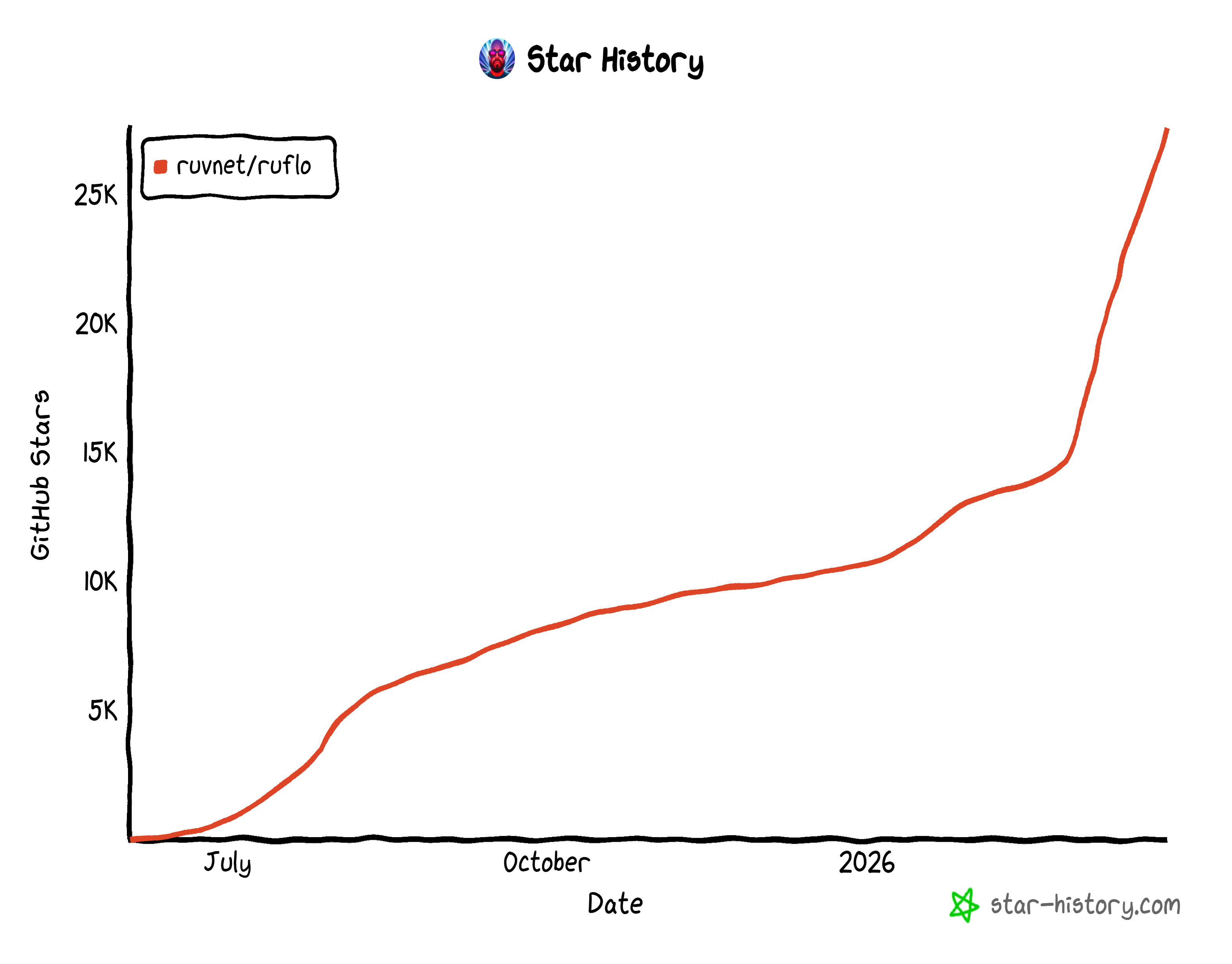
作为一个开源项目,Ruflo 拥有超过 27k GitHub 星标和 6,000 多次提交。这种快速增长凸显了 Ruflo 在开发者社区中获得关注的速度之快。
Ruflo 如何将 AI Agentic 编码助手提升到新水平
从高层次来看,Ruflo 提供的主要功能包括:
- 大规模多智能体编排:部署并协调约 100 个专业 AI 智能体,并行处理复杂开发任务。
- 基于 swarm 的协作:智能体在结构化的“群体”中运行,具备分层协调、共识机制和共享目标。
- 自学习和自适应路由:从过去的执行中学习,并使用模式识别将任务动态路由到最有效的智能体。
- 持久化内存和知识图谱: 结合向量搜索(HNSW)、共享内存和知识图谱,以在会话之间保留上下文。
- 智能成本和性能优化:使用多层路由(WASM + LLMs)来降低延迟,并将 API 成本最多削减约 75%。
- 支持多 LLM 并具备故障转移:可与 Claude、GPT、Gemini 和本地模型协同工作,并为每个任务自动选择最佳提供商。
- 面向生产环境的安全性和可扩展性:内置防护(提示注入、验证)以及用于扩展智能体、hooks 和工作流的插件系统。
这导致了 Claude Code 在有无 Ruflo 时的一个重大差异:
| 仅 Claude Code | Claude Code + Ruflo | |
|---|---|---|
| 智能体协作 | 智能体独立工作 | 智能体通过共享内存协作 |
| 协调 | 手动任务管理 | Queen 主导的层级结构与自动化协调 |
| 群体思维 | 不可用 | 跨智能体的集体智能 |
| 共识 | 无多智能体决策 | 具备容错能力并遵循多数规则的投票 |
| 内存 | 仅限会话 | 持久化向量内存 + 知识图谱 |
| 向量数据库 | 无 | RuVector PostgreSQL,快速搜索和高 QPS |
| 知识图谱 | 扁平列表 | 使用 PageRank 和社区检测突出关键洞察 |
| 集体记忆 | 无共享知识 | 跨智能体共享知识库 |
| 学习 | 静态,无适应能力 | 具备快速适应和洞察迁移的自学习 |
| 智能体作用域 | 仅限单个项目 | 多层级内存(项目/本地/用户)并支持跨智能体迁移 |
| 任务路由 | 手动选择智能体 | 基于学习模式的智能路由 |
| 复杂任务 | 需要手动拆解 | 跨多个领域自动分解 |
| 后台工作器 | 无 | 在文件更改或模式等触发器下自动分发 |
| LLM 提供商 | 仅 Anthropic | 多提供商,具备故障转移和成本优化 |
| 安全性 | 标准防护 | 强化:验证、加密、CVE 缓解 |
| 性能 | 基线 | 通过并行 swarms 和智能路由实现更快速度 |
最大的局限性以及如何解决它们
无论 Ruflo 约 100 个智能体及其整体能力多么丰富和强大,都存在一个根本性的局限。这在于 LLM 本身的性质。这些模型是在静态数据集上训练的,而这些数据集会在某个特定时间点停止更新,这从根本上限制了它们的知识范围。
当然,Ruflo 包含一个用于网页搜索、交互和数据提取的专用浏览器自动化智能体。现在,问题在于如今大多数网站都有反机器人系统,会阻止自动化请求。这也包括来自 AI 驱动浏览器智能体的请求。因此,Ruflo 的知识检索可能会失败,或者只能访问它所需内容的一部分。
这是一个关键问题,因为准确、新鲜且具备上下文的知识,才是真正让多智能体系统高效的核心。为了克服这个问题,你的 AI 编码助手需要专门为实时网页搜索、数据提取和无阻网页交互而设计的工具。
而这正是 Bright Data 所提供的!
Bright Data 网页数据工具作为解决方案
作为市场领先的网页数据平台,Bright Data 提供了适用于 AI 智能体的工具,例如:
- 搜索引擎 API:从 Google、Bing 等搜索引擎收集结果,为有依据的响应提供支持。
- 网络解锁器 API:访问任意网站的原始 HTML 或 Markdown,绕过 验证码破解、IP 封禁和反机器人措施。
- Browser API:以编程方式控制远程浏览器,对任意网站进行自动化、无阻的交互。
- 爬虫 API:从 Amazon、Instagram、LinkedIn、Yahoo Finance 等平台收集结构化数据。
- Crawl API:将整个网站转换为结构化数据集,用于下游 AI 工作流。
Bright Data 的与众不同之处在于其企业级基础设施。它建立在一个覆盖全球的代理网络之上,拥有遍布 195 个国家/地区的超过 4 亿个 IP,支持无限扩展性,同时保持 99.99% 的正常运行时间和 99.95% 的成功率。
Bright Data 与 Ruflo 协同工作,使你的 agentic 编码系统能够探索、检索并基于实时网页数据进行推理。所有这些都可以大规模完成,而且不会遇到封锁!
如何结合 Bright Data 和 Ruflo:两种方法
从技术上讲,你可以使用插件 SDK将 Bright Data 直接集成到 Ruflo 中。你需要定义自定义工具,以连接到你想使用的每个 Bright Data 产品。不过,这并不是最快的方法!
与其重复造轮子,不如更轻松地依赖:
- Bright Data Web MCP:一个一体化开源服务器,公开了 60 多种工具,用于无阻的网页搜索、导航、数据提取和交互。
- Bright Data 技能:预构建能力,用于教会你的编码智能体如何执行 AI 驱动的抓取、搜索和结构化数据检索。它们包括与 Web MCP 的连接。
这些都可以直接添加到 Claude Code(或 OpenAI Codex)中,从而形成一个统一的编码设置,将 Ruflo 和 Bright Data 结合起来。底层 LLM 随后便可以协调且协同地使用这两种解决方案中的工具。
注意:下面的示例使用 Claude Code,但你也可以轻松地将它们适配到 OpenAI Codex。
现在让我们看看如何使用 MCP 或 技能 通过 Bright Data 和 Ruflo 扩展 Claude Code。不过首先,先设置 Ruflo!
开始使用 Ruflo
按照以下说明,了解如何在你的编码项目中配置 Ruflo。
前提条件
要跟随本节内容,请确保你已具备:
- 已在本地安装并配置 Claude Code。
- 已在本地安装 Node.js 20+(推荐使用最新的 LTS 版本)。
第 1 步:配置 Ruflo
为你的编码项目创建一个新文件夹(例如,bright-data-ruflo-project)。你将在这里初始化 Ruflo。然后,在终端中进入该文件夹:
mkdir bright-data-ruflo-project
cd bright-data-ruflo-project注意:你也可以从现有项目文件夹开始。在大多数情况下,这就是你会做的。你会将 Ruflo 添加到你的项目中,以利用它的功能。
在终端中运行以下命令,通过 npm 启动 Ruflo 安装向导:
npx ruflo@latest init --wizard安装 ruflo 包可能需要几分钟时间,因此请耐心等待。
你应该会得到如下输出:
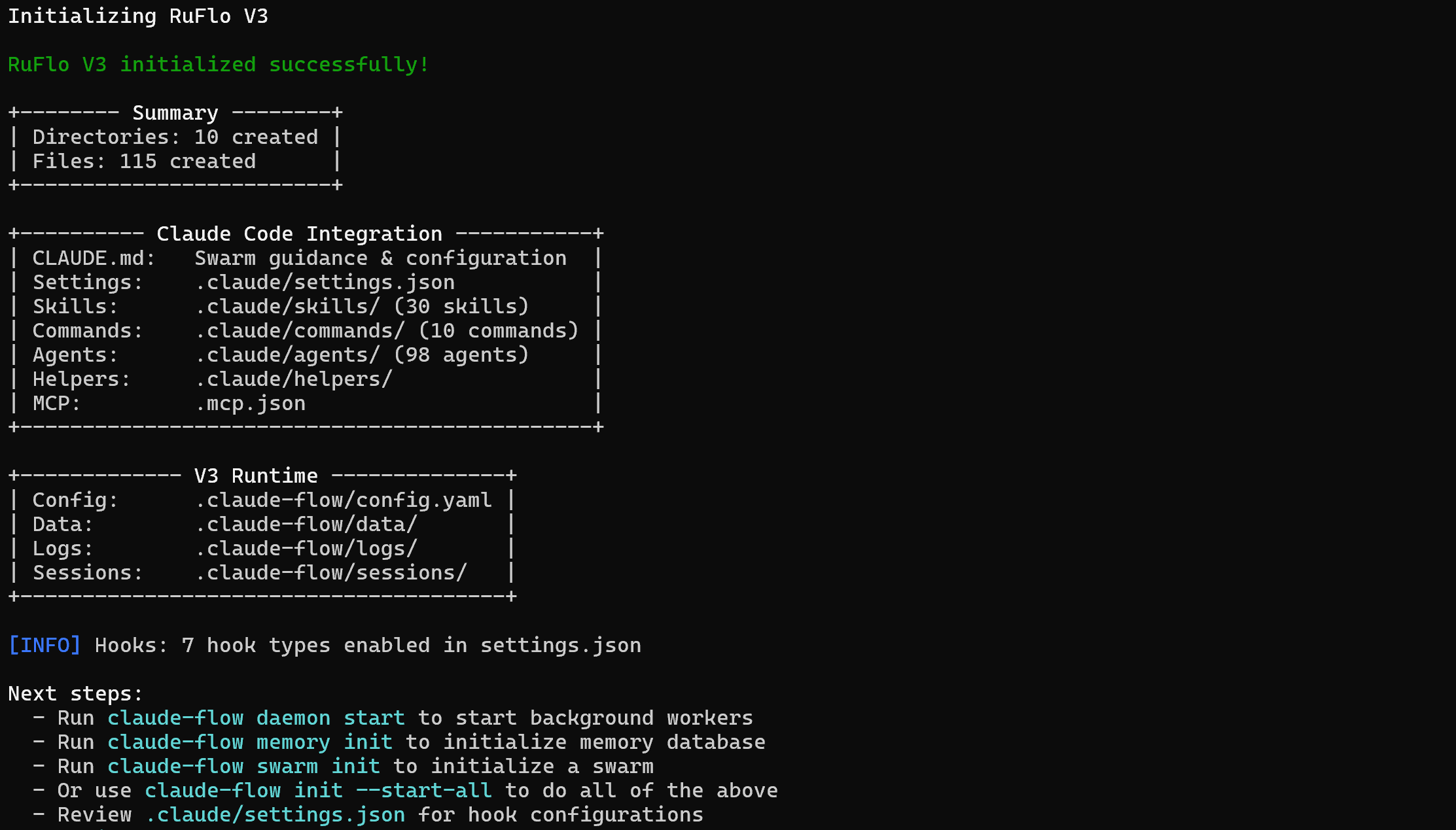
注意:CLI 中的输出可能会建议使用 claude-flow 命令来初始化后端服务、内存数据库或 swarms。不过,这并不准确。通过 npm 安装 Ruflo 时,正确的基础命令是:
npx ruflo@latest你的项目文件夹现在将存储:
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.md基本上,bright-data-ruflo-project 包含了Claude Code 在项目级访问新 技能、命令和智能体所需的所有文件。换句话说,Ruflo 已经完全集成到你的本地 Claude Code 设置中。做得好!
第 2 步:启动 Ruflo
Ruflo 已添加了多个智能体、命令和 skills。不过,要让 Claude Code 能够运行它们,你必须先启动 Ruflo。通过以下命令实现:
npx ruflo@latest start你应该会看到类似这样的输出:
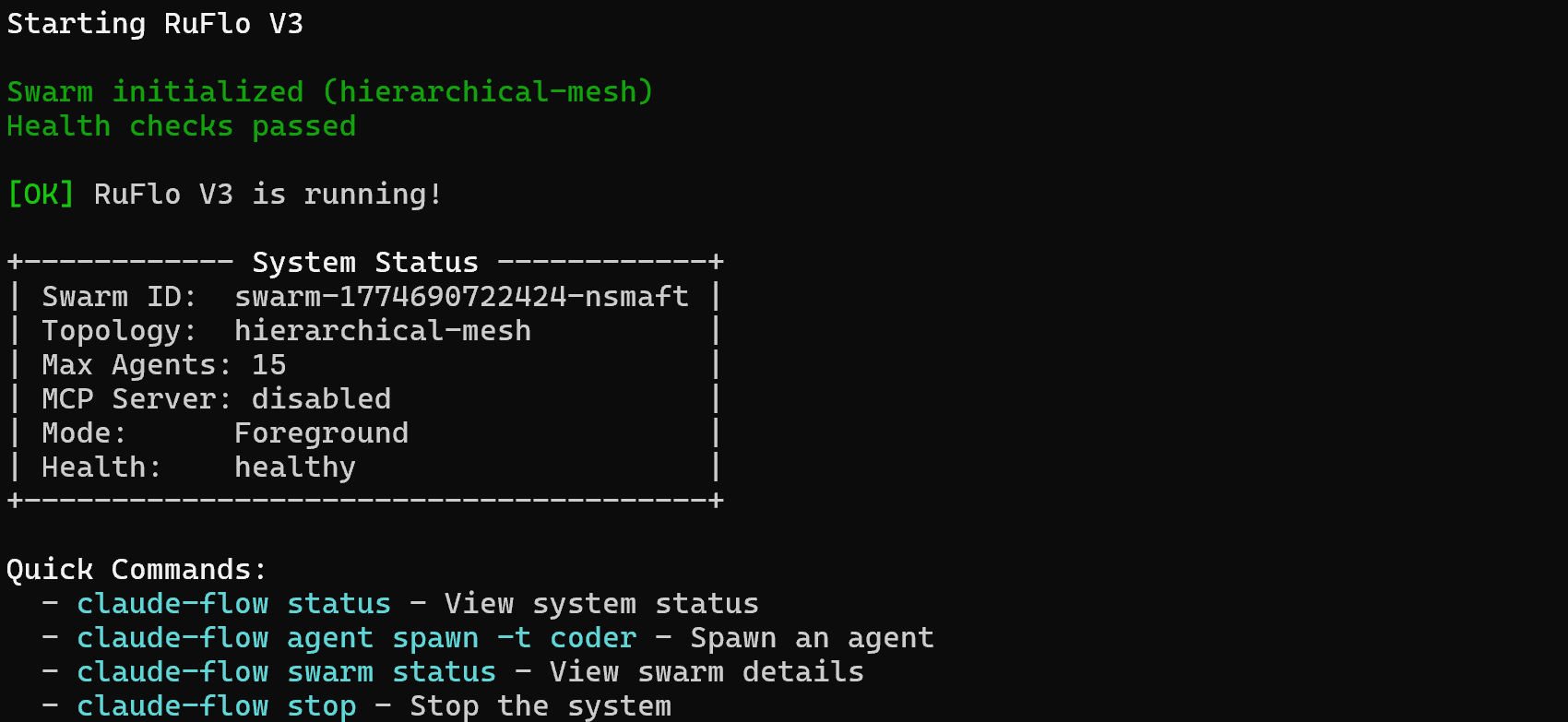
太棒了!你的 Claude Code 设置现在可以利用 Ruflo 提供的扩展功能。
第 3 步:验证集成
在你的项目目录中,启动 Claude Code:
claude你可能会收到如下消息:

选择选项 1 或选项 2。这样,Claude Code 将在启动时启动 Ruflo MCP 服务器并连接到它。
接下来,你会看到日志清楚地表明 Ruflo 在 Claude Code 中可用:
输入“/agent”,你应该会看到一些额外的 Ruflo 命令:

太好了!Claude Code 已成功连接到 Ruflo,确认集成有效。
集成方法 #1:Ruflo MCP + Bright Data MCP
在本节中,你将了解如何通过 MCP 将 Ruflo 和 Bright Data 的能力同时添加到你的 Claude Code 设置中。
前提条件
为了使本节保持简洁,我们将假设你已经将 Bright Data Web MCP 集成到你的 Claude Code 设置中。
如果你还没有这样做,请按照详细教程“将 Claude Code 与 Bright Data 的 Web MCP 集成”或文档指南“Claude Code MCP 服务器 Integration”进行操作。只需确保将所需配置添加到 Ruflo 在执行 init 命令期间创建的本地 .mcp.json 文件中。
熟悉 MCP 的工作原理以及如何将 MCP 服务器连接到 Claude Code也是非常重要的前提。
第 1 步:检查可用的 MCP 服务器
默认情况下,Ruflo MCP 服务器已在本地 .mcp.json 文件中配置。该文件还应包含连接到 Bright Data Web MCP 的配置。
预期行为是 Claude Code 自动检测并连接到这两个 MCP 服务器。为了验证这一点,请在你的项目文件夹中启动 Claude Code 并运行 /mcp 命令:
你应该会看到:
bright-data-web-mcp(或者你在.mcp.json配置中为 Bright Data Web MCP 指定的任何名称)。claude-flow(Ruflo MCP 服务器的名称)。
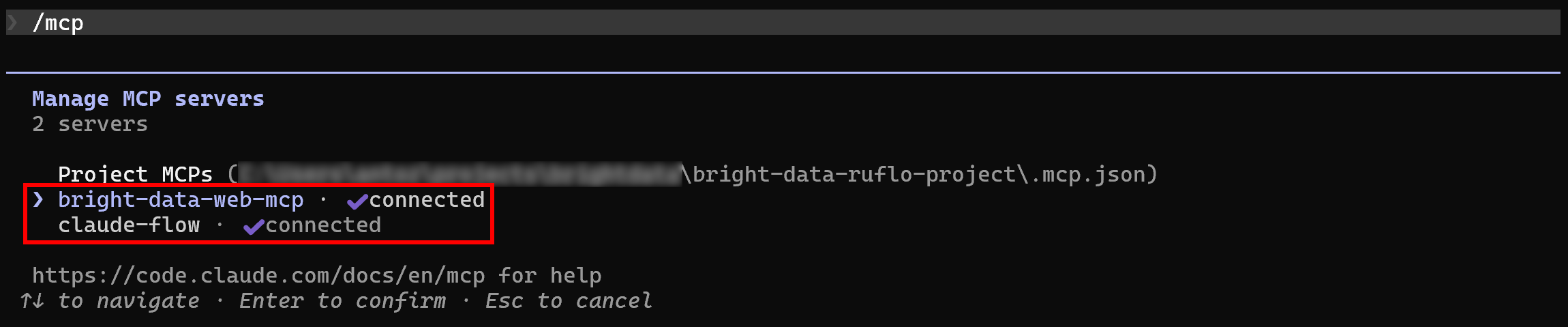
很好!Claude Code 现在已按预期连接到这两个 MCP 服务器。
第 2 步:检查 Bright Data Web MCP 服务器
选择 bright-data-web-mcp 条目(或者你为其指定的任何名称):

选择“View tools”选项以查看所有可用工具。如果你以 Pro 模式配置它,你将获得全部 65+ 个工具:

否则,你将只看到 4 个工具(scrape_as_markdown、search_engine 及其 2 个批处理版本)。
非常好!Bright Data Web MCP 正按预期公开其工具。
第 3 步:检查 Ruflo MCP 服务器
重复与上面相同的过程,但这次针对 claude-flow MCP。你应该会看到:

请注意,Ruflo MCP 一共公开了令人印象深刻的 254 个工具。哇!
集成方法 #2:Ruflo 技能 + Bright Data skills
在这里,你将获得指导,了解如何通过 技能 将 Ruflo 和 Bright Data 的能力添加到你的 Claude Code 设置中。
前提条件
要跟随本节内容,请确保你具备:
- 在基于 Unix 的操作系统(macOS、Linux 或 WSL)中设置好 Claude Code。
- 已在本地安装 Git。
- 一个已设置 网络解锁器 区域并配置了 API 密钥的 Bright Data 账户。
- 对Claude 技能 是什么以及如何在 Claude Code 中配置它们有基本了解。
- 熟悉官方 Bright Data Claude 技能 仓库中提供的 技能。
注意:暂时不用担心设置 Bright Data 账户,因为你将在下一步中获得相关指导。
然后,安装 curl 和 jq,这是 Bright Data Claude 技能 所需的两个前提条件。在 macOS 上,运行:
brew install curl jq同样地,在 Linux 上,执行:
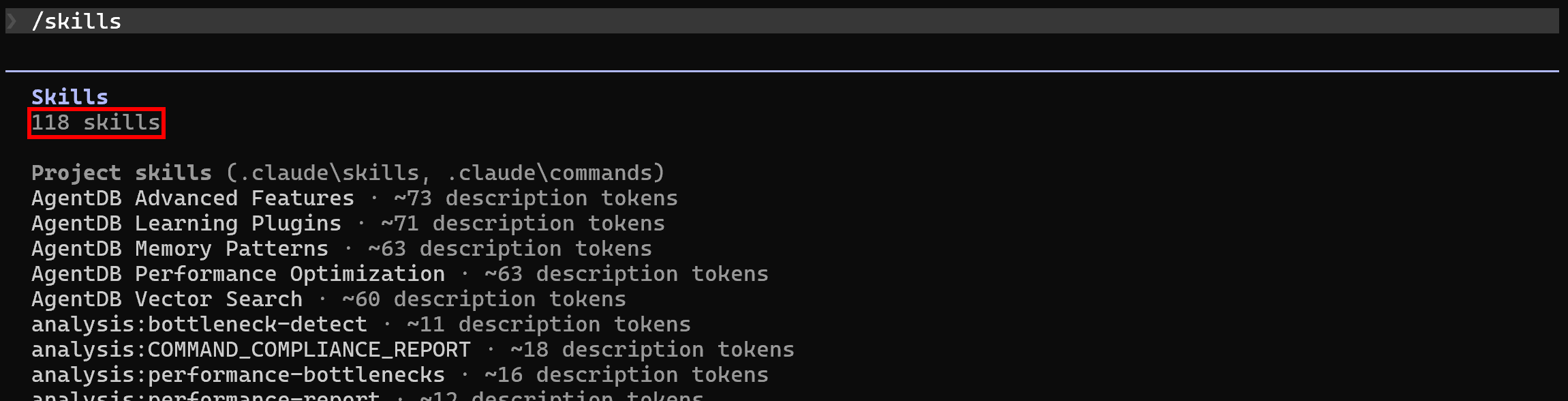
sudo apt-get install curl jq默认情况下,在本地项目中设置 Ruflo 后,Claude Code 将已经列出它的 118 个 技能。通过运行 /skills 命令来验证这一点:
第 1 步:设置你的 Bright Data 账户
如文档中所述,Bright Data Claude 技能 需要将以下两个密钥设置为全局环境变量:
BRIGHTDATA_API_KEY:你的 Bright Data API 密钥。BRIGHTDATA_UNLOCKER_ZONE:你账户中配置的 网络解锁器 区域名称。
作为指导,你可以参考“Bright Data 网络解锁器 API 快速入门指南”文档页面。或者,按照下面的说明操作。
如果你还没有 Bright Data 账户,请创建一个。否则,直接登录。进入控制面板,然后前往“Proxies & Scraping”页面。查看“My Zones”表格:
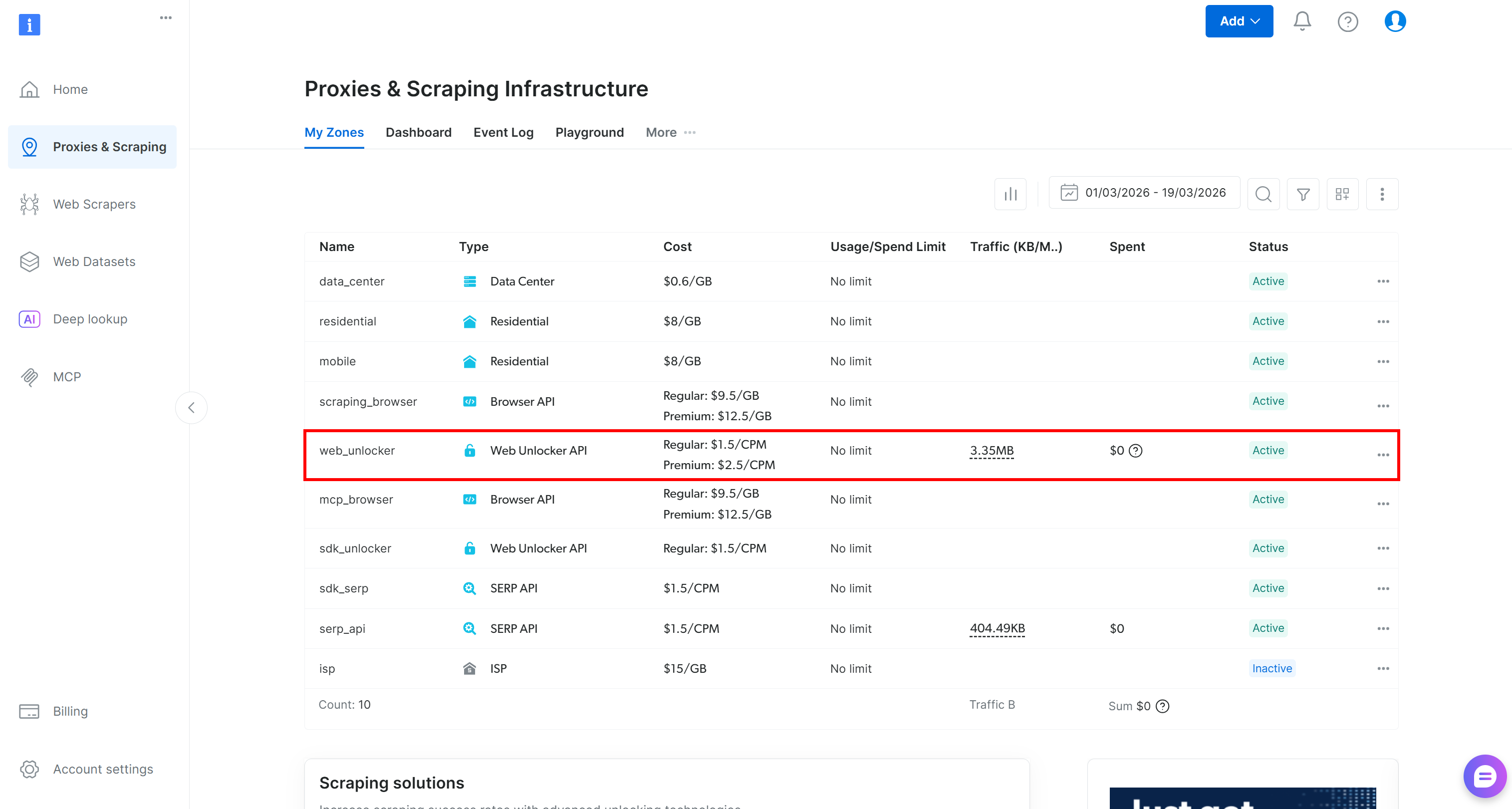
如果存在一个 网络解锁器 API 区域(例如 web_unlocker),你可以继续定义 API 密钥。
如果缺失,请创建一个新的。为此,滚动到“Unblocker API”卡片,点击“Create 区域”,并按照向导操作。
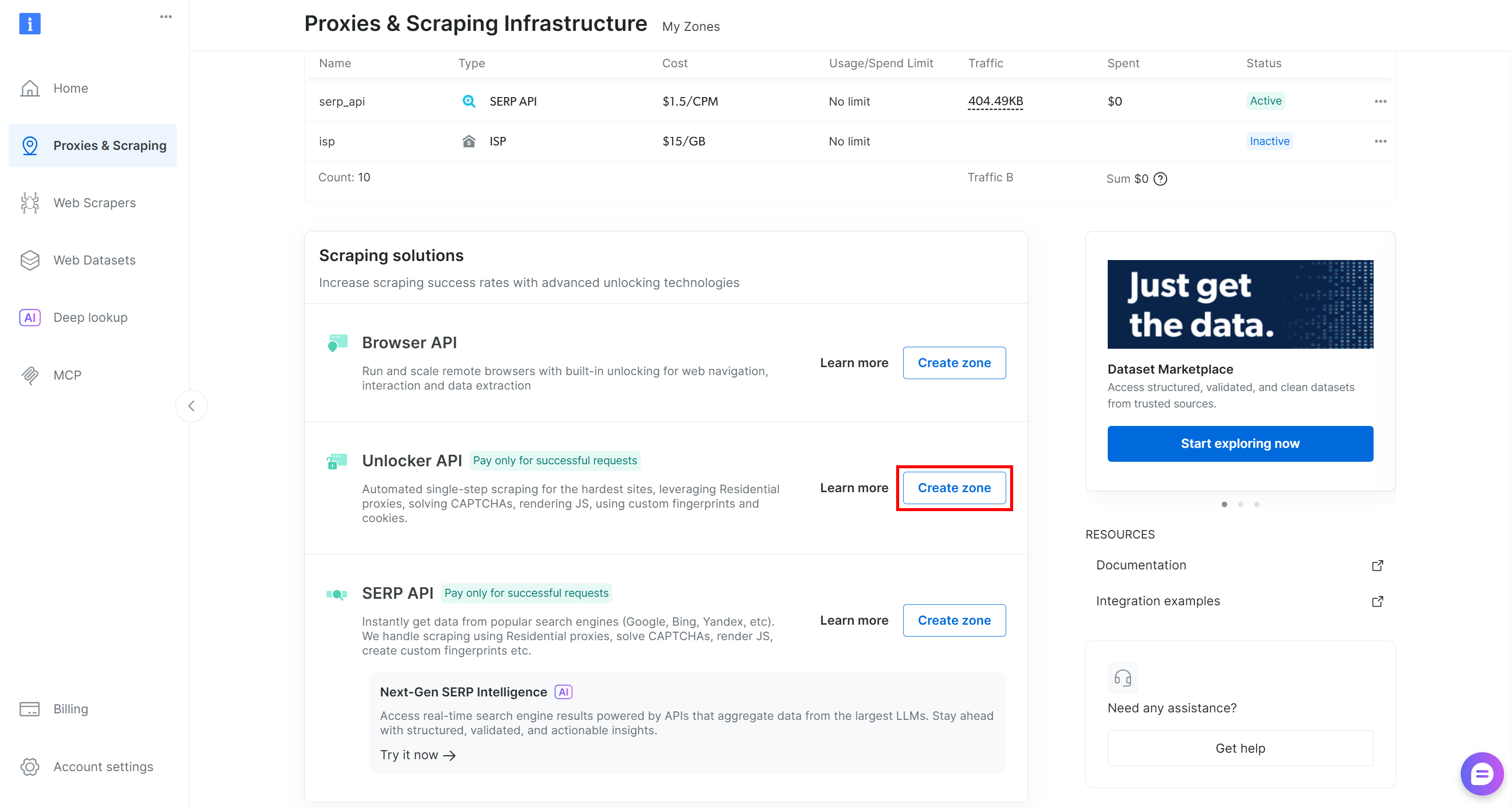
按照向导中的说明操作,为你的区域指定一个有意义的名称(例如 web_unlocker)。
最后,生成你的 Bright Data API 密钥。现在,使用你的 API 令牌和区域名称,像这样定义两个全局环境变量:
export BRIGHTDATA_API_KEY="<YOUR_BRIGHTDATA_API_KEY>"
export BRIGHTDATA_UNLOCKER_ZONE="<YOUR_BRIGHTDATA_UNLOCKER_ZONE>"太棒了!Bright Data Claude 技能 现在可以连接到你的账户并正常工作了。
第 2 步:获取 Bright Data 技能
要向你的设置中添加新 skills,请将它们的文件夹复制到本地 .claude/skills 目录中。
首先,将 Bright Data Claude 技能 仓库克隆到你选择的文件夹中:
git clone https://github.com/bright-cn/skills克隆后的结构应如下所示:
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdBright Data Claude 技能 包括:
search:查询 Google 并返回结构化 JSON 结果,包括标题、链接和描述。scrape:将任意网页提取为干净的 Markdown,同时自动绕过机器人检测。data-feeds:从 40+ 个网站拉取结构化数据,并进行自动轮询和更新。bright-data-mcp:编排 60+ 个 Bright Data MCP 工具,用于搜索、抓取、结构化提取和浏览器自动化。scraper-builder:构建可用于生产环境的爬虫工具,包括站点分析、API 选择、选择器、分页和实现。bright-data-best-practices:网络解锁器、SERP、Web 爬虫工具 和 Browser API 的参考。python-sdk-best-practices:brightdata-sdkPython 包指南:async/sync 客户端、抓取工具、数据集、错误处理和模式。brightdata-cli:Bright Data CLI 的终端指南:抓取、搜索、提取数据、管理代理区域以及检查账户。design-mirror:复制设计系统 token 和组件,以实现一致且高质量的 UI 实现。
将 skills/ 内的文件夹(bright-data-best-practices/、bright-data-mcp/ 等)复制到你项目目录中的本地 .claude/skills。你可以手动执行,也可以通过以下命令完成:
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/完美!Bright Data Claude 技能 已添加到你的项目中。
第 3 步:检查可用的 技能
再次在你的项目文件夹中启动 Claude Code,并运行 /skills 命令:
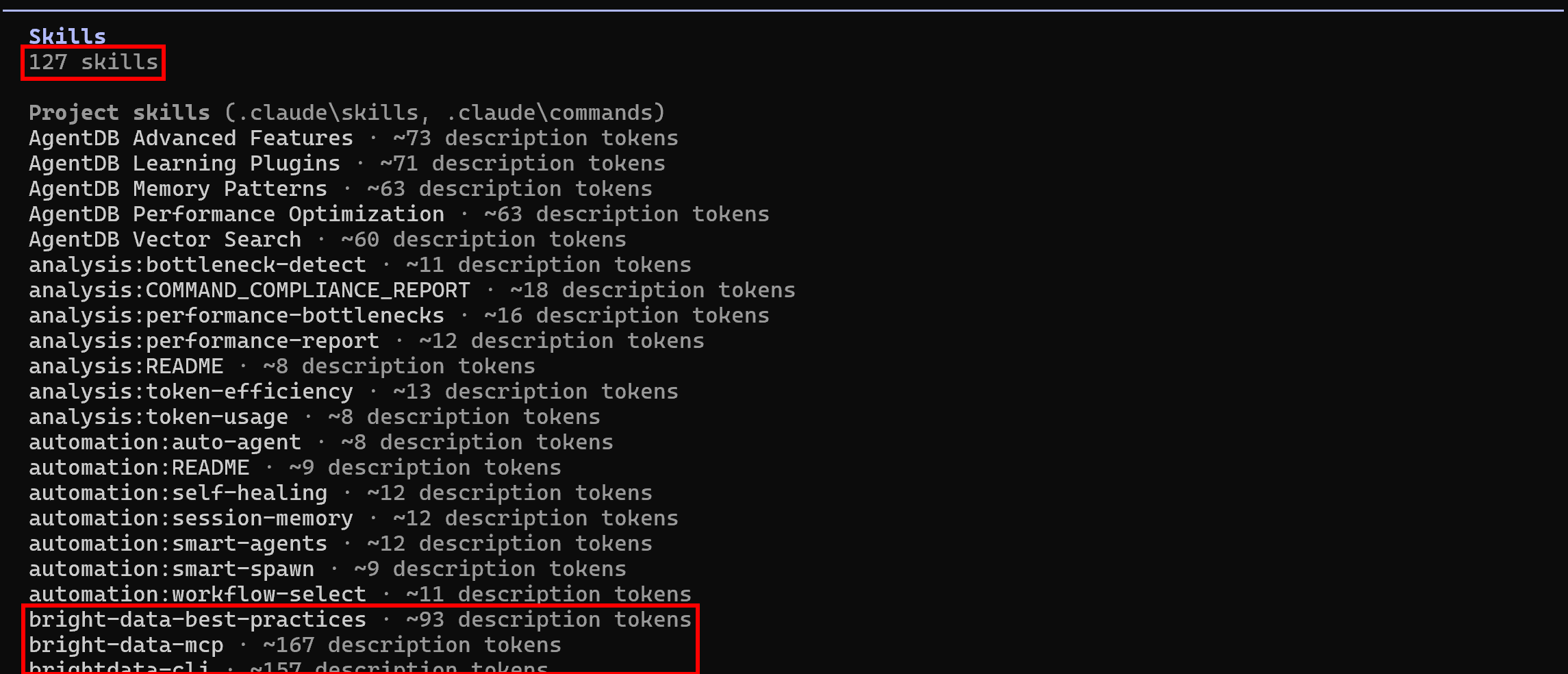
这一次,可用的 技能 应该是 127 个(高于最初的 118 个),这表明 Bright Data skills 已被成功读取。任务完成!你的 agentic 编码系统现在可以利用 Bright Data 技能 进行程序化网页数据提取、网页探索以及更多操作。
Ruflo + Bright Data:整合一切
你的 Claude Code 设置现在可以访问 300 多个 MCP 工具或 125 多个 skills。它们既能实现协调的编码工作,也能让智能体自主搜索网页、抓取数据并与网页交互——所有这些都不会遇到封锁或可扩展性限制。
这开启了许多新的可能性,包括:
- 检索实时搜索引擎结果(SERP),并将上下文链接嵌入到
README.md和其他文档页面中。 - 根据你当前的编码任务发现相关教程或文档,以更高效地改进你的代码库。
- 从网站抓取新鲜的公开数据,并将其保存在本地,用于 mock、分析或进一步处理。
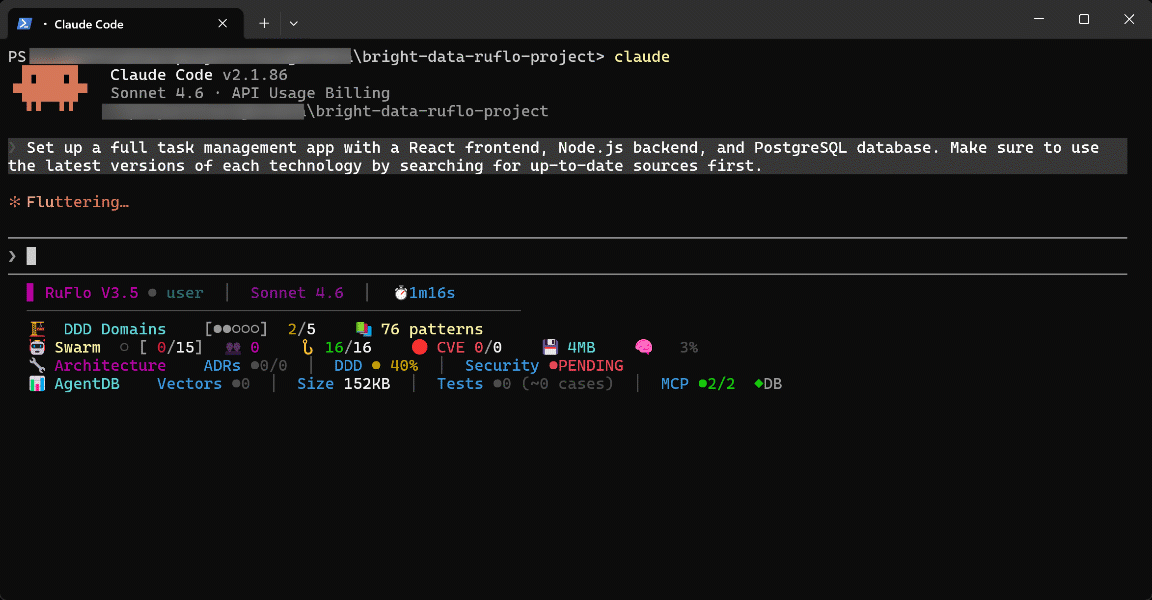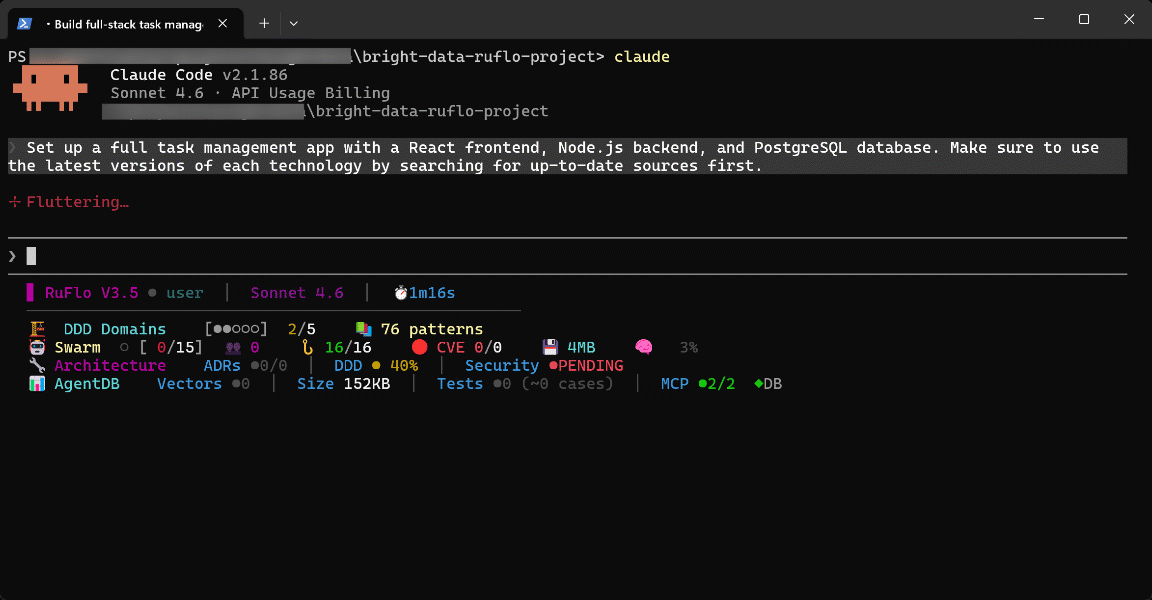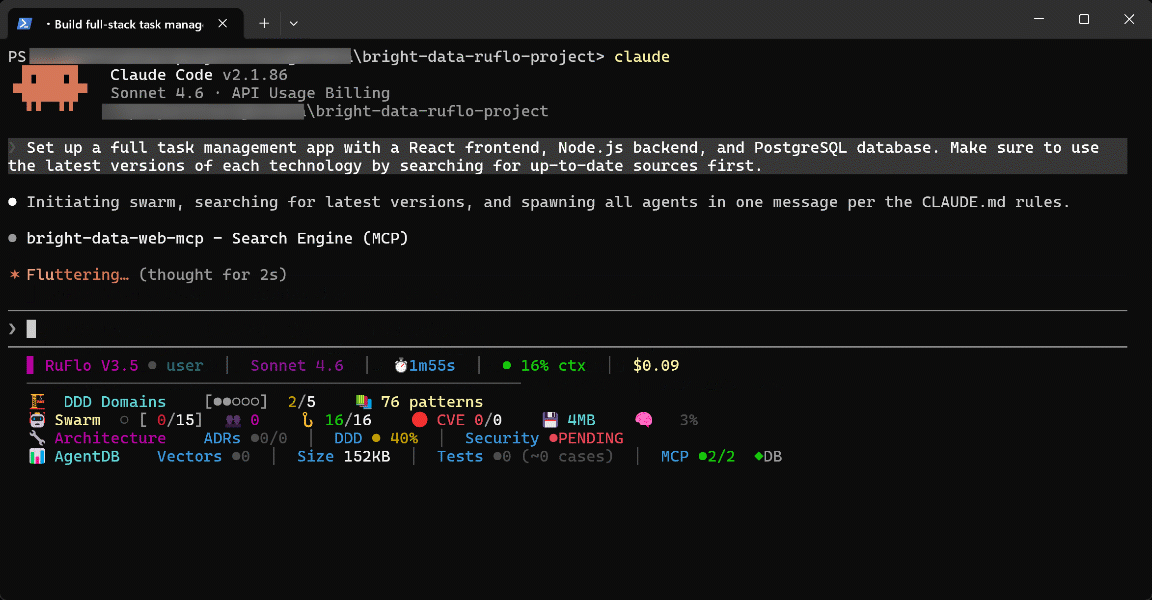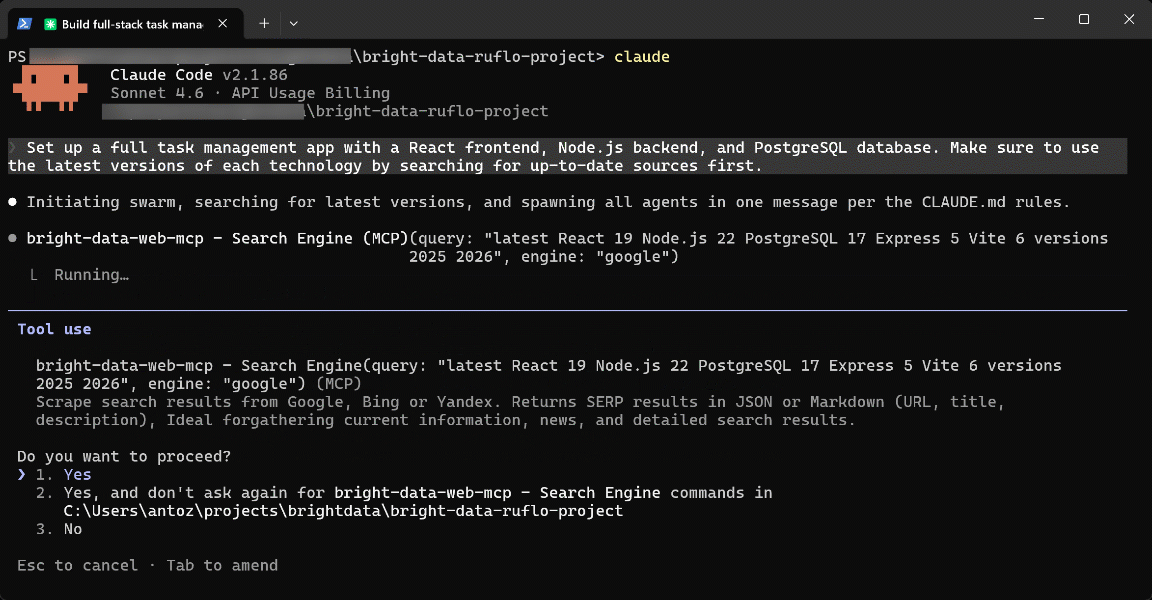
这些示例展示了在 Claude Code / OpenAI Codex 设置中将 Bright Data 与 Ruflo 一起使用所带来的协同优势。这种集成进一步扩展了 Ruflo 本已令人印象深刻的功能集,同时借助 Bright Data 的基础设施支持企业级用例。
结论
在这篇博文中,你了解了 Ruflo(前称 Claude Flow)是什么,以及它如何改变 Claude Code 和 OpenAI Codex 中的 agentic 体验。凭借约 100 个并行工作的智能体所构成的企业级基础设施,Ruflo 显著提升了性能,包括速度、token 效率和输出质量。
然而,这些工具缺乏一个面向企业、可用于网页数据检索、网页搜索以及与网站进行程序化交互的解决方案。这正是 Bright Data 发挥作用的地方,这得益于一个专用 Web MCP 服务器和一套官方 Claude 技能。这些让连接到Bright Data 面向 AI 构建的完整工具、服务和基础设施套件变得简单。
在这里,你学习了如何在 Claude Code 中配置强大的 Ruflo + Bright Data 设置,以最大限度提升编码辅助的效率和效果。
立即免费创建一个 Bright Data 账户,开始探索面向 AI 的网页数据解决方案!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。


